






一、引言
YOLOv4目标检测项目是一个基于深度学习技术的计算机视觉项目,其核心是使用YOLOv4算法实现高效且准确的目标检测任务。该项目主要包括以下几个方面的定义和内涵:
首先,目标检测是计算机视觉领域的一个重要任务,旨在从图像或视频中识别出感兴趣的目标物体,并确定其位置。这通常涉及到对图像中的每个目标进行边界框的标注,并识别其所属的类别。
其次,YOLOv4算法是该项目的核心组成部分。YOLOv4(You Only Look Once version 4)是一种实时目标检测算法,它基于深度学习,特别是卷积神经网络(CNN),通过构建一个端到端的物体检测模型来实现目标检测。该算法充分利用了多尺度特征和多层次特征融合的方式进行物体检测,具有出色的速度和精度。
二、实验具体操作流程
(一)实验准备
1.数据收集与标注
依老师实验要求,在老师原有的20个标签除外,选择一类目标物体作为目标数据检测,这里我选择了兔子(rabbit)作为我的目标检测并创建了class.txt文件,并且在文件中放入我的目标检测标签---rabbit;
从网页上收集一个包含目标物体的图像数据集,这部分我是与同学合作下载了396张有关兔子图片集,下载到新建的img1文件夹里面,图片的扩展名为.jpg格式。
将img1中的图片保存至代码文件的JPEGImages目录文件中:
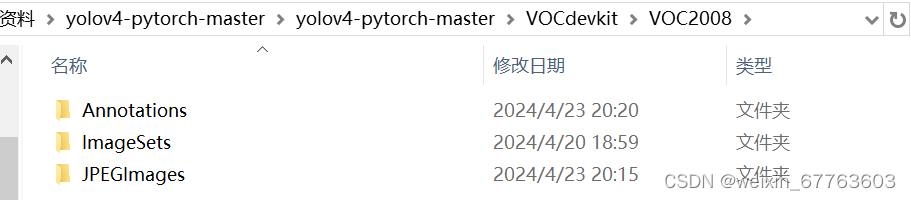
(这部分为了不影响老师原有的数据,我在老师原有的yolov4-pytorch-master文件中的VOCdevkit中创建了一个新的文件VOC2008)

准备好图片数据集后,接下来,我们需要对收集到的图片进行标注,即标出图片中目标物体的位置和类别。在本例中,我们使用labelImg_exe作为标注工具。标注完成后,每个图片都会生成一个对应的标签文件(以.xml为后缀),图像标注具体步骤如下所示:
