







论文地址
论文摘要
激光雷达点云3D物体检测,对于小物体如行人、自行车的检测精度较低,容易漏检误检,提出一种多尺度 Transformer激光雷达点云3D物体检测方法MSPT-RCNN(multi-scale point transformer-RCNN),提高点云3D物体检测精度。该方法包含两个阶段,即第一阶段(RPN)和第二阶段(RCNN)。RPN阶段通过多尺度Transformer网络提取点云特征,该网络包含多尺度邻域嵌入模块和跳跃连接偏移注意力模块,获取多尺度邻域几何信息和不同层次全局语义信息,生成高质量初始3D包围盒;在RCNN阶段,引入包围盒内的点云多尺度邻域几何信息,优化了包围盒位置、尺寸、朝向和置信度等信息。实验结果表明,该方法(MSPT-RCNN)具有较高检测精度,特别是对于远处和较小物体,提升更高。MSPT-RCNN通过有效学习点云数据中的多尺度几何信息,提取不同层次有效的语义信息,能够有效提升3D物体检测精度。
论文提出了一种新的基于Transformer的3d目标检测模型MSPT-RCNN,该模型包括2部分,分别为
- RPN部分;
- RCNN部分;
RPN部分主要是主要用来生成初始bbox,RCNN部分对生成的bbox进行优化。下面详细看下这两个模块都做了什么工作。
