







 本文提出了一种结合知识驱动和数据驱动的朝鲜语自动标音方法,通过提取朝鲜语语音变异规则的特征,构建基于决策树的发音预测模型,提高了字音转换的准确率,平均正确率为94.63%。这种方法能够适应朝鲜语的音变现象,有助于建立准确的朝鲜语发音字典,支持语音识别和合成系统。
本文提出了一种结合知识驱动和数据驱动的朝鲜语自动标音方法,通过提取朝鲜语语音变异规则的特征,构建基于决策树的发音预测模型,提高了字音转换的准确率,平均正确率为94.63%。这种方法能够适应朝鲜语的音变现象,有助于建立准确的朝鲜语发音字典,支持语音识别和合成系统。
目录
摘要
【应用背景】 在朝鲜语语音信息处理的资源建设中,自动标音技术即字音转换技术起着至关重要的作用。目前学界对于字音转换技术的方法主要有基于知识和基于数据两种。【目的】 为解决以往仅基于知识驱动的方法难以适应大量数据信息的实际情况,导致模型复杂、计算困难等问题;以及仅基于数据驱动的方法依赖高质量数据又难以合理确定输入变量,需要模型特征充足且选取精准等问题。【方法】 本文提出了一种知识与数据驱动相融合的朝鲜语自动标音方法。首先根据朝鲜语语音变异规律为基础提取精准的特征属性,获得高质量数据;然后结合数据驱动模型能够较好拟合输入与输出变量之间映射关系的优点,训练学习模型,实现对朝鲜语的自动标音。【结果】 通过本文方法,最终标音结果能够兼顾朝鲜语连续语流中音节弱化、脱落、增音、异化等音变现象,并能够准确地获得字素相对应的音素。经交叉测试,该方法使预测模型性能提高,平均正确字音转换率可达94.63%。【结论】 利用本文提出的朝鲜语自动标音方法能够有效建立准确的朝鲜语发音字典,有望为朝鲜语语音识别与语音合成等系统提供技术支持。
关键词: 知识驱动; 数据驱动; 朝鲜语; 语流音变; 字音转换
引言
自动标音技术即字音转换技术(grapheme-to-phoneme conversion, G2P),是指利用计算机自动为单词系统标注音标,将用字符拼写的单词文本转换为可供人或机器阅读和处理的单词发音。G2P算法可以应用到自然语言处理的很多领域,如语音识别技术、语音合成技术、语音关键词检测、机器翻译等应用中。
在语音识别与语音合成系统中,发音词典包含了从单词到音素之间的一一对应关系,在此基础上把声学模型和语言模型连接起来,共同组成一个用于进行解码工作的搜索状态空间,其规模和质量直接影响系统性能。随着朝鲜语自身的发展,内部不断涌现大量的新词和外来词,但字典数据库难以包括所有朝鲜语单词的发音。因此,除了数据库内的词汇,如何解决那些数据库以外的“集外词”即OOV(out of vocabulary)单词的读音就成了朝鲜语自然语言处理过程中不得不解决的问题。朝鲜语的字音转换技术不仅可以为朝鲜语发音字典的构建提供支持,并且能够有效解决OOV单词的自动注音问题。
字音转换方法可分成两类:
(1)基于知识驱动的方法。通过对朝鲜语的构词法和连续语流中的朝鲜语音节之间的音变现象进行总结,根据音变现象制定出朝鲜语的字音转换规则系统,然后实现字素到音素的转换。Wang等[1]在朝鲜语语音合成系统研发过程中对基于知识驱动的朝鲜语字音转换算法进行了研究,通过对朝鲜语语音的分析总结出了元音和辅音结合以及字间所产生的语音变异现象,根据他们发现的音变现象构建了一个基于知识驱动的模型,将这些模型应用于朝鲜语文本字符串,以预测发音的音位表示。但该模型最终并没有建立可以应用于朝鲜语语音处理的发音词典,实验过程中也没有进行严格的交叉测试。由于朝鲜语语音变异规则多样,基于知识驱动的模型无法涵盖所有语言事实,这些都会影响字音转换的准确率。
(2)基于数据驱动的方法。在丰富的训练数据支持下,利用概率统计和机器学习算法,建立发音模型,通过解码算法为任意单词进行标音。数据驱动的方法是目前主流的字音转换方法。在国外,Park等[2]基于双向长短时常记忆算法(Bi-directional Long Short-Term Memory, Bi-LSTM)实现了汉语字素到音素的转换,并在包含99,000多个句子的汉语数据集上进行了测试。Galescu等[3]基于期望最大化(Expectation Maximization, EM)算法实现了英语字素音素一对一对齐,通过N-Gram建立发音模型的字音转换方法。Jiampojamarn等[4]将隐马尔科夫模型(Hidden Markov Model, HMM)应用于发音建模提出了字素音素多对多的对齐方式。Hannemann等[5]提出了联合序列模型的方法,并在英语、德语和法语测试集上进行了测试,该方法也是当时较为主流的字音转换方法。Lim等[6]通过LSTM(Long Short-Term Memory)算法实现了韩国语的字音转换技术,并与基于规则和基于统计的方法进行了对比,最终识别率达到92.8%,实验结果表明,基于数据驱动方法的结果优于基于规则和基于统计的方法。