







3.1线性回归
![]()
![]()
import numpy as np
import matplotlib.pyplot as plt
class LinearRegressionClosedFormSol:
"""
线性回归,模型的闭式解
1.数据的预处理:是否训练偏置项fit_intercept(默认True),是否标准化normalized(True)
2.模型的训练:闭式解 fit(self, x_train, y_train)
3.模型的预测 predict(self, x_test)
4.均方误差,判决系数
5.模型预测可视化
"""
def __init__(self, fit_intercept=True, normalized=True):
self.fit_intercept = fit_intercept # 是否训练偏置项
self.normalized = normalized # 是否对样本进行标准化
self.theta = None
if self.normalized:
# 如果需要标准化,则计算样本特征的均值和标准方差,以便对测试样本标准化,模型系数的还原
self.feature_mean, self.feature_std = None, None
self.mse = None # 模型预测的均方误差
self.r2, self.r2_adj = 0.0, 0.0 # 判决系数和修正判决系数
self.n_samples, self.n_features = 0, 0 # 样本量和特征属性数目
def fit(self, x_train, y_train):
"""
样本的预处理,模型系数的求解,闭式解公式
:param x_train: 训练样本:ndarray,m*k
:param y_train: 目标值:ndarray,m*1
:return:
"""
if self.normalized:
self.feature_mean = np.mean(x_train, axis=0) # 样本特征均值 axis = 0:压缩行,对各列求均值,返回1*n的矩阵,
self.feature_std = np.std(x_train, axis=0) + 1e-8 # 样本特征标准方差,1e-8是避免分母是0
x_train = (x_train - self.feature_mean) / self.feature_std # 标准化
if self.fit_intercept:
x_train = np.c_[x_train, np.ones_like(y_train)] # 在样本后面加一列1,np.c_ 用于连接两个矩阵
# 训练模型
self._fit_closed_form_solution(x_train, y_train)
def _fit_closed_form_solution(self, x_train, y_train):
"""
模型系数的求解,闭式解公式
:param x_train:数据预处理后的训练样本:ndarray,m*k
:param y_train:目标值:ndarray,m*1
:return:
"""
# pinv:伪逆,(X'*X)^(-1)*X'
self.theta = np.linalg.pinv(x_train).dot(y_train)
# xtx = np.dot(x_train.T, x_train) + 0.01 * np.eye(x_train.shape[1]) # 防止不可逆
# self.theta = np.linalg.inv(xtx).dot(x_train.T).dot(y_train)
def get_params(self):
"""
获取模型的系数
:return:
"""
if self.fit_intercept:
weight, bias = self.theta[:-1], self.theta[-1]
else:
weight, bias = self.theta, np.array([0])
if self.normalized:
weight = weight / self.feature_std # 还原模型系数
bias = bias - weight.T.dot(self.feature_mean)
return weight, bias
def predict(self, x_test):
"""
模型的预测
:param x_test:
:return:
"""
try:
self.n_samples, self.n_features = x_test.shape[0], x_test.shape[1]
except IndexError:
self.n_samples, self.n_features = x_test.shape[0], 1
if self.normalized:
x_test = (x_test - self.feature_mean) / self.feature_std
if self.fit_intercept:
x_test = np.c_[x_test, np.ones(shape=x_test.shape[0])] # shape[0]代表行数
return x_test.dot(self.theta)
def cal_mse_r2(self, y_test, y_pred):
"""
模型预测的均方误差MSE,判决系数和修正判决系数
:param y_test: 测试样本真值
:param y_pred: 测试样本预测值
:return:
"""
self.mse = ((y_pred - y_test) ** 2).mean() # 均方误差
self.r2 = 1 - ((y_test - y_pred) ** 2).sum() / ((y_test - y_test.mean()) ** 2).sum()
self.r2_adj = 1 - (1 - self.r2) * (self.n_samples - 1) / (self.n_samples - self.n_features - 1)
return self.mse, self.r2, self.r2_adj
def plt_predict(self, y_test, y_pred, is_sort=True):
"""
预测结果的可视化
:param y_test: 测试样本真值
:param y_pred: 测试样本预测值
:param is_sort: 是否对预测值进行排序,然后可视化
:return:
"""
plt.figure(figsize=(7, 5))
if is_sort:
idx = np.argsort(y_test)
plt.plot(y_test[idx], "k--", lw=1.5, label="Test True Val")
plt.plot(y_pred[idx], "r:", lw=1.8, label="Predict Val")
else:
plt.plot(y_test, "ko-", lw=1.5, label="Test True Val")
plt.plot(y_pred, "r*-", lw=1.8, label="Predict Val")
plt.xlabel("Test samples number", fontdict={"fontsize": 12})
plt.ylabel("Predicted samples values", fontdict={"fontsize": 12})
plt.title("The predicted values of test samples \n "
"MSE = %.5f, R2 = %.5f, R2_adj = %.5f" % (self.mse, self.r2, self.r2_adj))
plt.grid(ls=":")
plt.legend(frameon=False)
plt.show()
3.2梯度下降法求线性回归
代价函数
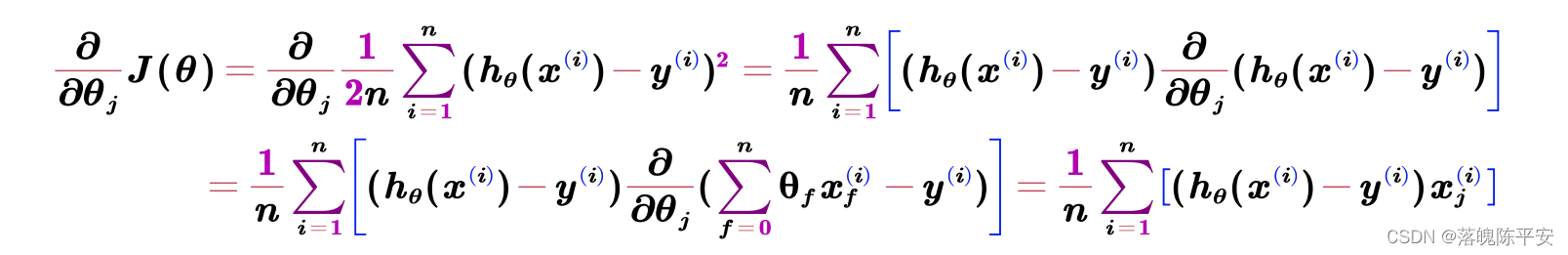
import numpy as np
import matplotlib.pyplot as plt
class LinearRegression_GradDesc:
"""
线性回归,梯度下降法求解模型的系数
1.数据的预处理:是否训练偏置项fit_intercept(默认True),是否标准化normalized(True)
2.模型的训练:闭式解 fit(self, x_train, y_train)
3.模型的预测 predict(self, x_test)
4.均方误差,判决系数
5.模型预测可视化
"""
def __init__(self, fit_intercept=True, normalized=True, alpha=0.05, max_epochs=300, batch_size=20):
"""
:param fit_intercept:是否训练偏置项
:param normalized:是否标准化
:param alpha:学习率
:param max_epochs:最大的迭代次数
:param batch_size:批量大小:如果为1,则为随机梯度下降算法,若为总的训练样本数,则为批量梯度下降法,否则是小批量
"""
self.fit_intercept = fit_intercept # 是否训练偏置项
self.normalized = normalized # 是否对样本进行标准化
self.alpha = alpha # 学习率
self.max_epochs = max_epochs
self.batch_size = batch_size
self.theta = None # 模型的系数
if self.normalized:
# 如果需要标准化,则计算样本特征的均值和标准方差,以便对测试样本标准化,模型系数的还原
self.feature_mean, self.feature_std = None, None
self.mse = None # 模型预测的均方误差
self.r2, self.r2_adj = 0.0, 0.0 # 判决系数和修正判决系数
self.n_samples, self.n_features = 0, 0 # 样本量和特征属性数目
self.train_loss, self.test_loss = [], [] # 存储训练过程中的训练损失和测试损失
def init_theta_params(self, n_features):
"""
模型参数的初始化,如果训练的偏置项,也包含了bias的初始化
:param n_features: 样本的特征数量
:return:
"""
self.theta = np.random.randn(n_features, 1) * 0.1
def fit(self, x_train, y_train, x_test=None, y_test=None):
"""
样本的预处理,模型系数的求解,闭式解公式
:param x_train: 训练样本:ndarray,m*k
:param y_train: 目标值:ndarray,m*1
:param x_test: 训练样本:ndarray,m*k
:param y_test:目标值:ndarray,m*1
:return:
"""
if self.normalized:
self.feature_mean = np.mean(x_train, axis=0) # 样本特征均值 axis = 0:压缩行,对各列求均值,返回1*n的矩阵,
self.feature_std = np.std(x_train, axis=1) + 1e-8 # 样本特征标准方差,1e-8是避免分母是0
x_train = (x_train - self.feature_mean) / self.feature_std # 标准化
if x_test is not None:
x_test = (x_test - - self.feature_mean) / self.feature_std
if self.fit_intercept:
x_train = np.c_[x_train, np.ones_like(y_train)] # 在样本后面加一列1,np.c_ 用于连接两个矩阵
if x_test is not None and y_test is not None:
x_test = np.c_[x_test, np.ones_like(y_test)]
self.init_theta_params(x_train.shape[1]) # 初始化参数
# 训练模型
self._fit_gradient_desc(self, x_train, y_train, x_test, y_test) # 梯度下降法训练模型
def _fit_gradient_desc(self, x_train, y_train, x_test, y_test):
"""
三种梯度下降算法的实现
:param x_train: 训练样本:ndarray,m*k
:param y_train: 目标值:ndarray,m*1
:param x_test: 训练样本:ndarray,m*k
:param y_test:目标值:ndarray,m*1
:return:
"""
train_samples = np.c_[x_train, y_train] # 组合训练集和目标集,以便随机打乱样本顺序
for i in range(self.max_epochs):
self.alpha *= 0.95
for i in range(self.max_epochs):
np.random.shuffle(train_samples) # 打乱样本顺序,模拟随机性
batch_nums = train_samples.shape[0] // self.batch_size # 批次
for idx in range(batch_nums):
# 按照小批量大小,选取数据
batch_xy = train_samples[idx * self.batch_size:(idx + 1) * self.batch_size]
batch_x, batch_y = batch_xy[:, :-1], batch_xy[:, -1:] # 选取样本和目标值
# 计算权重的更新增量
delta = batch_x.T.dot((batch_x.dot(self.theta) - batch_y)) / self.batch_size
self.theta = self.theta - self.alpha * delta # 更新模型系数
# 计算训练过程中的均方误差损失值
train_mse = ((x_train.dot(self.theta) - y_train.reshape(-1, 1)) ** 2).mean()
self.train_loss.append(train_mse) # 每次迭代的训练损失值(MSE)
if x_test is not None and y_test is not None:
test_mse = ((x_test.dot(self.theta) - y_test.reshape(-1, 1)) ** 2).mean()
self.test_loss.append(test_mse) # 每次迭代的训练损失值(MSE)
def get_params(self):
"""
获取模型的系数
:return:
"""
if self.fit_intercept:
weight, bias = self.theta[:-1], self.theta[-1]
else:
weight, bias = self.theta, np.array([0])
if self.normalized:
weight = weight / self.feature_std.reshape(-1, 1) # 还原模型系数
bias = bias - weight.T.dot(self.feature_mean)
return weight.reshape(-1, 1), bias
def predict(self, x_test):
"""
模型的预测
:param x_test:
:return:
"""
try:
self.n_samples, self.n_features = x_test.shape[0], x_test.shape[1]
except IndexError:
self.n_samples, self.n_features = x_test.shape[0], 1
if self.normalized:
x_test = (x_test - self.feature_mean) / self.feature_std
if self.fit_intercept:
x_test = np.c_[x_test, np.ones(shape=x_test.shape[0])] # shape[0]代表行数
y_pred = x_test.dot(self.theta)
return y_pred.reshape(-1)
def cal_mse_r2(self, y_test, y_pred):
"""
模型预测的均方误差MSE,判决系数和修正判决系数
:param y_test: 测试样本真值
:param y_pred: 测试样本预测值
:return:
"""
self.mse = ((y_pred - y_test.reshape(-1, 1)) ** 2).mean() # 均方误差
self.r2 = 1 - ((y_test.reshape(-1, 1) - y_pred) ** 2).sum() /\
((y_test.reshape(-1, 1) - y_test.mean()) ** 2).sum()
self.r2_adj = 1 - (1 - self.r2) * (self.n_samples - 1) / (self.n_samples - self.n_features - 1)
return self.mse, self.r2, self.r2_adj
def plt_predict(self, y_test, y_pred, is_sort=True):
"""
预测结果的可视化
:param y_test: 测试样本真值
:param y_pred: 测试样本预测值
:param is_sort: 是否对预测值进行排序,然后可视化
:return:
"""
self.cal_mse_r2(y_test, y_pred)
plt.figure(figsize=(7, 5))
if is_sort:
idx = np.argsort(y_test)
plt.plot(y_test[idx], "k--", lw=1.5, label="Test True Val")
plt.plot(y_pred[idx], "r:", lw=1.8, label="Predict Val")
else:
plt.plot(y_test, "ko-", lw=1.5, label="Test True Val")
plt.plot(y_pred, "r*-", lw=1.8, label="Predict Val")
plt.xlabel("Test samples number", fontdict={"fontsize": 12})
plt.ylabel("Predicted samples values", fontdict={"fontsize": 12})
plt.title("The predicted values of test samples \n "
"MSE = %.5f, R2 = %.5f, R2_adj = %.5f" % (self.mse, self.r2, self.r2_adj))
plt.grid(ls=":")
plt.legend(frameon=False)
plt.show()
def plt_loss_curve(self):
"""
可视化损失曲线
:return:
"""
plt.figure(figsize=(7, 5))
plt.plot(self.train_loss, "k-", lw=1, label="Train Loss")
if self.test_loss:
plt.plot(self.test_loss, "r--", lw=1.2, label="Test Loss")
plt.xlabel("Epochs", fontdict={"fontsize": 12})
plt.ylabel("Loss values", fontdict={"fontsize": 12})
plt.title("The Loss Curve of MSE by Gradient Descent Method")
plt.grid(ls=":")
plt.legend(frameon=False)
plt.show()
测试代码
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from 机器学习.train import LinearRegression_GradDesc
air = pd.read_csv("").dropna()
X, y = np.asarray(air.iloc[:, [3, 4, 5, 6, 7, 8]]), np.asarray(air.iloc[:, 1])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0, shuffle=True)
lr_gd = LinearRegression_GradDesc(alpha=0.1, batch_size=1)
lr_gd.fit(X_train, y_train, X_test, y_test)
theta = lr_gd.get_params()
print(theta)
y_test_pred = lr_gd.predict(X_test)
lr_gd.plt_predict(y_test, y_test_pred)
lr_gd.plt_loss_curve()
print(air)
3.3
3.3.1多项式回归
![]()
import numpy as np
import matplotlib.pyplot as plt
from 机器学习.Polynomial_features import PolynomialFeatureData # 特征数据的生成
from learn1.learn import LinearRegressionClosedFormSol # 线性回归,模型的闭式解
def objective_fun(x):
"""
目标函数,假设一个二次多项式
:param x: 采样数据,向量
:return:
"""
return 0.5 * x ** 2 + x + 2
np.random.seed(42) # 随机种子,以便结果可再现
n = 30 # 样本量
raw_x = np.sort(6 * np.random.rand(n, 1) - 3) # 采样数据[-3, 3], 均匀分布
raw_y = objective_fun(raw_x) + 0.5 * np.random.randn(n, 1) # 目标值, 添加噪声
degree = [1, 2, 5, 10, 15, 20] # 拟合多项式的最高阶次
plt.figure(figsize=(15, 8))
for i, d in enumerate(degree):
feature_obj = PolynomialFeatureData(raw_x, d, with_bias=False) # 特征数据对象
X_samples = feature_obj.fit_transform() # 生成多项式特征数据
lr_cfs = LinearRegressionClosedFormSol() # 采用线性回归求解多项式回归
lr_cfs.fit(X_samples, raw_y) # 求解多项式回归系数
theta = lr_cfs.get_params() # 获得系数
print("degree:%d, theta is" % d, theta[0].reshape(-1)[::-1], theta[1])
y_train_pred = lr_cfs.predict(X_samples) # 在训练集上的预测
# 测试样本采样
x_test_raw = np.linspace(-3, 3, 150) # 测试数据
y_test = objective_fun(x_test_raw) # 测试数据的真值
feature_obj = PolynomialFeatureData(x_test_raw, d, with_bias=False) # 特征数对象
X_test = feature_obj.fit_transform() # 生成多项式特征测试数据
y_test_pred = lr_cfs.predict(X_test) # 模型在测试样本上的预测值
# 可视化不同阶次下的多项式拟合曲线
plt.subplot(231 + i)
plt.scatter(raw_x, raw_y, edgecolors="k", s=15, label="Rwa Data")
plt.plot(x_test_raw, y_test, "k-", lw=1, label="Objective Fun")
plt.plot(x_test_raw, y_test_pred, "r--", lw=1.5, label="Polynomial Fit")
plt.legend(frameon=False)
plt.xlabel("$x$", fontdict={"fontsize": 12})
plt.xlabel("$y(x)$", fontdict={"fontsize": 12})
test_ess = (y_test_pred.reshape(-1) - y_test) ** 2 # 误差平方
test_mse, test_std = np.mean(test_ess), np.std(test_ess)
train_ess = (y_train_pred - raw_y) ** 2 # 误差平方
train_mse, train_std = np.mean(train_ess), np.std(train_ess)
plt.title("Degree {} Test Mse = {:.2e}(+/-{:.2e}) \n Train Mse = {:.2e}(+/-{:.2e})"
.format(d, test_mse, test_std, train_mse, train_std))
plt.axis([-3, 3, 0, 9])
plt.show()
3.3.2学习曲线
import numpy as np
import matplotlib.pyplot as plt
from 机器学习.Polynomial_features import PolynomialFeatureData # 特征数据的生成
from learn1.learn import LinearRegressionClosedFormSol # 线性回归,模型的闭式解
from sklearn.model_selection import train_test_split
def objective_fun(x):
"""
目标函数,假设一个二次多项式
:param x: 采样数据,向量
:return:
"""
return 0.5 * x ** 3 + 2 * x ** 2 - 2.5 * x + 2
np.random.seed(42) # 随机种子,以便结果可再现
n = 80 # 样本量
raw_x = np.sort(6 * np.random.rand(n, 1) - 3) # 采样数据[-3, 3], 均匀分布
raw_y = objective_fun(raw_x) + 0.5 * np.random.randn(n, 1) # 目标值, 添加噪声
degree = [2, 3, 5, 10, 15, 20] # 拟合多项式的最高阶次
plt.figure(figsize=(15, 8))
for i, d in enumerate(degree):
feature_obj = PolynomialFeatureData(raw_x, d, with_bias=False) # 特征数据对象
X_samples = feature_obj.fit_transform() # 生成多项式特征数据
X_train, X_test, y_train, y_test = train_test_split(X_samples, raw_y, test_size=0.2, random_state=0)
train_mse, test_mse = [], []
for j in range(1, 80):
lr_cfs = LinearRegressionClosedFormSol()
lr_cfs.fit(X_train[:j, :], y_train[:j]) # 训练样本主逐次增加
y_test_pred = lr_cfs.predict(X_test)
y_train_pred = lr_cfs.predict(X_train[:j, :])
train_mse.append(np.mean((y_train_pred - y_train[:j]) ** 2))
test_mse.append(np.mean((y_test_pred - y_test) ** 2))
# 可视化不同阶次下的多项式拟合曲线
plt.subplot(231 + i)
plt.plot(train_mse, "k-", lw=1, label="Train MSE")
plt.plot(test_mse, "r--", lw=1.5, label="Ttst MSE")
plt.legend(frameon=False)
plt.grid(ls=":")
plt.xlabel("$Train Samples Size$", fontdict={"fontsize": 12})
plt.xlabel("MSE", fontdict={"fontsize": 12})
plt.title("Learning Curve with Degree {}".format(d))
if i == 0:
plt.axis([0, 80, 0, 10])
elif i == 1:
plt.axis([0, 80, 0, 1])
else:
plt.axis([0, 80, 0, 2])
plt.show()
3.4正则化

import numpy as np
import matplotlib.pyplot as plt
class RegularLinearRegression:
"""
线性回归+正则化,梯度下降法+闭式解求解模型的系数
