






永久存储(上)
1. 永久存储
当我们在说 “永久存储” 的时候,是希望将数据保存到硬盘上,而非内存,因为内存在计算机断电后数据将会丢失。
2. 打开文件
使用 Python 打开一个文件,我们需要用到 open() 函数:
- >>> f = open("FishC.txt", "w")
第一个参数指定的是文件路径和文件名,这里我们没有添加路径的话,那么默认是将文件创建在 Python 的主文件夹下面,因为执行 IDLE 的程序就放在那里嘛(同样的道理,如果我们在桌面创建一个 test.py 的源文件,然后输入打开文件的代码,那么它就会在桌面创建一个 FishC.txt 的文本文件)。
第二个参数是指定文件的打开模式:
| 字符串 | 含义 |
| 'r' | 读取(默认) |
| 'w' | 写入(如果文件已存在则先截断清空文件) |
| 'x' | 排他性创建文件(如果文件已存在则打开失败) |
| 'a' | 追加(如果文件已存在则在末尾追加内容) |
| 'b' | 二进制模式 |
| 't' | 文本模式(默认) |
| '+' | 更新文件(读取和写入) |
3. 文件对象的各种方法大合集
open() 函数成功调用之后,会返回一个文件对象,那么通过这个文件对象,我们就可以往这个文件里面写入数据啦。
文件对象,提供了一系列方法,让你可以对它为所欲为。
文件对象的各种方法大合集 -> 传送门
有两个方法可以将字符串写入到文本对象种,一个是 write(),一个是 writelines():
- >>> f.write("I love Python.")
- 14
使用 write() 方法,它有一个返回值,就是总共写入到文件对象中的字符个数。
使用 writelines() 方法,则可以将多个字符串同时写入:
- >>> f.writelines(["I love FishC.\n", "I love my wife."])
- >>>
注意:虽然 writelines() 方法支持传入多个字符串,但它不会帮你添加换行符,所以我们要自己添加才行。[/code]
4. 关闭文件
我们使用 close() 方法来关闭文件:
- >>> f.close()
- >>>
注意,文件对象关闭之后,我们就没办法对它进行操作了。
如果想要继续操作文件,那么我们必须重新打开它。
5. 思维导图

永久存储(中)
1. 路径处理
不同操作系统,它的这个路径分隔符是不一样的,比如 Windows 系统是使用反斜杠,而其他大多数操作系统则是使用斜杠来分隔。
这个 Windows 采用的反斜杠,跟字符串中的转义字符的反斜杠是同一条杠,那么,如果你想要在 Windows 上使用反斜杠来分隔路径,你就不得不用另一条反斜杠来转移反斜杠,或者使用原始字符串,并不是说这么做有多困难吧,就是觉得这样做不是那么优雅……
2. 实用高效的速查手册(大家记得收藏哦)
pathlib 速查手册 -> 传送门
新旧路径处理模块大比拼(pathlib vs os.path)-> 传送门
3. 相对路径和绝对路径
相对路径:以当前目录作为基准,进而逐级推导(.. 表示上级目录;. 当前目录)。
绝对路径:文件真正存在的路径,从根目录逐级推导到指定的文件 / 文件夹。
4. pathlib.Path 实用功能讲解
使用 Path 里面的 cwd() 方法来获取当前的工作目录:
- >>> Path.cwd()
- WindowsPath('C:/Users/goodb/AppData/Local/Programs/Python/Python39')
创建路径对象:
- >>> p = Path('C:/Users/goodb/AppData/Local/Programs/Python/Python39')
使用斜杠(/)直接进行路径拼接:
- >>> q = p / "FishC.txt"
- >>> q
- WindowsPath('C:/Users/goodb/AppData/Local/Programs/Python/Python39/FishC.txt')
使用 is_dir() 方法可以判断一个路径是否为一个文件夹:
- >>> p.is_dir()
- True
- >>> q.is_dir()
- False
使用 is_file() 方法可以判断一个路径是否为一个文件:
- >>> p.is_file()
- False
- >>> q.is_file()
- True
通过 exists() 方法测试指定的路径是否真实存在:
- >>> p.exists()
- True
- >>> q.exists()
- True
- >>> Path("C:/404").exists()
- False
使用 name 属性去获取路径的最后一个部分:
- >>> p.name
- 'Python39'
- >>> q.name
- 'FishC.txt'
stem 属性用于获取文件名,suffix 属性用于获取文件后缀:
- >>> q.stem
- 'FishC'
- >>> q.suffix
- '.txt'
parent 属性用于获取其父级目录:
- >>> p.parent
- WindowsPath('C:/Users/goodb/AppData/Local/Programs/Python')
- >>> q.parent
- WindowsPath('C:/Users/goodb/AppData/Local/Programs/Python/Python39')
加个复数,parents,还可以获得其逻辑祖先路径构成的一个不可变序列:
- >>> p.parents
- <WindowsPath.parents>
- >>> ps = p.parents
- >>> for each in ps:
- ... print(each)
- ...
