






一、机器学习概述
1.什么是机器学习
机器学习是一个计算机程序,针对某个特定的任务,从经验中学习,并且越做越好。
针对机器学习最重要的内容:
- 数据:经验最终要转换为计算机能理解的数据,这样计算机才能从经验中学习。
- 模型:即算法。有了数据之后,可以设计一个模型,让数据作为输入来训练这个模型。经过训练的模型,最终就成了机器学习的核心,使得模型成为了能产生决策的中枢。
2.监督学习与无监督学习
(1)监督学习
监督学习(Supervised learning)通过大量已知的输入和输出相配对的数据,让计算机从中学习出规律,从而能针对一个新的输入做出合理的输出预测。
- 房价预测(回归问题)
如下图所示是房价预测的例子。正是监督学习的例子。
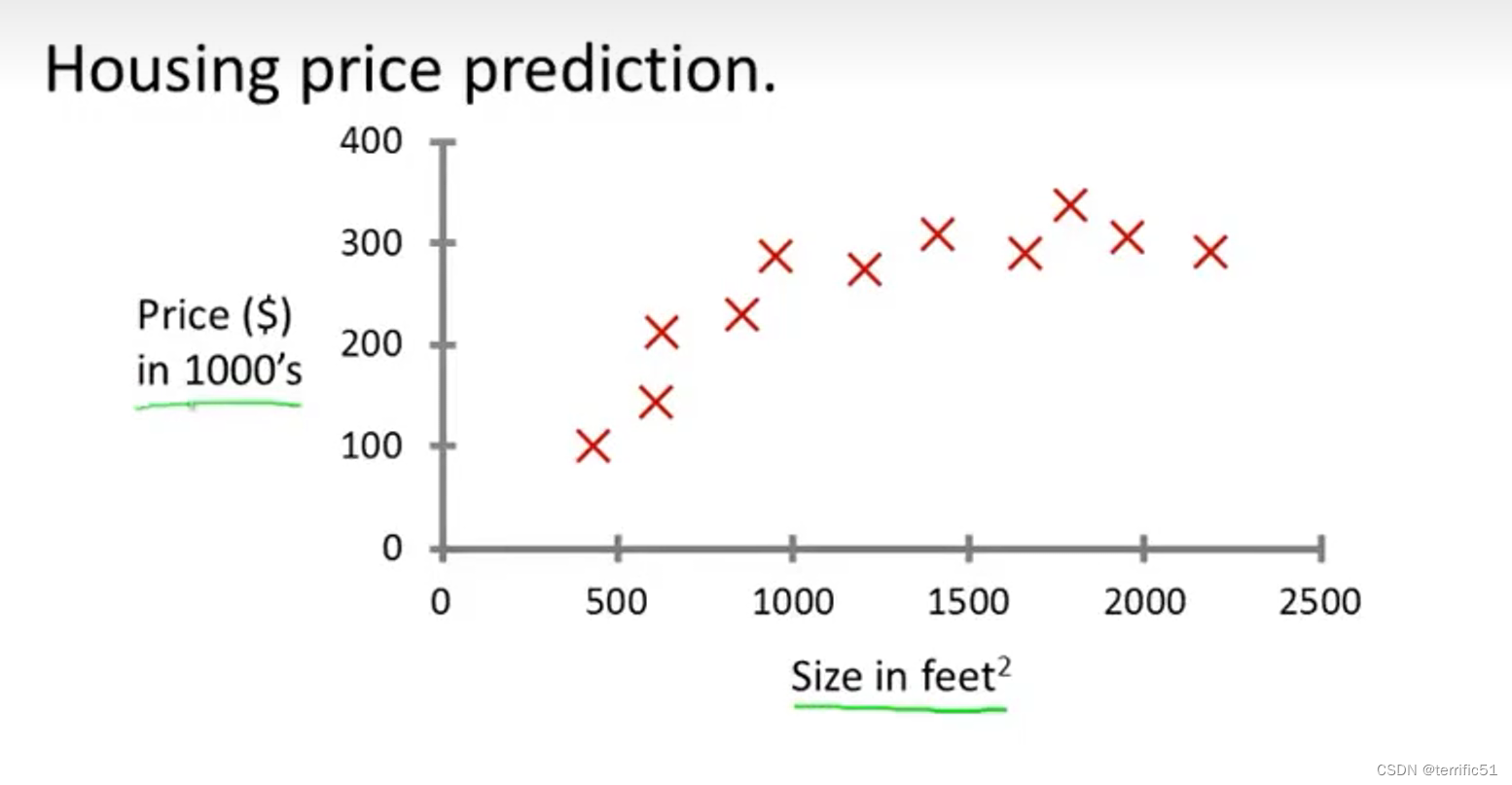
正如这个房价预测例子,监督学习即给算法提供一个数据集(其中包含正确答案),也就是说我们给它一个房价数据集,在这个数据集中的每个样本都对应有一个正确答案(即这个房子的实际卖价)。算法的目的则是给出更多的正确答案。
房价预测是一个回归问题(regression),因为房价是一个实数、连续值。
- 恶/良性癌症(分类问题)
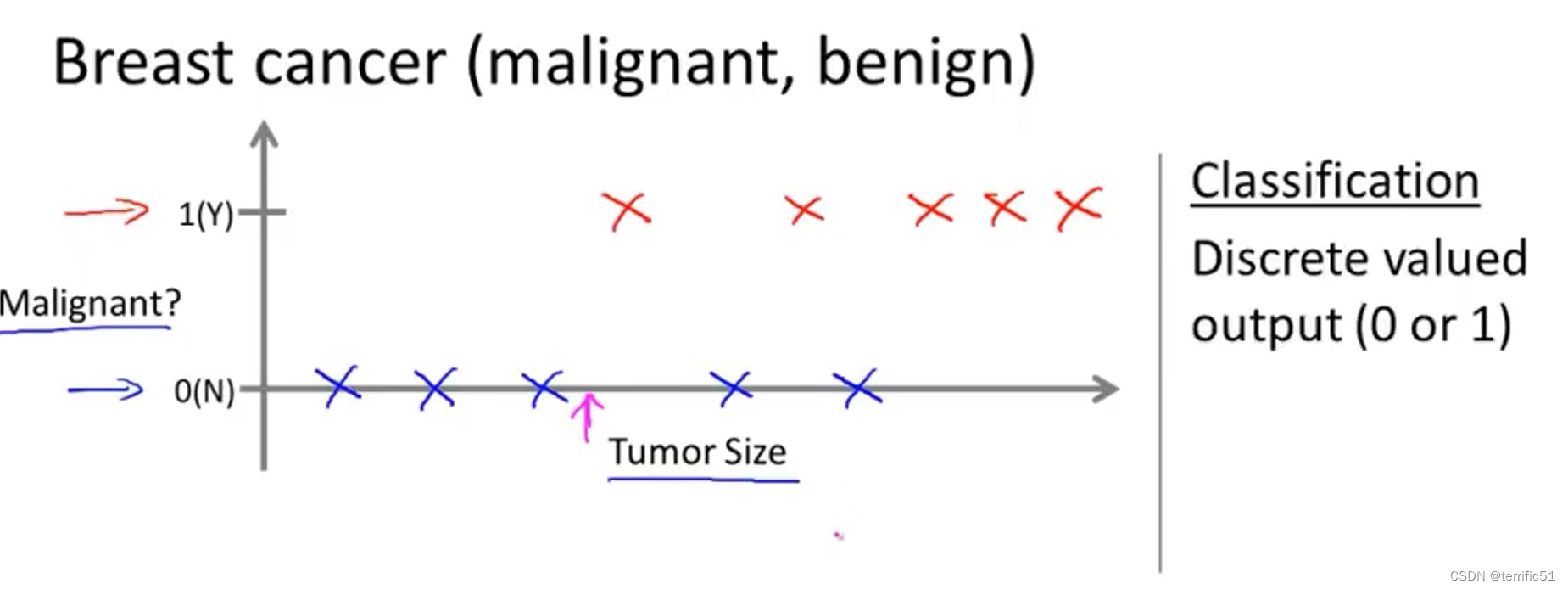
恶/良性癌症(即0/1)是一个分类问题,因为恶/良性(即0/1)是离散值。
(2)无监督学习
无监督学习(Unsupervised learning)通过学习大量的无标记的数据,去分析出数据本身的内在特点和结构。
无监督学习需要让算法自己从数据中发现一切。其中一个常见的算法为聚类算法:使用算法将新闻故事聚合在一起、市场细分等。
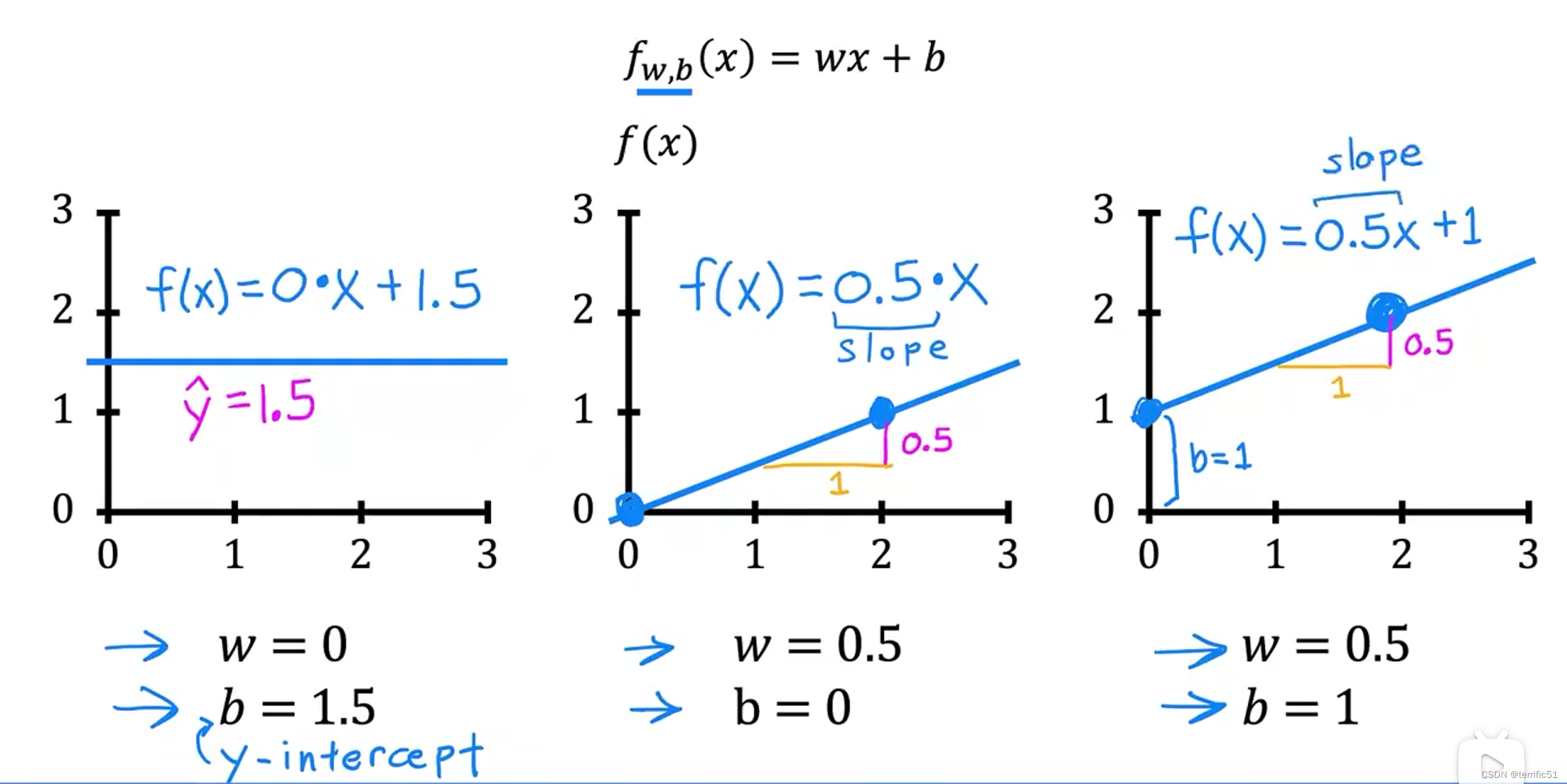
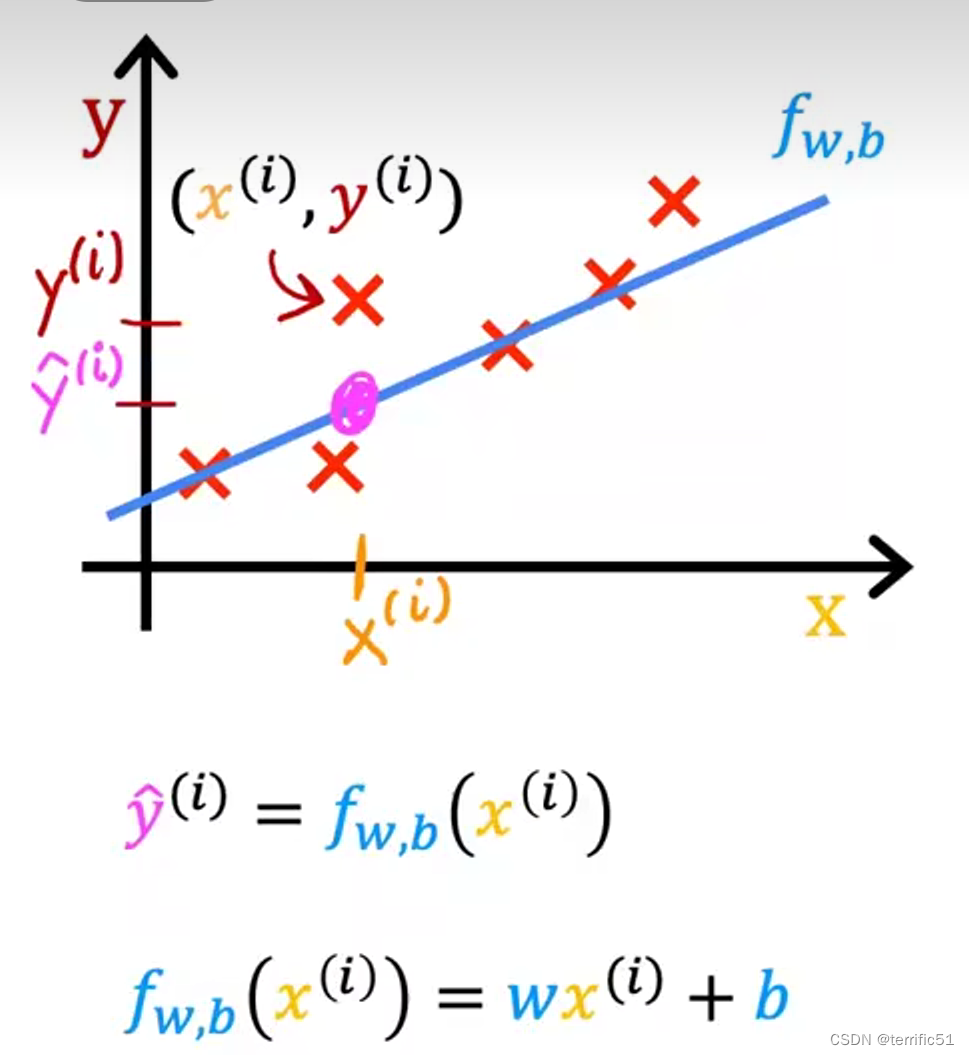
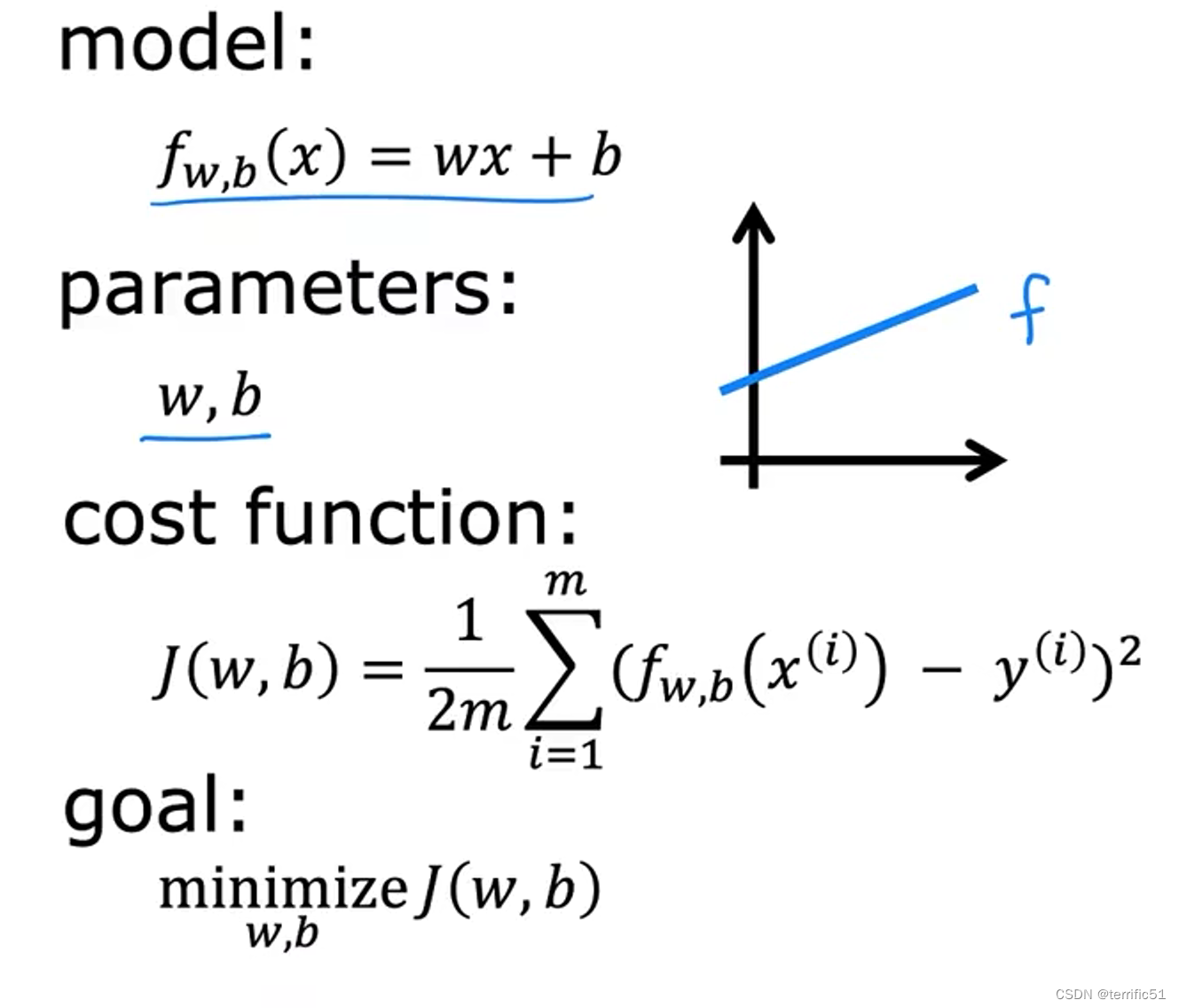
3.模型描述
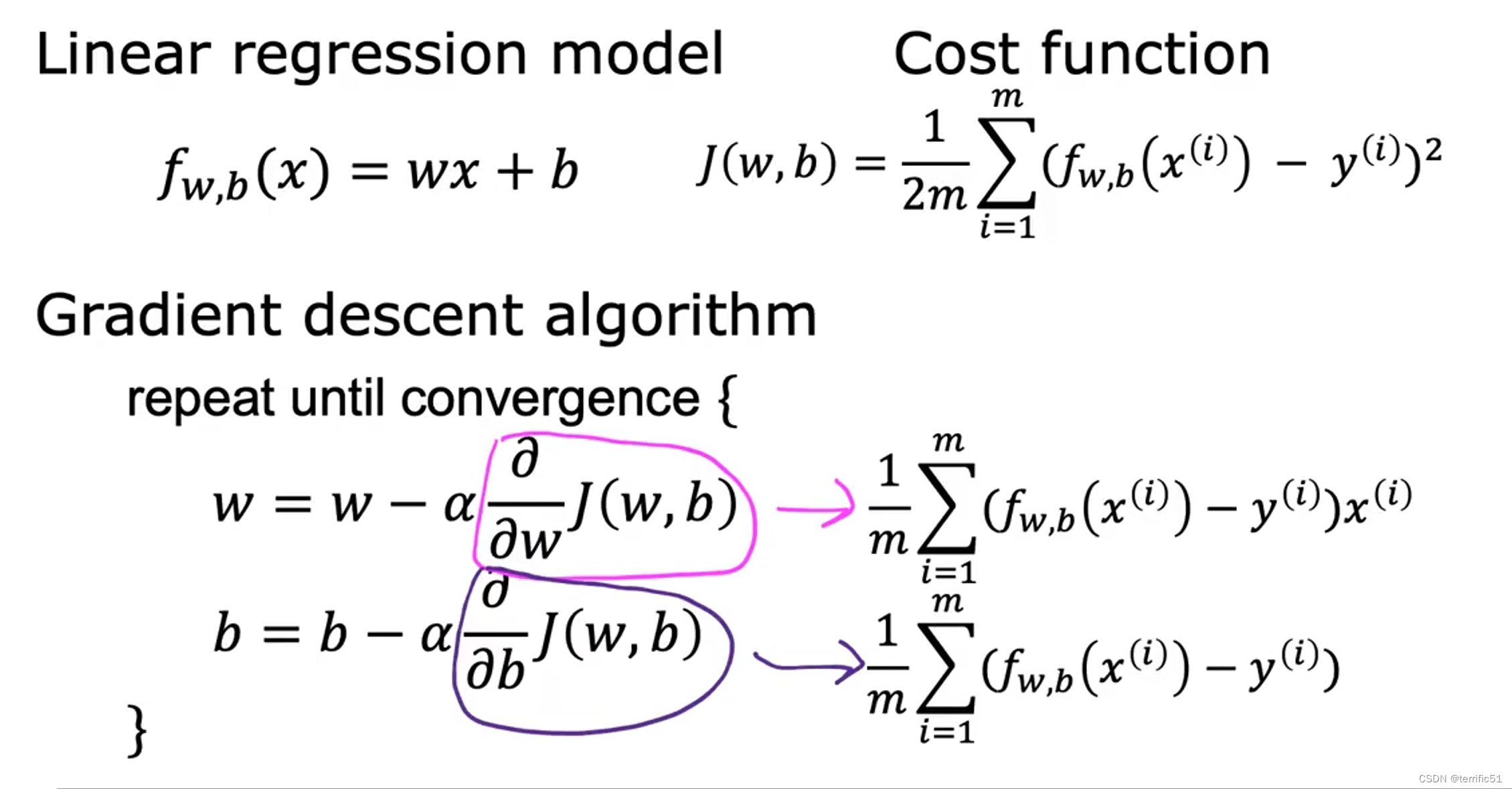
线性回归模型
代价函数
平方误差代价函数

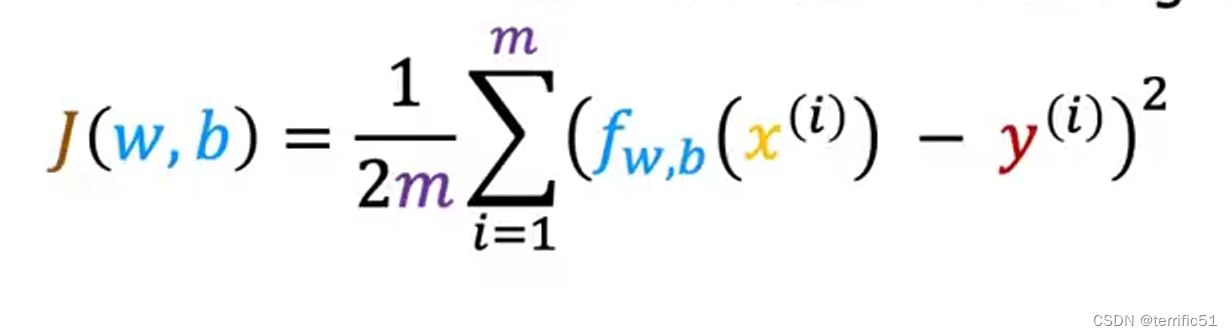
模型、参数、代价函数、目标(找到w、b的一个值使J(w,b)最小化)
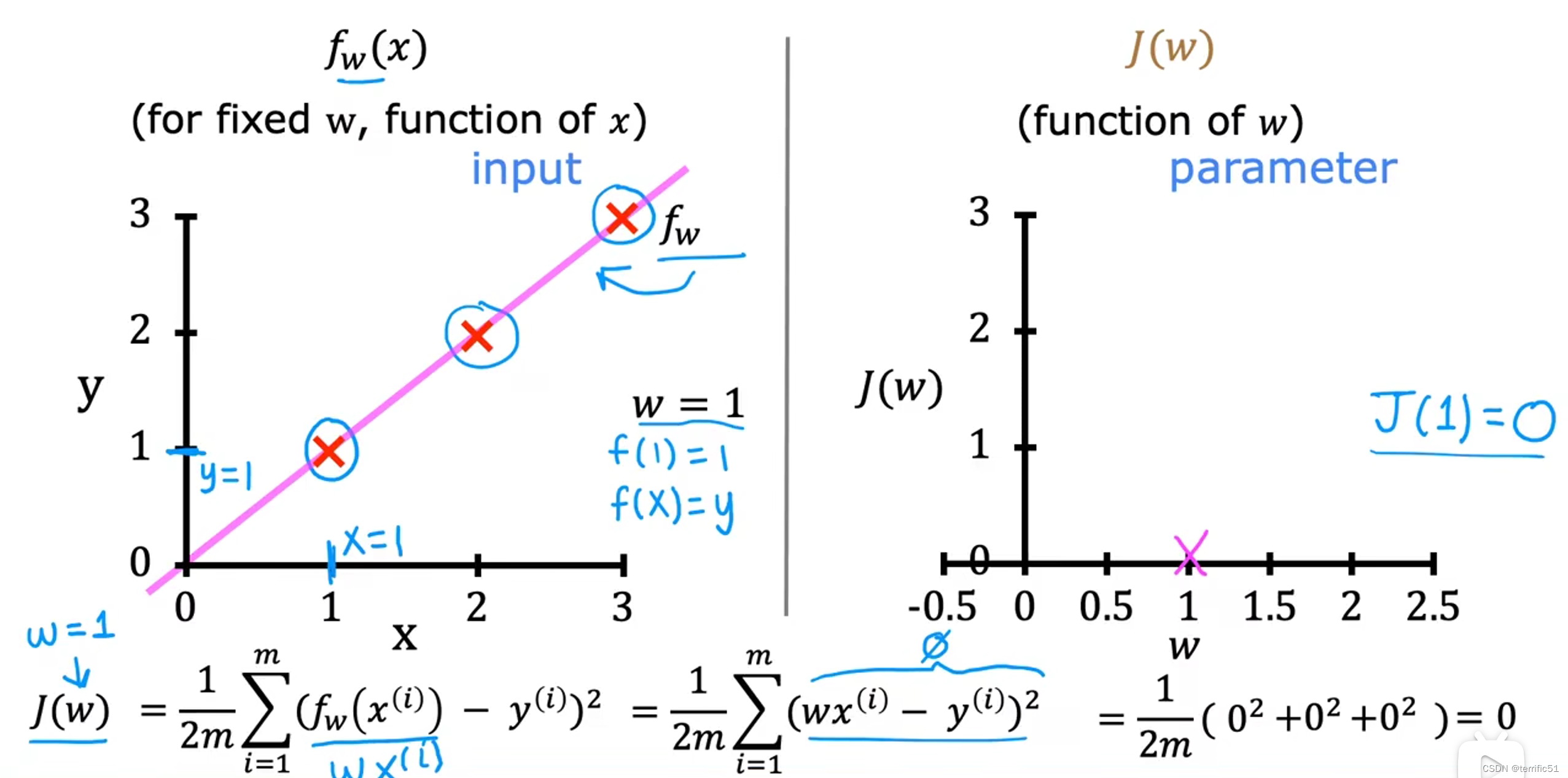
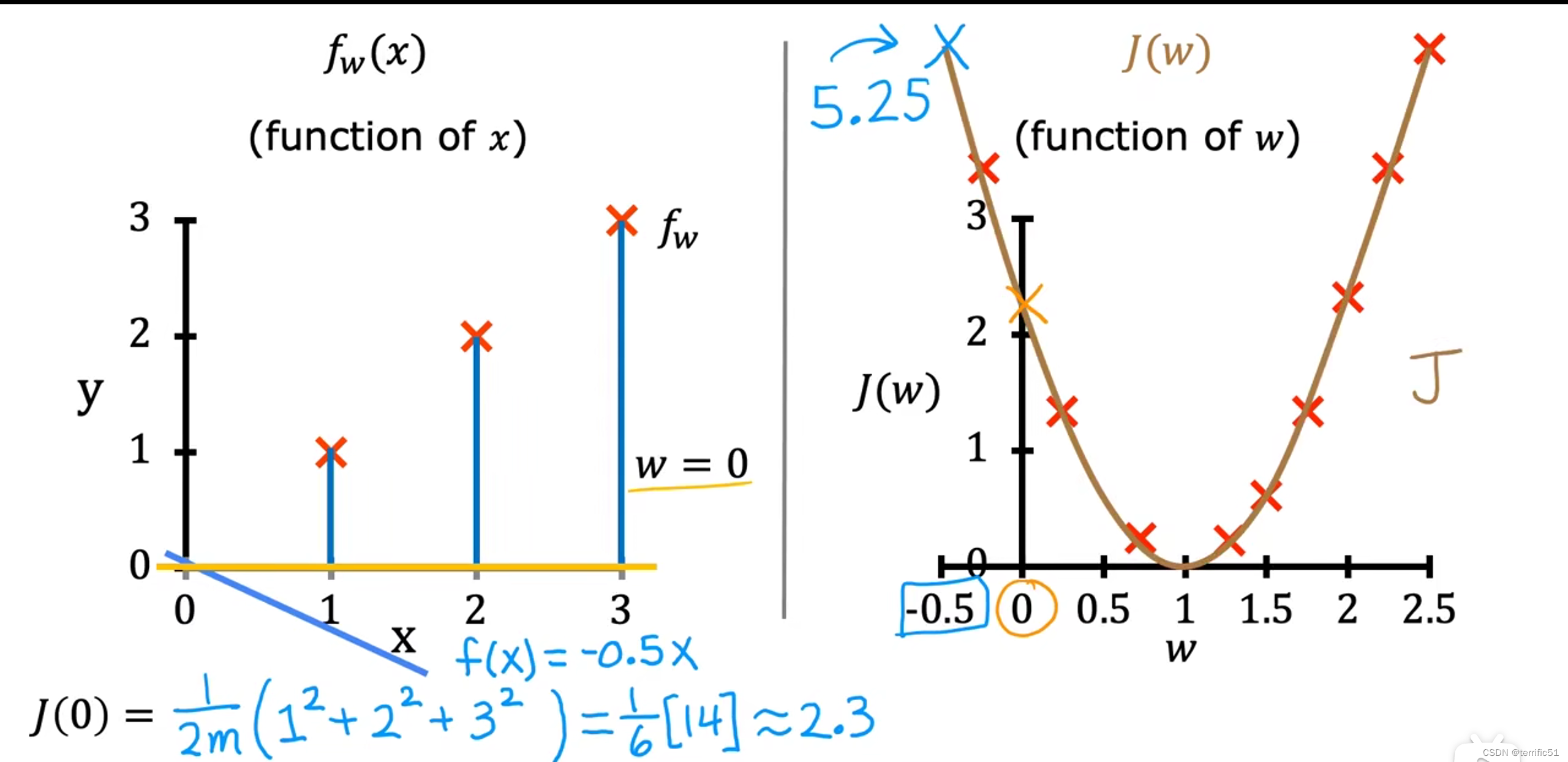
当b=0时
通过简化模型,我们的目标是找到w的一个值使J(w)最小化
当w=1时,计算出J(w)=0:
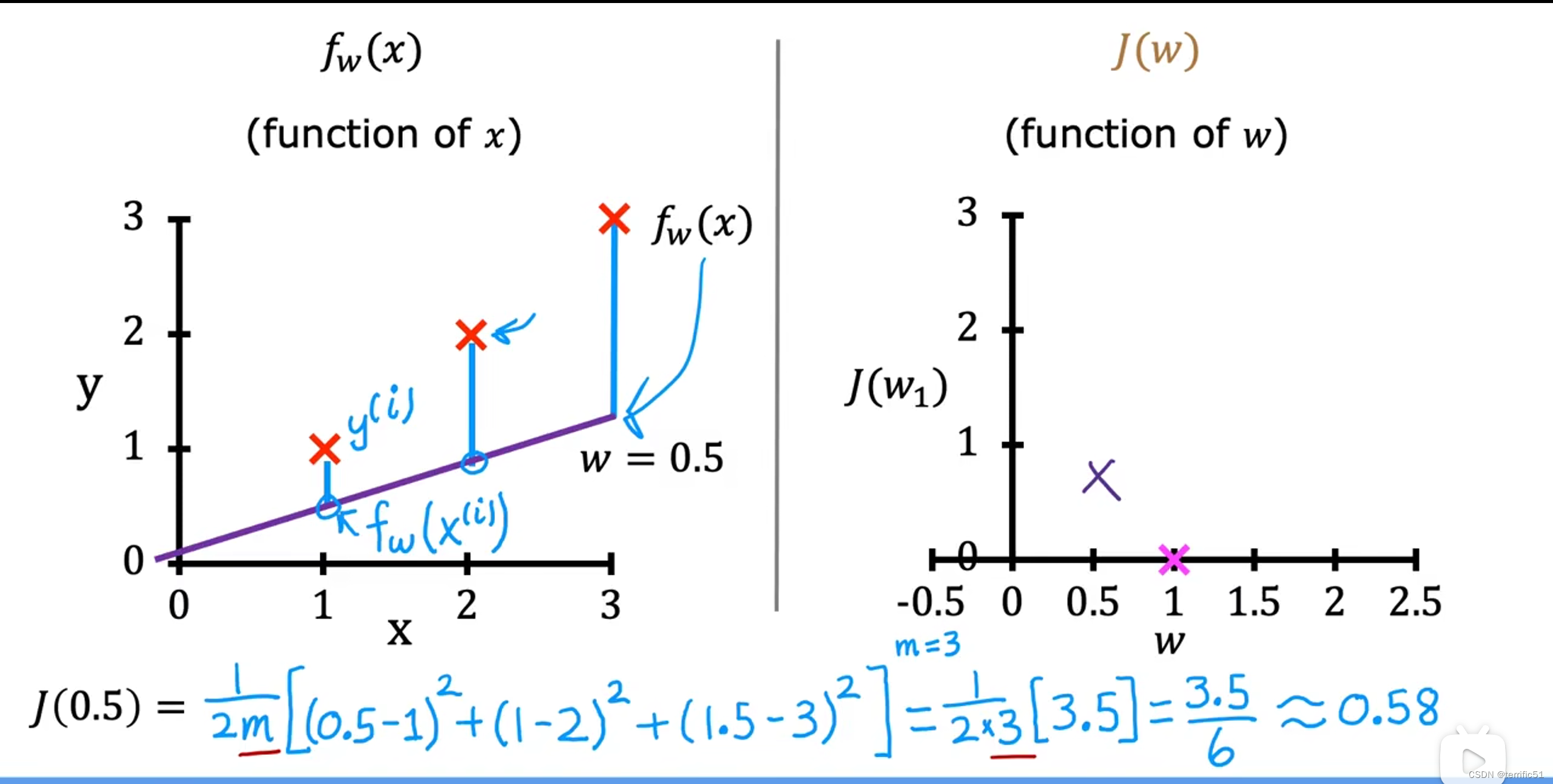
 当w=0.5时,计算出J(w)=0.58:
当w=0.5时,计算出J(w)=0.58:
取w的不同值,计算出J(w),画出如图示图形:
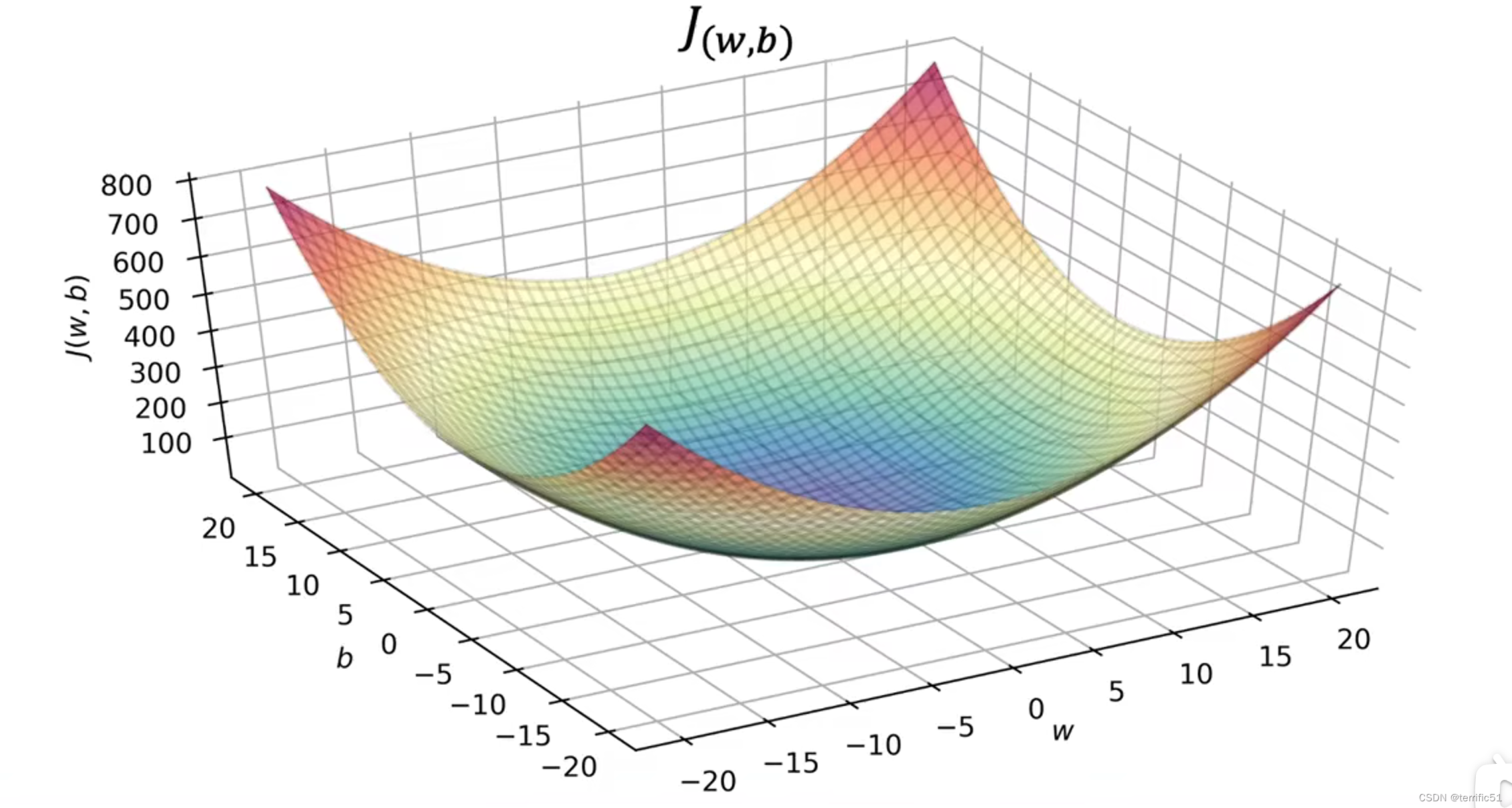
当b!=0时
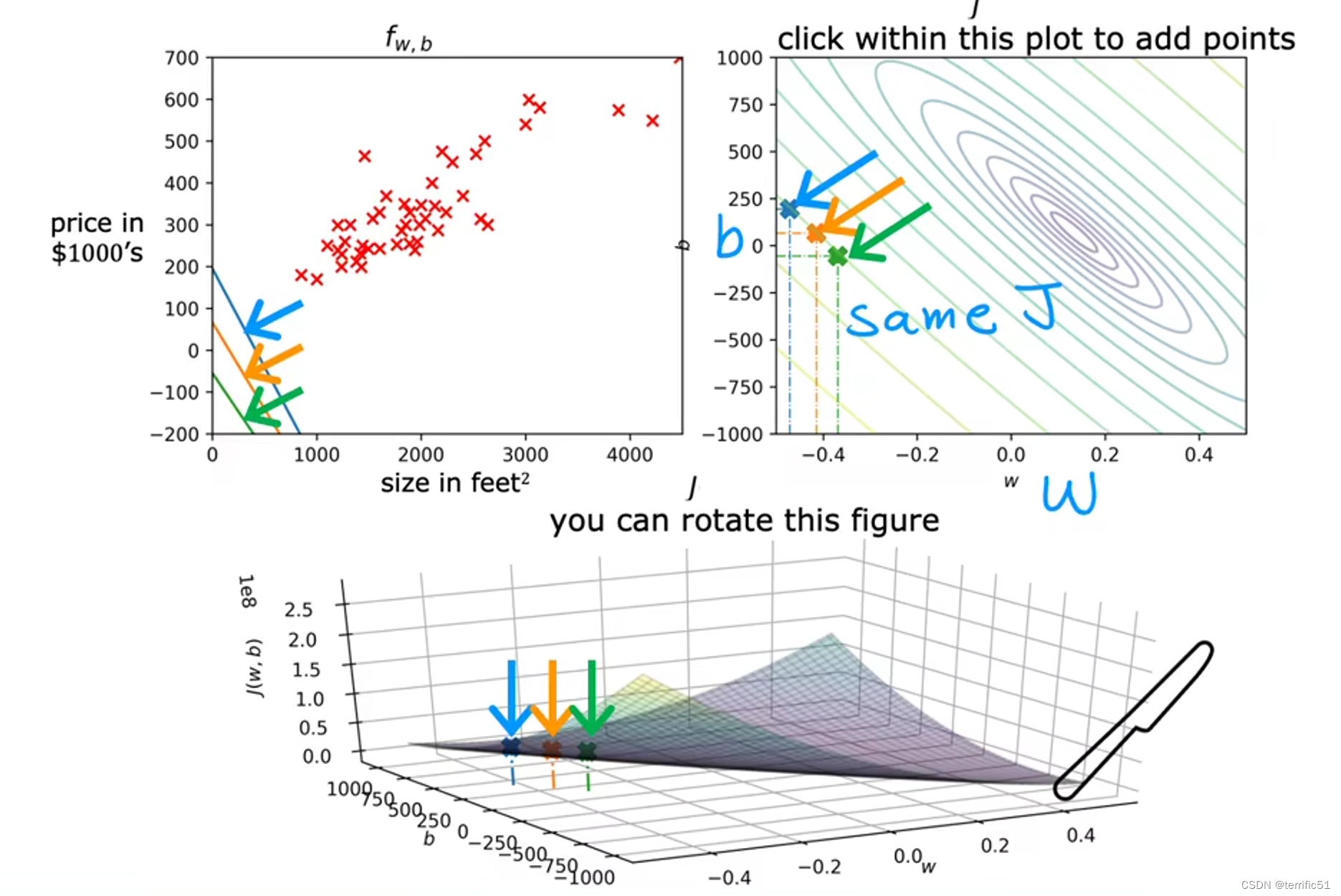
房价预测
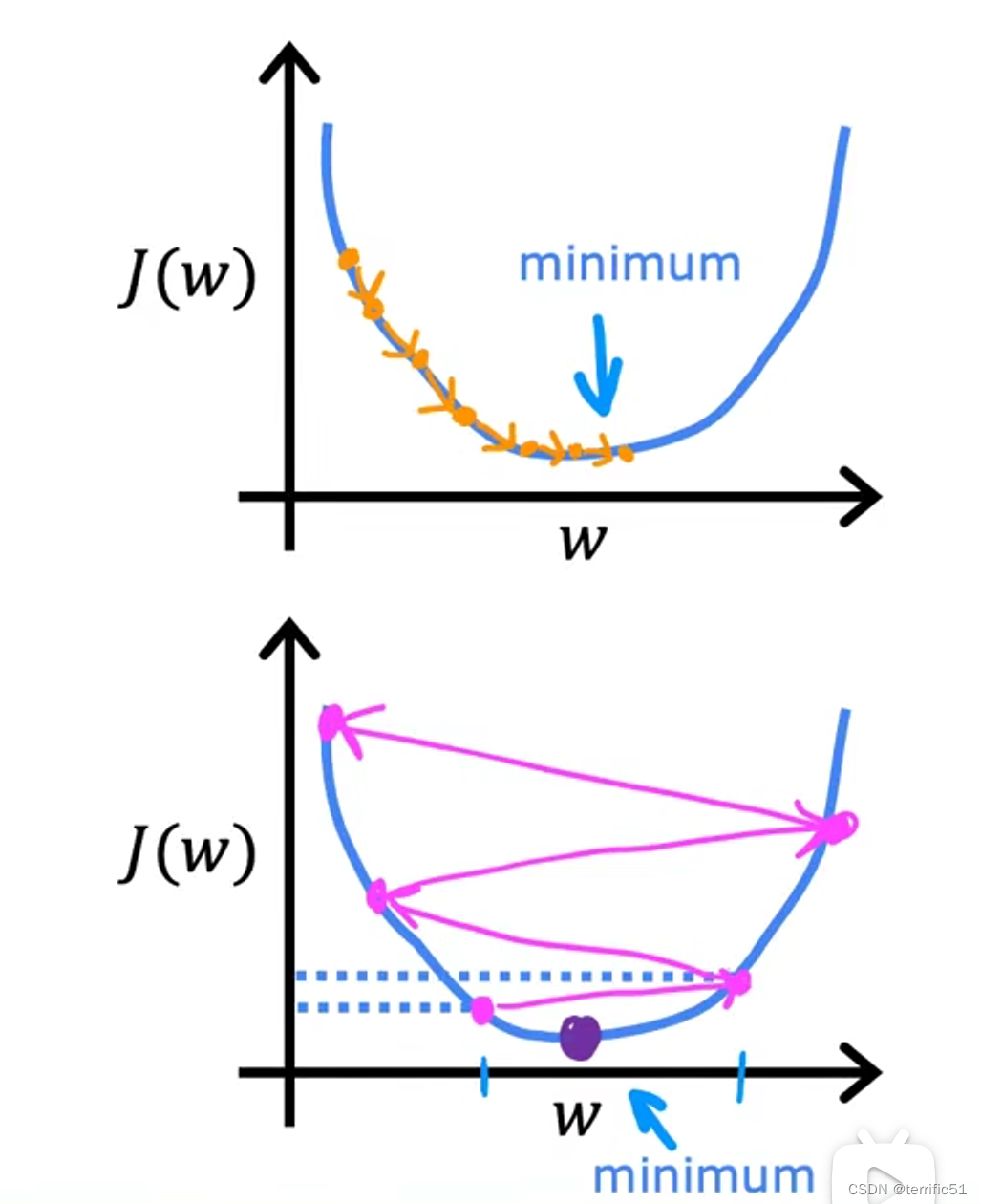
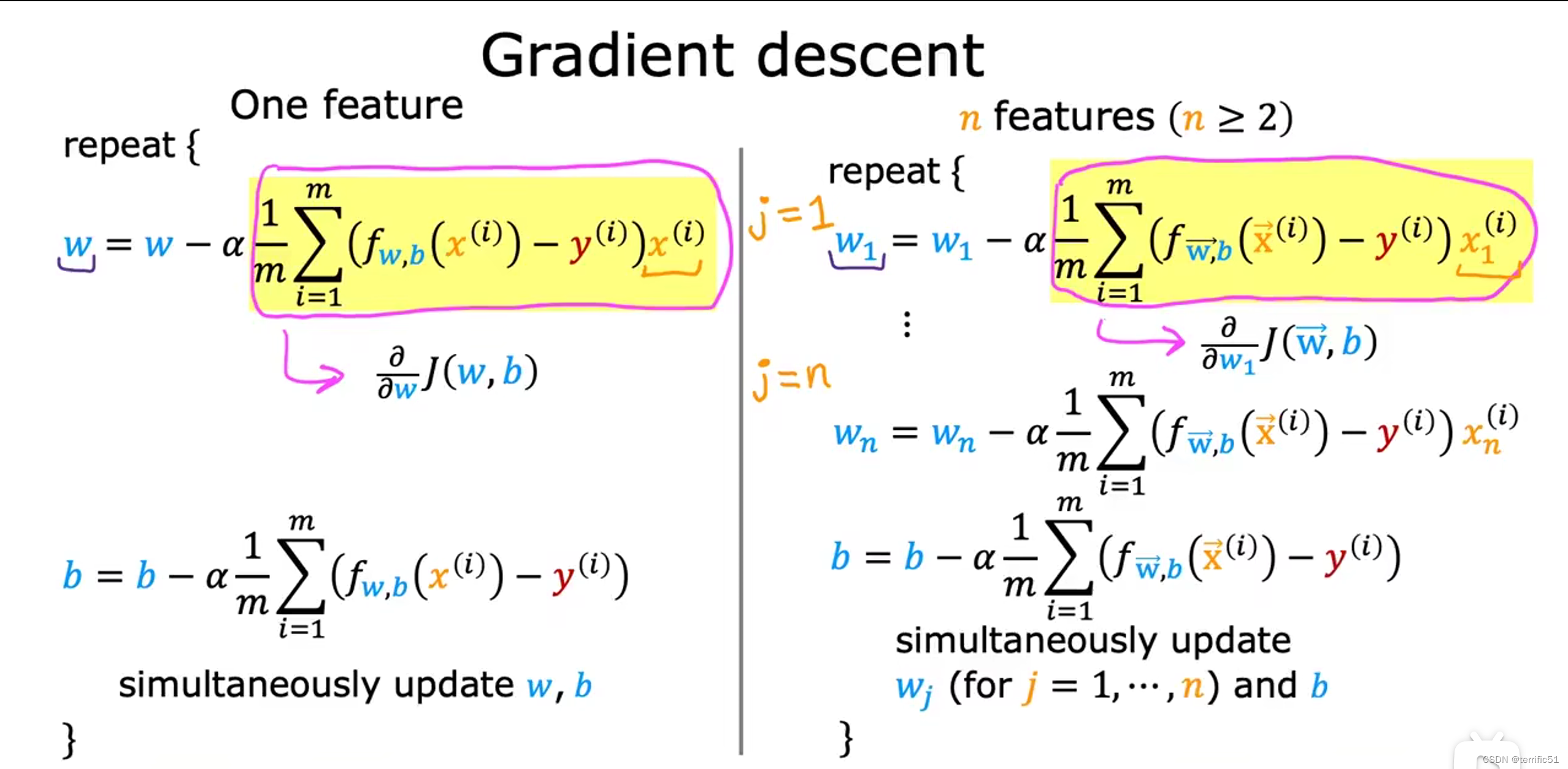
梯度下降算法