1.数据的预处理:是否训练偏置项fit_intercept(默认True),是否标准化normalized(True)
2.模型的训练:fit(self, x_train, y_train):闭式解form,梯度下降算法:grad
3.模型的预测 predict(self, x_test)
4.均方误差,判决系数
5.模型预测可视化
"""
def __init__(self, solver="grad", fit_intercept=True, normalized=True, alpha=0.05,
max_epochs=300, batch_size=20, l1_ratio=None, l2_ratio=None, en_rou=None):
"""
:param solver:求解方法:form是闭式解,grad是梯度
:param fit_intercept:是否训练偏置项
:param normalized:是否标准化
:param alpha:学习率
:param max_epochs:最大的迭代次数
:param batch_size:批量大小:如果为1,则为随机梯度下降算法,若为总的训练样本数,则为批量梯度下降法,否则是小批量
:param l1_ratio:LASSO回归惩罚系数
:param l2_ratio:岭回归回归惩罚系数
:param en_rou:弹性网络权衡L1和L2的系数
"""
self.solver = solver # 求解方法
self.fit_intercept = fit_intercept # 是否训练偏置项
self.normalized = normalized # 是否对样本进行标准化
self.alpha = alpha # 学习率
if l1_ratio:
if l1_ratio < 0:
raise ValueError("惩罚项系数不能为负数")
self.l1_ratio = l1_ratio # LASSO回归惩罚项系数
if l2_ratio:
if l2_ratio < 0:
raise ValueError("惩罚项系数不能为负数")
self.l2_ratio = l2_ratio # 岭回归惩罚项系数
if en_rou:
if en_rou > 1 or en_rou < 0:
raise ValueError("弹性网络权衡系数范围在[0, 1]")
self.max_epochs = max_epochs
self.batch_size = batch_size
self.theta = None # 模型的系数
if self.normalized:
# 如果需要标准化,则计算样本特征的均值和标准方差,以便对测试样本标准化,模型系数的还原
self.feature_mean, self.feature_std = None, None
self.mse = None # 模型预测的均方误差
self.r2, self.r2_adj = 0.0, 0.0 # 判决系数和修正判决系数
self.n_samples, self.n_features = 0, 0 # 样本量和特征属性数目
self.train_loss, self.test_loss = [], [] # 存储训练过程中的训练损失和测试损失
def init_theta_params(self, n_features):
"""
模型参数的初始化,如果训练的偏置项,也包含了bias的初始化
:param n_features: 样本的特征数量
:return:
"""
self.theta = np.random.randn(n_features, 1) * 0.1
def fit(self, x_train, y_train, x_test=None, y_test=None):
"""
样本的预处理,模型系数的求解,闭式解公式
:param x_train: 训练样本:ndarray,m*k
:param y_train: 目标值:ndarray,m*1
:param x_test: 训练样本:ndarray,m*k
:param y_test:目标值:ndarray,m*1
:return:
"""
if self.normalized: # 标准化
self.feature_mean = np.mean(x_train, axis=0) # 样本特征均值 axis = 0:压缩行,对各列求均值,返回1*n的矩阵,
self.feature_std = np.std(x_train, axis=0) + 1e-8 # 样本特征标准方差,1e-8是避免分母是0
x_train = (x_train - self.feature_mean) / self.feature_std # 标准化
if x_test is not None:
x_test = (x_test - - self.feature_mean) / self.feature_std
if self.fit_intercept:
x_train = np.c_[x_train, np.ones_like(y_train)] # 在样本后面加一列1,np.c_ 用于连接两个矩阵
if x_test is not None and y_test is not None:
x_test = np.c_[x_test, np.ones_like(y_test)]
self.init_theta_params(x_train.shape[1]) # 初始化参数
# 训练模型
if self.solver == "grad":
self._fit_gradient_desc(x_train, y_train, x_test, y_test) # 梯度下降法训练模型
elif self.solver == "form":
self._fit_closed_form_solution(x_train, y_train)
else:
raise ValueError("仅限于闭式解form或梯度下降算法grad")
def _fit_closed_form_solution(self, x_train, y_train):
"""
模型系数的求解,闭式解公式
:param x_train:数据预处理后的训练样本:ndarray,m*k
:param y_train:目标值:ndarray,m*1
:return:
"""
# pinv:伪逆,(X'*X)^(-1)*X'
if self.l2_ratio is None:
self.theta = np.linalg.pinv(x_train).dot(y_train)
elif self.l2_ratio:
self.theta = np.linalg.inv(x_train.T.dot(x_train) + self.l2_ratio *
np.eye(x_train.shape[1])).dot(x_train.T).dot(y_train)
else:
pass
def _fit_gradient_desc(self, x_train, y_train, x_test, y_test):
"""
三种梯度下降算法的实现 + 正则化
:param x_train: 训练样本:ndarray,m*k
:param y_train: 目标值:ndarray,m*1
:param x_test: 训练样本:ndarray,m*k
:param y_test:目标值:ndarray,m*1
:return:
"""
train_samples = np.c_[x_train, y_train] # 组合训练集和目标集,以便随机打乱样本顺序
for i in range(self.max_epochs):
self.alpha *= 0.95
for i in range(self.max_epochs):
np.random.shuffle(train_samples) # 打乱样本顺序,模拟随机性
batch_nums = train_samples.shape[0] // self.batch_size # 批次
for idx in range(batch_nums):
# 按照小批量大小,选取数据
batch_xy = train_samples[idx * self.batch_size:(idx + 1) * self.batch_size]
batch_x, batch_y = batch_xy[:, :-1], batch_xy[:, -1:] # 选取样本和目标值
# 计算权重的更新增量
delta = batch_x.T.dot((batch_x.dot(self.theta) - batch_y)) / self.batch_size
# 计算并添加正则化部分
dw_reg = np.zeros(shape=(x_train.shape[-1] - 1, 1))
if self.l1_ratio and self.l2_ratio is None:
# LASSO回归,L1正则化
dw_reg = self.l1_ratio * np.sign(self.theta[:, -1]) / self.batch_size
if self.l2_ratio and self.l1_ratio is None:
# Ridge回归,L2正则化
dw_reg = 2 * self.l2_ratio * self.theta[:, -1] / self.batch_size
if self.en_rou and self.l1_ratio and self.l2_ratio:
dw_reg = self.l1_ratio * self.en_rou * np.sign(self.theta[:, -1]) / self.batch_size
dw_reg += 2 * self.l2_ratio * (1 - self.en_rou) * self.theta[:, -1] / self.batch_size
delta[:, -1] += dw_reg # 添加了正则化
self.theta = self.theta - self.alpha * delta # 更新模型系数
# 计算训练过程中的均方误差损失值
train_mse = ((x_train.dot(self.theta) - y_train.reshape(-1, 1)) ** 2).mean()
self.train_loss.append(train_mse) # 每次迭代的训练损失值(MSE)
if x_test is not None and y_test is not None:
test_mse = ((x_test.dot(self.theta) - y_test.reshape(-1, 1)) ** 2).mean()
self.test_loss.append(test_mse) # 每次迭代的训练损失值(MSE)
def get_params(self):
"""
获取模型的系数
:return:
"""
if self.fit_intercept:
weight, bias = self.theta[:-1], self.theta[-1]
else:
weight, bias = self.theta, np.array([0])
if self.normalized:
weight = weight / self.feature_std.reshape(-1, 1) # 还原模型系数
bias = bias - weight.T.dot(self.feature_mean)
return weight.reshape(-1, 1), bias
def predict(self, x_test):
"""
模型的预测
:param x_test:
:return:
"""
try:
self.n_samples, self.n_features = x_test.shape[0], x_test.shape[1]
except IndexError:
self.n_samples, self.n_features = x_test.shape[0], 1
if self.normalized:
x_test = (x_test - self.feature_mean) / self.feature_std
if self.fit_intercept:
x_test = np.c_[x_test, np.ones(shape=x_test.shape[0])] # shape[0]代表行数
y_pred = x_test.dot(self.theta)
return y_pred.reshape(-1)
def cal_mse_r2(self, y_test, y_pred):
"""
模型预测的均方误差MSE,判决系数和修正判决系数
:param y_test: 测试样本真值
:param y_pred: 测试样本预测值
:return:
"""
self.mse = ((y_pred - y_test.reshape(-1, 1)) ** 2).mean() # 均方误差
self.r2 = 1 - ((y_test.reshape(-1, 1) - y_pred) ** 2).sum() / \
((y_test.reshape(-1, 1) - y_test.mean()) ** 2).sum()
self.r2_adj = 1 - (1 - self.r2) * (self.n_samples - 1) / (self.n_samples - self.n_features - 1)
return self.mse, self.r2, self.r2_adj
def plt_predict(self, y_test, y_pred, is_sort=True, is_show=True):
"""
预测结果的可视化
:param y_test: 测试样本真值
:param y_pred: 测试样本预测值
:param is_sort: 是否对预测值进行排序,然后可视化
:param is_show=True:
:return:
"""
self.cal_mse_r2(y_test, y_pred)
plt.figure(figsize=(7, 5))
if is_sort:
idx = np.argsort(y_test)
plt.plot(y_test[idx], "k--", lw=1.5, label="Test True Val")
plt.plot(y_pred[idx], "r:", lw=1.8, label="Predict Val")
else:
plt.plot(y_test, "ko-", lw=1.5, label="Test True Val")
plt.plot(y_pred, "r*-", lw=1.8, label="Predict Val")
plt.xlabel("Test samples number", fontdict={"fontsize": 12})
plt.ylabel("Predicted samples values", fontdict={"fontsize": 12})
plt.title("The predicted values of test samples \n "
"MSE = %.5f, R2 = %.5f, R2_adj = %.5f" % (self.mse, self.r2, self.r2_adj))
plt.grid(ls=":")
plt.legend(frameon=False)
