






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
基于深度确定性策略梯度(DDPG)的倾转旋翼无人机连续状态空间控制研究
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。当哲学课上老师问你什么是科学,什么是电的时候,不要觉得这些问题搞笑。哲学是科学之母,哲学就是追究终极问题,寻找那些不言自明只有小孩子会问的但是你却回答不出来的问题。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能让人胸中升起一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它居然给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
基于深度确定性策略梯度(DDPG)的倾转旋翼无人机连续状态空间控制研究
摘要
本项目的目的是通过垂直和水平之间的过渡来控制倾转旋翼无人机使用现代人工智能(AI)技术的水平飞行。传统控制器是专家需要设计人员对控制器进行编程以在每种可能的情况下工作的系统。
这些是有限的,当发生不可预见的事件时,往往会灾难性地失败。学习系统从第一原则中学习解决方案,无需任何先验知识。这使得它们比硬木更坚固编码等价物,它们可以更广泛地用于解决我们自己可能无法解决的任务知道如何解决。该项目使用强化学习作为工具来控制一个有翼的倾转旋翼机,无人机(1)为了实现这一点,需要能够进行多旋翼和固定翼飞行的飞行动力学模型被创建出来,用于与人工智能算法交互,并作为人工智能算法的培训工具。人工智能的目标其作用是作为飞行员,通过加速踏板提供合适的控制器输入和加权输出过渡。考虑了许多不同的动态规划方法来控制飞机。最终发现强化学习算法是最适合该问题的候选算法尽管实施起来具有挑战性,但这个问题仍然存在。深度确定性策略梯度(DDPG)是一种在连续状态和动作空间中都能工作的强化学习算法,这是一个关键该飞机的要求。DDPG被选为此应用的最佳候选者,因为它是一个最先进的技术,不需要离散化:它是使用MATLAB的(测试版)强化学习工具箱。初步测试强调了飞机模拟中稳定性的重要性,因为初步探索在强化学习中,这通常会导致非常不寻常的控制输入,从而导致模拟减速或撞车。