






3.4 多个例子中的向量化
对于m个样本而言,上述步骤要重复m次,即输入,四个等式进行计算,输出
;输入
,四个等式进行计算,输出
;
;输入
,四个等式进行计算,输出
;假如使用for loop编程:
版本1:
如何向量化?先进行定义:
记住一条原则:横向堆叠就可遍历不同样本;
版本2:Vectorized
![w^{[1]},b^{[1]},w^{[2]},b^{[2]},A^{[1]},A^{[2]}](https://latex.csdn.net/eq?w%5E%7B%5B1%5D%7D%2Cb%5E%7B%5B1%5D%7D%2Cw%5E%7B%5B2%5D%7D%2Cb%5E%7B%5B2%5D%7D%2CA%5E%7B%5B1%5D%7D%2CA%5E%7B%5B2%5D%7D) 这些矩阵的维度怎么判断?
这些矩阵的维度怎么判断?
首先从入手,
显然是
的矩阵;
,它的列数是
,而它的行数是
,表示第一层的隐藏单元数;
,它的列数是1,而它的行数是
;
,它的列数等于m,它的行数等于
;
的维数与
保持一致;
,它的列数等于
,它的行数等于1,也等于
,是巧合吗?
,是一个数,但是也可以说它的列数是1,而它的行数等于
,是巧合吗?
,它的列数等于m,它的行数等于1,也等于
;
,它的维度与
保持一致;
事实上,即使对于多隐层神经网络,也就是我们常说的深层神经网络而言,我们能够总结出一些普适性的维度规律:
的维度必须是
;
的维度必须是
,即使是多样本下对
之类也一样;
的维度必须是
,且
的维度就是
;
为什么说这四个方程就实现了向量化?
第一列等于:
第m列等于:
通过广播变为
显然加起来以后,的第一列和
的第一列相一致,验证二者第m列也一致,由于m可以变化,所以具有普适性,证明
,也就证明这实现了对m个样本的向量化
笔者虽然证明了实现了向量化的原因,但就不放在这了;
3.6 激活函数
并不总是用函数,一般形式应该写为:
主要有四类激活函数:函数、
函数、
函数、
函数;
什么时候使用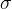 函数进行激活?
函数进行激活?
只有在做二元分类问题时,才会仅仅在输出层使用函数进行激活;
什么时候使用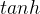 函数进行激活?
函数进行激活?
它的激活效果总是优于函数;

它实际上就是函数的图像进行平移和伸缩变换以后的图像;
它的学名叫双曲正切函数,输出介于-1到1之间,激活函数的平均值更接近于0,有类似于数据中心化的效果,能够使下一层更简单,所以效果优于函数;
函数和函数共有的缺点是什么?
当很大或很小时,导数非常小,接近于0,此时会大幅降低梯度下降法的效率;
什么时候用 函数进行激活?
函数进行激活?
如果不确定隐层要用什么激活函数,那么默认用函数即可;

虽然函数当
时导数为0,但实际中是有可能避免这个缺点的;
函数只是在
函数基础上,当
时修改了一下,使得其导数不再为0,而是一个很小的数,默认是0.01;

使用函数,神经网络的学习速度会加快很多,因为有相当大的
空间导数一直为1不会衰减,更不会出现斜率接近于0时减慢学习速度的效应。
3.7 为什么需要非线性激活函数?
如果全是线性激活函数比如,那么模型的输出
或
就仅仅是输入特征
的线性组合,无论隐藏层多深都改变不了这一点;数学上,两个线性函数的组合依然只是线性函数;几乎只有在应用机器学习的回归问题时才可能在输出层的节点使用线性激活函数,其他都不会考虑使用;注意
函数是非线性的;
3.8 激活函数的导数
这意味着如果对于函数和
函数,如果求出了
,就能够快速求导;
可以认为定义处的导数值,但几乎没有影响;















 5339
5339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









