









作者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:
本文介绍了使用 Python 库 Zipline 和 Pyfolio 进行算法交易策略的开发、回溯测试、性能分析和可视化的过程。我会先设回溯测试环境,再讲均值回归策略实现。然后用 Pyfolio 分析绩效,用 Matplotlib 和 Seaborn 可视化数据。最后通过案例演示评估和优化策略。
算法交易彻底改变了金融策略的开发和执行方式。Zipline 是一个用于回溯测试和分析交易算法的强大 Python 库,Pyfolio 是一个用于性能和风险分析的工具。利用这些库,我们可以设计和测试均值回归策略,分析关键性能指标,并将回报、波动率、缩水和投资组合风险等关键方面可视化。通过这一过程,我们可以深入了解策略的有效性,优化决策,并更好地理解金融市场行为。
import sys
from pathlib import Path
import pandas as pd
from pytz import UTC
from zipline import run_algorithm
from zipline.api import (attach_pipeline, date_rules, time_rules, order_target_percent,
pipeline_output, record, schedule_function, get_open_orders, calendars,
set_commission, set_slippage)
from zipline.finance import commission, slippage
from zipline.pipeline import Pipeline, CustomFactor
from zipline.pipeline.factors import Returns, AverageDollarVolume
import logbook
import matplotlib.pyplot as plt
import seabornfrom pyfolio.utils import extract_rets_pos_txn_from_ziplinezipline 回溯测试库用于建立运行算法交易策略的环境。首先,它需要导入一些基本模块,如用于系统操作的 sys 和 pathlib、用于金融的 pandas 和用于以 UTC 处理一致时间戳的 pytz。此外,Zipline 还用于创建和管理交易算法,因此它也导入了这些组件。其中的关键函数包括 run_algorithm、attach_pipeline、pipeline_output、order_target_percent、track performance over time、schedule_function 和 get_open_orders。这些函数对在给定日期范围内执行交易策略、attach_pipeline 和 pipeline_output 都很有用。
此外,代码还从 Zipline 的财务模块中导入佣金和滑点设置,以模拟真实的交易条件,其中佣金代表交易过程中的费用,而滑点则代表价格差异。通过使用 CustomFactor,可以定制投资策略。此外,还导入了用于活动记录的 logbook、用于数据可视化的 seaborn 以及用于执行后分析的 Pyfolio 工具。基本上,这些代码为构建、执行和分析算法交易策略奠定了基础。
sns.set_style('darkgrid') Set_style 指定绘图的视觉外观。该行使用 Seaborn 库,这是一个流行的 Python 数据可视化库。Seaborn 的 darkgrid 参数创建了一种具有深色背景和网格覆盖的样式,可增强绘图的可读性,让您更容易解释数据。深色背景让图表颜色更容易看清。在创建可视化之前,它就会为你的可视化创建一种风格,让你的可视化看起来更精致、更专业。
# setup stdout logging
zipline_logging = logbook.NestedSetup([
logbook.NullHandler(level=logbook.DEBUG),
logbook.StreamHandler(sys.stdout, level=logbook.INFO),
logbook.StreamHandler(sys.stderr, level=logbook.ERROR),
])
zipline_logging.push_application() 该代码段使用日志库配置了多个日志处理程序。NullHandler 位于 DEBUG 级别,因此会忽略日志信息,也不会对处理程序丢失发出警告。然后创建两个 StreamHandler 实例:一个用于向标准输出发送 INFO 消息,另一个用于在出现严重问题时向标准错误发送 ERROR 消息。然后调用 push_application 激活日志记录配置,这样就可以根据严重程度管理消息了。
# Settings
MONTH = 21
YEAR = 12 * MONTH
N_LONGS = 200
N_SHORTS = 0