1.打开要标注的图像:通过点击Labelimg界面上的“Open Dir”按钮打开要标注的图像,这里我的图像文件是img1;
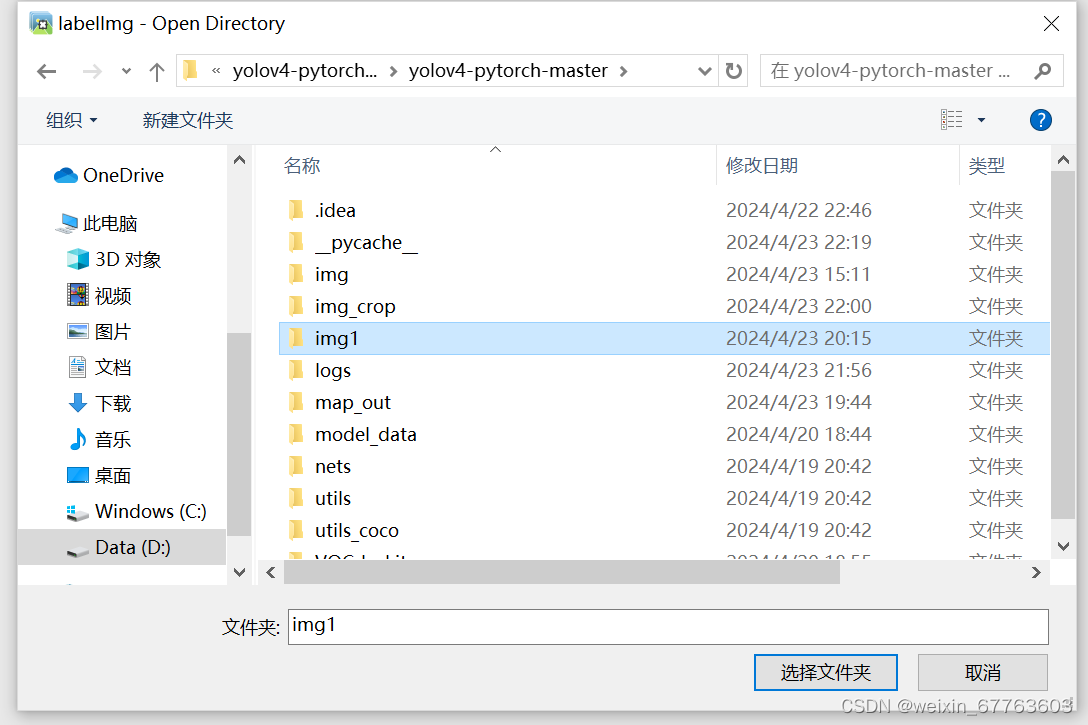
2.打开“Change Save Dir”选择框选完的图片保存位置:yolov4-pytorch-master\VOCdevkit\VOC2008\Annotations
3.创建标注框:点击Labelimg界面上的“Create RectBox”按钮,通过鼠标左键单击并拖动,创建一个边界框来框选目标。
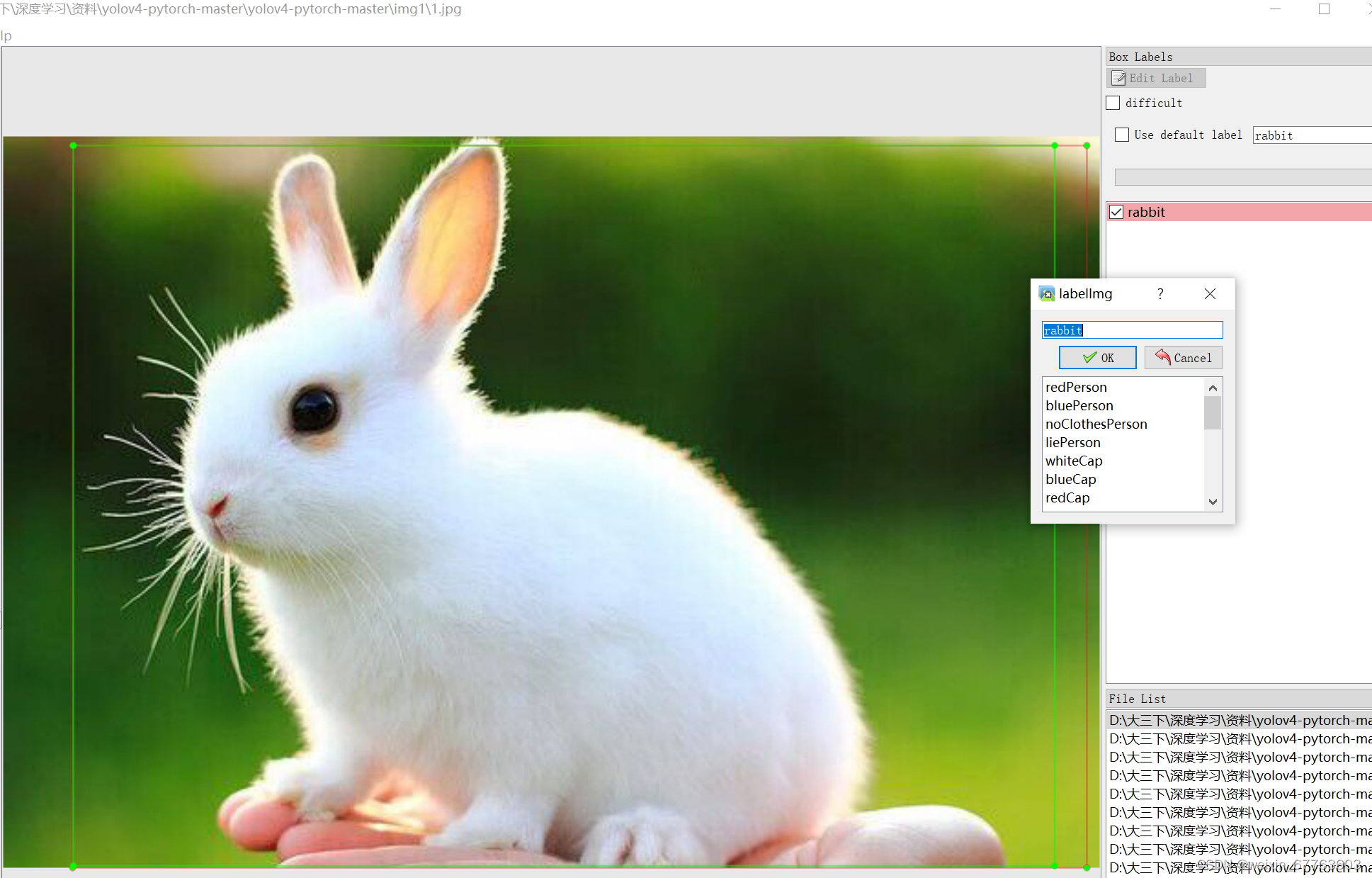
4.保存标注:在左下角的控制台中,点击“Save”按钮或使用快捷键(Ctrl + S)保存标注结果。
2.环境搭建
