







笔记内容
复杂度学习率
激活函数
损失函数
缓解过拟合
优化器
1复杂度学习率
指数衰减学习率,为得到最优效果学习率,一般写在for循环中,按迭代轮数衰减。
import tensorflow as tf
w = tf.Variable(tf.constant(5, dtype=tf.float32))
#tf.variable()定义了一个可被优化的变量
#tf.constant()定义了一个初始值为5,数据类型为float.32的常量张量
epoch = 40
LR_BASE = 0.2 # 最初学习率
LR_DECAY = 0.99 # 学习率衰减率
LR_STEP = 1 # 喂入多少轮BATCH_SIZE后,更新一次学习率
for epoch in range(epoch): # for epoch 定义顶层循环,表示对数据集循环epoch次,此例数据集数据仅有1个w,初始化时候constant赋值为5,循环100次迭代。
lr = LR_BASE * LR_DECAY ** (epoch / LR_STEP)
with tf.GradientTape() as tape: # with结构到grads框起了梯度的计算过程。
loss = tf.square(w + 1)
grads = tape.gradient(loss, w) # .gradient函数告知谁对谁求导
w.assign_sub(lr * grads) # .assign_sub 对变量做自减 即:w -= lr*grads 即 w = w - lr*grads
print("After %s epoch,w is %f,loss is %f,lr is %f" % (epoch, w.numpy(), loss, lr))2激活函数
sigmoid函数
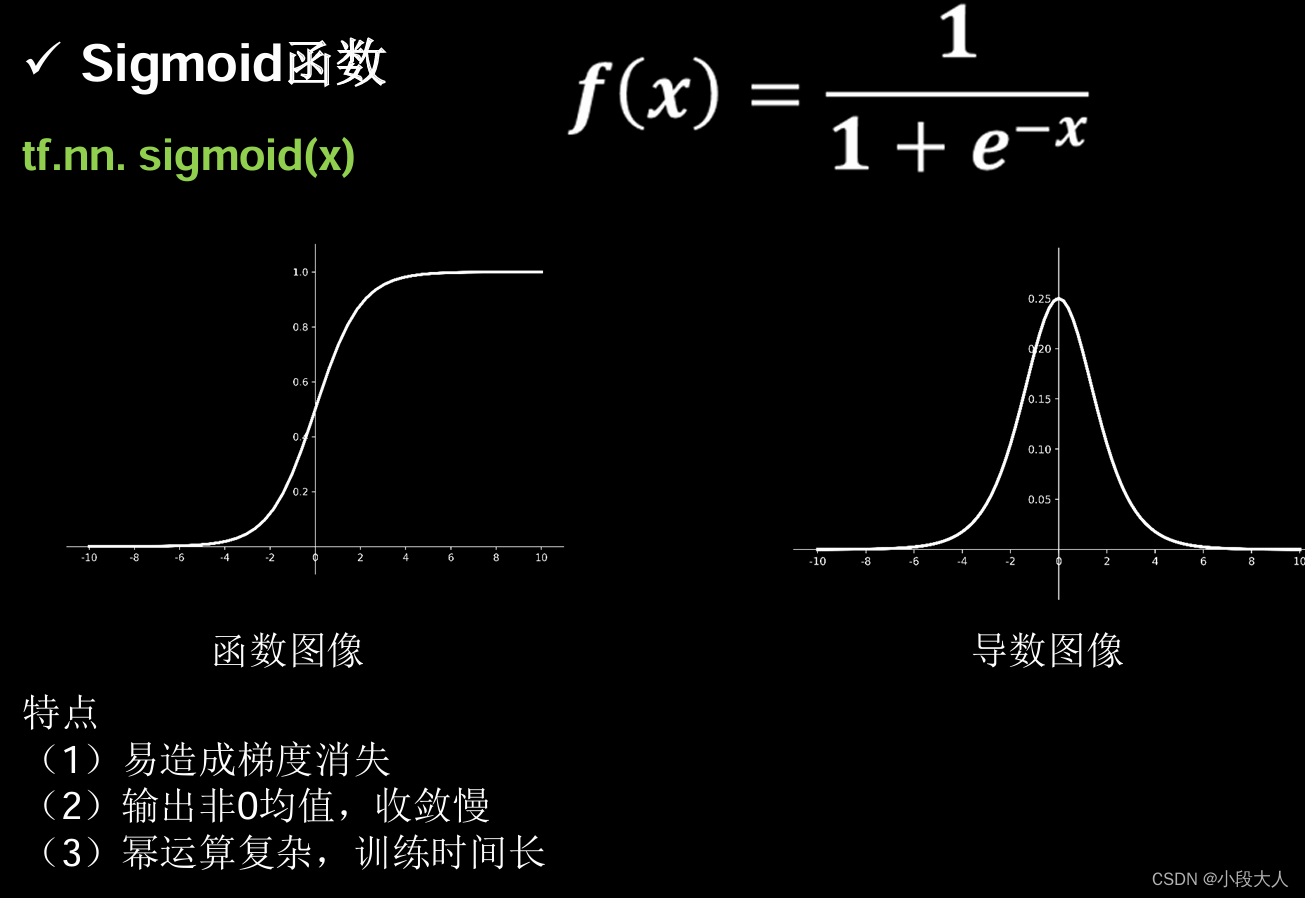
tanh函数

relu函数
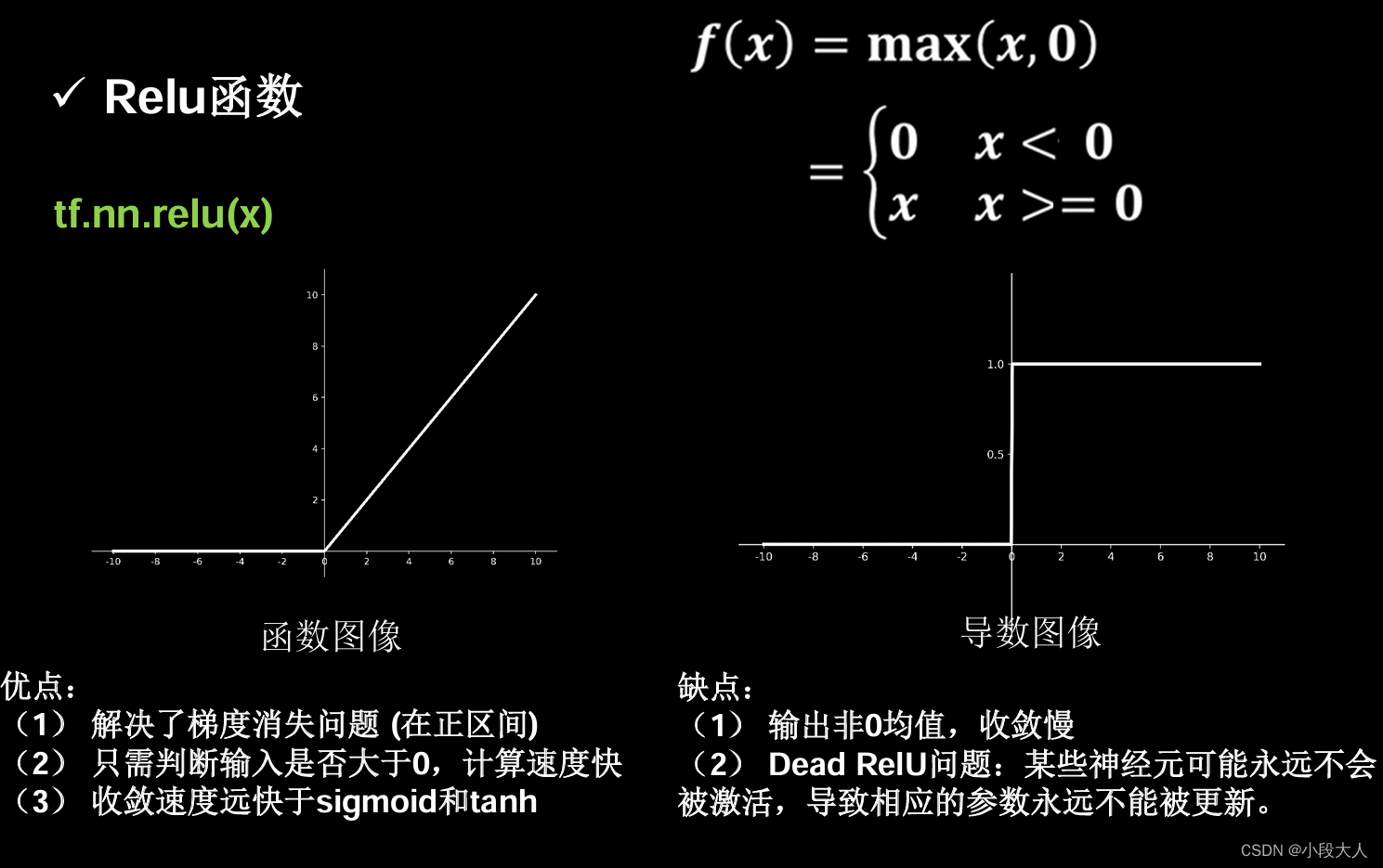
过多负数特征会导致神经元死亡
leaky relu函数
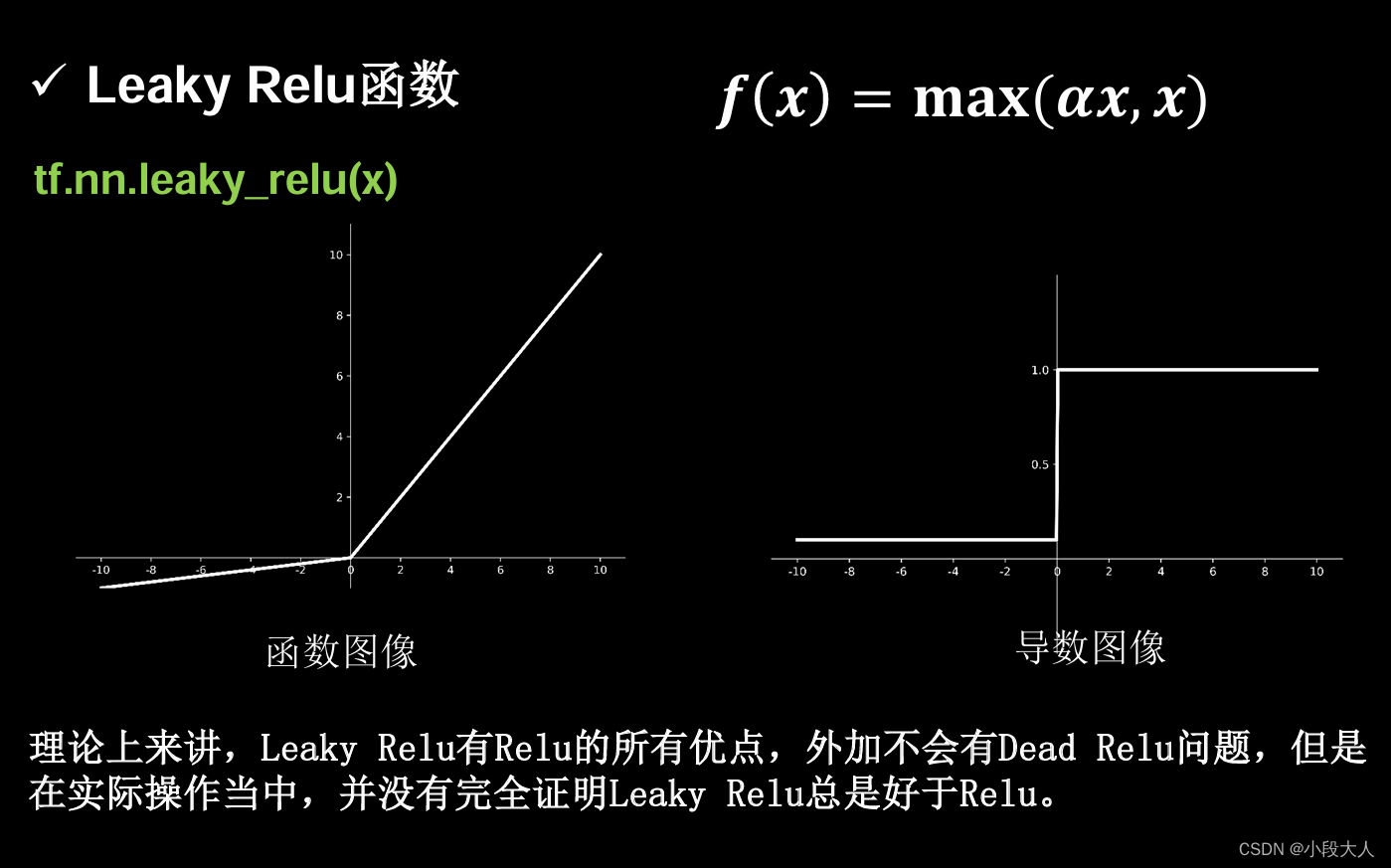
初学者建议

3损失函数
前向传播 预测值y 与标准答案 y_之间的差距loss
用mse计算,也可以根据实际情况修正