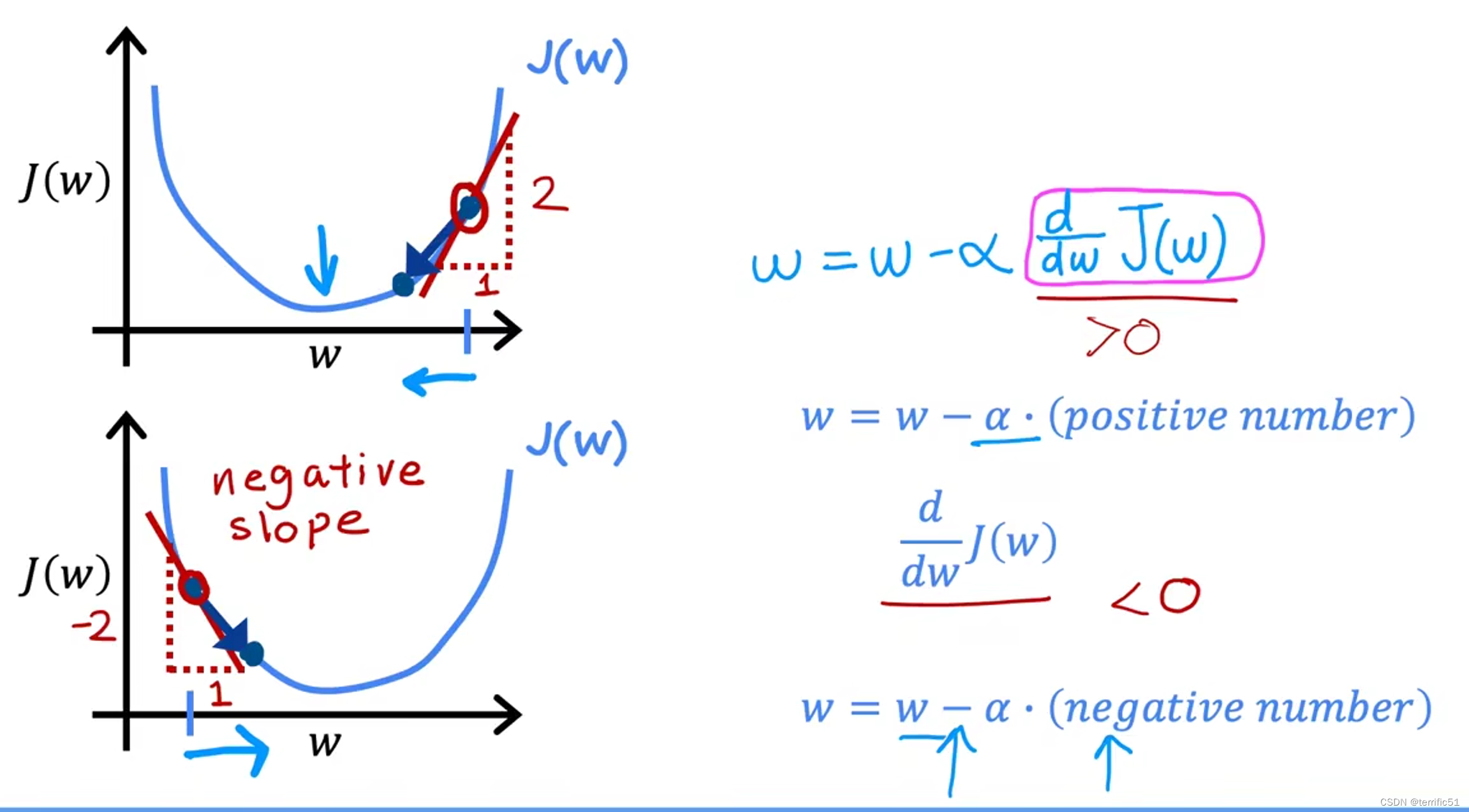
其中,a为学习率。如果学习率太小,那么大的下降是可行的,但会很慢。这将花费很长时间,因为你将会采取很小很小的步骤,在它接近最小值之前需要很多步骤。但是如果学习率太大,步子就会很大,很可能由于步子太大跳过最小值、永远达不到最小值。
如图示:
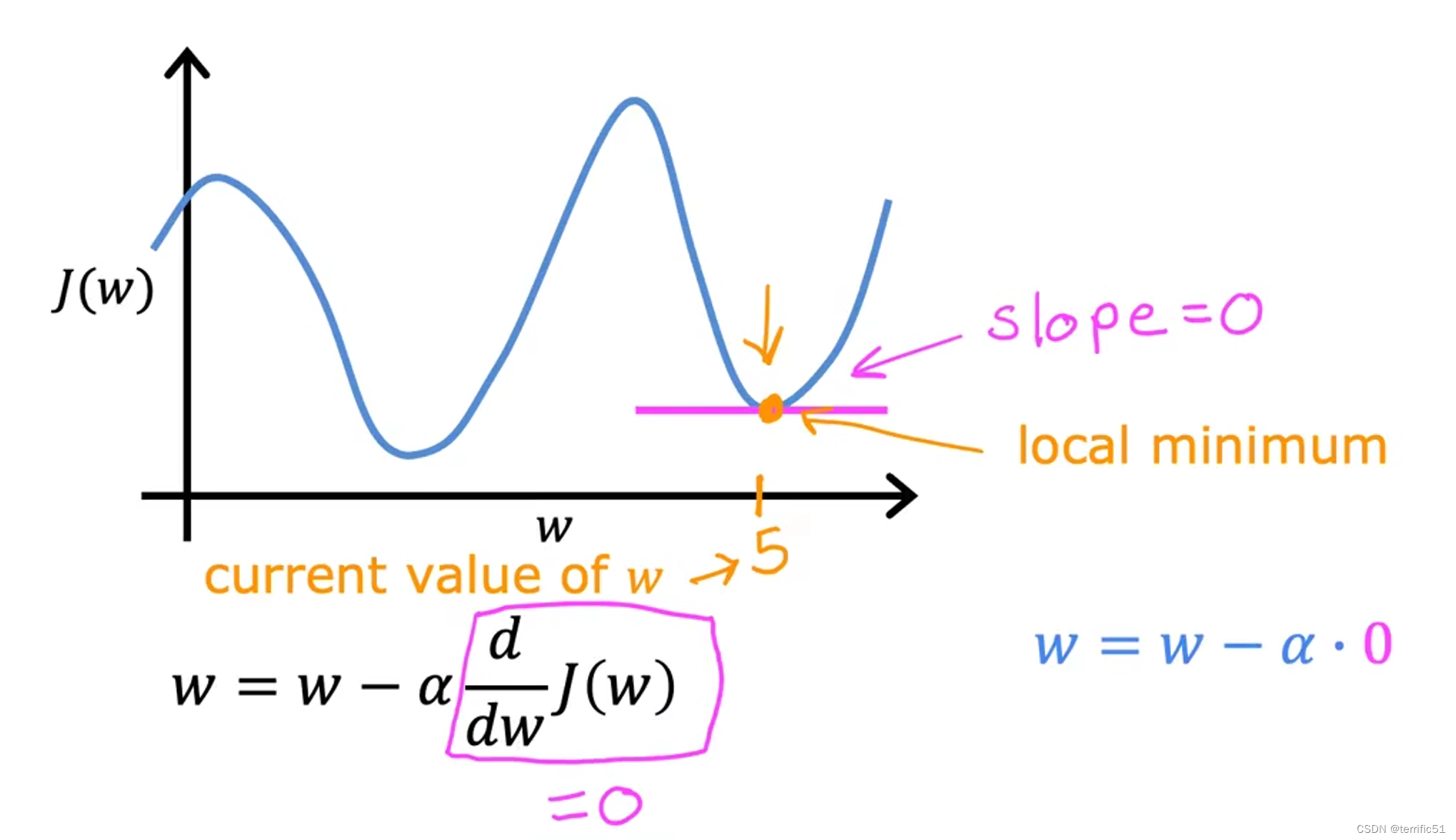
如果参数达到了局部最小值,那么进一步的分级将步骤降到完全没有。它不会改变过程,这正是因为它会使解保持在局部最小值。
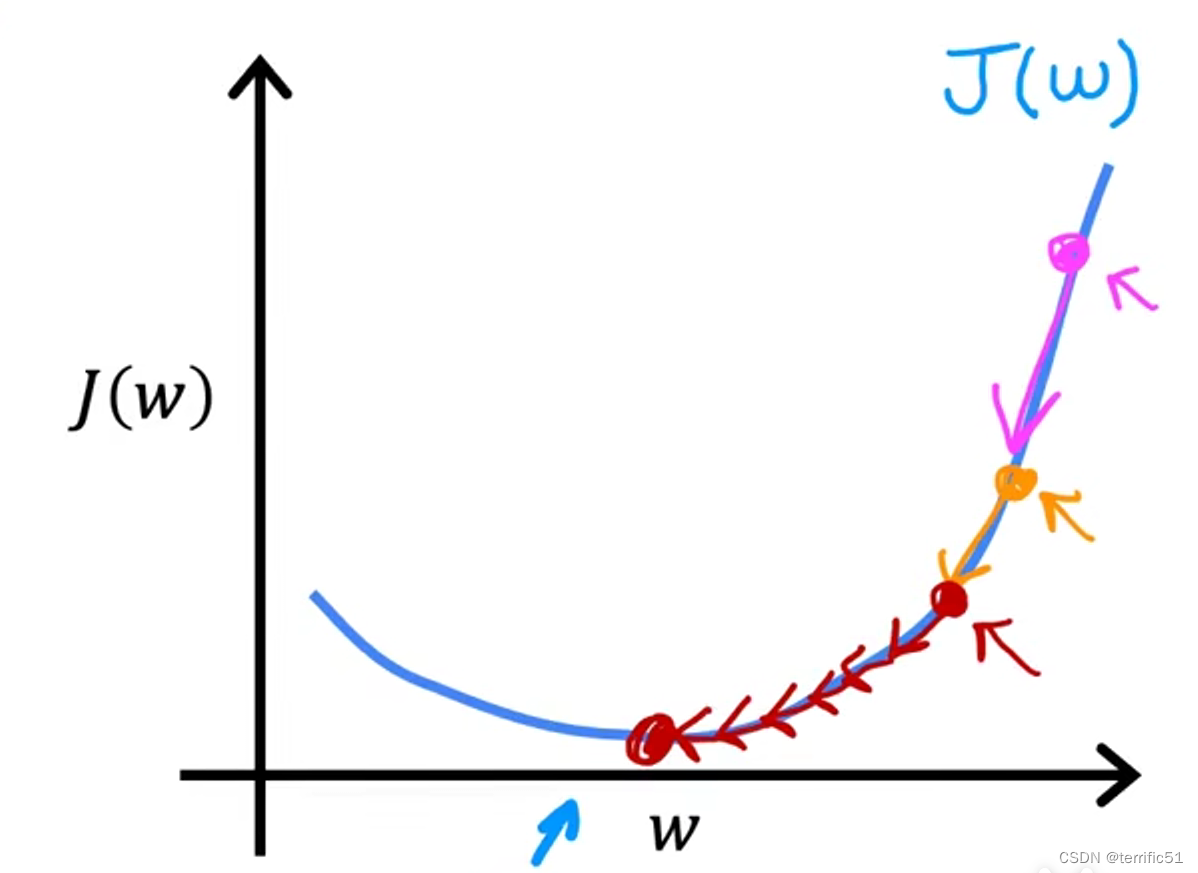
当我们接近局部最小值时,分级下降会自动地采取更小的步骤,这是因为当我们接近局部最小值时,导数会自动地变小,这意味着步骤也会自动变小,即使a保持在某个固定的值。
推导:
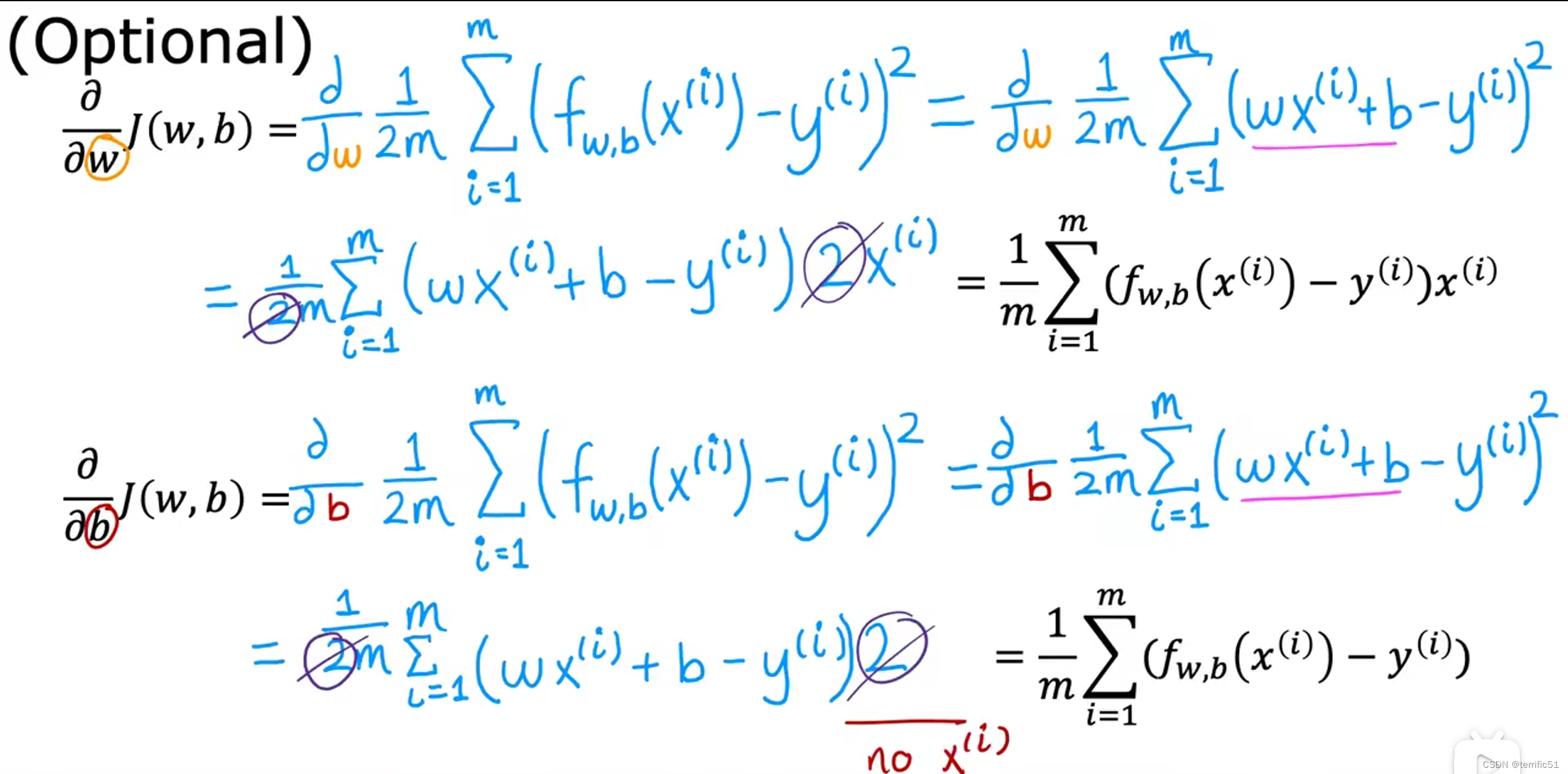
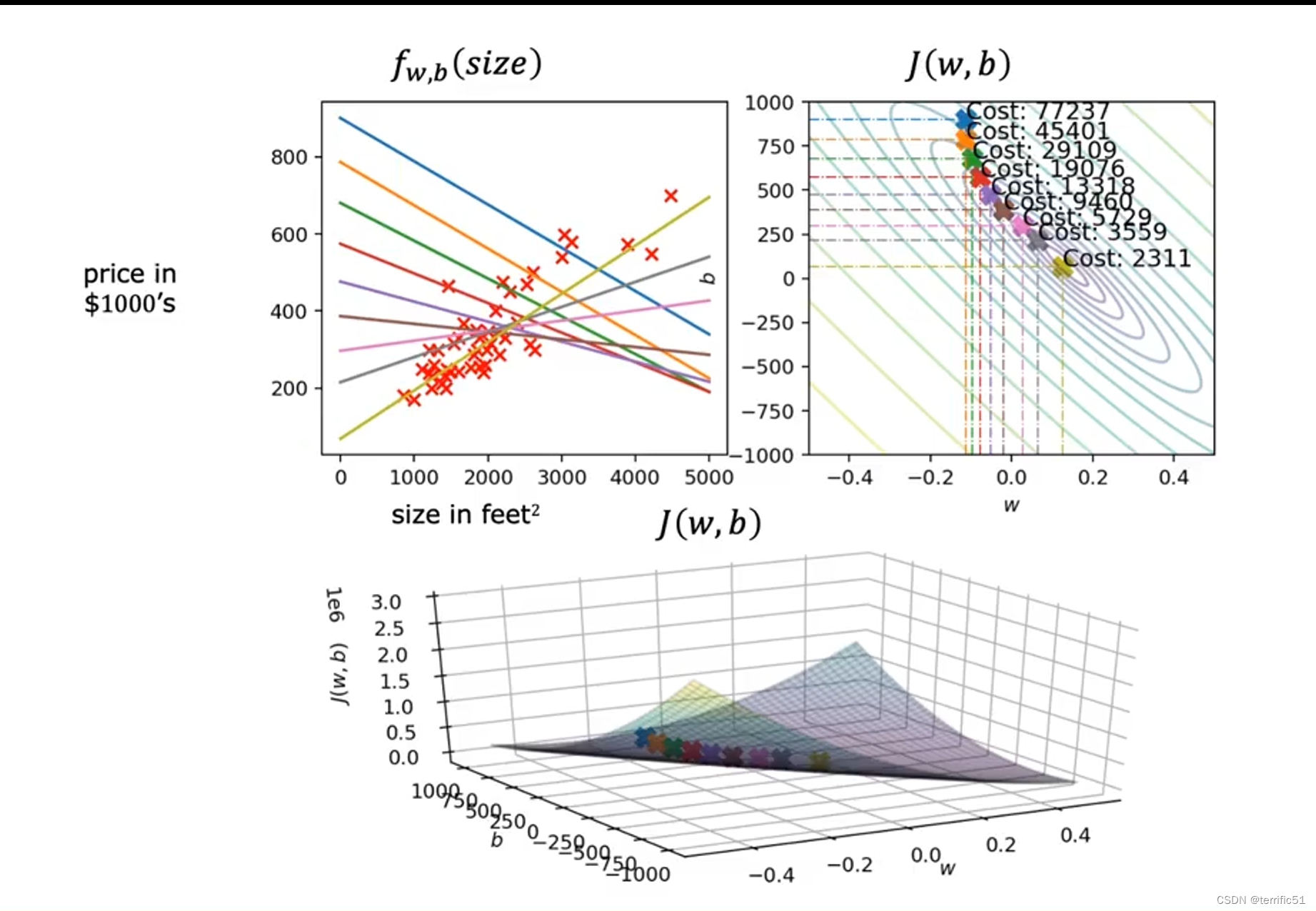
如图,我们可以通过看左图得到相应的直线拟合,发现越来越好地拟合数据,直到到达全局最小值。这个模型可以用来拟合房屋数据,从而预测房产的价格。
多元线性回归

numpy中的dot()函数是两个之间的顶级私有操作的向量实现,特别是在它的小屋中,它的运行速度要比前面两个代码示例快得多。

向量化
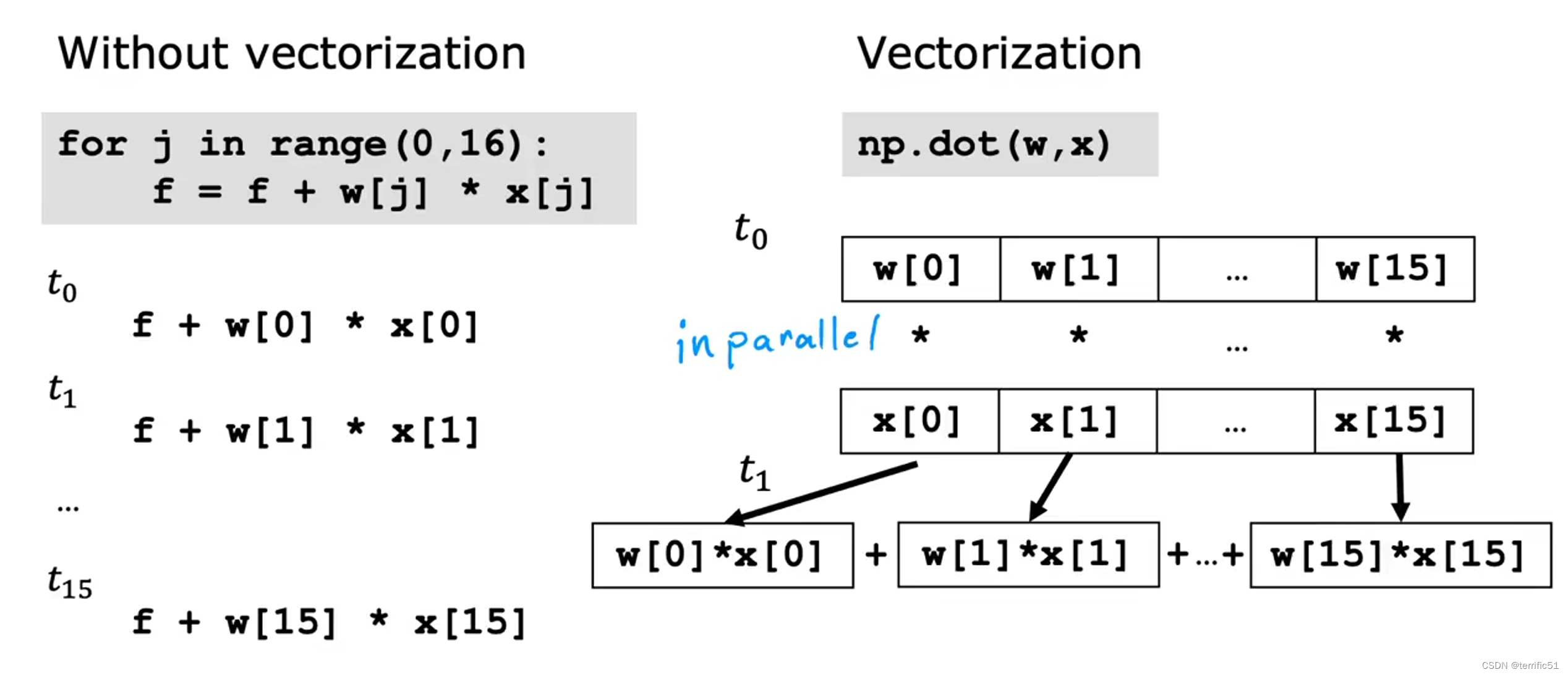
使用向量化,将会更有效率地实现线性回归


—————————————————————————————————

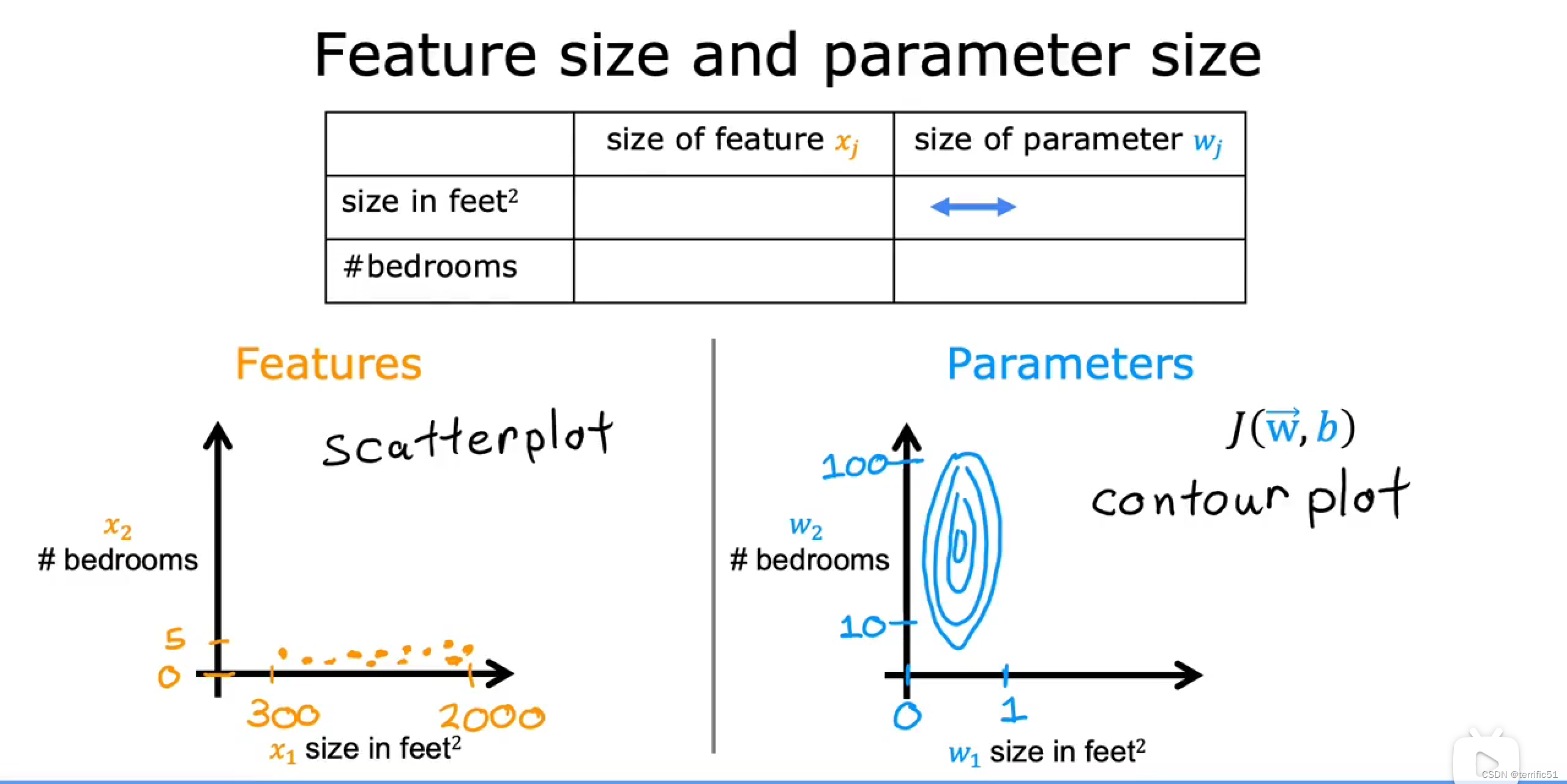
w的一个很小的变化会对估计价格产生很大的影响,对成本也会有很大的影响。
进行扩展:x、y轴均变为0-1。
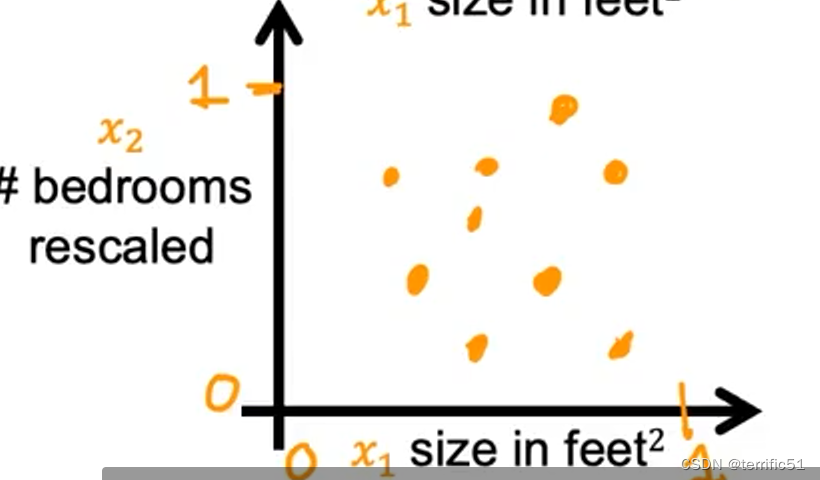
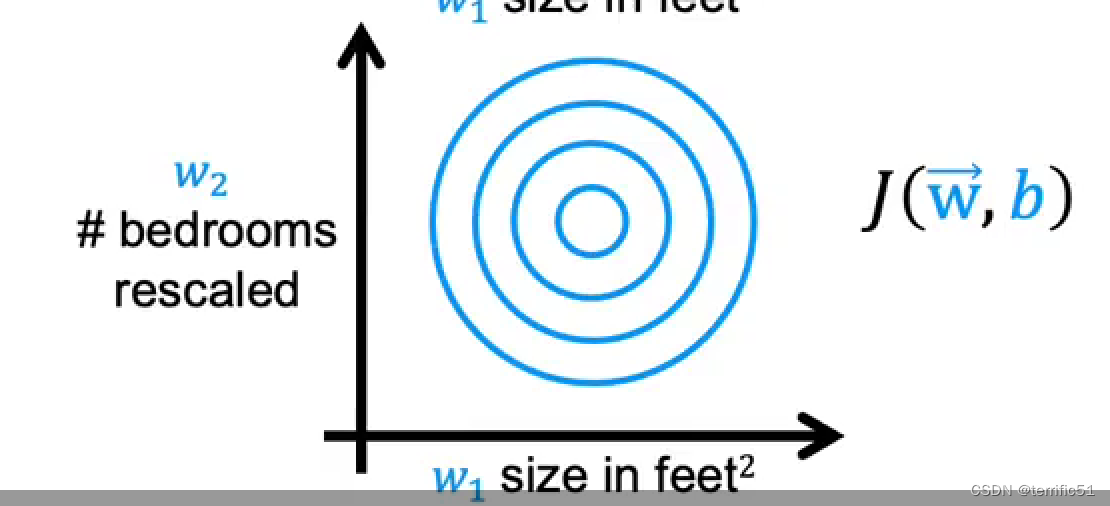
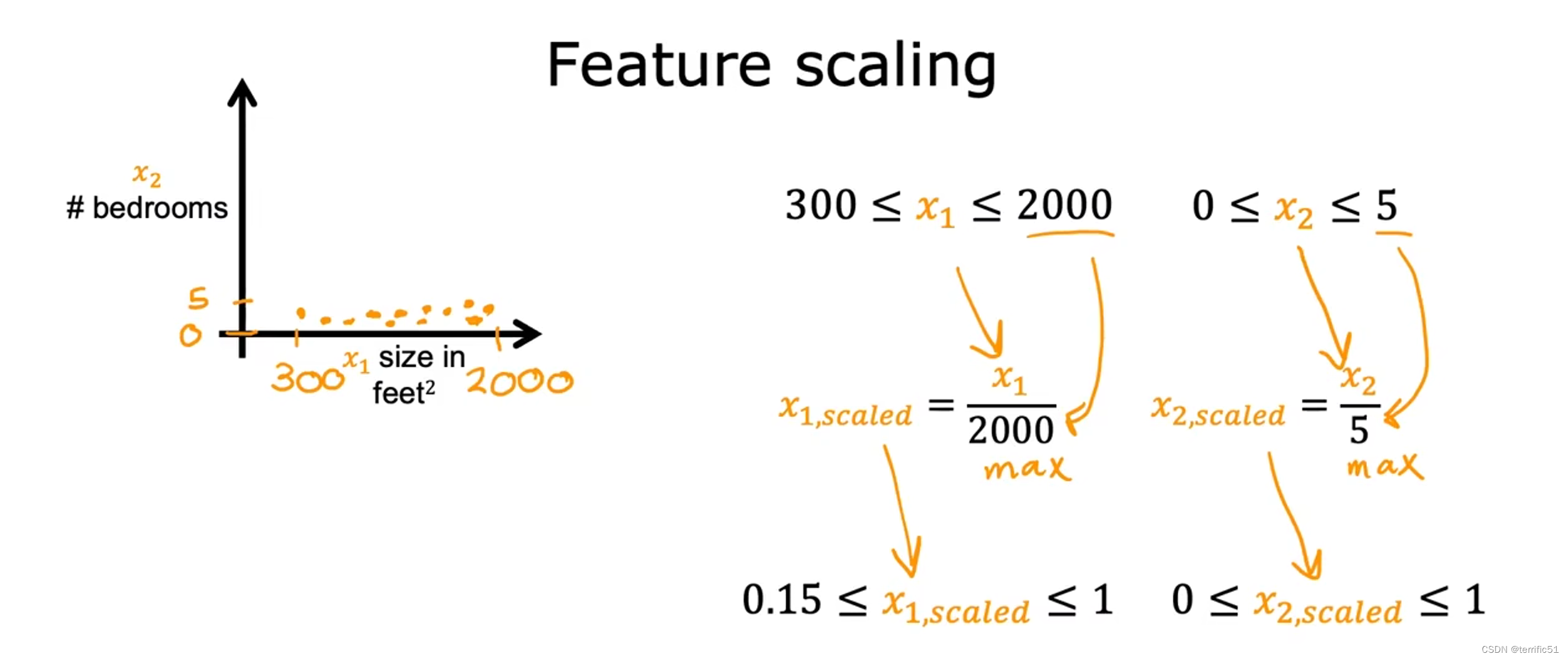
进行数据缩放
均值归一化