- C:\Users\goodb\AppData\Local\Programs\Python
- C:\Users\goodb\AppData\Local\Programs
- C:\Users\goodb\AppData\Local
- C:\Users\goodb\AppData
- C:\Users\goodb
- C:\Users
- C:\
还支持索引:
- >>> ps[0]
- WindowsPath('C:/Users/goodb/AppData/Local/Programs/Python')
- >>> ps[1]
- WindowsPath('C:/Users/goodb/AppData/Local/Programs')
- >>> ps[2]
- WindowsPath('C:/Users/goodb/AppData/Local')
parts 属性将路径的各个组件拆分成元组的形式:
- >>> p.parts
- ('C:\\', 'Users', 'goodb', 'AppData', 'Local', 'Programs', 'Python', 'Python39')
- >>> q.parts
- ('C:\\', 'Users', 'goodb', 'AppData', 'Local', 'Programs', 'Python', 'Python39', 'FishC.txt')
最后,还可以查询文件或文件夹的状态信息:
- >>> p.stat()
- os.stat_result(st_mode=16895, st_ino=281474976983758, st_dev=1289007019, st_nlink=1, st_uid=0, st_gid=0, st_size=4096, st_atime=1648462096, st_mtime=1648205377, st_ctime=1605695407)
- >>> q.stat()
- os.stat_result(st_mode=33206, st_ino=4503599627467517, st_dev=1289007019, st_nlink=1, st_uid=0, st_gid=0, st_size=0, st_atime=1648206152, st_mtime=1648206152, st_ctime=1648205377)
比如这个 st_size 就是文件或文件夹的尺寸信息:
- >>> p.stat().st_size
- 4096
- >>> q.stat().st_size
- 0
使用 resolve() 方法可以将相对路径转换为绝对路径:
- >>> Path('./doc').resolve()
- WindowsPath('C:/Users/goodb/AppData/Local/Programs/Python/Python39/Doc')
- >>> Path('../FishC').resolve()
- WindowsPath('C:/Users/goodb/AppData/Local/Programs/Python/FishC')
最后还可以通过 iterdir() 获取当前路径下面的所有子文件和子文件夹对象:
- >>> p.iterdir()
- <generator object Path.iterdir at 0x0000012D57CBE660>
它生成的是一个迭代器对象,所以可以放到 for 语句中去提取数据:
- >>> for each in p.iterdir():
- ... print(each.name)
- ...