VOL_SCREEN = 1000 为了便于以后使用,我将 MONTH 设置为 21,表示以月为单位的时间段。年的计算方法是 MONTH 乘以 12,结果是 252 个月。在交易策略中,N_LONGS 表示有多少多头头寸,而 N_SHORTS 表示没有空头头寸,这表明买入是优先事项。VOLSCREEN 设置为 1000,确保只考虑交易量高于该阈值的资产。这些常量为接下来的步骤设置了参数。
start = pd.Timestamp('2010-01-01', tz=UTC)
end = pd.Timestamp('2018-01-01', tz=UTC)
capital_base = 1e7 使用Panda’s 时间戳和 capital_base 初始化了两个变量。Start和end被定义为时间戳,表示一个时间段的开始和结束。使用 pd.Timestamp,我们给出了一个字符串日期,并将时区设置为 UTC,开始和结束时间设置为 2010 年 1 月 1 日。在财务分析或建模中,capital_base 可以作为初始资本额。时间范围和起点在此设置。
class MeanReversion(CustomFactor):
"""Compute ratio of latest monthly return to 12m average,
normalized by std dev of monthly returns"""
inputs = [Returns(window_length=MONTH)]
window_length = YEAR def compute(self, today, assets, out, monthly_returns):
df = pd.DataFrame(monthly_returns)
out[:] = df.iloc[-1].sub(df.mean()).div(df.std()) MeanReversion 通过比较最近一个月的收益率和过去一年中平均一个月的收益率来评估均值回归,并用标准差对差值进行归一化处理。输入属性指定分析以月度收益率为重点,而收益率函数则获取上个月的数据。通过将窗口长度设置为一年,所有计算均使用年度数据。
参数包括:今天是当前日期,assets 是要分析的资产,out 是结果的存储位置,monthon_returns 是去年的数据。您可以在 pandas DataFrames 中操作月回报率。只需减去之前月度回报的平均值,除以标准差,然后取最近的月度回报。通过归一化处理,你可以看到最新收益率与平均值的偏差有多大。根据前一年的表现,输出数组会得到一个分数,表明最新收益率离群的程度。
def compute_factors():
"""Create factor pipeline incl. mean reversion,
filtered by 30d Dollar Volume; capture factor ranks"""
mean_reversion = MeanReversion()
dollar_volume = AverageDollarVolume(window_length=30)
return Pipeline(columns={'longs' : mean_reversion.bottom(N_LONGS),
'shorts' : mean_reversion.top(N_SHORTS),
'ranking': mean_reversion.rank(ascending=False)},
screen=dollar_volume.top(VOL_SCREEN)) 金融因素管道通过均值回复法来找交易机会。用 MeanReversion 对象,能根据股价走势和回落到平均价的可能性给股票打分。为了只分析流动性好的股票,会建个平均日交易量的实例,时间窗口是 30 天。
管道由三个主要栏目组成。多头栏根据均值回归标准选择表现不佳的股票,参数为多头头寸的数量。绩优股在短线栏中通过使用相同的标准来识别,参数为短线头寸的数量。在排名栏中,股票按均值回复逻辑从高到低排列。
作为管道的一部分,只有符合交易量标准的股票才会被纳入其中,这意味着这些股票近期交易情况良好,更有可能取得成功。通过均值回复分析,该功能可识别多头和空头头寸,同时通过美元成交量过滤器确保足够的流动性。
def before_trading_start(context, data):
"""Run factor pipeline"""
context.factor_data = pipeline_output('factor_pipeline')
record(factor_data=context.factor_data.ranking)
assets = context.factor_data.index
record(prices=data.current(assets, 'price')) 在交易开始时,before_trading_start 函数会运行一个因子流水线,用于根据量化金融中的某些标准对股票进行评估。调用该函数时,它会使用 pipeline_output 函数检索因子流水线的输出,并将其存储到包含大量资产信息的 context.factor_data 中。为了分析随时间变化的性能,该函数使用 record 函数记录排名。assets 变量根据 context.factor_data 中的索引提供相关资产列表。它还使用 data.current 方法获取并记录这些资产的当前价格,这对了解市场背景非常重要。这是交易活动前进行准备的重要功能,可以根据市场情况做出数据驱动的决策。