MSPT-RCNN
网络整体结构,左侧为RPN,右侧为RCNN结构。
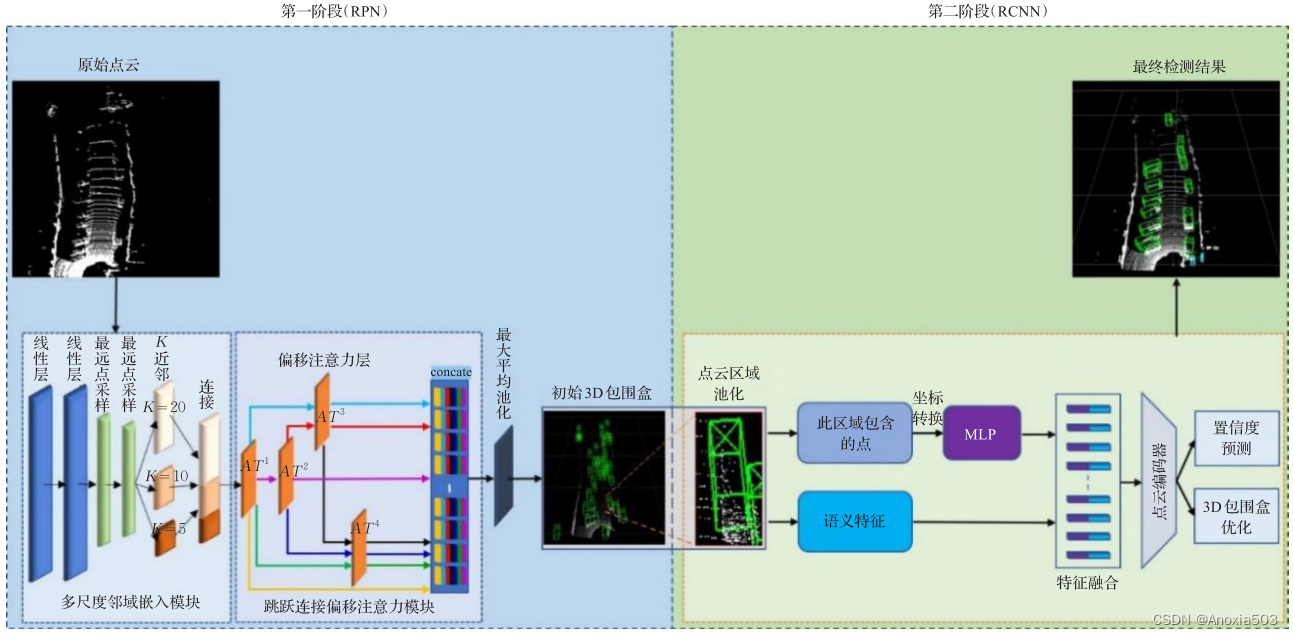
RPN
多尺度领域嵌入模块
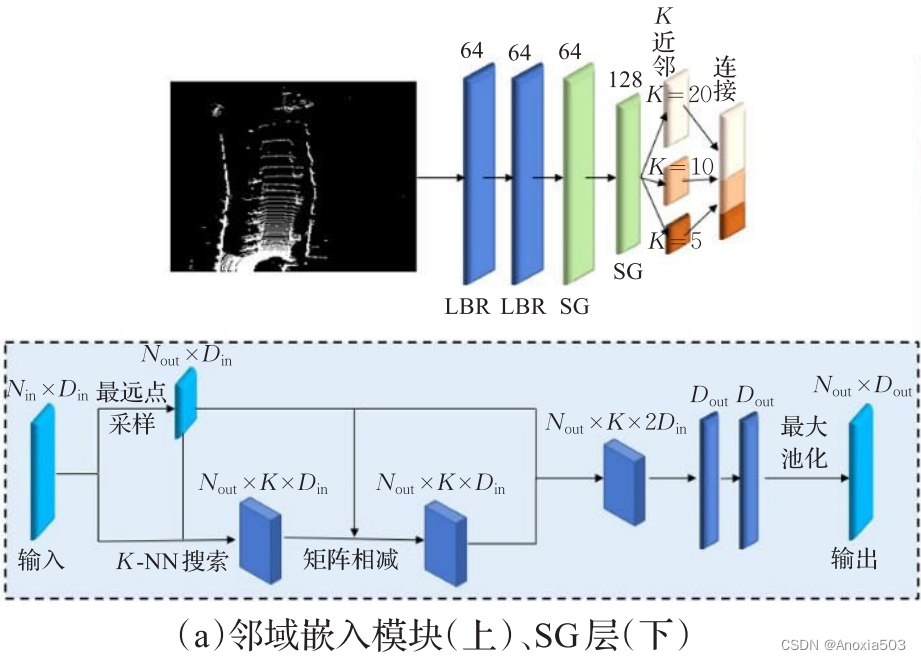
该模块主要包括两部分内容,两个LBR(Linear, BatchNorm, ReLU)和两个SG(Sampling, Grouping)。LBR部分比较清晰,每个LBR包括线性层、BatchNorm和ReLU三部分,但是这里的SG稍微有点不太好理解。下面介绍下SG部分。
关于SG部分,文中有给出以下几个公式:
{
Δ
F
(
p
)
=
c
o
n
c
a
t
q
∈
K
N
N
(
p
,
P
)
(
F
(
q
)
−
F
(
p
)
)
.
(
7
)
F
~
(
P
)
=
c
o
n
c
a
t
(
Δ
F
(
p
)
,
R
P
(
F
(
p
)
,
k
)
)
.
(
8
)
F
s
(
p
)
=
M
P
(
L
B
R
(
L
B
R
(
F
~
(
p
)
)
)
)
.
(
9
)
F
M
S
(
p
)
=
∑
i
=
20
,
10
,
5
F
S
i
(
p
)
.
