







1.确定自己的硬件信息
- 确定电脑是否有英伟达(NVIDIA)显卡(如果没有此教程后续做不了)
方法一:
任务管理器-性能-GPU-查看是否有NVIDIA字眼

方法二:
win+x-设备管理器-显示适配器
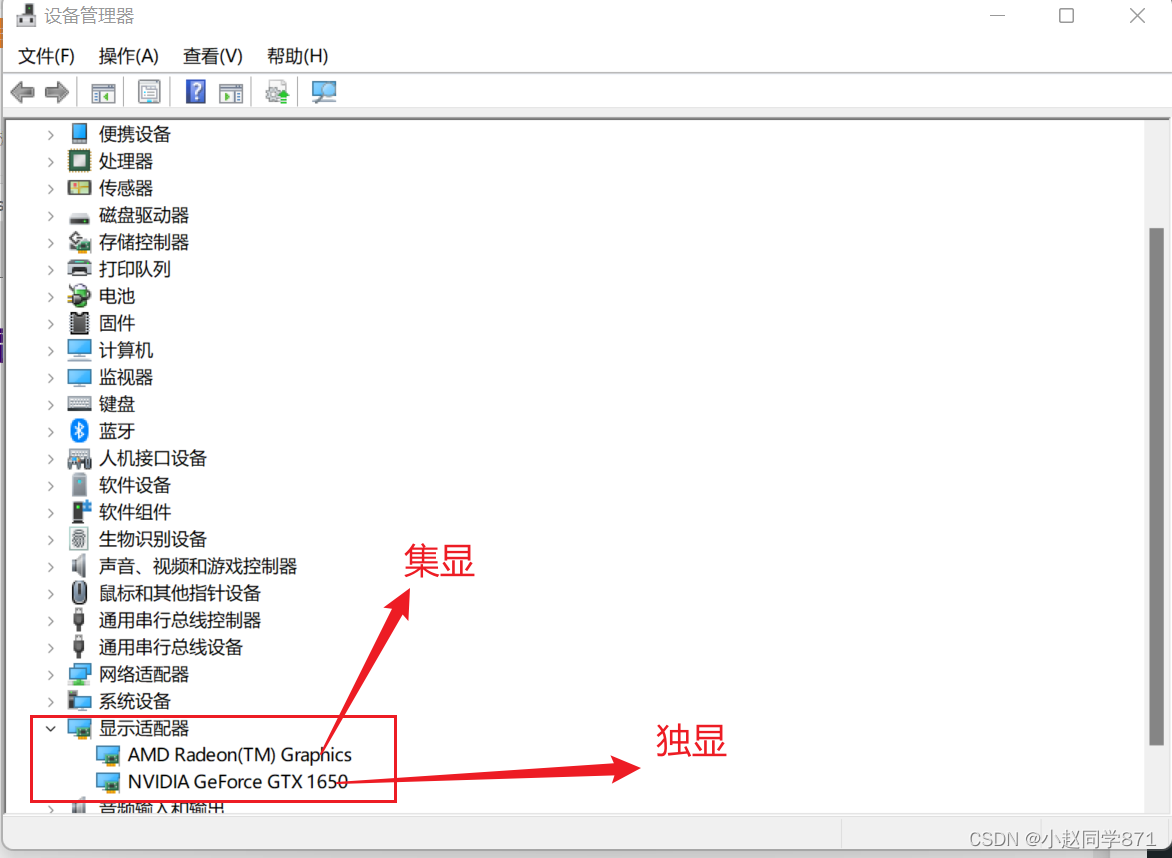
有时候可能独显没有启用通过方法一是无法看到独显的,这个时候是需要自己手动点击独显进行启用,这样后面是深度学习任务才可以正常使用NVDIA的GPU
- 集显:任务不大一般电脑都采用集显
- 独显:性能更好一点任务大电脑会自动进行独显运行
- 当然可以设置任务都采用独显或者个别软件采用集显个别采用独显
这里可以用NVIDIA控制面板进行设置
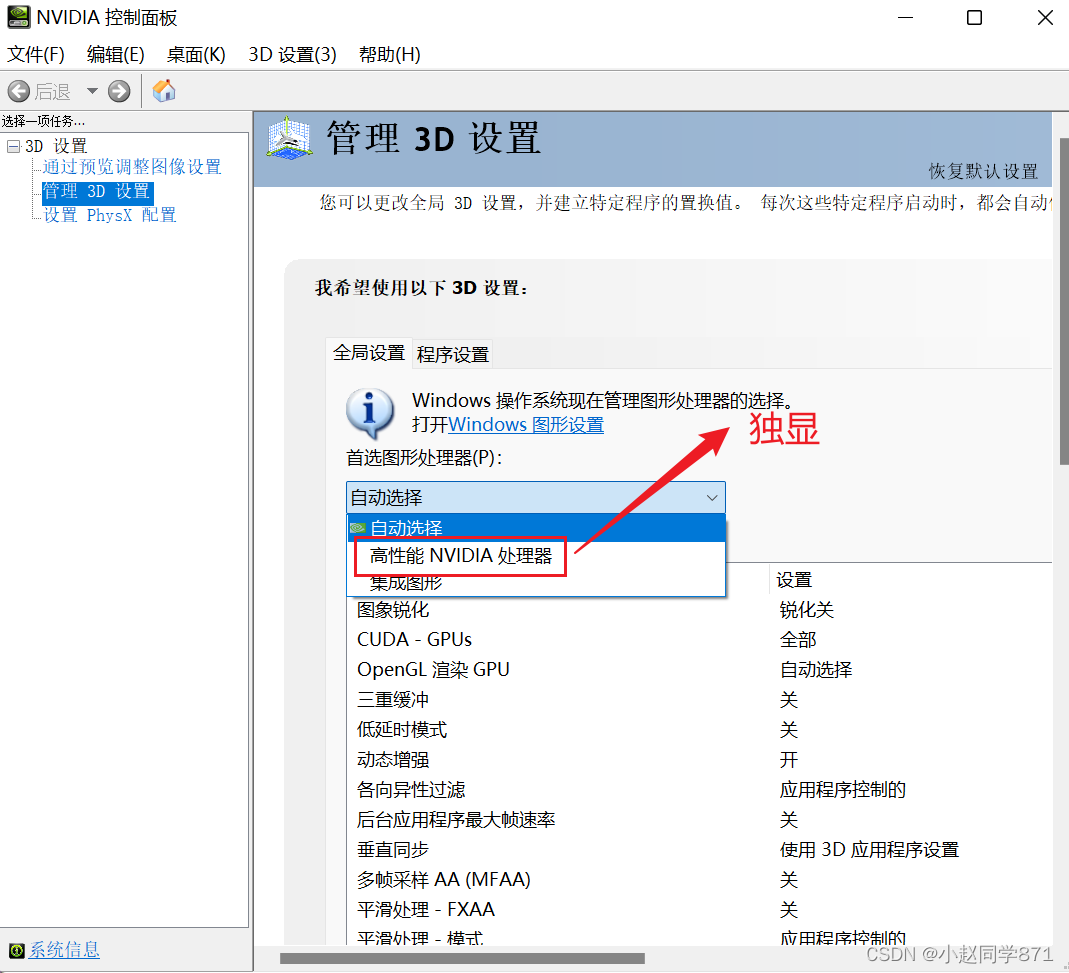
这里一般不设置因为跑深度学习任务我们有专门指令可以指定GPU进行数据的处理,一般不用设置,但是玩游戏什么的可以自己设置
- 如果自己没有NVIDIA GPU的当然也可以采用CPU跑数据但是效率没有那么快
2.下载Anaconda
Anaconda历史版本下载地址
建议不要下载最新版本,下载前几年的版本,因为新版本会因为兼容性问题出现差错,不好解决
具体安装过程这里不多赘述,可以参考超详细Anaconda安装教程
3.利用conda或者pip安装PyTorch