def rebalance(context, data):
"""Compute long, short and obsolete holdings; place trade orders"""
factor_data = context.factor_data
assets = factor_data.index longs = assets[factor_data.longs]
shorts = assets[factor_data.shorts]
divest = context.portfolio.positions.keys() - longs.union(shorts)exec_trades(data, assets=divest, target_percent=0)
exec_trades(data, assets=longs, target_percent=1 / N_LONGS if N_LONGS else 0)
exec_trades(data, assets=shorts, target_percent=-1 / N_SHORTS if N_SHORTS else 0) 再平衡功能中,过时的持仓会被清算,多头和空头头寸会根据您提供的因子进行再平衡。因子数据是第一步,其中包含各种资产和交易信号的信息。资产是指这些数据中包含在资产变量中的资产。
该函数定义了三组资产:多头,即多头头寸;空头,即空头头寸;剥离,即当前投资组合中没有多头或空头头寸的资产,计算方法是减去多头和空头资产的总和。
调用剥离资产时,会调用目标百分比为 0 的 exec_trades。根据多头头寸的数量,它将投资平均分配给这些多头头寸,如果没有多头头寸,则设置 0%。利用空头头寸的数量,确保资金平均分配到负方向。
这样,投资组合就能根据最新的交易信号不断优化,头寸也能得到有效管理。
def exec_trades(data, assets, target_percent):
"""Place orders for assets using target portfolio percentage"""
for asset in assets:
if data.can_trade(asset) and not get_open_orders(asset):
order_target_percent(asset, target_percent) 在 exec_trades 函数中,您需要给出三个参数:数据、资产和 target_percent。它会根据目标百分比为特定资产下单。该函数会检查每种资产是否允许交易,以及资产列表中是否没有该资产的未结订单。一旦这两个条件都满足,它就会调用 order_target_percent,设置资产的目标分配。这种方法只有在允许下单和没有挂单的情况下才会下单,从而确保高效的交易管理。
def initialize(context):
"""Setup: register pipeline, schedule rebalancing,
and set trading params"""
attach_pipeline(compute_factors(), 'factor_pipeline')
schedule_function(rebalance,
date_rules.week_start(),
time_rules.market_open(),
calendar=calendars.US_EQUITIES)set_commission(us_equities=commission.PerShare(cost=0.00075, min_trade_cost=.01))
set_slippage(us_equities=slippage.VolumeShareSlippage(volume_limit=0.0025, price_impact=0.01)) 初始化函数为交易算法设置环境。它配置必要的组件,使其能正常工作。使用 attach_pipeline 注册管道,收集数据并计算影响交易决策的因素。再平衡函数会在每周开市时调整投资组合的持有量,确保交易按时执行。
此外,佣金是通过 set_commission 设置的,最低价格为 0.01 美元,每股成本为 0.00075 美元。这样,即使交易量不大,也有最低费用。通过将滑点设置为 0.0025,并假设每笔交易对价格的影响为 1%,该交易策略可以有效地收集数据、管理持股,并在规定的成本和风险范围内运作。
backtest = run_algorithm(start=start,
end=end,
initialize=initialize,
before_trading_start=before_trading_start,
capital_base=capital_base)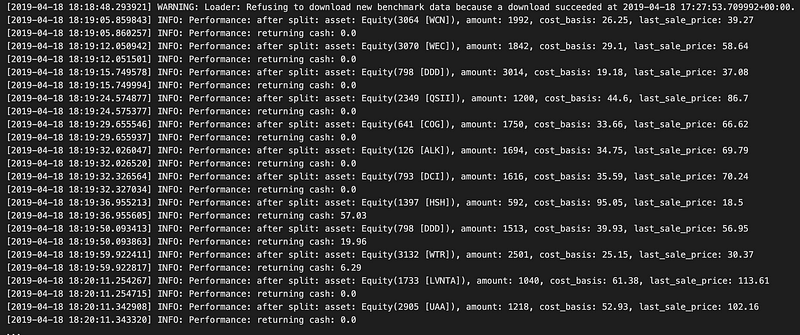
回溯测试使用 Zipline 的 run_algorithm 函数进行,Zipline 是一个算法交易库。开始和结束是用于回溯测试的参数,initialize 用于设置交易算法,before_trading_start 用于进行交易前调整,capital_base 用于指定策略的初始资金。
