







模拟卷特别是大题还是很有难度的,而且有些题有错,还是先把真题吃透,后面没时间的话就不整理了。
目录
第一套:

一棵树转化为二叉树,那么这棵二叉树一定为右子树为空的树
计算不同种形态,即计算6个结点的二叉树有几种形态,利用卡特兰数计算:




① 芯片总线每秒传输数据的次数为133.25*8次=1066M次,而存储器总线每个时钟周期传两次数据,所以存储器时钟频率为1066M/2=533M
② 存储器的带宽即存储器的最大数据传输率,存储器总线每秒能传送1066M次数据,一次传输8B数据,1066*8≈8.5GB

考查:时延带宽积。指发送端发送的第一个比特即将到达终点时,发送端已经发出了多少个比特,因此又称以比特为单位的链路长度,即时延带宽积=传播时延x信道带宽。
① 信道带宽的计算使用香农定理 ② 计算传播时延


SR的基本要求:① 发送窗口+接收窗口<=2^n ② 发送窗口>=接收窗口
所以得到发送窗口=11。
注:如果是默认的话发送窗口=接收窗口=
补充:
对于接收窗口来说,其窗口大小为5,即刚开始接收窗口为0~5,但是发送方收到5号帧的确认,说明接收窗口对0号帧发送了确认并向后挪了,只是0号确认帧在发送的时候丢失了。当发送窗口再次发来0号帧时,接收窗口将其丢弃,并再次发送0号帧的确认。



① TCP每发送一个报文段,就对这个报文段设置一个超时计时器。计时器设置的重传时间到期但还未收到确认时,就要重传这一报文段。
② TCP为每个连接设有一个持续计时器,只要发送方收到对方的零窗口通知,就启动持续计时器。若计时器超时,就发送一个零窗口探测报文段,而对方就在确认这个探测报文段时给出现在的窗口值。如果窗口仍然为零,则发送方收到确认报文段后就重新设置持续计时器。
③ TCP还设有一个保活计时器。设想TCP双方已建立连接,但后来客户主机突然出现故障。显然,服务器以后就不能再收到客户发来的数据。因此,应当有措施使服务器不要再白白等待下去,这个问题就可以使用保活计时器来解决。
④ TCP断开连接中的等待2MSL就是由时间等待计时器计时的。

第二套:


所以最少25位

A.64M,说明每个芯片有2^13行2^13列,所以行缓冲为2^13*8b=8KB,所以8个芯片有64KB
B.正确 C.由于DRAM采用地址复用,所以增加1个地址引脚,会增加4倍 D也正确,因为总线宽度64位。


首先要知道求时延的方法:


最好情况:

最坏情况:
不可能出现发送窗口停留在0,1,2的情况,如果停留在0,1,2,接收方不可能收到3,4帧,所以最坏情况如下图:

序号组合:2,3,4 3,4,5 4,5,6 5,6,7
答案:C
这道题不难,只是讲下更简单的方法:

由于等长的子网划分会出现地址的冗余,所以采用不等长的子网划分。
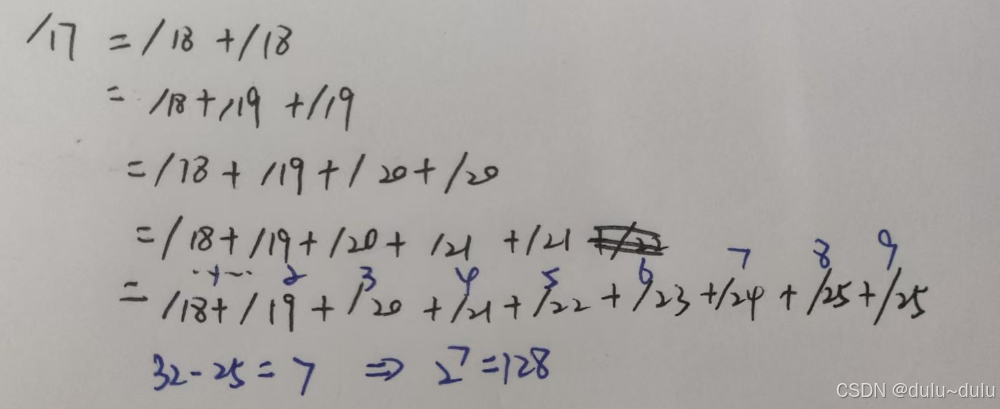
第三套:
这题很简单,只是讲一下技巧:

要让顶点数最少,则连通的点要尽量多,所以图G是n个顶点连通+1个单独的顶点,尽量少的n个顶点连通,并且有36条边,不难想到就是完全图,所以
=36,n=9,再加上一个单独的点,9+1=10

答案:C

补充:算查找成功的平均查找长度可以不花折半查找树,但是如果算查找失败的平均查找长度还是得画图比较方便。


① 操作控制字段需要:3+4(还需要一个表示没有任何微指令)+4+2=13
② 还需要3个外部条件,即上图的判断测试字段,3个外部条件需要3位:3个外部条件不是任意一个中选择一个,而是有3个外部条件都不满足:000,都满足:111。
③ 微指令字长24位,24-13-3=8位,8位表示后继地址字段,所以能表示2^8条指令。
2^8*24b=256*24b

CPU-处理器总线采用同步方式,异步方式只有I/O总线才会使用。
I/O总线大多采用半同步方式,拆分事务方式可以提高总线的有效带宽。
所以C正确,D错误。


I.一条指令结束后,CPU才会采用INT信号,若信号有效,才进入中断响应周期。
Ⅱ.产生越界中断 Ⅲ.产生缺页中断
Ⅳ.进程P要启动外设工作了,进程P使用进程调度程序切换。外设完成工作后,进程响应并处理中断时没有进行进程切换,因为没有使用进程调度程序。即在Q进程响应就在Q进程执行中断服务程序。
注意:中断服务程序不是以单独的进程形式存在的。



主要看这幅图:

答案:A
B.输入进程或输出进程执行的都是I/O指令,都需要在内核态下执行。C.当 用户进程输出数据时,只需要把数据放到输出井中,设备空闲,再从输出井中取数据,这时,两个进程是并发执行的。D.(1) 磁盘 (2) 要进行数据交互的具体外设,如打印机。
① 输入井与输出井在磁盘上开辟,用来存放输入和输出的数据。
② 输入缓冲区与输出缓冲区存在于内存中,都不止一个
③ 输入进程又称为预输入进程,假如正在运行的进程要求得到设备的输入的话,那么就会通过井管理程序从输入井中读过来,而输入井中的数据是外设提前输入到输入井中的,所以输入进程也叫预输入进程。同理,正在运行的作业要进行输出,就会通过井管理程序,将输出的缓冲区的数据放到输出井中,设备空闲后,再通过(输出进程)缓输出进程,输出到输出设备中。
④ 井管理程序,控制输入井和输出井与内存之间的数据交互。
补充:
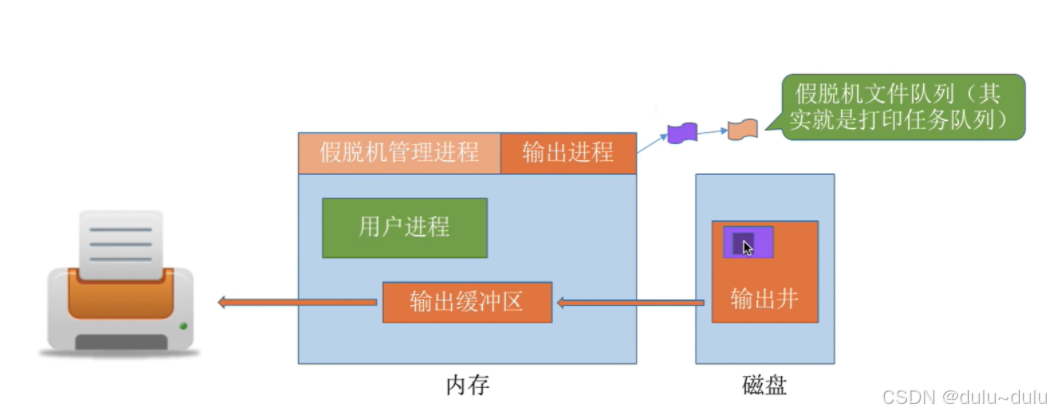
当多个用户进程提出输出打印的请求时,系统会答应它们的请求,但是并不是真正把打印机分配给他们,而是由假脱机管理进程(即整个Spooling系统)为每个进程做两件事:
(1)在磁盘输出井中为进程申请一个空闲缓冲区(也就是说,这个缓冲区是在磁盘上的),并将要打印的数据送入其中:
(2)为用户进程申请一张空白的打印请求表,并将用户的打印请求填入表中(其实就是用来说明用户的打印数据存放位置等信息的),再将该表挂到假脱机文件队列上。当打印机空闲时,输出进程会从文件队列的队头取出一张打印请求表,并根据表中的要求将要打印的数据从输出井传送到输出缓冲区,再输出到打印机进行打印。用这种方式可依次处理完全部的打印任务。这里的空闲缓冲区和文件队列都是在磁盘上。

答案:C
提高磁盘I/O速度的方法:
① 提前读:在读当前盘块的同时,将下一个可能要访问到的盘块中的数据也读入缓冲区。
② 延迟写:在写盘块时、本应将对应缓冲中的数据立即写盘,但考虑到该盘块中的数据在不久之后可能还会被再次访问,因而并不立即将对应缓冲区中的数据写入磁盘,而只是将它置上“延迟写”标志并挂到空闲缓冲队列的末尾。
③ 优化物理块的布局
④ 使用磁盘高速缓存(存在于内存中,之前考察过)
补充:影响页面换入换出效率
① 页面置换算法 ② 写回磁盘的频率 ③ 读入内存的频率
为了减少页面换入换出频率,通常在内存中设置空闲页面链表(记录空闲物理块)和修改页面链表(已修改的页面形成的链表)