特征值调节的合适范围

在下降中的学习曲线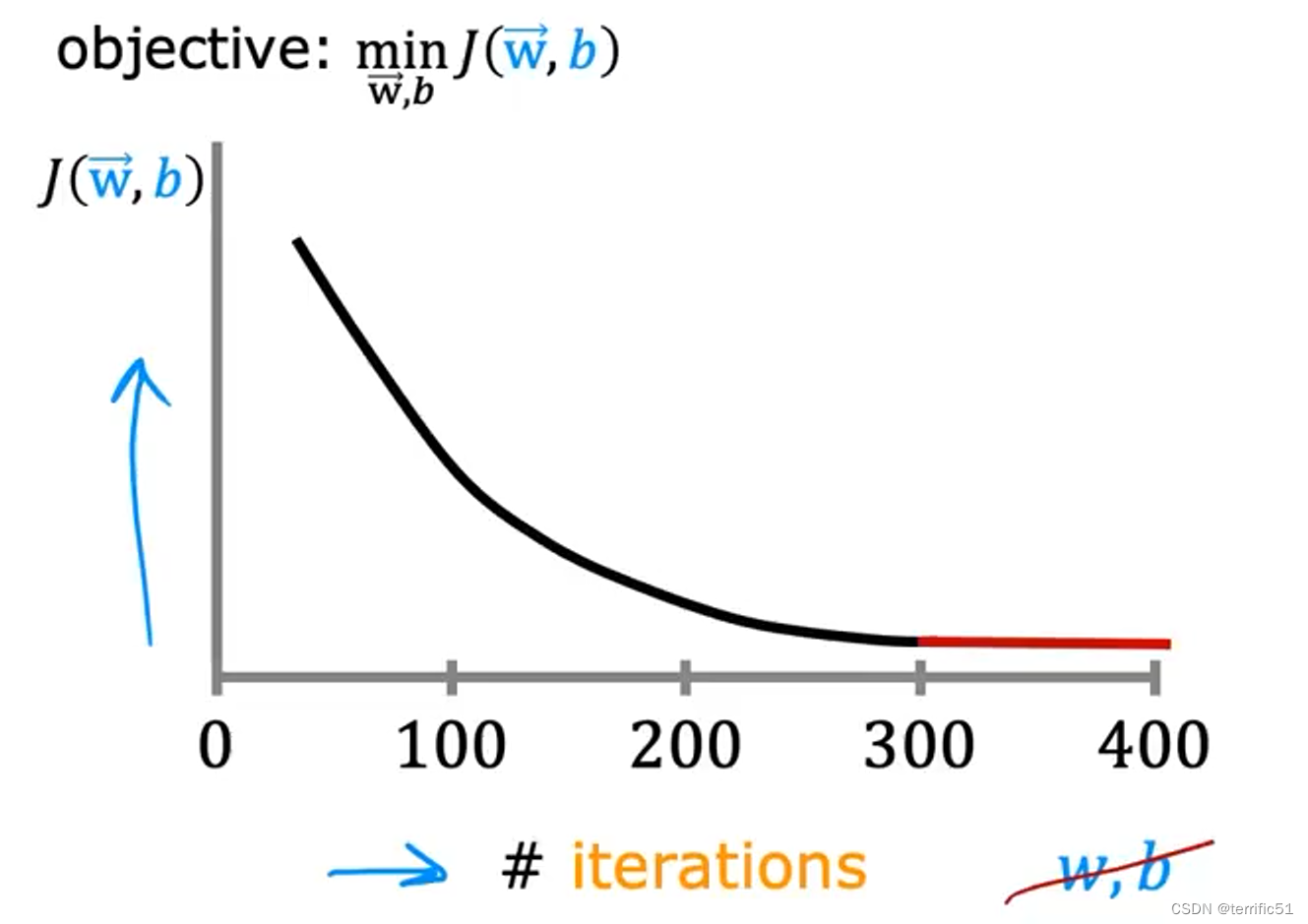
注意:横轴是迭代次数。纵轴是成本J。
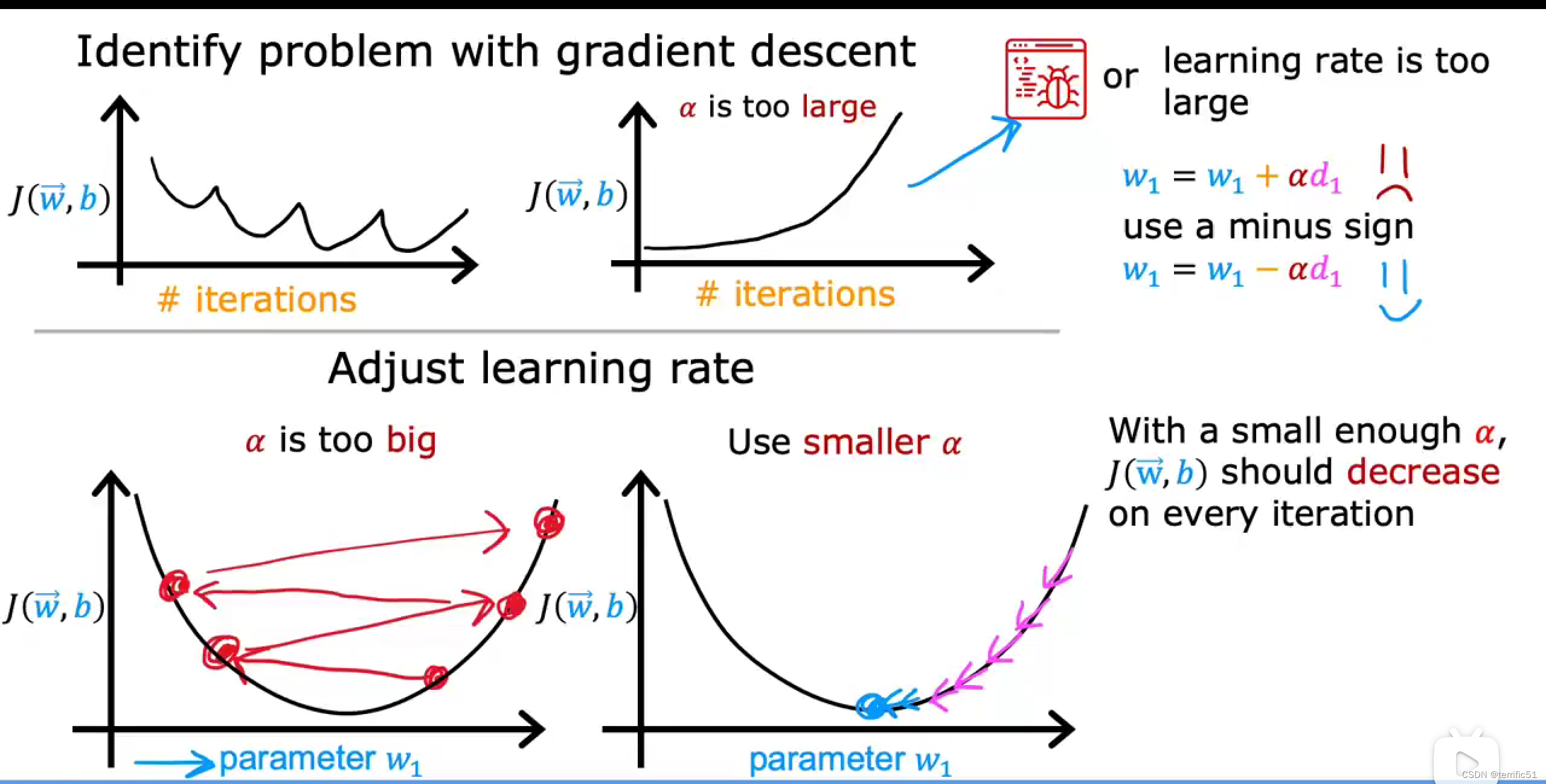
如果J在一次迭代中增加了,这意味着要么a选择得很差,通常意味着a太大或者可能存在漏洞。
(检查梯度下降是否收敛)

————————————————————————————————————
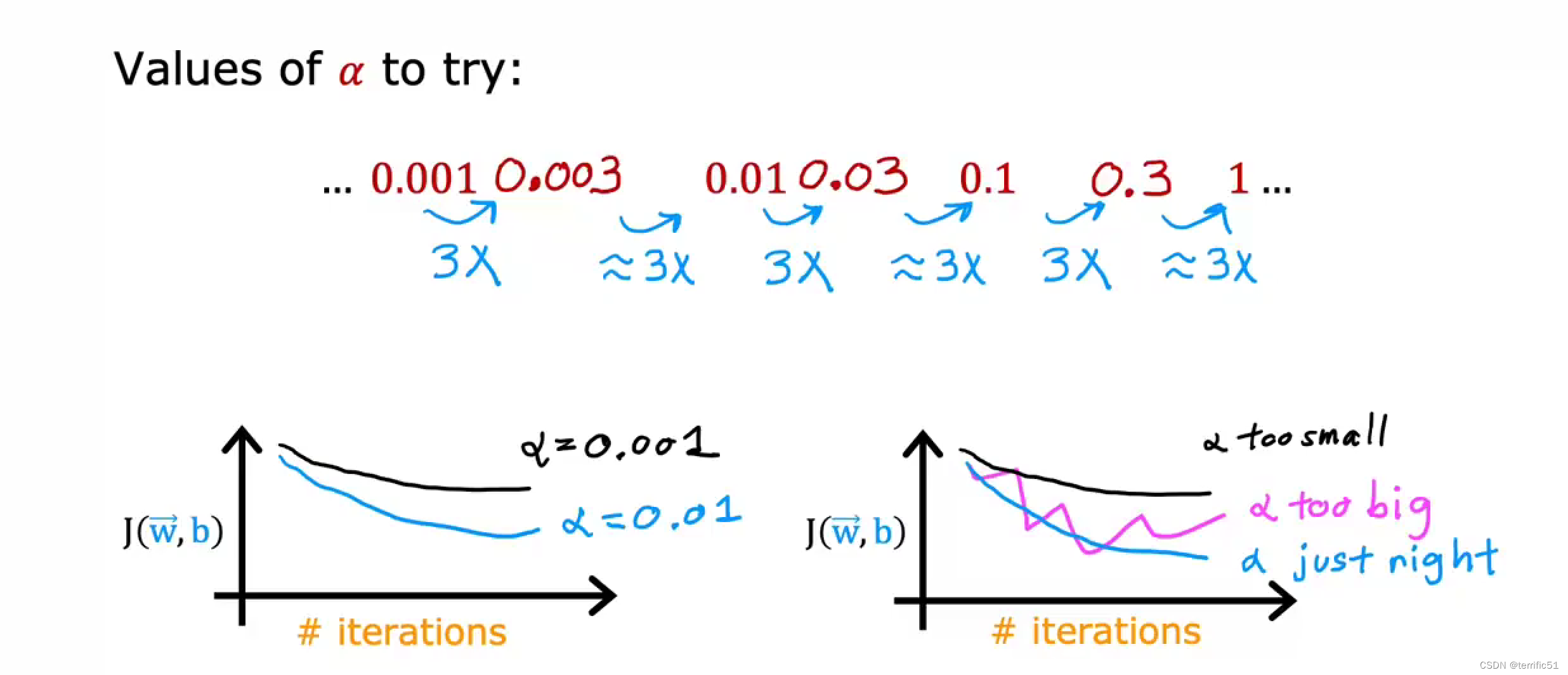
学习率的选择
进行调试方法:先将a设置为一个非常小的数字,然后看看这是否会导致每次迭代的成本降低。
————————————————————————————————————
特征工程
利用对问题知识或直觉来设计新特征,通常是通过转换或结合问题的原始特征来让学习曲线更容易做出准确的预测。
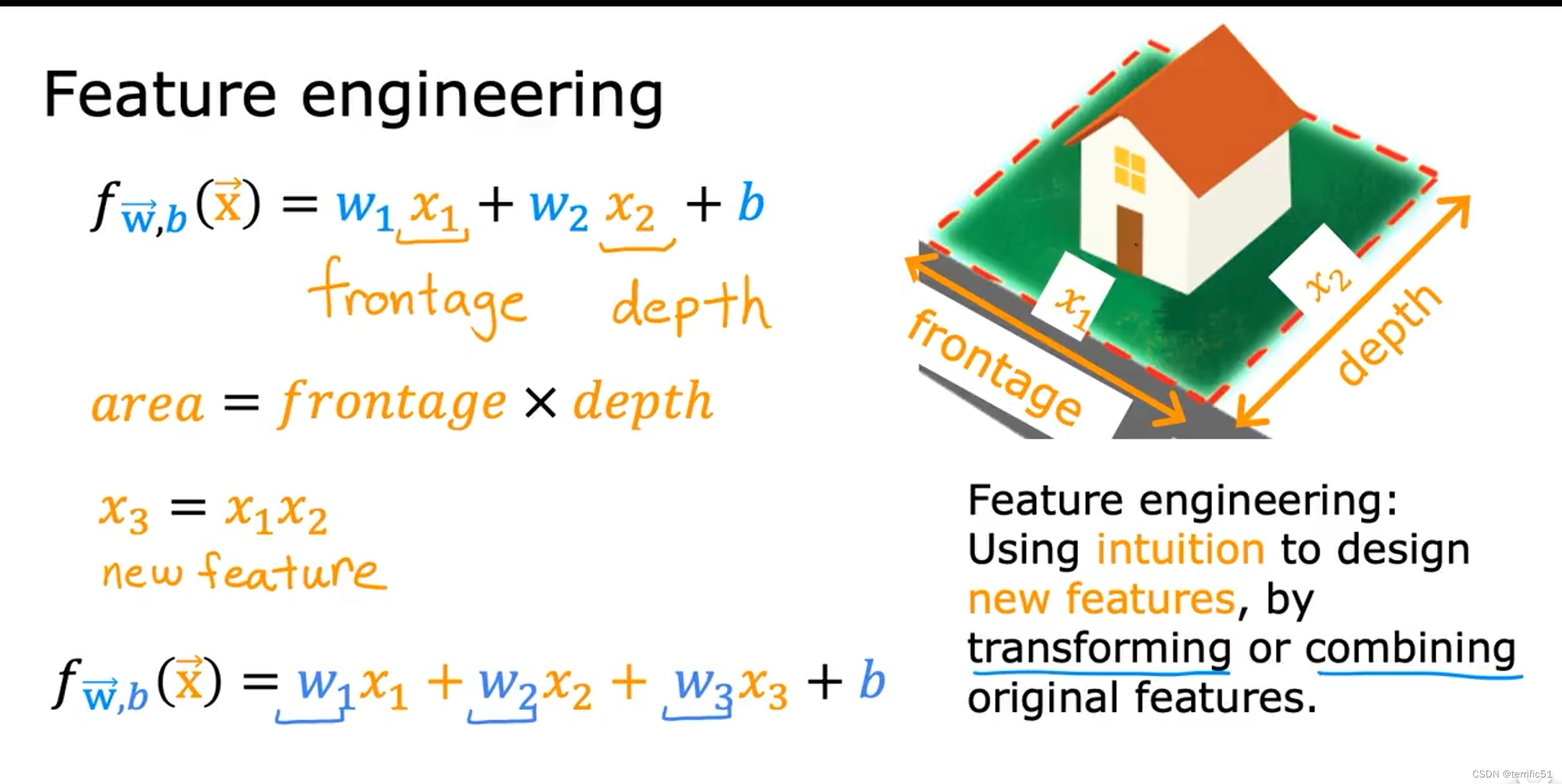
因此,学习曲线取决于对应用程序的见解,而不是仅仅取刚开始使用的特性。有时通过定义新特性,可能会得到一个更好的模型。
————————————————————————————————————
多项式回归
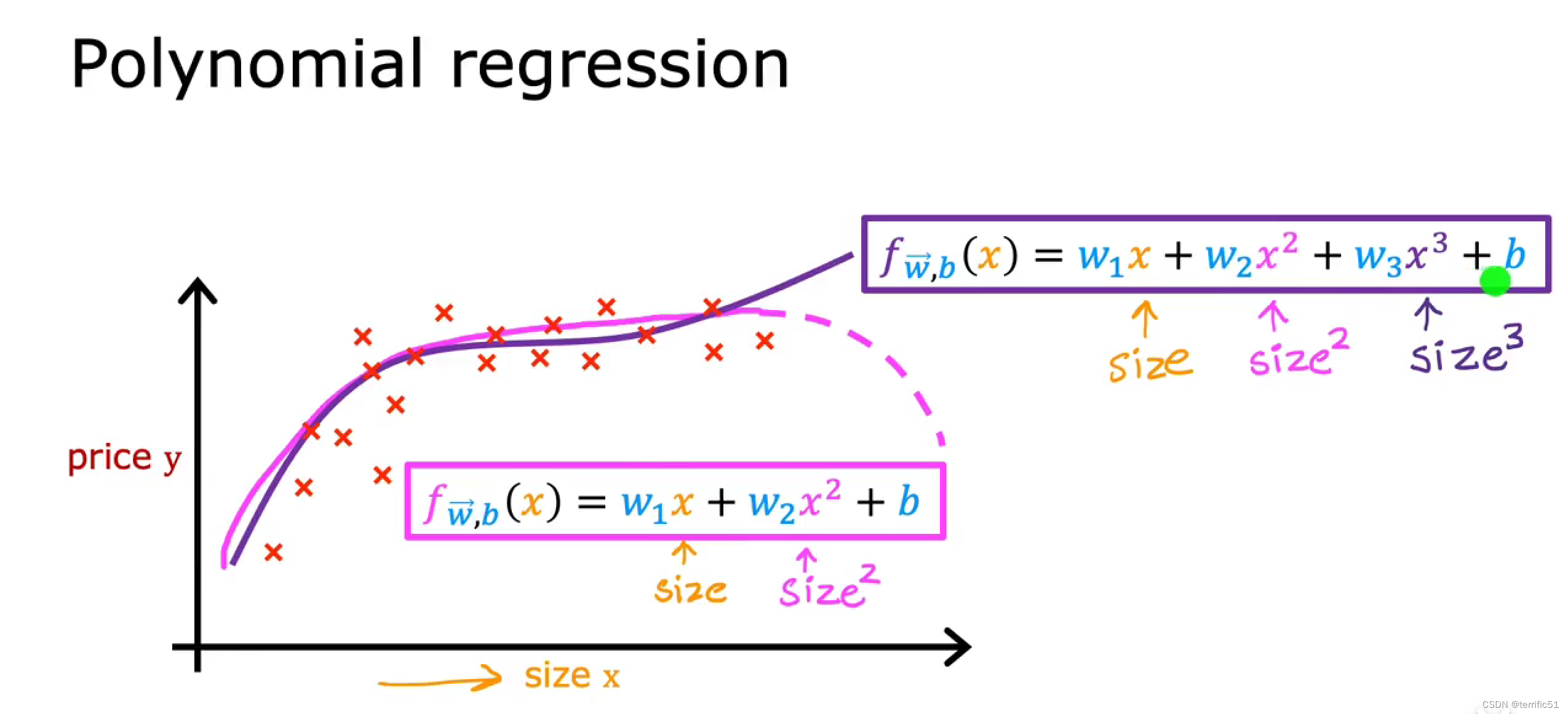
这两个都是多项式回归的例子,因为可选特征X并将其提高到2或3次幂或任何其他幂。
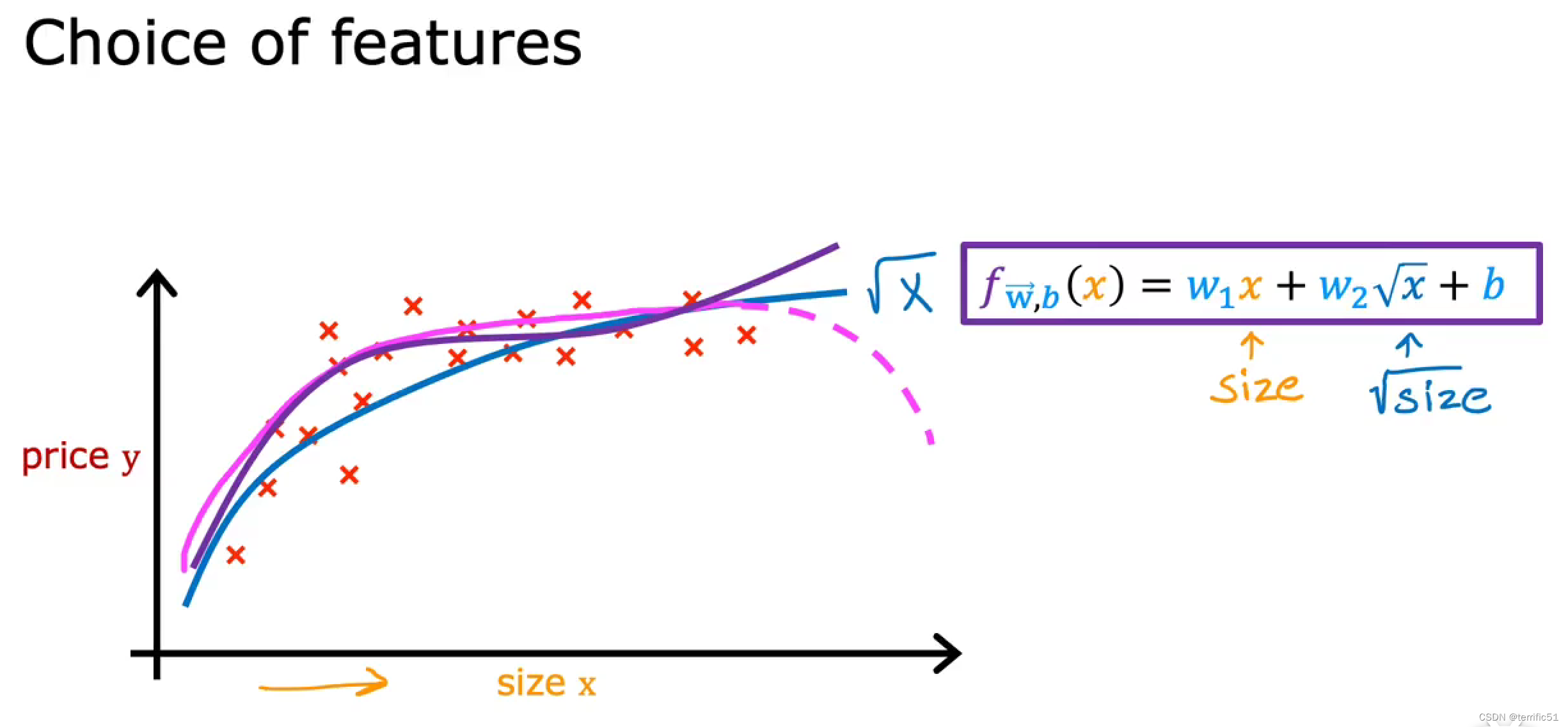
通过使用特征工程和多项式函数可以为数据获得更好的模型。
————————————————————————————————————
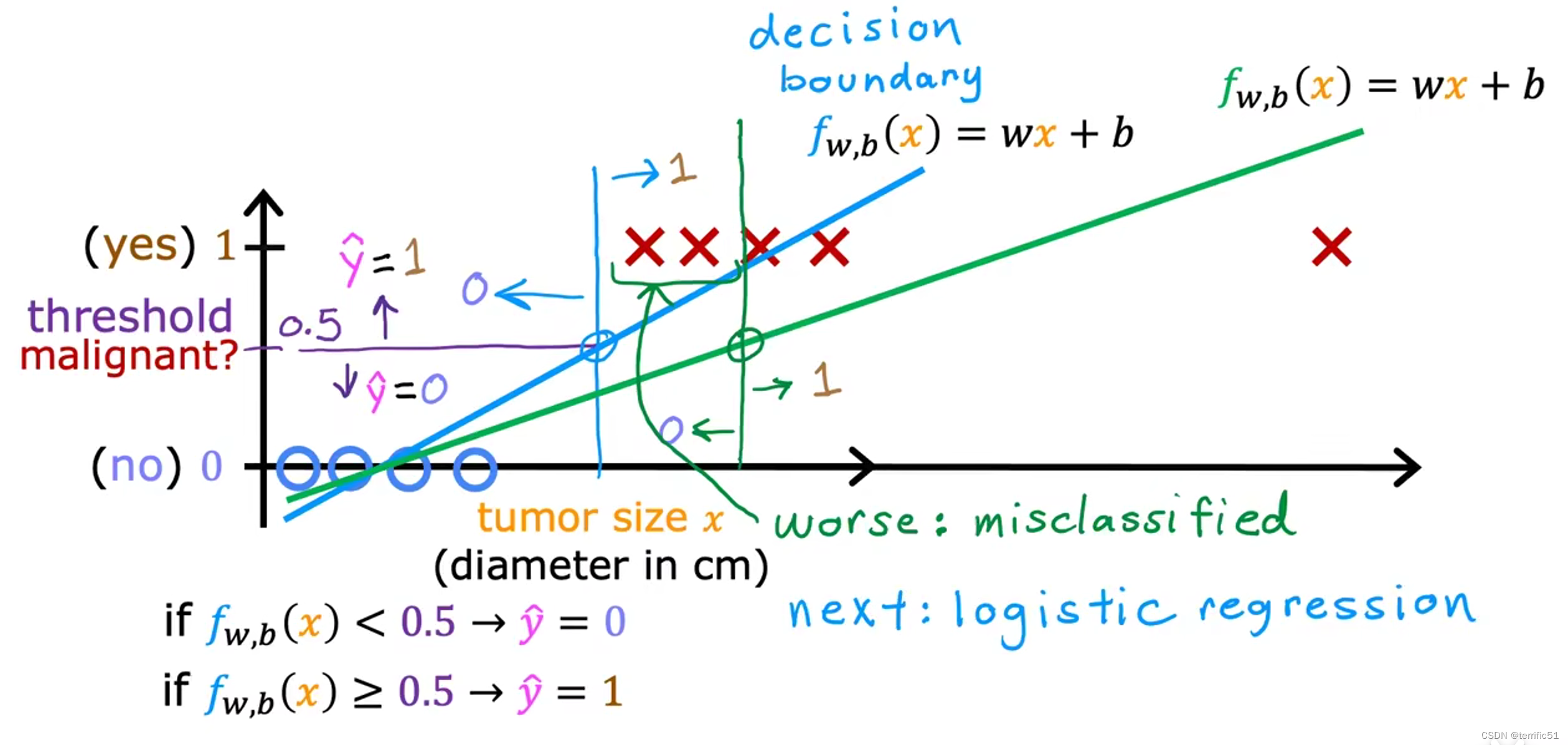
逻辑回归
我们所做的逻辑回归是拟合一条S形曲线。
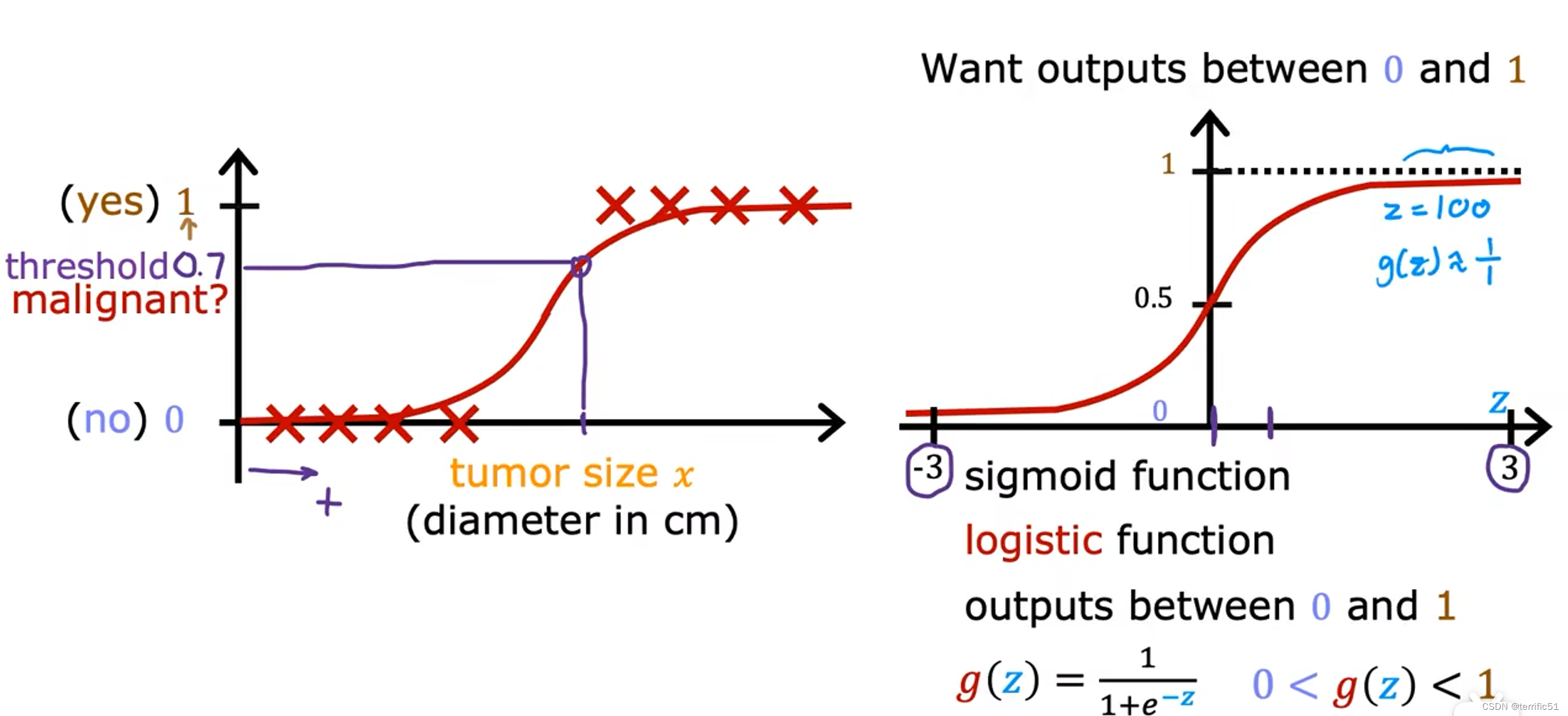
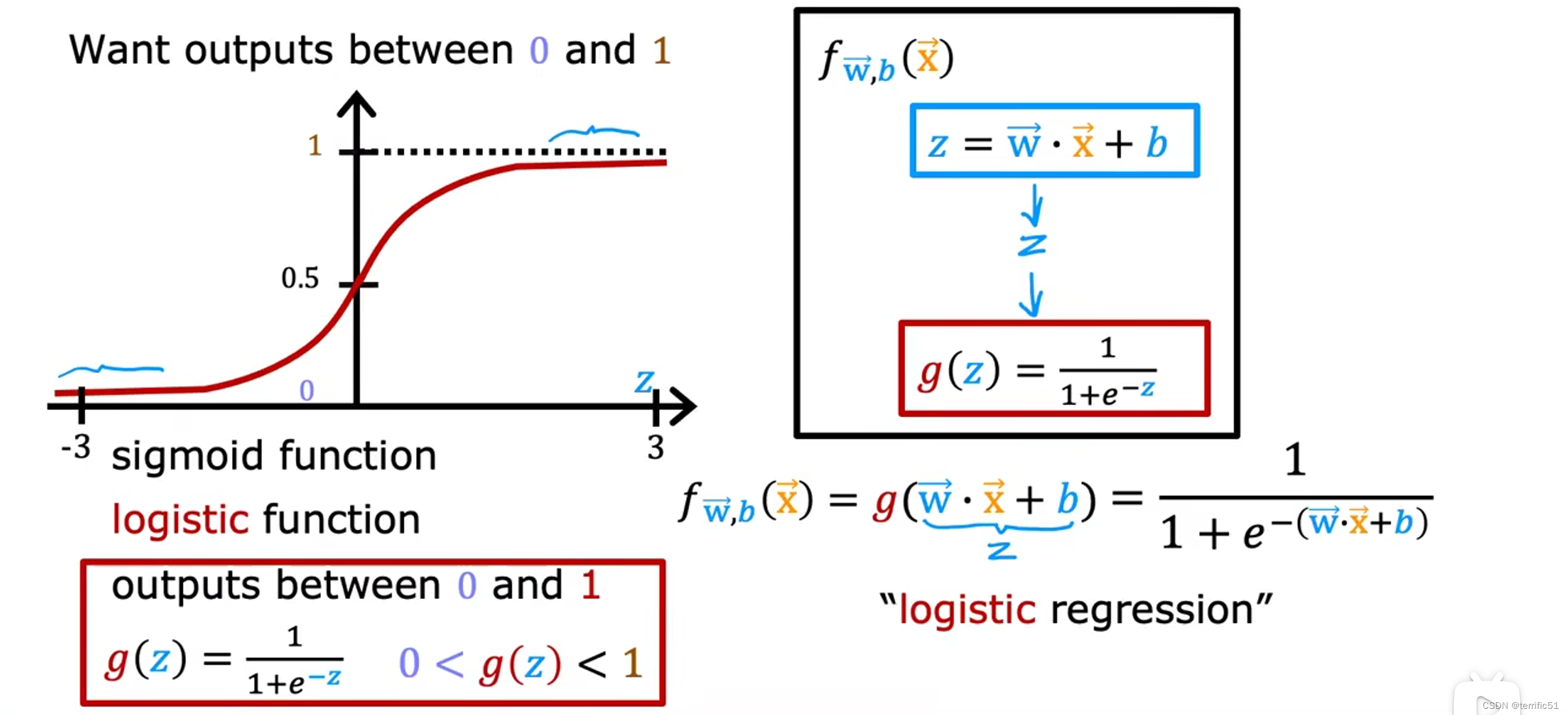
这就是逻辑回归模型,它所做的是输入一个特征或一组特征X,输出0到1之间的数字。
————————————————————————————————————
决策边界
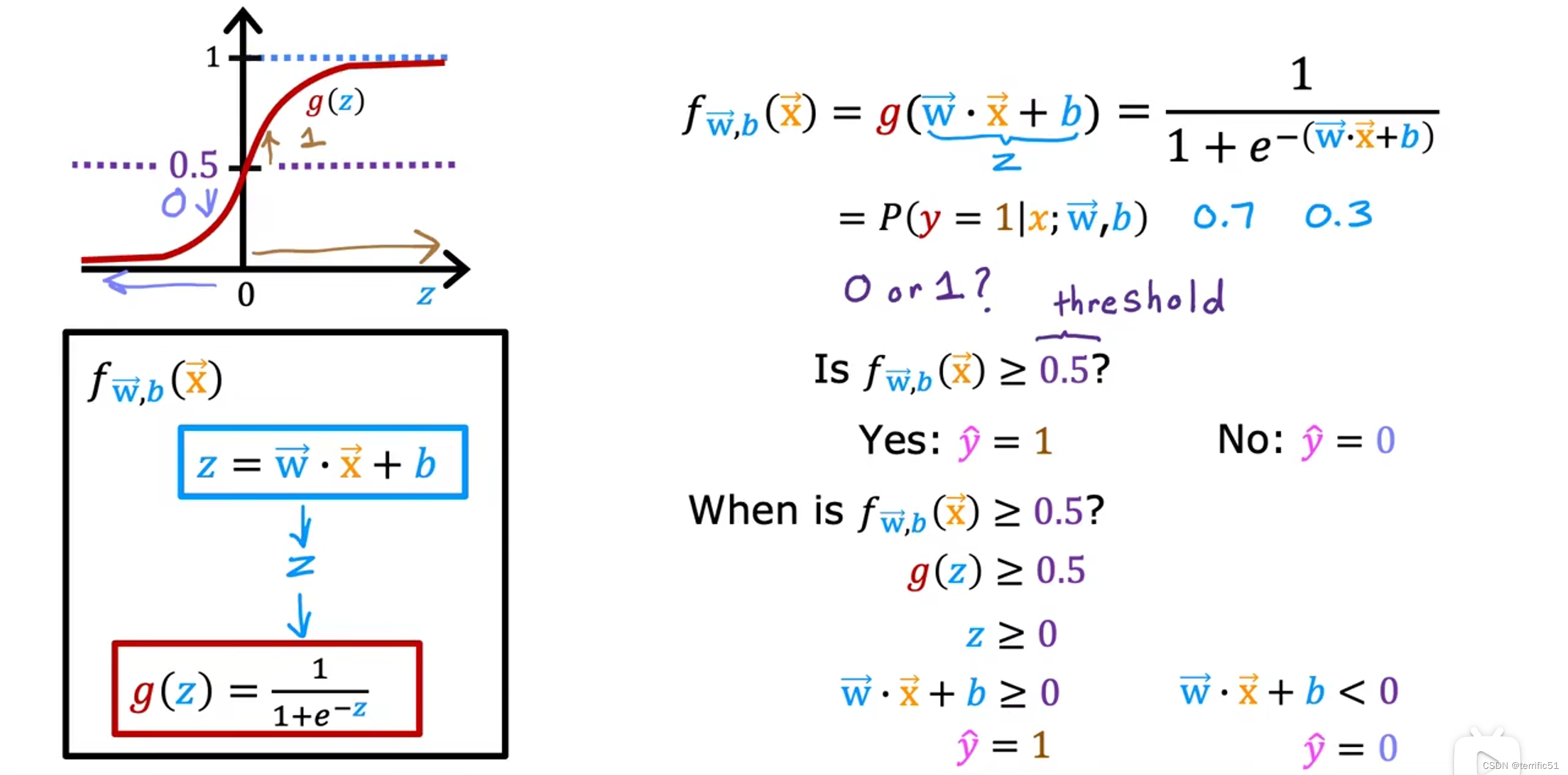
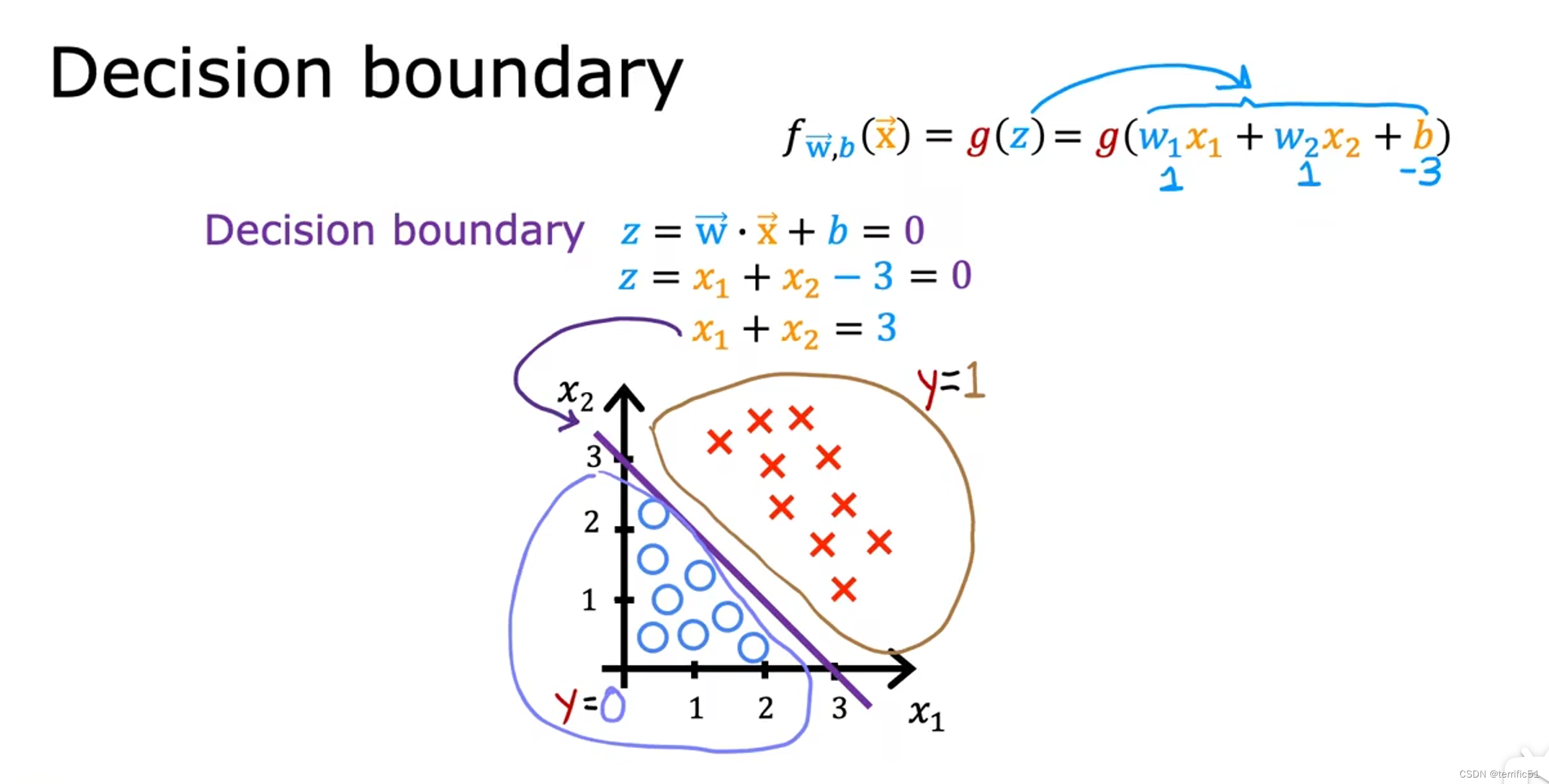