在输出日志中,您可以看到回溯测试的执行情况,一开始会出现基准数据不可用的警告,但后来确认数据已经下载。在回溯测试期间,性能指标显示在标有 INFO 的日志条目中。它们显示了各种资产的金额、成本基础和现金余额。
例如,股票(3064 [WCN])和股票(3070 [WEC])的业绩连同其金额和成本基础都记录在案。在交易过程中,现金余额会发生变化,反映交易结果。此外,分录还告诉你股票拆分后的表现,这对于弄清股票拆分对投资组合价值的影响非常重要。
在回溯测试过程中,日志会定期显示交易策略对业绩的影响。由于最后的条目,回溯测试跨越了 2013 年,因此用户可以评估其交易策略的有效性、评估风险并做出明智的调整。
returns, positions, transactions = extract_rets_pos_txn_from_zipline(backtest) 这行代码调用以 backtest 变量为参数的 extract_rets_pos_txn_from_zipline 函数。它使用 Python 算法交易库 Zipline 获取回溯测试的具体信息。其中有三个数据点:收益、仓位和交易。收益包含策略性能,如利润或亏损。仓位显示你在回溯测试期间持有的资产。交易详细记录了整个回溯测试期间执行的交易,包括买入和卖出活动。元组解包使得分配输出变得简单。
with pd.HDFStore('backtests.h5') as store:
store.put('backtest', backtest)
store.put('returns', returns)
store.put('positions', positions)
store.put('transactions', transactions) 使用 pandas 库将回溯测试过程中的数据组件存储在 HDF5 文件中。HDFStore 上下文管理器确保数据安全无虞。在这种情况下,put 方法会保存数据集,如回溯测试、回报、仓位和交易,这些数据集对回溯测试结果非常重要,并使数据存储和检索更加容易。
在 HDF5 中序列化某些对象类型可能会出现问题,因为数据可能包含无法映射到 C 类型的元素。有关性能问题的警告强调了确保存储数据与 HDF5 兼容的必要性,尤其是对于复杂的数据结构和自定义对象。
fig, axes= plt.subplots(nrows=2, figsize=(14,6))
returns.add(1).cumprod().sub(1).plot(ax=axes[0], title='Cumulative Returns')
transactions.groupby(transactions.dt.dt.day).txn_dollars.sum().cumsum().plot(ax=axes[1], title='Cumulative Transactions')
fig.tight_layout();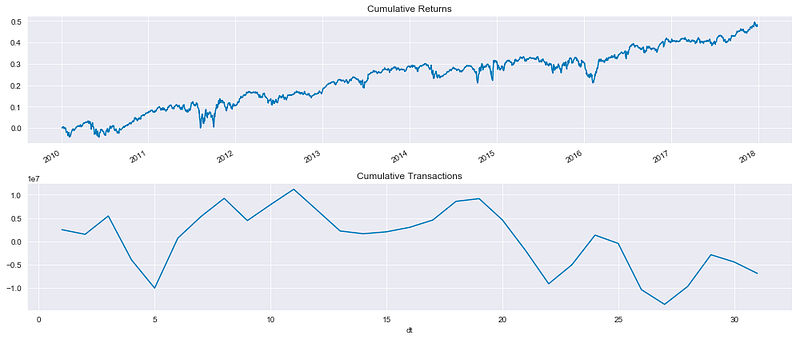
该代码片段可生成一个包含两个子图的图表,直观显示使用 Zipline 进行均值回归回溯测试所获得的财务数据。第一个子图显示随时间推移的累计收益,第二个子图显示随时间推移的累计交易值。
将收益加一并计算累计乘积,可以跟踪第一幅子图中从一开始的投资增长情况。它通常呈上升趋势,因此投资策略是有利可图的,但也时有波动。
它通过将每日交易金额相加并计算累计金额来显示一段时间内的总交易量。由于交易活动的波动性,该图谱比累计收益更容易变化。
这种布局便于比较累计回报和交易活动。通过这些可视化图表,我们可以深入了解交易策略的表现和交易动态。
positions.info()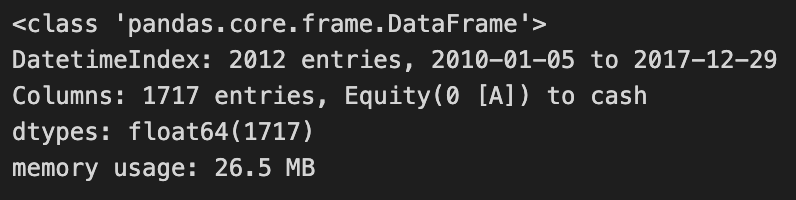
Positions.info() 使用的是 Pandas,可以让你在 Python 中分析和处理数据。这是 DataFrame 的摘要,在本例中,它跟踪的是使用均值回复策略 Zipline 框架的回溯测试项目中的头寸。在一个相当长的时间段内,DataFrame 包含 1717 个条目,按时间顺序排列,便于分析。股票和现金表示它代表了一段时间内的资产和投资价值,重点是现金。采用 float64 数据类型,数值为浮点数,非常适合包含小数的财务数据。考虑到其条目数量,它的内存使用量相当适中,这对提高数据处理效率很有帮助。Positions.info() 可以让用户深入了解 DataFrame 的结构和内容,从而判断数据是否可以用于进一步分析或建模。
transactions.describe()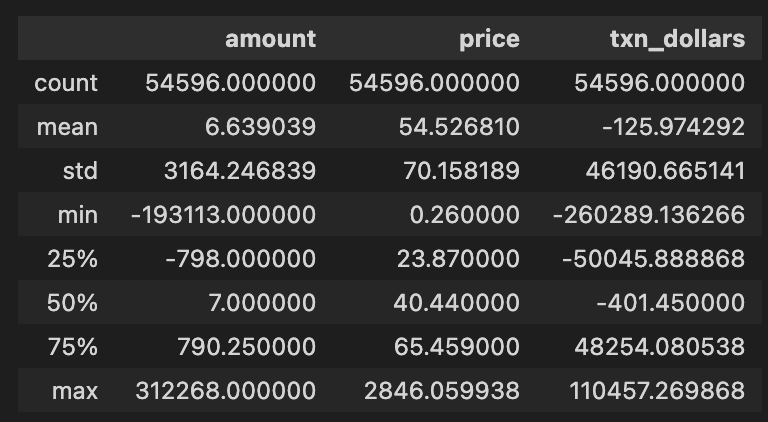
在均值回归回溯测试项目中,transactions.describe() 为名为 transactions 的 DataFrame 生成描述性统计。每列有 54,596 个条目,表明这是一个庞大的数据集,其中有三个关键列:金额、价格和 txn_dollars。大约有 6.64 笔交易,每单位平均价格为 54.53,平均金额为 -125.97,这表明数据集主要是销售或损失。
从标准偏差值可以看出,该金额的标准偏差很高,为 3164.43,表明其波动很大。-19,313是最小交易额,表明有很多抛售或负交易,而312,268是最大交易额,表明有很多交易。在四分位数中,金额的第 25 百分位数为 -798,这意味着有 25% 的交易低于该值;中位数为 7,表明有一半的交易低于该值;第 75 百分位数为 790.25,这意味着大多数交易没有那么大。