RTT=往返传播时延+中间设备的排队时延+中间设备的处理时延
所以选择D选项。

每层的协议数据单元都有一个通俗的名称,如物理层的PDU 称为比特流,数据链路层的PDU称为帧,网络层的 PDU 称为分组,传输层的PDU称为报文段。
序号占32位,范围是0~2^32-1,若A,B两端进行通信,A端发送0~2^32-1个帧,则在发送下一段数据的0号帧时,必须保证前一段数据的0号帧被接收,否则之前具有相同序号的PDU会从网络消失,为了避免这样的序号绕回,设定了PDU的最大生存时间,题目是51.2s,则表示51.2s后,数据一定能被接收方完整接收。


第四套:

(1)控制信息,地址信息是CPU发送给I/O接口的。(2)数据信息是双向传输的。(3)状态信息是I/O接口反馈给CPU的。
注意:
数据信息≠数据线上传输的信息。
数据线上传输的信息有两类:
① 数据缓冲寄存器:主机与外设进行数据交换
② 状态/控制寄存器:主机发出控制命令或者外设返回一些状态信息。
控制信息≠控制线上传输的信息。
控制信息是CPU向I/O接口发送的控制命令;而控制线上的信息可以是双向的,例如I/O接口向CPU发送中断请求信号。
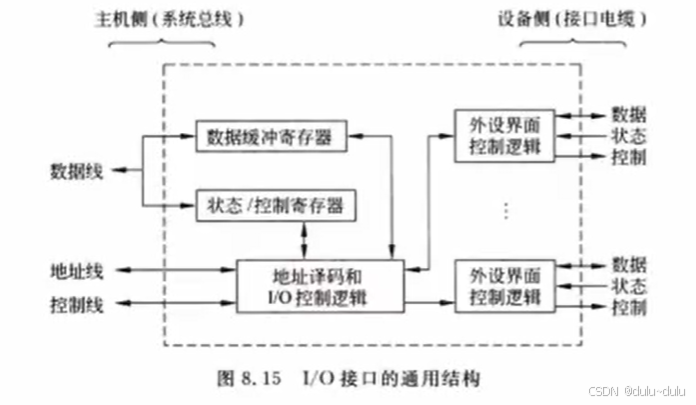

答案:B
进程地址空间大小指的是进程虚拟地址空间大小,它是由操作系统决定的,一个操作系统分配给进程的地址空间大小都是一样大的,所以没必要存下来。
PCB包含的内容:
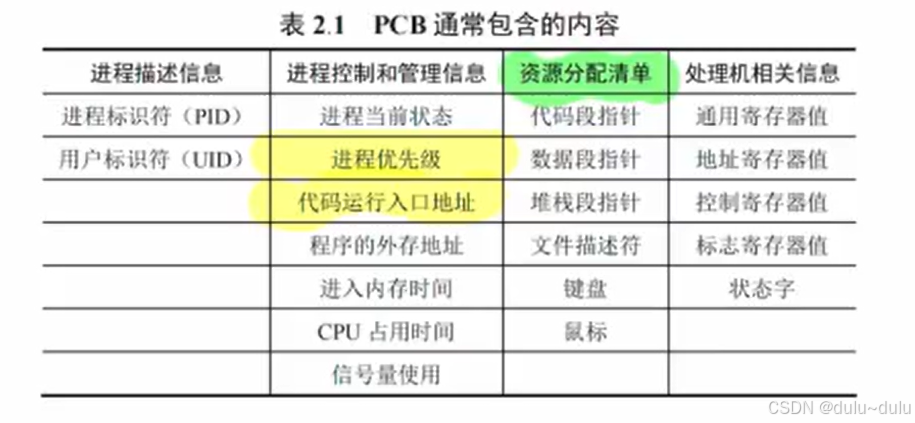

对于B,在多线程进程中,线程是有独立的栈空间的
王道书有写:
同一进程中的所有线程都完全共享进程的地址空间和全局变量。各个线程都可以访进程地址空间的每个单元,所以一个线程可以读、写或甚至清除另一个线程的堆栈。(一个线程去访问另一个线程的堆栈发生在异常的情况下,不能说线程间共享堆栈)。
其他选项:


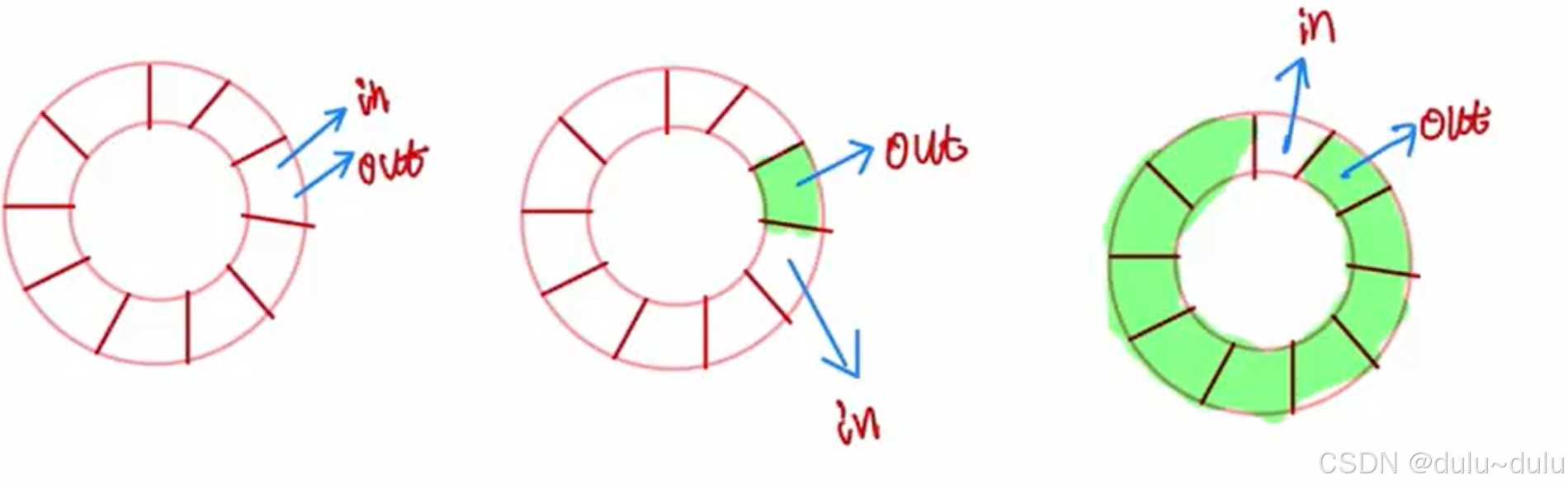
这题考察的数据结构循环队列的知识点:以牺牲一个空位为代价判断队满或队空。
答案:B

答案:B
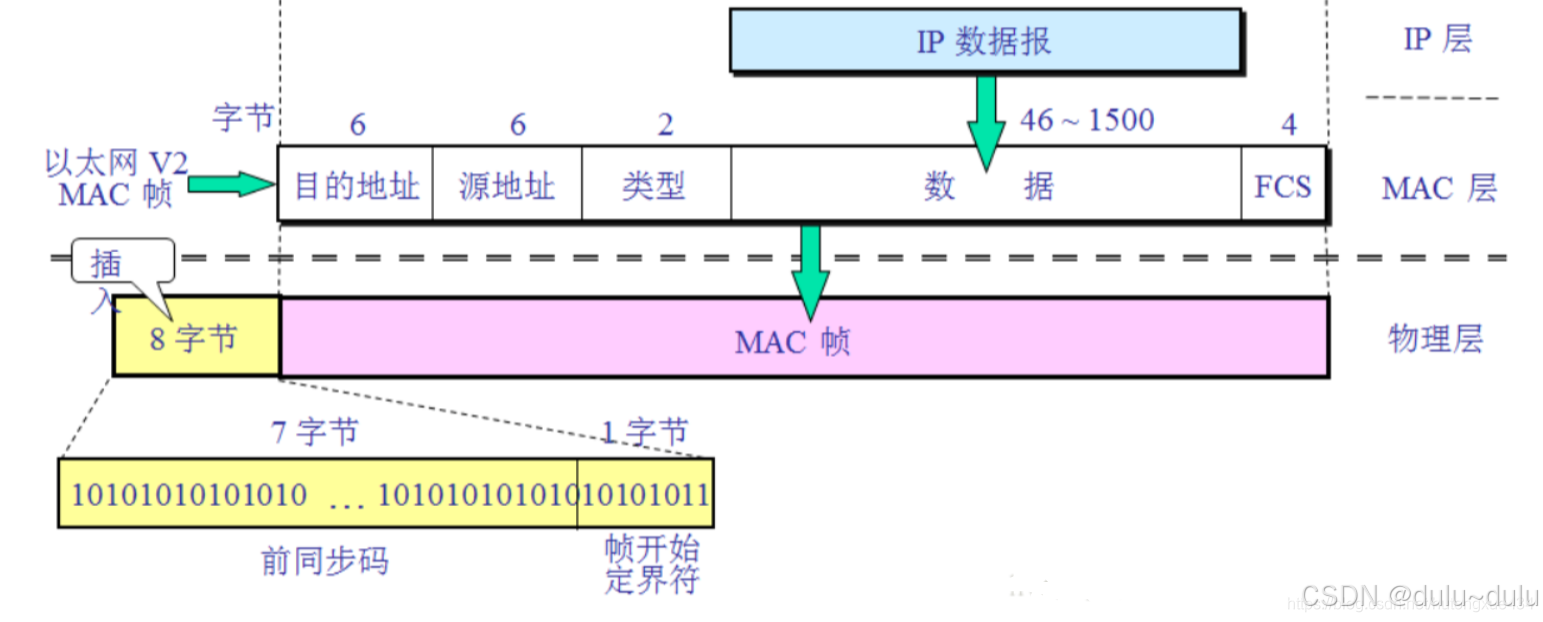
局域网能看见的数据也就是数据帧的数据部分,即IP数据报。
一定要区分数据帧的数据部分和IP数据报的数据部分:
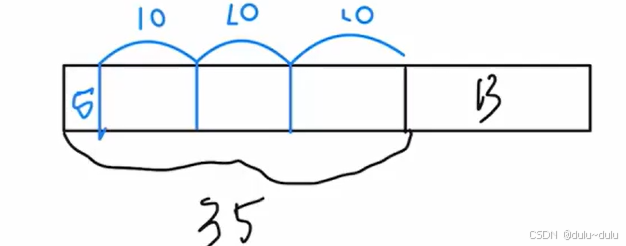
IP数据报大小,400B的数据部分以及20B的首部
这里局域网能传送的最长数据帧的数据部分只有1200bit,也就是IP数据报长度1200bit(150字节),除去首部就是130B,分片大小要是8B的整数倍(最后一个分片除外),所以分片如下:
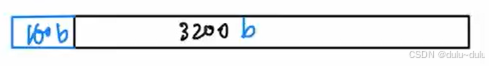