————————————————————————————————————
逻辑回归的代价函数
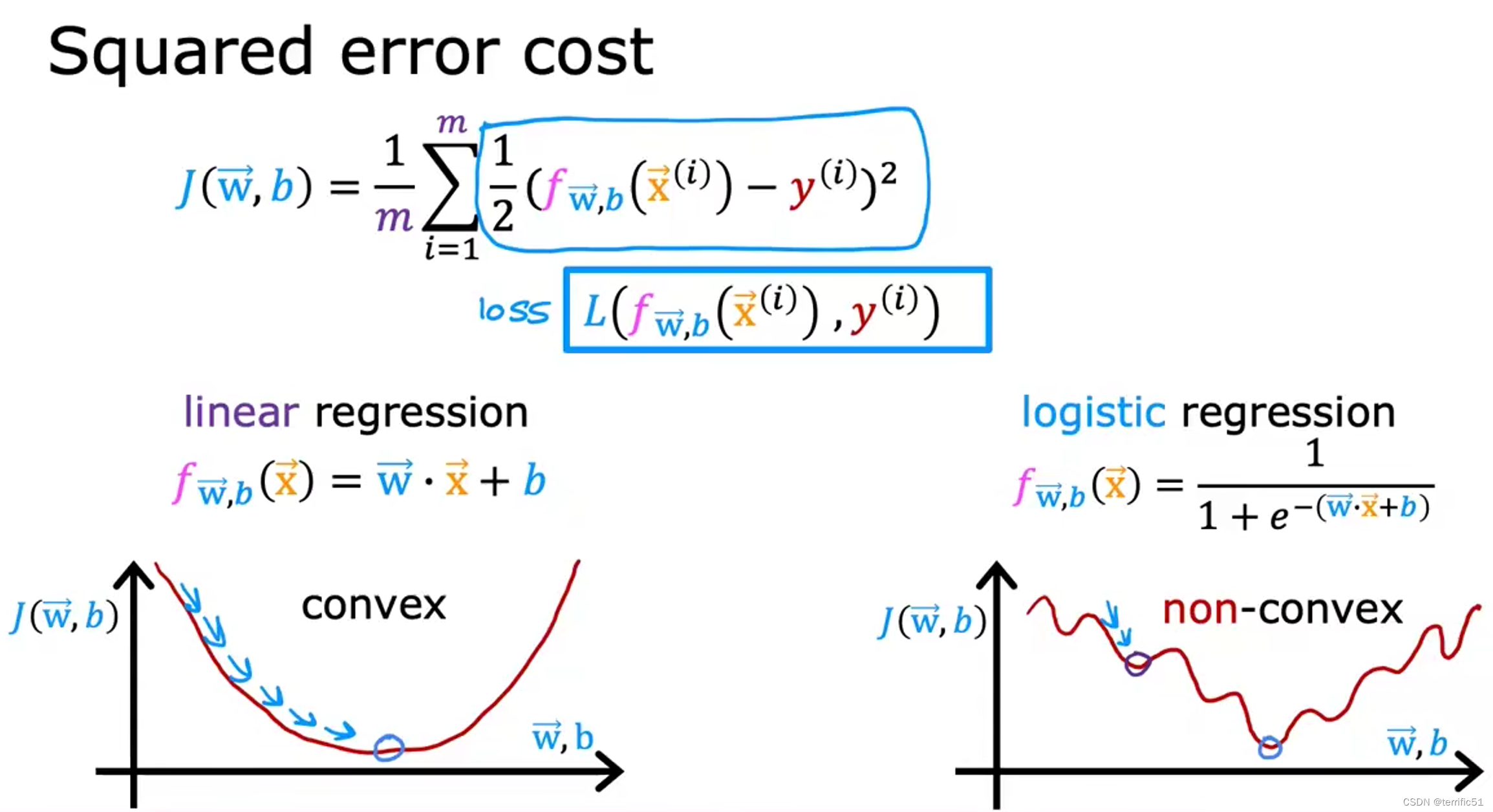
当预测值与真实值接近时,损失最小。
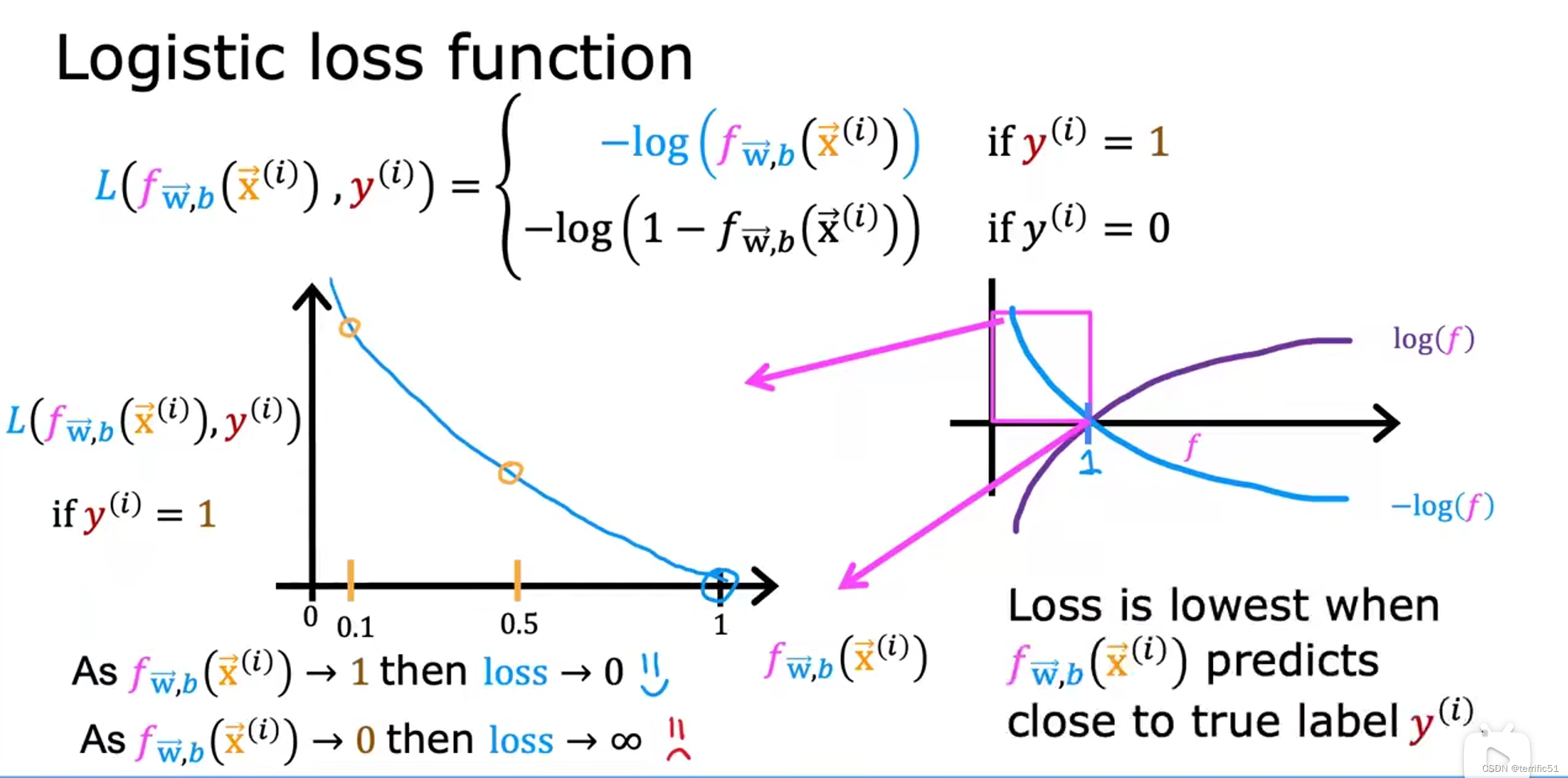
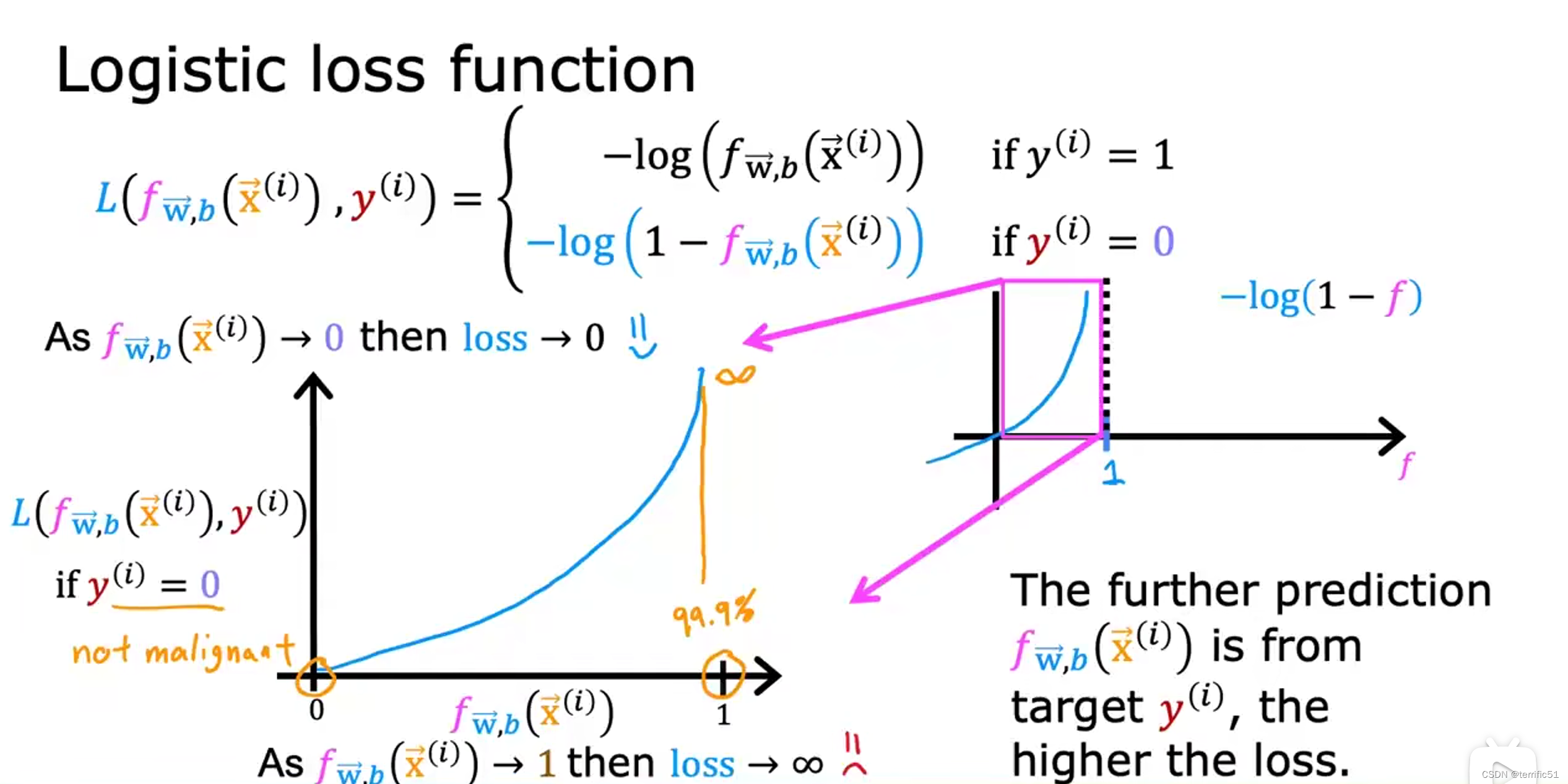
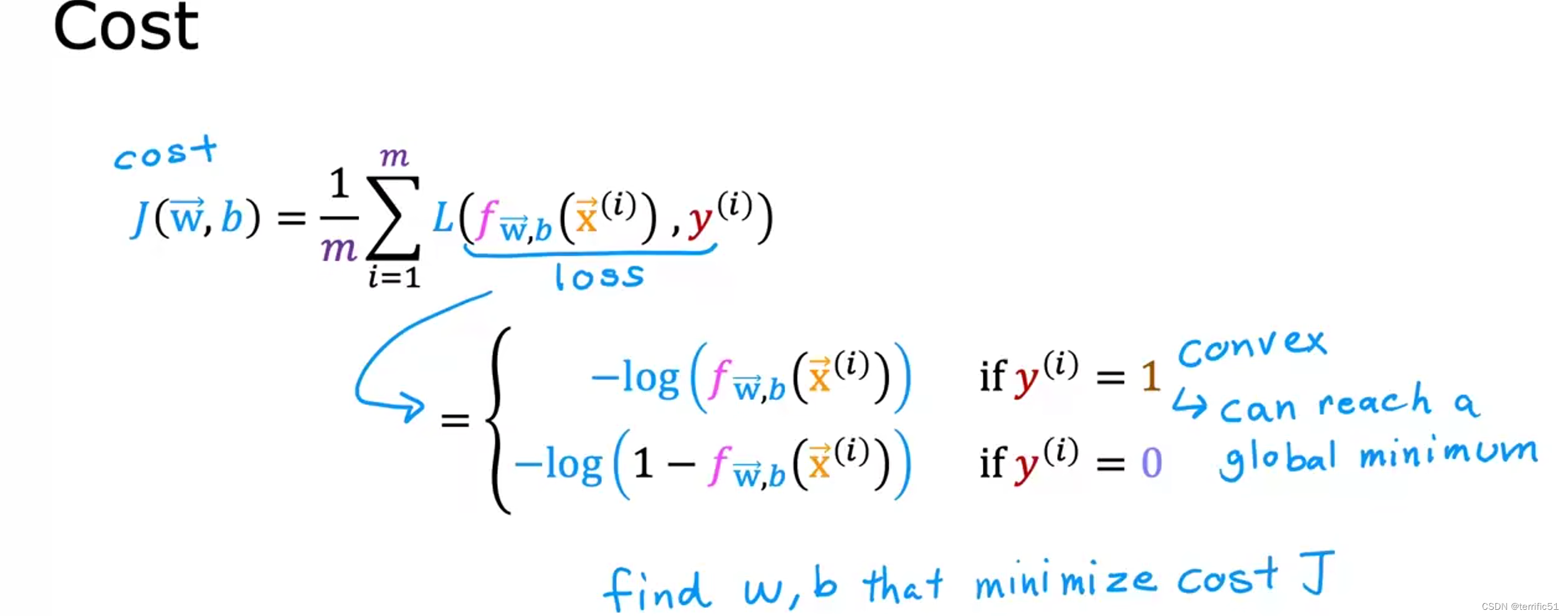
逻辑回归的简化版代价函数


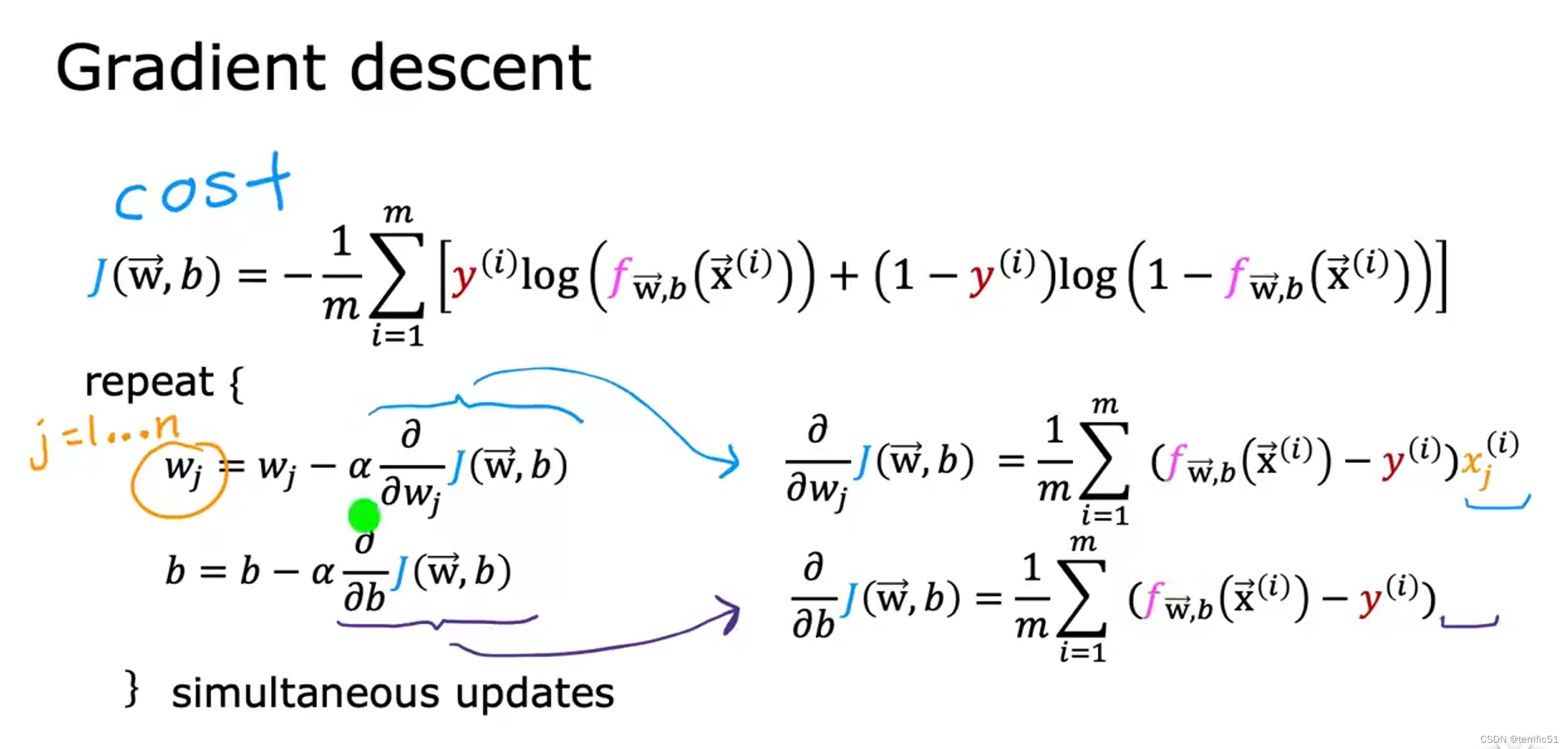
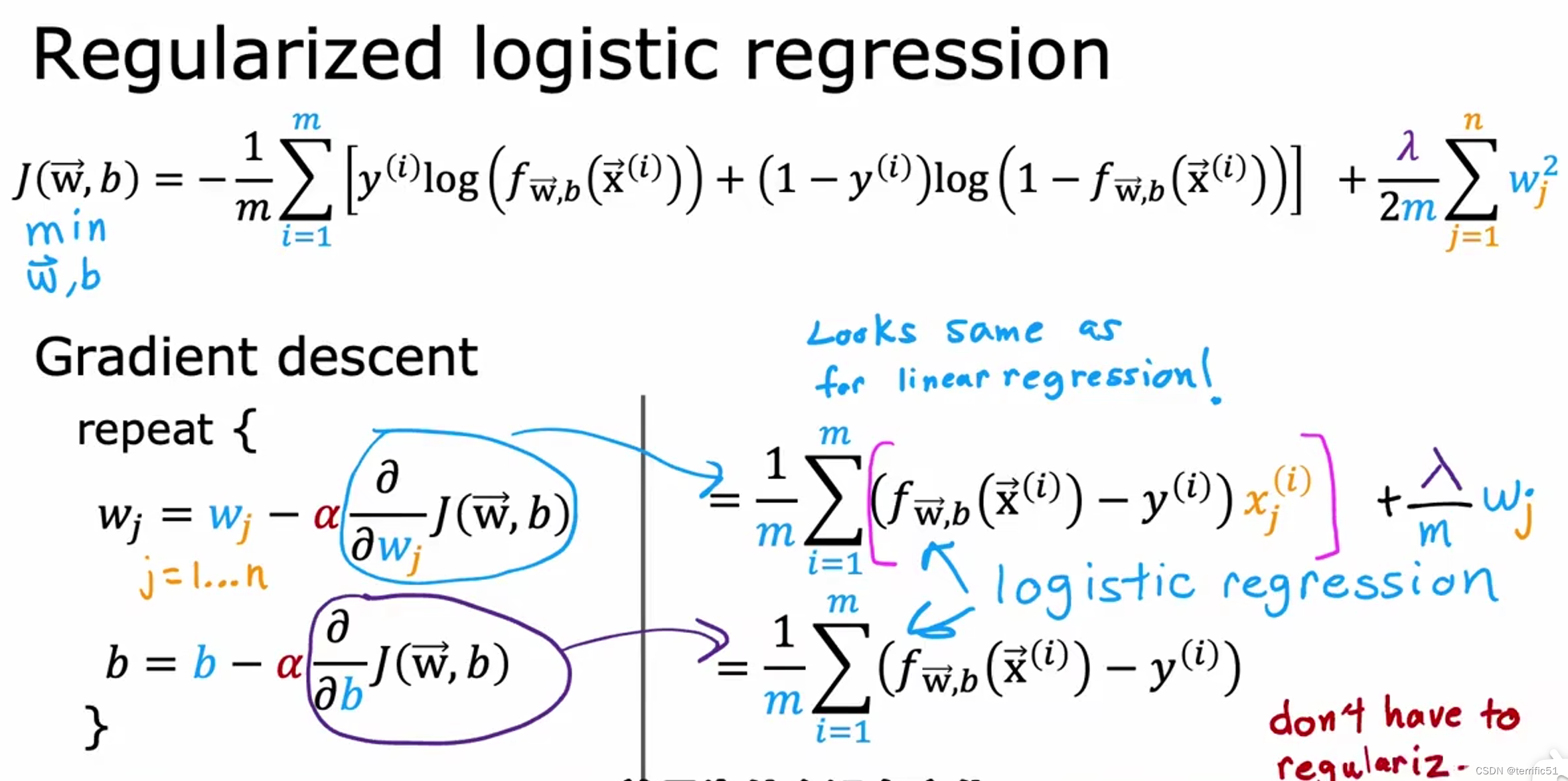
梯度下降实现


过拟合问题
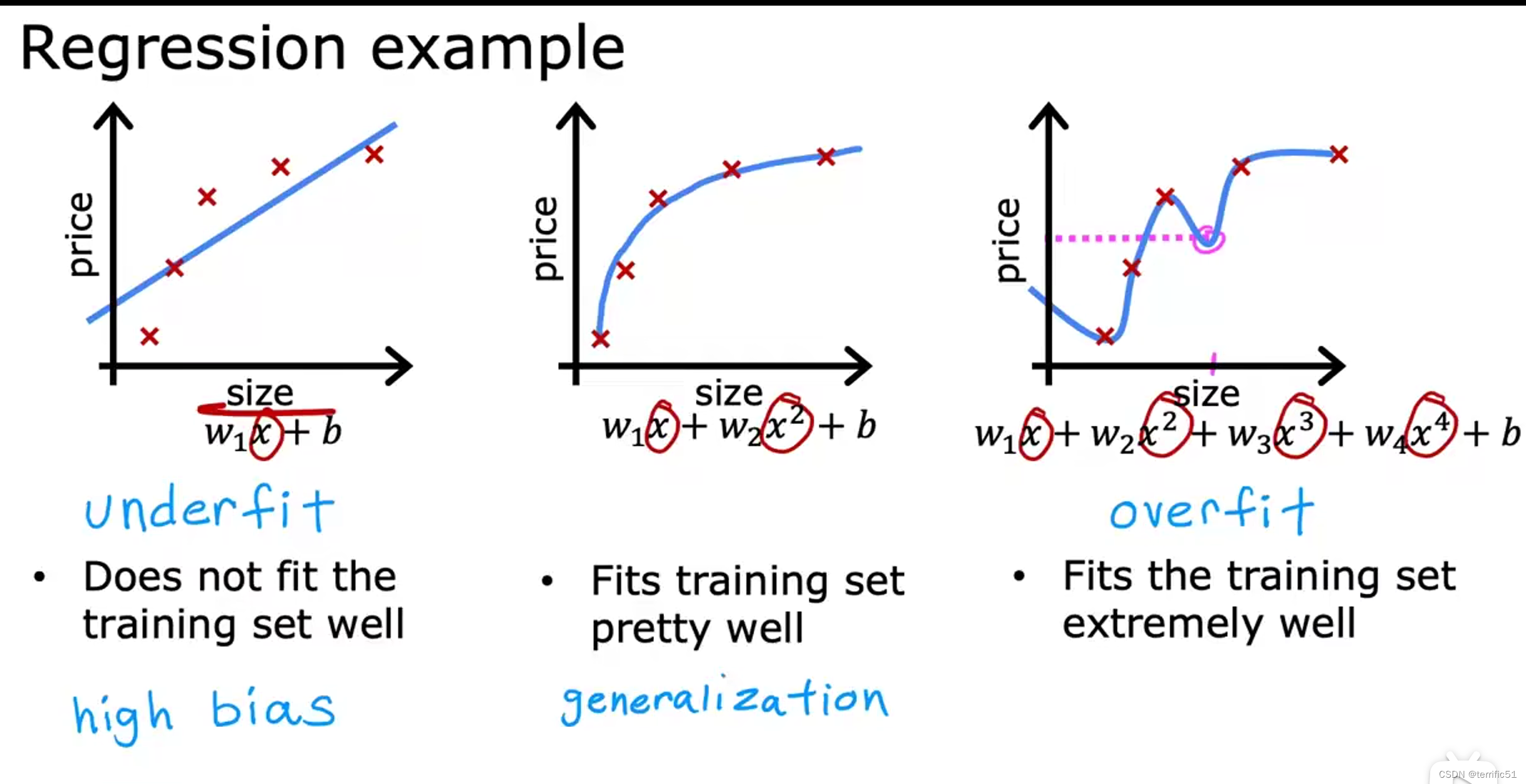
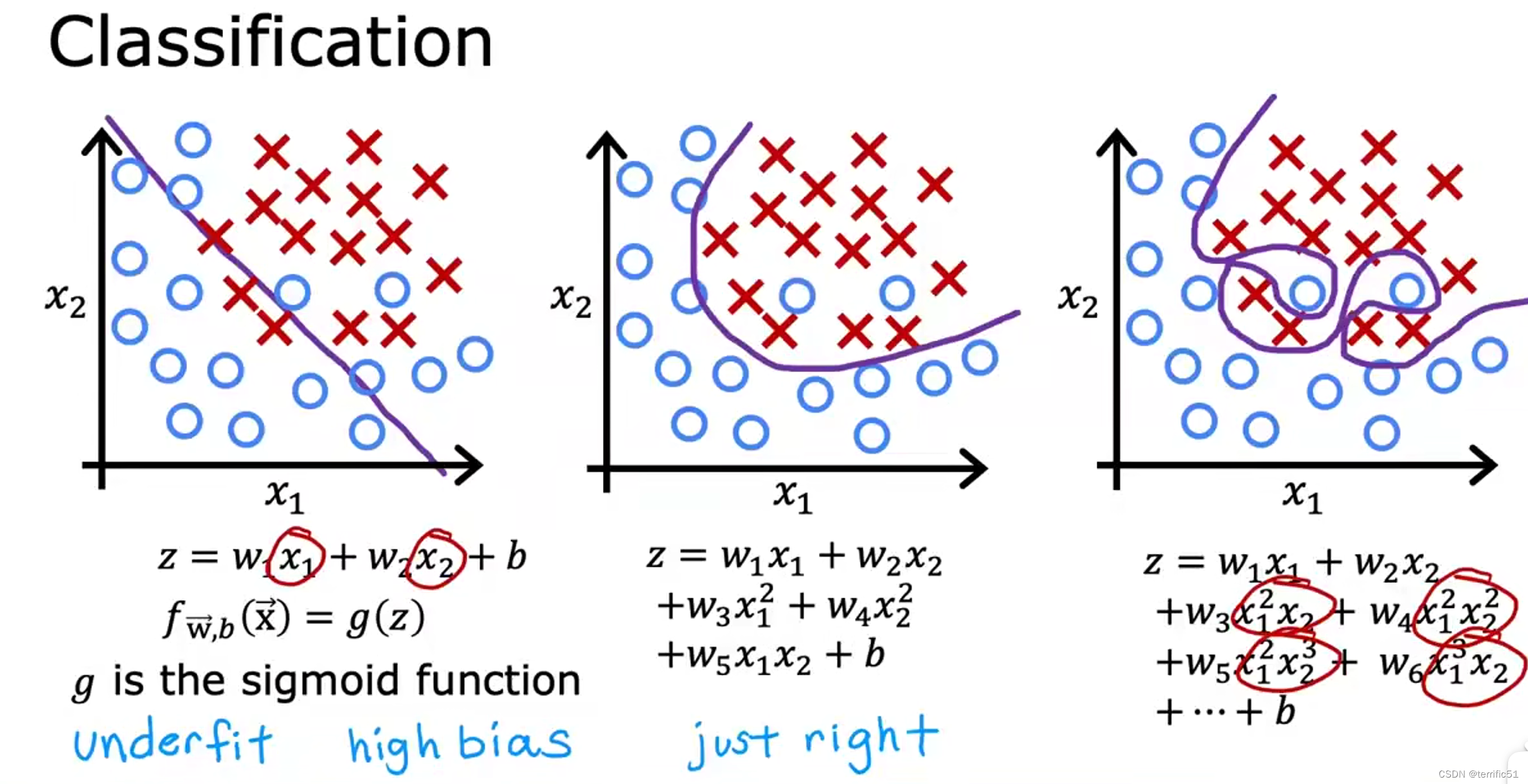
以上两种情况均为:
左图:欠拟合、高偏差
右图:过拟合、高方差(虽然数据拟合得很好,但不能较好地预测数据)
————————————————————————————————————
解决过拟合
- 1.收集更多地数据
- 2.选择合适特征用于预测任务算法
- 3.正则化

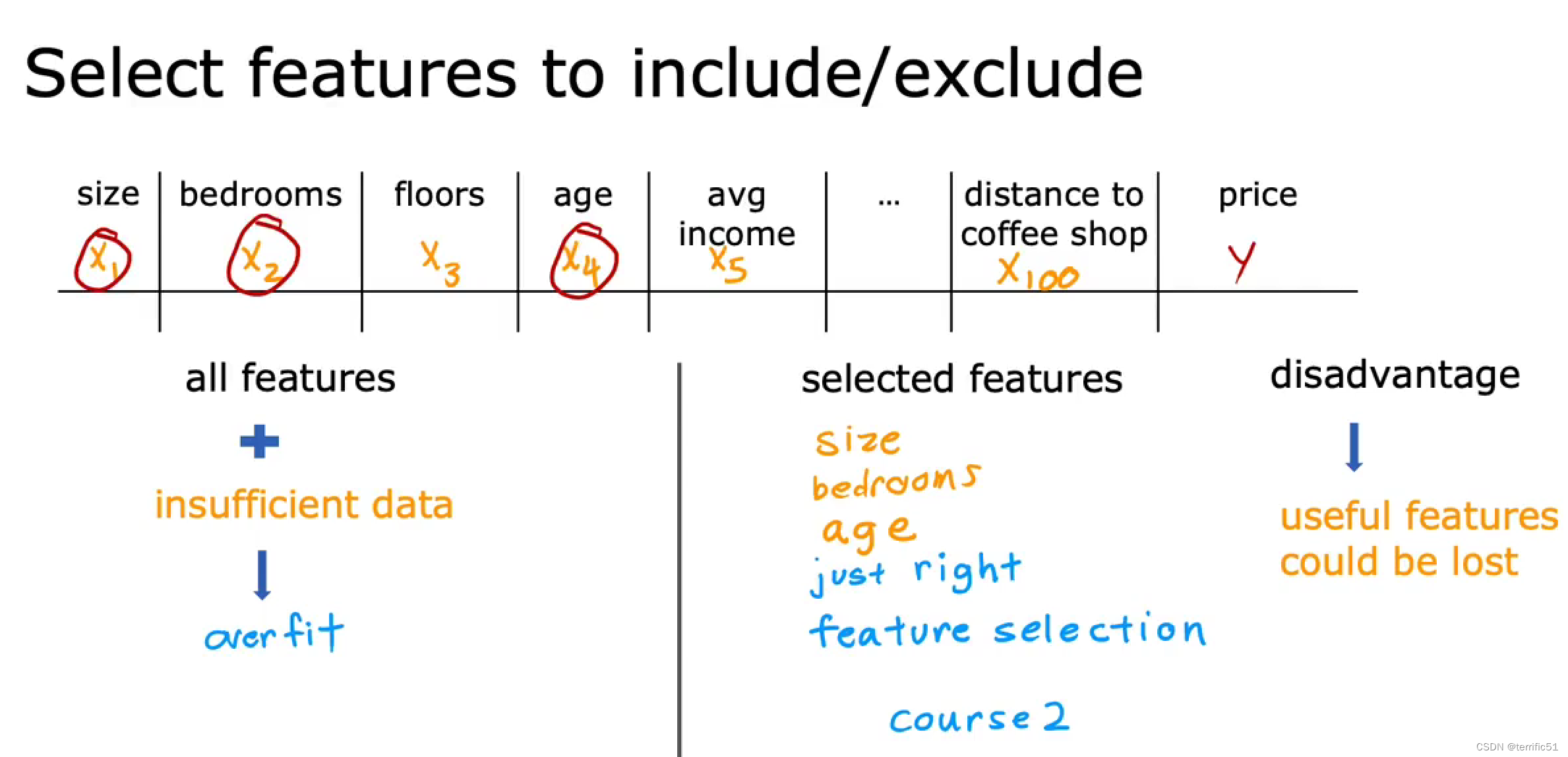
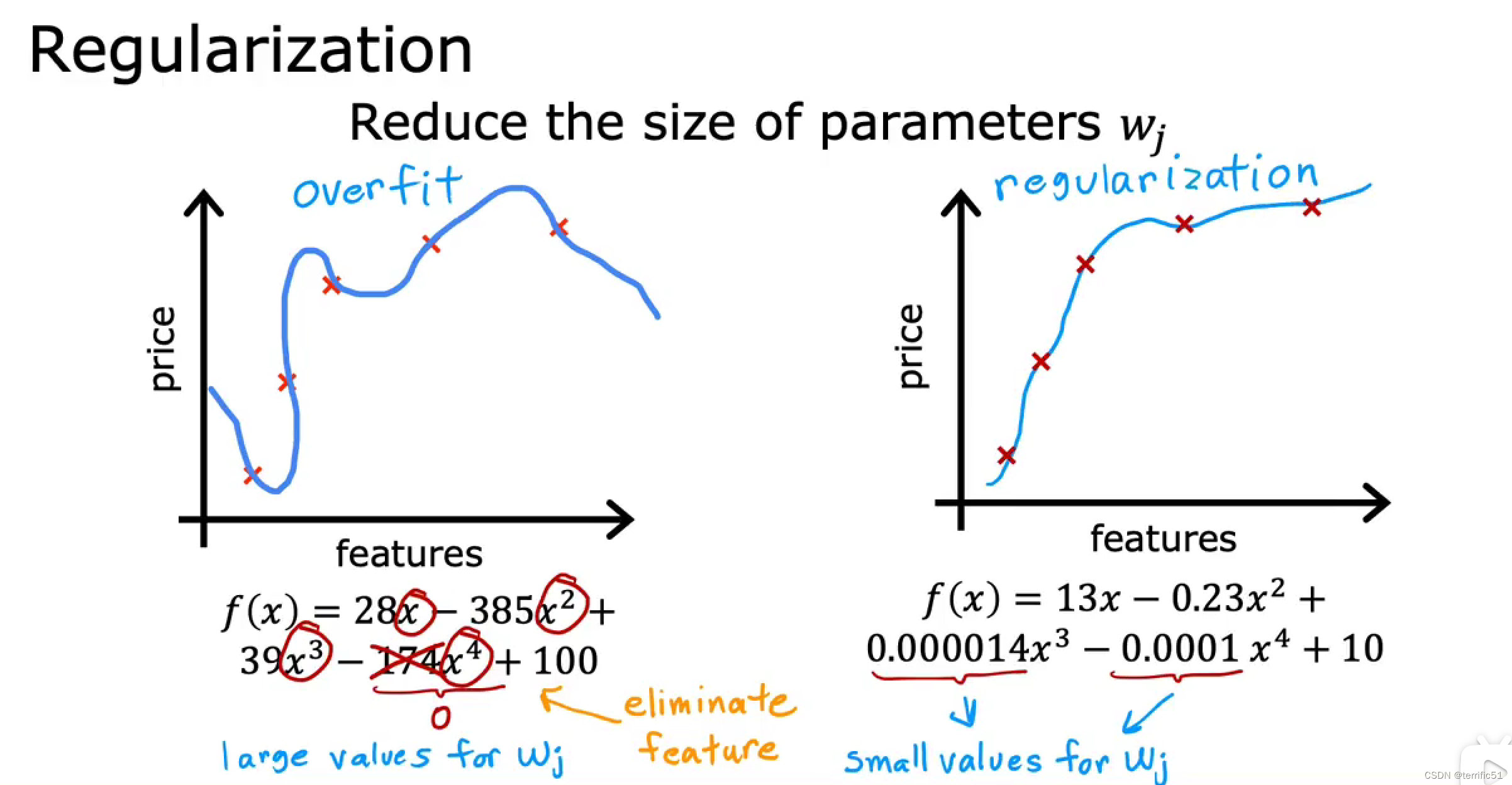
———————————————————————————