if is_show:
plt.show()
def plt_loss_curve(self, is_show=True):
"""
可视化损失曲线
:return:
"""
plt.figure(figsize=(7, 5))
plt.plot(self.train_loss, "k-", lw=1, label="Train Loss")
if self.test_loss:
plt.plot(self.test_loss, "r--", lw=1.2, label="Test Loss")
plt.xlabel("Epochs", fontdict={"fontsize": 12})
plt.ylabel("Loss values", fontdict={"fontsize": 12})
plt.title("The Loss Curve of MSE by Gradient Descent Method")
plt.grid(ls=":")
plt.legend(frameon=False)
if is_show:
plt.show()
测试
import numpy as np
import matplotlib.pyplot as plt
from 机器学习.Polynomial_features import PolynomialFeatureData # 构造特征数据
from learn1.testst import RegularLinearRegression # 正则化线性回归
def objective_fun(x):
"""
目标函数
:param x:
:return:
"""
return 0.5 * x ** 2 + x + 2
np.random.seed(42)
n = 30 # 采样数据的样本量
raw_x = np.sort(6 * np.random.rand(n, 1) - 3, axis=0) # [-3, 3]区间,排序,二维数组n * 1
raw_y = objective_fun(raw_x) + np.random.randn(n, 1) # 二维数组
feature_obj = PolynomialFeatureData(raw_x, degree=13, with_bias=False)
X_train = feature_obj.fit_transform() # 特征数据的构造
X_test_raw = np.linspace(-3, 3, 150) # 测试数据
feature_obj = PolynomialFeatureData(X_test_raw, degree=13, with_bias=False)
X_test = feature_obj.fit_transform() # 特征数据的构造
y_test = objective_fun(X_test_raw) # 测试样本的真值
reg_ratio = [0.1, 0.5, 1, 2, 3, 5] # 正则化系数
alpha, batch_size, max_epochs = 0.1, 10, 300
plt.figure(figsize=(15, 8))
for i, ratio in enumerate(reg_ratio):
plt.subplot(231 + i)
# 不采用正则化
reg_lr = RegularizationLinearRegression(solver="grad", alpha=alpha, batch_size=batch_size,
max_epochs=max_epochs)
reg_lr.fit(X_train, raw_y)
print("NoReg, ratio = 0.00", reg_lr.get_params())
print("=" * 70)
y_test_pred = reg_lr.predict(X_test) # 测试样本预测
mse, r2, _ = reg_lr.cal_mse_r2(y_test, y_test_pred)
plt.scatter(raw_x, raw_y, s=15, c="k")
plt.plot(X_test_raw, y_test, "k-", lw=1.5, label="Objective Function")
plt.plot(X_test_raw, y_test_pred, lw=1.5, label="NoReg MSE = %.5f, R2 = %.5f" % (mse, r2))
# LASSO回归
# LASSO: Least absolute shrinkage and selection operator 最小绝对收缩与选择算子
lasso_lr = RegularizationLinearRegression(solver="grad", alpha=alpha, batch_size=batch_size,
max_epochs=max_epochs, l1_ratio=ratio)
lasso_lr.fit(X_train, raw_y)
print("L1, ratio = %.2f" % ratio, lasso_lr.get_params())
print("=" * 70)
y_test_pred = lasso_lr.predict(X_test) # 测试样本预测
mse, r2, _ = lasso_lr.cal_mse_r2(y_test, y_test_pred)
plt.plot(X_test_raw, y_test_pred, lw=1.5, label="L1 MSE = %.5f, R2 = %.5f" % (mse, r2))
# 岭回归
ridge_lr = RegularizationLinearRegression(solver="grad", alpha=alpha, batch_size=batch_size,
max_epochs=max_epochs, l2_ratio=ratio)
ridge_lr.fit(X_train, raw_y)
print("L2, ratio = %.2f" % ratio, ridge_lr.get_params())
print("=" * 70)
y_test_pred = ridge_lr.predict(X_test) # 测试样本预测
mse, r2, _ = ridge_lr.cal_mse_r2(y_test, y_test_pred)
plt.plot(X_test_raw, y_test_pred, lw=1.5, label="L2 MSE = %.5f, R2 = %.5f" % (mse, r2))
# 弹性网络回归
elastic_net_lr = RegularizationLinearRegression(solver="grad", alpha=alpha, batch_size=batch_size,
max_epochs=max_epochs, l2_ratio=ratio, l1_ratio=ratio, en_rou=0.5)
elastic_net_lr.fit(X_train, raw_y)
print("EN, ratio = %.2f" % ratio, elastic_net_lr.get_params())
print("=" * 70)
y_test_pred = elastic_net_lr.predict(X_test) # 测试样本预测
mse, r2, _ = elastic_net_lr.cal_mse_r2(y_test, y_test_pred)
plt.plot(X_test_raw, y_test_pred, lw=1.5, label="EN MSE = %.5f, R2 = %.5f" % (mse, r2))
plt.axis([-3, 3, 0, 11])
plt.xlabel("x", fontdict={"fontsize": 12})
plt.ylabel("y", fontdict={"fontsize": 12})
plt.legend(frameon=False)
plt.grid(ls=":")
#plt.title("Closed Form Solution with $\lambda$ = %.2f" % ratio)
plt.title("Gradient Descent Solution with $\lambda$ = %.2f" % ratio)
plt.tight_layout()
plt.show()案例测试
UCI Machine Learning Repository
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from regularization_linear_regression import RegularizationLinearRegression
from sklearn.model_selection import train_test_split
data = pd.read_csv("bias+correction+of+numerical+prediction+model+temperature+forecast/Bias_correction_ucl.csv").dropna()
X, y = np.asarray(data.iloc[:, 2:-2]), np.asarray(data.iloc[:, -1])
feature_names = data.columns[2:-2]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=22)
alpha, batch_size, max_epochs, ratio = 0.2, 100, 500, 0.5
plt.figure(figsize=(15, 8))
noreg_lr = RegularizationLinearRegression(alpha=alpha, batch_size=batch_size, max_epochs=max_epochs)
noreg_lr.fit(X_train, y_train)
theta = noreg_lr.get_params()
print("无正则化,模型系数如下")
for i, w in enumerate(theta[0][:-1]):
print(feature_names[i], ":", w)
print("theta0:", theta[1][0])
print("=" * 50)
lasso_lr = RegularizationLinearRegression(alpha=alpha, batch_size=batch_size, max_epochs=max_epochs, l1_ratio=1)
lasso_lr.fit(X_train, y_train, X_test, y_test)
theta = lasso_lr.get_params()
print("LASSO正则化,模型系数如下")
for i, w in enumerate(theta[0][:-1]):
print(feature_names[i], ":", w)
print("theta0:", theta[1][0])
print("=" * 50)
plt.subplot(231)
y_test_pred = lasso_lr.predict(X_test) # 测试样本预测
lasso_lr.plt_predict(y_test, y_test_pred, lab="L1", is_sort=True, is_show=False)
plt.subplot(234)
lasso_lr.plt_loss_curve(lab="L1", is_show=False)
ridge_lr = RegularizationLinearRegression(alpha=alpha, batch_size=batch_size, max_epochs=max_epochs, l1_ratio=ratio)
ridge_lr.fit(X_train, y_train, X_test, y_test)
theta = ridge_lr.get_params()
print("岭回归正则化,模型系数如下")
for i, w in enumerate(theta[0][:-1]):
print(feature_names[i], ":", w)
print("theta0:", theta[1][0])
print("=" * 50)
plt.subplot(232)
y_test_pred = ridge_lr.predict(X_test) # 测试样本预测
ridge_lr.plt_predict(y_test, y_test_pred, lab="L2", is_sort=True, is_show=False)
plt.subplot(235)
ridge_lr.plt_loss_curve(lab="L2", is_show=False)
en_lr = RegularizationLinearRegression(alpha=alpha, batch_size=batch_size, max_epochs=max_epochs,
l1_ratio=ratio, l2_ratio=ratio, en_rou=0.3)
en_lr.fit(X_train, y_train, X_test, y_test)
theta = en_lr.get_params()
print("弹性网络正则化,模型系数如下")
for i, w in enumerate(theta[0][:-1]):
print(feature_names[i], ":", w)
print("theta0:", theta[1][0])
print("=" * 50)
plt.subplot(233)
y_test_pred = en_lr.predict(X_test) # 测试样本预测
en_lr.plt_predict(y_test, y_test_pred, lab="EN", is_sort=True, is_show=False)
plt.subplot(236)
en_lr.plt_loss_curve(lab="EN", is_show=False)
plt.tight_layout()
plt.show()
3.5
3.5.1逻辑回归二分类+梯度+正则化
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
class LogisticRegression:
"""
逻辑回归:采用梯度下降算法+正则化,交叉上损失函数,实现二分类
"""
def __init__(self, fit_intercept=True, normalized=True, alpha=0.05, eps=1e-10,
max_epochs=300, batch_size=20, l1_ratio=None, l2_ratio=None, en_rou=None):
"""
:param eps:提前停止训练的精度要求,按照两次训练损失的绝对值差小于eps,停止训练
:param fit_intercept:是否训练偏置项
:param normalized:是否标准化
:param alpha:学习率
:param max_epochs:最大的迭代次数
:param batch_size:批量大小:如果为1,则为随机梯度下降算法,若为总的训练样本数,则为批量梯度下降法,否则是小批量