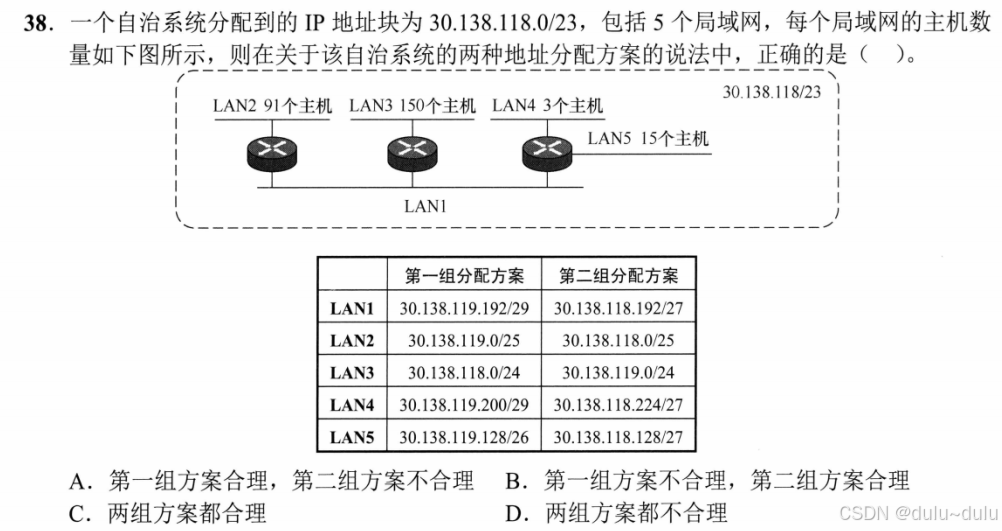
是否合理要看两点:
① 是否包含在被分配的IP地址块中,如该题 一个自治系统分配到的IP地址块为30.138.118.0/23。
② 每个IP地址空间是否有重叠。
③ 为每个网络分配的IP地址是否足够。
答案:C
分配网络前缀时,应先分配地址数量较多的前缀。题目没有说LAN1有几个主机,但至少需要3个地址以供3个路由器的接口使用。
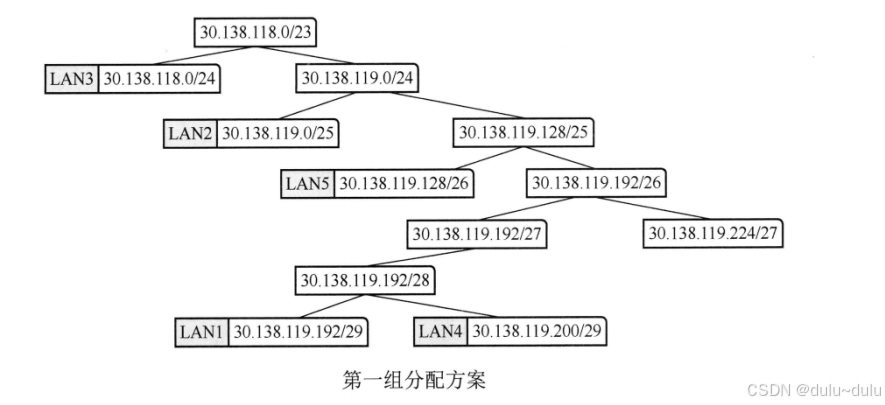
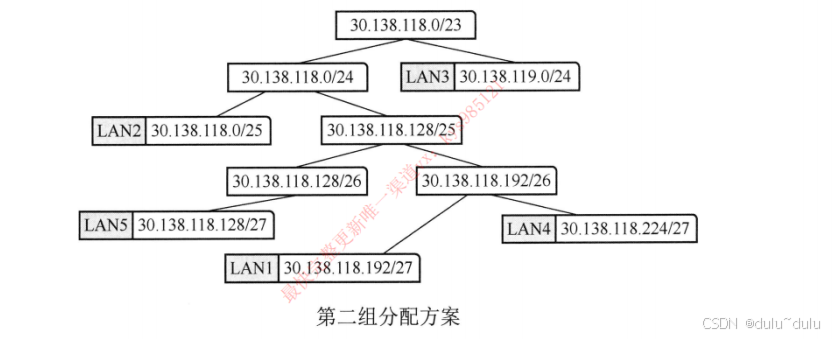

UDP检验和的计算方法如下:
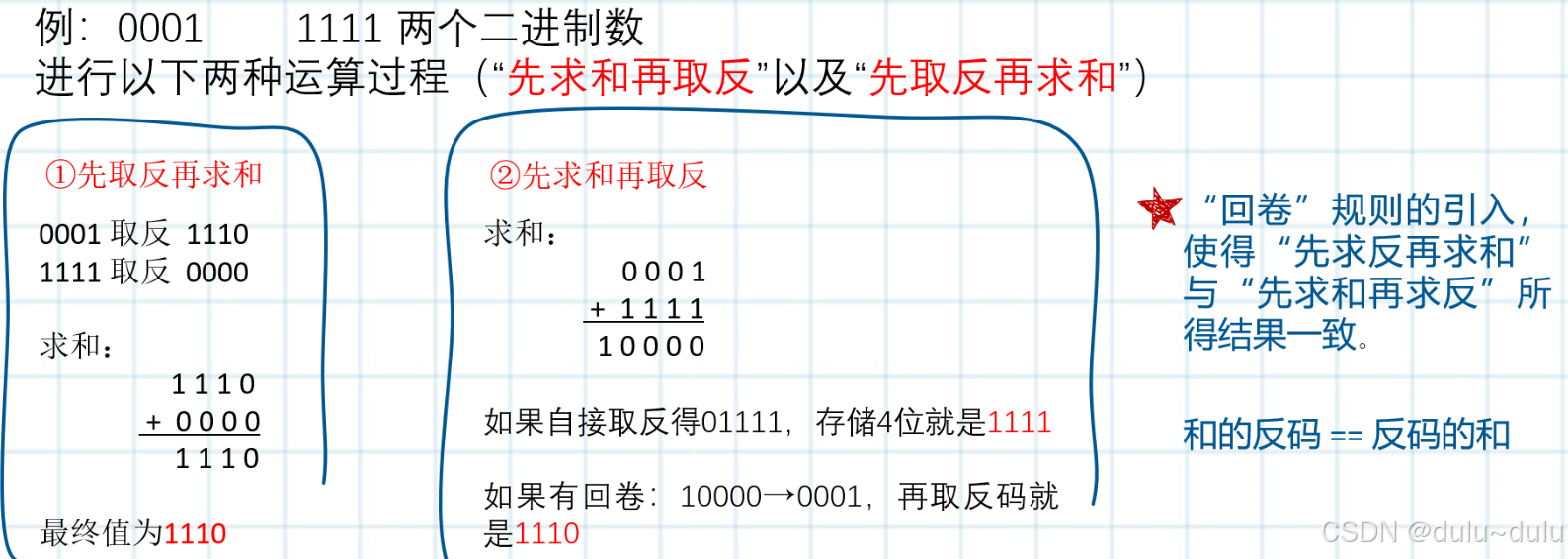
① ② 正确。
UDP的上层用户可以关闭检验和功能(在UDP的传送过程中不使用检验和),这样做的好处是可以提高UDP的传送速度(但要牺牲一些可靠性)。如果发送方决定不使用检验和,那么发送方的检验和的值应置为全0。这表示该数值不是计算出来的,而是发送方关闭了检验和的检错功能,选项 ① 正确。UDP规定:如果检验和的计算结果刚好是全0,就人为地将它置为全1(以区分关闭检验和),选项 ② 正确。
③ 以先求和再取反为例,如果UDP计算结果为全1,也就是取反后为全1,那么取反前的求和结果就是全0,只有一种情况,就是参与校验的数据全为0,这是不可能的。

第五套:

由于栈指针指向当前元素的下一个位置,所以应该是S2.top+1=S1.top
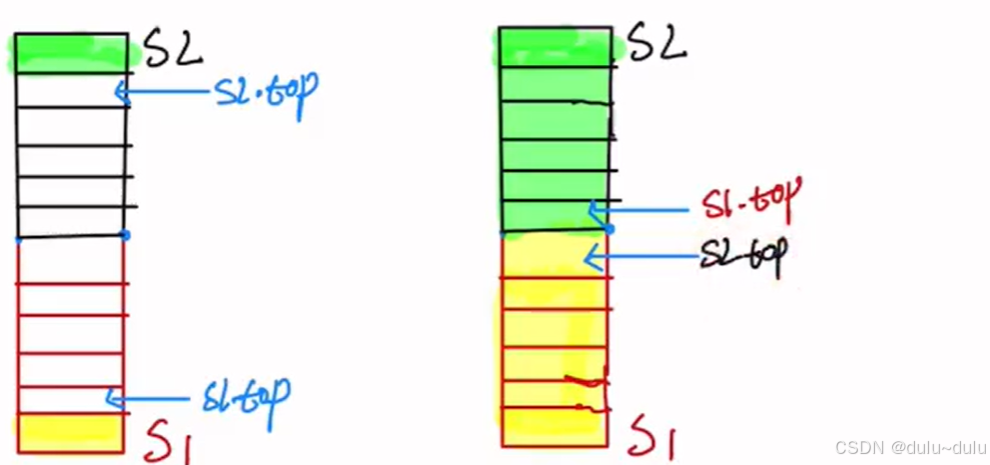

答案:C
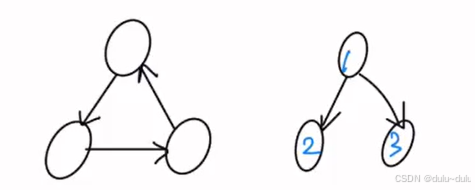
对于B,解析有错:
解析“不同的强连通分量需要进行单独1次的深搜”,例如下图:1,2,3都是强连通分量,但是只需要从1出发进行深搜,只需要1次深搜。但是如果有向图是一个强连通分量,那么只需要1次深搜就可以。
对于D:拓扑序列可以是1-->2-->3,也可以是1-->3-->2


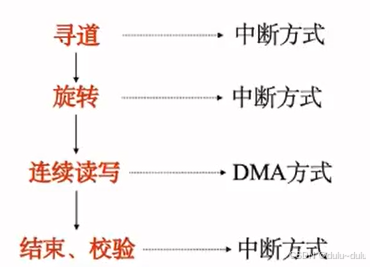
A.访问内存时缺页,会引发内部中断,即故障。
B.解析说法错误,Cache没有命中不是外部中断,也不是内部中断。
C.磁盘寻找到正确的磁道,以及旋转到对应扇区后,都会向CPU发出中断请求。
D.属于内部异常中的“故障”。




相关题型:
lCDMA码分多址复用计算题_在一条广播信道上连有4个站点a、b、c、d,采用码分复用技术,当a、b、c要向d发送数-CSDN博客

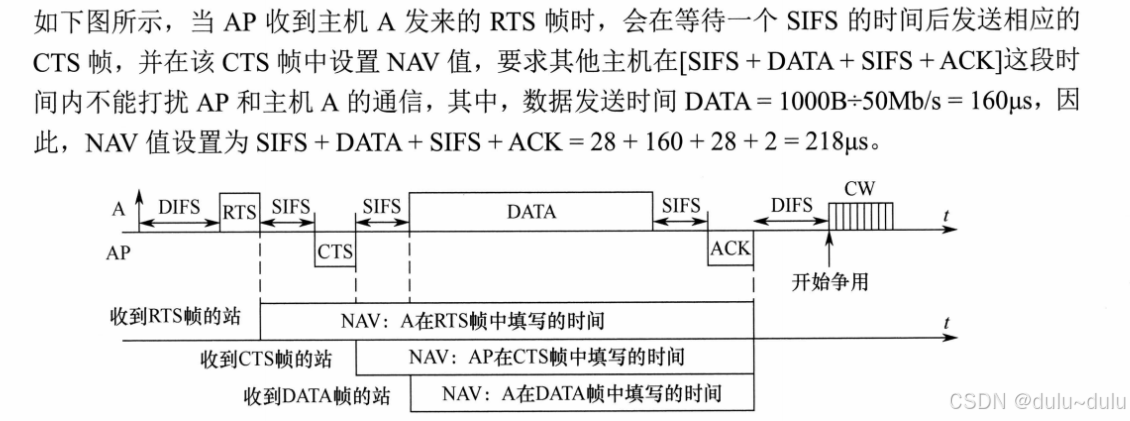
NAV向量会告诉其他站点哪段时间不能发送数据:
如下图所示,当发送方发送了RTS帧之后,其他站点会收到RTS帧。从其他站点收到RTS帧,到接收方回复ACK这段时间就是RTS帧中NAV的值。其他分析也一样。
第六套:

由于是循环队列,需要考虑front>rear的情况:
答案:A

浮点数运算步骤:① 对阶 ② 尾数相加减 ③ 规格化 ④ 舍入 ⑤ 判溢出
对于A,EX- EY是对阶时候的操作,而转入相应的溢出程序是"判溢出"要完成的操作。
由于
溢出,补码的表示范围是-128~127
① 若EX>EY,则EX-EY>=127 EX>=EY+127,而移码能表示的范围是-126~127,所以:EX >= -126+127=1
用移码表示0,即0+127=127(0111 1111),而EX>=1,所以EXS(最高位)一定为1
由于EX>EY,所以"小阶向大阶看齐",y要右移至少128位,而单精度浮点数的尾数部分只有23位,所以右移128位,尾数部分即使有数也被移出去了,所以尾数部分=0
② 若EX<EY,即EX-EY<=-128,EX<=-128+EY,EY的最大值为127,所以EX<=-1,-1+127=126(0111 1110),所以EXS=0。EX<EY,x要进行右移操作,由于至少右移128位,所以尾数有效数据也全被移除。
答案:B

这里主要说比较的流程,如下图所示:
① 根据组号找对应组。
② 将主存的标记位和Cache中的tag位进行比较,如果是8路组相联就需要8个比较器,如果是2路组相联就需要2个;直接映射相当于每组1个,则只需要1个比较器;全相联映射每个Cache行都需要一个比较器。
③ 有效位要为"1"。两者相与,表示tag相同且有效位为"1",则Cache行命中。
④ 若Cache命中,取Cache行数据输出。若Cache不命中取,主存数据输出。
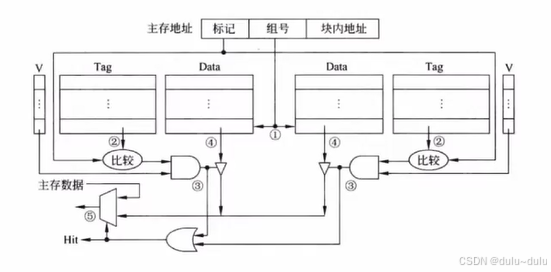
答案:C

B,C都是错的。B错误,TLB缺失,只会到主存里面找页表,若页面没有在主存中,则从磁盘调入,并更新TLB,不会更新Cache,就算主存里面找到页表,也只会更新TLB,不会更新Cache。
C.很明显,TLB和Cache缺失都都不会导致执行错误。


对于B,之前学到的取指译码的过程都是有信号的,这是因为我们分析的都是单总线数据通路,而在流水线数据通路中,只有译码阶段结束,即ID结束,才会产生控制信号,而IF和ID的执行是由时钟信号控制的。
答案:C
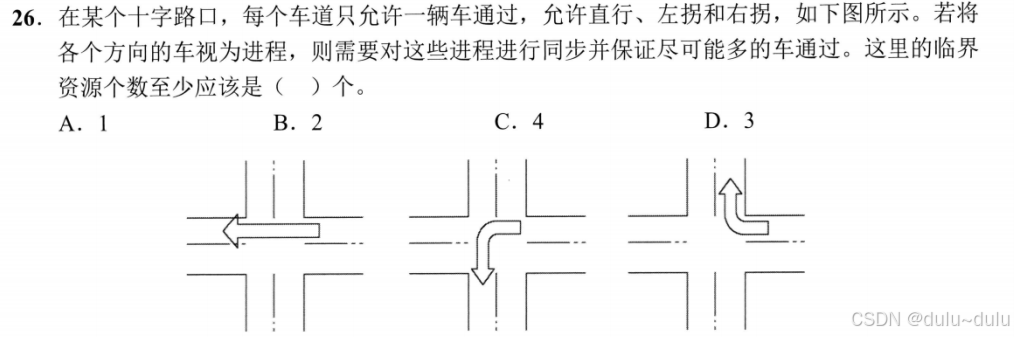
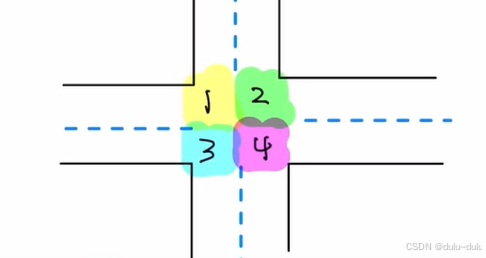
要并发度尽可能高,至少需要4个临界资源。若只定义两个临界资源,1,2一个临界区域,3,4一个临界区域,那么从南向北与从北向南的车就不能同时通过,因为会同时经过两个临界区。

