










发展历程:
YOLOV1 (CVPR2016)->YOLOV2/YOLO9000 (CVPR2017)->YOLOV3 (2018)->YOLOV4 (2020)
->YOLOV5 (2020)->YOLOV6 (2021)->YOLOV7 (2022)
目标检测分为两类:一阶段和二阶段
一阶段也可叫做端到端,输入图片后直接输出检测框和种类(YOLO系列);
二阶段先画出检测框,再进行分类(Fast-RCNN、Mask-RCNN、Faster-RCNN)。
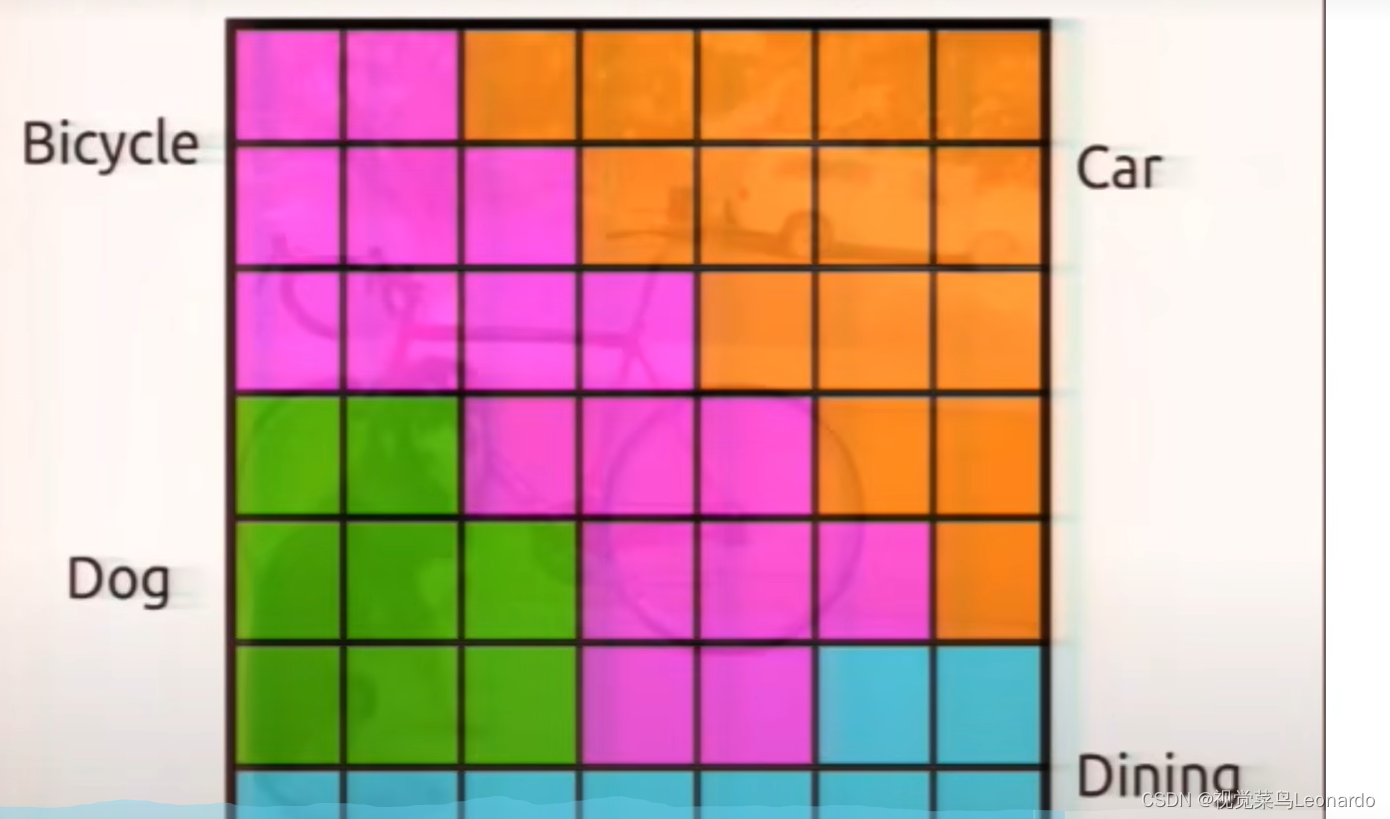
对于VOC2012数据集,首先生成7x7个grid cell,每一个grid cell生成两个bounding box并赋予对应的置信度,