3.1创建一个虚拟环境(比如叫做xiaozhaopytorch)
#利用conda create 指令创建新的虚拟环境
conda create -n 虚拟环境名字 python=版本
#添加镜像加速
conda create -n 虚拟环境名字 python=版本 -c 镜像地址

3.2算力、CUDA Driver Version 、CUDA Runtime Version
3.2.1首先确定自己显卡的算力-确定自己的显卡型号
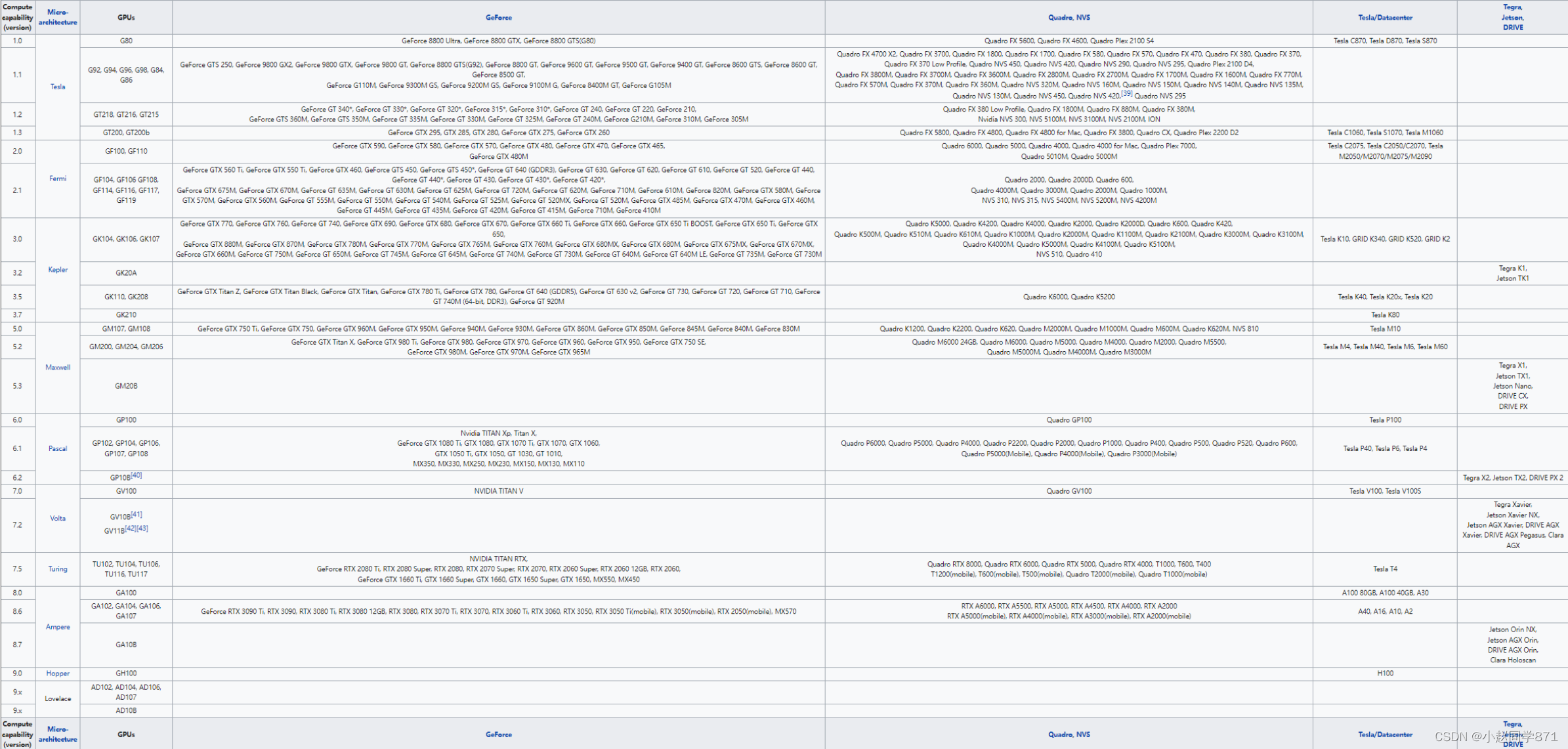
确定自己硬件信息时可以看到NVIDIA显卡的信息例如:NVIDIA GeForce GTX 1650,在对照上图查看自己的算力,比如我的就是7.5,记住这个算力

如上图可以看到我的支持CUDA10.0-11.7
3.2.2查看自己的驱动CUDA Driver Version
win+R+cmd 输入nvidia-smi
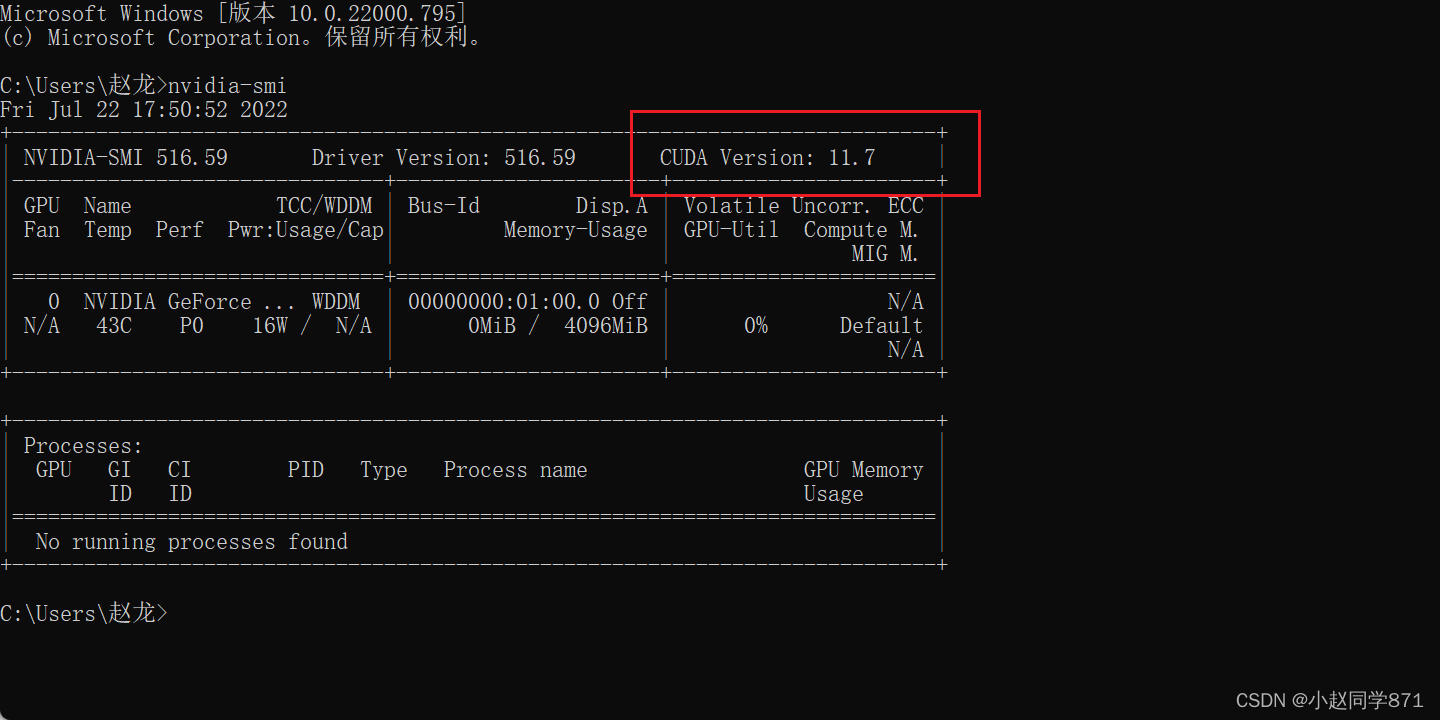
可以看到我的CUDA Driver Version为11.7
3.2.3确定自己可以选择的CUDA Runtime Version(也就是我们对应pytorch官网上的CUDA)
确保自己的CUDA Runtime 版本<= CUDA Driver 版本