需要考虑两个公式,香农定理和奈氏准则:
奈氏准则:
,这里的W就是信号能通过的频率范围,n表示一个码元对应的信号的状态数。



非坚持监听算法不能减少网络空闲时间:
① 非坚持相对于1-坚持监听算法,会等待随机的时间再监听。
② 非坚持相对于p-坚持监听算法,非坚持型检测到信道忙,会随机等待一段时间(多个时隙),而这一段时间肯定比下一时隙再监听来得慢。
并且p-坚持型监听算法,能够减少冲突的概率,若A,B同时检测到信道空闲,同时发送数据,那么就会发生冲突。
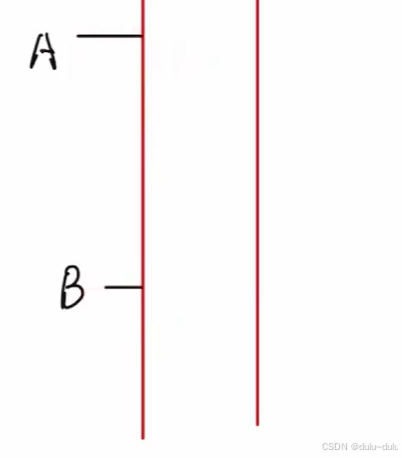

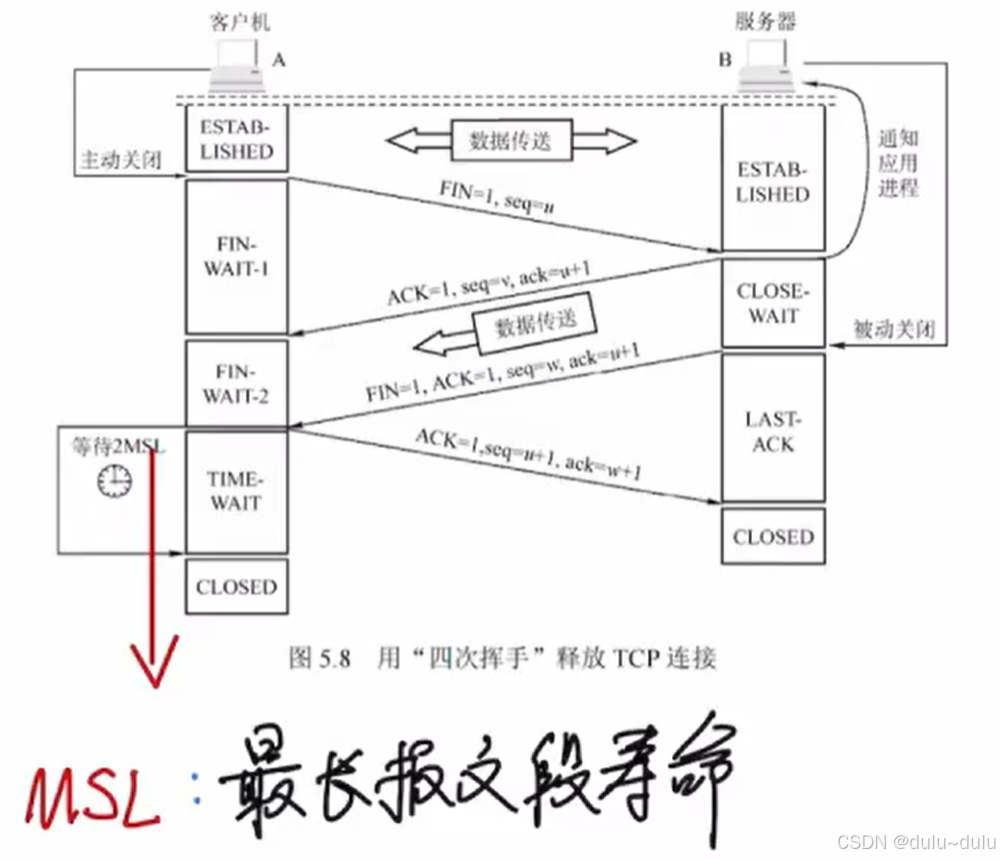
为什么要设置MSL:
① 保证A发送的最后一个报文段顺利到达B,假如A发送的最后一个报文段丢失,即ACK报文段丢失,那么B就会重传FIN报文段。如果此时A已经关闭,那么服务器B就不能close,如果有MSL,A就会重传ACK报文段,并且重启时间等待计时器。
② 使本连接产生的报文段都从网络中消失,否则会对后续的TCP连接产生干扰。
第七套:
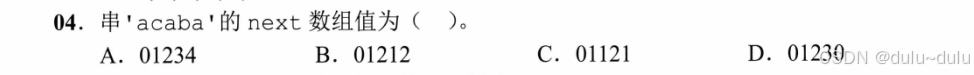
这里只补充:
若next数组第1个数组内容为-1,则这个模式串是从next[0]开始存放的。若next数组从next[1]开始存放那么next[1]为0,next[2]为1。
nextval数组值为:01020
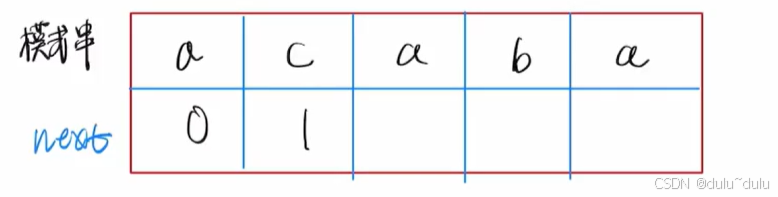

这里可以记公式也可以自己推:
答案:C

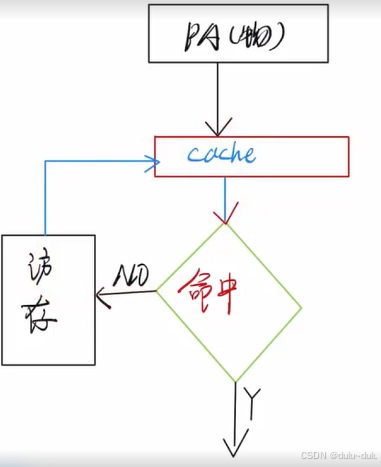
说明:
访存时间实际上是:访问Cache时间(未命中)+访存+调入Cache后访问Cache的时间,这道题的50ns就是这一系列时间加起来的时间。
Cache-主存系统的效率:Cache命中时间/平均访存时间。


① "起始和转移地址发生器"会根据机器指令的操作码字段产生入口地址,入口地址存入CU中。
② 微程序控制单元会使用这个地址从CU中取出第一条微指令,并将指令放到微指令寄存器(uIR)中。 微指令的操作码通过译码产生相应微命令。
③ 每当一个时钟信号到来时,uPC+1,指向下一个要执行的微指令的地址。这样,后续的微指令就可以被顺序地从控制存储器中取出并执行。
注意区分:机器指令的操作码和微指令的操作码。机器指令的操作码用于生成微程序入口地址,微指令的操作码用于生成相应微命令。
转移地址指令,类似于指令的转移指令,转移地址指令会被送到"起始和转移地址发生器",如果是条件转移,还需结合条件码,最后生成转移地址。
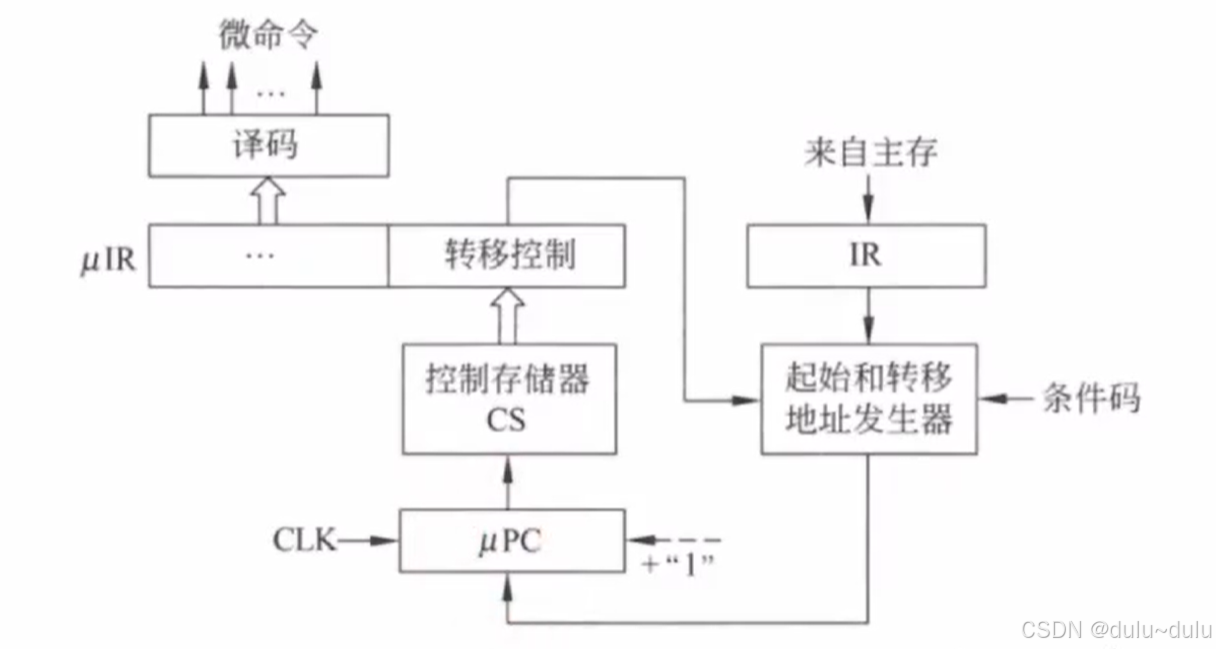
答案:C