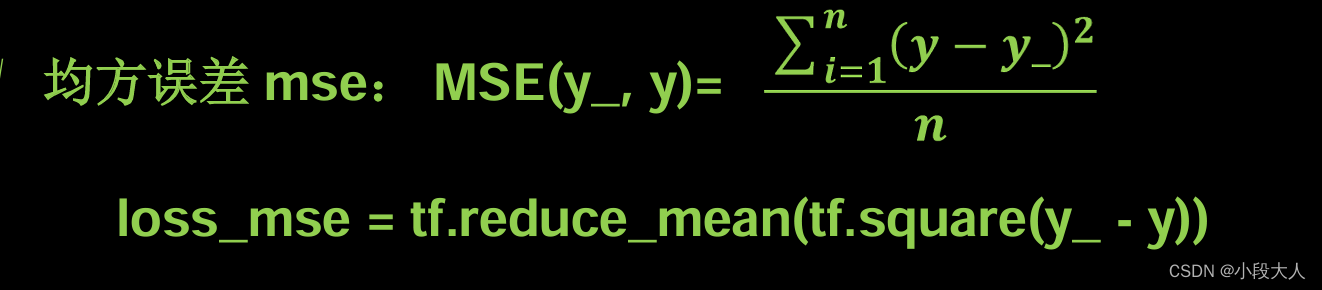
这是我敲的,可能有错
# 已知 y_= x1 +x2 + 扰动
import tensorflow as tf
import numpy as np
SEED = 1
rdm = np.random.RandomState()
x = rdm.rand(32,2)
y_ = [x1 + x2 + (rdm.rand()/10 - 0.05) for x1,x2 in x]
x = tf.cast(x,dtype=tf.float32)
w1 = tf.Variable(tf.random.normal([2,1],stddev=1,seed=1))
epoch = 15000
lr = 0.005
for epoch in range(epoch):
with tf.GradientTape() as tape:
y = tf.matmul(x,w1)
loss_mse = tf.reduce_mean(tf.square(y_-y))
grads = tape.gradient(loss_mse,w1)