- DLLs
- Doc
- FishC
- FishC.txt
- include
- Lib
- libs
- LICENSE.txt
- NEWS.txt
- python.exe
- python3.dll
- python39.dll
- pythonw.exe
- Scripts
- tcl
- Tools
- vcruntime140.dll
- vcruntime140_1.dll
如果我们要将当前路径下面的所有文件整理成一个列表,可以这么做(注意,是文件,不包含文件夹,所以我们要加一个条件过滤):
- >>> [x for x in p.iterdir() if x.is_file()]
- [WindowsPath('FishC.txt'), WindowsPath('LICENSE.txt'), WindowsPath('NEWS.txt'), WindowsPath('python.exe'), WindowsPath('python3.dll'), WindowsPath('python39.dll'), WindowsPath('pythonw.exe'), WindowsPath('vcruntime140.dll'), WindowsPath('vcruntime140_1.dll')]
以上是用得比较多的,与路径查询相关的操作。
那么修改路径也是支持的,比如我们可以使用 mkdir() 方法来创建文件夹:
- >>> n = p / "FishC"
- >>> n.mkdir()
- >>>
注意,如果需要创建的文件夹已经存在,那么它就会报错:
- >>> n.mkdir()
- Traceback (most recent call last):
- File "<pyshell#16>", line 1, in <module>
- n.mkdir()
- File "C:\Users\goodb\AppData\Local\Programs\Python\Python39\lib\pathlib.py", line 1323, in mkdir
- self._accessor.mkdir(self, mode)
- FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。: 'C:\\Users\\goodb\\AppData\\Local\\Programs\\Python\\Python39\\FishC'
也可以避开这个报错信息,我们设置其 exist_ok 参数的值为 True 即可:
- >>> n.mkdir(exist_ok=True)
- >>>
还有一点需要注意的就是,如果路径中有存在多个不存在的父级目录,那么也会出错的,比如这样:
- >>> n = p / "FishC/A/B/C"
- >>> n.mkdir(exist_ok=True)
- Traceback (most recent call last):
- File "<pyshell#22>", line 1, in <module>
- n.mkdir(exist_ok=True)
- File "C:\Users\goodb\AppData\Local\Programs\Python\Python39\lib\pathlib.py", line 1323, in mkdir
- self._accessor.mkdir(self, mode)
- FileNotFoundError: [WinError 3] 系统找不到指定的路径。: 'C:\\Users\\goodb\\AppData\\Local\\Programs\\Python\\Python39\\FishC\\A\\B\\C'
它也定义了一个参数用于对付这种情况,将 parents 参数设置为 True 就可以了:
- >>> n.mkdir(parents=True, exist_ok=True)
- >>>
Path 内部其实还打包了一个 open() 方法,除了不用传入路径之外,其它参数跟 open() 函数是一摸一样的:
- >>> n = n / 'FishC.txt'
- >>> n
- WindowsPath('C:/Users/goodb/AppData/Local/Programs/Python/Python39/FishC/A/B/C/FishC.txt')
- >>> f = n.open('w')
- >>> f.write("I love FishC.")
- 13
- >>> f.close()
可以给文件或文件夹修改名字,使用 rename() 方法来实现:
- >>> n.rename("NewFishC.txt")
- WindowsPath('NewFishC.txt')
然后使用 replace() 方法替换文件或文件夹:
- >>> m = Path("NewFishC.txt")
- >>> n
- WindowsPath('C:/Users/goodb/AppData/Local/Programs/Python/Python39/FishC/A/B/C/FishC.txt')
- >>> m.replace(n)
- WindowsPath('C:/Users/goodb/AppData/Local/Programs/Python/Python39/FishC/A/B/C/FishC.txt')
还有删除操作,rmdir() 和 unlink() 方法,前者用于删除文件夹,后者用于删除文件:
- >>> n.parent.rmdir()
- Traceback (most recent call last):
- File "<pyshell#6>", line 1, in <module>
- n.parent.rmdir()
- File "C:\Users\goodb\AppData\Local\Programs\Python\Python39\lib\pathlib.py", line 1363, in rmdir
- self._accessor.rmdir(self)
- OSError: [WinError 145] 目录不是空的。: 'C:\\Users\\goodb\\AppData\\Local\\Programs\\Python\\Python39\\FishC\\A\\B\\C'
可以看到,如果不是空文件夹,它是删不掉的,我们需要先把里面的文件删了:
- >>> n.unlink()
- >>>
现在再删除文件夹,就 OK 啦:
- >>> n.parent.rmdir()
- >>>
最后是功能强大的查找,由 glob() 方法来实现:
- >>> p = Path('.')