答案:D
主要补充下面的知识点:
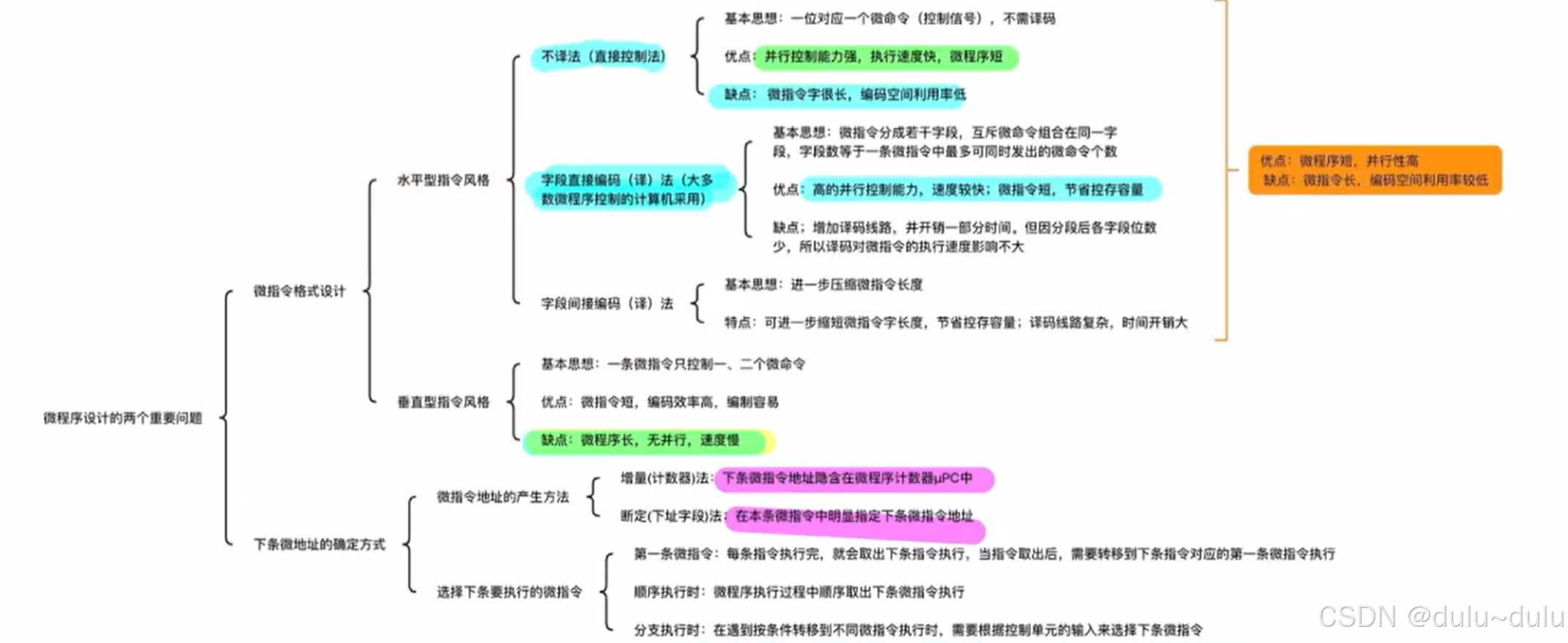


四个说法都错误。
A.中断响应周期,关中断是由硬件完成的。
B.最后一条指令是中断返回指令,需要恢复PC和PSWR(标志寄存器)中的值,与无条件转移指令是不同的。
D.DMA方式是由硬件完成数据传输的,这里不包括CPU预处理和后处理的过程。

如果按照① ---> ② ---> ④ ---> ⑤ ---> ③ ---> ⑥执行,P0,P1会同时进入临界区。
如果按照① ---> ④ ---> ② ---> ① ---> ⑤ ---> ① ---> ④ ---> ② ...这样的顺序,可能会发生死循环,但是这样的概率极低,所以选B。另一个角度,产生饥饿的原因:
① 资源分配不足。
② 分配策略不公平。
但是两段代码没有体现这两种现象。


① 不引入索引节点:
一个文件控制块大小为64B,1个盘块能装512B/64B(8)个文件控制块,总共256个目录项,256/8=32个磁盘块。所以平均启动磁盘次数(文件放在第1个磁盘块,查1次,第2个,查2次....):
1+2+3+4....+32/32=1+32/2=16.5
② 引入索引节点:
需要先到找到文件FCB,再根据索引节点号找到相应索引节点。
文件名+文件索引节点编号=6+2=8B,512/8=64个文件目录,256/64=4个磁盘块:
1+2+3+4/4=2.5次,最后再查到索引节点:2.5+1=3.5
16.5-3.5=13次
答案:C

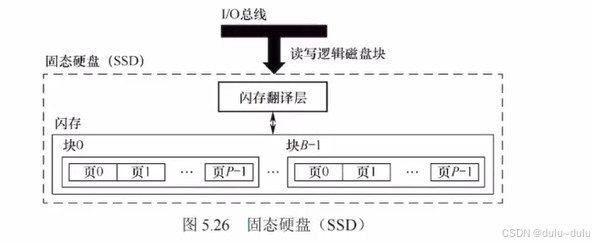
A.固态硬盘基于闪存(Flash)技术。C.固态硬盘的随机写于常规硬盘相差也很大,闪存翻译层可以快速定位到要读的区域,而不需要常规磁盘:寻道时间+旋转延迟时间+读数据的时间。
答案:B

2^0,2^1,2^2,2^3为校验位:
15二进制1111,在权值为1的位为"1",所以15位要参与S1的检验过程。以此类推,所有奇数位都要参与S1的检验:



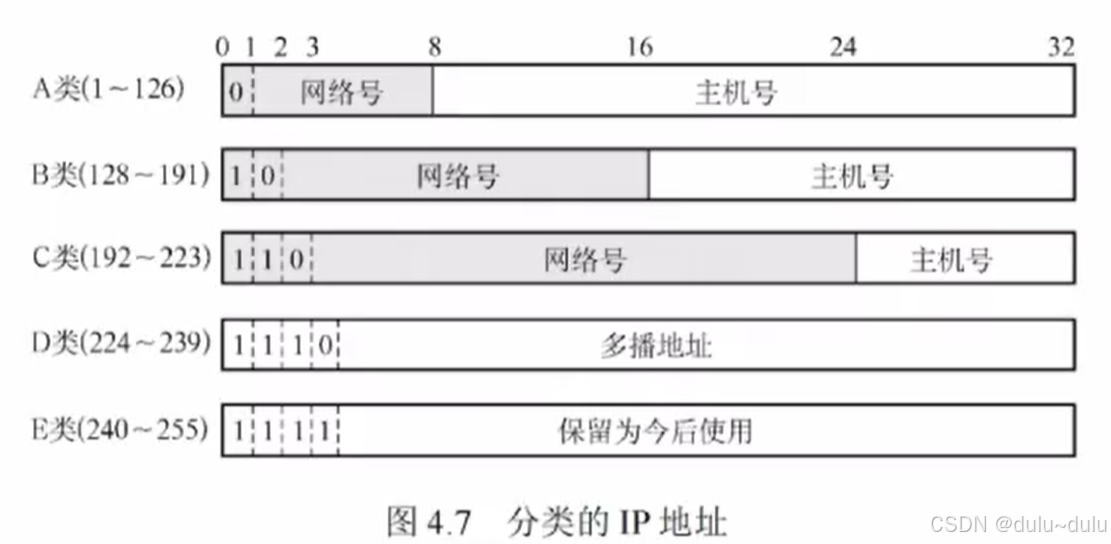
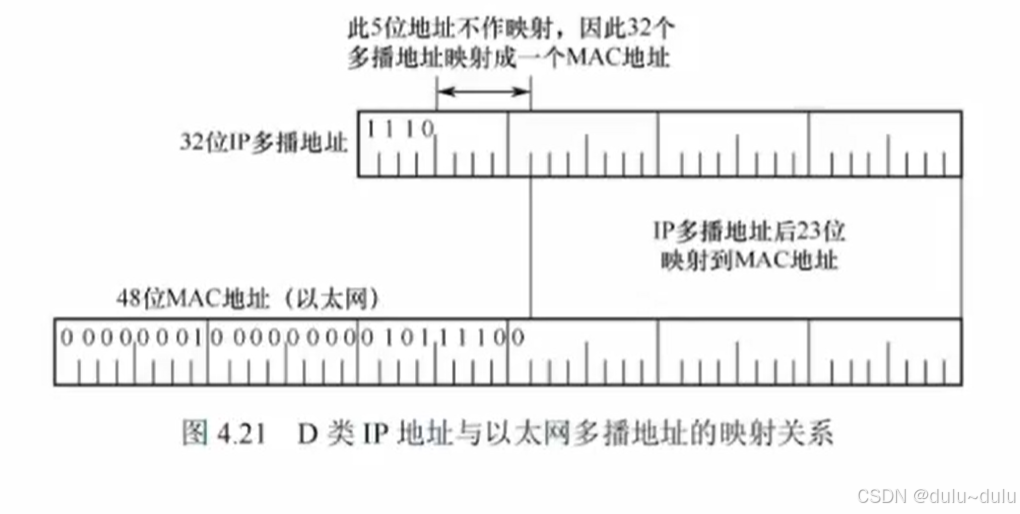
多播地址为D类地址,范围:224.0.0.0~239.255.255.255
32位IP地址,只取后23位,映射到以太网多播地址的后23位,前25位固定。
所以:

第八套:
比较常规,没有特别偏的知识点:
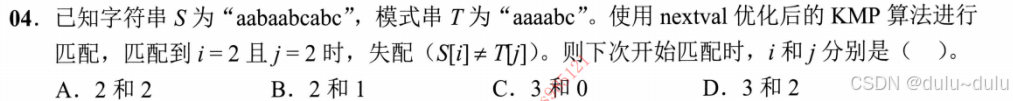
这里只要注意:序号从0开始,next数组为-1,0开头,序号从1开始,next数组开头为0,1。
先求next数组,再求nextval数组:
next数组:-1 0 1 2 3 0
nextval数组:-1 -1 -1 -1 3 0
或者可以直接匹配出来,也就是观察出来接下来应该将i=3,j=0进行比较。
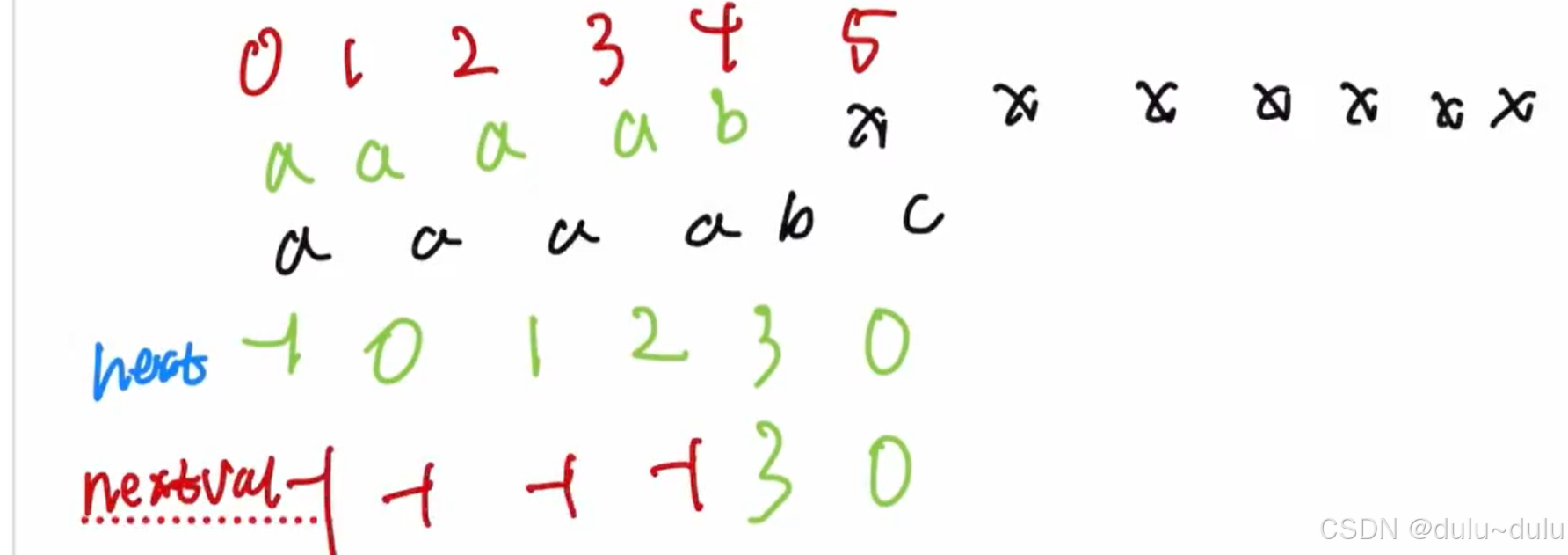
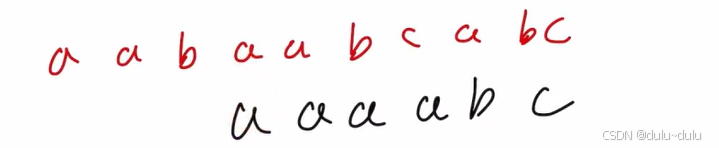

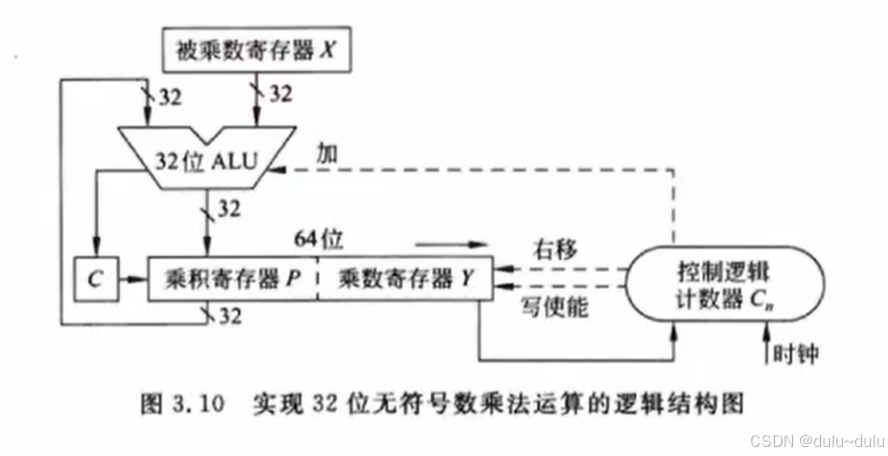
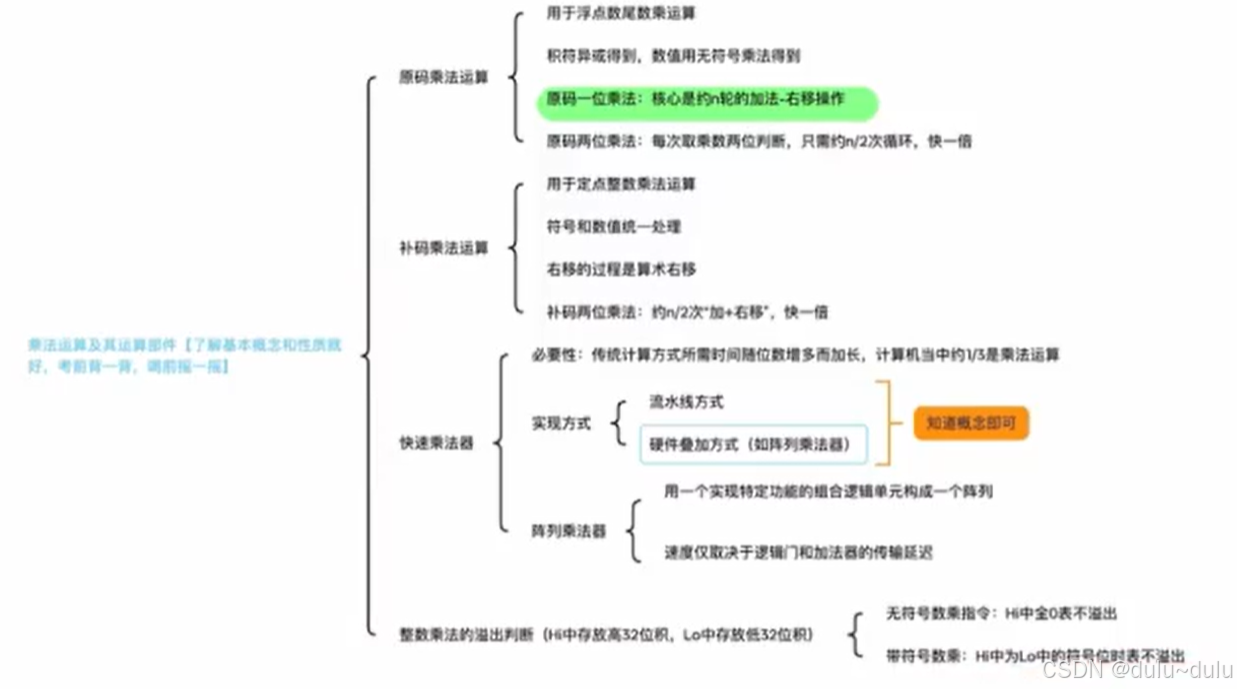
原码乘法,符号位要单独计算,剩下的31位,每一位都需要经过1次加法和右移:
31*2=62,再加上1次判断符号位的异或运算:62+1=63

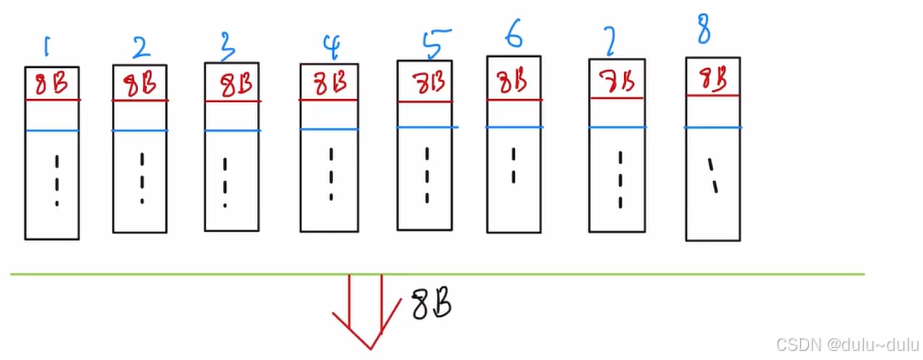
8B/10ns=800MB/s
这里补充一点:
这里采用的是低位交叉存储的轮流启动方式,也就是下面第1个图,则流水线充分执行起来后,每隔10ns提供8B数据。总线周期=1/8的存储周期
若采用同时启动方式,则总线周期=存储周期