在国内,王永生等[7]基于一种动态有限泛化法(Dynamic Finite Generalization, DFGA)的机器学习算法,用于英语字音转换规则的学习。冯伟等[8]针对俄语语音合成和语音识别系统中发音词典规模有限的问题,提出一种基于LSTM序列到序列模型的俄语词汇标音算法,实验结果表明,该算法音素正确率达到了94.5%。冯伟等[9]将加权有限状态转化器(WFST)用于实现俄语字音转换技术,首先利用期望最大化算法以“多对多”的方式对俄语字音进行对齐,然后将对齐结果通过联合N-gram模型训练,并转化为WFST发音模型,最后通过WFST解码算法对任意单词的发音进行预测。交叉验证实验结果表明,平均音素正确率为92.2%。李鹏等[10]基于CART树(Classification And Regression Tree)方法的构建了一个英语字素到音素的转换系统。赵坤等[11]提出了一种通过有条件维数扩展(Conditional Mixincrementing algorithm, CMI)决策树算法解决英语字音转换的方法。王永生等[12]提出过一种基于决策树的字素音素转换的监督学习算法,生成德语字素音素转换规则,进过10轮交叉测试,实现了德语字素到音素的转换。
综上所述,字音转换技术在国内外已有不少研究,但应用对象主要为英语、俄语、德语,目前国内还没有任何朝鲜语字音转换方面的研究和实验,并且相关研究中均采用的是单一方法,或是仅基于知识驱动或是仅基于数据驱动。基于知识驱动的方法有比较完备的理论支撑,可解释性强、执行效率较高,但大规模复杂问题导致模型复杂计算困难,且难以使模型持续学习进化。基于数据驱动的方法通用性强,可支持模型持续学习进化,但理论知识分析困难,依赖高质量数据又难以合理确定输入变量,且需要模型特征充足且选取精准。因此,有必要以朝鲜语语音学知识为基础,融合数据驱动的方法,对朝鲜语字音转换方法的实现与应用做进一步研究。考虑到朝鲜语的发音特点及音变规则,其字音转换模型训练的过程与其他语言存在差异性,本文根据朝鲜语的发音规则以及字间的语音变异规律提取特征属性送入预测模型中进行训练。本研究建立了10,000条朝鲜语字素和音素对照的平行语料库,目的是在这个平行语料库的基础上,通过朝鲜语音变知识与数据驱动相融合的方法来解决朝鲜语自动注音问题。
1 基于知识驱动的朝鲜语数据属性特征提取
1.1 朝鲜语语音结构特点
朝鲜语是国内外朝鲜民族的共同语,使用区域主要有中国东北三省的部分地区和朝鲜半岛,既是中国的少数民族语言之一,同时也是朝鲜、韩国使用的通用语。朝鲜语文字属于音型文字,其在组字的时候以音节为单位,即每一个朝鲜文字表示一个音节。每个朝鲜语音节至多由3个音素构成,按照发音顺序,分别称为首辅音、元音和尾辅音。朝鲜语文字按照“从左到右,自上而下”的基本规则进行读写,如果以C代表辅音,V代表元音,则朝鲜语的音节结构类型有CVC、VC、CV或V。图1给出了一个朝鲜语文字的示例[13]。
图1
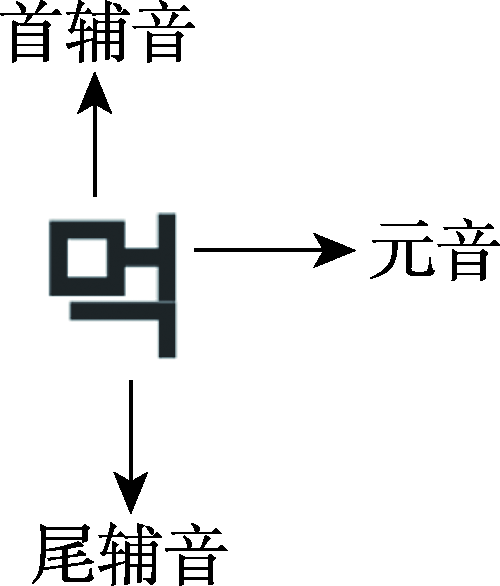
图1 朝鲜语文字示例
Fig. 1 Example of Korean characters
按书写方式来分,在朝鲜语中共有首辅音19种、元音21种、尾辅音27种,本研究为每个位置可能出现的字母定义了对应的拉丁转写映射,如表1所示。
表1 朝鲜语字母及其拉丁字母映射表
Table 1 Korean letters and its Latin transcription mappings
| 首辅音 |
ㄱ |
ㄴ |
ㄷ |
ㅁ |
ㅂ |
ㅅ |
ㄹ |
|
| g |
n |
d |
m |
b |
s |
l |
||
| ㅇ |
ㅈ |
ㅊ |
ㅋ |
ㅌ |
ㅍ |
ㅎ |
||
| sp |
j |
ch |
kh |
t |
p |
h |
||
| ㄲ |
ㄸ |
ㅃ |
ㅆ |
ㅉ |
||||
| gg |
dd |
bb |
ss |
jj |
||||
| 元音 |
ㅏ |
ㅑ |
ㅓ |
ㅕ |
ㅗ |
ㅜ |
ㅠ |
ㅡ |
| a |
ya |
eo |
yeo |
o |
u |
yu |
eu |
|
| ㅣ |
ㅐ |
ㅒ |
ㅔ |
ㅖ |
ㅘ |
ㅙ |
ㅚ |
|
| i |
ae |
yae |
e |
ye |
wa |
wae |
oe |
|
| ㅝ |
ㅞ |
ㅟ |
ㅢ |
ㅛ |
||||
| wo |
we |
wi |
ui |
yo |
||||
| 尾辅音 |
ㄱ |
ㄴ |
ㄷ |
ㅁ |
ㅂ |
ㅅ |
ㄹ |
ㅎ |
| g2 |
n2 |
d2 |
m2 |
b2 |
d2 |
l2 |
sp(h2) |
|
| ㅇ |
ㅈ |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