- >>> list(p.glob("*.txt"))
- [WindowsPath('FishC.txt'), WindowsPath('LICENSE.txt'), WindowsPath('NEWS.txt')]
这就查找当前目录下的所有 .txt 后缀的文件,如果要查找当前目录的下一级目录中的所有 .py 后缀的文件,可以这么写:
- >>> list(p.glob('*/*.py'))
- [WindowsPath('Lib/abc.py'), WindowsPath('Lib/aifc.py'), WindowsPath('Lib/antigravity.py'), ...]
好了,那么如果希望进行向下递归搜索,也就是查找当前目录以及该目录下面的所有子目录,可以使用两个星号(**)表示:
- >>> list(p.glob('**/*.py'))
- [WindowsPath('Lib/abc.py'), WindowsPath('Lib/aifc.py'), WindowsPath('Lib/antigravity.py'), ...]
5. 思维导图

永久存储(下)
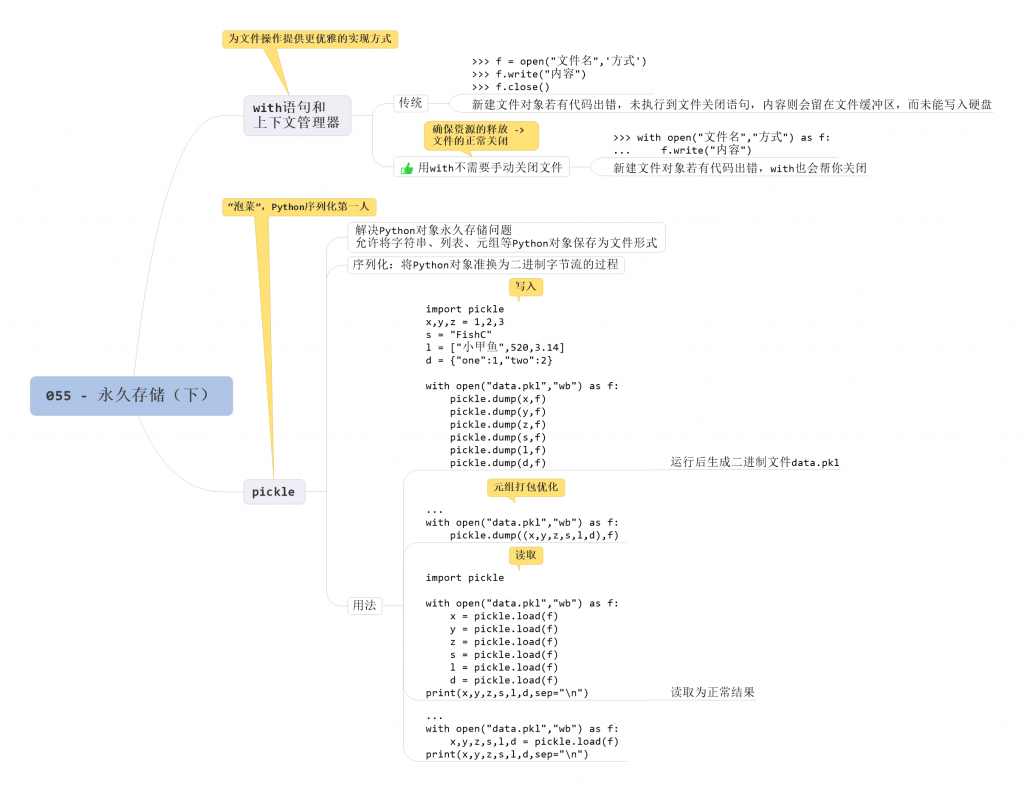
1. with 语句和上下文管理器
上下文管理器为文件操作提供了一种更为优雅的实现方式。
我们先来看一下传统的文件操作实现:
- >>> f = open("FishC.txt", "w")
- >>> f.write("I love FishC.")
- 13
- >>> f.close()
总结下来无非就是三板斧:打开文件 -> 操作文件 -> 关闭文件
那么使用 with 上下文管理器方案,应该如何实现呢?
- >>> with open("FishC.txt", "w") as f:
- ... f.write("I love FishC.")
- ...