对于CPU中的所有寄存器,用户都能访问吗?
CPU中的寄存器分为用户可访问寄存器和用户不可见寄存器。一般把用户可访问寄存器称为通用寄存器(GPR)。这些寄存器都有一个编号,在指令中用编号标识寄存器。因此执行指令时,指令中的寄存器编号要送到一个地址译码器进行译码,然后才能选中某个寄存器进行读写。通用寄存器可以用来存放操作数或运算结果,或作为地址指针、变址寄存器、基址寄存器等。
CPU中有一些寄存器是用户不可见的,没有编号,不能通过程序直接访问。如指令寄存器 IR,程序状态字寄存器 PSWR,存储器地址寄存器 MAR,存储器数据寄存器 MDR 等。对于程序计数器PC,它虽然是专用寄存器,没有编号,不能在指令中被明确指定,但用户可以通过转移类指令来修改其值,以改变程序执行的顺序。CPU 中的寄存器:
CPU中存在大量寄存器,根据对用户程序的透明程度可以分成以下三类(1)用户可见寄存器
指用户程序中的指令可直接访问或间接修改其值的寄存器。包括通用寄存器、地址寄存器和程序计数器PC。通用寄存器可用来存放地址或数据;地址寄存器专门用来存放首地址或指针信息,如段寄存器、变址寄存器、基址寄存器、堆栈指针、帧指针等;程序计数器 PC存放当前或下条指令的地址。
(2)用户部分可见寄存器
指用户程序中的指令只能读取部分信息的寄存器,如程序状态字寄存器PSWR或标志(条件码)寄存器FLAG,其内容由CPU根据指令执行结果自动设定,用户程序执行过程中可能会隐含读出其部分内容,以确定程序的执行顺序,但不能修改这些寄存器的内容。
(3)用户不可见寄存器
指用户程序不能进行任何访问操作的寄存器,这些寄存器大多用于记录控制信息和状态信息,只能由CPU硬件或操作系统内核程序访问。例如,指令寄存器IR用来存放正在执行的指令,只能被硬件访问;存储器地址寄存器(MAR)和存储器数据寄存器(MDR)分别用来存放将要访问的存储单元的地址和数据,也由硬件直接访问;中断请求寄存器、进程控制块指针、系统堆栈指针、页表基址寄存器等寄存器只能由内核程序访问,因此也都是用户不可见寄存器。

I,Ⅱ由DMA控制器完成,Ⅳ是由中断服务程序完成的。程序中断部件提出中断,CPU执行相应的中断处理程序处理中断。
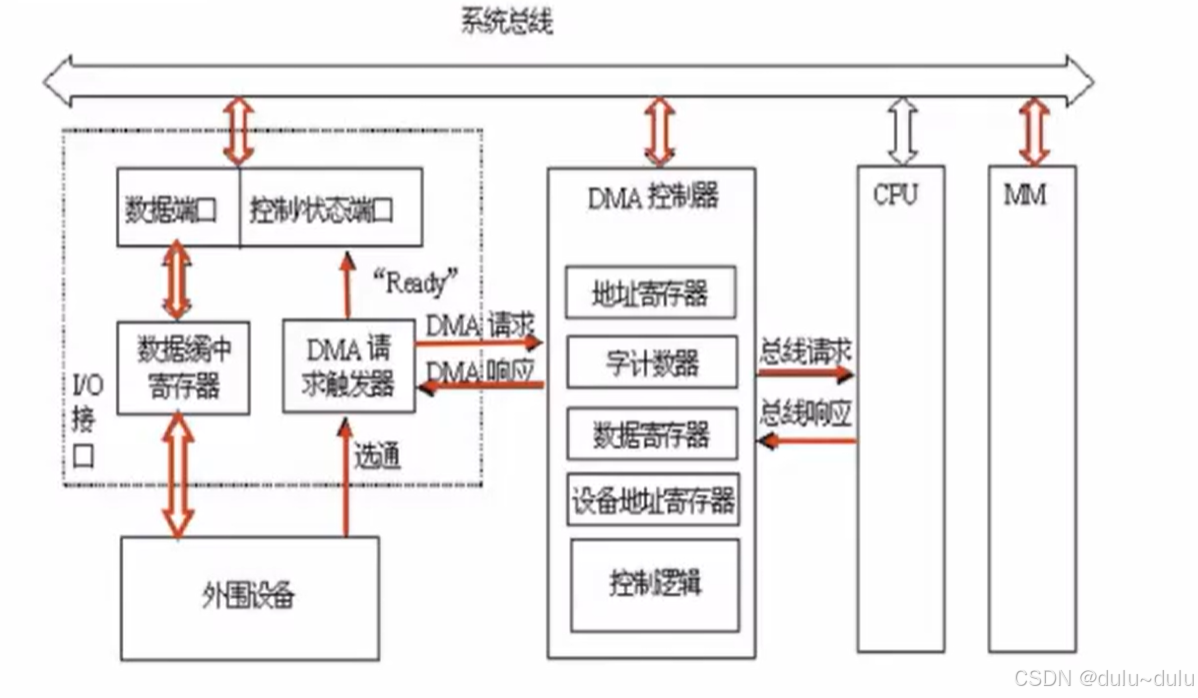
DMA方式的流程:
① 预处理:设备驱动程序执行I/O指令设置DMA控制器相关参数(内核)。
② 数据传输:每当外围设备向I/O接口的数据缓冲寄存器存满数据后,向DMA控制器发送DMA请求,DMA控制器再向CPU发出总线请求(这一个过程叫做DMA请求)。
③ 完成传输后I/O接口向CPU发出中断,CPU会进行后处理,也就是响应中断请求,并检查本次中断是否出错或传输是否完成。

除了1级页表(顶级页表),其他页表都要存满页表项。每页能够存放2^10个页表项:

设备无关层和设备驱动程序都会检查I/O命令的合法性


MAC层的“类型”字段会指明封装的IP数据报采用的是什么协议。接收方收到MAC帧后,会通过"类型"得知如何解读IP数据报(数据部分)的内容。
数据链路层的服务访问点:类型字段
网络层的服务访问点:协议字段(告诉接收方按照TCP还是UDP格式解析传输层数据)
传输层的服务访问点:端口号字段(告诉接收方应该交付给应用层的哪一个进程)
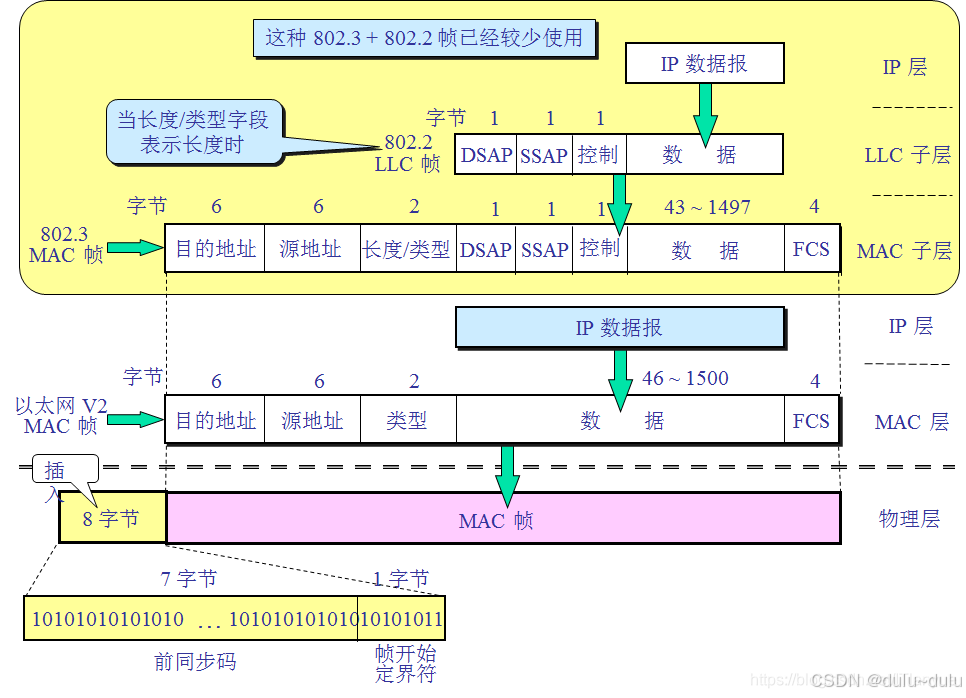

答案:B
与IPv4相比,IPv6对首部中的某些字段进行了如下的更改:
取消了首部长度字段,因为它的首部长度是固定的(40字节)
取消了服务类型字段,因为优先级和流标号字段实现了服务类型字段的功能。
取消了总长度字段,改用有效载荷长度字段。
取消了标识、标志和片偏移字段,因为这些功能已包含在分片扩展首部中。
把 TTL字段改称为跳数限制字段,但作用是一样的(名称与作用更加一致)。
取消了协议字段,改用下一个首部字段。
取消了检验和字段,这样就加快了路由器处理数据报的速度。我们知道,在数据链路层对检测出有差错的帧就丢弃。在运输层,当使用UDP时,若检测出有差错的用户数据报就丢弃。当使用TCP时,对检测出有差错的报文段就重传,直到正确传送到目的进程为止。因此在网络层的差错检测可以精简掉。取消了选项字段,而用扩展首部来实现选项功能。

这里只补充UDP面向数据报,TCP面向字节流的原因:
面向报文的传输方式是应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。因此,应用程序必须选择合适大小的报文。若报文太长,则IP层需要分片,降低效率。若太短,会使IP太小。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。这也就是说,应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。
虽然应用程序和TCP的交互是一次一个数据块(大小不等),但TCP把应用程序看成是一连串的无结构的字节流。TCP有一个缓冲,当应用程序传送的数据块太长,TCP就可以把它划分短一些再传送。如果应用程序一次只发送一个字节,TCP也可以等待积累有足够多的字节后再构成报文段发送出去。
在TCP建立连接前两次握手的SYN报文中选项字段的MSS值,通信双方商定通信的最大报文长度。如果应用层交付下来的数据过大,就会对数据分段,然后发送;否则会通过滑动窗口协议来控制通信双方发的数据。


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









