






本文章主要讲解百度的rt-detr模型环境搭建和如何训练自己的数据集,
进入github下载rt-detr源码:rt-detr源码连接
下载完毕后解压打开rt-detr pytorch,界面如下:
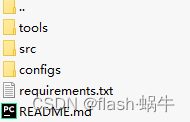
项目目录介绍
其中:tools文件是训练和模型导出的py文件,包含了模型训练和模型导出模块。文件内容如下:
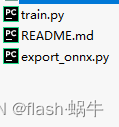
其中train.py主要是模型的训练接口。export_onnx.py主要是将pytorch模型转化为onnx模型方便后续部署。
src文件主要包含了模型优化器,主干网络,数据加载,日子记录,配置文件的读取的源码。子文件如下:
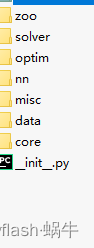
configs文件主要是模型的配置文件,可以通过模型设置配置文件进行模型训练前的配置。子文件如下:
requirements.txt主要是运行该项目所需要安装的库,直接运行一下命令进行安装:
pip install -r requirements.txt安装完成后就可以开始制自己的数据集。
训练自己的数据集:
1:在configs文件下创建train_src文件夹
将标注的图像和xml放入train_src文件。
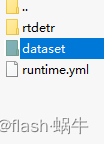
2:在config文件下的dataset文件里创建coco数据集格式的文件,文件目录如下:

3:将xml转换为coco数据集格式:
这里我为大家提供xml转coco数据集格式代码:
"""
划分数据集
"""
import os
import glob
import json
import shutil
import numpy as np
import xml.etree.ElementTree as ET
path2 = 'configs/dataset/coco'
START_BOUNDING_BOX_ID = 1
def get(root, name):
return root.findall(name)
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise NotImplementedError('Can not find %s in %s.' % (name, root.tag))
if length > 0 and len(vars) != length:
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.' % (name, length, len(vars)))
if length == 1:
vars = vars[0]
return vars
def convert(xml_list, json_file):
json_dict = {"images": [], "type": "instances", "annotations": [], "categories": []}
categories = pre_define_categories.copy()
bnd_id = START_BOUNDING_BOX_ID
all_categories = {}
for index, line in enumerate(xml_list):
# print("Processing %s"%(line))
xml_f = line
tree = ET.parse(xml_f)
root = tree.getroot()
filename = os.path.basename(xml_f)[:-4] + ".jpg"
image_id = 0 + index
size = get_and_check(root, 'size', 1)
width = int(get_and_check(size, 'width', 1).text)
height = int(get_and_check(size, 'height', 1).text)
image = {'file_name': filename, 'height': height, 'width': width, 'id': image_id}
json_dict['images'].append(image)
## Cruuently we do not support segmentation
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, 'object'):
category = get_and_check(obj, 'name', 1).text
if category in all_categories:
all_categories[category] += 1
else:
all_categories[category] = 1
if category not in categories:
if only_care_pre_define_categories:
continue
new_id = len(categories) + 1
print(
"[warning] category '{}' not in 'pre_define_categories'({}), create new id: {} automatically".format(
category, pre_define_categories, new_id))
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, 'bndbox', 1)
xmin = int(float(get_and_check(bndbox, 'xmin', 1).text))
ymin = int(float(get_and_check(bndbox, 'ymin', 1).text))
xmax = int(float(get_and_check(bndbox, 'xmax', 1).text))
ymax = int(float(get_and_check(bndbox, 'ymax', 1).text))
assert (xmax > xmin), "xmax <= xmin, {}".format(line)
assert (ymax > ymin), "ymax <= ymin, {}".format(line)
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {'area': o_width * o_height, 'iscrowd': 0, 'image_id':
image_id, 'bbox': [xmin, ymin, o_width, o_height],
'category_id': category_id, 'id': bnd_id, 'ignore': 0,
'segmentation': []}
json_dict['annotations'].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {'supercategory': 'none', 'id': cid, 'name': cate}
json_dict['categories'].append(cat)
json_fp = open(json_file, 'w')
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
print("------------create {} done--------------".format(json_file))
print("find {} categories: {} -->>> your pre_define_categories {}: {}".format(len(all_categories),
all_categories.keys(),
len(pre_define_categories),
pre_define_categories.keys()))
print("category: id --> {}".format(categories))
print(categories.keys())
print(categories.values())
if __name__ == '__main__':
classes = ['back','FZ','ls']
pre_define_categories = {}
# for i, cls in enumerate(classes):
# pre_define_categories[cls] = i
pre_define_categories = {'back':-1,'FZ': 0,'ls':1}
only_care_pre_define_categories = True
# only_care_pre_define_categories = False
train_ratio = 0.9
# path="./configs/dataset/coco/annotations"
# save_json_train =os.path.join(path,'instances_train2017.json')
# save_json_train=os.path.abspath(save_json_train)
# # print(save_json_train)
# # save_json_train = 'configs/dataset/coco/annotations/instances_train2017.json'
# save_json_val = os.path.join(path,'instances_val2017.json')
# save_json_val=os.path.abspath(save_json_val)
save_json_train='instances_train2017.json'
save_json_val='instances_val2017.json'
xml_dir = "configs/trian_src"
xml_list = glob.glob(xml_dir + "/*.xml")
xml_list = np.sort(xml_list)
np.random.seed(100)
np.random.shuffle(xml_list)
train_num = int(len(xml_list) * train_ratio)
xml_list_train = xml_list[:train_num]
xml_list_val = xml_list[train_num:]
convert(xml_list_train, save_json_train)
convert(xml_list_val, save_json_val)
if os.path.exists(path2 + "/annotations"):
shutil.rmtree(path2 + "/annotations")
os.makedirs(path2 + "/annotations")
if os.path.exists(path2 + "/train2017"):
shutil.rmtree(path2 + "/train2017")
os.makedirs(path2 + "/train2017")
if os.path.exists(path2 + "/val2017"):
shutil.rmtree(path2 + "/val2017")
os.makedirs(path2 + "/val2017")
# f1 = open("train.txt", "w")
for xml in xml_list_train:
img = xml[:-4] + ".jpg"
# f1.write(os.path.basename(xml)[:-4] + "\n")
shutil.copyfile(img, path2 + "/train2017/" + os.path.basename(img))
# f2 = open("test.txt", "w")
for xml in xml_list_val:
img = xml[:-4] + ".jpg"
# f2.write(os.path.basename(xml)[:-4] + "\n")
shutil.copyfile(img, path2 + "/val2017/" + os.path.basename(img))
# f1.close()
# f2.close()
print("-------------------------------")
print("train number:", len(xml_list_train))
print("val number:", len(xml_list_val))
print("开始生成json")
path="./configs/dataset/coco/annotations"
save_json_train =os.path.join(path,'instances_train2017.json')
save_json_train=os.path.abspath(save_json_train)
save_json_val = os.path.join(path,'instances_val2017.json')
save_json_val=os.path.abspath(save_json_val)
if os.path.exists(save_json_train):
os.remove(save_json_train)
if os.path.exists(save_json_val):
os.remove(save_json_val)
shutil.move('instances_train2017.json',save_json_train)
shutil.move('instances_val2017.json',save_json_val)
·运行上面代码:自动生成coco数据集。
4:生成coco数据集后,开始配置yaml文件,需要配置的yml文件路径如下:
rtdetr_pytorch_self\configs\dataset\coco_detection.yml打开coco_detection.yml文件找到以下4行:
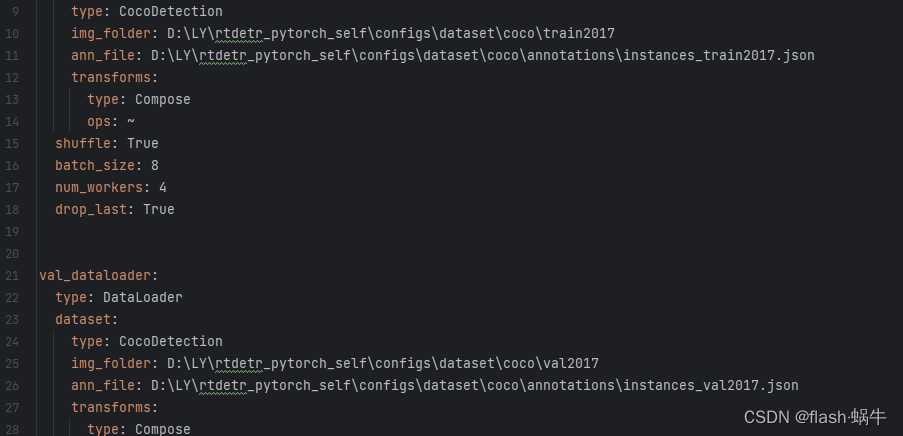
第10行和11行分别填入对应训练集的图像路径和json路径。
第25行和26行分别填入对应验证集的图像路径和json路径。
修改完成后,进入train.py文件,
 修改45行,填入你需要的模型,点击开始训练即可
修改45行,填入你需要的模型,点击开始训练即可
















 5572
5572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