通过这种分析,我们可以对交易数据有一个清晰的概览,揭示模式和异常值,帮助我们了解交易策略的性能和行为。
from pathlib import Path
import warnings
import re
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt pathlib 中的 Path 简化了文件路径操作。该代码片段导入了用于数据处理、可视化和文件处理的 Python 库和模块。使用 warnings 模块,可以控制警告信息的显示方式,从而避免崩溃。使用 re 模块,可以搜索字符串,并使用正则表达式匹配模式。有了 Numpy,你可以运行数组并使用数学函数。Pandas 是分析结构化数据的完美工具,DataFrames 可让您轻松处理和清理数据。Matplotlib.pyplot 是一个用于创建静态、动画和交互式数据可视化的流行库,它建立在 Matplotlib 的基础上。Seaborn 可让您使用 Matplotlib.pyplot 轻松创建极具吸引力的统计可视化效果。这些库为处理数据、执行分析和生成可视化洞察力提供了强大的基础。Path 可处理数据文件,Pandas 和 Numpy 可处理数据操作,而 Seaborn 和 Matplotlib 可将结果可视化。
from pyfolio.timeseries import perf_stats, extract_interesting_date_ranges
# from pyfolio.tears import create_returns_tear_sheet 为进行金融投资组合绩效分析,该代码导入了 Pyfolio 函数。为进行交易策略性能分析,pyfolio.utils 中的 extract_rets_pos_txn_from_zipline 从 Zipline 回溯测试结果中提取收益、头寸和交易。
然后从 pyfolio 中导入几个绘图函数。plot_rolling_beta 用于衡量投资组合相对于基准的波动率,plot_rolling_fama_french 用于直观显示与法马-法式因子相关的表现、plot_rolling_returns 用于显示滚动回报;plot_rolling_sharpe 用于评估风险调整后的回报;plot_rolling_volatility 用于说明投资组合波动率的变化;plot_drawdown_periods 用于突出显示缩水期;plot_drawdown_underwater 用于直观显示缩水期间投资组合在水下的程度。
从 pyfolio.timeseries 中,perf_stats 可以计算关键的性能指标,而 extract_interesting_date_ranges 则可以识别特定的日期,以便深入分析性能的极端值或缺点。同样,create_returns_tear_sheet 也被注释掉了,这表明它在为一组回报生成详细的性能指标报告方面可能很有用,尽管目前并不需要它。
%matplotlib inline
plt.style.use('fivethirtyeight')
warnings.filterwarnings('ignore') 该代码段使用 Matplotlib 配置 Jupyter Notebook 环境以实现数据可视化。使用 %matplotlib inline 命令可使图表直接显示在笔记本中,方便查看可视化输出。命令 plt.style.use('fivethirtyeight') 为图表应用了类似于 FiveThirtyEight 网站的样式,以简洁现代的外观增强了视觉吸引力。此外,warnings.filterwarnings('ignore') 会抑制可能干扰输出的警告信息,从而在探索性数据分析或原型设计时提供更干净的工作空间。这些命令为可视化过程提供了便利,并增强了数据分析的美感。
with pd.HDFStore('../01_trading_zipline/backtests.h5') as store:
backtest = store['backtest']
backtest.info()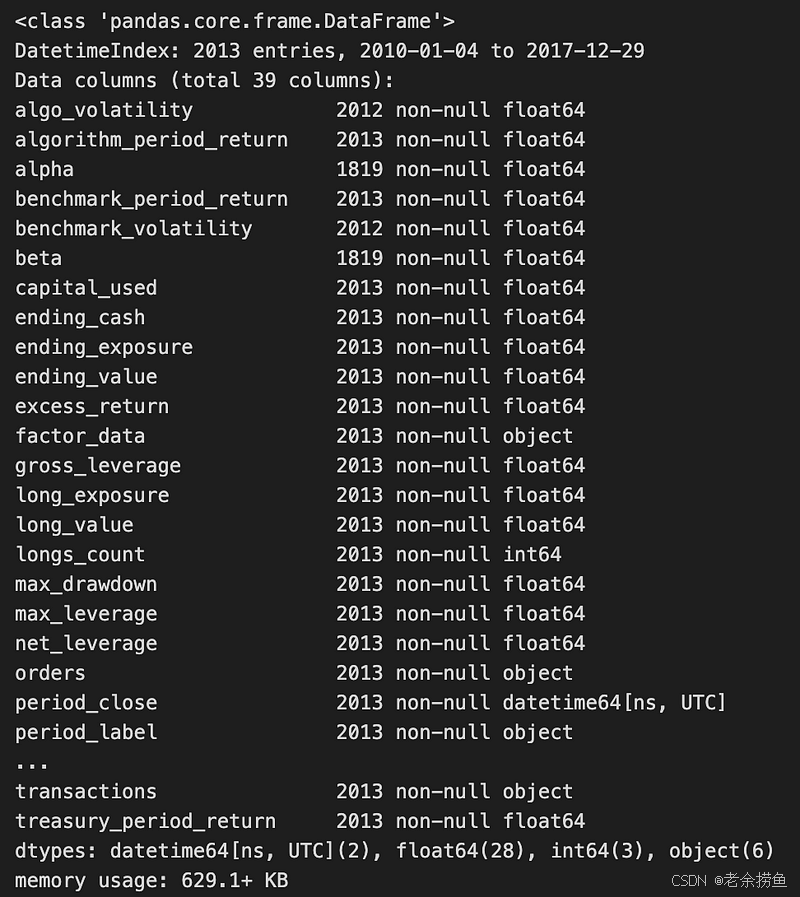
代码片段使用 pandas 库访问 HDF5 文件中的数据,特别是名为 backtest 的数据集。它使用 with 语句高效地打开和关闭 HDF5 文件,并使用 pd.HDFStore 函数管理位于 ./.01_trading_zipline/backtests.h5 的文件。在这种情况下,回溯测试数据集被加载到 backtest 变量中。
backtest.info()方法的输出总结了 DataFrame 的结构,显示了从 2010 年 1 月 4 日到 2017 年 12 月 29 日的 DatetimeIndex,共有 2013 个条目。它包括 30 列,分别代表与回溯测试结果相关的各种指标,如算法周期回报率、阿尔法、基准周期回报率和超额回报率,这些指标对评估交易策略性能至关重要。
列数据类型各不相同,大多数为 float64,表示数值,而其他则为 int64 或对象,可能包含分类数据或时间戳。大多数列中存在非空条目表明数据集是完整的,这对准确分析至关重要。输出还提供了 DataFrame 的内存使用情况(629.1 KB),这对了解数据集的复杂性和进一步分析所需的计算资源至关重要。