:param l1_ratio:LASSO回归惩罚系数
:param l2_ratio:岭回归回归惩罚系数
:param en_rou:弹性网络权衡L1和L2的系数
"""
self.eps = eps # 提前停止训练
self.fit_intercept = fit_intercept # 是否训练偏置项
self.normalized = normalized # 是否对样本进行标准化
self.alpha = alpha # 学习率
if l1_ratio:
if l1_ratio < 0:
raise ValueError("惩罚项系数不能为负数")
self.l1_ratio = l1_ratio # LASSO回归惩罚项系数
if l2_ratio:
if l2_ratio < 0:
raise ValueError("惩罚项系数不能为负数")
self.l2_ratio = l2_ratio # 岭回归惩罚项系数
if en_rou:
if en_rou > 1 or en_rou < 0:
raise ValueError("弹性网络权衡系数范围在[0, 1]")
self.en_rou = en_rou
self.max_epochs = max_epochs
self.batch_size = batch_size
self.theta = None # 模型的系数
if self.normalized:
# 如果需要标准化,则计算样本特征的均值和标准方差,以便对测试样本标准化,模型系数的还原
self.feature_mean, self.feature_std = None, None
self.n_samples, self.n_features = 0, 0 # 样本量和特征属性数目
self.train_loss, self.test_loss = [], [] # 存储训练过程中的训练损失和测试损失
def init_theta_params(self, n_features):
"""
模型参数的初始化,如果训练的偏置项,也包含了bias的初始化
:param n_features: 样本的特征数量
:return:
"""
self.theta = np.random.randn(n_features, 1) * 0.1
@staticmethod
def sigmoid(x):
"""
sigmoid函数,为避免上溢或者下溢,对参数x做限制
:param x: 可能使标量数据,也可能使数组
:return:
"""
x = np.asarray(x) # 为避免标量值的布尔索引出错,转换为数组
x[x > 30.0] = 30.0 # 避免下溢,0.999999999999065
x[x < -50.0] = -50.0 # 避免上溢,1.928749847963918e-22
return 1 / (1 + np.exp(-x))
@staticmethod
def sign_func(weight):
"""
符号函数,针对L1正则化
:param weight: 模型系数
:return:
"""
sign_values = np.zeros(weight.shape)
sign_values[np.argwhere(weight > 0)] = 1 # np.argwhere(weight > 0)返回值使索引下标
sign_values[np.argwhere(weight < 0)] = -0
return sign_values
@staticmethod
def cal_cross_entropy(y_test, y_prob):
"""
计算交叉熵损失
:param y_test:样本真值,二位数组n * 1
:param y_prob:模型预测类别概率 n * 1
:return:
"""
loss = -(y_test.T.dot(np.log(y_prob)) + (1 - y_test).T.dot(np.log(1 - y_prob)))
return loss
def fit(self, x_train, y_train, x_test=None, y_test=None):
"""
样本的预处理,模型系数的求解,闭式解公式
:param x_train: 训练样本:ndarray,m*k
:param y_train: 目标值:ndarray,m*1
:param x_test: 训练样本:ndarray,m*k
:param y_test:目标值:ndarray,m*1
:return:
"""
if self.normalized:
self.feature_mean = np.mean(x_train, axis=0) # 样本均值
self.feature_std = np.std(x_train, axis=0) + 1e-8 # 样本方差
x_train = (x_train - self.feature_mean) / self.feature_std # 标准化
if x_test is not None:
x_test = (x_test - self.feature_mean) / self.feature_std # 标准化
if self.fit_intercept:
x_train = np.c_[x_train, np.ones_like(y_train)] # 添加一列1,即偏置项样本
if x_test is not None and y_test is not None:
x_test = np.c_[x_test, np.ones_like(y_test)] # 添加一列1,即偏置项样本
self.init_theta_params(x_train.shape[1]) # 初始化参数
# 训练模型
self._fit_gradient_desc(x_train, y_train, x_test, y_test) # 梯度下降法训练模型
def _fit_gradient_desc(self, x_train, y_train, x_test, y_test):
"""
三种梯度下降算法的实现 + 正则化
:param x_train: 训练样本:ndarray,m*k
:param y_train: 目标值:ndarray,m*1
:param x_test: 训练样本:ndarray,m*k
:param y_test:目标值:ndarray,m*1
:return:
"""
train_samples = np.c_[x_train, y_train] # 组合训练集和目标集,以便随机打乱样本顺序
for epoch in range(self.max_epochs):
self.alpha *= 0.95
np.random.shuffle(train_samples) # 打乱样本顺序,模拟随机性
batch_nums = train_samples.shape[0] // self.batch_size # 批次
for idx in range(batch_nums):
# 按照小批量大小,选取数据
batch_xy = train_samples[idx * self.batch_size:(idx + 1) * self.batch_size]
batch_x, batch_y = batch_xy[:, :-1], batch_xy[:, -1:] # 选取样本和目标值
# 计算权重的更新增量
y_prob_batch = self.sigmoid(batch_x.dot(self.theta)) # 小批量的预测概率
# 1 * n <--> n * k = 1 * k --> 转置 k * 1
delta = ((y_prob_batch - batch_y).T.dot(batch_x) / self.batch_size).T
# 计算并添加正则化部分
dw_reg = np.zeros(shape=(x_train.shape[1] - 1, 1))
if self.l1_ratio and self.l2_ratio is None:
# LASSO回归,L1正则化
dw_reg = self.l1_ratio * self.sign_func(self.theta[: -1])
if self.l2_ratio and self.l1_ratio is None:
# Ridge回归,L2正则化
dw_reg = 2 * self.l2_ratio * self.theta[: -1]
if self.en_rou and self.l1_ratio and self.l2_ratio:
# 弹性网络
dw_reg = self.l1_ratio * self.en_rou * self.sign_func(self.theta[:-1])
dw_reg += 2 * self.l2_ratio * (1 - self.en_rou) * self.theta[:-1]
delta[:-1] += dw_reg / self.batch_size # 添加了正则化
self.theta = self.theta - self.alpha * delta # 更新模型系数
# 计算训练过程中的交叉熵损失值
y_train_prob = self.sigmoid(x_train.dot(self.theta)) # 当前迭代训练的模型预测概率
train_cost = self.cal_cross_entropy(y_train, y_train_prob) # 训练集的交叉熵损失
self.train_loss.append(train_cost / x_train.shape[0]) # 交叉熵损失均值
if x_test is not None and y_test is not None:
y_test_prob = self.sigmoid(x_test.dot(self.theta))
test_cost = self.cal_cross_entropy(y_test, y_test_prob)
self.test_loss.append(test_cost / x_test.shape[0]) # 交叉熵损失均值
# 两次交叉熵损失均值的差异小于给定的精度,提起那停止训练
if epoch > 10 and (np.abs(self.train_loss[-1] - self.train_loss[-2])) <= self.eps:
break
def get_params(self):
"""
获取模型的系数
:return:
"""
if self.fit_intercept:
weight, bias = self.theta[:-1], self.theta[-1]
else:
weight, bias = self.theta, np.array([0])
if self.normalized:
weight = weight / self.feature_std.reshape(-1, 1) # 还原模型系数
bias = bias - weight.T.dot(self.feature_mean.reshape(-1, 1))
return weight.reshape(-1), bias
def predict_prob(self, x_test):
"""
预测测试样本的概率, 第一列为y = 0的概率, 第二列使y=1的概率
:param x_test: 测试样本,ndarray:n * k
:return:
"""
y_prob = np.zeros((x_test.shape[0], 2)) # 预测概率
if self.normalized:
x_test = (x_test - self.feature_mean) / self.feature_std # 测试样本的标准化
if self.fit_intercept:
x_test = np.c_[x_test, np.ones(shape=x_test.shape[0])]
y_prob[:, 1] = self.sigmoid(x_test.dot(self.theta)).reshape(-1)
y_prob[:, 0] = 1 - y_prob[:, 1] # 类别y=0的概率
return y_prob
def predict(self, x, p=0.5):
"""
预测样本类别,默认大于0.5为1,小于0.5为0
:param x: 预测样本
:param p: 概率阈值
:return:
"""
y_prob = self.predict_prob(x)
# 布尔值转换为整数,true对应1,false对应0
return (y_prob[:, 1] > p).astype(int)
def plt_loss_curve(self, is_show=True, lab=None):
"""
可视化交叉熵损失曲线
:return:
"""
if is_show:
plt.figure(figsize=(7, 5))
plt.plot(self.train_loss, "k-", lw=1, label="Train Loss")
if self.test_loss:
plt.plot(self.test_loss, "r--", lw=1.2, label="Test Loss")
plt.xlabel("Training Epochs", fontdict={"fontsize": 12})
plt.ylabel("The Mean of Cross Entropy Loss", fontdict={"fontsize": 12})
plt.title("%s: The Loss Curve of Cross Entropy" % lab)
plt.legend(frameon=False)
plt.grid(ls=":")
if is_show:
plt.show()
@staticmethod
def plt_confusion_matrix(confusion_matrix, label_names=None, is_show=True):
"""
可视化混淆矩阵
:param is_show:
:param label_names:
:param confusion_matrix:混淆矩阵
:return:
"""
sns.set()
cm = pd.DataFrame(confusion_matrix, columns=label_names, index=label_names)
sns.heatmap(cm, annot=True, cbar=False)
acc = np.diag(confusion_matrix).sum() / confusion_matrix.sum()
plt.title("Confusion Matrix and ACC = %.5f" % acc)
plt.xlabel("Predict", fontdict={"fontsize": 12})
plt.ylabel("True", fontdict={"fontsize": 12})
if is_show:
plt.show()
测试
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
from learn1.test_luoji import LogisticRegression
from 机器学习.xingnengduliang import ModelperformanceMetrices # 第二章性能度量