例如我的这个就要求CUDA Driver版本小于等于11.7
最终确定我们适用于10.0-11.7的CUDA
更为简单的操作
1.安装NVIDIA显卡驱动最新版本
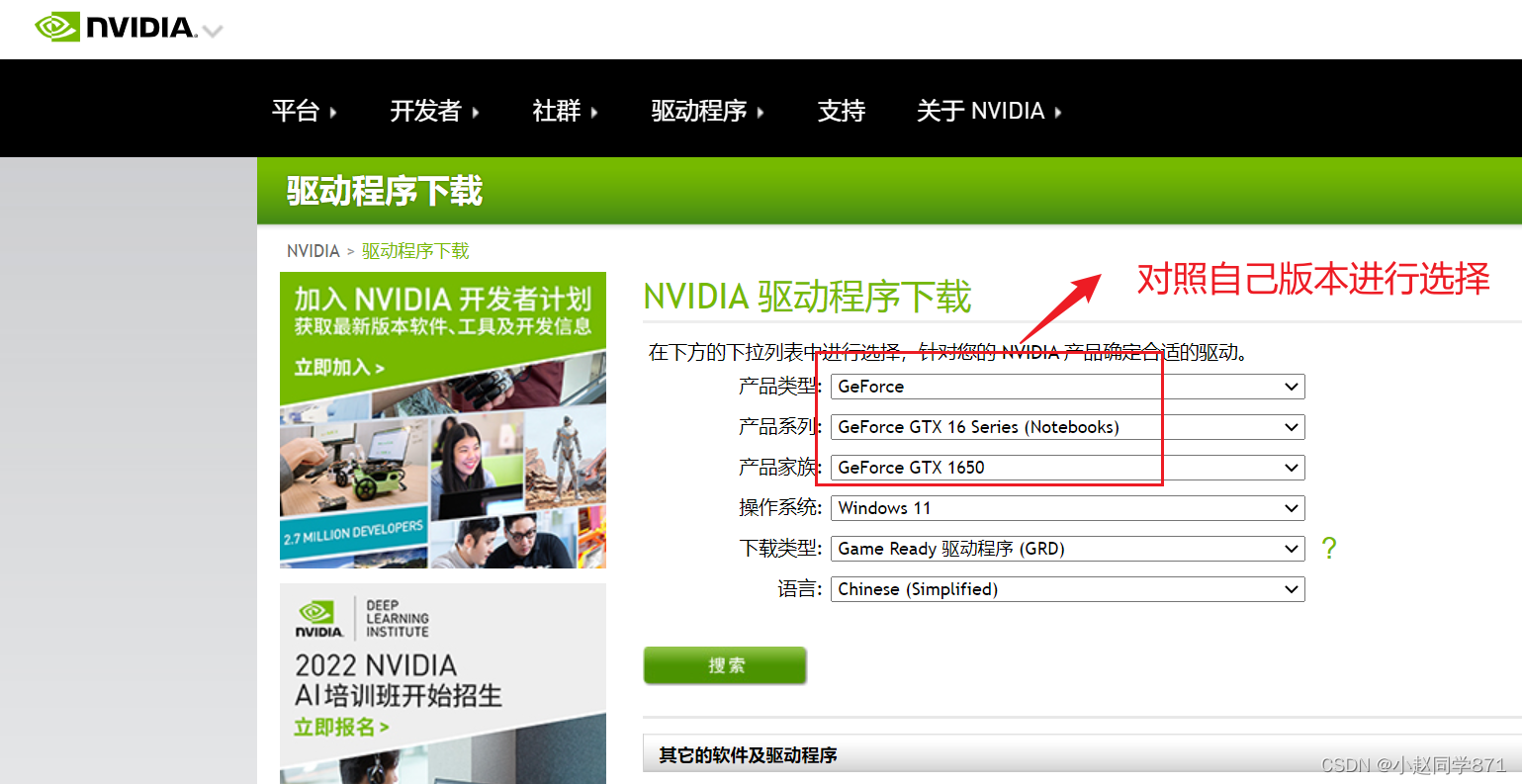
选择好后进行下载安装就行,安装过程不需要注意什么全程按照要求安装就OK
安装完以后再进行nvidia-smi就可以看到最新的CUDA Driver版本
2.打开PyTorch官网,选择小于11.7的CUDA版本就OK
3.3安装PyTorch
1.在上步创建的虚拟环境中安装PyTorch(安装PyTorch,需要安装pytorch、torchvision、torchaudio三个包)
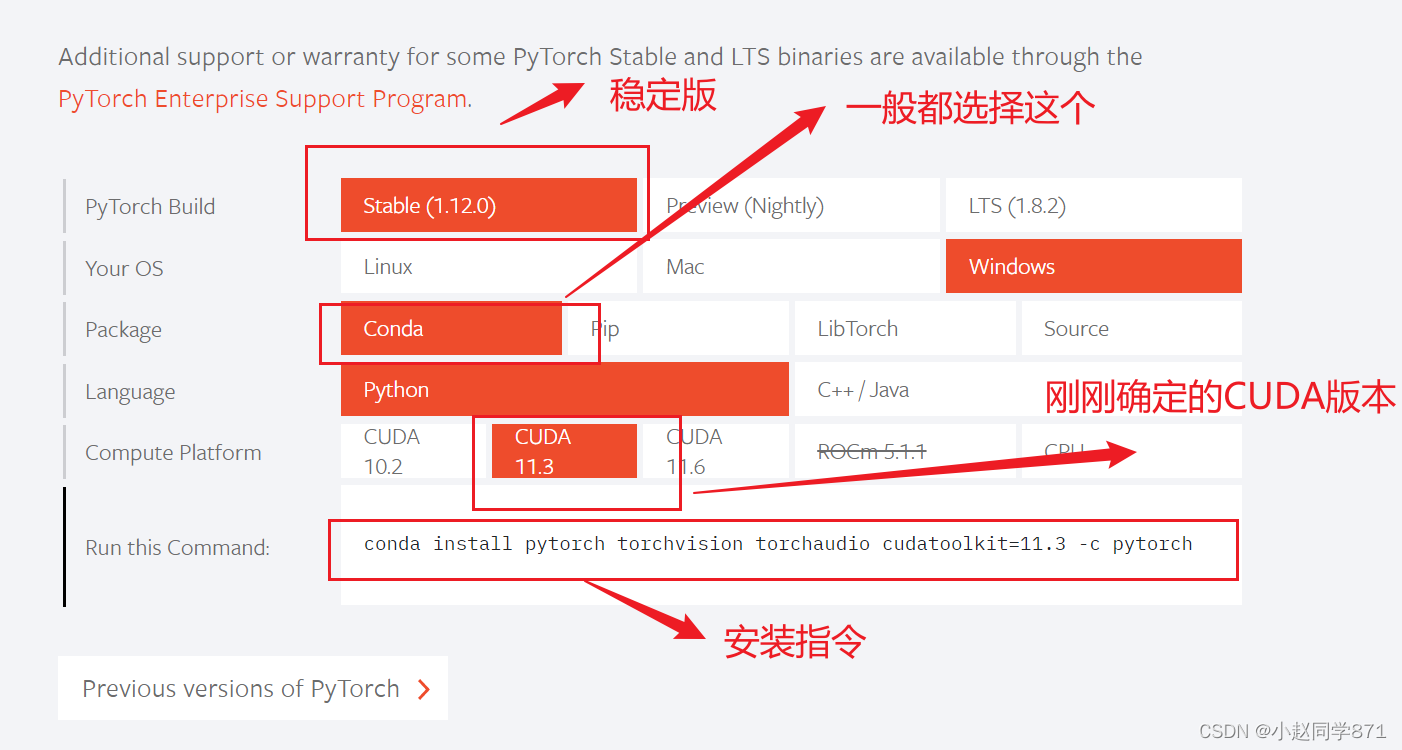
得到指令
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch

4.验证PyTorch是否安装成功
1.conda activate 虚拟环境名
2.输入conda list 看看有没有pytorch或者torch包
3.输入python
4.输入import torch
5.输入torch.cuda.is_available()
6.如果显示为True,说明PyTorch安装成功了
