






一、强化学习简介
机器学习可以分为两种类型:
——预测型
——根据数据预测所需进行输出(有监督学习)
——生成数据实例(无监督学习)
——决策型
——在动态环境中采取行动(强化学习)
----转变到新的状态、获得即时奖励、随着时间的推移最大化累积奖励
强化学习的定义:
强化学习(Reinforcement Learning, RL),又称增强学习,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
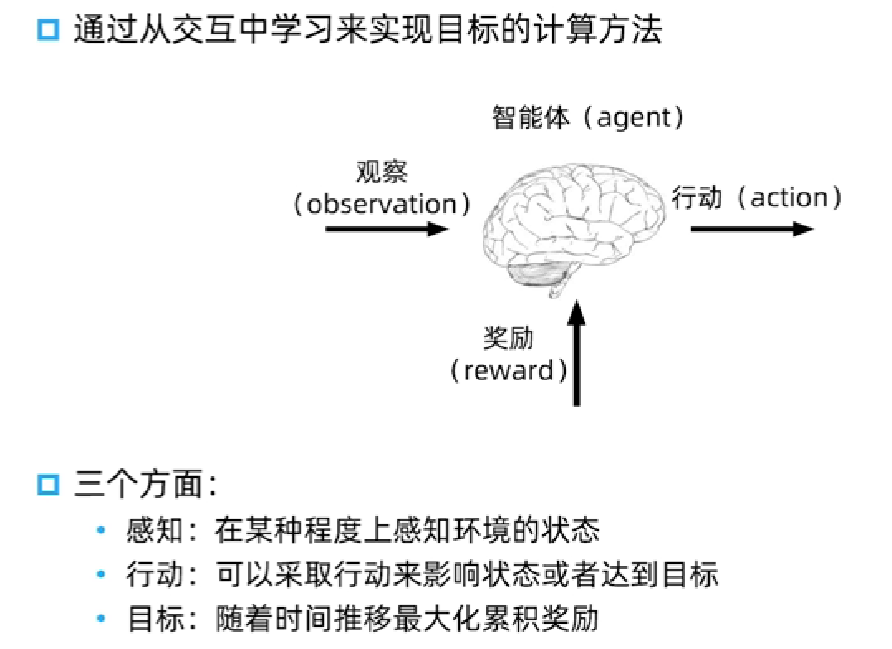
强化学习的交互过程:
智能体与环境不断进行感知、交互、获得奖励的一个过程。
历史(History)是观察、行动和奖励的序列。
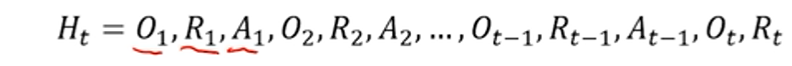
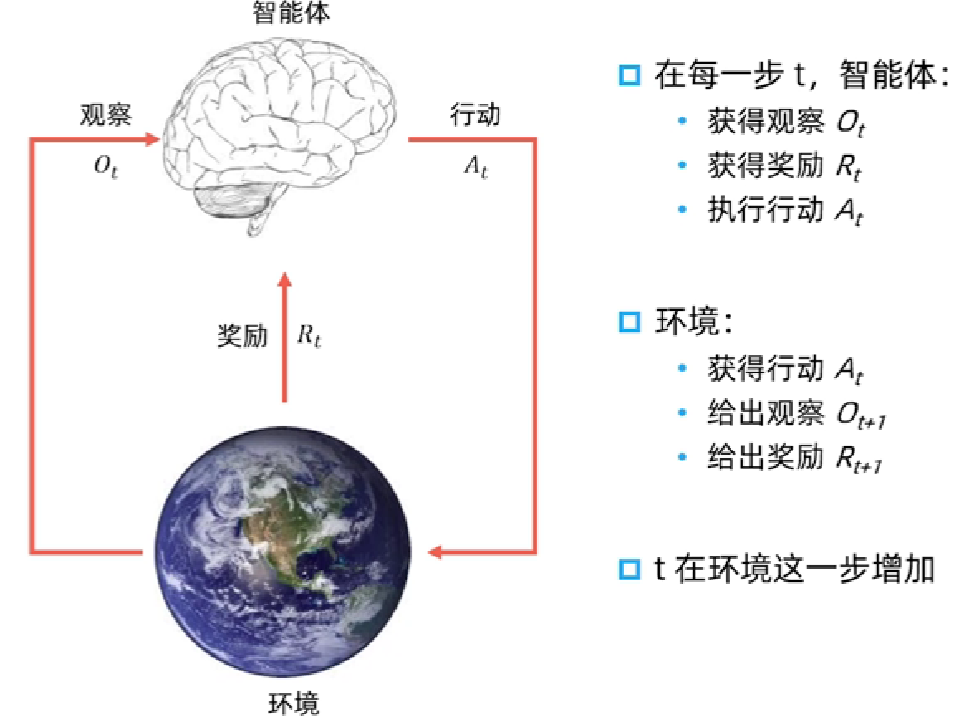
即不断的进行观测、奖励、决策、观测、奖励、决策等构成一个sequence。
即一直到时间t为止的所有可观测变量。
根据这个历史可以决定接下来会发生什么:智能体选择行动/环境选择观察和奖励。
状态(state)是一种用于确定接下来会发生什么的事情(行动、观察、奖励)的信息。
状态时关于历史的函数 ![]()
策略(Policy)时学习智能体在特定时间的行为方式。
——是从状态到行动的映射
——确定性策略(Deterministic Policy)![]() ==》是从状态到策略的函数
==》是从状态到策略的函数
——随机策略(Stochastic Policy)![]() ==》从状态到策略的条件概率分布
==》从状态到策略的条件概率分布
ps:状态相当于是对当前环境的一个描述;而策略是状态到行为的映射,即我在现在这个状态下该采取什么行为。
奖励(Reward):
——一个定义强化学习目标的标量
——能立即感知到什么是好的
ps:如果是及时的奖励,可以让agent更好的得到反馈,比如向左一步会得到+1的reward,向右一步会得到-1的reward,那么agent会很快学到向左这个policy。但如果reward是延迟的话,比如agent需要走很多步才能得到反馈,这样会加大agent的学习难度,因为agent在行动中并不知道自己的policy是不是正确的。这个在RL中被称为sparse reward。
价值函数(Value Function):
——状态价值是一个标量,用于定义对于长期来说什么是好的
——价值函数是对于未来累积奖励的预测。用来评估状态的好坏
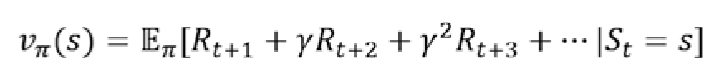
强化学习智能体分类:
——基于模型的强化学习
—策略(和/或)价值函数
—环境模型
—比如:迷宫游戏、围棋等
——模型无关的强化学习
—策略(和/或)价值函数
—没有环境模型
二、探索与利用
这是序列决策任务中的一个基本问题
——基于目前策略获取已知最优收益还是尝试不同的决策。
——Exploitation 执行能够获得已知最有收益的决策
——Exploration 尝试更多可能的决策,不一定会是最优收益
 通过探索与利用,将当前策略不断更新,使向最右策略接近。
通过探索与利用,将当前策略不断更新,使向最右策略接近。
策略探索的一些原则:
——朴素方法(Native Exploration)
——添加策略噪声 -greedy
——积极初始化(Optimistic Initialization)
——基于不确定性的度量(Uncertainty Measurement)
——尝试具有不确定收益的策略,可能带来更高的收益
——概率匹配(Probability Matching)
——基于概率选择的最佳策略
——状态搜索(State Searchiing)

















 884
884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