最后保留置信度最高的bounding box

共有20个类,每一个grid cell生成对应20个类的概率,选取最大概率并保留
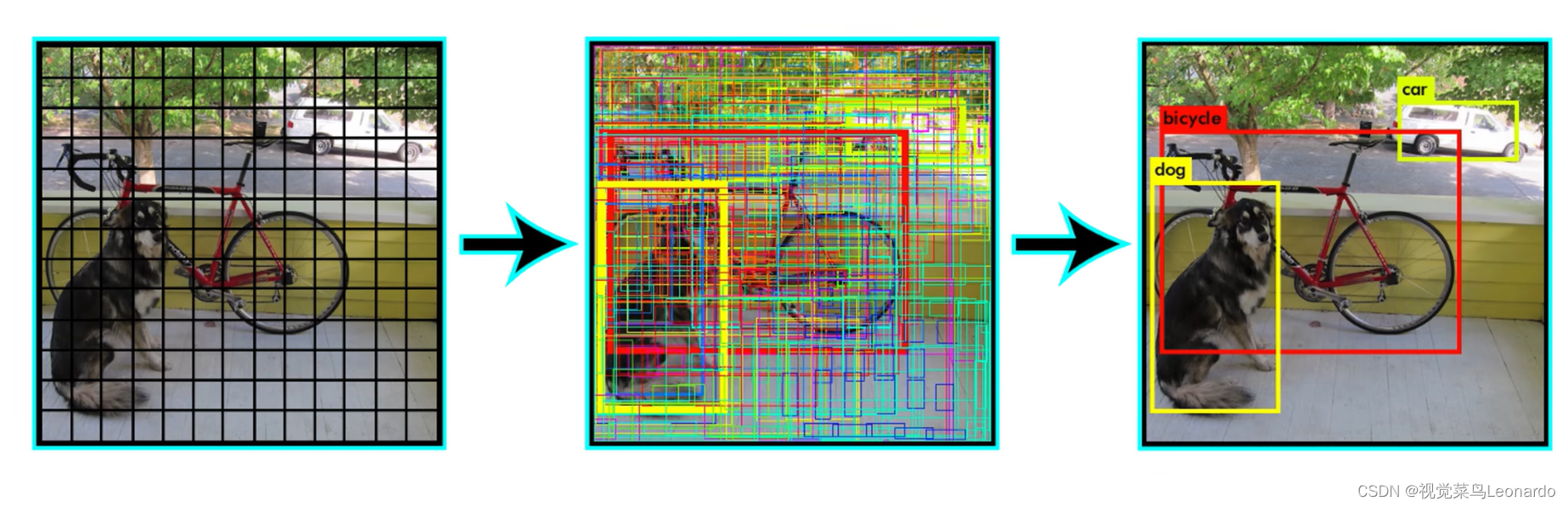
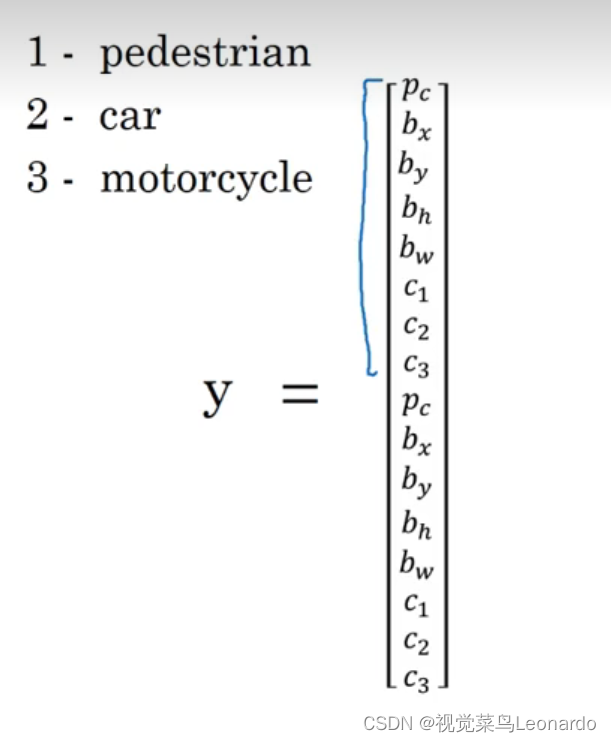
Bounding Boxes:
将输入图像分成n块,这里是9个grid cell,利用图像分类和定位算法,逐一应用到每个格子中,每个格子指定一个标签y

y中各元素的含义:Pc:是否有物体;bx、by、bh、bw:如果有对象,输出格子的边界框;c1、c2、c3:对象的类别。


因为上面三个格子啥玩意没有,Pc=0,其他的不管
如果中间一个格子两边格子中车的部分区域,那么会对对象分配中心点,中心点落在哪里就属于哪个格子,而另一个格子中的区域将不会被识别

对于右边和左边格子:
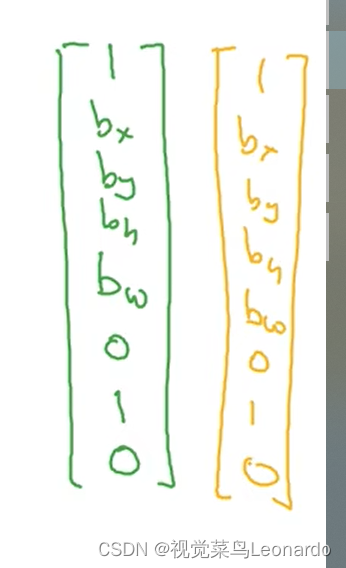
最终的目标输出尺寸为3x3x8,每一个格子左上角为(0,0)右下角为(1,1),bx、by为中心点,bh、bw为高和宽,以上数值只能在[0,1]。
交并比
预测与标签的交集和并集之比