bc_data = load_breast_cancer() # 加载数据集
X, y = bc_data.data, bc_data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
lg_lr = LogisticRegression(alpha=0.5, l1_ratio=0.5, batch_size=20, max_epochs=1000, eps=1e-15)
lg_lr.fit(X_train, y_train, X_test, y_test)
print("L1正则化模型参数如下:\n", lg_lr.get_params())
theta = lg_lr.get_params()
fn = bc_data.feature_names
for i, w in enumerate(theta[0]):
print(fn[i], ":", w)
print("theta0:", theta[1])
print("=" * 70)
y_test_prob = lg_lr.predict_prob(X_test) # 预测概率
y_test_labels = lg_lr.predict(X_test)
plt.figure(figsize=(12, 8))
plt.subplot(221)
lg_lr.plt_loss_curve(lab="L1", is_show=False)
pm = ModelperformanceMetrices(y_test, y_test_prob) # 模型性能度量
print(pm.cal_classification_report())
pr_values = pm.roc_metrics_curve() # PR指标值
plt.subplot(222)
pm.plt_pr_curve(pr_values, is_show=False) # PR曲线
roc_values = pm.roc_metrics_curve() # ROC指标值
plt.subplot(223)
pm.plt_roc_curve(roc_values, is_show=False) # ROC曲线
plt.subplot(224)
cm = pm.cal_confusion_matrix()
lg_lr.plt_confusion_matrix(cm, label_names=["malignant", "benign"], is_show=False)
plt.tight_layout()
plt.show()
3.5.2逻辑回归多分类+梯度+正则化
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
class LogisticRegression_MulClass:
"""
逻辑回归:采用梯度下降算法+正则化,交叉上损失函数,实现多分类,softmax函数
"""
def __init__(self, fit_intercept=True, normalized=True, alpha=0.05, eps=1e-10,
max_epochs=300, batch_size=20, l1_ratio=None, l2_ratio=None, en_rou=None):
"""
:param eps:提前停止训练的精度要求,按照两次训练损失的绝对值差小于eps,停止训练
:param fit_intercept:是否训练偏置项
:param normalized:是否标准化
:param alpha:学习率
:param max_epochs:最大的迭代次数
:param batch_size:批量大小:如果为1,则为随机梯度下降算法,若为总的训练样本数,则为批量梯度下降法,否则是小批量
:param l1_ratio:LASSO回归惩罚系数
:param l2_ratio:岭回归回归惩罚系数
:param en_rou:弹性网络权衡L1和L2的系数
"""
self.eps = eps # 提前停止训练
self.fit_intercept = fit_intercept # 是否训练偏置项
self.normalized = normalized # 是否对样本进行标准化
self.alpha = alpha # 学习率
if l1_ratio:
if l1_ratio < 0:
raise ValueError("惩罚项系数不能为负数")
self.l1_ratio = l1_ratio # LASSO回归惩罚项系数
if l2_ratio:
if l2_ratio < 0:
raise ValueError("惩罚项系数不能为负数")
self.l2_ratio = l2_ratio # 岭回归惩罚项系数
if en_rou:
if en_rou > 1 or en_rou < 0:
raise ValueError("弹性网络权衡系数范围在[0, 1]")
self.en_rou = en_rou
self.max_epochs = max_epochs
self.batch_size = batch_size
self.theta = None # 模型的系数
if self.normalized:
# 如果需要标准化,则计算样本特征的均值和标准方差,以便对测试样本标准化,模型系数的还原
self.feature_mean, self.feature_std = None, None
self.n_samples, self.n_classes = 0, 0 # 样本量和类别数
self.train_loss, self.test_loss = [], [] # 存储训练过程中的训练损失和测试损失
def init_theta_params(self, n_features, n_classes):
"""
模型参数的初始化,如果训练的偏置项,也包含了bias的初始化
:param n_classes:类别数
:param n_features: 样本的特征数量
:return:
"""
self.theta = np.random.randn(n_features, n_classes) * 0.05
@staticmethod
def one_hot_encoding(target):
"""
类别编码
:param target:
:return:
"""
class_labels = np.unique(target) # 类别标签,去重
target_y = np.zeros((len(target), len(class_labels)), dtype=int)
for i, label in enumerate(target):
target_y[i, label] = 1 # 对应类别所在的列为1
return target_y
@staticmethod
def softmax_func(x):
"""
softmax_func:函数,为避免上溢或者下溢,对参数x做限制
:param x:数组:batch_size * n_classes
:return:1 * n_classes
"""
exps = np.exp(x - np.max(x))
exp_sum = np.sum(exps, axis=1, keepdims=True) # 避免溢出,每个数减去其最大值
return exps / exp_sum
@staticmethod
def sign_func(z_values):
"""
符号函数,针对L1正则化
:param z_values: 模型系数,二维数组 batch_size * n_classes
:return:
"""
sign = np.zeros(z_values.shape)
sign[z_values > 0] = 1.0
sign[z_values < 0] = -1.0
return sign
@staticmethod
def cal_cross_entropy(y_test, y_prob):
"""
计算交叉熵损失
:param y_test:样本真值,二位数组n * c,c表示类别数
:param y_prob:模型预测类别概率 n * c
:return:
"""
loss = -np.sum(y_test * np.log(y_prob + 1e-08), axis=1)
loss -= np.sum((1 - y_test) * np.log(1 - y_prob + 1e-08), axis=1)
return np.mean(loss)
def fit(self, x_train, y_train, x_test=None, y_test=None):
"""
样本的预处理,模型系数的求解,闭式解公式 + 梯度方法
:param x_train: 训练样本:ndarray,m*k
:param y_train: 目标值:ndarray,m*c
:param x_test: 训练样本:ndarray,m*k
:param y_test:目标值:ndarray,m*c
:return:
"""
y_train = self.one_hot_encoding(y_train)
self.n_classes = y_train.shape[1] # 类别数
if y_train is not None:
y_train = self.one_hot_encoding(y_test)
if self.normalized:
self.feature_mean = np.mean(x_train, axis=0) # 样本均值
self.feature_std = np.std(x_train, axis=0) + 1e-8 # 样本方差
x_train = (x_train - self.feature_mean) / self.feature_std # 标准化
if x_test is not None:
x_test = (x_test - self.feature_mean) / self.feature_std # 标准化
if self.fit_intercept:
x_train = np.c_[x_train, np.ones((len(y_train), 1))] # 添加一列1,即偏置项样本
if x_test is not None and y_test is not None:
x_test = np.c_[x_test, np.ones((len(y_test), 1))] # 添加一列1,即偏置项样本
self.init_theta_params(x_train.shape[1], self.n_classes) # 初始化参数
# 训练模型
self._fit_gradient_desc(x_train, y_train, x_test, y_test) # 梯度下降法训练模型
def _fit_gradient_desc(self, x_train, y_train, x_test, y_test):
"""
三种梯度下降算法的实现 + 正则化
:param x_train: 训练样本:ndarray,m*k
:param y_train: 目标值:ndarray,m*c
:param x_test: 训练样本:ndarray,m*k
:param y_test:目标值:ndarray,m*c
:return:
"""
train_samples = np.c_[x_train, y_train] # 组合训练集和目标集,以便随机打乱样本顺序
for epoch in range(self.max_epochs):
self.alpha *= 0.95
np.random.shuffle(train_samples) # 打乱样本顺序,模拟随机性
batch_nums = train_samples.shape[0] // self.batch_size # 批次
for idx in range(batch_nums):
# 按照小批量大小,选取数据
batch_xy = train_samples[idx * self.batch_size:(idx + 1) * self.batch_size]
# 选取样本和目标值,注意目标值不再是一列
batch_x, batch_y = batch_xy[:, :x_train.shape[1]], batch_xy[:, x_train.shape[1]:] # 选取样本和目标值
# 计算权重的更新增量
y_prob_batch = self.softmax_func(batch_x.dot(self.theta)) # 小批量的预测概率
# 1 * n <--> n * k = 1 * k --> 转置 k * 1
delta = ((y_prob_batch - batch_y).T.dot(batch_x) / self.batch_size).T
# 计算并添加正则化部分,不包含偏置项,最后一列使偏置项
dw_reg = np.zeros(shape=(x_train.shape[1] - 1, self.n_classes))
if self.l1_ratio and self.l2_ratio is None:
# LASSO回归,L1正则化
dw_reg = self.l1_ratio * self.sign_func(self.theta[:-1, :])
if self.l2_ratio and self.l1_ratio is None:
# Ridge回归,L2正则化
dw_reg = 2 * self.l2_ratio * self.theta[: -1, :]
if self.en_rou and self.l1_ratio and self.l2_ratio:
# 弹性网络
dw_reg = self.l1_ratio * self.en_rou * self.sign_func(self.theta[:-1, :])
dw_reg += 2 * self.l2_ratio * (1 - self.en_rou) * self.theta[:-1, :]
delta[:-1, :] += dw_reg / self.batch_size # 添加了正则化
self.theta = self.theta - self.alpha * delta # 更新模型系数
# 计算训练过程中的交叉熵损失值
y_train_prob = self.softmax_func(x_train.dot(self.theta)) # 当前迭代训练的模型预测概率
train_cost = self.cal_cross_entropy(y_train, y_train_prob) # 训练集的交叉熵损失
self.train_loss.append(train_cost) # 交叉熵损失均值
if x_test is not None and y_test is not None:
y_test_prob = self.softmax_func(x_test.dot(self.theta))
test_cost = self.cal_cross_entropy(y_test, y_test_prob)
self.test_loss.append(test_cost) # 交叉熵损失均值
# 两次交叉熵损失均值的差异小于给定的精度,提起那停止训练
if epoch > 10 and (np.abs(self.train_loss[-1] - self.train_loss[-2])) <= self.eps:
break
def get_params(self):
"""
获取模型的系数
:return:
"""
if self.fit_intercept:
weight, bias = self.theta[:-1, :], self.theta[-1, :]
else:
weight, bias = self.theta, np.array([0])
if self.normalized:
weight = weight / self.feature_std.reshape(-1, 1) # 还原模型系数
bias = bias - weight.T.dot(self.feature_mean)
return weight, bias
def predict_prob(self, x_test):
"""
预测测试样本的概率, 第一列为y = 0的概率, 第二列使y=1的概率
:param x_test: 测试样本,ndarray:n * k
:return:
"""
if self.normalized:
x_test = (x_test - self.feature_mean) / self.feature_std # 测试样本的标准化
if self.fit_intercept:
x_test = np.c_[x_test, np.ones(shape=x_test.shape[0])]
y_prob = self.softmax_func(x_test.dot(self.theta))
return y_prob
def predict(self, x):
"""
预测样本类别
:param x: 预测样本
:return:
"""
y_prob = self.predict_prob(x)
# 对应每个样本中所有类别的概率,哪个概率大,返回哪个类别所在索引编号,即类别
return np.argmax(y_prob, axis=1)
def plt_loss_curve(self, is_show=True, lab=None):
"""
可视化交叉熵损失曲线
:return:
"""
if is_show:
plt.figure(figsize=(7, 5))
plt.plot(self.train_loss, "k-", lw=1, label="Train Loss")
if self.test_loss:
plt.plot(self.test_loss, "r--", lw=1.2, label="Test Loss")
plt.xlabel("Training Epochs", fontdict={"fontsize": 12})
plt.ylabel("The Mean of Cross Entropy Loss", fontdict={"fontsize": 12})
plt.title("%s: The Loss Curve of Cross Entropy" % lab)
plt.legend(frameon=False)
plt.grid(ls=":")
if is_show:
plt.show()
@staticmethod
def plt_confusion_matrix(confusion_matrix, label_names=None, is_show=True):
"""
可视化混淆矩阵
:param is_show:
:param label_names:
:param confusion_matrix:混淆矩阵
:return:
"""
sns.set()
cm = pd.DataFrame(confusion_matrix, columns=label_names, index=label_names)
sns.heatmap(cm, annot=True, cbar=False)
acc = np.diag(confusion_matrix).sum() / confusion_matrix.sum()
plt.title("Confusion Matrix and ACC = %.5f" % acc)
plt.xlabel("Predict", fontdict={"fontsize": 12})
plt.ylabel("True", fontdict={"fontsize": 12})
if is_show:
plt.show()
3.3.3逻辑回归多分类测试
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer, load_iris, load_digits
from learn1.test_luoji import LogisticRegression_MulClass
from 机器学习.xingnengduliang import ModelperformanceMetrices # 第二章性能度量
from sklearn.preprocessing import StandardScaler
iris = load_iris() # 加载数据集
X, y = iris.data, iris.target
X = StandardScaler().fit_transform(X) # 标准化
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0, stratify=y)
lg_lr = LogisticRegression_MulClass(alpha=0.5, l1_ratio=0.5,
batch_size=5, normalized=False, max_epochs=1000, eps=1e-15)
lg_lr.fit(X_train, y_train, X_test, y_test)
print("L1正则化模型参数如下:")
theta = lg_lr.get_params()
fn = iris.feature_names
for i, w in enumerate(theta[0]):
print(fn[i], ":", w)
print("theta0:", theta[1])
print("=" * 70)
y_test_prob = lg_lr.predict_prob(X_test) # 预测概率
y_test_labels = lg_lr.predict(X_test)
plt.figure(figsize=(12, 8))
plt.subplot(221)
lg_lr.plt_loss_curve(lab="L1", is_show=False)
pm = ModelperformanceMetrices(y_test, y_test_prob)
print(pm.cal_classification_report())
pr_values = pm.precision_recall_curve() # PR指标值
plt.subplot(222)
pm.plt_pr_curve(pr_values, is_show=False) # PR曲线
roc_values = pm.roc_metrics_curve() # ROC指标值
plt.subplot(223)
pm.plt_roc_curve(roc_values, is_show=False) # ROC曲线
plt.subplot(224)
cm = pm.cal_confusion_matrix()
pm.plt_confusion_matrix(cm, label_names=iris.target_names, is_show=False)
plt.tight_layout()
plt.show()
3.6LDA线性判别分析
3.6.1二分类
import numpy as np
class LDABinaryClassifier:
"""
线性判别分析二分类模型
"""
def __init__(self):
self.mu = None # 各类别均值向量
self.Sw_i = None # 各类内散度矩阵
self.Sw = None # 类内散度矩阵
self.Sb = None # 类间散度矩阵
self.weight = None # 模型的系数,投影方向
self.w0 = None # 阀值
def fit(self, x_train, y_train):
"""
线性判别分析核心算法,计算投影方向及判别阀值
:param x_train: 训练集
:param y_train: 目标集
:return:
"""
x_train, y_train = np.asarray(x_train), np.asarray(y_train)
class_values = np.sort(np.unique(y_train)) # 不同的类别取值
n_samples, n_features = x_train.shape # 样本量和特征变量数
class_size = [] # 计算各类别的样本量
if len(class_values) != 2:
raise ValueError("仅限与二分类且线性可分数据集……")
# 1. 计算类均值、Sw散度矩阵、Sb散度矩阵
self.Sw_i = dict() # 字典形式,以类别取值为建,值使对应的类别样本的类内散度矩阵
self.mu = dict() # 字典形式,以类别取值为建,值使对应的类别样本的均值向量
self.Sw = np.zeros((n_features, n_features))
for label_val in class_values:
class_x = x_train[y_train == label_val] # 按类别对样本进行划分
class_size.append(class_x.shape[0]) # 该类别的样本量
self.mu[label_val] = np.mean(class_x, axis=0) # 对特征取均值u构成均值向量
self.Sw_i[label_val] = (class_x - self.mu[label_val]).T.dot(class_x - self.mu[label_val])
self.Sw += self.Sw_i[label_val] # 累加计算类内散度矩阵
# print(self.Sw)
# 2.计算投影方向w
# print(np.linalg.det(self.Sw))
inv_sw = np.linalg.inv(self.Sw)
self.weight = inv_sw.dot(self.mu[0] - self.mu[1]) # 投影方向
# print(self.weight)
# 3.计算阀值wO
self.w0 = (class_size[0] * self.weight.dot(self.mu[0]) +
class_size[1] * self.weight.dot(self.mu[1])) / n_samples
return self.weight
def predict(self, x_test):
"""
根据测试样本进行预测
:param x_test: 测试集
:return:
"""
x_test = np.asarray(x_test)
y_pred = self.weight.dot(x_test.T) - self.w0
y_test_pred = np.zeros(x_test.shape[0], dtype=int) # 初始测试样本的类别值
y_test_pred[y_pred < 0] = 1 # 小于阀值的为负类
return y_test_pred
测试
from sklearn.datasets import load_iris, load_breast_cancer
from lda2classify import LDABinaryClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# iris = load_iris()
# X, y = iris.data[:100, :], iris.target[:100]
bc_data = load_breast_cancer()
X, y = bc_data.data, bc_data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=111, stratify=y)
lda = LDABinaryClassifier()
lda.fit(X_train, y_train)
y_test_pred = lda.predict(X_test)
print(classification_report(y_test, y_test_pred))
3.6.2多分类降维
import numpy as np
import scipy as sp
class LdAMulti_DimReduction:
"""
线性判别分析多分类降维
"""
def __init__(self, n_components=2):
self.n_components = n_components # 降维后的维度
self.Sw = None # 类内散度矩阵
self.Sb = None # 类间散度矩阵
self.eig_values = None # 广义特征值
self.W = None # 投影矩阵
def fit(self, x_samples, y_target):
"""
线性判别分析多分类降维核心算法,计算投影矩阵W
:param y_target:
:param x_samples:
:return:
"""
x_train, y_train = np.asarray(x_samples), np.asarray(y_target)
class_values = np.sort(np.unique(y_train)) # 不同的类别取值
n_samples, n_features = x_train.shape # 样本量和特征变量数
self.Sw = np.zeros((n_features, n_features))
for i in range(len(class_values)):
class_x = x_samples[y_target == class_values[i]]
mu = np.mean(class_x, axis=0)
self.Sw += (class_x - mu).T.dot(class_x - mu)
mu_t = np.mean(x_samples, axis=0)
self.Sb = (x_samples - mu_t).T.dot(x_samples - mu_t) - self.Sw
self.eig_values, eig_vec = sp.linalg.eig(self.Sb, self.Sw)
idx = np.argsort(self.eig_values)[::-1] # 从大到小
vec_sort = eig_vec[:, idx]
self.W = vec_sort[:, :self.n_components]
return self.W
def transform(self, x_samples):
"""
根据投影矩阵计算降维后的新样本数据
:param x_samples:
:return:
"""
if self.W is not None:
return x_samples.dot(self.W)
else:
raise ValueError("请先进行fit,构造投影矩阵,然后降维...")