returns, positions, transactions = extract_rets_pos_txn_from_zipline(backtest)这行代码调用函数 extract_rets_pos_txn_from_zipline,并将变量 backtest 传递给它。函数将返回三个值:收益、仓位和交易。收益包含与回溯测试的交易策略相关的性能数据,仓位提供了回溯测试期间不同时间段所持股票或合约的信息,而交易则详细说明了所执行的交易,包括买入和卖出。该功能可从回溯测试中提取重要指标和数据,从而对结果进行有效评估和分析。
returns.head().append(returns.tail())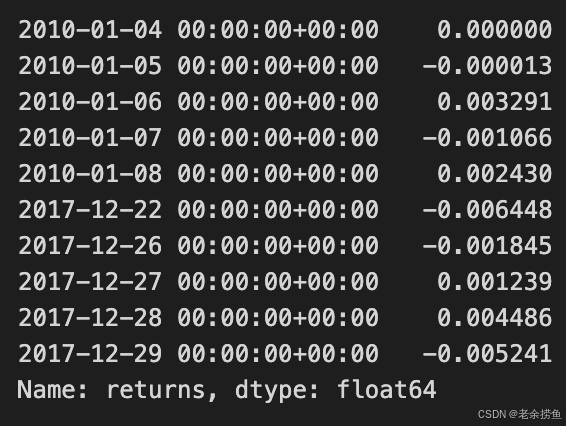
代码片段 returns.head().append(returns.tail()) 提供了一个包含财务收益数据的 DataFrame 的简明概览。head() 方法获取初始行,而 tail() 方法获取最终行。通过追加这两组数据,代码结合了最早和最近的条目,提供了回报率随时间变化的快照。
输出结果显示了从 2010 年 1 月 4 日到 2017 年 12 月 29 日按日期索引的回报值。最初几行反映的是 2010 年 1 月初的回报率,数值从 0.000000 到 -0.003291。2017 年底的最后一个条目显示了正负收益的混合,最终值为-0.005241。该输出说明了回报率的波动情况,提供了对观察期开始和结束时资产表现的深入了解。
这种方法能有效帮助分析师快速评估投资业绩趋势,显示从数据集开始到结束的回报变化情况。
positions.columns = [c.symbol for c in positions.columns[:-1]] + ['cash']
positions.index = positions.index.normalize()
positions.info()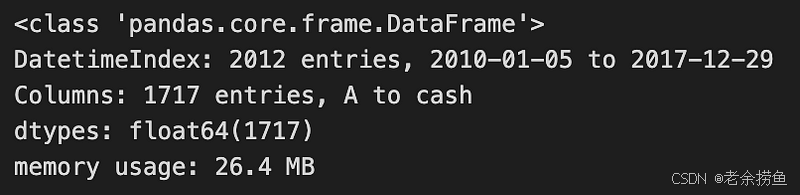
代码修改了一个名为 positions 的 DataFrame,其中包含一个交易策略的财务数据。首先更新列名,将最后一列替换为 "现金",表示它代表现金持有量,这是管理财务数据的常见做法。然后,将 DataFrame 的索引归一化,从任何日期时间条目中移除时间成分,以便于日期比较。
代码输出了修改后的 DataFrame 的摘要,该 DataFrame 类型为 pandas.core.frame.DataFrame,包含从 2010 年 1 月 5 日到 2017 年 12 月 29 日的 2,012 个条目。其中包括 1717 列,主要是资产符号和新的 "现金 "列。所有条目都是 float64 数据类型,这表明它们代表的是货币数值。DataFrame 的内存使用量为 26.4 MB,表明其资源消耗情况。该代码通过确保列名和索引的正确格式化,有效地为 DataFrame 的分析或可视化做好了准备。
transactions.symbol = transactions.symbol.apply(lambda x: x.symbol)这行代码在事务 DataFrame 的符号列上使用 apply 函数,通过应用 lambda 函数转换每个条目。lambda 函数接收一个参数,并从符号列中的每个对象中提取符号属性。因此,执行这一行后,符号列将只包含每个原始条目的符号属性值。当原始条目是对象时,这种转换非常有用,可以将其符号值保留为字符串或其他类型。
transactions.head().append(transactions.tail())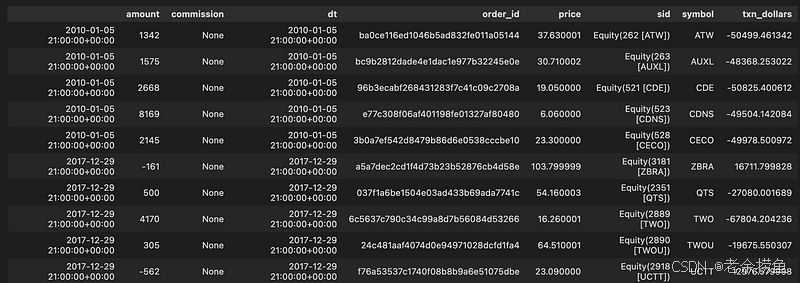
代码片段 transactions.head().append(transactions.tail()) 将名为 transactions 的 DataFrame 的前五行和后五行合并在一起。通过这一操作可以快速检查数据集的开头和结尾,有助于识别趋势或异常。生成的 DataFrame 包括金额、佣金、日期、订单号、价格、SID、符号和 txn_dollars 等列,数据时间为 2010 年 1 月 5 日至 2017 年 12 月 29 日。每一行代表一笔交易,详细记录了交易金额、佣金、日期和时间、订单 ID、价格和证券代码。
例如,2010 年 1 月 5 日的第一笔交易显示金额为 1342,价格为 37.630001,而 2017 年 12 月 29 日的最后一笔交易显示金额为 -562,价格为 23.090000。这种头尾结合的方式可以让用户同时查看初始交易和最后交易,提供数据范围的快照,并深入了解交易随时间的演变。输出说明了交易 DataFrame 的结构和内容,便于分析整个时间轴上的财务数据。
HDF_PATH = Path('..', '..', 'data', 'assets.h5')这行代码定义了一个名为 HDF_PATH 的变量,用于存储名为 assets.h5 的文件路径。Path 函数来自 pathlib 模块,可以轻松操作文件路径。通过使用 Path('...','...','data','assets.h5'),它创建了一个相对路径,向上导航两个目录,进入包含 assets.h5 文件的数据文件夹。这种方法避免了硬编码的完整路径,从而增强了代码的可移植性,因为在不同的环境下,完整路径可能会有所不同。因此,HDF_PATH 可以灵活、简洁地指定 assets.h5 文件的位置。