lambda,正则化参数
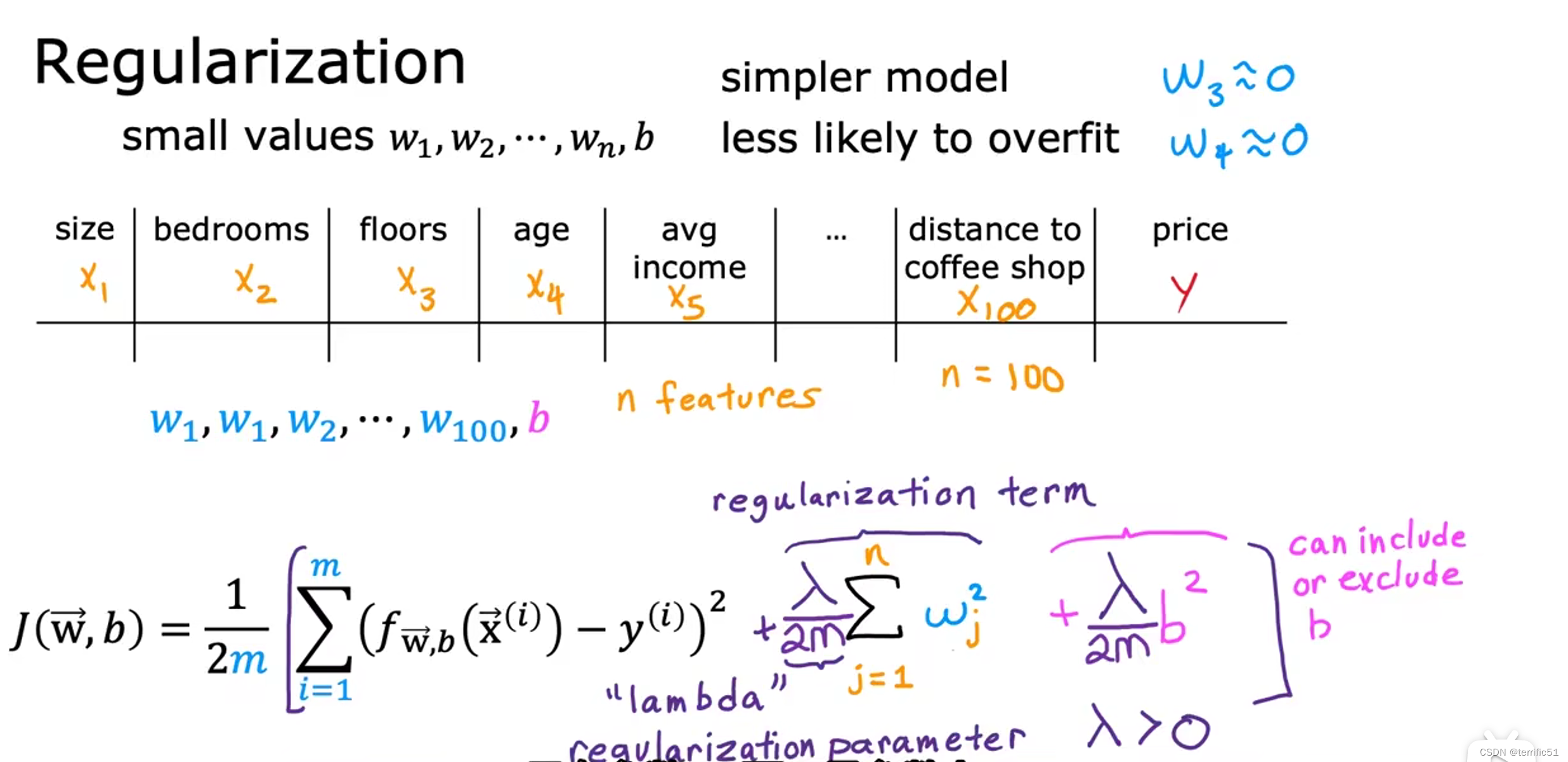
用于线性回归的正则方法

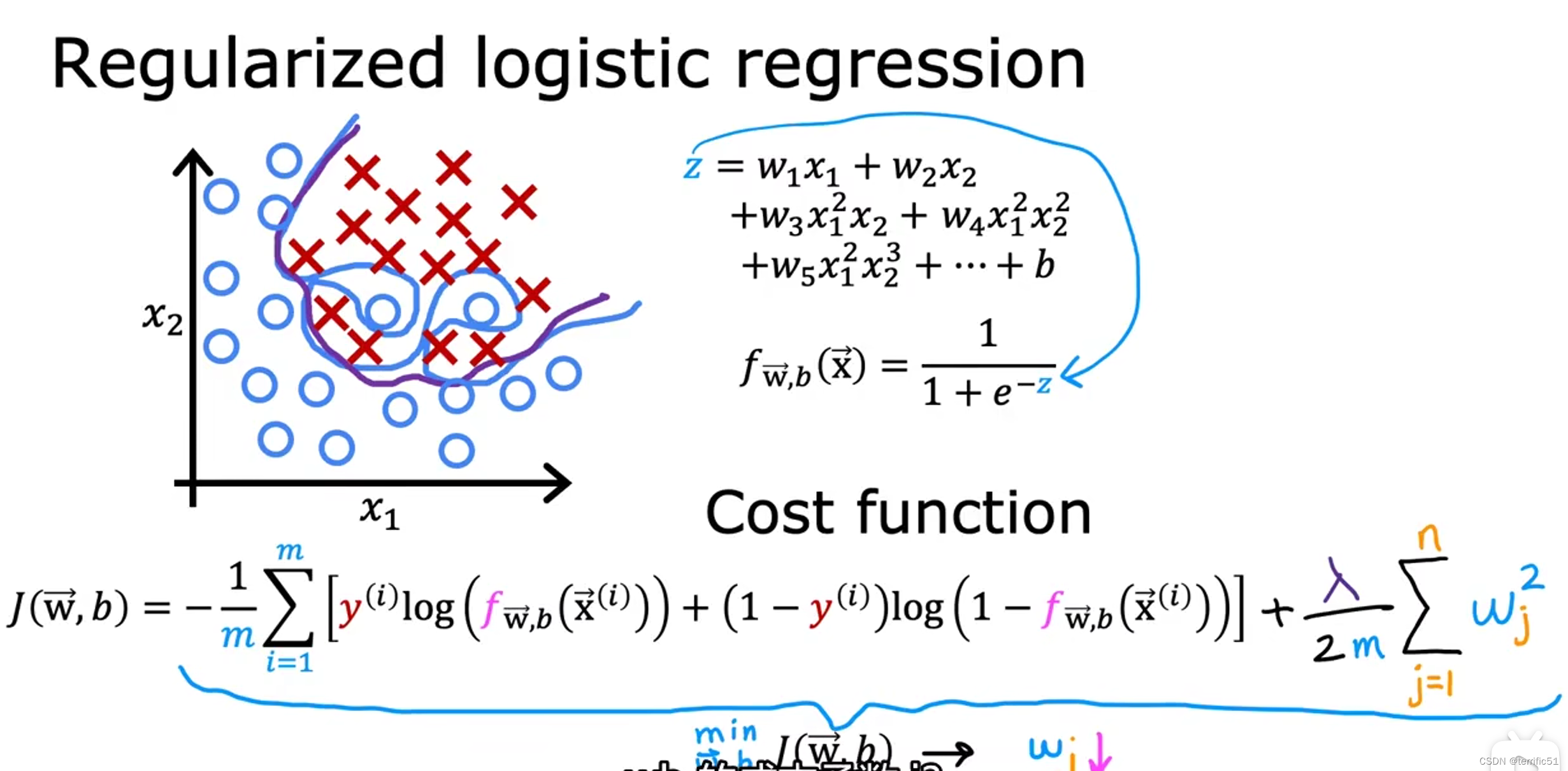
用于逻辑回归的正则方法
神经元和大脑

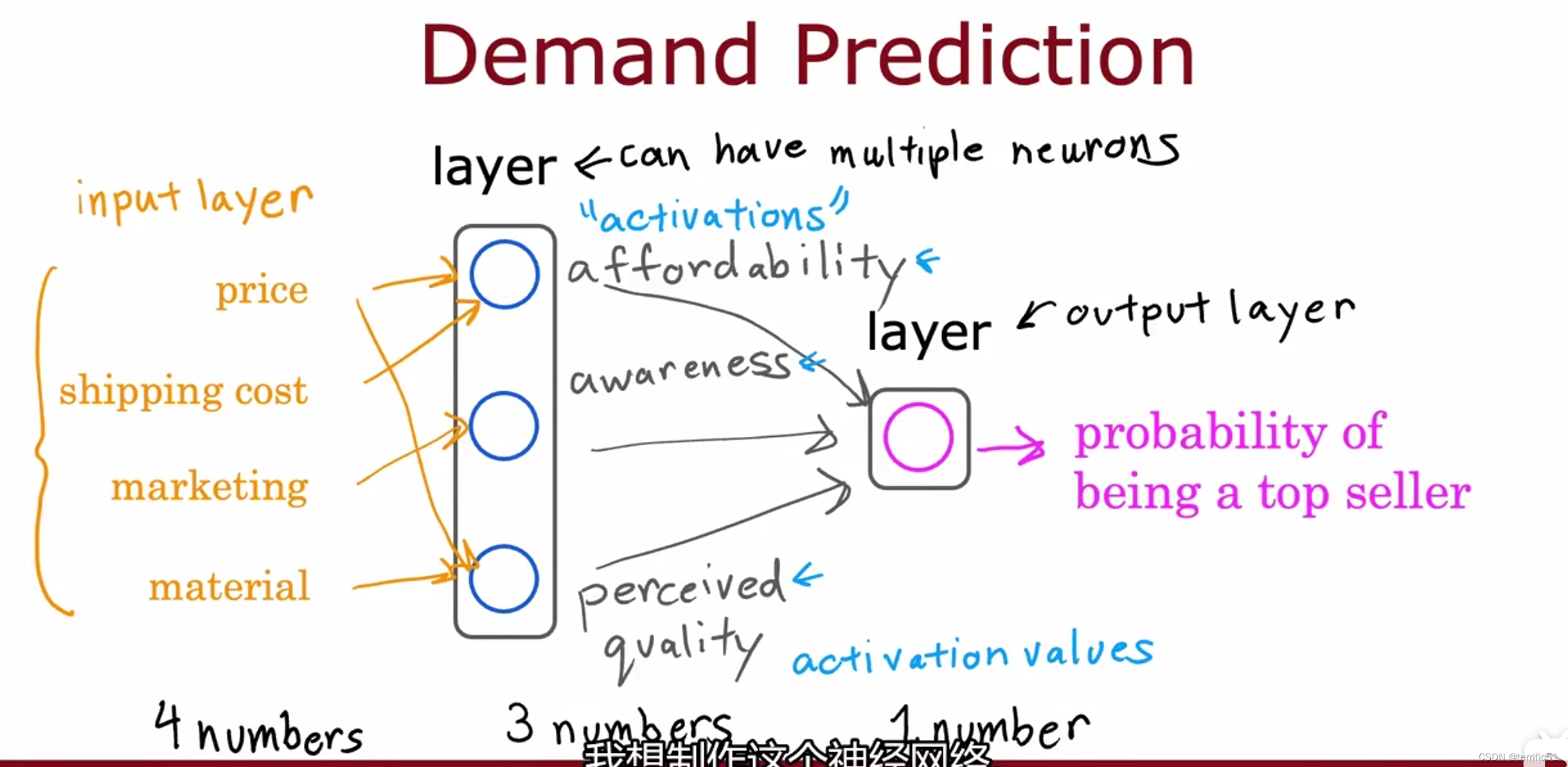
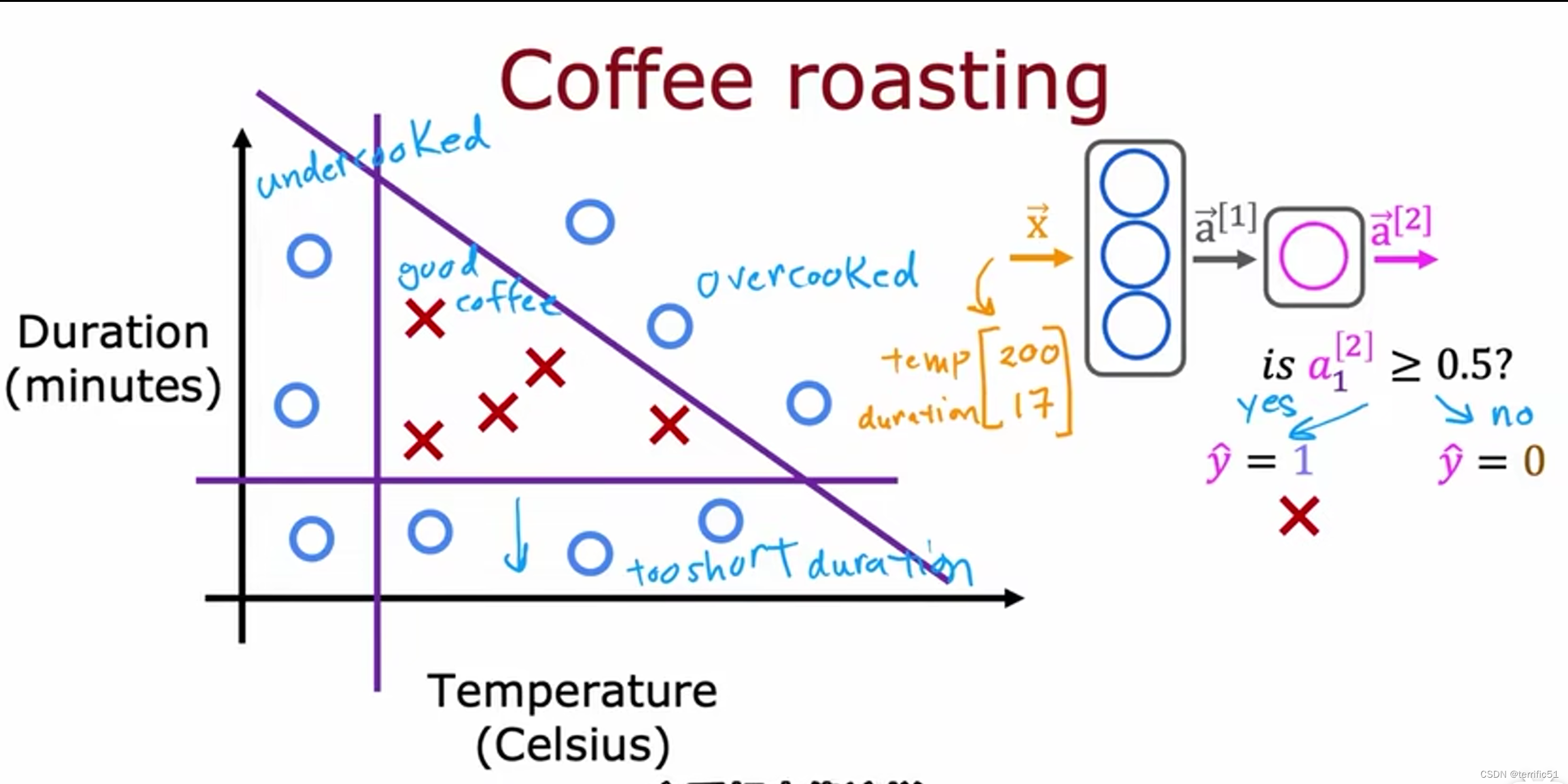
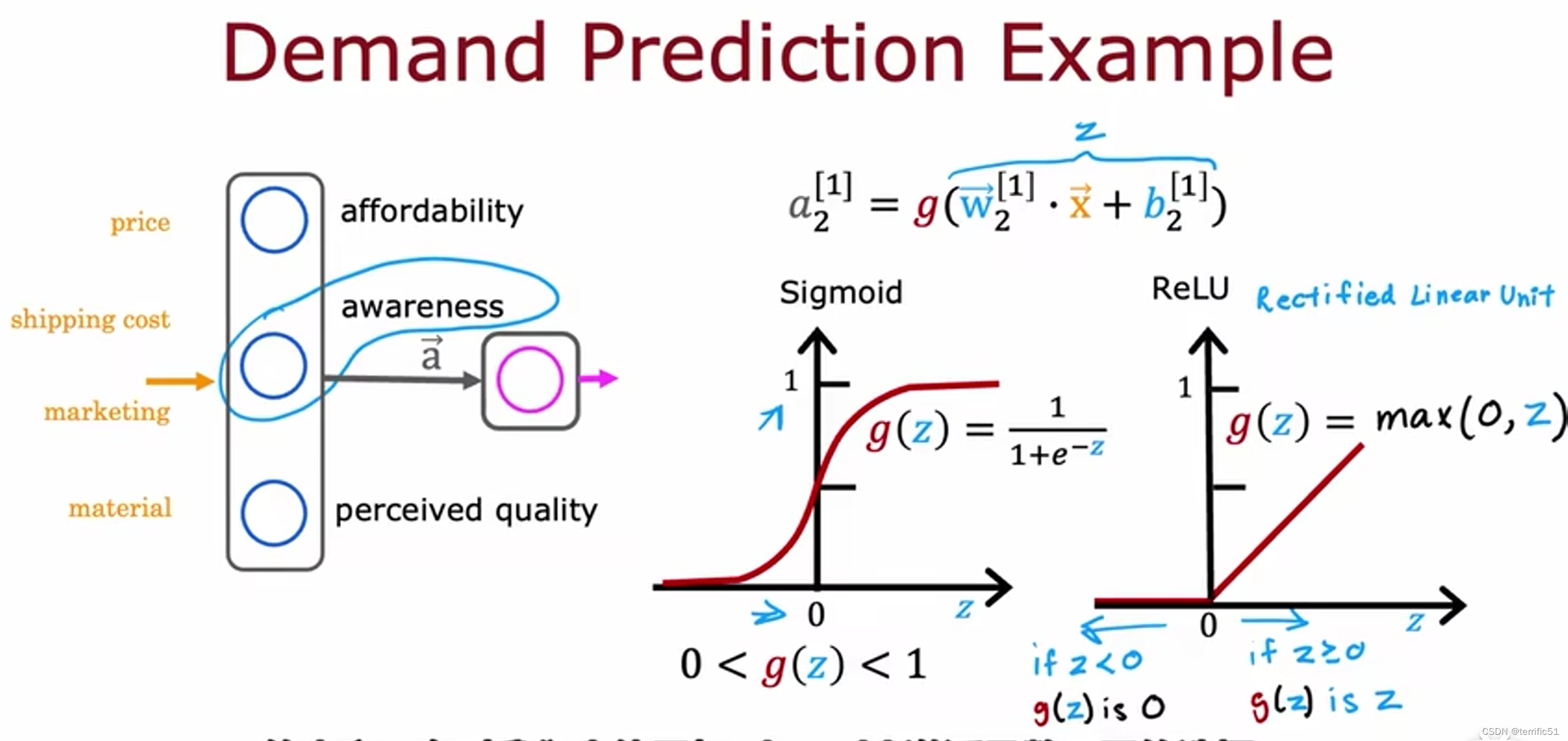
需求预测(神经网络的工作)
根据收集的数据判断T恤是否会成为畅销品。
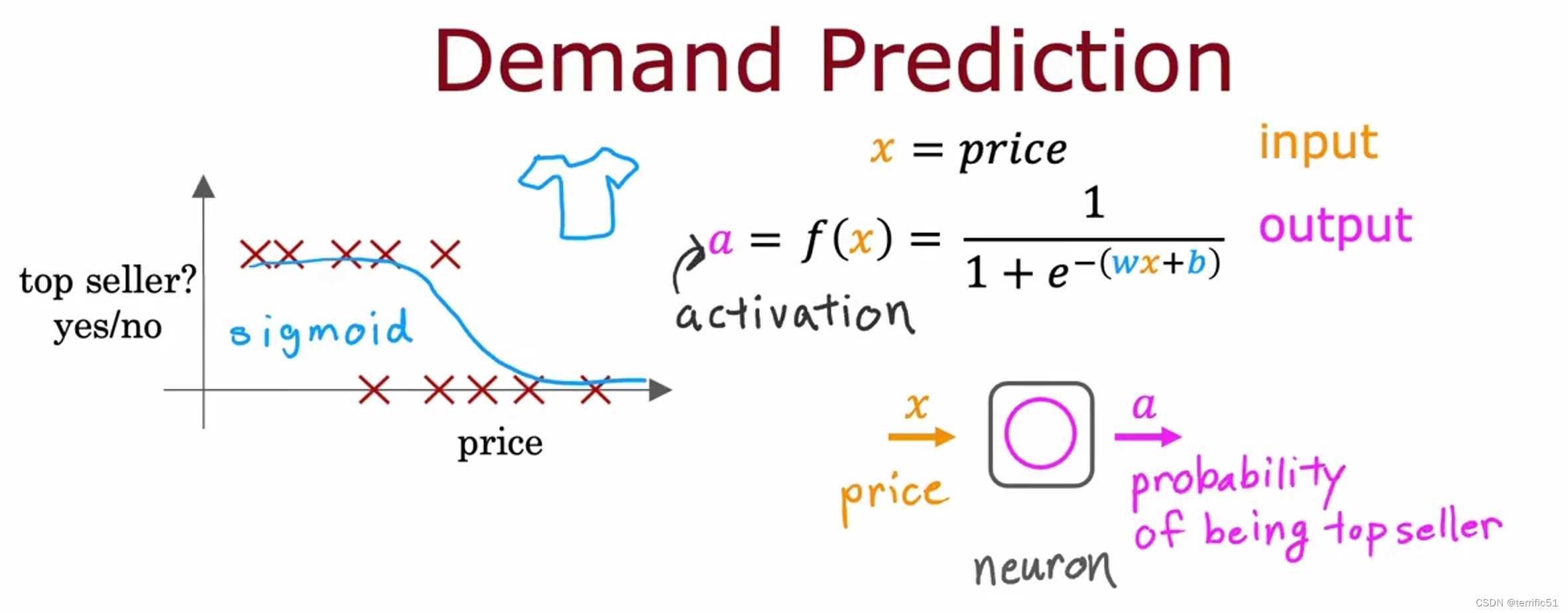
下面的例子中有四个特征判断T恤是否会成为畅销品。
创建一个人工神经网络进行预测(方法:逻辑回归)
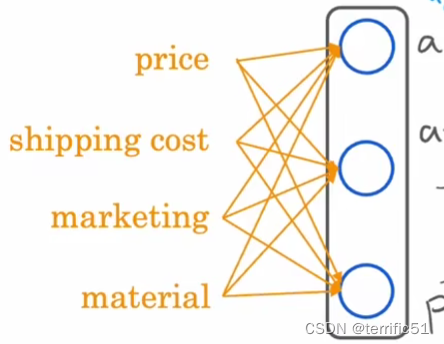
神经网络——输入四个特征(特征向量)->隐藏层->输出最终预测
有一个隐藏层
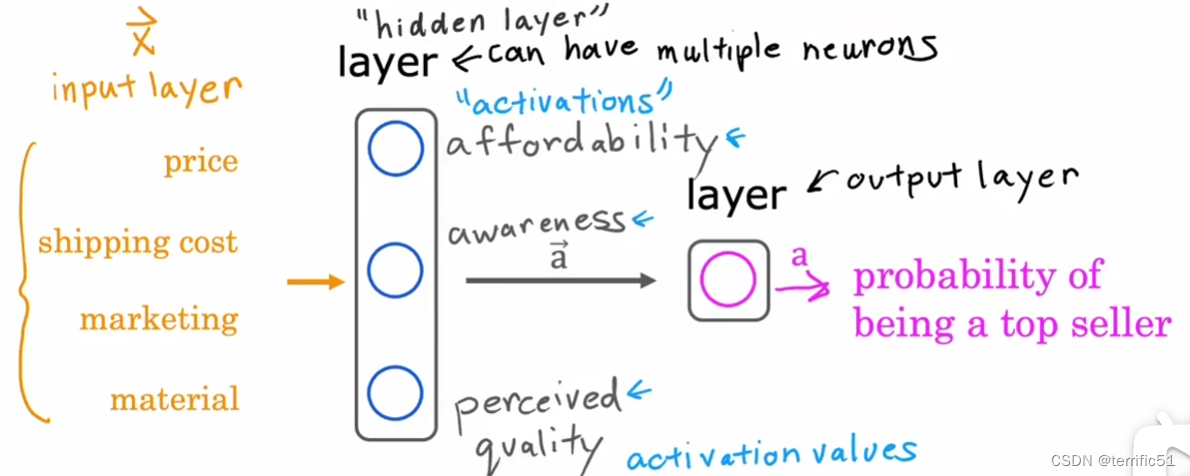
神经网络的骨架
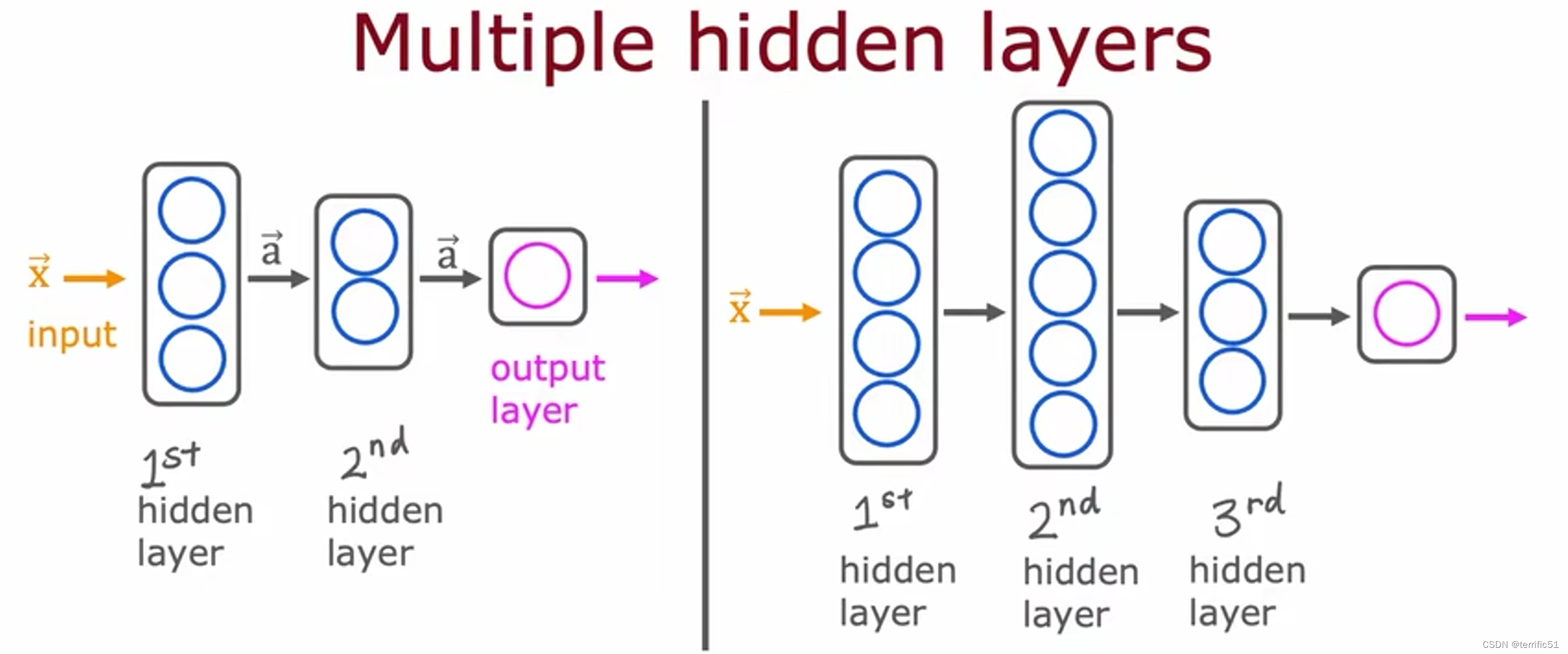
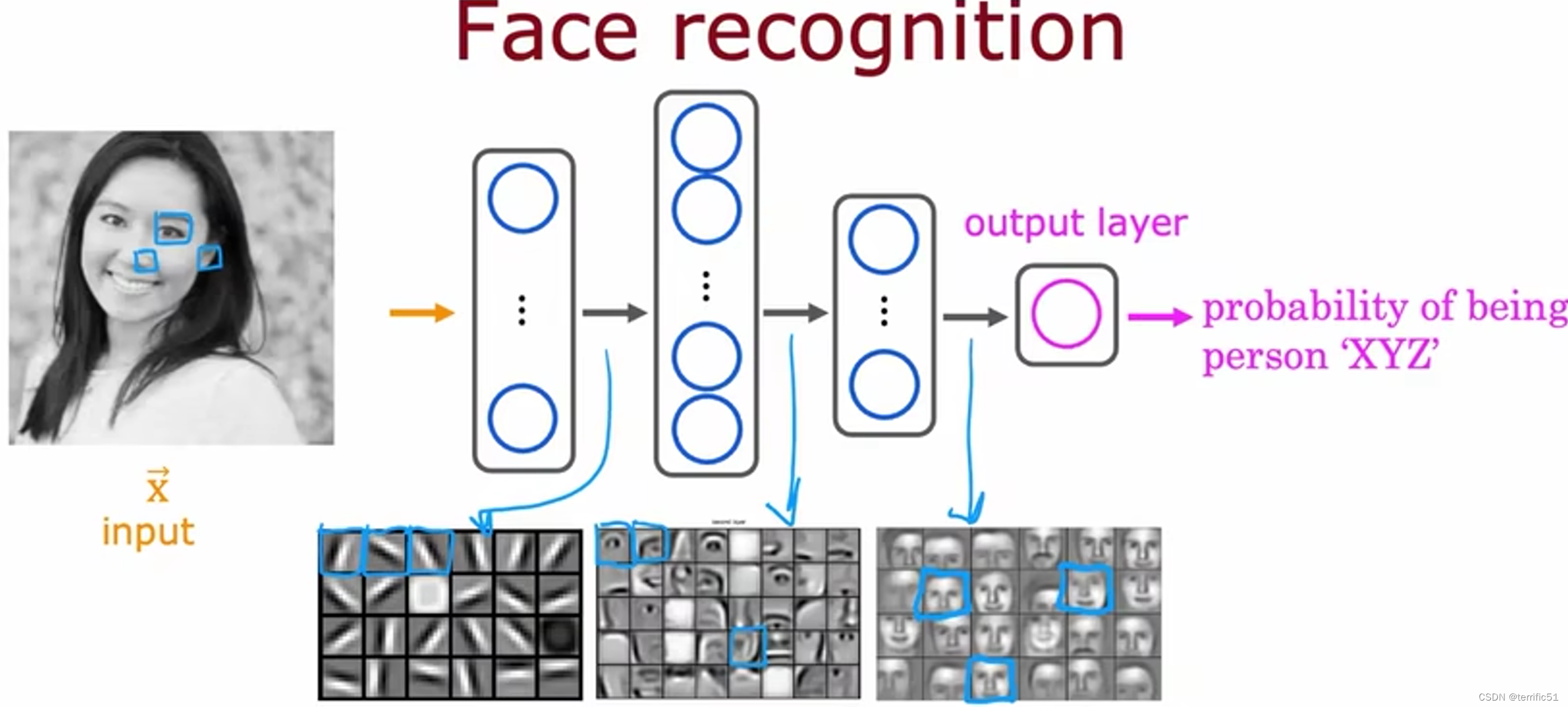
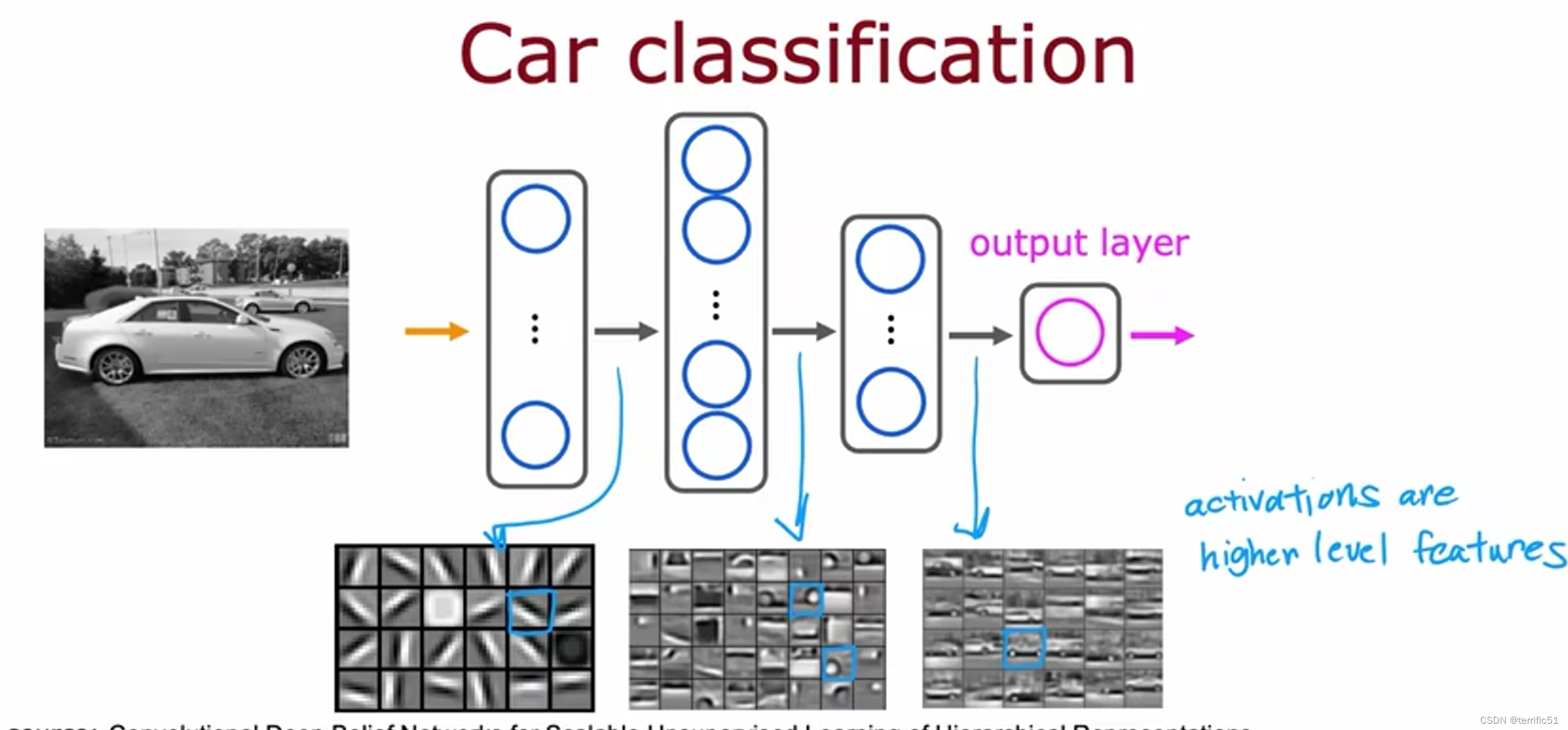
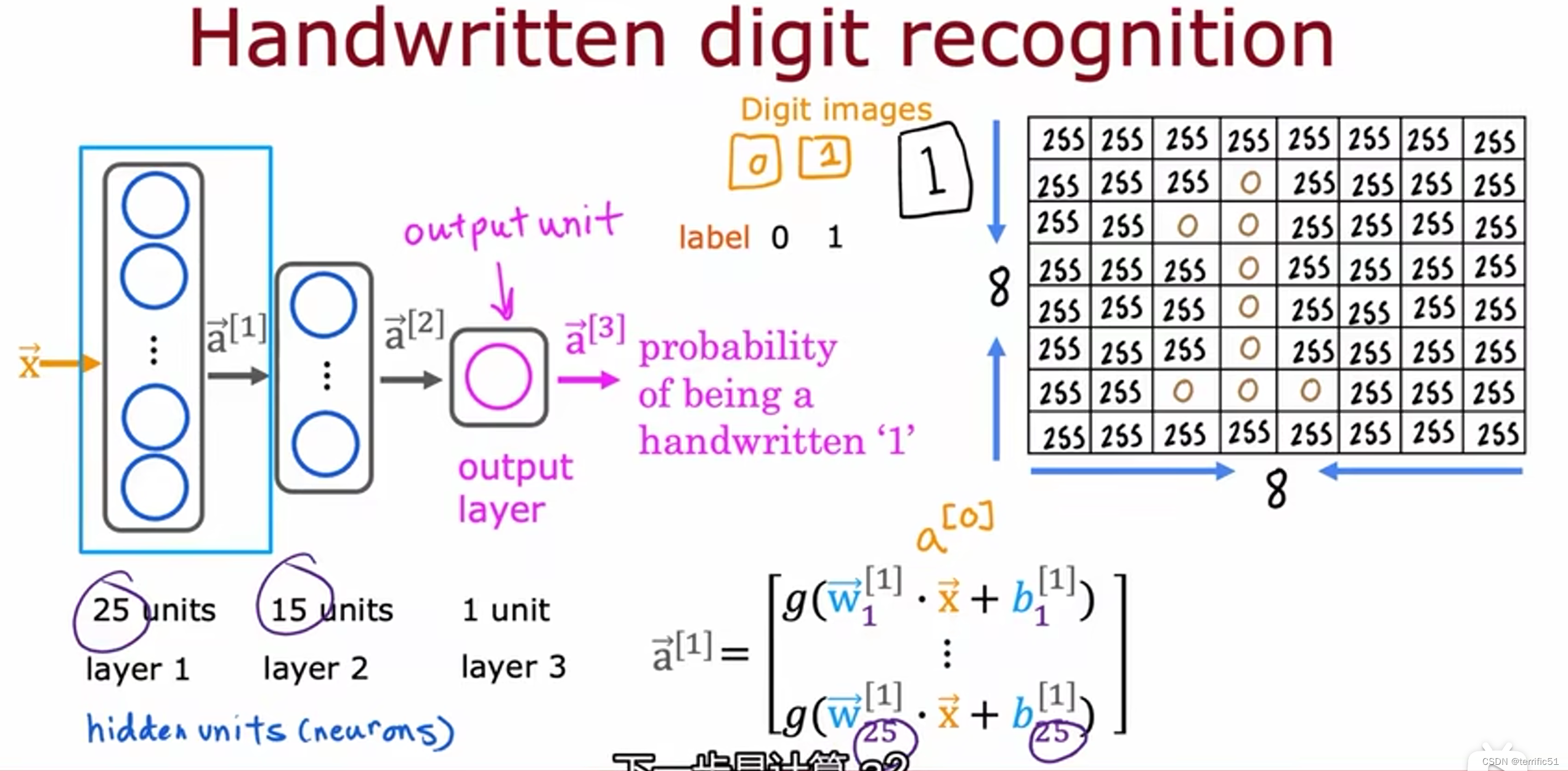
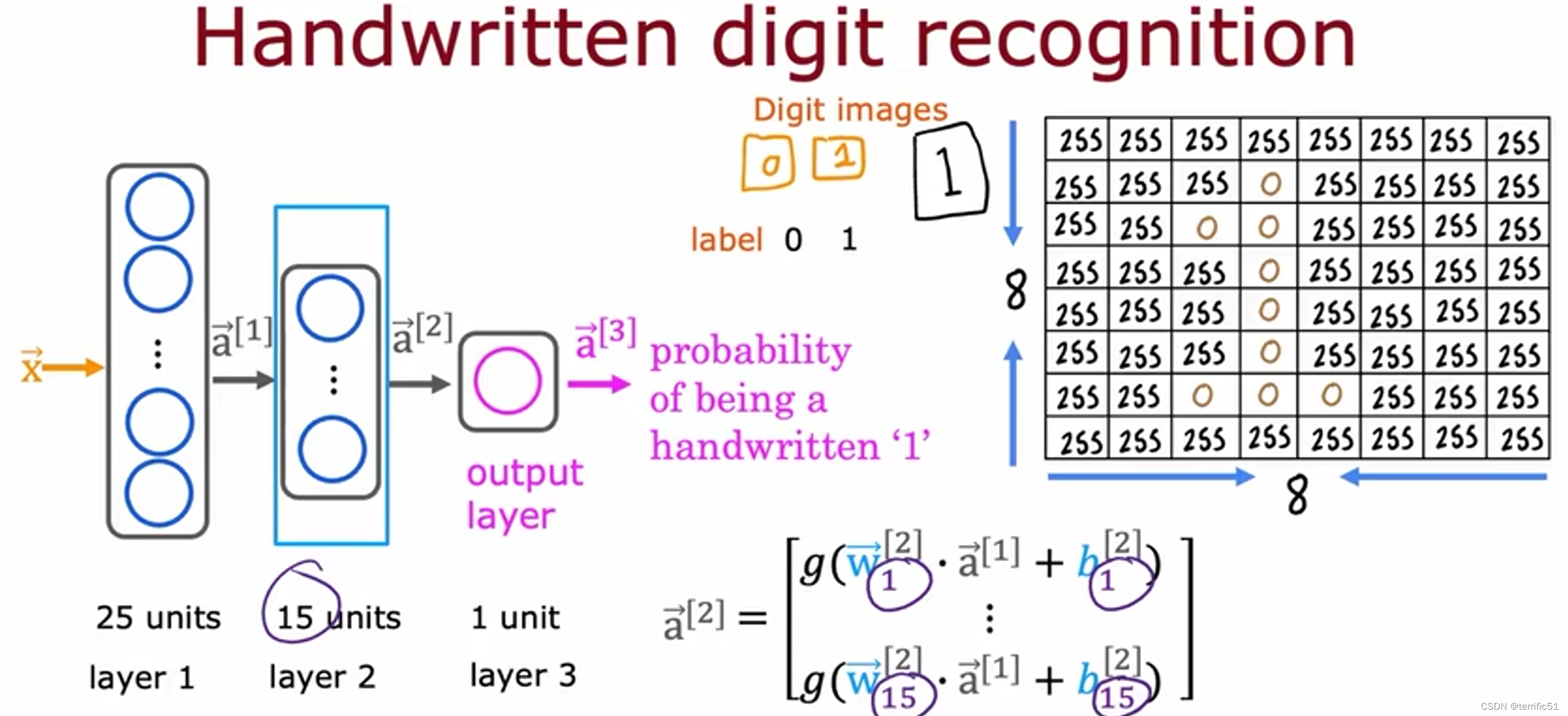
举例:图像感知
提供数据,神经网络便会自动学习检测不同的特征以便尝试预测任务的训练。
神经网络中的网络层
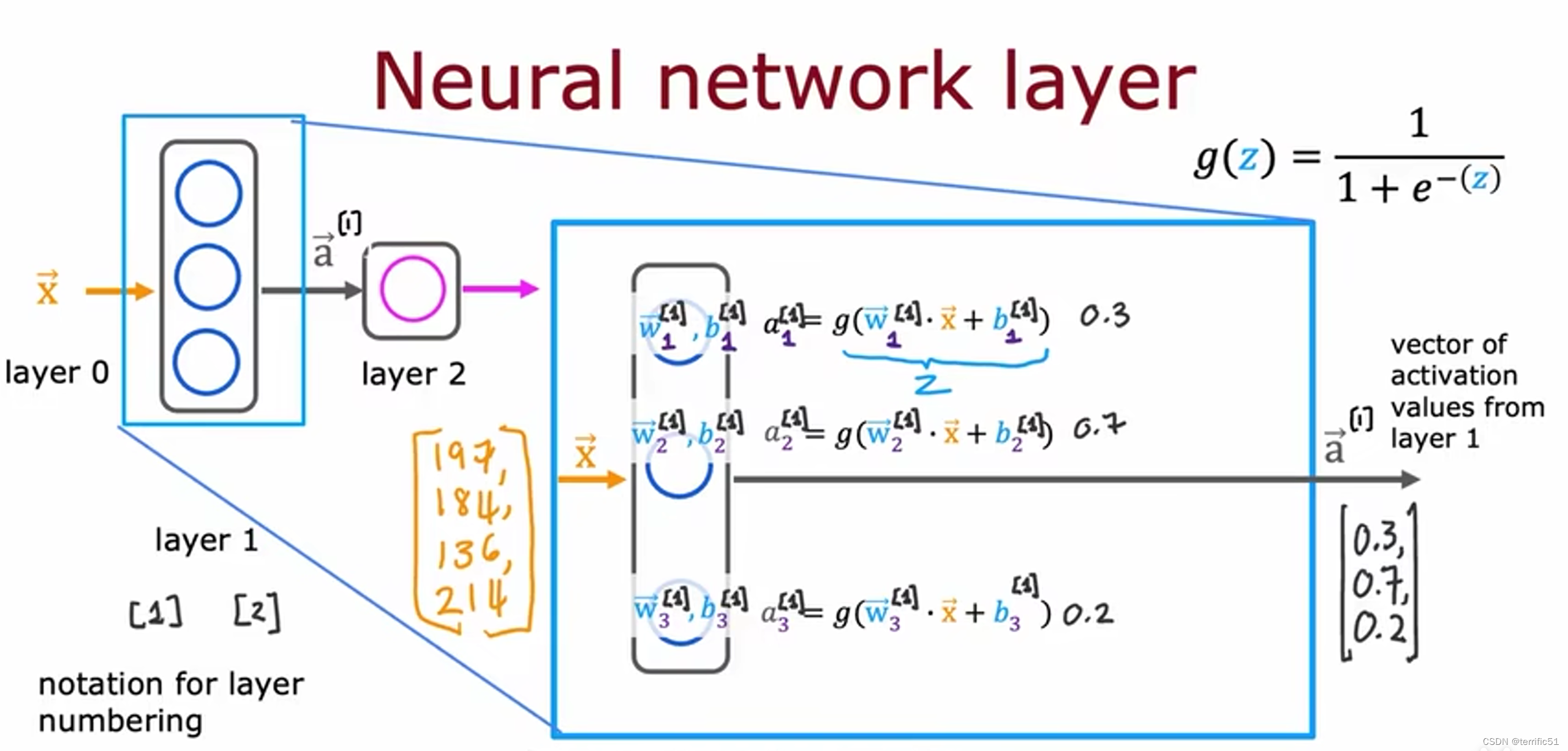
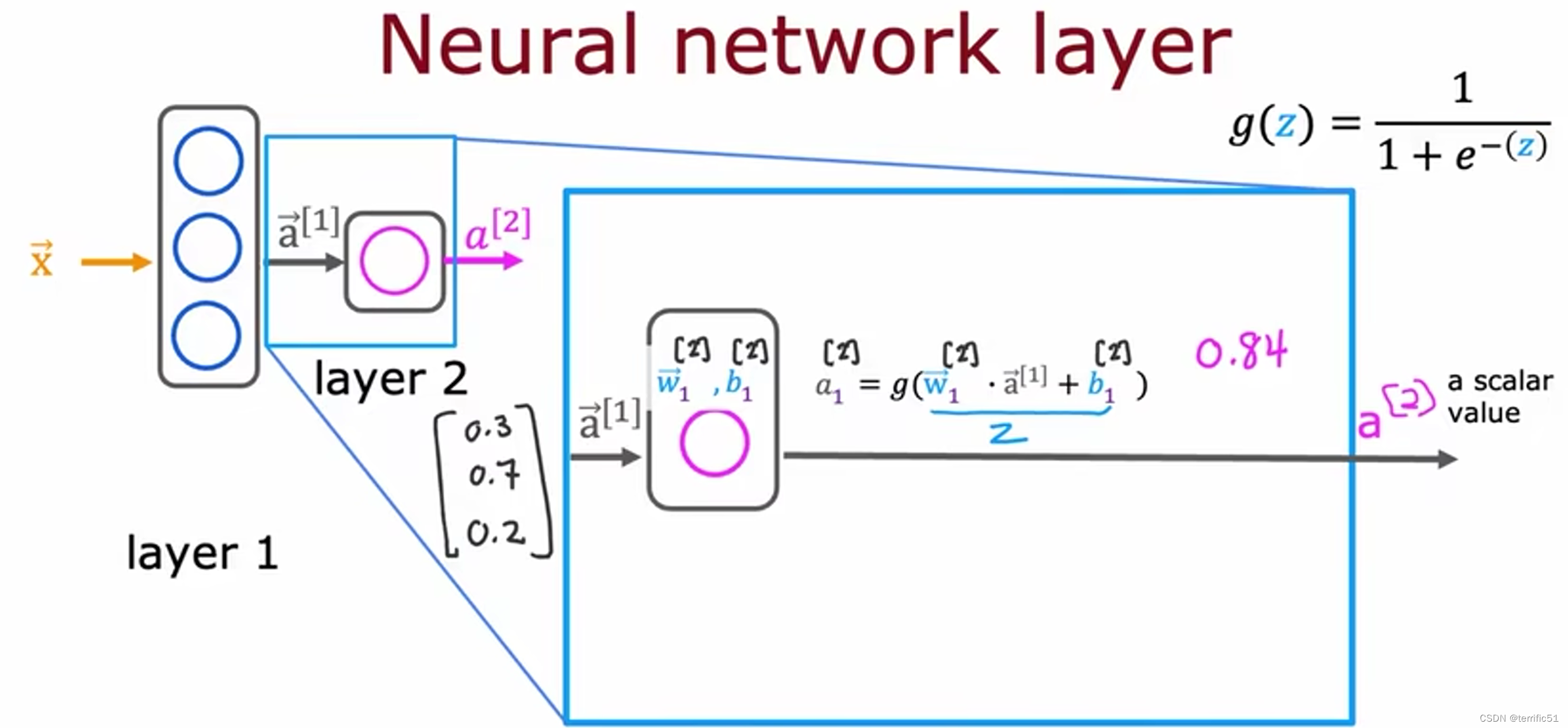
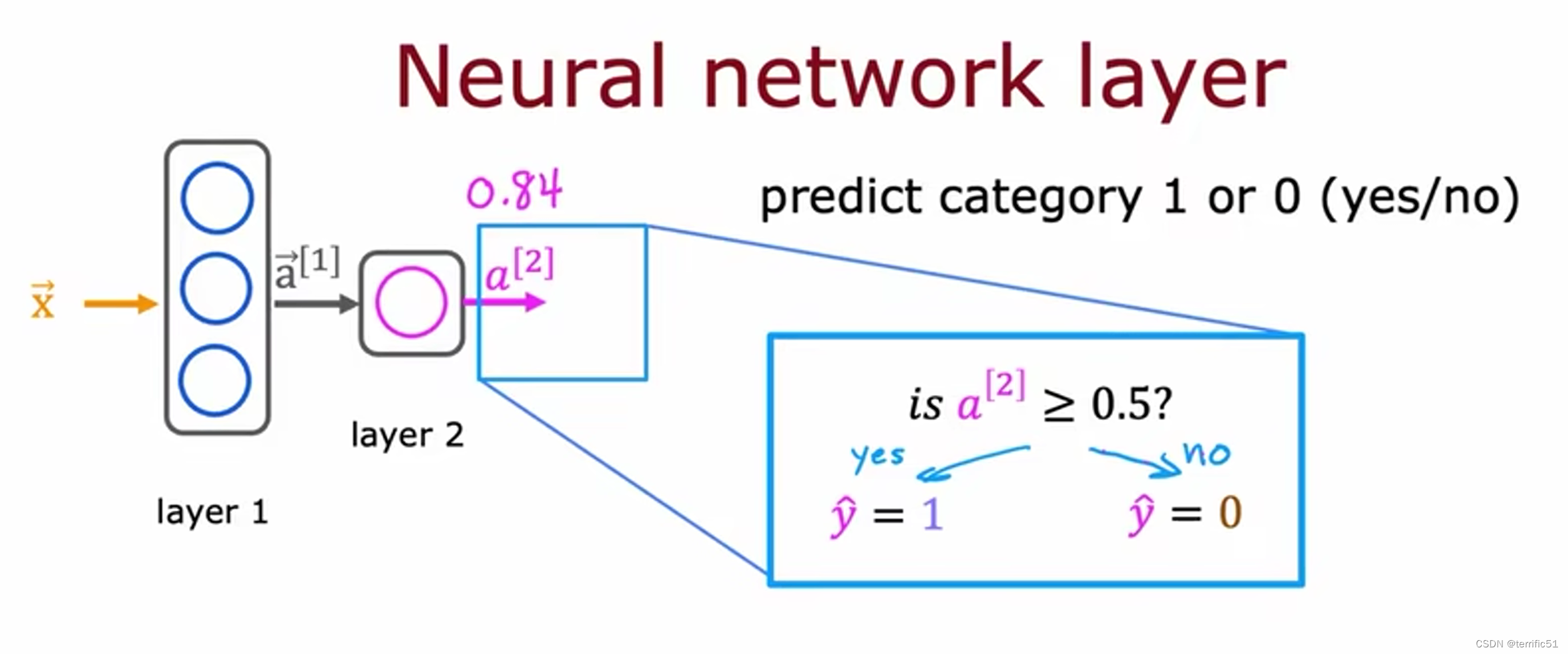
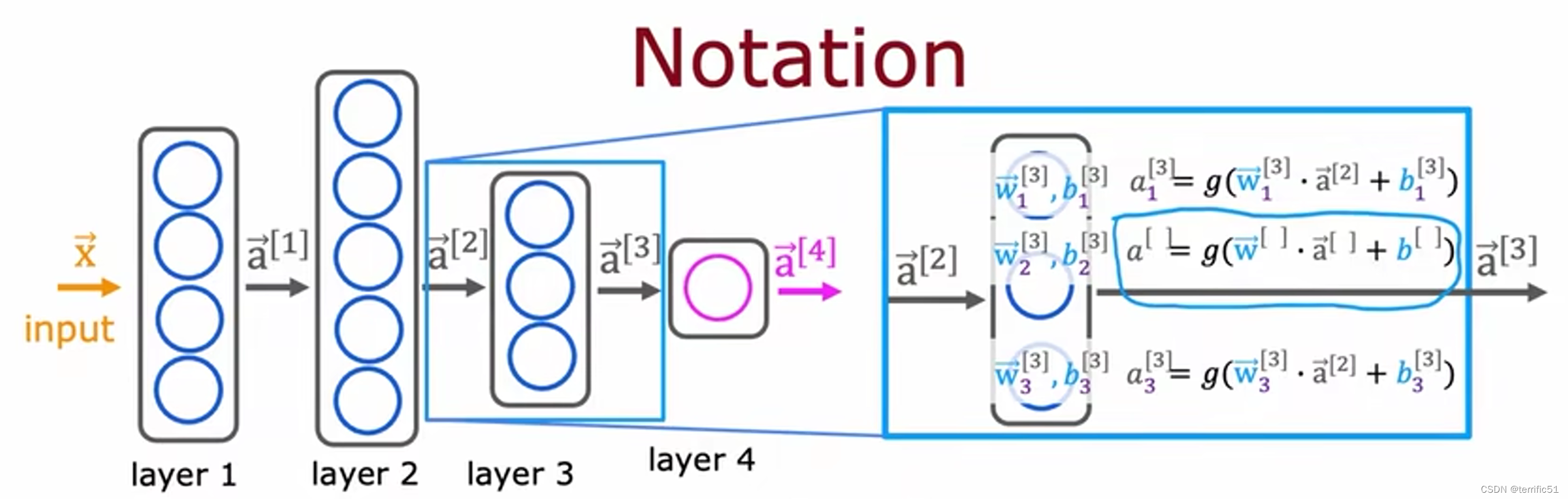
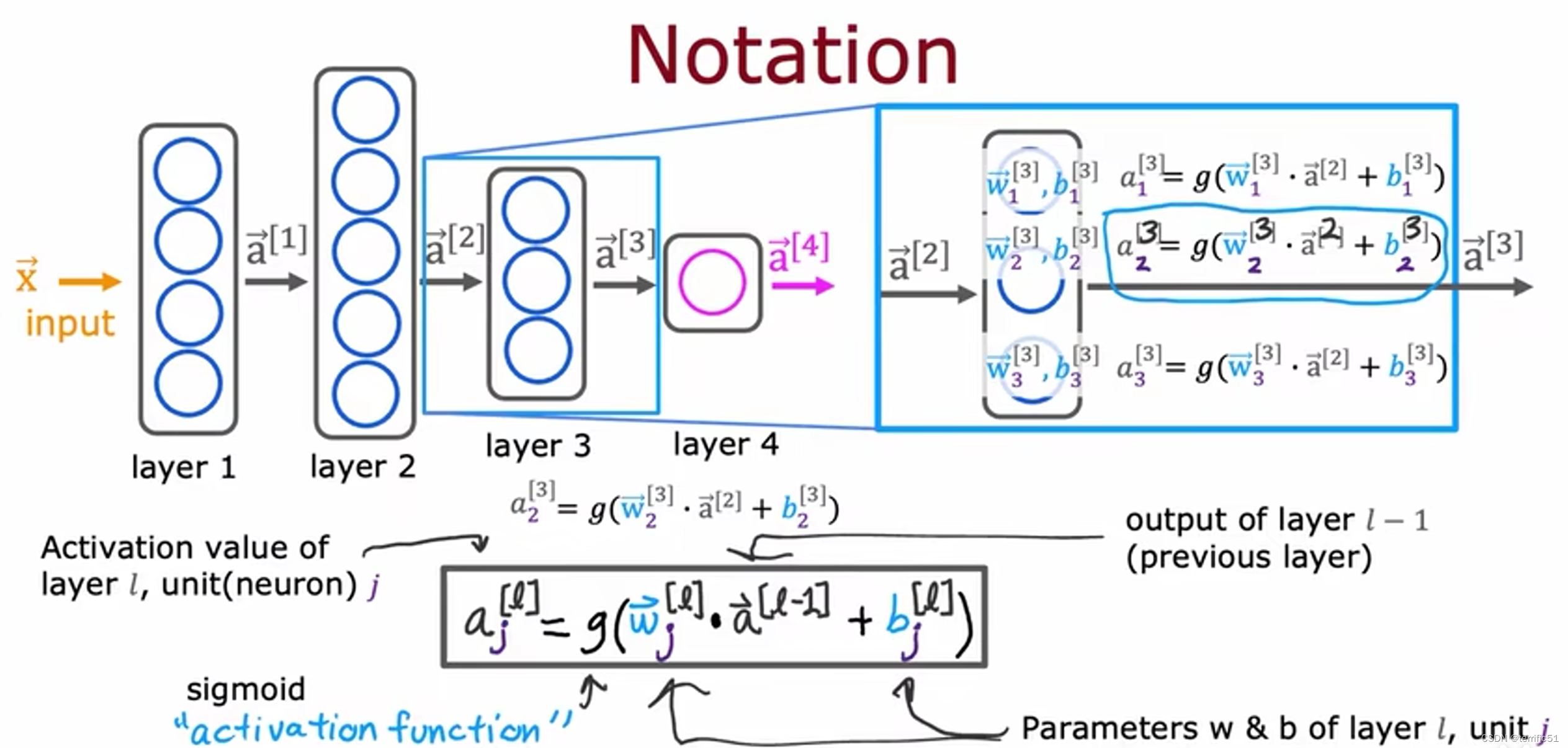
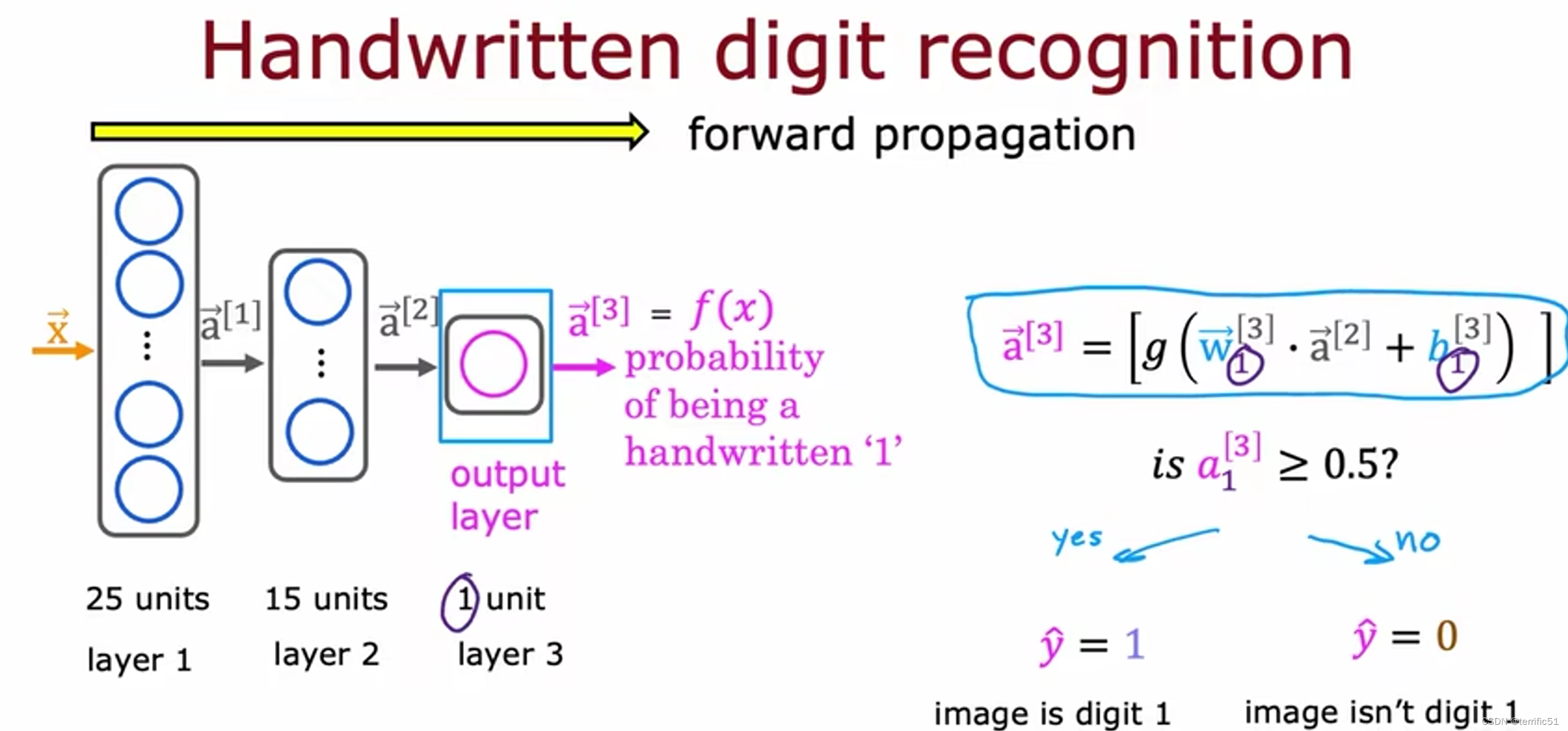
神经网络前向传播
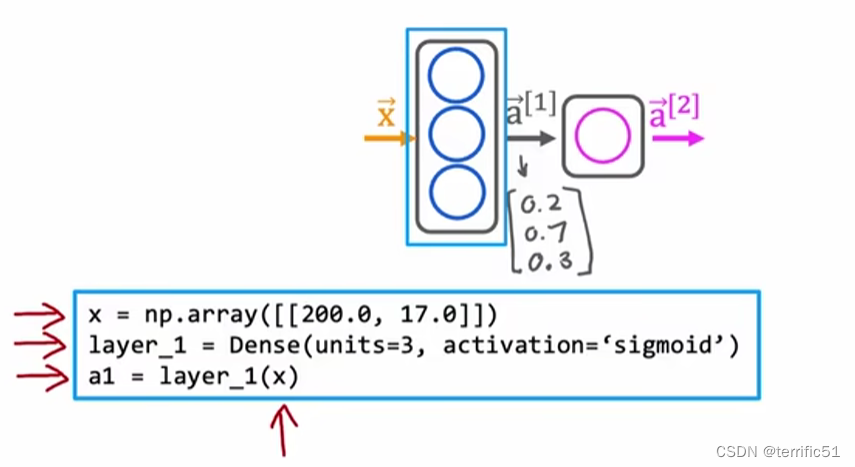
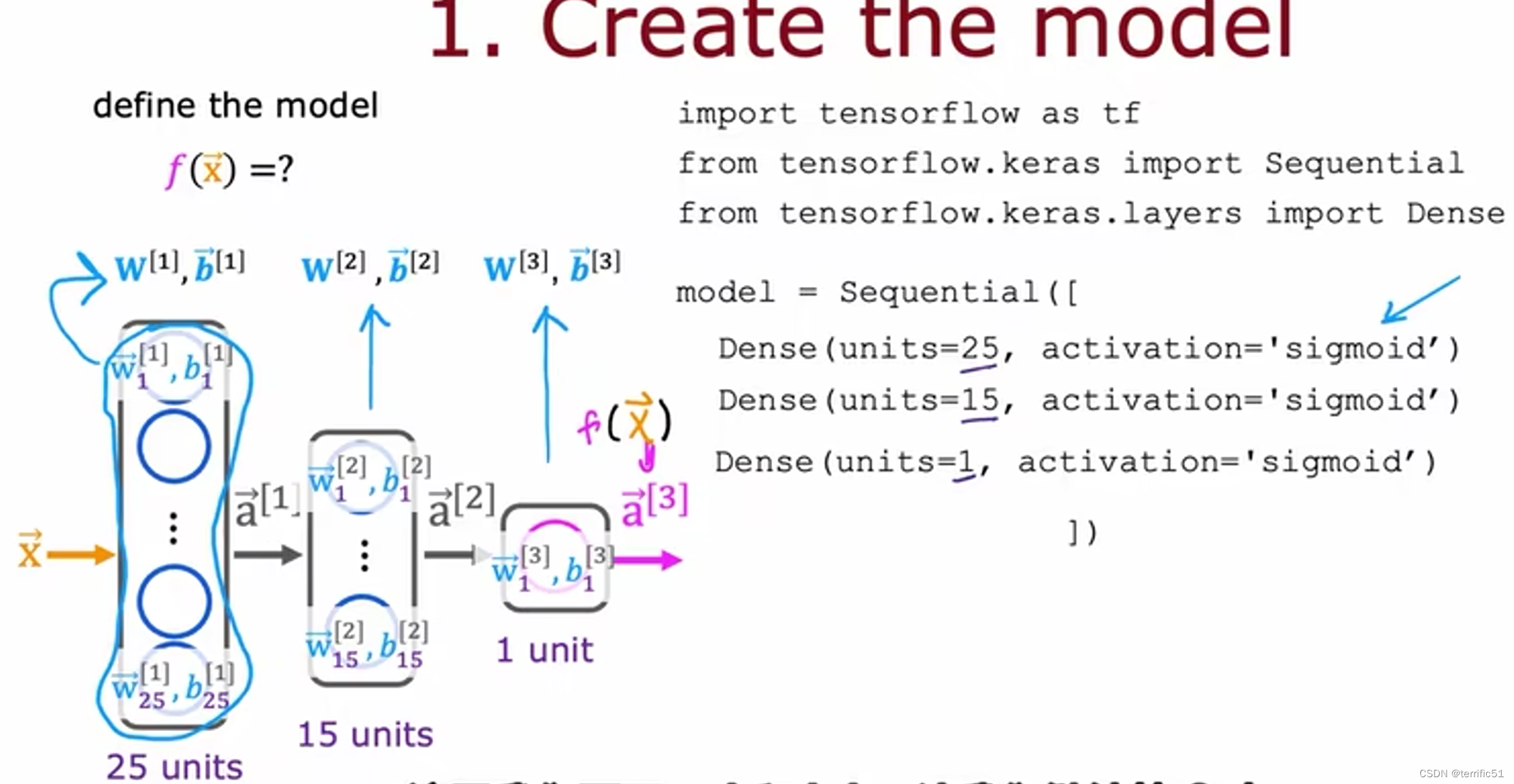
TensorFlow 实现推理代码
第一层:密集元素为3,激活隐藏层。
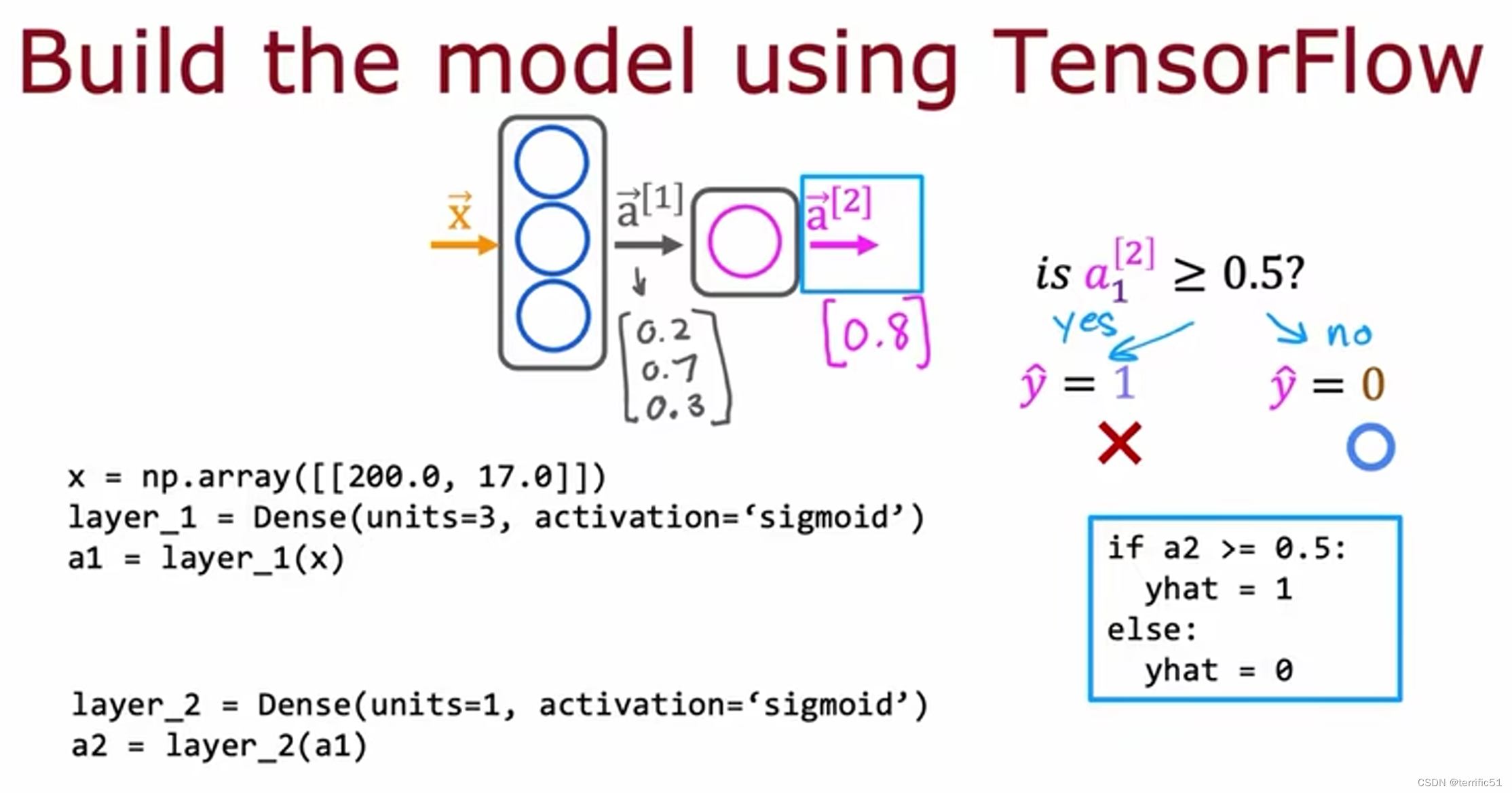

