
# 导入模块
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB
from sklearn.decomposition import TruncatedSVD
# 获取数据
data = pd.read_csv('IMDB Dataset.csv')
# 数据处理 去除缺失值
x = data['review']
y = data['sentiment']
# 特征工程
transfer = CountVectorizer()
x = transfer.fit_transform(x)
y = data['sentiment'].map({'positive': 1, 'negative': 0})
# 数据集的划分
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=22)
svd = TruncatedSVD(n_components=100) # 保留100个主成分
x_train_gb = svd.fit_transform(x_train)
x_test_gb = svd.fit_transform(x_test)
# 创建模型---比较不同朴素贝叶斯变体(高斯、多项式、伯努利)的性能
# 高斯
gb = GaussianNB()
mb = MultinomialNB(alpha=1)
bb = BernoulliNB()
# 模型训练
gb.fit(x_train_gb, y_train)
mb.fit(x_train, y_train)
bb.fit(x_train, y_train)
# 预测
y_pred_gb = gb.predict(x_test_gb)
y_pred_mb = mb.predict(x_test)
y_pred_bb = bb.predict(x_test)
# 评估
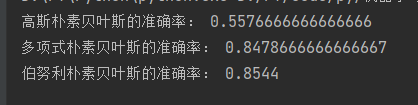
print('高斯朴素贝叶斯的准确率:', gb.score(x_test_gb, y_test))
print('多项式朴素贝叶斯的准确率:', mb.score(x_test, y_test))
print('伯努利朴素贝叶斯的准确率:', bb.score(x_test, y_test))
# 可视化
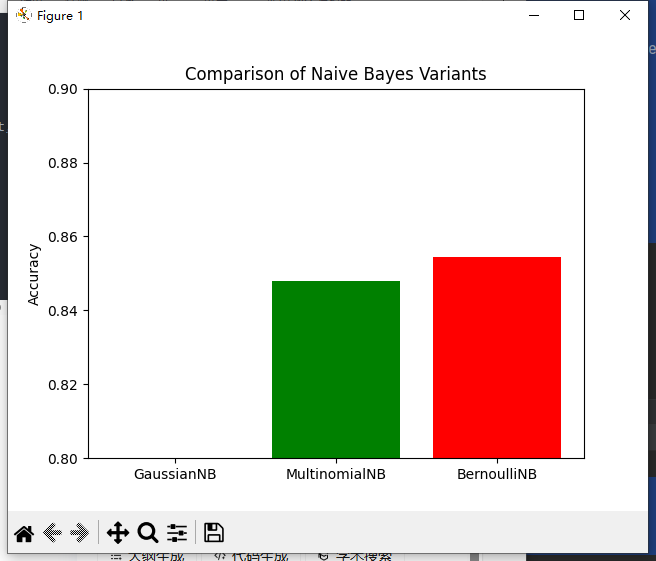
models = ['GaussianNB', 'MultinomialNB', 'BernoulliNB']
scores = [gb.score(x_test_gb, y_test), mb.score(x_test, y_test), bb.score(x_test, y_test)]
plt.bar(models, scores, color=['blue', 'green', 'red'])
plt.ylabel('Accuracy')
plt.title('Comparison of Naive Bayes Variants')
plt.ylim(0.8, 0.90)
plt.yticks(np.arange(0.8, 0.92, 0.02))
plt.show()
























 6152
6152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