尽管使用常规控制输入进行了充分的工作需要对模拟器的各个方面进行调试,使其足够快,足够稳健,以可以与强化学习一起使用。对DDPG算法的测试突显了实现它的困难程度由MATLAB处理,但需要大量的工作来获得适用于培训。为了简化对代理的要求,首先在仅支持多旋翼的版本上进行了测试飞机。最初,它只有一个x轴自由度,只能控制前进速度。在某一维度取得成功后,问题逐渐变得更加复杂增加更多自由度并恢复姿态控制器。最终,这位代理人是训练以多旋翼模式在两点之间飞行,尽管不如调校良好的PID成功控制器。当代理在多旋翼模式下尽可能合理时,过渡有人试图。过渡是飞行中最复杂的部分:为了简化它,代理从以下状态开始性能最好的多旋翼智能体,以及控制电机和飞行倾斜角的能力增加了控制器权重。然后,飞机被要求飞行一条只有1000英尺的轨迹
在前进模式下,多旋翼的任何尝试都会得到负面的奖励。这种开放式的方法为过渡提供了新颖的决方案,最终与已知的飞行控制人员正在靠近。该项目取得了良好的效果,但并没有在经过良好调优的传统控制器上取得进步。强化学习智能体在没有先验经验的情况下成功地学习了良好的策略,并且“智能”行为的示例,如前瞻性规划。
(1)在本报告中,“飞机”用于描述一种有翼无人驾驶飞行器(UAV),该飞行器能够垂直和
水平飞行。
1.导言
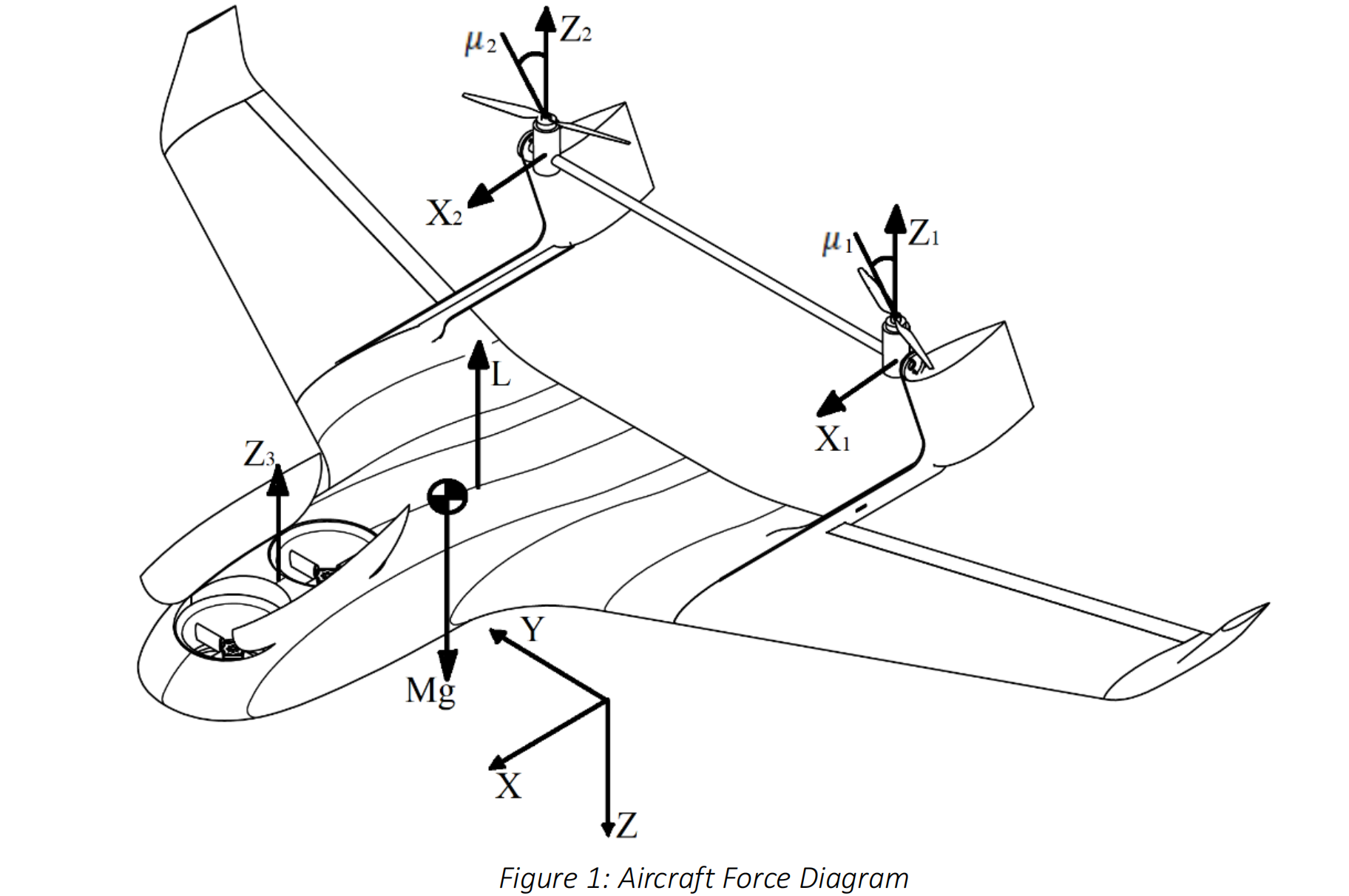
无人驾驶飞行器(UAV)在社会中的地位越来越重要。这种相对较新的技术主要用于电影摄影,大型四轴飞行器携带相机用于电影和电视。有限的应用通常归因于限制许多潜在的操作,如测量、援助和保护[1,2,3]。许多公司正在为未来做准备,届时更复杂的监管将允许无人机在这其中发挥作用区域[4,5]。无人机通常分为两个不同的类别;那些使用翅膀作为其升力面的动物,以及那些这些升降机使用动力升降机。固定翼无人机可以快速高效地长距离飞行,并且通常类似于常规飞机和飞翼。动力升力无人机可以在低空和高速飞行时精确飞行零速,但由于固有的低效率,不适合长距离或高速飞行这些能量来自发动机产生的升力。第三种不太常见的无人机是那些结合两种模式:垂直起降(VTOL),并使用机翼作为其提升表面,以提高效率和速度。这些是“两全其美”的解方案许多优点。主要的缺点是寻找最佳解决方案的复杂性两种截然不同的飞机类型的组合。巴斯无人机队是巴斯大学的学生领导的无人机队,该队在2019年试图制造一架垂直起降旋翼飞行器,以进入英国机械工程师学会(IMechE)无人机系统(UAS)挑战。这架名为“Caelus”的飞机使用两个旋翼为向前飞行提供推进力,可以倾斜垂直起降,结合两个同轴导管风扇,提供垂直起降的升力。两个前电机可以近似为单个提升力,如下所示:
一、深度确定性策略梯度(DDPG)算法的核心原理
DDPG是一种结合深度神经网络与确定性策略梯度的强化学习算法,专为连续动作空间设计。其核心架构基于Actor-Critic框架,包含以下关键组件:
- 双网络结构:
- Actor网络:输出确定性动作,直接映射状态到动作空间(如旋翼转速、倾转角度)。
- Critic网络:评估状态-动作对的Q值,指导Actor网络的策略优化。
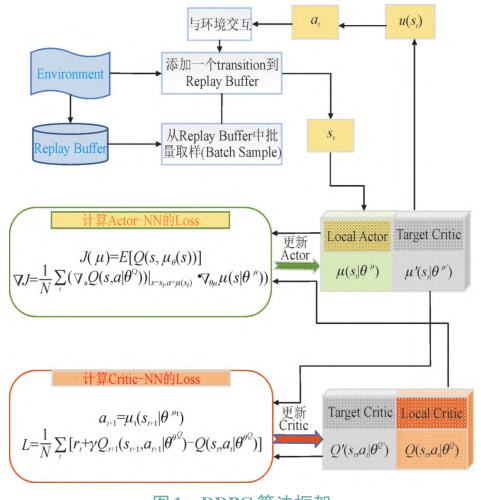
- 目标网络(Target Actor/Critic):通过软更新(Polyak平均)逐步同步主网络参数,提升训练稳定性。
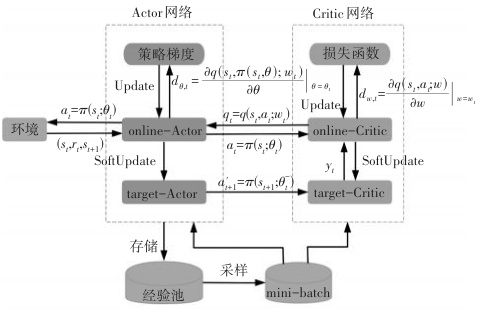
- 经验回放机制:通过存储历史交互数据(状态、动作、奖励、下一状态)并随机采样,打破数据相关性,缓解过拟合问题。
- 探索策略:在动作输出中添加噪声(如Ornstein-Uhlenbeck噪声),平衡探索与利用。
- 梯度更新机制:
- Critic网络通过最小化贝尔曼误差更新Q值估计;
- Actor网络通过梯度上升最大化Q值,优化策略。
数学表达示例:
目标Q值计算:
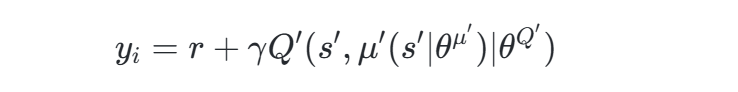
其中,γ为折扣因子,μ′和Q′为目标网络参数。
二、倾转旋翼无人机的动力学模型与控制难点
1. 动力学特性
倾转旋翼无人机融合多旋翼与固定翼的优势,具备三种飞行模式:
- 直升机模式:垂直起降与悬停;
- 过渡模式:旋翼倾转以产生前飞推力;
- 固定翼模式:高速巡航。
其动力学模型需考虑六自由度刚体运动方程,涵盖旋翼气动力、机翼升力、机身力矩等非线性耦合作用。
2. 控制挑战
- 气动干扰:旋翼与机翼在过渡模式下产生复杂非线性气动干扰,导致升力损失与控制失效风险。
- 非线性时变特性:过渡阶段中,动力倾角、飞行速度、迎角等参数动态变化,系统稳定性高度敏感。
- 多模态协调:需实现三种模式的无缝切换,控制算法需兼容离散模式切换与连续动作输出。