TensorFlow中数据形式


上图最后一行只是一个没有行或列的线性数组,是一个数字列表。
TensorFlow旨在处理非常大的数据集,并通过在矩阵而不是一维数组中表示数据。

Tensor是TensorFlow团队创建的一种数据类型,用于有效地存储和执行矩阵计算。
a1.numpy()它将获取相同的数据并以Numpy数组的形式返回。

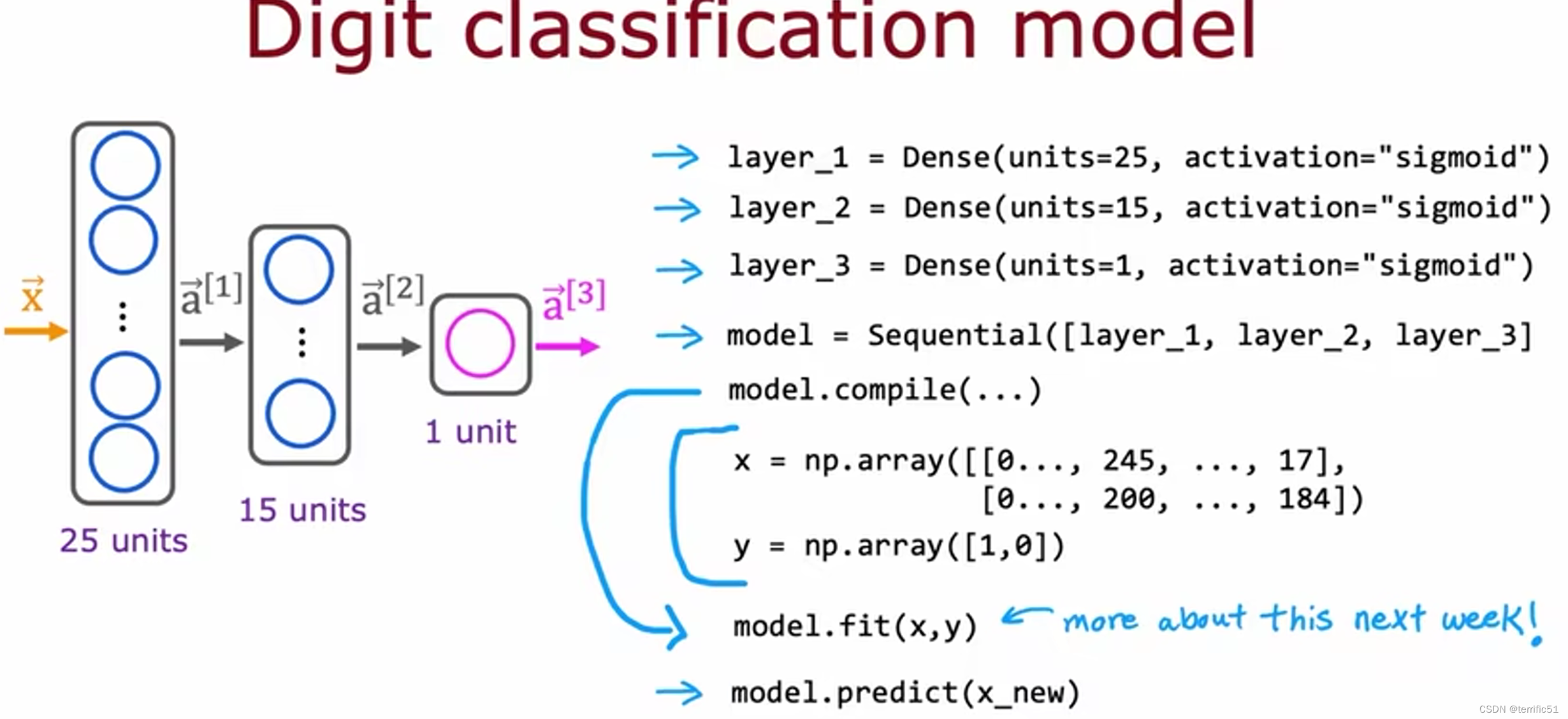
搭建一个神经网络

通过顺序将创建的两个层串联在一起。

X、Y存储在此矩阵X和数组Y中。
 在X_new上调用模型预测和给定X的输入值。
在X_new上调用模型预测和给定X的输入值。

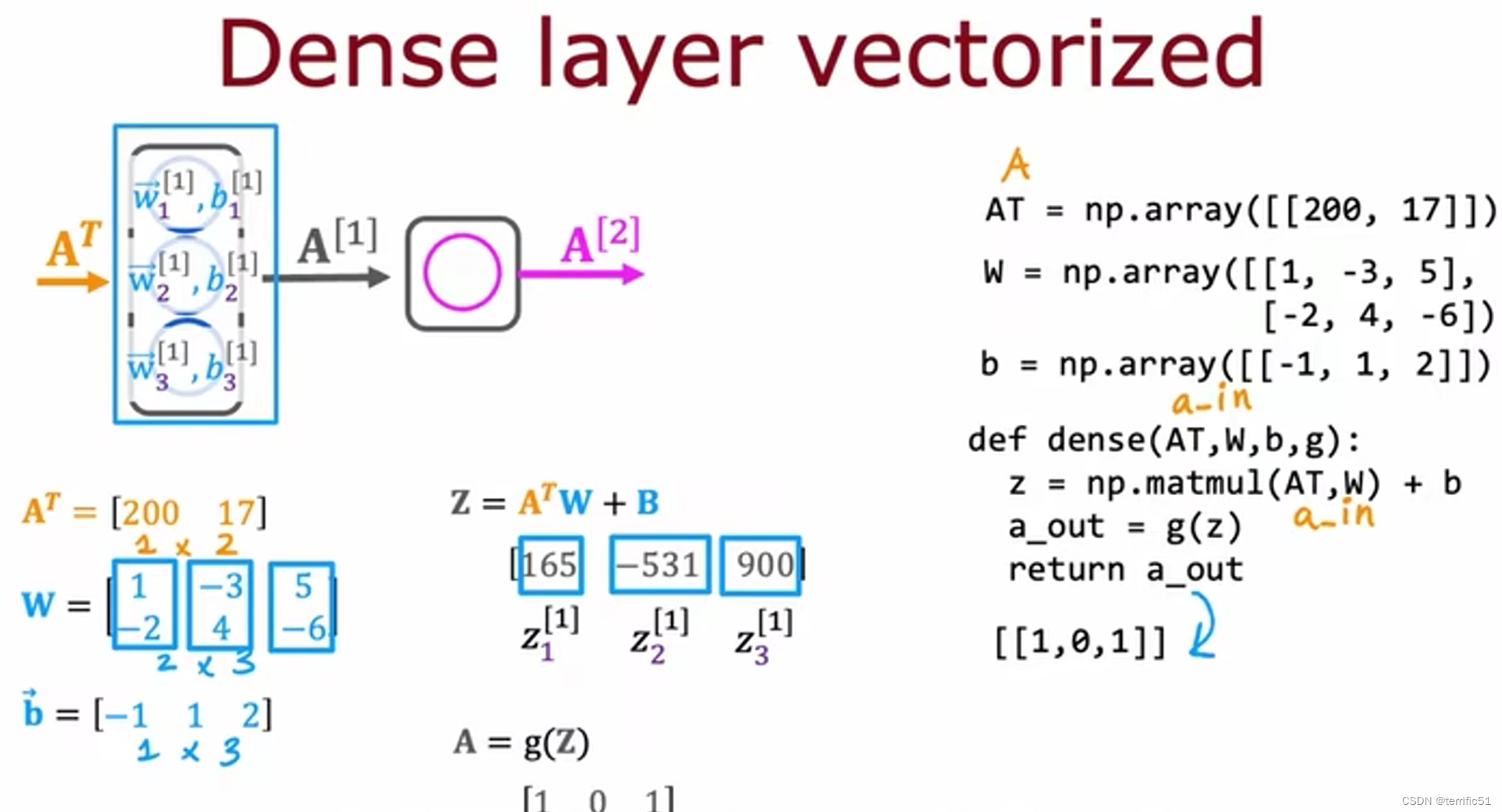
单个网络层上的前向传播

前向传播的一般实现
编写一个函数来实现一个密集层(神经网络的单层)
定义密集函数作为输入

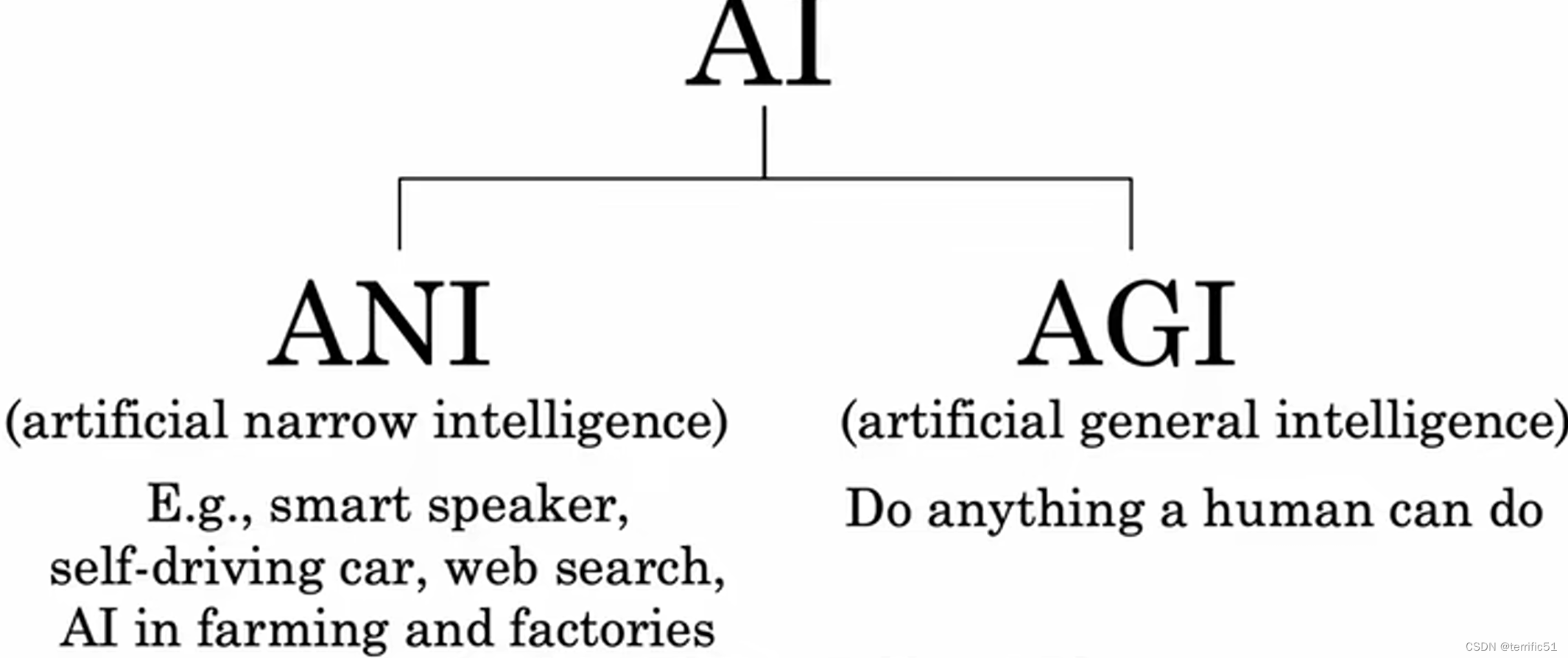
强人工智能
神经网络为何如此高效

矩阵乘法代码

TensorFlow实现
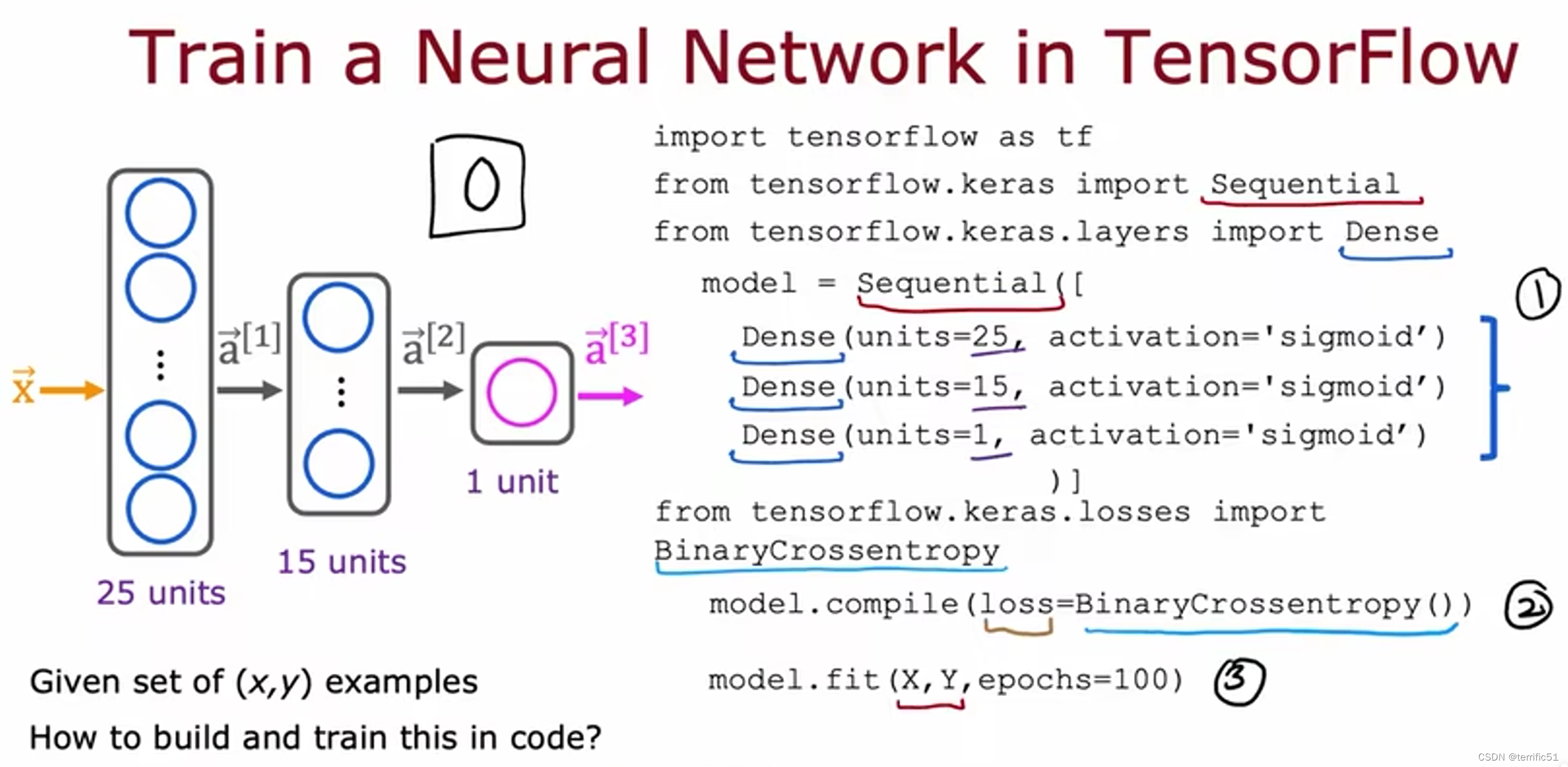
1.TensorFlow将神经网络的这三层顺序串在一起;
2.让TensorFlow编译模型
3.调用fit函数拟合
Epoch 是一个技术术语,表示您可能想要运行多少步来创建下降。
模型训练细节(训练逻辑回归/神经网络)
1.指定如何在给定输入X和参数情况下计算输出;
2.指定损失和成本;
3.最小化。



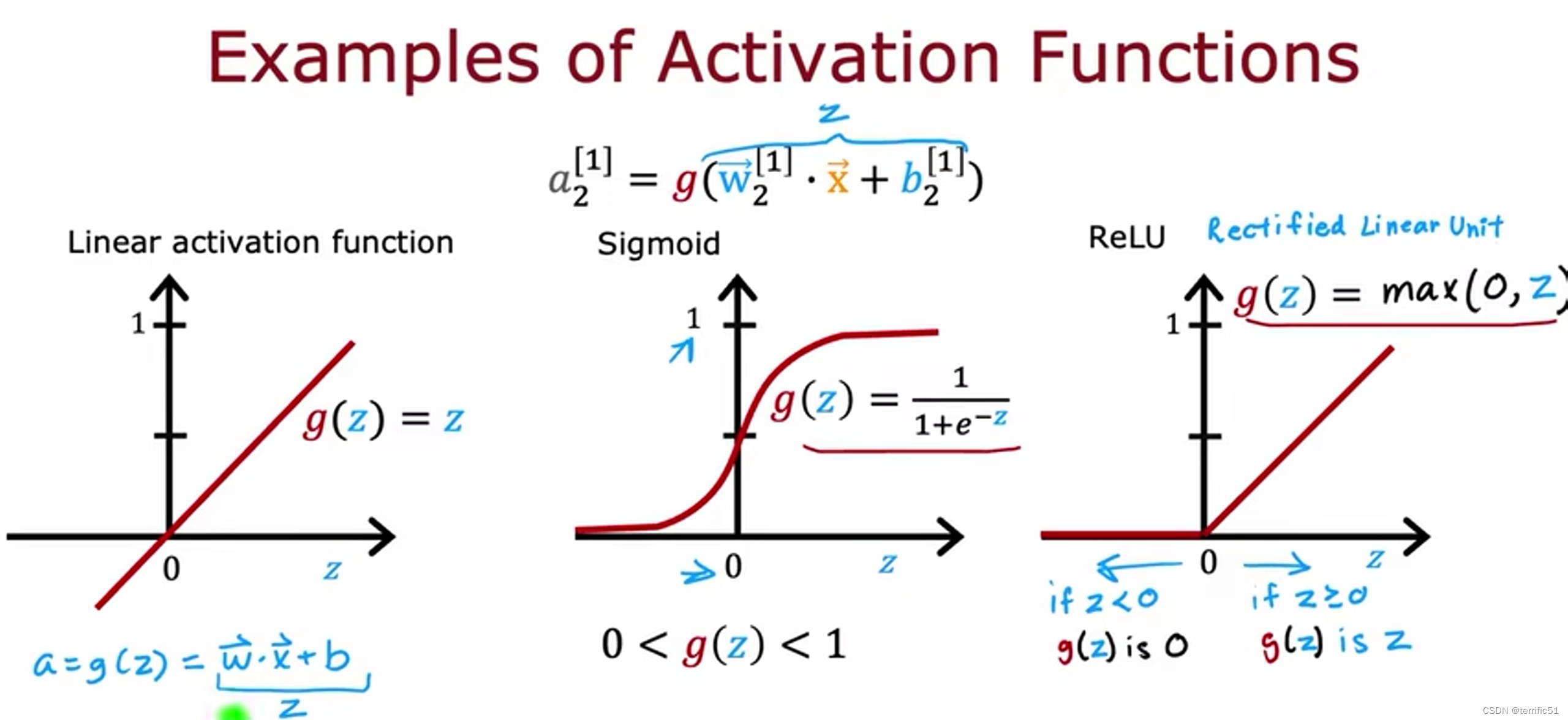
Sigmoid激活函数
ReLU 来指代g(z)
倘若假设意识要么知道要么不知道,但可能也存在有点意识和非常意识的情况;因此,与其将意识建模为0或1,不如尝试估计意识的概率。其中也不应建模意识只是一个介于0和1之间的数字。也许意识应该是任何非负数,因为意识的任何非负数都可以从0到非常大数字。
神经网络最常用的激活函数(其中g是sigmoid函数,介于0和1之间)
如何选择激活函数
我们将从如何为输出层选择它的一些指导开始,事实证明,取决于目标标签或真实标签y是什么。输出层的激活函数将有一个相当自然的选择,然后我们再看看激活函数的选择。(神经网络的隐藏层)
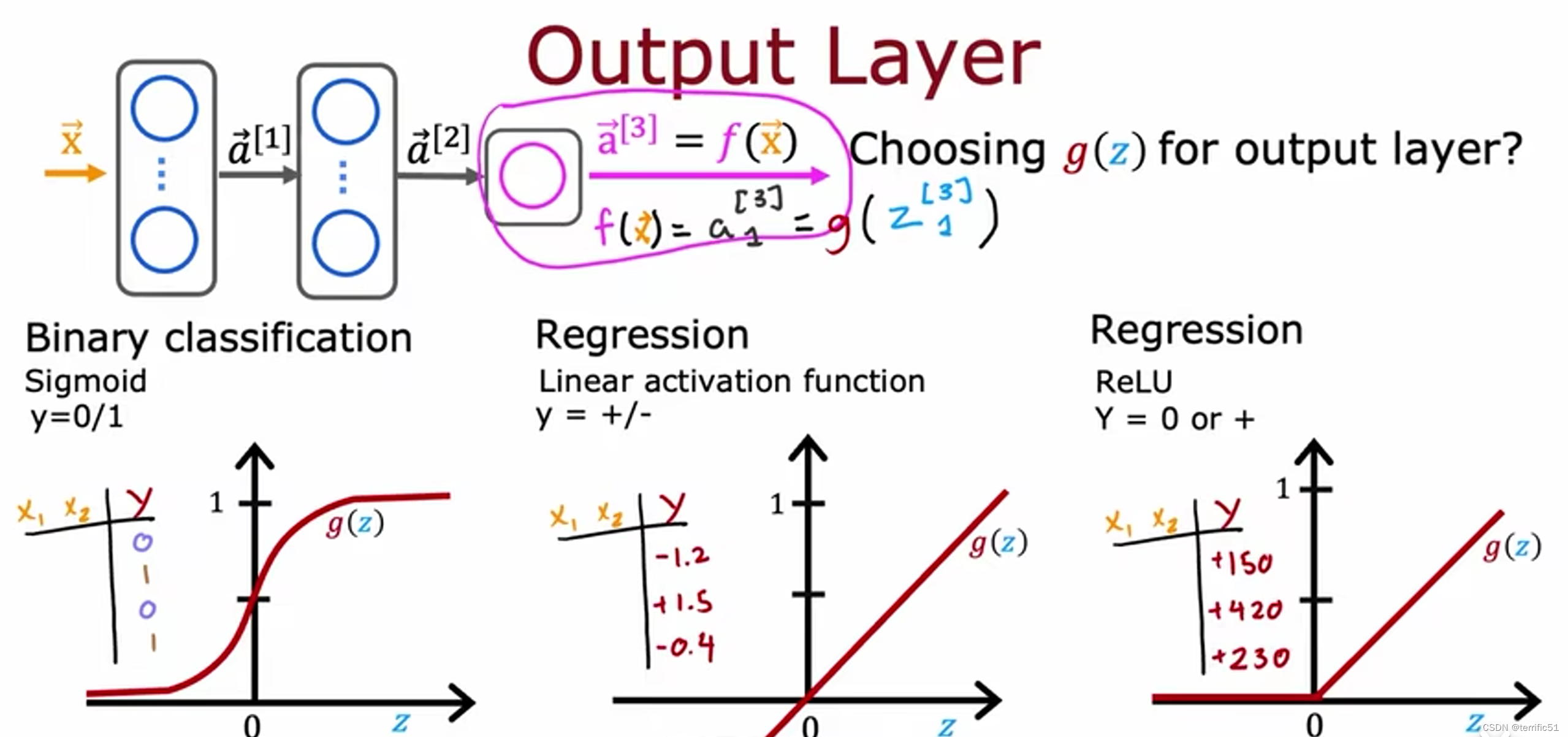
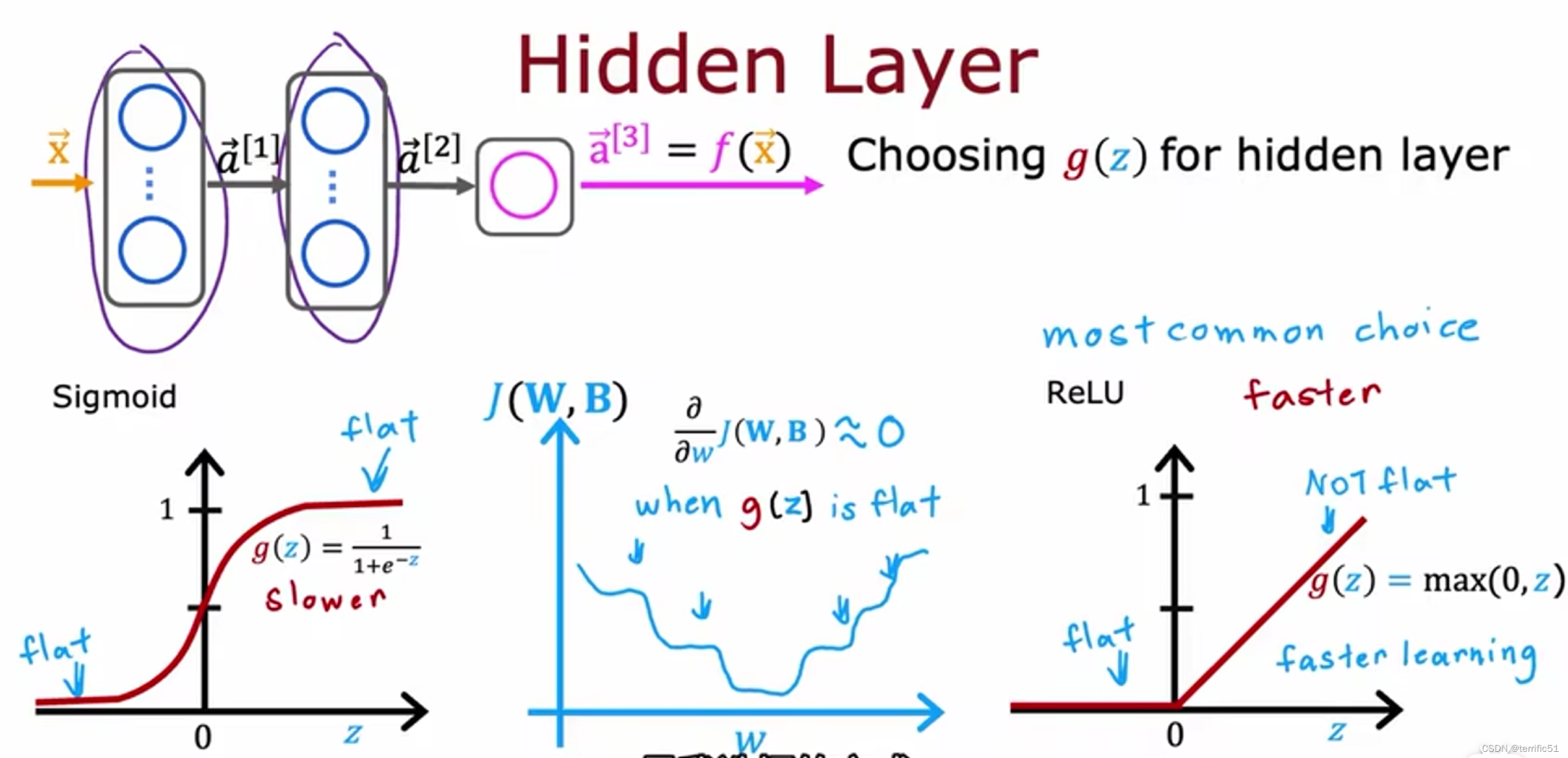