在PyCharm中打开yolov4-pytorch-master文件
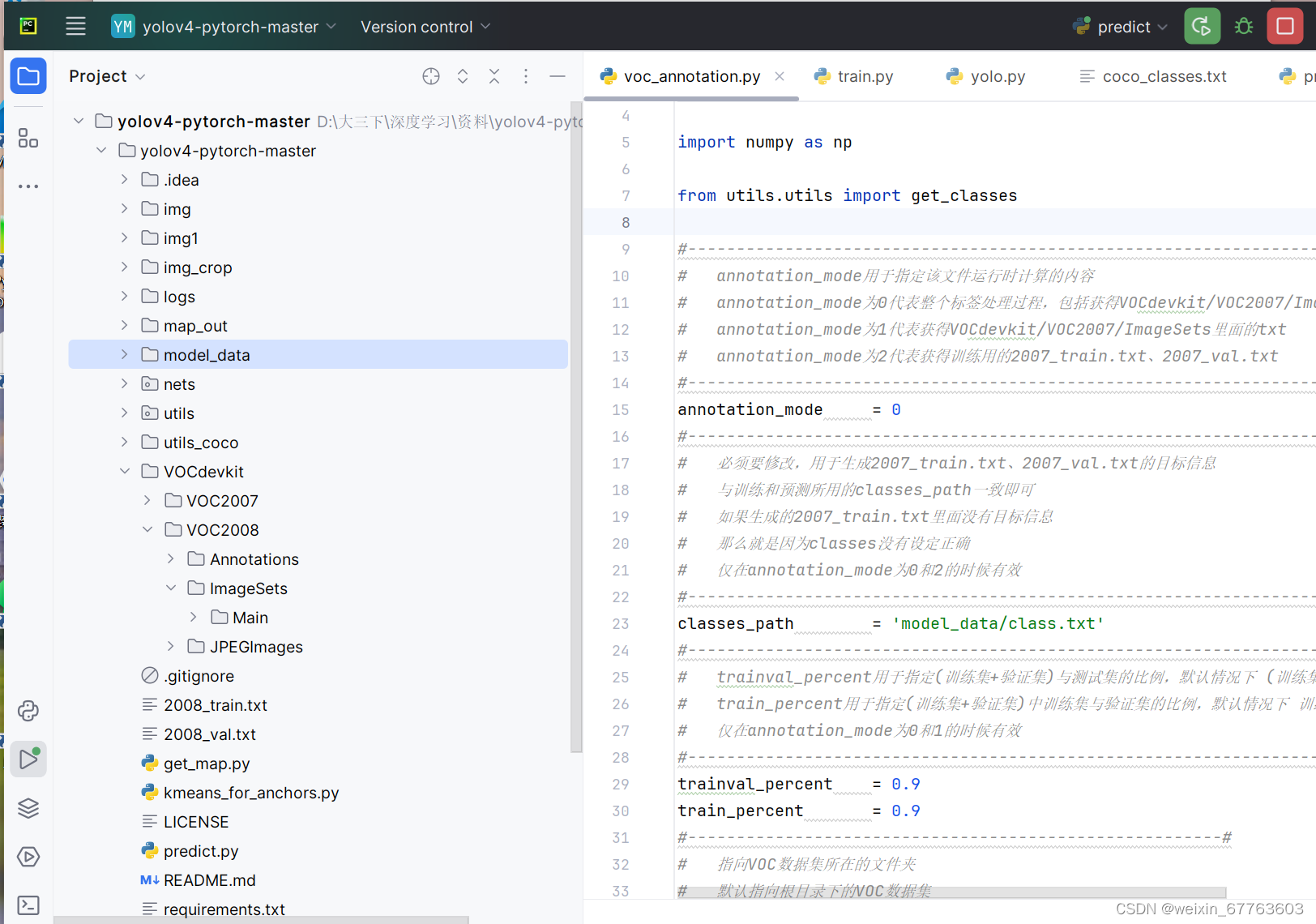
配置运行解释器,这里我使用的是Python3.8版本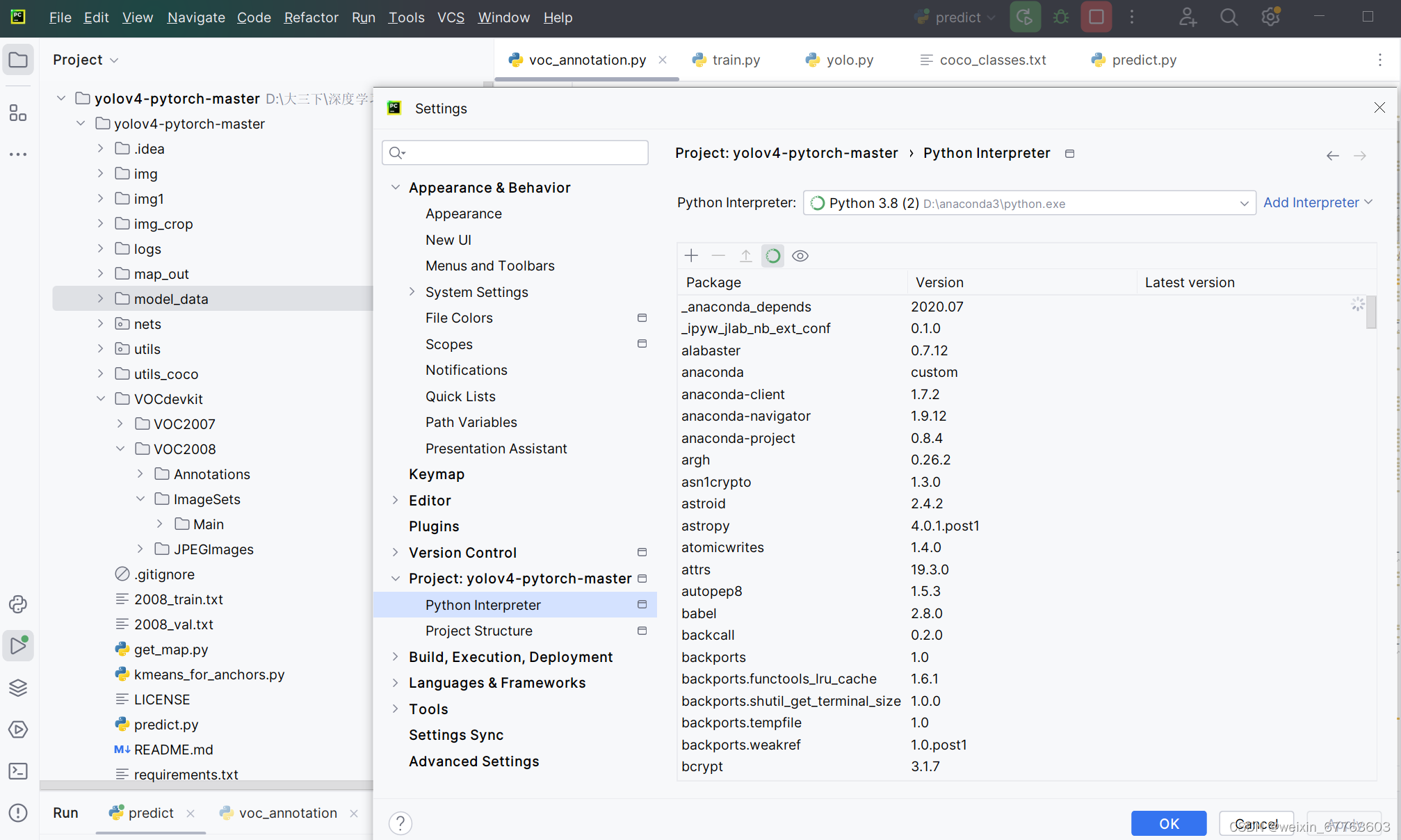
在运行相关代码之前,需要安装一些相关的Python库。这些库包括:
opencv-python:用于图像处理和目标检测结果的可视化。
pillow:用于图像处理和转换。
numpy:用于数值计算和数组操作。
onnx:用于模型转换和部署。
tensorboard:用于可视化训练过程中的损失和准确率等指标。
在安装这些包库的时候我们可以在后面使用一些镜像源来帮助我们快速的安装
国内镜像地址:
豆瓣(douban)
http://pypi.douban.com/simple/
清华大学
