






用于分类问题,类型如下。
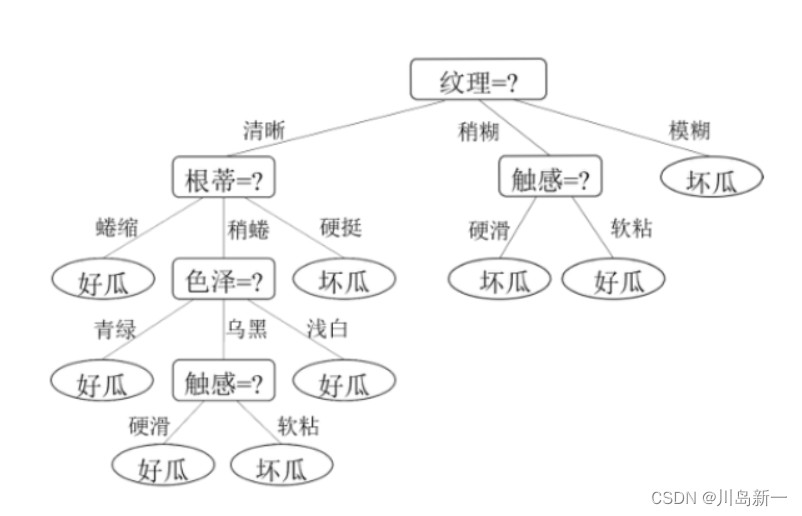
基本过程:生成节点,选择属性,划分子节点.222222234
输入:
一组样本D,样本D需要分类的属性集A
过程:
- 函数TreeGenerate(D, A)
- 生成节点node
- if D为属于同一类别,或需要分类的属性集A为空/相同
- then 标记node
- return
- end if
- 选择最优划分属性 a ∗ a_* a∗
- for
a
∗
a_*
a∗中每个取值
a
∗
v
a_*^v
a∗v do
- 生成一个node,包含分支 D ∗ v D_*^v D∗v
- if
D
∗
v
D_*^v
D∗v为空 then
- 将node标记为D中众数类别
- else
- 以TreeGenerate( D ∗ v D_*^v D∗v,A \ a ∗ a_* a∗ )为分支节点
- return node
输出:
决策树的根节点
划分属性的选择
希望划分后节点中的样本尽量属于同一类别,“纯度”更高,用信息熵(entropy)来衡量节点“纯度”。
假设样本集D中有k个类别,每个类别所占比重为
p
i
p_i
pi,信息熵Ent(D)定义如下:
E
n
t
(
D
)
=
−
∑
1
k
p
i
l
o
g
2
p
i
Ent(D) = -\sum_1^k p_i log_2 p_i
Ent(D)=−1∑kpilog2pi
一、基于信息熵增益
G
a
i
n
(
D
,
a
)
=
E
n
t
(
D
)
−
∑
1
V
∣
D
v
∣
∣
D
∣
E
n
t
(
D
v
)
Gain(D,a) = Ent(D) - \sum_1^V {|D^v|\over|D|}Ent(D^v)
Gain(D,a)=Ent(D)−1∑V∣D∣∣Dv∣Ent(Dv)
即划分后的子集熵的加权和最小。
问题:某些类似“编号”的属性没有划分价值,却被衡量为最优划分属性。
解决:考虑属性取值的数量,数量越多,价值越低。
二、增益率
G a i n _ r a t i o ( D , a ) = G a i n ( D , a ) I V ( a ) 其中 I V ( a ) = − ∑ 1 V q i l o g 2 q i 其中 q i 为取值为 i 的样本在所有样本中所占比例 \begin{aligned} Gain\_ratio(D,a) = {Gain(D,a) \over IV(a)} \\ 其中IV(a) = - \sum_1^Vq_ilog_2q_i \\ 其中q_i为取值为i的样本在所有样本中所占比例 \end{aligned} Gain_ratio(D,a)=IV(a)Gain(D,a)其中IV(a)=−1∑Vqilog2qi其中qi为取值为i的样本在所有样本中所占比例
三、基尼指数
信息熵平替,随机抽取两个样本不一样的概率,基尼指数越小,样本集纯度越高。
G
i
n
i
(
D
)
=
1
−
∑
1
k
p
i
2
Gini(D) = 1 - \sum_1^kp_i^2
Gini(D)=1−1∑kpi2
问题:过拟合
深层次节点包含的样本数量少,不具有统计意义。
解决:剪枝
两种剪枝思路:
- 边生成边剪枝(预剪枝)
- 生成后剪枝(后剪枝)
后剪枝
- 检测原决策树准确率
- for 非叶节点 in 所有节点(自底向上)
- 计算剪枝后准确率
- if 准确率提升 then 剪枝
- else 不剪枝
问题:这样做是不是把测试集也作为训练集了?
![![[Pasted image 20240416133823.png]]](https://img-blog.csdnimg.cn/direct/5069b1cdcb3b4b75b9b1467ab48b368a.png)
![![[Pasted image 20240416134400.png]]](https://img-blog.csdnimg.cn/direct/7d68e2298386404498ab37784e66874d.png)
预剪枝
在得到最优划分属性后,通过验证集计算划分前后准确率,决定是否划分该属性。
- 计算不划分该属性,决策树准确率p1
- 计算划分该属性后,决策树准确率p2
- if p2>p1 then 划分
- else 不划分,标记节点为叶子节点
![![[Pasted image 20240416135109.png]]](https://img-blog.csdnimg.cn/direct/fb620d622b984714995d7f6c413c5c18.png)















 1340
1340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