(
10
)
\begin{cases} \Delta{F(p)} = concat_{q{\in}KNN(p,P)}(F(q)-F(p)). & (7)\\ \tilde{F}(P) = concat(\Delta{F(p)},RP(F(p),k)).&(8)\\ F_s(p)=MP(LBR(LBR(\tilde{F}(p)))).&(9)\\ F_{MS}(p)=\sum_{i=20,10,5}F_{S_i}(p).&(10) \end{cases}
⎩⎪⎪⎪⎨⎪⎪⎪⎧ΔF(p)=concatq∈KNN(p,P)(F(q)−F(p)).F~(P)=concat(ΔF(p),RP(F(p),k)).Fs(p)=MP(LBR(LBR(F~(p)))).FMS(p)=∑i=20,10,5FSi(p).(7)(8)(9)(10)
其中,公式(7)的concat下标结果为KNN搜索箭头右边的矩阵块,右侧将KNN结果和最远点采样结果相减,得到
Δ
F
(
p
)
\Delta{F}(p)
ΔF(p),就是矩阵相减右边的矩阵快;公式(8)将矩阵采样右边的矩阵块和最远点采样结果和
Δ
F
(
p
)
\Delta{F}(p)
ΔF(p)相加,这里的K是用来保证相加的二者形状一致,结果记为
F
~
(
P
)
\tilde{F}(P)
F~(P);公式(9)对
F
~
(
P
)
\tilde{F}(P)
F~(P)做两个LBR和一个MaxPooling,得到最终SG层的输出记为
F
s
(
p
)
F_s(p)
Fs(p)。
第二个输出128维度的SG层的输出会通过三个k分别为20、10、5的KNN,输出进行concat得到邻域嵌入模块的最终输出。
这里公式写的是求和,但是图里面是concat,公式可能写错了。
跳跃连接偏移注意力模块
注意力模块
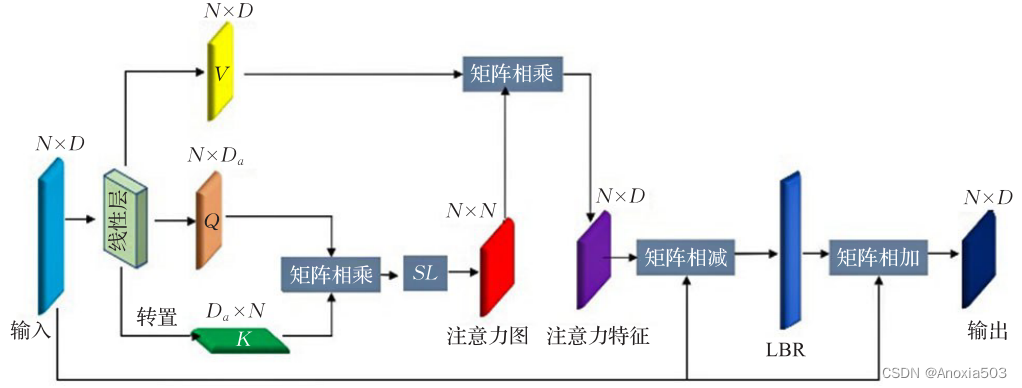
这部分内容在文中有如下几个公式:
{ ( Q , K , V ) = F M S ( p ) ⋅ ( W q , W k , W v ) . ( 11 ) Q , K ∈ R N × D a , V ∈ R N × D e . ( 12 ) W q , W k ∈ R D e × D a , W v ∈ R D e × D e . ( 13 ) \begin{cases} (Q,K,V)=F_{MS}(p)\cdot(W_q,W_k,W_v).&(11)\\ Q,K\in{R^{N\times{D_a}}},V\in{R^{N\times{D_e}}}.&(12)\\ W_q,W_k\in{R^{D_e\times{D_a}}},W_v\in{R^{D_e\times{D_e}}}.&(13) \end{cases} ⎩⎪⎨⎪⎧(Q,K,V)=FMS(p)⋅(Wq,Wk,Wv).Q,K∈RN×Da,V∈RN×De.Wq,Wk∈RDe×Da,Wv∈RDe×De.(11)(12)(13)
F M S F_{MS} FMS是多尺度邻域嵌入模块的输出,作为输入进入到偏移注意力模块,文中 D a = D e 4 D_a=\frac{D_e}{4} Da=4De。后面的SL表示归一化,文中说第一个维度用softmax第二个维度用L1正则化,这个第一第二个维度没懂是什么。然后有公式:
F O A = L B R ( F M S ( p ) − F s a ) + F M S ( p ) . ( 18 ) F_{OA}=LBR(F_{MS}(p)-F_{sa})+F_{MS}(p). (18) FOA=LBR(FMS(p)−Fsa)+FMS(p).(18)
公式(18)比较清晰的刻画了模型对注意力特征的处理。
跳跃连接偏移注意力模块
跳跃连接偏移注意力模块包含4个偏移注意力模块,连接如下:
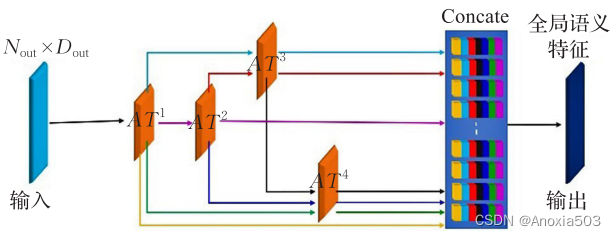
这里的跳跃偏移注意力模块有4个偏移注意力模块,关于这四个偏移注意力模块之间是如何连接的,由公式如下:
{ F 1 = A T 1 ( F M S ( p ) ) . ( 20 ) F i j = A T j ( F i ) . ( 21 ) F C = F 1 + ∑ i , j = 2 , 3 , 4 F i j . ( 22 ) F G = F C ⋅ W 0 . ( 23 ) \begin{cases} F_1=AT^1(F_{MS}(p)).&(20)\\ F_{ij}=AT^j(F_i).&(21)\\ F_C=F_1+\sum_{i,j=2,3,4}{F_{ij}}.&(22)\\ F_G=F_C\cdot{W_0}.&(23) \end{cases} ⎩⎪⎪⎪⎨⎪⎪⎪⎧F1=AT1(FMS(p)).Fij=ATj(Fi).FC=F1+∑i,j=2,3,4Fij.FG=FC⋅W0.(20)(21)(22)(23)
F M S ( p ) F_{MS}(p) FMS(p)为输入特征, A T j AT^j ATj为第 j j j个偏移注意层,每层的输入处处具有相同的维度, F 1 F_1 F1表示第1层的输出, F i , j F_{i,j} Fi,j表示 F i F_i Fi经过 A T j AT^j ATj的输出, W 0 W_0 W0表示线性层的权重。
后面接着有两个池化层,分别为最大池化和平均池化。
第一阶段,即初始bbox的生成到此结束,后面的RCNN会对初始bbox进行优化。
RCNN
点云区域池化与坐标转换
这部分包括两块,分别是点云区域池化和坐标转换。
为了避免信息遗漏和充分利用目标bbox的上下文信息,文中将在RPN阶段生成的bbox进行扩展放大,每个box从原来的 b o x i = ( x i , y i , z i , h i , w i , l i , θ i ) box_i=(x_i,y_i,z_i,h_i,w_i,l_i,\theta_i) boxi=(xi,yi,zi,hi,wi,li,θi)扩大为 b o x i e = ( x i , y i , z i , h i + η , w i + η , l i + η , θ i ) box_i^e=(x_i,y_i,z_i,h_i+\eta,w_i+\eta,l_i+\eta,\theta_i) boxie=(xi,yi,zi,hi+η,wi+η,li+η,θi),也就是将每个bbox的长宽高增加 η \eta η,文中设置 η = 1.0 m \eta=1.0m η=1.0m。这部分应该是点云区域池化。
坐标转换按照文中介绍,是将点云中每个点的坐标从世界坐标系转换为局部坐标系。主要是针对每个bbox,以每个bbox的中心点为坐标原点,X轴和Z轴与地面平行,Y轴与地面垂直,通过转换,将每个bbox中的点转换到这个局部坐标系中。然后用MLP去学习这些点的特征。
语义特征
对于每个新的包围盒,将内部点的坐标信息 F ( x , y , z ) F_{(x,y,z)} F(x,y,z)、逐点特征 F P F_P FP、多尺度领域几何特征 F M S ( P ) F_{MS}(P) FMS(P)、激光反射强度信息 F r ( p ) F_{r(p)} Fr(p)和激光雷达距离深度信息 F d ( p ) F_{d(p)} Fd(p)做concat,进行MAX_pooling得到局部全局语义特征 F C F_C FC,将 F C F_C FC通过几个全连接层网络整形到和MLP的输出 F P ~ F_{\tilde{P}} FP~相同的维度,得到语义特征 F C o u t F_{C_{out}} FCout。
特征融合
坐标转换能够实现鲁棒的局部空间特征学习,但同时会完全丢失每个点的深度信息,因此在坐标转换之后将全局语义特征融合到点P的特征中去,这样就不至于丢失点的深度特征。
将 F P ~ F_{\tilde{P}} FP~和 F C o u t F_{C_{out}} FCout做concat得到 F R F_R FR,最后将 F R F_R FR,输入到一个点云编码器网络,得到一个特征向量,用于之后的分类置信度预测和包围盒优化。最后保留一个得分最高的bbox作为检测对象的三位边界框。
感想:看论文的过程中还是有很多细节的东西把握不住,还是看论文太少了。














 1827
1827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