也可以直接在最后pycharm对于虚拟环境中直接输入如下代码进行验证
import torch
print(torch.__version__)
print(torch.cuda.is_available())
x = torch.randn(1)
if torch.cuda.is_available():
device = torch.device("cuda")
y = torch.ones_like(x, device=device)
x = x.to(device)
z = x + y
print(z)
print(z.to("cpu", torch.double))
结果为:
1.10.2
True
tensor([2.0444], device='cuda:0')
tensor([2.0444], dtype=torch.float64)
5.安装PyCharm并进行配置
1.下载PyCharm
2.安装也不多赘述可以找下教程不难
3.配置合适的python解释器(虚拟环境)
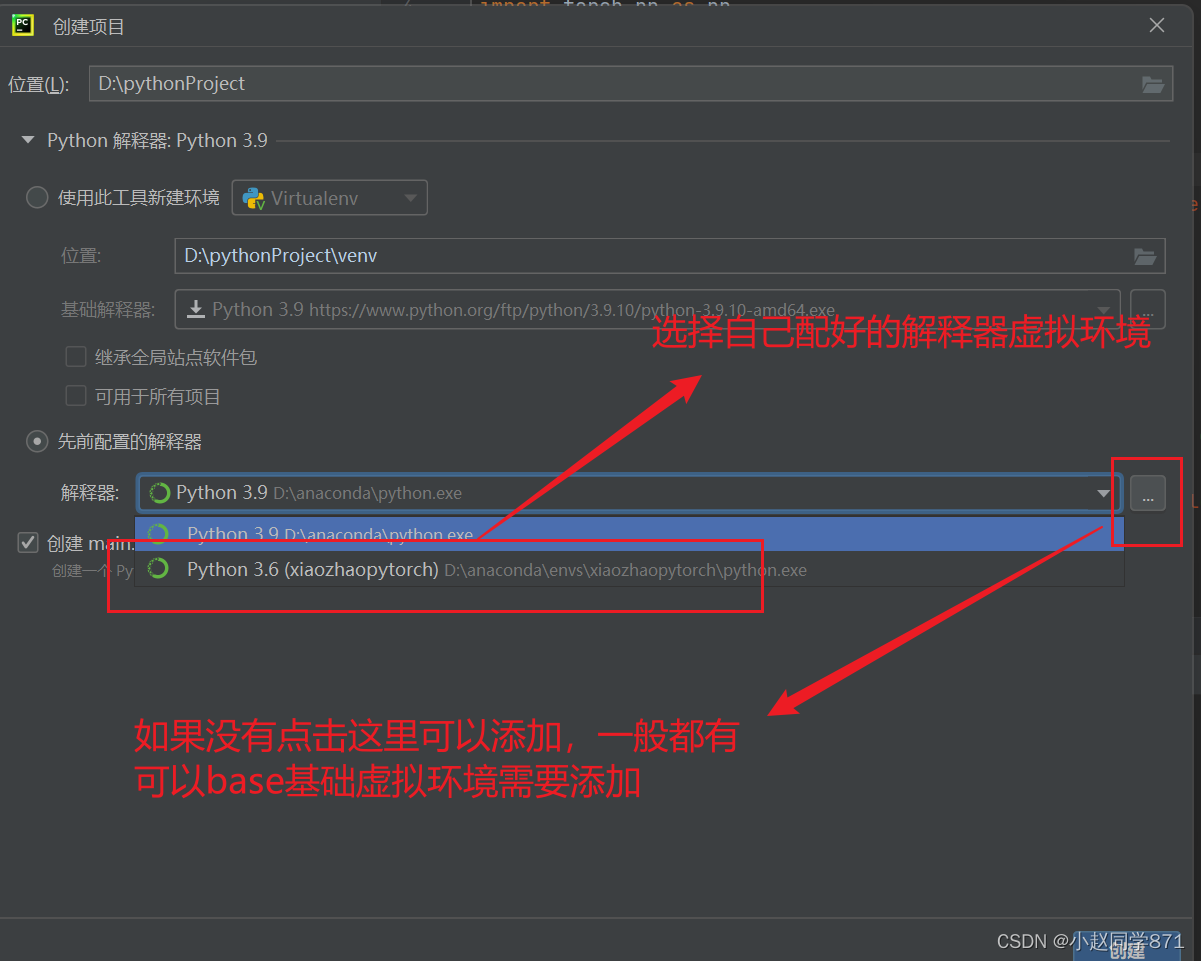
6.跑实例查看GPU使用率
直接上代码
from sklearn
import datasets from sklearn.model_selection
import train_test_splitimport torch