- 13
两者是等效的,通俗来讲,对于文件操作这样的三板斧来说,上文就是打开文件,下文就是关闭文件,这个就是上下文管理器做的事情。
使用上下文管理器,最大的优势是能够确保资源的释放(在这里就是文件的正常关闭)。
2. pickle
pickle 模块支持你将 Python 的代码序列化,解决的就是一个永久存储 Python 对象的问题。
说白了,就是将咱们的源代码,转变成 0101001 的二进制组合。
掌握 pickle,只需要学习两个函数的用法:一个是 dump(),另一个是 load()。
使用 dump() 函数将数据写入文件中(文件后缀要求是 .pkl):
- import pickle
- x, y, z = 1, 2, 3
- s = "FishC"
- l = ["小甲鱼", 520, 3.14]
- d = {"one":1, "two":2}
- with open("data.pkl", "wb") as f:
- pickle.dump(x, f)
- pickle.dump(y, f)
- pickle.dump(z, f)
- pickle.dump(s, f)
- pickle.dump(l, f)
- pickle.dump(d, f)
使用 load() 函数读取 pickle 文件中的数据:
- import pickle
- with open("data.pkl", "rb") as f:
- x = pickle.load(f)
- y = pickle.load(f)
- z = pickle.load(f)
- s = pickle.load(f)
- l = pickle.load(f)
- d = pickle.load(f)
- print(x, y, z, s, l, d, sep="\n")
如果觉得反复写很多个 dump() 和 load() 太麻烦了,可以将多个对象打包成元组后再进行序列化:
- ...
- pickle.dump((x, y, z, s, l, d), f)
- ...
- x, y, z, s, l, d = pickle.load(f)
- ...
3. 思维导图
异常(上)
1. 编程时通常会遇到的两类错误
一类是语法错误,就是不按 Python 规定的语法来写代码,这也是初学者最容易犯的错误,比如:
- >>> print(“I love FishC.”)
- SyntaxError: invalid character '“' (U+201C)
另一类错误并非由于语法错误导致的:
- >>> 1 / 0
- Traceback (most recent call last):
- File "<pyshell#3>", line 1, in <module>
- 1 / 0