目标定位:
检测出对象位置,用检测框标出,判断对象在图片中的具体位置
非极大值抑制(NMS)
NMS可以保证对每个对象只检测一次,计算不同矩形框的交并比,并抑制概率小的矩形框,只能输出概率最大的预测结果。

Anchor box:
预先定义两个框

当图像中检测到有两个不同类别的对象重叠在一起时,只能选择一个输出,加入anchor box 后,会进行相应的匹配,同时输出两个。
YOLO算法
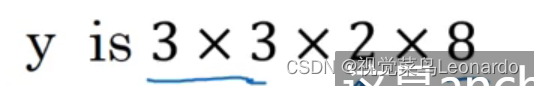
3x3表示9个网格、2代表两个anchor box、8代表向量中的类
左上角那个就是他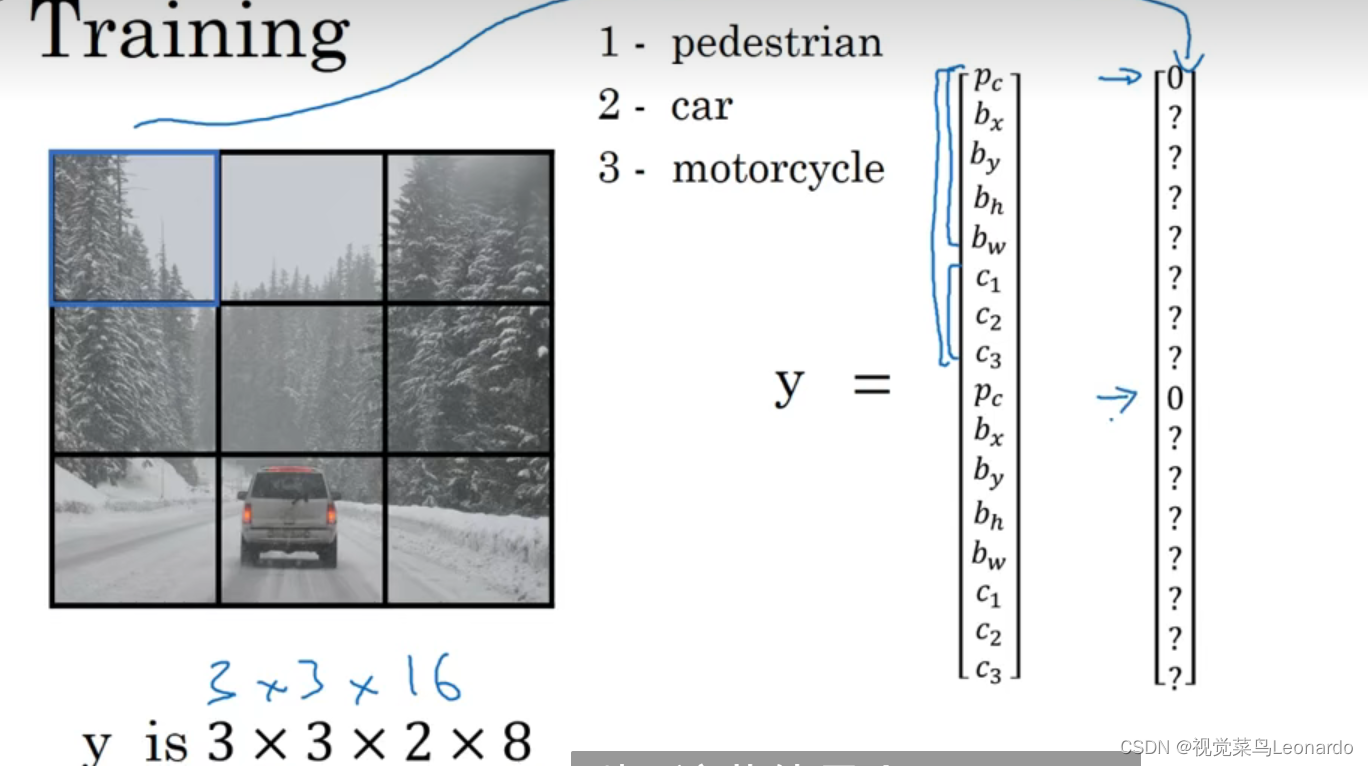
1.找到每个格子中的两个预测的边界框,bounding box可以超过格子的高度和宽度
2.去掉概率低的bounding boxs
3.对每个类别单独的运行非最大值抑制
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