assets = positions.columns[:-1]
with pd.HDFStore(HDF_PATH) as store:
df = store.get('us_equities/stocks')['sector'].dropna()
df = df[~df.index.duplicated()]
sector_map = df.reindex(assets).fillna('Unknown').to_dict()该代码管理存储在 HDF5 文件中的一组资产的扇区数据。首先,它要识别位置数据帧(DataFrame)中的资产列,但不包括最后一列。然后,使用上下文管理器打开位于 HDF_PATH 的 HDF5 存储,以确保使用后正确关闭。在此上下文中,它会从 us_equities/stocks 关键字中检索 "扇区 "DataFrame,并删除扇区列中任何缺失值的条目,以清理数据。
然后,通过过滤唯一索引记录,消除数据帧中的重复索引。对数据帧进行重新索引,使其与资产列表相匹配,任何缺乏相应扇区条目的资产都会被赋值为 NaN,然后替换为 "未知"。最后,处理后的 DataFrame 会转换为字典,将每项资产映射到相应的部门,方便快速查找,并将未找到的资产默认为 "未知"。
with pd.HDFStore(HDF_PATH) as store:
benchmark_rets = store['sp500/prices'].close.pct_change()
benchmark_rets.name = 'S&P500'
benchmark_rets = benchmark_rets.tz_localize('UTC').filter(returns.index)
benchmark_rets.tail()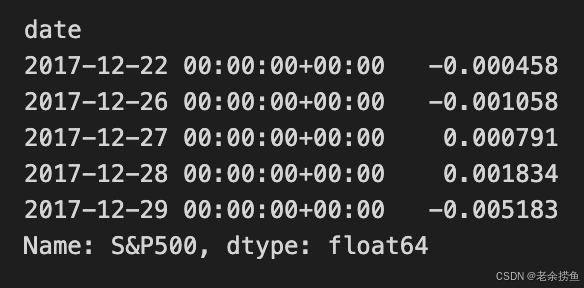
代码片段使用 pandas 库处理以 HDF5 格式存储的金融数据。它访问位于 HDF_PATH 的 HDF5 存储,以检索标准普尔 500 指数的收盘价,并应用 pct_change 方法计算连续收盘价之间的百分比变化,从而将价格数据转换为收益,这对金融分析至关重要。
计算收益后,代码会将生成的系列标记为 "S&P500",以便于识别。它使用 tz_localize('UTC')方法将时间戳标准化为 UTC。filter(returns.index)方法将基准收益率与另一个名为 returns 的系列对齐,确保 benchmark_rets 系列中只保留收益率索引中的日期。
输出显示了 benchmark_rets 系列的最后几个条目,其中捕捉了标准普尔 500 指数的日期和相应的每日百分比回报率,显示了指定时期内的正负波动。该输出还确认回报值为 float64 类型,适合金融分析中的数值计算。在将项目从 Zipline 过渡到 Pyfolio 的过程中,这一过程对于风险评估或业绩比较等进一步分析至关重要。
perf_stats(returns=returns, factor_returns=benchmark_rets, positions=positions, transactions=transactions)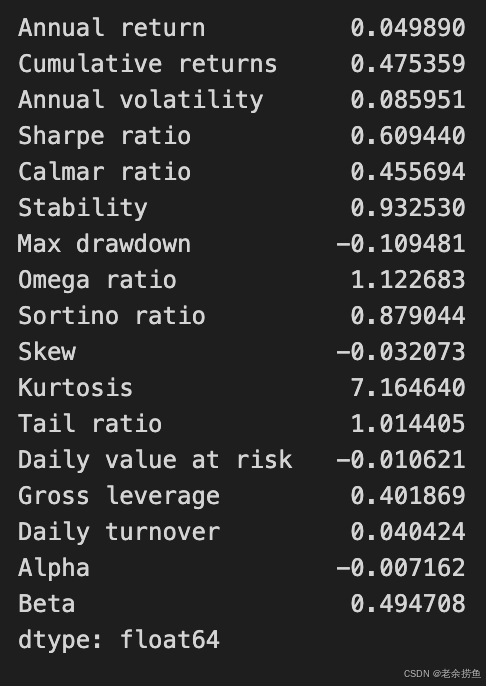
函数 perf_stats 通过分析提供的收益、基准收益、头寸和交易中的各种财务指标来评估交易策略的性能。输出结果包括评估策略有效性和风险状况的关键绩效指标。
年收益率约为 0.0499,表示年平均利润,累计收益率约为 0.4754,反映分析期内的总收益。年波动率约为 0.0859,用于衡量收益变化和相关风险。夏普比率约为 0.6094,表明每单位风险的合理回报。
卡尔马比率约为 0.4557,将年度回报与-0.1095 的最大缩水进行比较,显示出投资价值的最大跌幅,凸显出巨大的潜在损失。稳定度为 0.9323,表明表现稳定。
其他指标包括 1.1227 的 Omega 比率(表明收益高于损失的可能性)和约 0.8790 的 Sortino 比率(关注下行风险)。偏度为-0.0320,表明略微倾向于负收益,而峰度为 7.1644,表明出现极端结果的可能性较高。
约 1.0144 的尾部比率评估了极端损失的风险,-0.0166 的每日风险值量化了潜在的每日损失。总杠杆率为 1.4014,反映了借入资金的程度,日周转率约为 0.0404,表明了交易频率。阿尔法值为-0.0072,表明表现不佳,而贝塔值为 0.4948,表明与市场走势有一定的相关性。这些指标合在一起,可以全面反映交易策略的绩效和风险特征。
plot_perf_stats(returns=returns, factor_returns=benchmark_rets)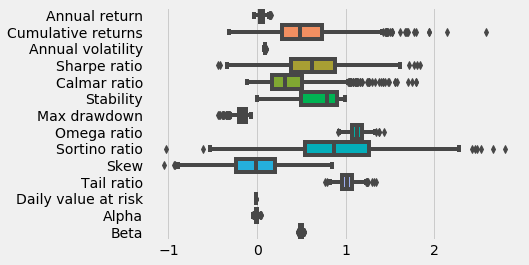
plot_perf_stats(returns=returns, factor_returns=benchmark_rets)代码片段可视化财务策略或投资组合的绩效统计数据。它有两个参数:returns 代表所分析投资的收益,factor_returns 代表用于比较的基准或市场因子的收益。