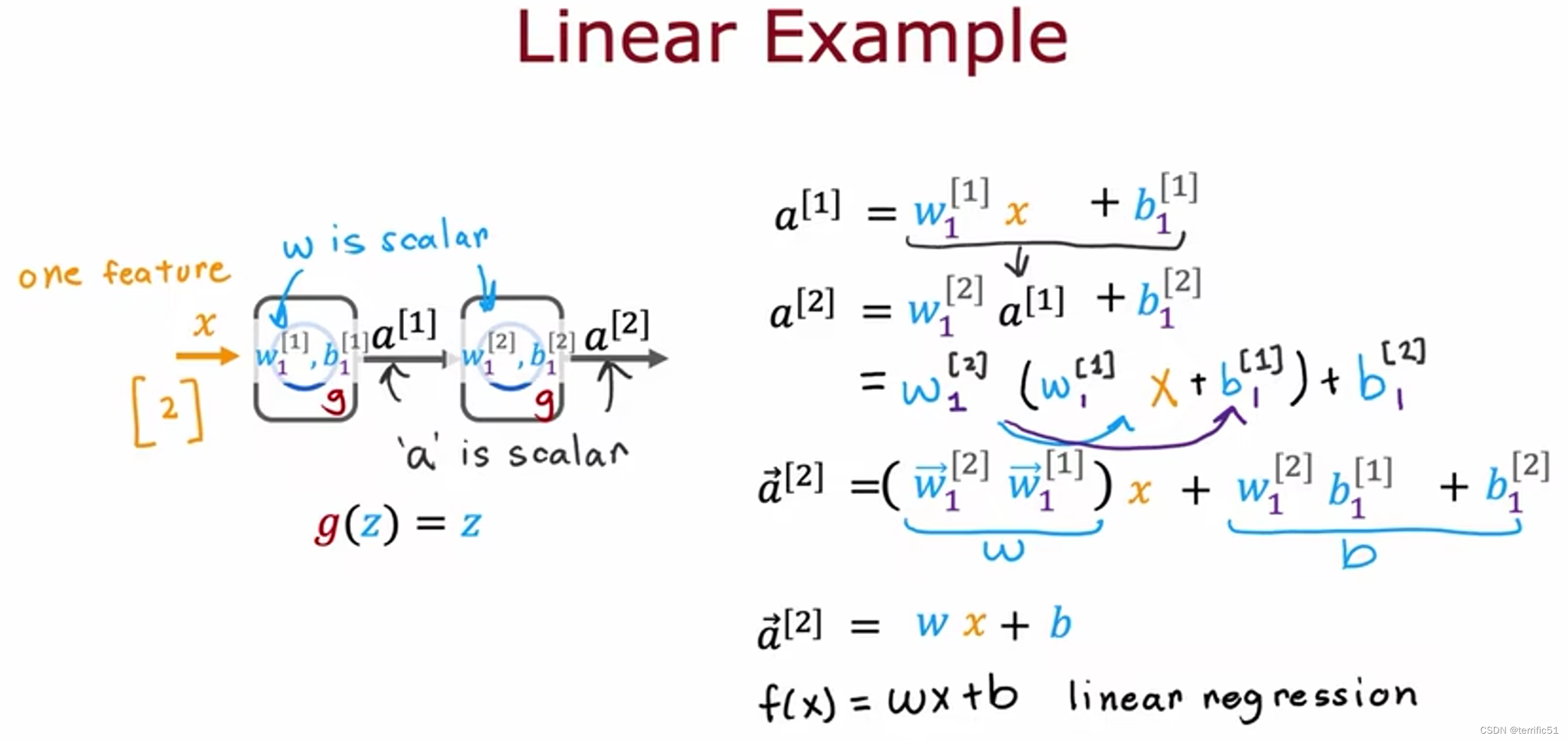
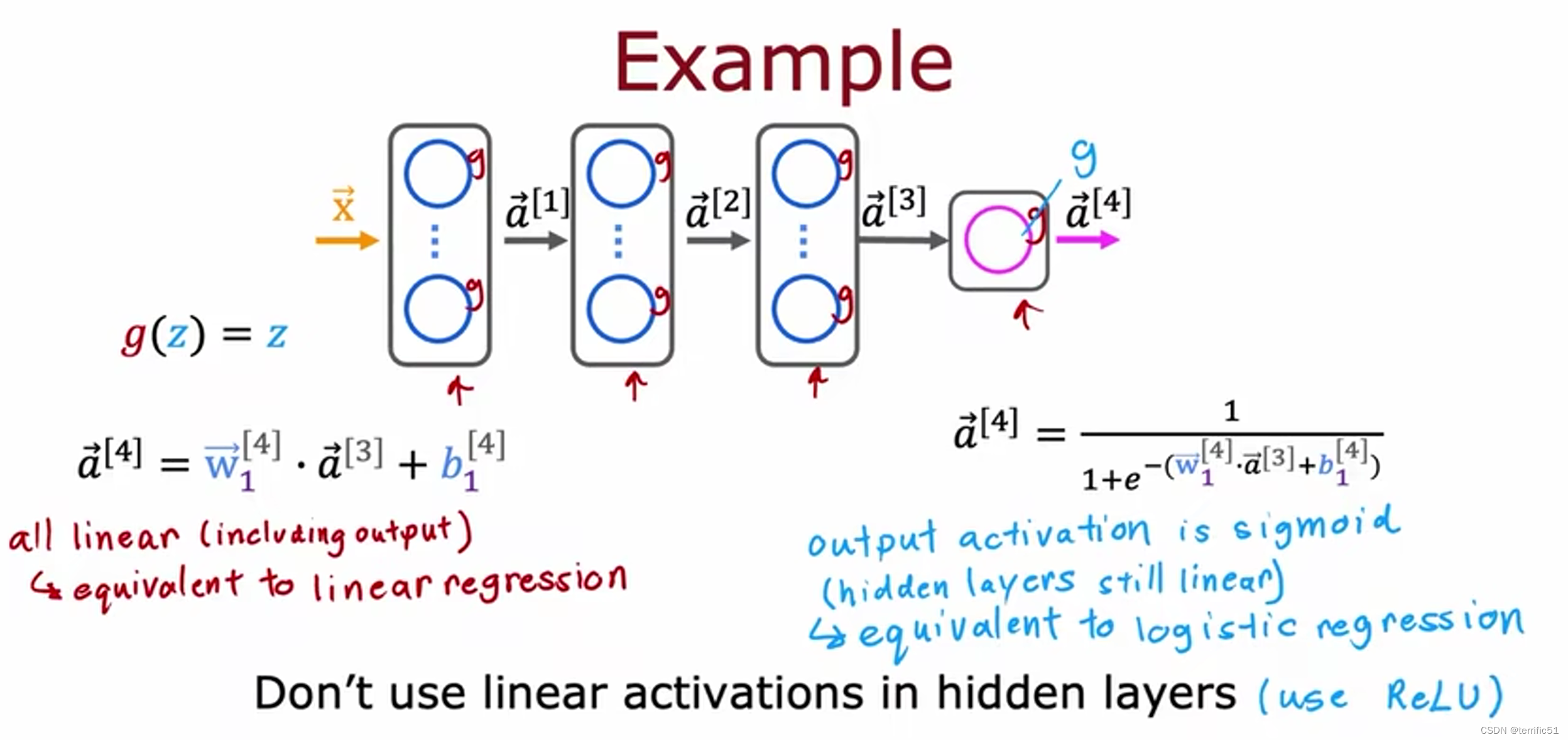
为什么模型需要激活函数,神经网络需要激活函数,而不是线性激活函数
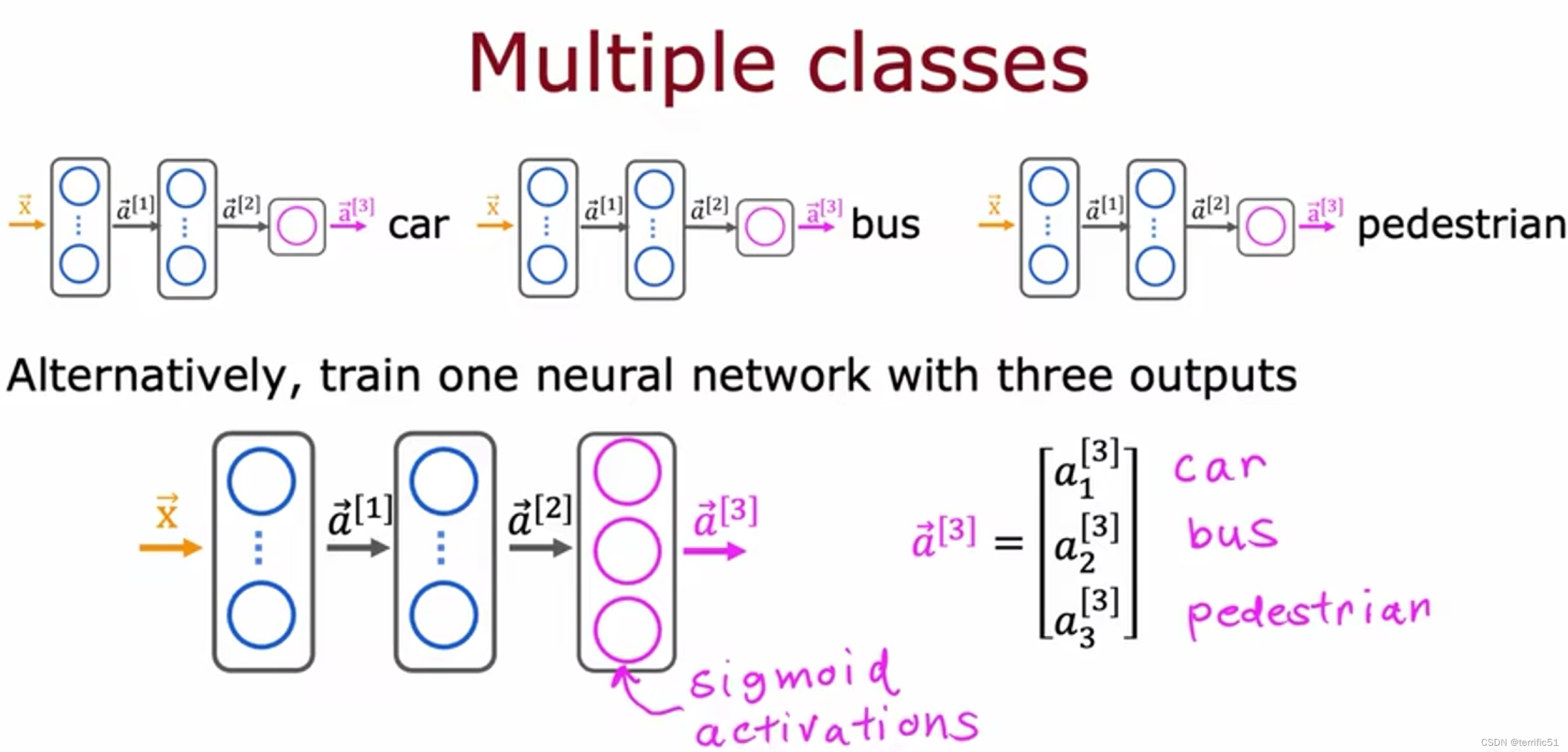
多分类问题
是指分类问题可以有两个以上可能的输出标签,而不仅仅是0或1。
例如手写识别0或1,但实际可能需要识别10个数字;尝试分类患者是否可能患有三种或五种不同的可能疾病;视觉缺陷检查;工厂里的零件制造商;您可能会在哪里查看一家制药公司生产的药丸的图片并试图弄清楚它是否有划痕效应或变色缺陷或芯片缺陷(针对多种不同的缺陷,对这种药丸进行分类);
目标y可以取少量离散类别(可以取两个以上的可能值)。

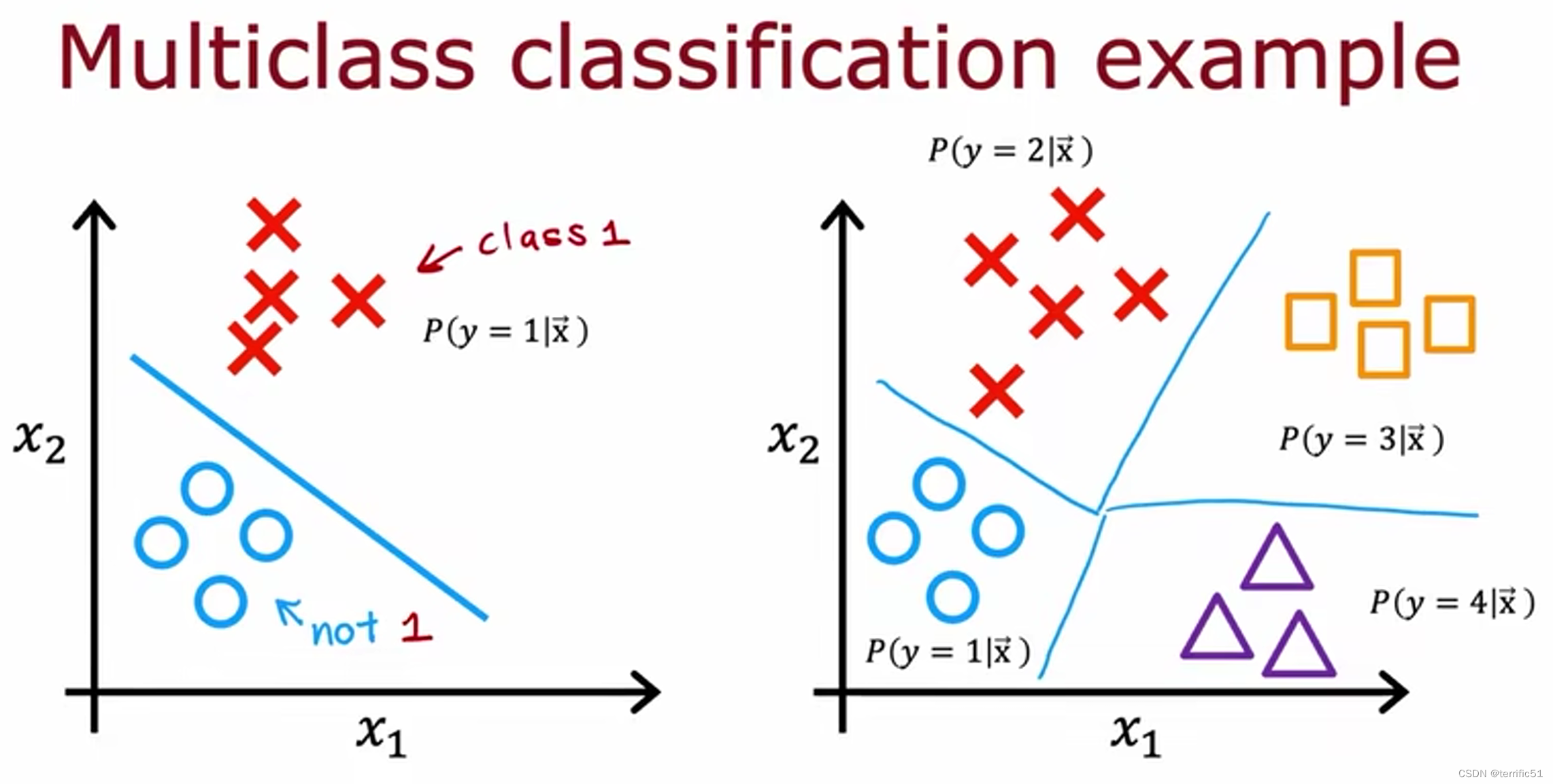
Softmax
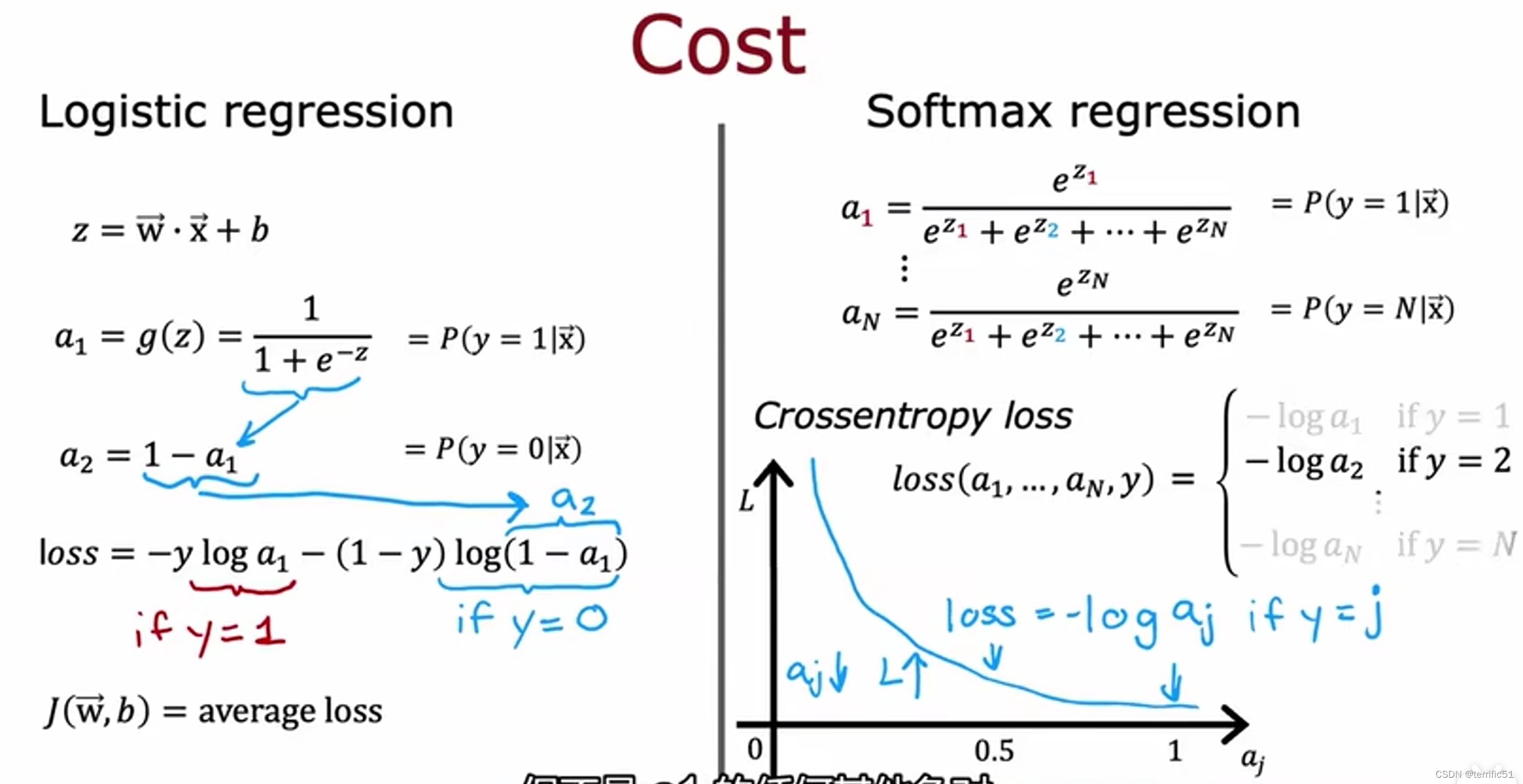
Softmax算法是逻辑回归的推广,这是多类分类上下文的二进制分类算法。

神经网络的Softmax输出
为了构建一个可以进行一个多类分类的神经网络,我们将采用Softmax回归模型和将其放入神经网络的输出层。
如果想用10个类别进行手写数字分类,所有数字从0到9,神经网络有10个这样的输出单元,这个新的输出层将是一个Softmax输出层。
使用激活函数,a1是Z1和Z2以及Z3一直到Z10的函数。所以这些激活值中的每一个都取决于Z的所有值。
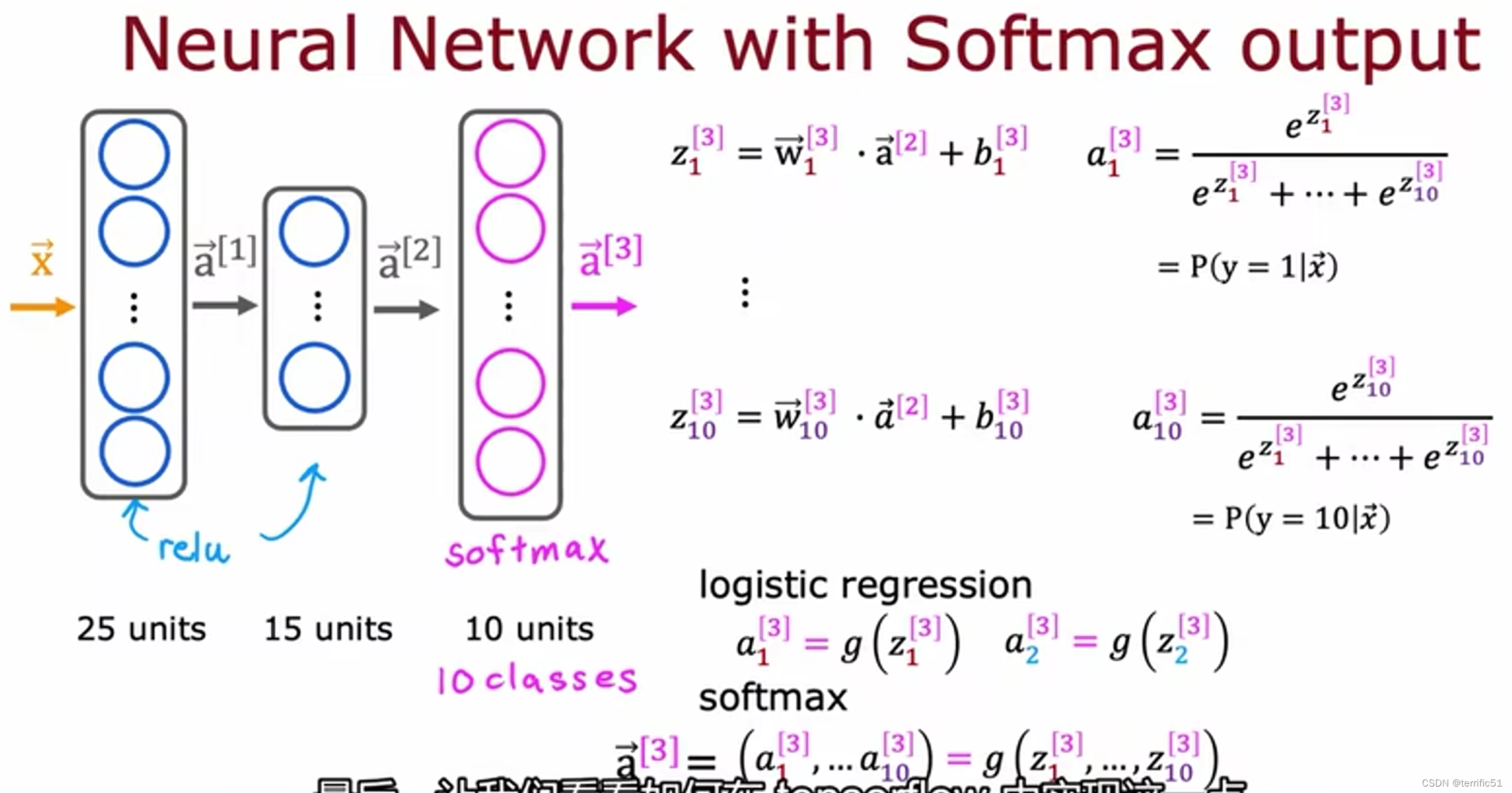
实现该神经网络的代码
1.告诉tensorflow将三层依次串在一起;(第一层和第二层分别是带有25和15激活功能的轨道单元、第三层是10个输出单元)

Softmax的改进实现
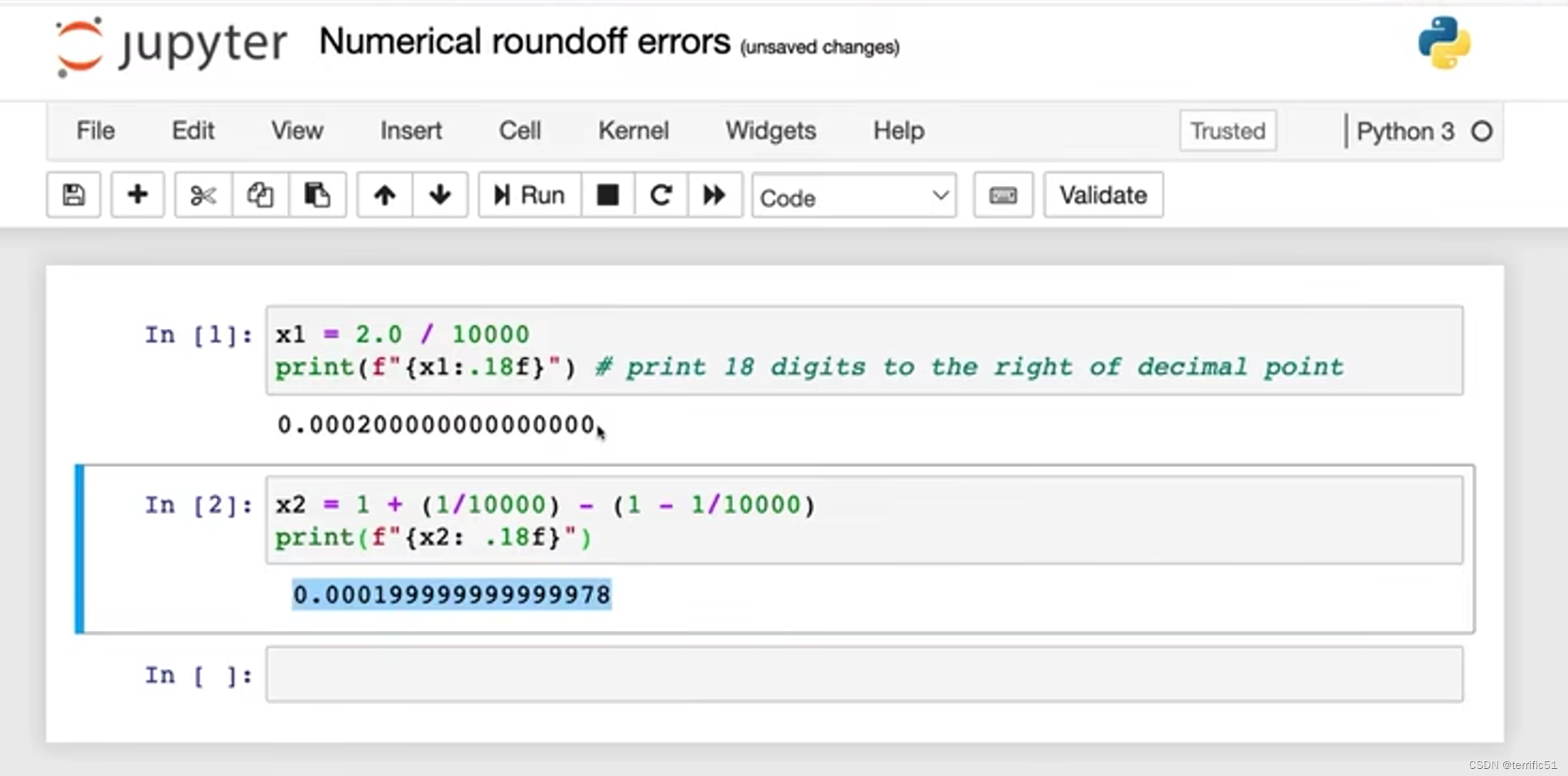
有一种不同的方式来制定它,减少这些数字舍入误差,
首先用逻辑回归说明想法(数字舍入错误)




多个输出的分类(多标签分类问题)

其中一个方法是将其视为三个完全独立的机器学习问题,可以建立一个神经网络来决定,第一个决定有没有汽车、第二个检测公交车、第三个检测行人;
高级优化方法
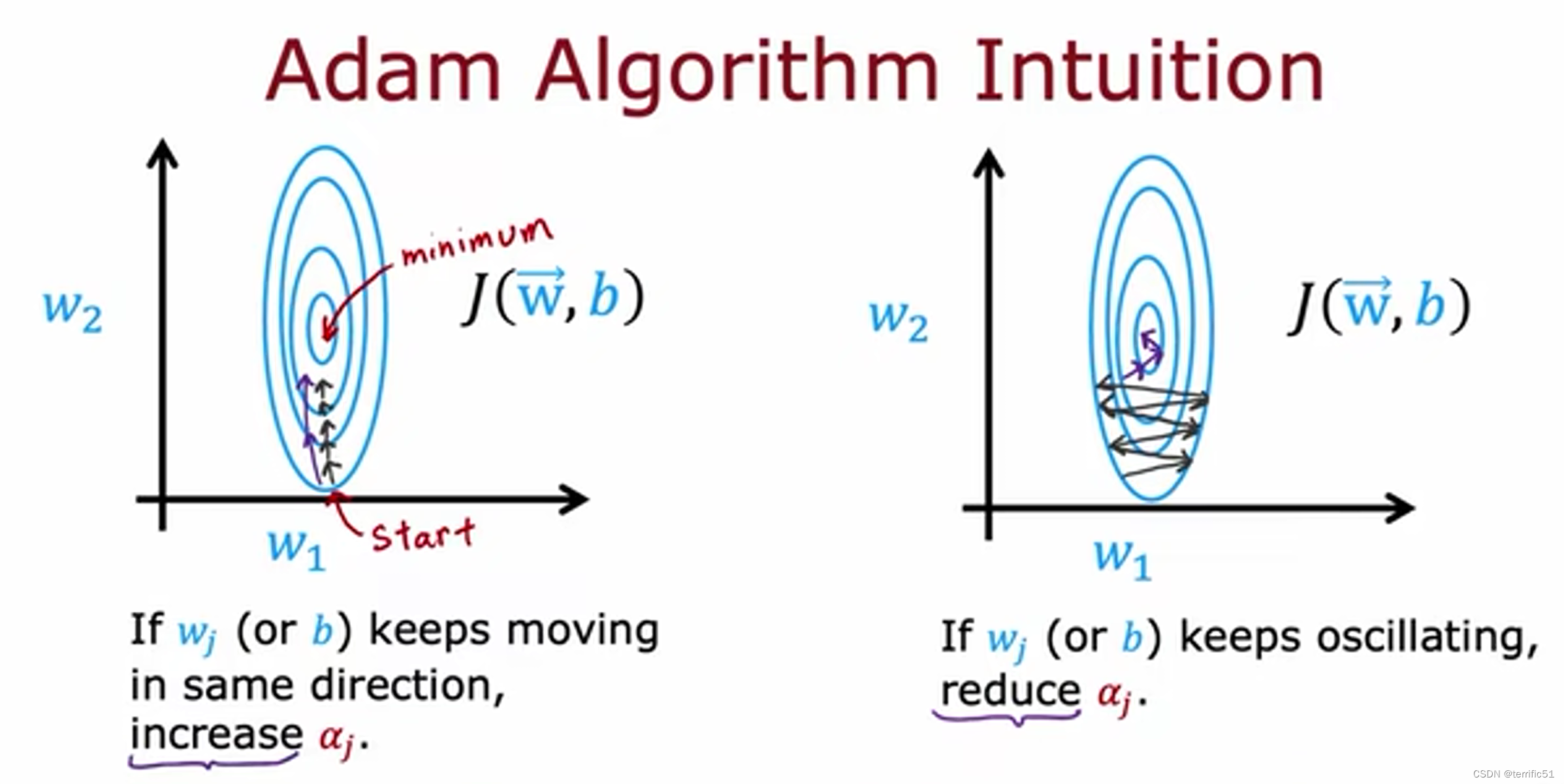
梯度下降是广泛应用于机器学习的优化算法,并且是许多算法的基础。如线性回归和逻辑回归和神经网络的早期实现,但事实证明现在还有一些其他的优化算法用于最小化成本函数甚至比梯度下降更好。
下面我们了解一下可以提供帮助的算法,你训练你的神经网络比梯度下降更快。
Adam 算法可以自动调整学习率。Adam 算法并没有使用单一的全局学习率a,它对模型的每个参数使用不同的学习率。


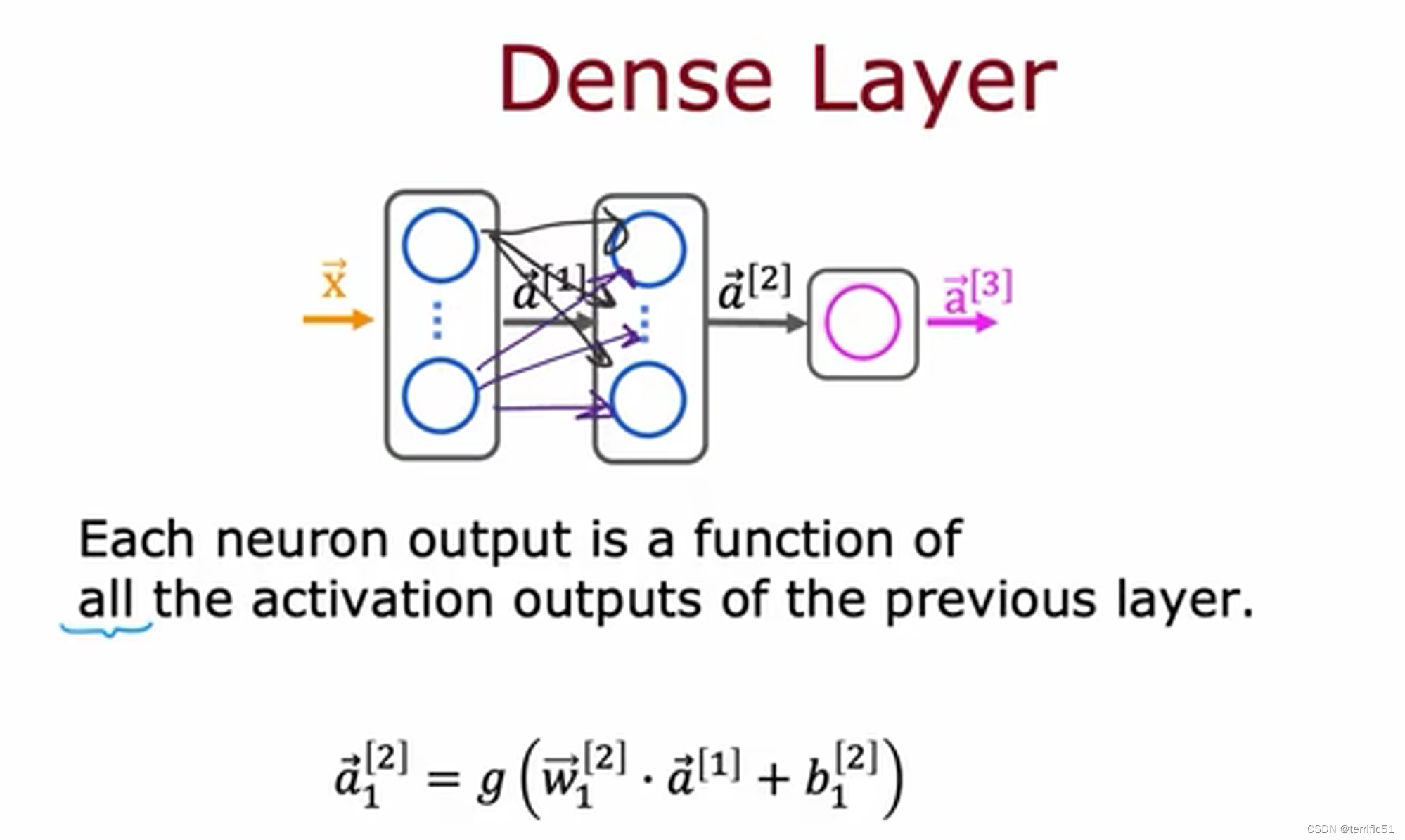
其他的网络层类型
密集层、卷积层、
卷积层
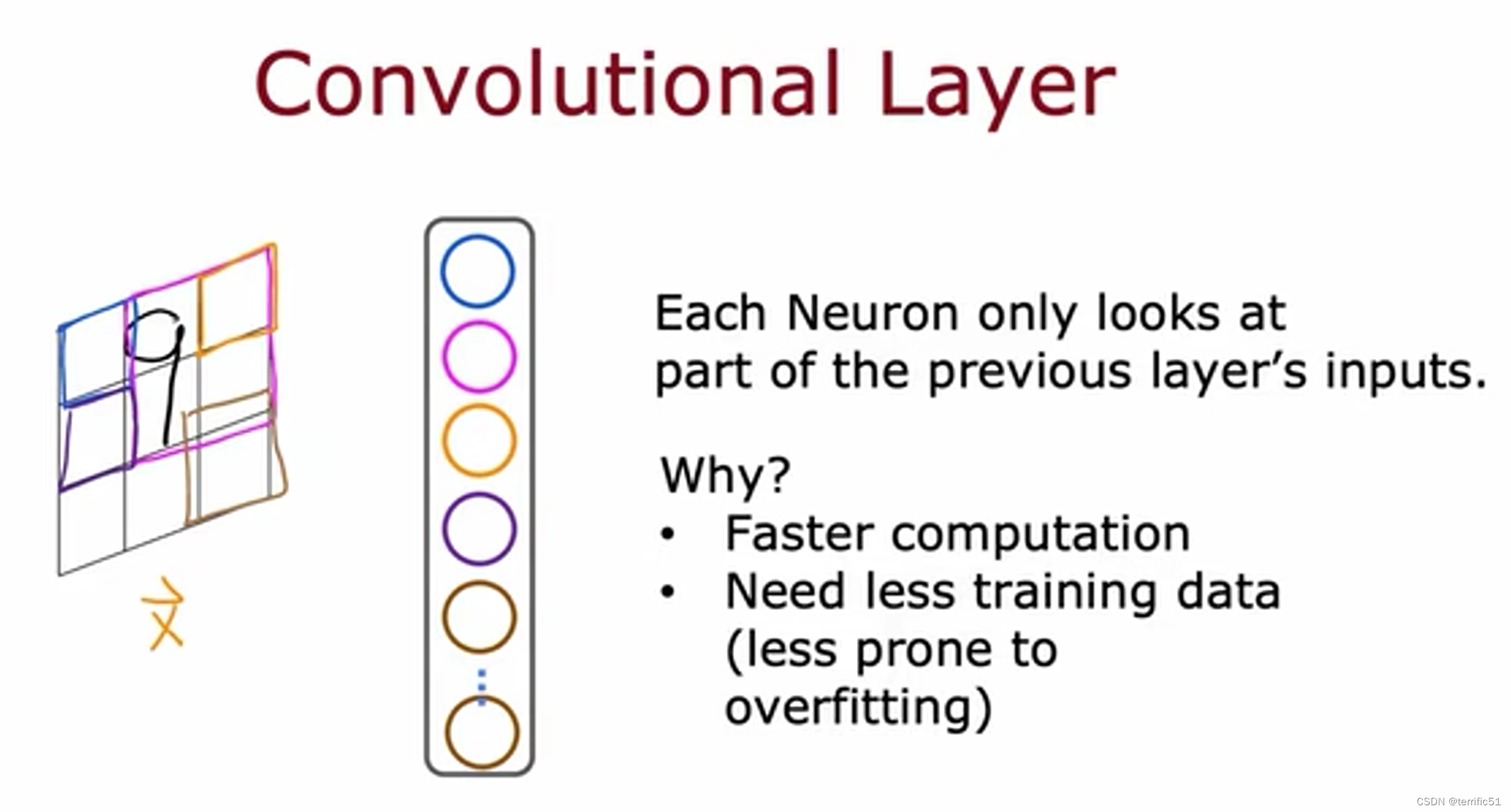
如图,第一个隐藏层是卷积层,第二个隐藏层也是卷积层,然后输出层是一个sigmoid层。事实证明,对于卷积层,有许多架构选择。例如,单个神经元应该查看的输入窗口有多大以及层应该有多少个神经元,通过有效地选择这些架构参数,您可以构建更有效的新版本神经网络比某些应用程序的密集层。
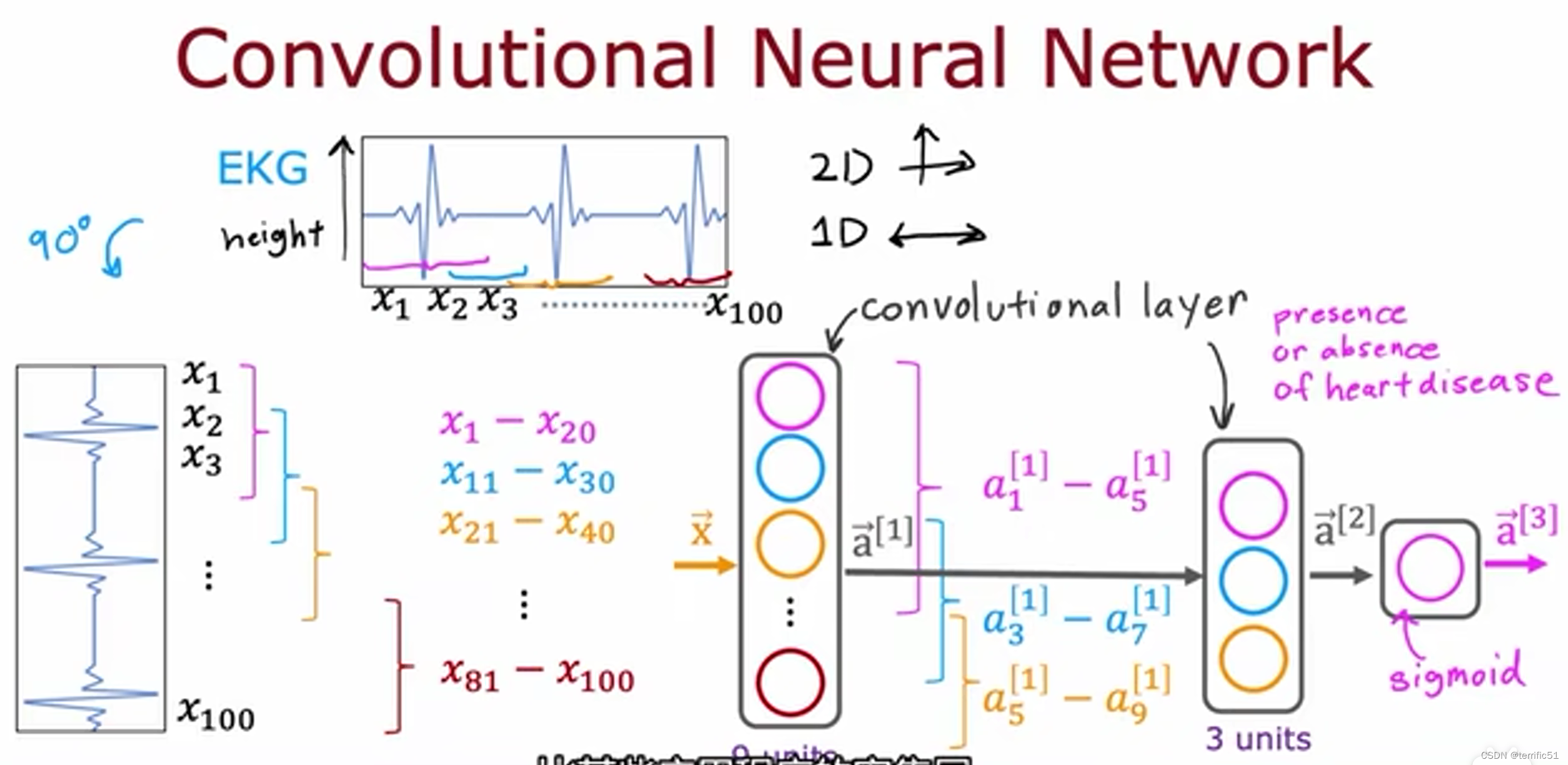
模型评估
将数据集分成两部分,其中一部分作为训练集用于训练模型及相关参数;然后我们将在测试集上测试它的表现。