- ZeroDivisionError: division by zero
这里虽然 Python 的语法没有错,但由于没有过硬的小学数学知识,同样导致了代码无法正确执行,引发了 ZeroDivisionError 这个异常。
2. 异常机制
Python 通过提供异常机制来识别及响应错误。
Python 的异常机制可以分离出程序中的异常处理代码和正常业务代码,使得程序代码更为优雅,并提高了程序的健壮性。
Python 内置异常大合集 -> 传送门(Python 的所有内置异常,全部都在这里了,大家遇到看不懂的异常信息,直接打开这个网页,然后 Ctrl+F,输入异常的名称就可以)
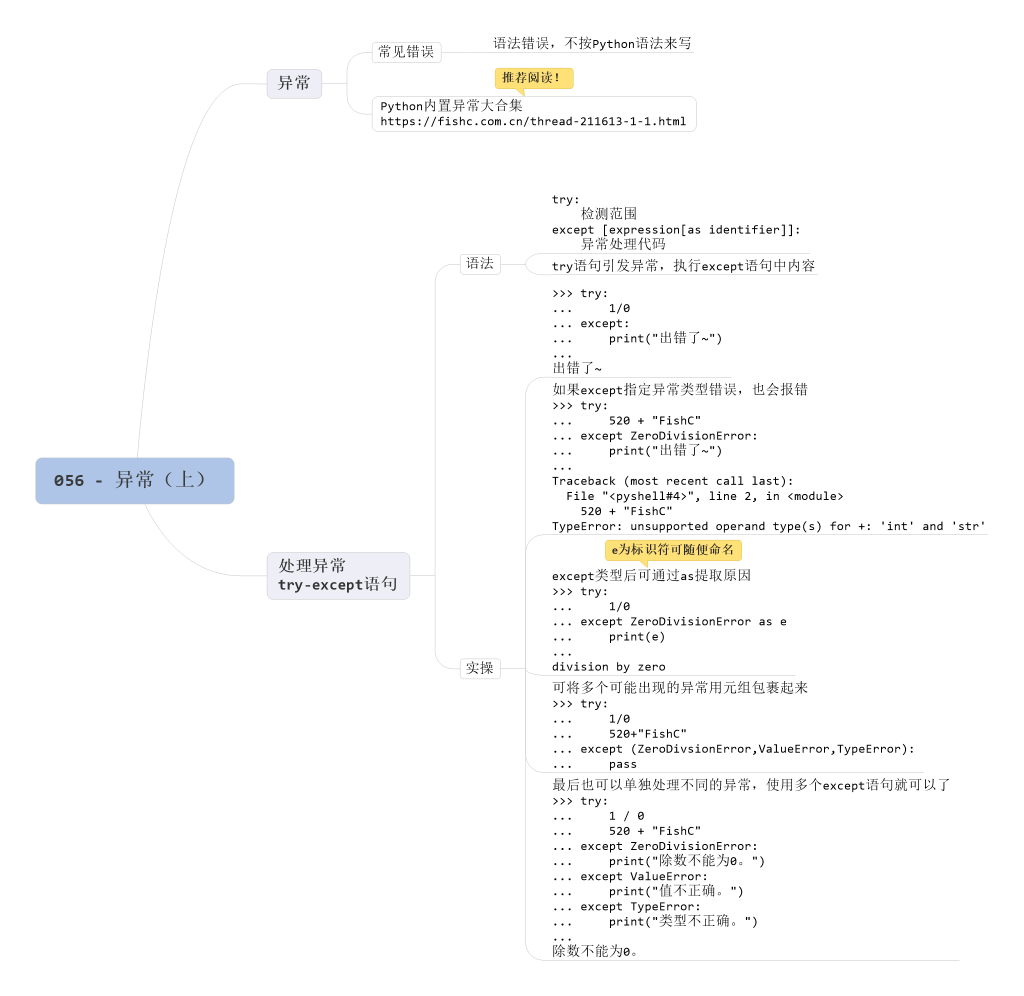
3. 处理异常
利用 try-except 语句来捕获并处理异常语法如下:
- try:
- 检测范围
- except [expression [as identifier]]:
- 异常处理代码
举个例子:
- >>> try:
- ... 1 / 0
- ... except:
- ... print("出错了~")
- ...
- 出错了~
我们可以在 except 后面指定一个异常:
- >>> try:
- ... 1 / 0
- ... except ZeroDivisionError:
- ... print("除数不能为0。")
- ...
- 除数不能为0。
后面还有一个可选的 as,这样的话可以将异常的原因给提取出来:
- >>> try:
- ... 1 / 0
- ... except ZeroDivisionError as e:
- ... print(e)
- ...
- division by zero
其实就是把冒号后面的那部分异常原因给引用出来。
我们还可以将多个可能出现的异常使用元组的形式给包裹起来:
- >>> try:
- ... 1 / 0
- ... 520 + "FishC"
- ... except (ZeroDivisionError, ValueError, TypeError):
- ... pass
- ...
在这个代码中,但凡检测到 try 语句中包含这三个异常中的任意一个,都会执行 pass 语句,直接忽略跳过。
最后也可以单独处理不同的异常,使用多个 except 语句就可以了:
- >>> try:
- ... 1 / 0
- ... 520 + "FishC"
- ... except ZeroDivisionError:
- ... print("除数不能为0。")
- ... except ValueError:
- ... print("值不正确。")
- ... except TypeError:
- ... print("类型不正确。")
- ...