import torch.nn as nnimport torch.nn.functional as F
# 加载数据boston = datasets.load_boston()
X, y = (boston.data, boston.target)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=0)
# 组合训练数据及标签myset = list(zip(X_train, y_train))
# 把数据转换为批处理加载方式批次大小为128,打乱数据from torch.utils import datadevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
dtype = torch.FloatTensortrain_loader = data.DataLoader(myset, batch_size=128, shuffle=True)
# 定义网络class Net1(nn.Module):
""" 使用sequential构建网络,Sequential()函数的功能是将网络的层组合到一起 """
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Net1, self).__init__()
self.layer1 = torch.nn.Sequential(nn.Linear(in_dim, n_hidden_1))
self.layer2 = torch.nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2))
self.layer3 = torch.nn.Sequential(nn.Linear(n_hidden_2, out_dim))
def forward(self, x):
x1 = F.relu(self.layer1(x))
x1 = F.relu(self.layer2(x1))
x2 = self.layer3(x1)
# 显示每个GPU分配的数据大小
print("\tIn Model: input size", x.size(), "output size", x2.size())
return x2if __name__ == '__main__':
# 把模型转换为多GPU并发处理格式
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 实例化网络
model = Net1(13, 16, 32, 1)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs")
# dim = 0 [64, xxx] -> [32, ...], [32, ...] on 2GPUs
model = nn.DataParallel(model)
model.to(device)
# 选择优化器及损失函数
optimizer_orig = torch.optim.Adam(model.parameters(), lr=0.01)
loss_func = torch.nn.MSELoss()
# 模型训练,并可视化损失值
# from torch.utils.tensorboard import SummaryWriter # writer = SummaryWriter(log_dir='logs') for epoch in range(100):
model.train()
for data, label in train_loader:
input= data.type(dtype).to(device)
label = label.type(dtype).to(device)
output = model(input)
loss = loss_func(output, label)
# 反向传播
optimizer_orig.zero_grad()
loss.backward()
optimizer_orig.step()