模型选择(交叉验证数据集)




通过偏差与方法进行诊断

正则化、偏差、方差
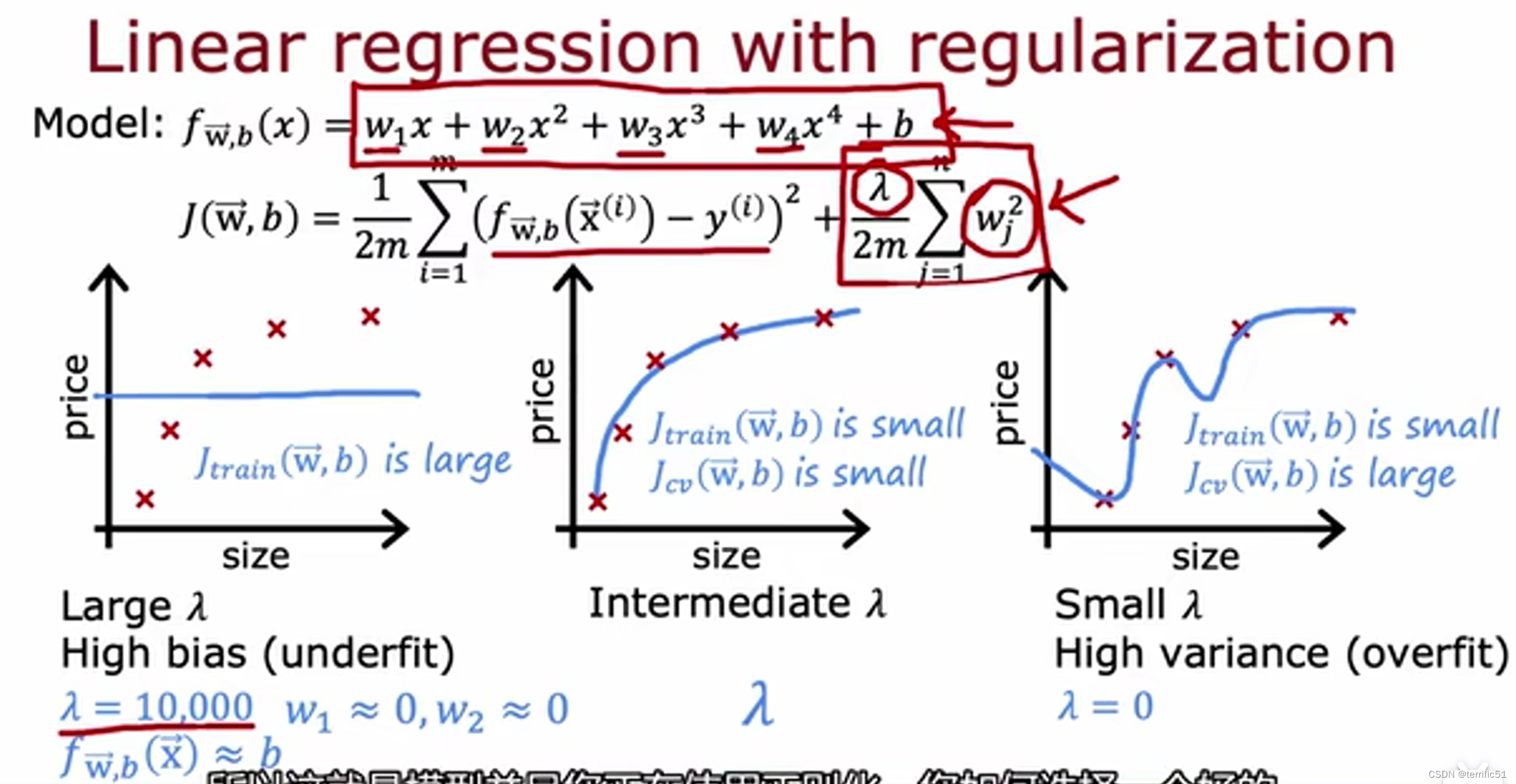

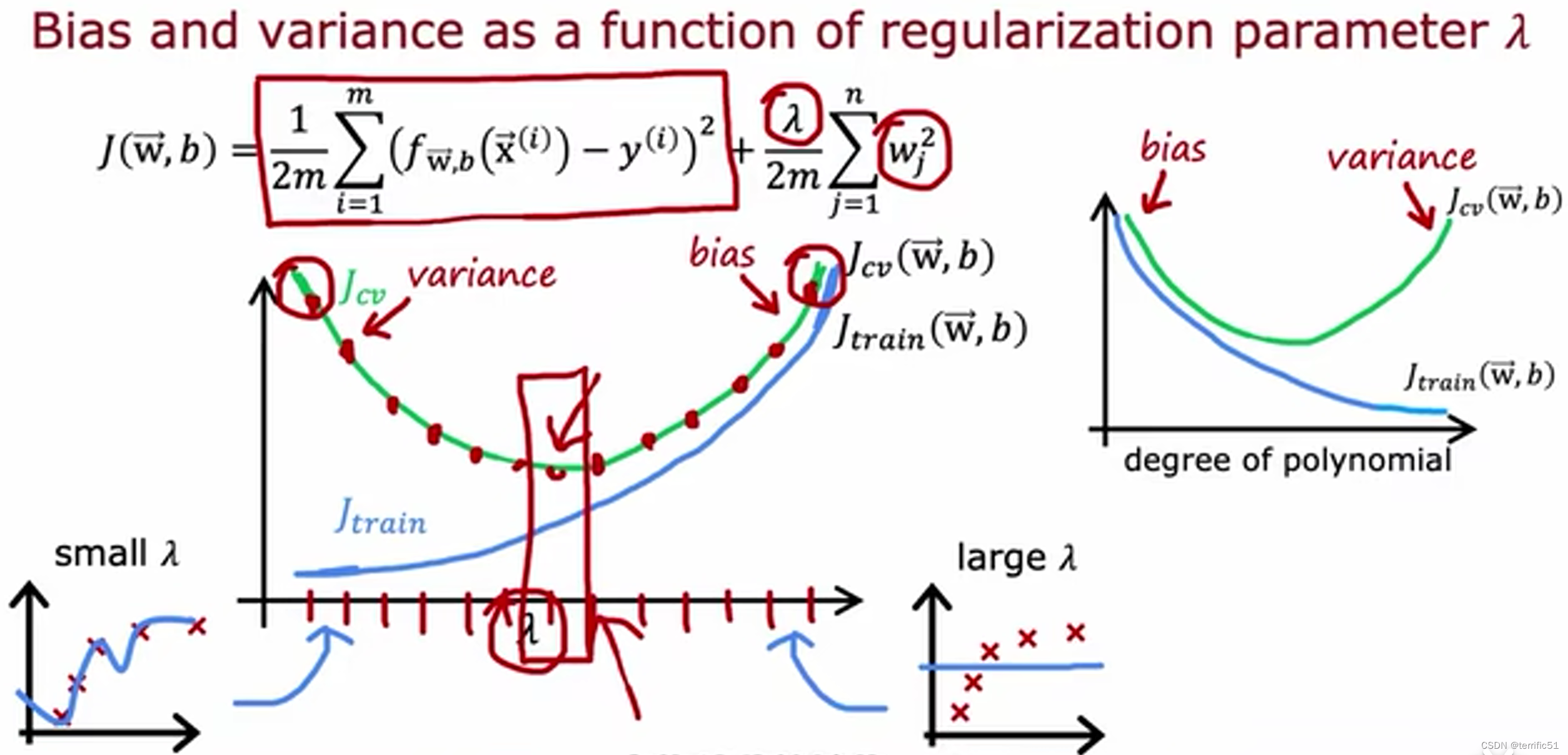
制定一个用于性能评估的基准


学习曲线
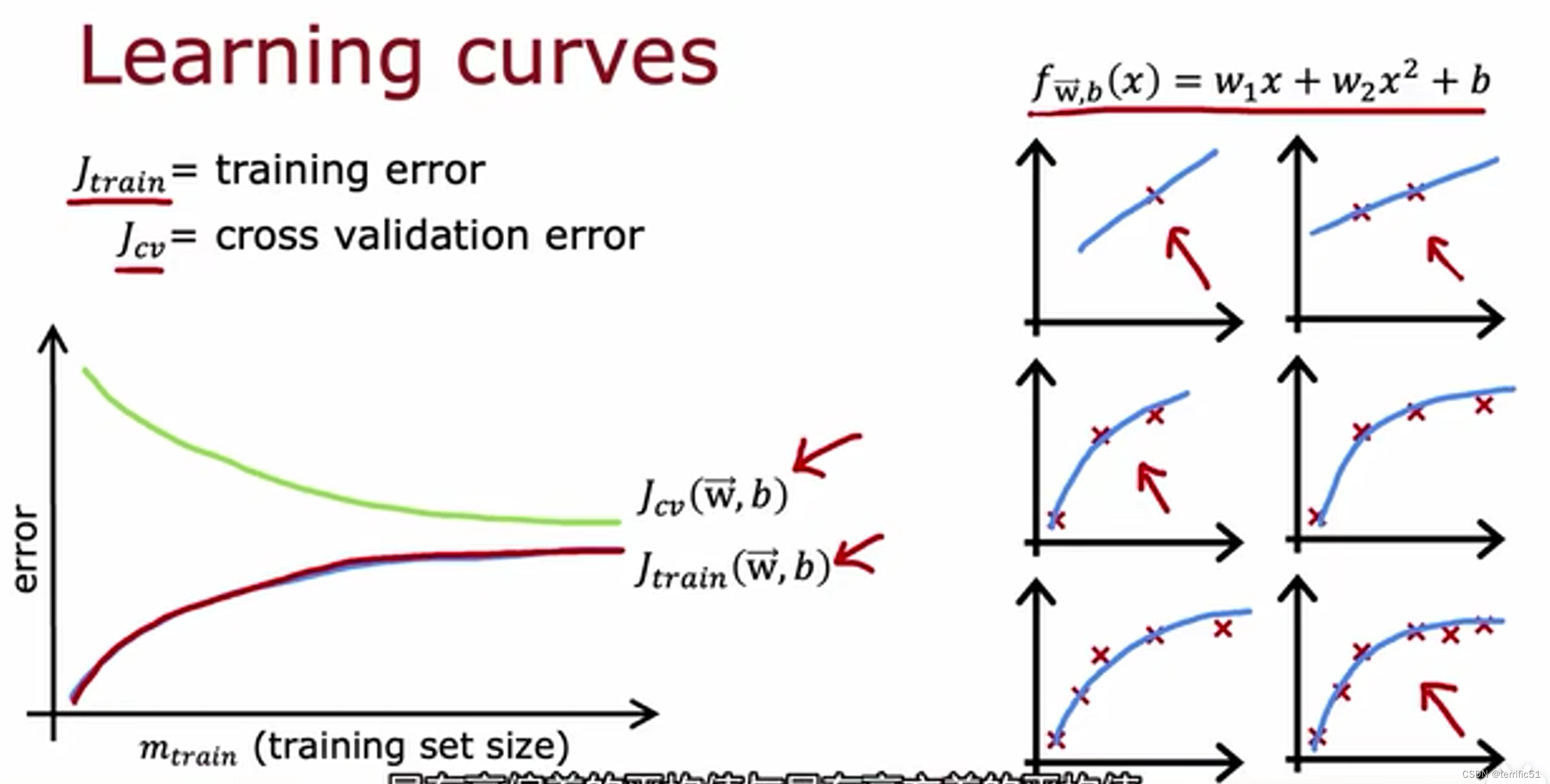
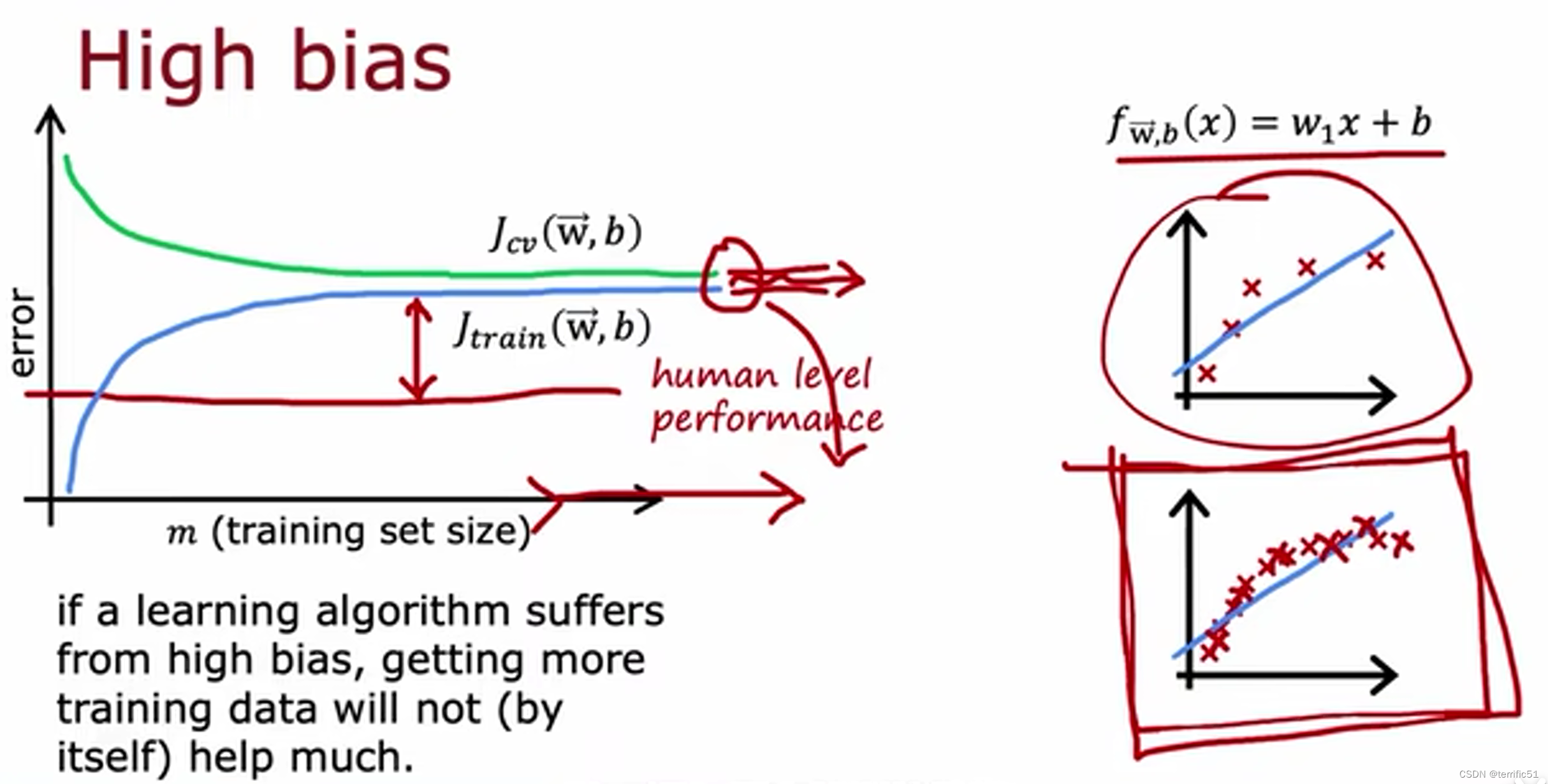

方差与偏差

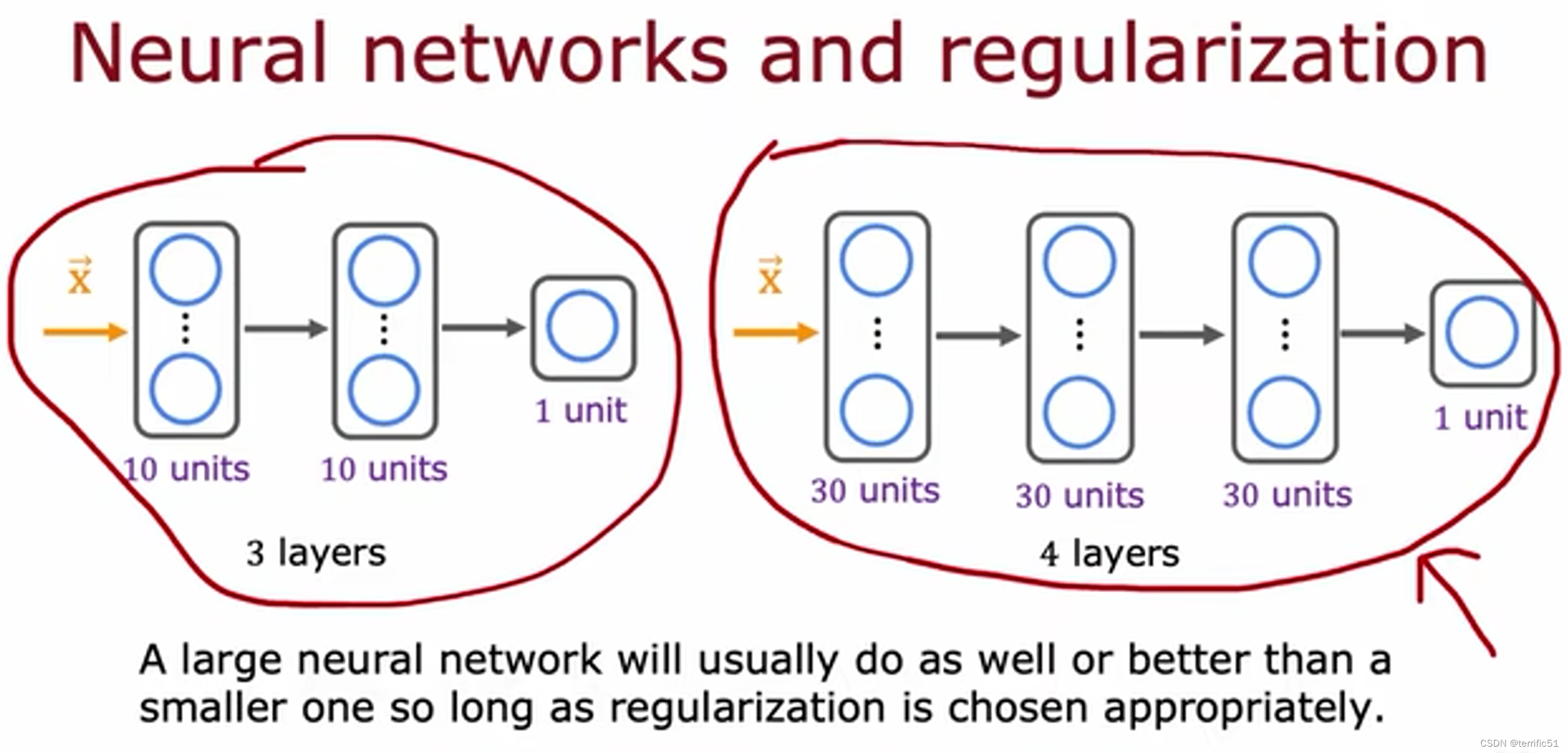
神经网络中实现正则化


误差分析
添加更多数据
迁移学习
用来自不同任务的数据来帮助应用程序。在迁移学习中可以直接下载别人可能用过的神经网络,然后用自己的输出层代替输出层,并进行选项一或二。

微调其他人已经携带的神经网络,进行监督预训练。

迁移学习分为两步:
1.下载带参数的神经网络(已经在大型数据上进行了预训练与应用程序相同的输入类型)或者自己训练。
2.根据自己的数据进一步训练或微调神经网络。
机器学习项目的完整周期
公平、偏见与伦理

倾斜数据集的误差指标
精确度和召回率

算法123比较精确度和召回率使用F1score
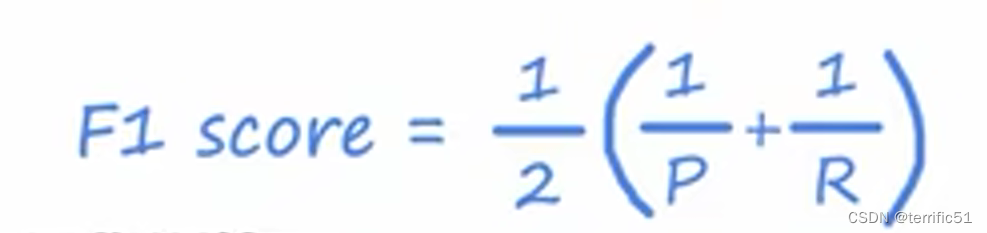

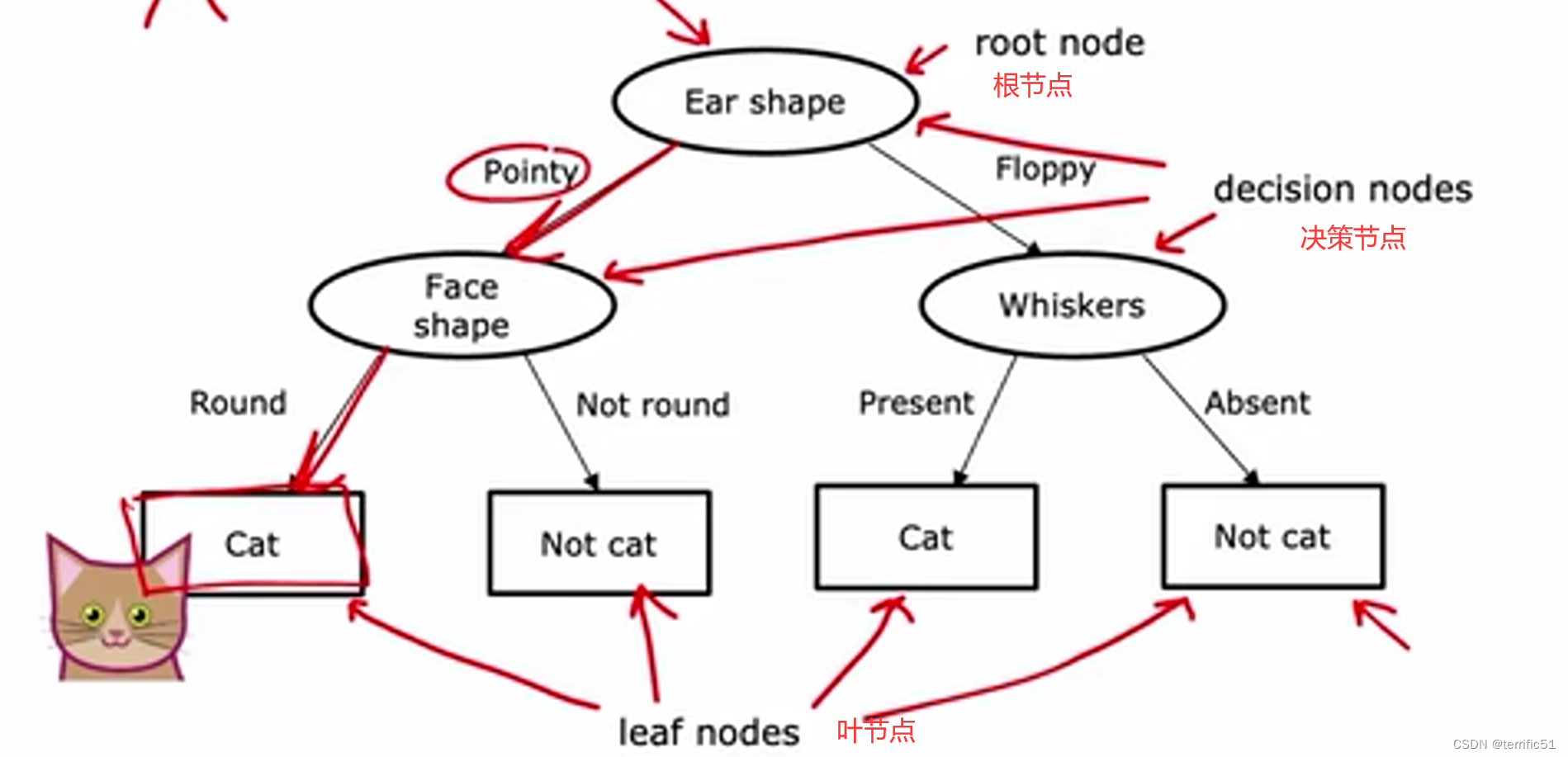
决策树
创建决策树的关键点
1.选择决定根节点用什么特征
2.提高纯度(如何估计杂质、减少杂质)
3.何时停止拆分


熵是衡量一组数据是否不纯的指标,熵函数从零开始上升到一再回到零。

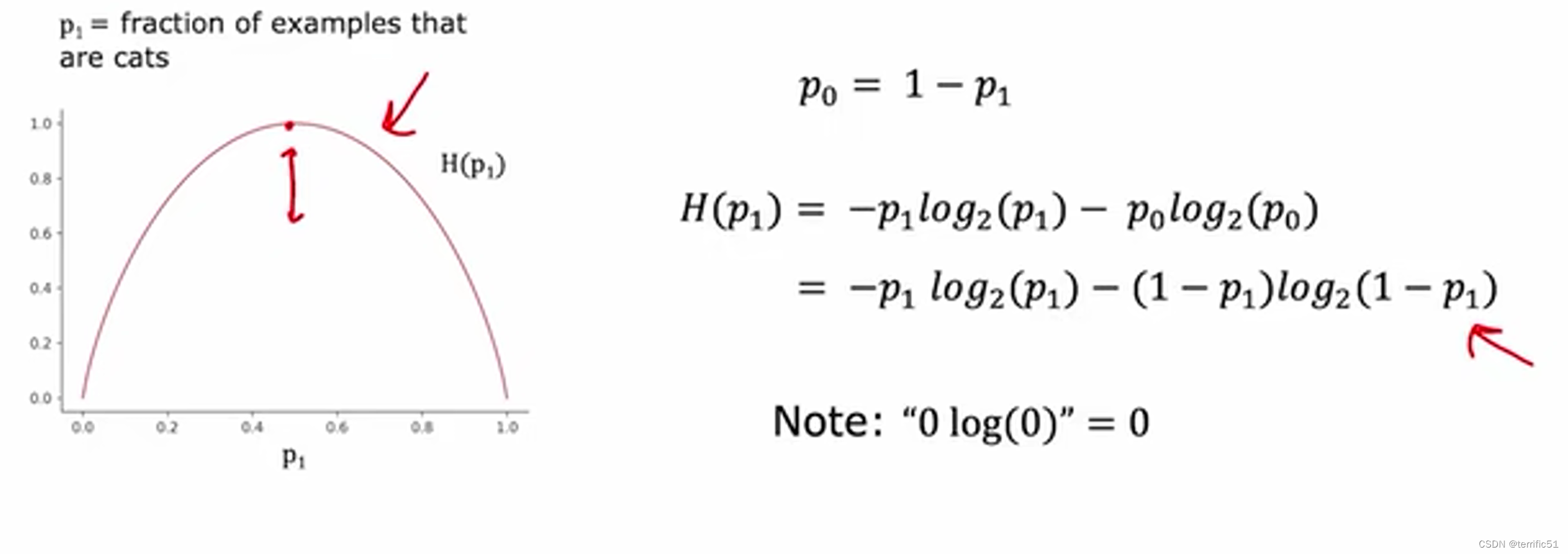
构建决策树时选择的特征基于最大程度地减少熵或减少杂质或最大化纯度。
在决策树学习中,熵的减少称为信息增益,信息增益越大越好
针对在根节点使用的功能中,我们认为哪一个效果最好?事实证明,与其查看这些熵数并进行比较,对它们进行加权平均会很有用。

信息增益


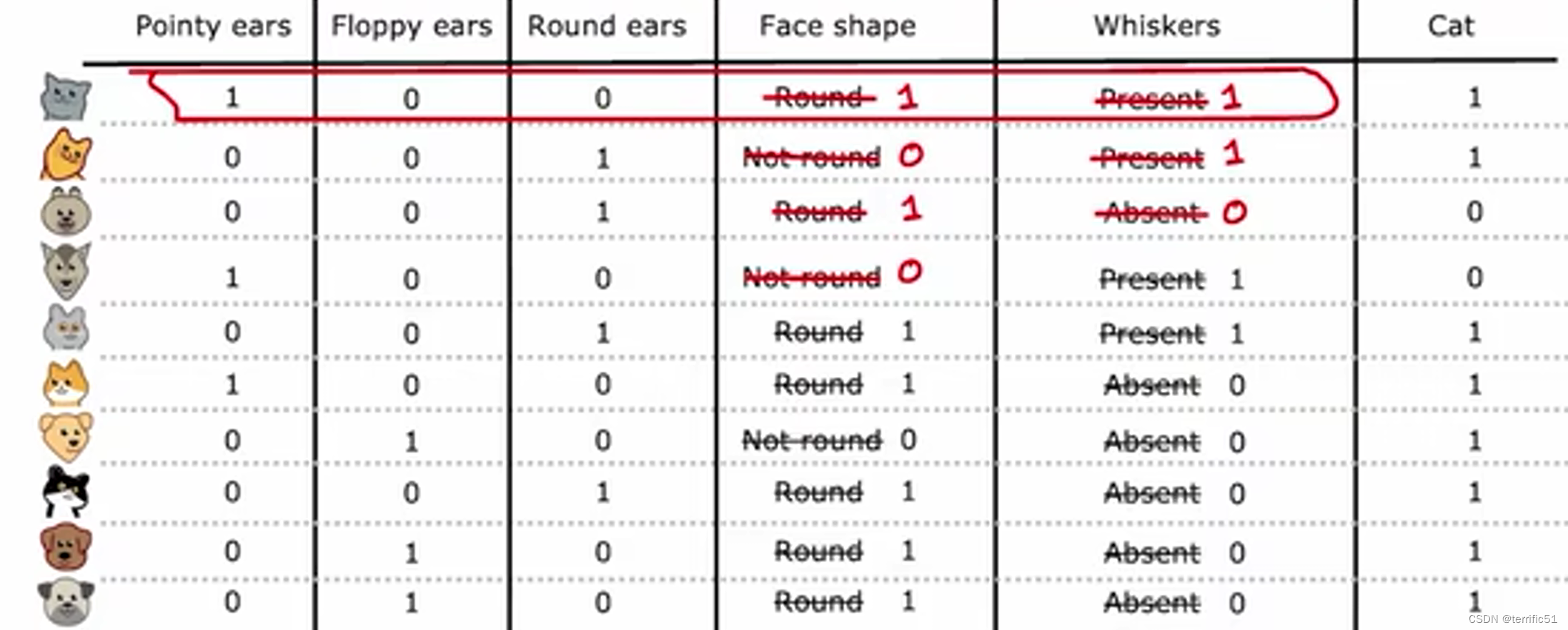
One-hot编码(处理离散值)
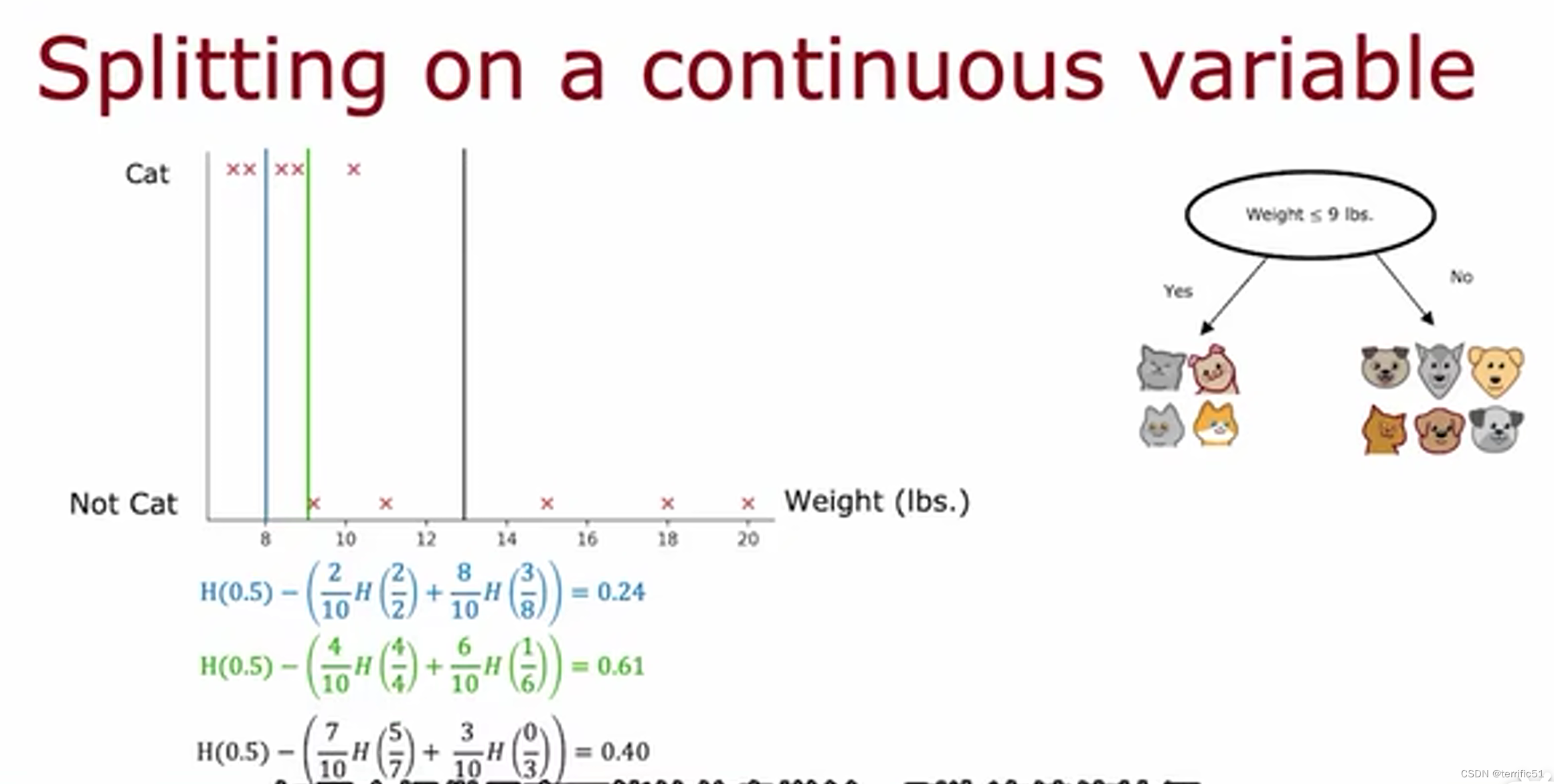
处理连续值
回归树
方差的减少

使用多个决策树(树集合)
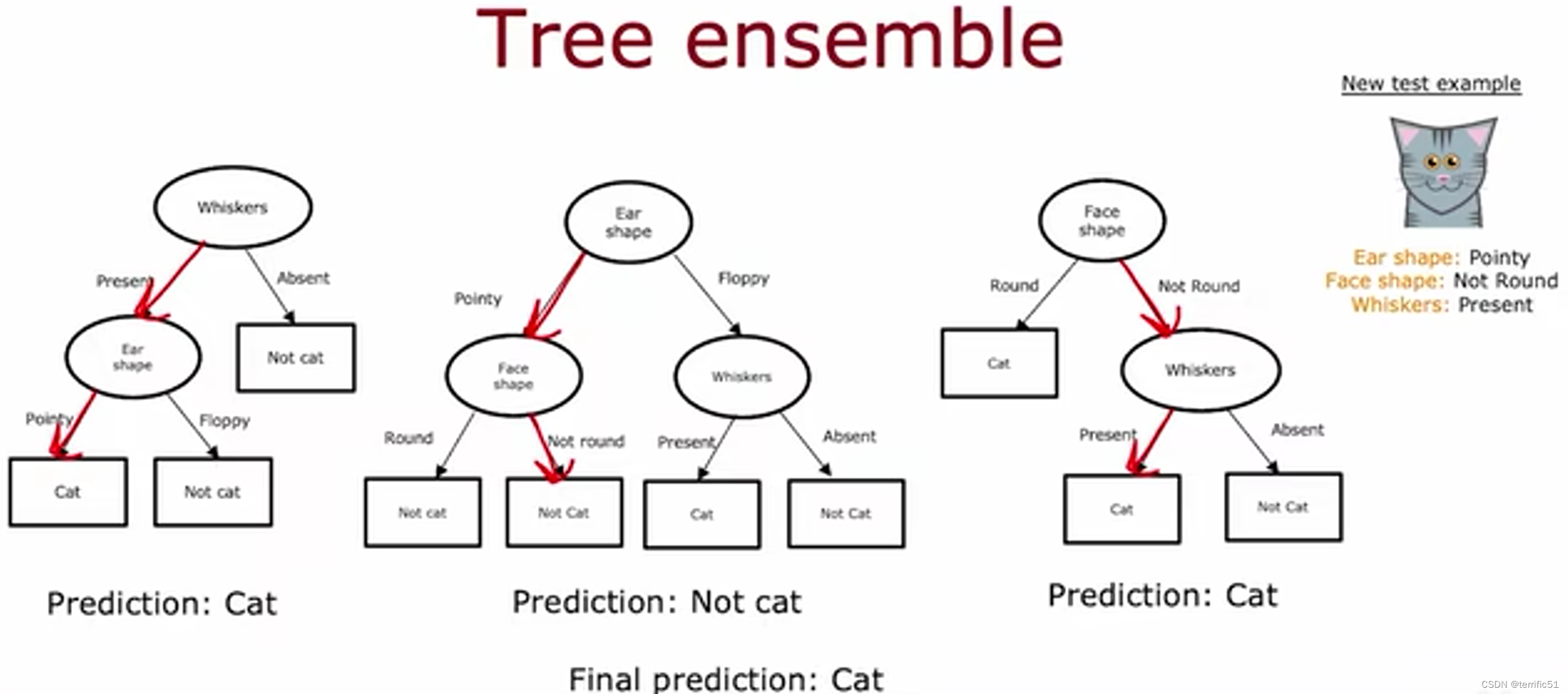
有放回抽样
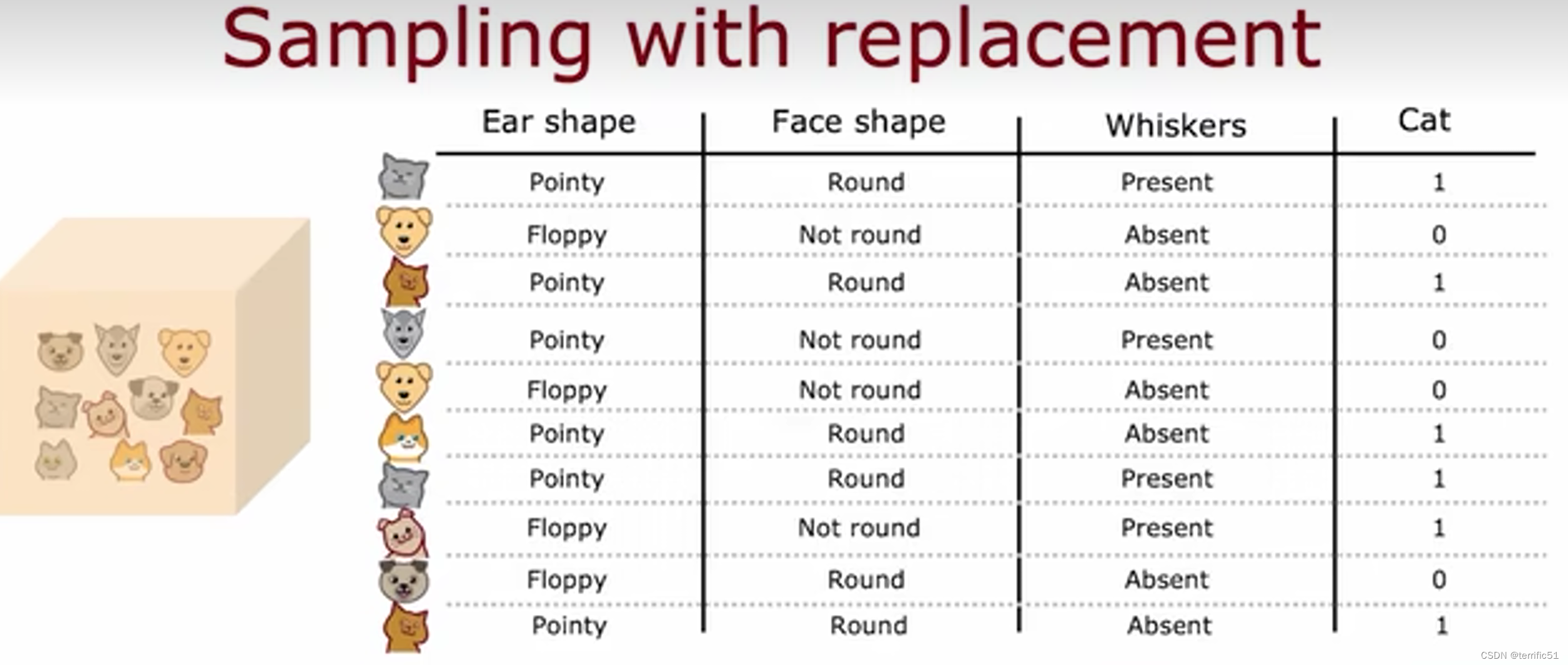
随机森林(反向决策树算法)

增强决策树算法

何时使用决策树















 456
456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