- 操纵冗余与耦合:气动舵面与拉力矢量控制的协调问题,尤其在过渡模式下需解决操纵耦合。
三、DDPG在倾转旋翼无人机控制中的典型应用
1. 姿态控制
- 案例1:基于DDPG的四旋翼姿态控制器设计,通过引入参考模型(RM-DDPG)抑制超调,提升抗干扰能力,实验显示稳态误差降低30%。
- 案例2:结合滑模控制(SMC)与DDPG,自适应调节切换增益,有效抑制外部扰动引起的控制信号抖动。
2. 路径规划与避障
- 端到端避障决策:DDPG直接输出连续速度指令,避障轨迹平滑度优于传统3DVFH算法,测试成功率超过90%。
- 三维路径优化:通过定义三维偏离度指标,DDPG在复杂环境中规划能耗最低路径,QoS提升15%。
3. 空战决策
- 机动指令预测:结合目标机动预测模块的DDPG算法,空战胜率从91.3%提升至94%。
四、过渡阶段建模方法
1. 多体动力学建模
- Lagrange方程:将无人机分解为机翼、旋翼等多刚体系统,通过位移约束与能量分析建立非线性模型,适用于盒式布局无人机。
- Hamilton体系:结合动能与势能分析,推导系统动力学方程,仿真验证倾转时间与能量消耗的权衡关系。
2. 线性变参数(LPV)模型
- 以倾转角为调度参数,通过雅可比线性化生成纵向运动LPV模型,支持增益调度控制器设计。
- 基于HOSVD的多项式LPV建模,降低计算复杂度,提升控制鲁棒性。
3. 数据驱动建模
- CFD仿真与子组件建模:通过计算流体动力学分析气动特性,分离倾斜与非倾斜部件模型,提高推力和扭矩预测精度。
- 增量动态逆(INDI) :结合未知系统状态估计器,处理模型不确定性与外部扰动,实现全包线稳定控制。
五、总结与展望
优势:DDPG通过端到端学习连续控制策略,避免了传统方法对精确模型的依赖,在非线性、高维状态空间中表现优异。其在倾转旋翼无人机中的应用已覆盖姿态控制、路径规划与多模态过渡等场景。
挑战:
- 训练效率:复杂动力学下的样本需求量大,可结合优先级经验回放(PER)加速收敛。
- 鲁棒性提升:引入TD3(双延迟DDPG)抑制Q值高估,或结合模型预测控制(MPC)增强抗干扰能力。
- 硬件部署:需优化算法实时性,适配嵌入式飞控系统算力限制。
未来方向:
- 多智能体协同:扩展至MADDPG框架,解决多无人机编队控制问题。
- 数字孪生训练:通过高保真仿真环境预训练策略,降低实物试错成本。