- 除数不能为0。
4. 思维导图
异常(下)
1. 处理异常
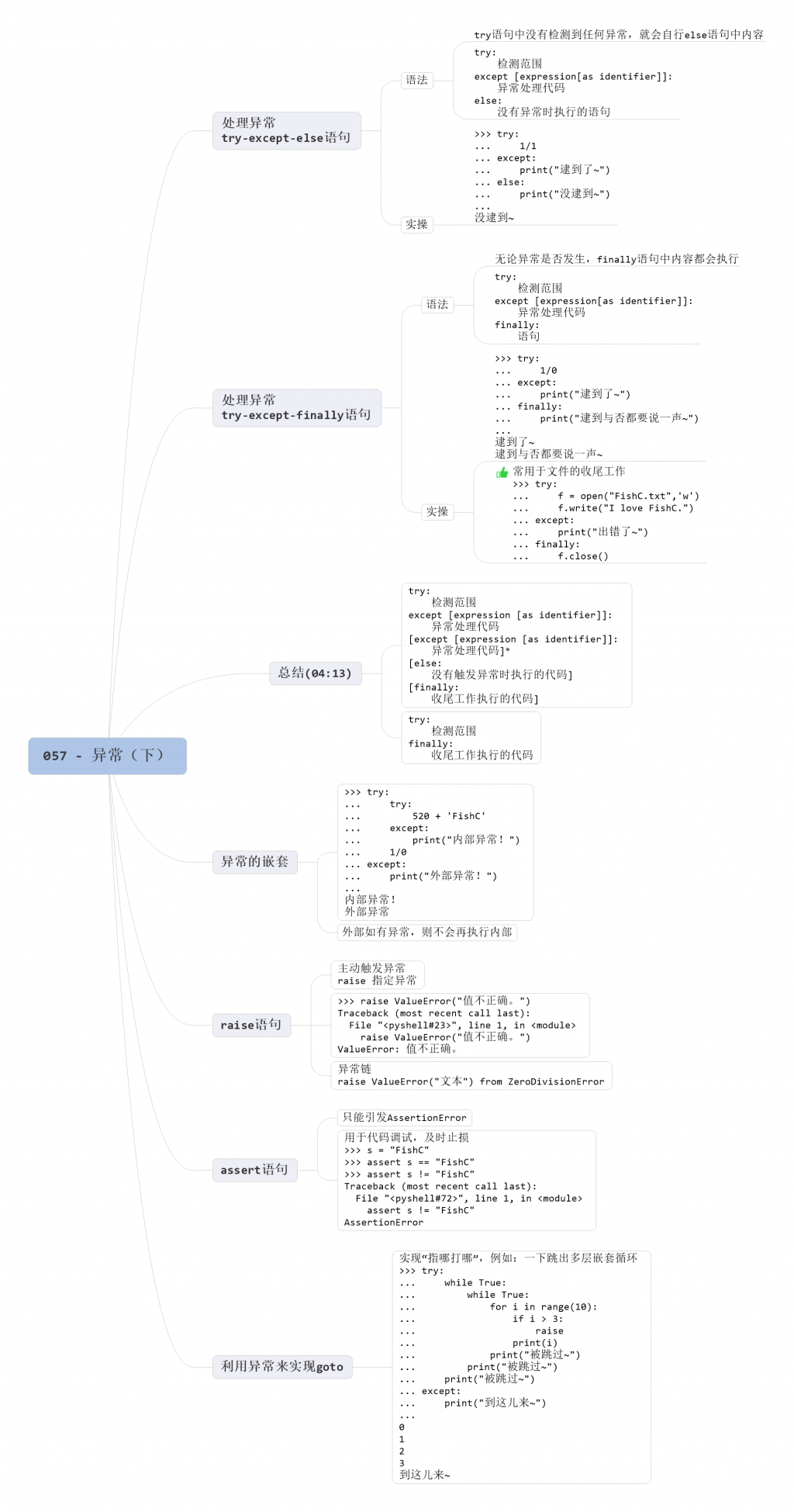
try-except-else
try-except 还可以跟 else 进行搭配,它的含义就是当 try 语句没有检测到任何异常的情况下,就执行 else 语句的内容:
- >>> try:
- ... 1 / 0
- ... except:
- ... print("逮到了~")
- ... else:
- ... print("没逮到~")
- ...
- 逮到了~
如果在 try 语句中检测到异常,那么就执行 except 语句的异常处理内容:
- >>> try:
- ... 1 / 1
- ... except:
- ... print("逮到了~")
- ... else:
- ... print("没逮到~")
- ...