w1.assign_sub(lr*grads)
if epoch%500 == 0:
print("after %d training steps,w1 is "% (epoch))
print(w1.numpy())
print("final w1 is :",w1.numpy())
运行了老师的代码,得到的结果和他不一样,分析了一下,无果,结果是这样的
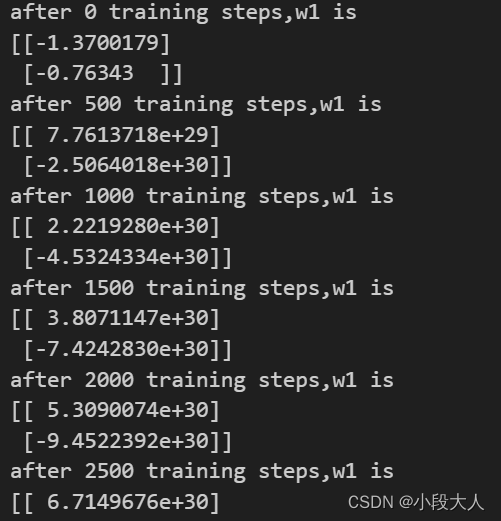
留个坑
修正loss,用tf.where
#分别定义成本和利润的数值,当预测值(进货)大于真实值(卖货),损失的是成本,反之,损失的是利润。
cost = 1
profit = 99
#只需要修改loss函数
loss_mse = tf.reduce_mean(tf.square(tf.where(tf.square(y,y_),cost*(y-y_),profit*(y_-y))))














 477
477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