print("Outside: input size", input.size(), "output_size", output.size())
# writer.add_scalar('train_loss_paral', loss, epoch)
代码借鉴:https://blog.csdn.net/smile1231385/article/details/122385373?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_title~default-0-122385373-blog-111661128.pc_relevant_multi_platform_whitelistv1_exp2&spm=1001.2101.3001.4242.1&utm_relevant_index=3
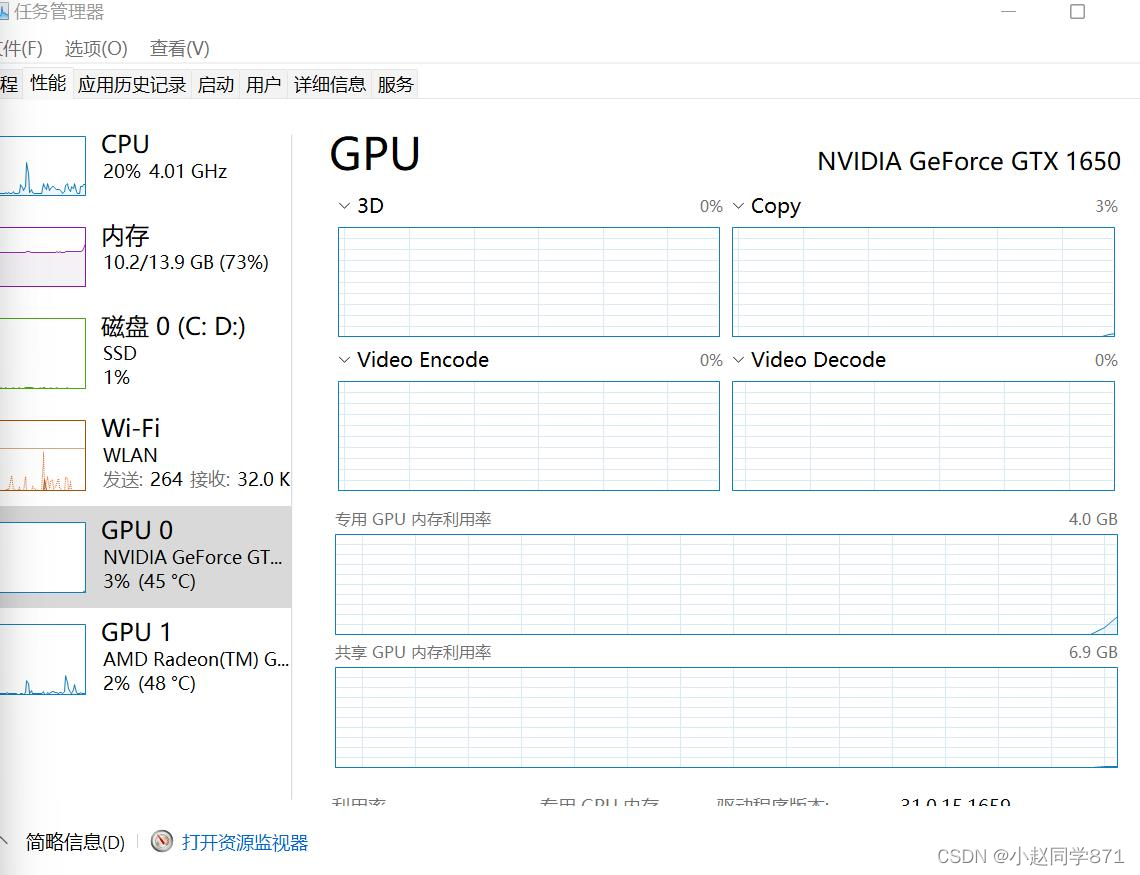
只要NVIDIA显卡对应的GPU使用率百分之多少动了(例如我的就是GPU0达到3%,平时都是0%)就表示完全配置好深度学习环境了!
如上较多内容借鉴参考我是土堆up主相关教程!















 3775
3775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