https://pypi.tuna.tsinghua.edu.cn/simple/
使用方法:如下图所示

(二) 模型训练
依次运行相关代码
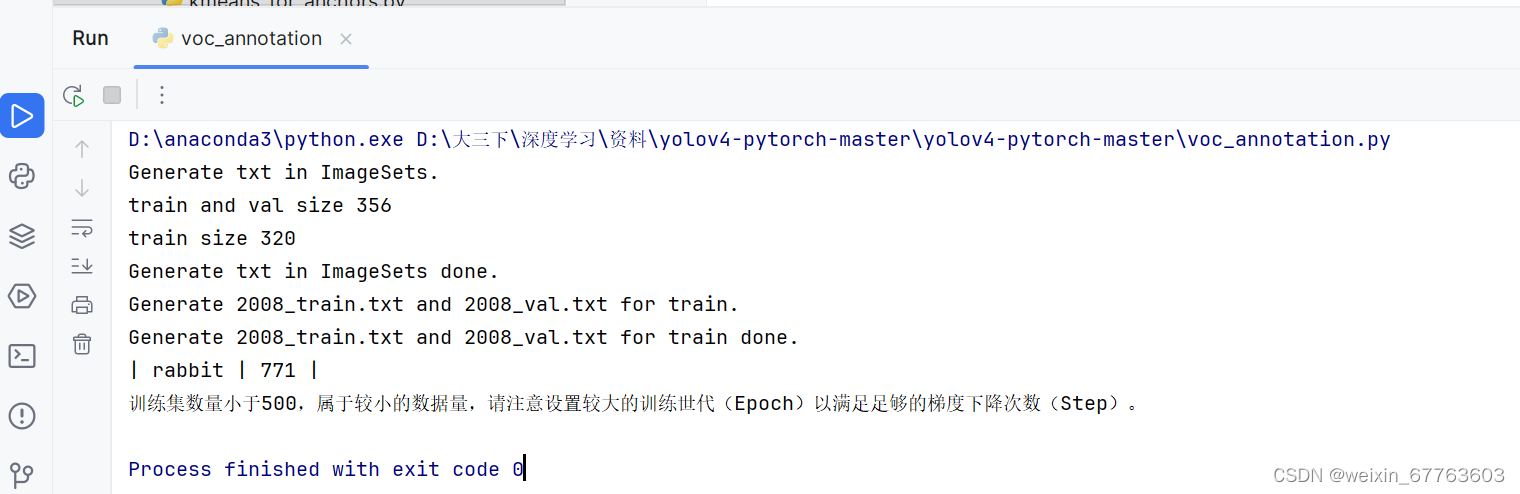
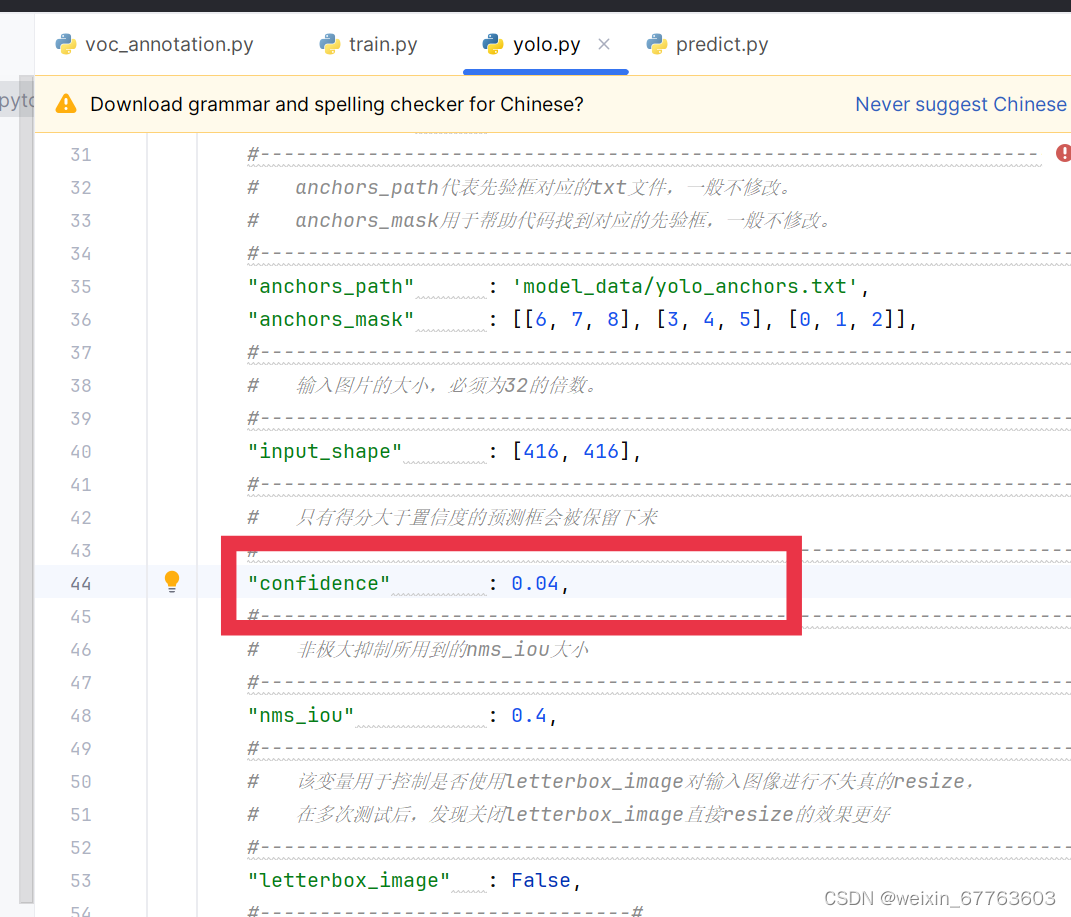
1.运行voc_annotation.py文件
需要修改以下相关内容,如下图所示
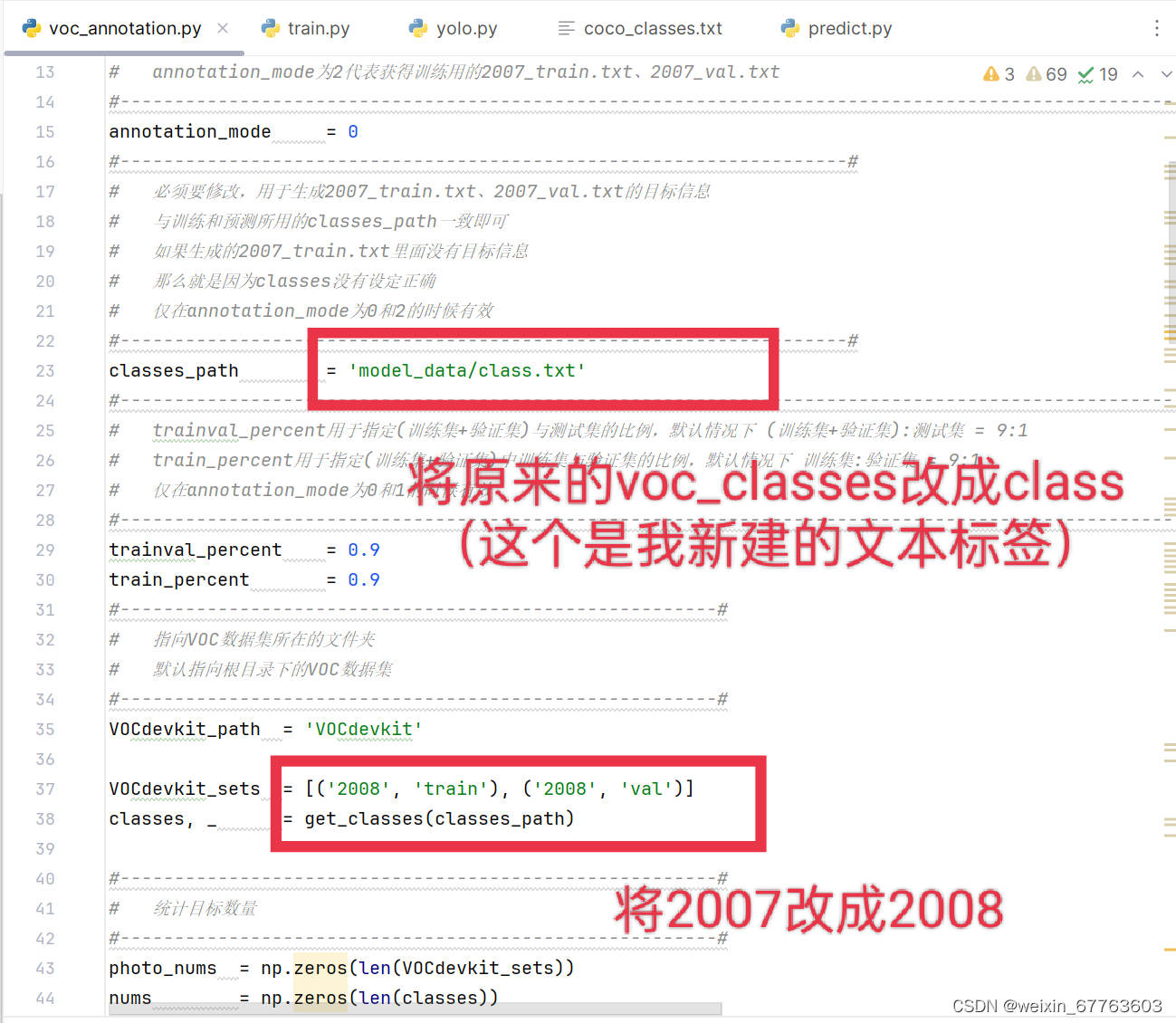
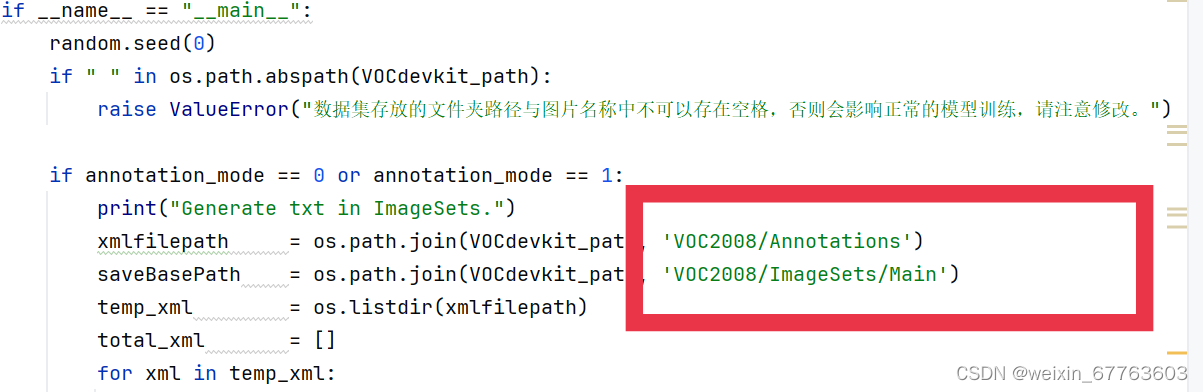
运行完voc_annotation.py文件后生成训练所需的2008_train.txt和2008_val.txt文件。这两个文件包含了训练集和验证集中图片的路径以及对应的标注信息。
2.运行运行train.py文件
