






引言
在数字化转型的浪潮中,运维工程师的角色正从「系统管家」向「架构设计师」演进。本文以本人的十年运维历程为脉络,解析传统运维向云原生运维的转型路径,呈现电力、汽车行业的规模化实践与信创迁移的深度落地经验。
一、技术转型:从 Linux 深度运维到云原生工程实践
1. 传统运维深耕:电力行业的企业级夯实(2018-2024)
▶ 湖北国家电网项目
- 监控体系:搭建 Zabbix + Prometheus 混合监控平台,通过 Grafana 可视化 500+ 指标,实现「分钟级告警-小时级处置」闭环
- 容灾架构:设计「同城双活+异地灾备」三级架构(RTO<30min, RPO<15min),保障核心业务 99.99% SLA
- 标准化建设:编制《国网系统运维操作手册(2022)》,沉淀 200+ 标准作业流程(SOP),培养 5 名持证运维工程师(RHCE/OCSP)
▶ 技术栈:Linux 内核调优(CentOS 7/8)|Bash/Python 自动化|ITIL 4 运维体系|Zabbix 二次开发
2. 云原生跃迁:汽车行业的规模化实践(2024至今)
▶ 东风集团华中云平台
- 集群构建:基于 K8s v1.25 搭建 3000+ 节点生产集群(含 8 大业务线:风神/岚图/猛士等)
- 分层架构:Control Plane(5 节点 etcd 高可用)+ Worker Plane(按业务划分 Node Pool,GPU/CPU 资源隔离)
- 服务治理:Istio 1.18 服务网格(实现流量镜像、故障注入)+ Prometheus 联邦监控(覆盖 10 万+ 指标)
- 自动化体系:
- 部署工具:Helm 3.10 管理 200+ Chart(交付效率提升 3 倍)
- 巡检脚本:Python 实现节点异常检测(集成企业微信告警,MTTR 缩短至 20min)
# K8s 节点资源巡检脚本(示例) from kubernetes import client, config config.load_incluster_config() v1 = client.CoreV1Api() nodes = v1.list_node().items for node in nodes: allocatable = node.status.allocatable if float(allocatable['cpu']) < 0.5: # CPU 可用率 < 500m send_alert(f"节点 {node.metadata.name} CPU 资源紧张")
二、运维工程师的三大核心能力矩阵
1. 架构治理能力
- 集群生命周期管理:自研K8s Operator实现应用一键部署(交付效率提升3倍)
- 成本优化实践:通过Node资源配额+KEDA弹性伸缩,降低25%的云资源成本
2. 自动化工程能力
-
工具链建设:
![graph LR
A[Prometheus监控] --> B[Alertmanager告警]
B --> C{一级处理:团队成员}
C -->|解决| D[Jira记录]
C -->|升级| E[二级处理:本人]
E --> F[编写Ansible Playbook]
F --> G[纳入运维自动化平台]](https://i-blog.csdnimg.cn/direct/c451d45931084b909f4c95c7eb7d4d79.png)
-
效率数据:自动化覆盖 80% 重复性工作(如节点扩容、日志归档),人均维护节点数从 200 提升至 500+
-
工具链建设:
# 自动化巡检脚本示例(检测K8s节点异常) import kubernetes from prometheus_api_client import PrometheusConnect def check_node_anomalies(): pc = PrometheusConnect(url="http://prometheus:9090") query = 'sum(rate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) < 0.1' results = pc.custom_query(query) return [instance['metric']['instance'] for instance in results] if __name__ == "__main__": anomalies = check_node_anomalies() if anomalies: send_alert(f"发现异常节点:{anomalies}") # 集成企业微信告警
3. 团队赋能体系