- 1.0
- 没逮到~
try-except-finally
跟 try-except 语句搭配的还有一个 finally,就是说无论异常发生与否,都必须要执行的语句:
- >>> try:
- ... 1 / 0
- ... except:
- ... print("逮到了~")
- ... else:
- ... print("没逮到~")
- ... finally:
- ... print("逮没逮到都会咯吱一声~")
- ...
- 逮到了~
- 逮没逮到都会咯吱一声~
- >>> try:
- ... 1 / 1
- ... except:
- ... print("逮到了~")
- ... else:
- ... print("没逮到~")
- ... finally:
- ... print("逮没逮到都会咯吱一声~")
- ...
- 1.0
- 没逮到~
- 逮没逮到都会咯吱一声~
finally 通常是用于执行那些收尾工作,比如关闭文件的操作:
- >>> try:
- ... f = open("FishC.txt", "w")
- ... f.write("I love FishC.")
- ... except:
- ... print("出错了~")
- ... finally:
- ... f.close()
这样的话,无论 try 语句中是否存在异常,文件都能够正常被关闭。
现在我们的异常处理语法变成了这样:
- try:
- 检测范围
- except [expression [as identifier]]:
- 异常处理代码
- [except [expression [as identifier]]:
- 异常处理代码]*
- [else:
- 没有触发异常时执行的代码]
- [finally:
- 收尾工作执行的代码]
或者:
- try:
- 检测范围
- finally:
- 收尾工作执行的代码
3. 异常的嵌套
异常也是可以被嵌套的:
- >>> try:
- ... try:
- ... 520 + "FishC"
- ... except:
- ... print("内部异常!")
- ... 1 / 0
- ... except:
- ... print("外部异常!")
- ... finally:
- ... print("收尾工作~")
- ...
- 内部异常!
- 外部异常!
- 收尾工作~
4. raise 语句
使用 raise 语句,我们可以手动的引发异常:
- >>> raise ValueError("值不正确。")
- Traceback (most recent call last):
- File "<pyshell#23>", line 1, in <module>
- raise ValueError("值不正确。")
- ValueError: 值不正确。
注意,你不能够 raise 一个并不存在的异常哈:
- >>> raise FishCError("小甲鱼说你不行你就不行~")
- Traceback (most recent call last):
- File "<pyshell#31>", line 1, in <module>
- raise FishCError("小甲鱼说你不行你就不行~")
- NameError: name 'FishCError' is not defined
由于这个 FishCError 未定义,所以是小甲鱼不行,不是你不行~
还有一种叫异常链,在 raise 后面加个 from:
- >>> raise ValueError("这样可不行~") from ZeroDivisionError
- ZeroDivisionError
- The above exception was the direct cause of the following exception:
- Traceback (most recent call last):
- File "<pyshell#37>", line 1, in <module>
- raise ValueError("这样可不行~") from ZeroDivisionError
- ValueError: 这样可不行~
5. assert 语句
assert 语句跟 raise 类似,都是主动引发异常,不过 assert 语句只能引发一个叫 AssertionError 的异常。
这个语句的存在意义,通常是用于代码调试:
- >>> s = "FishC"
- >>> assert s == "FishC" # 得到期待的结果,通过
- >>> assert s != "FishC" # 没有得到期待的结果,引发异常
- Traceback (most recent call last):
- File "<pyshell#72>", line 1, in <module>
- assert s != "FishC"
- AssertionError
6. 利用异常来实现 goto
有学过 C 语言的同学应该听到过一个叫做 goto 的语句,虽然用的不多,但有时候,有这么一个可以指哪跳哪的功能,可以说是非常方便,比如说要在多个嵌套循环语句里面一把跳出来,就非常方便了……可惜 Python 没有!
没错,通过异常,我们完全可以实现:
- >>> try:
- ... while True:
- ... while True:
- ... for i in range(10):
- ... if i > 3:
- ... raise
- ... print(i)
- ... print("被跳过~")
- ... print("被跳过~")
- ... print("被跳过~")
- ... except:
- ... print("到这儿来~")
- ...
- 0
- 1
- 2
- 3
- 到这儿来~
7. 思维导图

















 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









