






记录cv2中kmeans函数的使用方法,包括各个参数的含义,方便以后查看。
参考文档有:
1. kmeans中的帮助文档
import cv2
help(cv2.kmeans)2. https://blog.csdn.net/lanshi00/article/details/104109963
正文:
一、函数说明
K-Means聚类算法流程:
第一步:确定K值,聚类成K个类簇。
第二步:从数据中随机选择(或按照某种方式)K个数据点作为初始分类的中心。
第三步:分别计算数据中每个点到每个中心的距离,将每个点划分到离中心最近的类中
第四步:当每个中心都划分了一些点后,去每个类的均值,选出新的中心。
第五步:比较新的中心和之前的中心,如果新的中心和之前的中心之间的距离小于某阈值,或迭代次数超过某阈值,认为聚类已经收敛,终止。
第六步:否则继续迭代执行第三到五步,直到第五步满足。
————————————————
版权声明:本文为CSDN博主「一只辛巴」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lanshi00/article/details/104109963
cv2.kmeans的函数格式如下:
retval, bestLabels, centers = cv2.kmeans(data, K, bestLabels, criteria, attempts, flags[, centers])
1. 输入参数:
1.1 data:输入的数据集合,可以是一维或者多维数据,每个样本应该用一行表示。类型是Mat类型,例如:
-
Mat points(count, 2, CV_32F):表示数据是二维,32位浮点数数据集。
-
Mat points(count, 1, CV_32FC2):表示数据是一维,32位单精度浮点数的复数数据集。
其中,该矩阵的大小为 (count, 1),即有 count 行,1列。每个矩阵元素都是一个复数类型,使用 CV_32FC2 表示,其中 32 表示使用单精度浮点数存储,FC2 表示每个元素包含两个单精度浮点数,分别表示复数的实部和虚部。因此,该矩阵可以用来表示包含 count 个复数的向量。
1.2 K:聚类簇数。
1.3 bestLabels:算法内部使用的标记数组,可以用于指定初始聚类标记。默认为 None。
1.4 criteria:算法结束的条件。它是一个三元组:(type,max_iter,epsilon),其中:
- type:终止条件类型,可以为如下三种类型:
- cv2.TERM_CRITERIA_EPS:通过计算精确度来结束算法,精度为epsilon。
- cv2.TERM_CRITERIA_MAX_ITER:通过执行最大迭代次数来结束算法,迭代次数为 max_iter。
- cv2.TERM_CRITERIA_EPS+cv2.TERM_CRITERIA_MAX_ITER:通过这两个条件的任 何一个满足时结束算法。
- max_iter:最大迭代次数。
- epsilon:算法的精度阈值。
1.5 attempts:使用不同初始标记执行算法的次数。算法选择产生最佳结果的标记作为输出。默认为10。
1.6 flags:标志参数,可以为如下值:
- cv2.KMEANS_RANDOM_CENTERS:随机选择初始聚类中心。当数据分布较为均匀时,使用随机选择的初始聚类中心可能效果不错,因为每个聚类中心可能位于数据的中心位置。但是,当数据分布不均匀时,随机选择的初始聚类中心可能会导致算法找到局部最优解。
- cv2.KMEANS_PP_CENTERS:使用 kmeans++ 算法选择初始聚类中心。可以提高算法的稳定性和收敛速度,从而更容易找到全局最优解。因此,当数据分布不均匀或聚类数量较多时,使用 kmeans++ 算法可以得到更好的聚类结果。
- cv2.KMEANS_USE_INITIAL_LABELS:使用传入的 bestLabels 来指定初始聚类标记。可以从指定的初始聚类标记开始迭代算法,从而加速算法的收敛。这种方法通常用于需要在多个数据集之间保持一致的情况。
1.7 centers:可选的输出参数,包含每个聚类的中心。默认为 None。