- 能力模型:四维评估体系(技术深度/项目管理/行业认知/沟通协调)
- 知识沉淀:内部 Wiki 300+ 文档(含《K8s 故障排查手册》《信创迁移操作指南》)+ 月度复盘会(重大故障根因分析)
三、信创迁移:全栈国产化的实战图谱(精确到技术栈)
1. 迁移矩阵(东风某核心项目)
| 层级 | 原技术栈 | 信创替代方案 | 优化策略 |
|---|---|---|---|
| 基础设施 | AWS EC2 | 中国电子云(CECloud)C3 服务器 | 定制 BIOS 固件(支持飞腾/鲲鹏芯片) |
| 操作系统 | CentOS 8 | 银河麒麟 V10 SP2(国产化内核) | 内核参数调优(net.ipv4.tcp_tw_reuse=1) |
| 容器平台 | K8s社区版 | 中国电子云容器平台(基于K8s v1.23) | 适配国产化 CNI(Kube-OVN 2.6) |
| 数据库 | MySQL 8.0 | 达梦数据库 DM8(集群版) | 读写分离架构(主库 2 节点+从库 3 节点) |
| 中间件 | Tomcat 9 | 东方通 TongWeb 7.0 | 连接池优化(最大连接数从 200 增至 500) |
| 消息队列 | Kafka 2.8 | 金仓消息中间件 KingbaseESMQ | 多副本机制(3 副本保障数据一致性) |
2. 实施路径
- 双轨验证:新旧环境并行运行 14 天(流量按 20%:80% 逐步切换)
- 性能调优:
- 容器启动优化:预热镜像(减少 30% 启动时间)+ 内核命名空间隔离
- 数据库迁移:数据脱敏工具(自研 Python 脚本)+ 全量备份(使用达梦 DMRMAN 工具)
- 成果数据:
- 完成 217 个微服务迁移,平均响应时间增加 80ms(优化后缩至 30ms)
- 构建「15 分钟故障回滚」机制(基于 Velero 备份恢复)
四、职业发展:从执行到架构的跃迁路径
1. 能力进化图谱 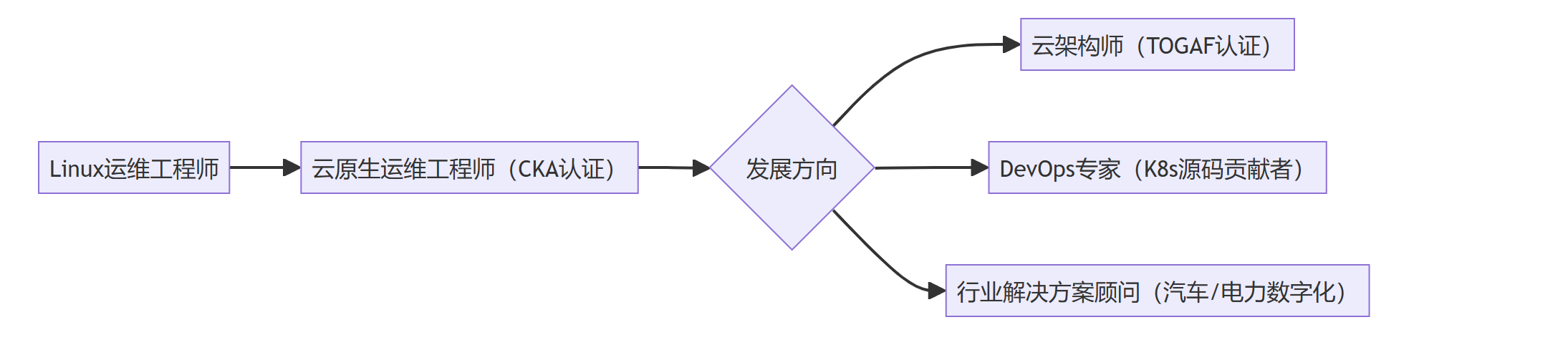
2. 转型建议
- 技术纵深:精读《Kubernetes 权威指南》(第 5 版)+ 掌握 Service Mesh 原理(Istio 流量管理)
- 行业洞察:理解汽车数字化核心场景(车联网实时数据处理、OTA 升级运维)
- 软技能:学习 ITIL 4 服务价值体系 + OKR 目标管理(提升跨团队协作效率)
五、未来展望:智能运维的行业实践
1. 汽车行业:车云协同运维体系
- 边缘计算:基于 K3s 构建车载边缘集群(支持 100ms 级故障自愈)
- 数据湖运维:治理 10PB 级车联网日志(Flink 实时分析 + Hudi 数据湖架构)
2. 信创领域:全栈国产化最佳实践
- 制定《容器云信创适配标准》(涵盖 12 类国产化组件兼容性测试)
- 探索「信创多云管理」(中国电子云 + 华为云 Stack 混合部署)
结语
本人的十年运维之路,印证了「运维即架构」的核心理念:从国家电网的稳态架构到汽车云的敏态创新,从传统工具到云原生体系,运维工程师始终是技术与业务的桥梁。在智能运维时代,我们需要兼具「螺丝刀精神」(深耕技术细节)与「建筑师思维」(设计系统架构),方能在不确定性中构建确定性的技术底座。
技术人箴言:
“运维的终极目标,是让复杂的系统看起来简单——这需要对每个组件的深刻理解,更需要对全局架构的精准把控。”
作者简介:
本人,10 年运维老兵,现任某头部 IT 企业云原生运维负责人(PMP/CKA/信创运维认证)。主导完成:
- 湖北国家电网「两地三中心」容灾体系(获 2023 年国网运维创新奖)
- 东风集团首个信创云平台(支撑 8 大汽车品牌数字化转型)
- 中国电子云容器平台行业适配(贡献 3 项国产化 CNI 优化补丁)
博客互动:
- 技术探讨
- 经验交流



















 5621
5621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