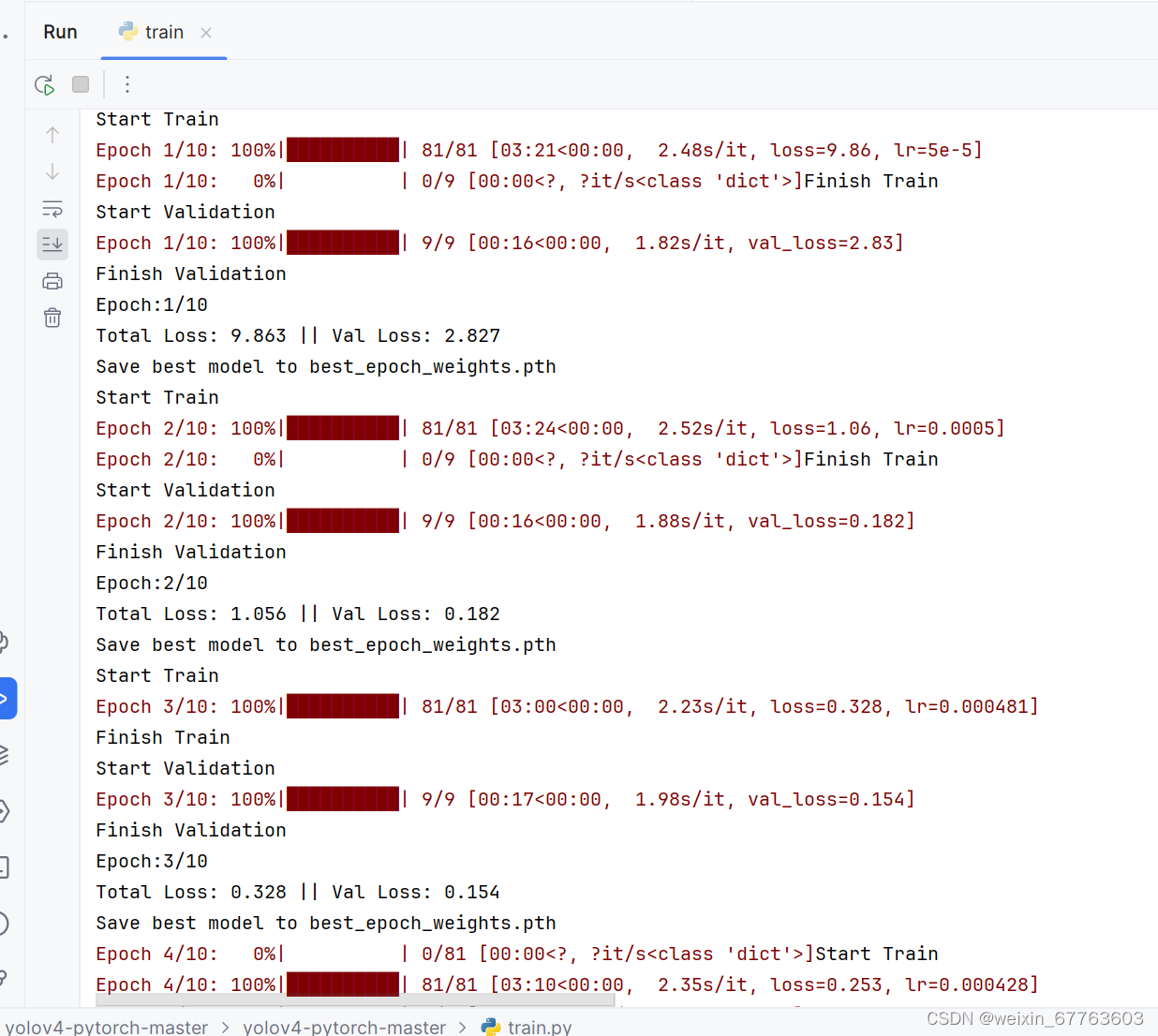
训练前,请仔细检查model_path和classes_path是否对应

3.运行predict.py 文件
(三)训练结果预测
在predict.py文件下输入自己想要预测的图片的地址
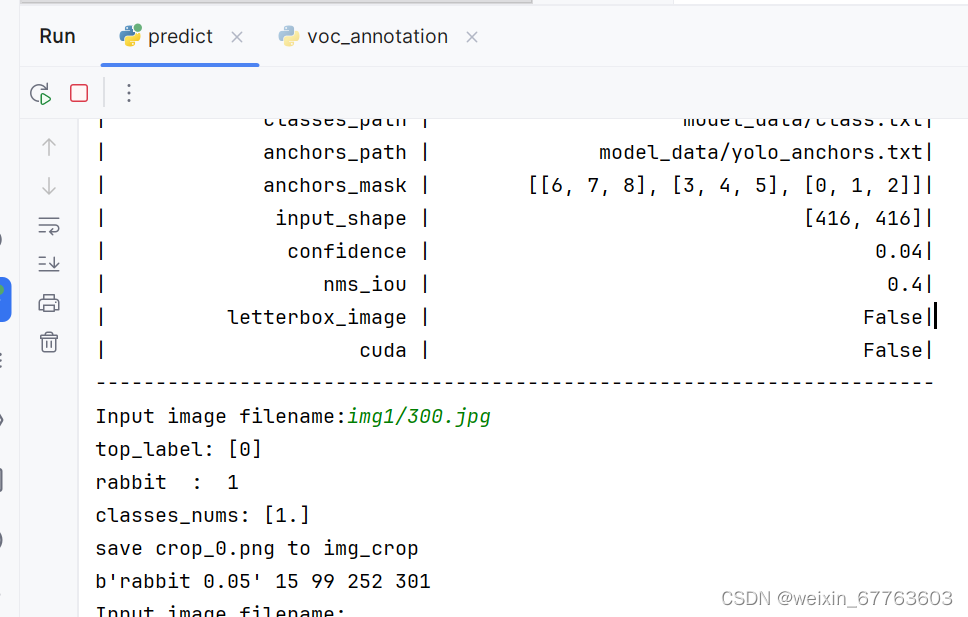
输出的图片如下所示:

注意事项:如果无法检测出目标,则将置信度调低
三、实验总结与反思
(一)总结
本次YOLOv4目标检测项目实验旨在利用YOLOv4算法实现对图像中目标物体的检测。通过实验,我们成功地训练了一个能够识别并定位目标物体的模型,并在测试集上取得了令人满意的性能表现。
在实验过程中,我们首先对YOLOv4算法的原理和特性进行了深入学习,并了解了其相比之前版本的优势。接着,我们收集并标注了一个包含目标物体的图像数据集,用于模型的训练和测试。通过调整模型的超参数和优化算法,我们不断优化模型的性能,并最终在验证集上取得了较高的准确率和召回率。