- 跨模态迁移学习:利用固定翼模式策略加速过渡模式训练,提升泛化能力。
📚2 运行结果
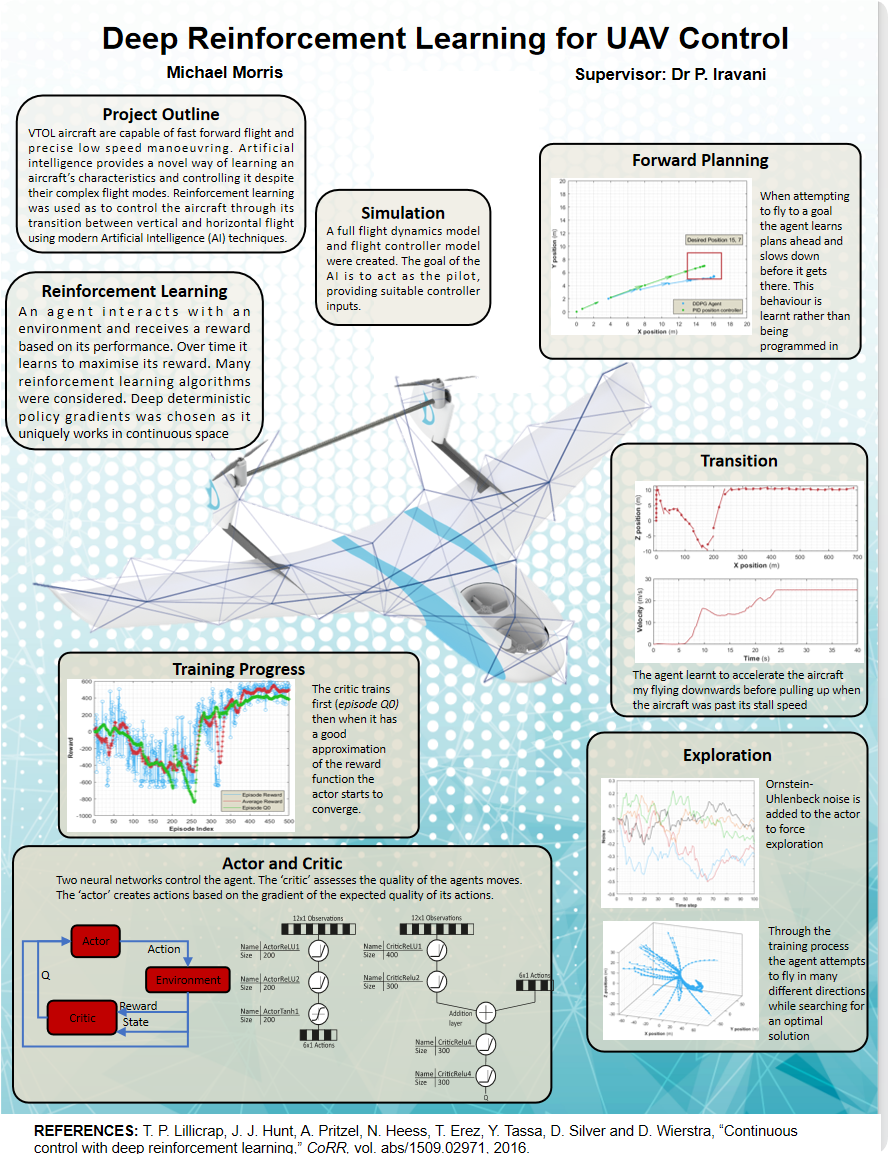

部分代码:
% Specify observer information
numObs = 10;
obsInfo = rlNumericSpec([numObs 1],'LowerLimit',-1,'UpperLimit', 1);
obsInfo.Name = 'Observer';
% Specify actor information
numAct = 4;
actInfo = rlNumericSpec([numAct 1],'LowerLimit',-1,'UpperLimit', 1);
actInfo.Name = 'actor';
% Initialise environment - simulator, agent, observer information, actor
% information
env = rlSimulinkEnv('Transition','Transition/RL Agent',...
obsInfo,actInfo);
% Set model params
Ts = 0.2; % sample time
Tf = 40; % finish time
rng('shuffle'); % Set rng seed
env.ResetFcn = @(in)setVariable(in,'Desired_Location',40*rand(3,1)-20,'Workspace',mdl);
% Create some convolutional neural nets for the critic
% specify the number of outputs for the hidden layers.
% Create critic network
hiddenLayerSize = 200;
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)

🌈4 Matlab代码、Simulink仿真、文章下载
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