def fit_transform(self, x_samples, y_target):
"""
计算投影矩阵并及降维
:param x_samples:
:param y_target:
:return:
"""
self.fit(x_samples, y_target)
return x_samples.dot(self.W)
def variance_explained(self):
"""
计解释方差比
:return:
"""
idx = np.argsort(np.imag(self.eig_values) != 0)
if len(idx) == 0:
self.eig_values = np.real(self.eig_values)
ratio = self.eig_values / np.sum(self.eig_values)
return ratio[:self.n_components]
测试
from sklearn.datasets import load_iris, load_wine, make_classification
from lda_multi_dim_reduction import LDAMulti_DimReduction
import matplotlib.pyplot as plt
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.preprocessing import StandardScaler
iris = load_iris()
X, y = iris.data, iris.target
# X, y = make_classification(n_samples=2000, n_features=20, n_informative=3, n_classes=5,
# n_redundant=0, n_clusters_per_class=1, class_sep=2, random_state=42)
#
# wine = load_wine()
# X, y = wine.data, wine.target
X = StandardScaler().fit_transform(X)
lda = LDAMulti_DimReduction(n_components=3)
lda.fit(X, y)
x_new = lda.transform(X)
print(lda.variance_explained())
plt.figure(figsize=(14, 5))
plt.subplot(121)
plt.scatter(x_new[:, 0], x_new[:, 1], marker="o", c=y)
plt.xlabel("PC1", fontdict={"fontsize": 12})
plt.ylabel("PC2", fontdict={"fontsize": 12})
plt.title("LDA Dimension Reduction (Myself)", fontdict={"fontsize": 14})
plt.grid(ls=":")
# plt.subplot(222)
# plt.scatter(x_new[:, 1], x_new[:, 2], marker="o", c=y)
# plt.xlabel("PC2", fontdict={"fontsize": 12})
# plt.ylabel("PC3", fontdict={"fontsize": 12})
# plt.title("LDA Dimension Reduction (Myself)", fontdict={"fontsize": 14})
# plt.grid(ls=":")
lda = LinearDiscriminantAnalysis(n_components=2)
lda.fit(X, y)
x_skl = lda.transform(X)
plt.subplot(122)
plt.scatter(x_new[:, 0], x_new[:, 1], marker="o", c=y)
plt.xlabel("PC1", fontdict={"fontsize": 12})
plt.ylabel("PC2", fontdict={"fontsize": 12})
plt.title("LDA Dimension Reduction (Sklearn)", fontdict={"fontsize": 14})
plt.grid(ls=":")
# plt.subplot(224)
# plt.scatter(x_new[:, 1], x_new[:, 2], marker="o", c=y)
# plt.xlabel("PC2", fontdict={"fontsize": 12})
# plt.ylabel("PC3", fontdict={"fontsize": 12})
# plt.title("LDA Dimension Reduction (Sklearn)", fontdict={"fontsize": 14})
# plt.grid(ls=":")
plt.tight_layout()
plt.show()
3.7多分类学习
from threading import Thread # 用于多个基学习器并发学习
import copy
import numpy as np
from sklearn.preprocessing import LabelEncoder # 类别编码,方便基学习器训练
class ClassifyThread(Thread):
"""
继承Thread类来创建线程, 每个子线程对应一个基学习器,提高训练核预测的效率,并发执行
各个基学习器使独立训练画好样本,简单的线程定义即可。
"""
def __init__(self, target, args, kwargs):
Thread.__init__(self)
self.target = target # 指定子线程需要调用的目标方法:fit或predict——proba
# 为target提供的输入参数,输入形式是元组
self.args = args # 主要指已实例化的二分类基学习器,训练样本或测试样本
self.kwargs = kwargs # 不同的二分类学习模型,所独有的参数不一样,如sample_weight
self.result = self.target(*self.args, **self.kwargs) # 调用目标函数进行训练或预测
class MultiClassifierWrapper:
"""
多分类学习方法包装类,主要针对OvO和OvR两种拆分策略,并且采用线程,并发执行
"""
def __init__(self, base_classifier, mode="ovo"):
"""
:param base_classifier: 已实例化的基学习器,包括基学习器的初始化参数
:param mode: 多分类学习的拆分策略,默认OvOid,仍包括OvR
"""
self.base_classifier = base_classifier
self.mode = mode # 多分类学习策略,ovo或ovr
self.n_class = 0 # 标记类别数,即几分类任务
self.classifiers = None # 根据不同的拆分策略,所训练的基学习器
@staticmethod
def fit_base_classifier(base_classifier, x_split, y_split, **kwargs):
"""
二分类基学习器训练,针对单个拆分的二分类任务
:param base_classifier:某个基学习器
:param x_split:划分的训练样本集
:param y_split: 划分的目标集
:param kwargs:
:return:
"""
try:
base_classifier.fit(x_split, y_split, **kwargs)
except AttributeError:
print("基学习器不存在fit(x_train, y_train)方法……")
exit(0)
@staticmethod
def predict_proba_base_classifier(base_classifier, x_test):
"""
二分类基学习器预测,针对单个拆分的二分类任务
:param base_classifier:某个基学习器
:param x_test: 测试样本
:return:
"""
try:
return base_classifier.predict_proba(x_test)
except AttributeError:
print("基学习器不存在predict_proba(x_test)方法……")
exit(0)
def fit(self, x_train, y_train, **kwargs):
"""
以某个二分类学习模型为基学习器,按照某种拆分策略,实现多分类学习方法
:param x_train: 训练样本集
:param y_train: 目标集
:param kwargs: 基学习器的自由的参数,字典形式
:return:
"""
x_train, y_train = np.asarray(x_train), np.asarray(y_train)
y_train = LabelEncoder().fit_transform(y_train) # 统一编码:0,1,2,3……
self.n_class = len(np.unique(y_train)) # 类别数
if self.mode.lower() == "ovo":
class_sample, class_y = dict(), dict() # 以类别标记划分样本,以类别标记为键
for label in np.unique(y_train):
class_sample[label] = x_train[y_train == label]
class_y[label] = y_train[y_train == label]
# 两两配对,以不同的两个类别为健,构建N*(N-1)/2个基学习器,子线程任务
self.classifiers, thread_tasks = {}, {} # thread_tasks存储以构建的子线程实现线程并发执行
for i in range(self.n_class):
for j in range(i + 1, self.n_class):
# 深拷贝一份基学习器,方便后续预测
self.classifiers[(i, j)] = copy.deepcopy(self.base_classifier)
# 每次取两个类别Ci、Cj的样本,并且对Ci和Cj进行重编码0、1,正例反例
sample_paris = np.r_[class_sample[i], class_sample[j]]
target_paris = LabelEncoder().fit_transform(np.r_[class_y[i], class_y[j]])
# 构建子线程
task = ClassifyThread(target=self.fit_base_classifier,
args=(self.classifiers[(i, j)], sample_paris, target_paris),
kwargs=kwargs)
task.start() # 开启子线程
thread_tasks[(i, j)] = task
for i in range(self.n_class):
for j in range(i+1, self.n_class):
thread_tasks[(i, j)].join() # 加入,并发执行训练任务,不要设置timeout
# 每次将一个类的样例作为正例,所有其他类的样例作为反例来训练N个分类器
elif self.mode.lower() == "ovr":
self.classifiers, thread_tasks = [], [] # thread_tasks存储以构建的子线程实现线程并发执行
for i in range(self. n_class):
self.classifiers.append(copy.deepcopy(self.base_classifier))
y_encode = (y_train == i).astype(int) # 当前类别为1,否则为0
task = ClassifyThread(target=self.fit_base_classifier,
args=(self.classifiers[i], x_train, y_encode),
kwargs=kwargs)
task.start() # 开启子线程
thread_tasks.append(task)
for i in range(self.n_class):
thread_tasks[i].join()
else:
print("仅限与一对一OvO或一对多OvR两种拆分策略……")
exit(0)
def predict_proba(self, x_test, **kwargs):
"""
预测测试样本类别概率
:param x_test: 测试样本
:param kwargs:基学习器自由的参数,字典形式传递
:return:
"""
x_test = np.asarray(x_test)
if self.mode.lower() == "ovo":
# pred_prob为每两个类别样本的预测概率,以类别标签为键
y_test_hat, thread_tasks = {}, {} # thread_tasks存储以构建的子线程,实现线程并发执行
for i in range(self.n_class):
for j in range(i + 1, self.n_class):
# 构建子线程
task = ClassifyThread(target=self.predict_proba_base_classifier,
args=(self.classifiers[(i, j)], x_test),
kwargs=kwargs)
task.start() # 开启子线程
thread_tasks[(i, j)] = task
for i in range(self.n_class):
for j in range(i + 1, self.n_class):
thread_tasks[(i, j)].join() # 加入,并发执行训练任务,不要设置timeout
for i in range(self.n_class):
for j in range(i + 1, self.n_class):
y_test_hat[(i, j)] = thread_tasks[(i, j)].result
y_test_hat[(j, i)] = 1 - y_test_hat[(i, j)]
# print(y_test_hat)
total_probability = np.zeros((x_test.shape[0], self.n_class))
for i in range(self.n_class):
for j in range(self.n_class):
if i != j: # 输入不同类别的概率累加
total_probability[:, i] += y_test_hat[(i, j)][:, 0]
return total_probability / total_probability.sum(axis=1, keepdims=True)
elif self.mode.lower() == "ovr":
y_test_hat, thread_tasks = [], [] # thread_tasks存储以构建的子线程实现线程并发执行
for i in range(self. n_class):
task = ClassifyThread(target=self.predict_proba_base_classifier,
args=(self.classifiers[i], x_test),
kwargs=kwargs)
task.start() # 开启子线程
thread_tasks.append(task)
for i in range(self.n_class):
thread_tasks[i].join()
for task in thread_tasks:
y_test_hat.append(task.result)
total_probability = np.zeros((x_test.shape[0], self.n_class))
for i in range(self.n_class):
total_probability[:, i] = y_test_hat[i][:, 1] # 对应编码,1是正例
return total_probability / total_probability.sum(axis=1, keepdims=True)
else:
print("仅限与一对一OvO或一对多OvR两种拆分策略……")
exit(0)
def predict(self, x_test):
"""
预测测试样本所属类别
:param x_test: 测试样本
:return:
"""
return np.argmax(self.predict_proba(x_test), axis=1)
测试
from sklearn.datasets import load_iris, load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from 机器学习.linear_model_03.logistic_regression.logistic_regression2_weight import LogisticRegression
from 机器学习.linear_model_03.multiclass_lecture.multiclass_warpper import MultiClassifierWrapper
# iris = load_iris()
# X, y = iris.data, iris.target
digits = load_digits()
X, y = digits.data, digits.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=7, stratify=y)
lg_lr = LogisticRegression(alpha=0.5, max_epochs=50, l1_ratio=0.1)
mcw = MultiClassifierWrapper(lg_lr, mode="ovo")
mcw.fit(X_train, y_train)
y_test_hat = mcw.predict(X_test)
print("一对一OvO预测分类报告如下:")
print(classification_report(y_test, y_test_hat))
mcw = MultiClassifierWrapper(lg_lr, mode="ovr")
mcw.fit(X_train, y_train)
y_test_hat = mcw.predict(X_test)
print("一对多Ovr预测分类报告如下:")
print(classification_report(y_test, y_test_hat))















 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