2. 返回值
2.1 retval:聚类的紧凑度(样本到其所属聚类中心的距离平方和)。
2.2 labels:一个与输入数据大小相同的一维数组,包含每个样本的标记,标记的取值范围为 0 到 K-1。
2.3 centers:聚类的中心。如果未提供,则由函数计算。中心矩阵的大小为 K 行(每个簇一个中心),每行数据的列数与输入数据的列数相同。
二、应用
1. 需求:对一张rgb图片进行聚类处理,得到聚类后的图像。以其通过聚类分辨出背景和前景。
2. 步骤:
1. 聚类前操作--改图像的shape和数据类型,配置函数参数
(1) 读入图片
(2)将图转换为二维数据(即符合1.1中data的要求),并将字符类型转为浮点型
(3)配置kmeans函数中的参数,包括聚类簇数K,条件criteria。
2. 聚类后操作--应用聚类,得到聚类后的图像
(4)应用cv2.kmeans函数,得到三个返回值,分别为紧凑度,标记,中心。
(5)将聚类中心centers从浮点型转为int
(6)根据标记,将图像中每个像素点的灰度值(3个通道)赋值为聚类中心的灰度值(3个通道)
(7)调整聚类后数据的形状,得到聚类操作后的图像
3. 代码:
import numpy as np
import cv2
import matplotlib.pyplot as plt
# 1. 读入图片
img_path = r'图\像\地\址'
img = cv2.imread(img_path,1)
# print('shape of img:', img.shape) # 输出为(540, 437, 3)
# 2. 转换图片格式
# 2.1 # 使用reshape将一个像素点的RGB值作为一个单元处理
data = img.reshape((-1, 3)) # 540*437行 3列
# 2.2 # 整型转换为浮点类型
data = np.float32(data) # 浮点型数据
# 3. 配置参数
K = 4
type = cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER
max_iter = 20
epsilon = 1.0
criteria = (type, max_iter, epsilon)
attempts = 10
# flags = cv2.KMEANS_RANDOM_CENTERS
flags = cv2.KMEANS_PP_CENTERS
# 4. 应用聚类
ret, labels, centers = cv2.kmeans(data, K, None, criteria, attempts, flags)
print('shape of labels',labels.shape ) # 输出为(235980, 1),2维的
# 5. 对聚类中心的处理
centers = np.uint8(centers) # 转为整型
# 6. 将聚类中心储存的颜色数据赋值给各个标记位置的像素
img_re = centers[labels.flatten()] # 高级索引操作:lables.flatten()将labels展开为1维序列list。
# labels中储存的为每个像素位置的聚类标记,K=2时,为0和1,作用为分别取centers中的第0行和第1行数据。
img_re2 = img_re.reshape((img.shape)) # 转换为原图像的shape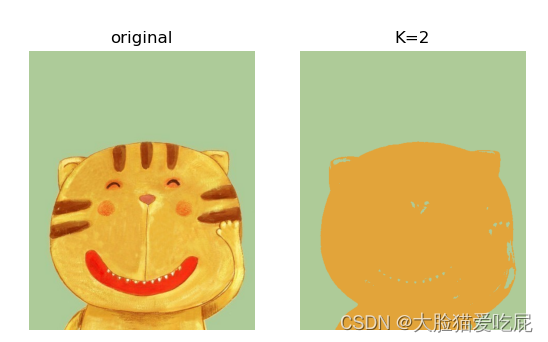
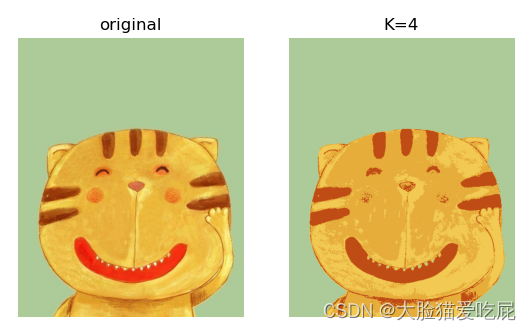
总结:
1. cv2中的聚类操作需要先将原图像数据降维,经过聚类后再升维。
2. 对kmeans中的参数进行了学习,但未详细比较不同flags值的差异。
3. 对像素赋值时用到了“高级索引”或“花式索引操作”。
4. 不懂的地方就print出来
其他资料:















 9122
9122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