此外,我们还对模型进行了可视化评估,通过观察检测结果图,我们能够直观地了解模型对不同目标物体的识别能力。实验结果表明,YOLOv4算法在目标检测任务中表现出色,具有较高的检测精度和实时性能。
(二)反思
在实验过程中,我们也遇到了一些问题和挑战,以下是对这些问题的反思以及可能的改进方向:
-
数据集质量与多样性:虽然我们在实验中取得了较好的结果,但数据集的质量和多样性对模型的性能具有重要影响。在未来的实验中,我们应该进一步扩大数据集的规模,增加不同场景、不同角度和不同光照条件下的图像,以提高模型的泛化能力。
-
超参数调整与优化:超参数的选择对模型的性能具有关键作用。在实验中,我们主要依赖经验和其他研究者的推荐来设置超参数。未来,我们可以尝试使用自动化超参数调整工具或算法来寻找最优的超参数组合,以进一步提高模型的性能。
-
模型改进与扩展:YOLOv4算法虽然强大,但仍有改进的空间。我们可以尝试结合其他目标检测算法的优点,或者引入新的技术来改进YOLOv4的性能。此外,我们还可以将YOLOv4应用于其他相关领域,如视频目标检测、目标跟踪等。
-
实时性能优化:虽然YOLOv4算法在实时性能上表现出色,但在处理高分辨率图像或大规模数据集时仍可能面临挑战。未来,我们可以考虑采用更高效的计算资源或优化算法来进一步提高模型的实时性能。
综上所述,本次YOLOv4目标检测项目实验为我们提供了宝贵的经验和教训。通过不断反思和改进,我们可以进一步提高模型的性能,为实际应用提供更好的支持。















 6511
6511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