该功能可生成一个方框图,显示各种绩效指标,如年回报率、累计回报率、年波动率、夏普比率、卡尔马比率、最大缩水率和阿尔法等。通过这些指标可以深入了解投资业绩的不同方面。例如,年度回报率显示的是平均年度回报率,而夏普比率评估的是风险调整后的回报率。
箱形图的形式可以清楚地比较投资与其基准之间的这些指标。方框表示四分位数之间的范围,每个方框内的线表示中值,而须线表示数据范围,并相应地标出异常值。这种可视化方式有助于评估投资相对于基准的风险和收益情况,便于识别业绩的优势和劣势。总体而言,该功能对投资者和分析师评估和比较投资策略非常有用。
oos_date = '2017-01-01'这一行创建了一个名为 oos_date 的变量,并为其分配了字符串值 2017-01-01,表示 2017 年 1 月 1 日。如果以后需要进行日期操作,可能需要使用 Python 中的 datetime 等库将此字符串转换为日期对象。现在,它只是一个简单的日期字符串。
show_perf_stats(returns=returns,
factor_returns=benchmark_rets,
positions=positions,
transactions=transactions,
live_start_date=oos_date)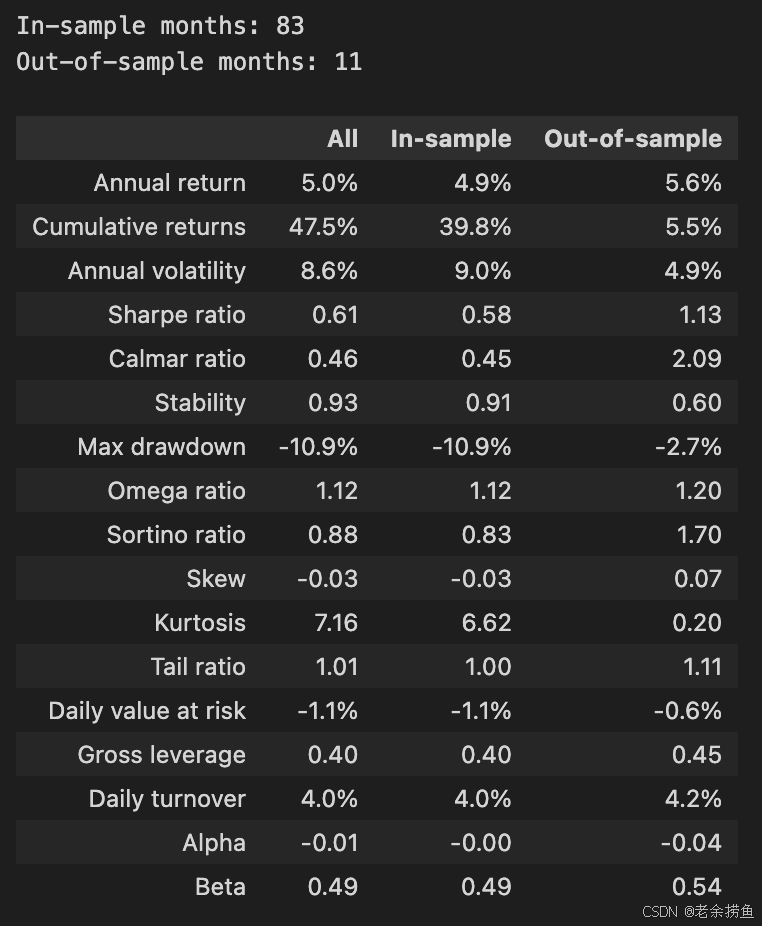
代码片段调用 show_perf_stats 函数来分析和显示交易策略的性能统计。它需要的参数包括:由策略产生的收益;用于基准比较的 factor_returns;交易期间持有的仓位;记录已执行交易的事务;以及标记样本外测试开始的 live_start_date。
输出总结了样本内和样本外两个阶段的绩效指标,样本内跨度为 83 个月,样本外跨度为 11 个月。年度回报率略有提高,从样本内的 5.0% 提高到样本外的 5.6%,表明后一阶段的表现更好。累计回报率也呈现类似趋势,样本内回报率为 47.5%,样本外回报率为 39.8%。
年波动率从样本内的 8.6% 降至样本外的 4.9%,表明未见数据的波动率降低。夏普比率从 0.61 提高到 1.13,表明样本外期间的风险调整回报率更高。卡尔马比率也从 0.46 显著上升到 2.09,反映了绩效的提高。
最大缩水率等指标显示,样本外业绩从样本内的-10.9%下降到-2.7%,表明后一时期的弹性更大。其他指标,包括 Omega 比率和 Sortino 比率,在样本外数据中显示出有利的风险状况。
总之,研究结果表明,在根据样本外数据进行评估时,交易策略不仅保持了其性能,而且在几个关键领域有所改进,这凸显了其稳健性和在现实世界中的应用潜力。
plot_rolling_returns(returns=returns, factor_returns=benchmark_rets, live_start_date=oos_date, cone_std=(1.0, 1.5, 2.0))
plt.gcf().set_size_inches(14, 8)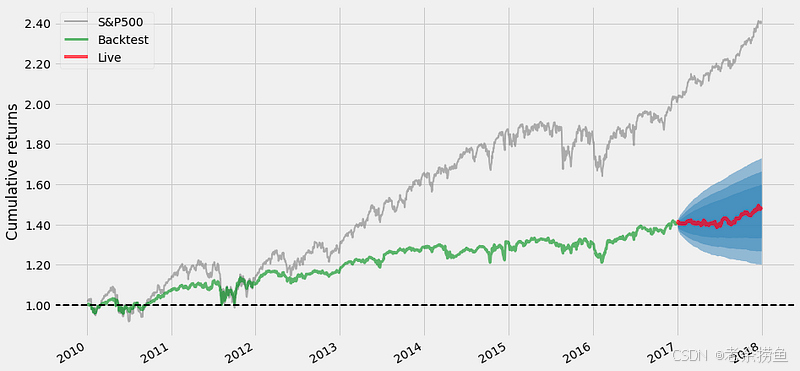
代码片段使用 plot_rolling_returns 函数可视化交易策略相对于标准普尔 500 指数的表现。它需要策略收益、基准收益和实时交易开始日期等参数。con_std 参数设置为 1.0、1.5 和 2.0,用于定义图中置信区间的标准偏差。
输出显示了一段时间内的累计回报,三条线代表不同的绩效指标。灰色线表示 2010 年至 2018 年的标准普尔 500 指数基准。绿线表示交易策略的回溯测试收益率,该策略最初落后于基准,但在随后几年中表现出显著增长。红线反映的是实时回报,它紧跟回溯测试的回报,但也有一些波动。
实时收益线周围的阴影区域说明了置信区间,显示了基于历史波动的预期收益范围。这种可视化方式有助于将策略的表现与基准进行比较,强调交易策略在一段时间内的有效性。14 x 8 英寸的版面尺寸确保了可读性,使其成为相对于市场进行绩效分析的重要工具。
plot_rolling_sharpe(returns=returns)
plt.gcf().set_size_inches(14, 8);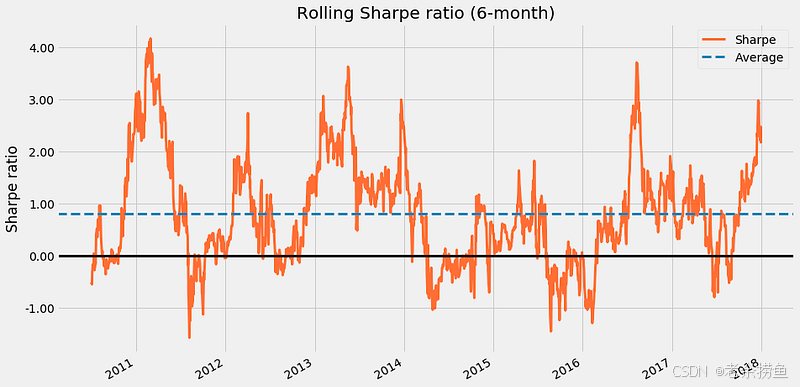
代码片段 plot_rolling_sharpe(returns=returns) 显示一组收益随着时间推移的滚动夏普比率。夏普比率衡量风险调整后的收益,显示相对于风险较高资产的波动率的超额收益。该函数计算的是六个月滚动窗口内的夏普比率,有助于深入了解不同市场条件下的表现。
输出图像显示了 2011 年至 2018 年的滚动夏普比率。橙色线描绘了计算出的夏普比率,在超过 4 的地方有明显的峰值,表明风险调整后的回报率很高。蓝色虚线表示作为基准的平均夏普比率,而位于零点的黑线则表示相对于风险的充足回报的临界值。图中显示了夏普比率低于零的情况,表明在此期间收益不足以证明风险的合理性。这种可视化方式有效地说明了投资战略的绩效,揭示了成功与挑战。
plot_rolling_beta(returns=returns, factor_returns=benchmark_rets)
plt.gcf().set_size_inches(14, 8);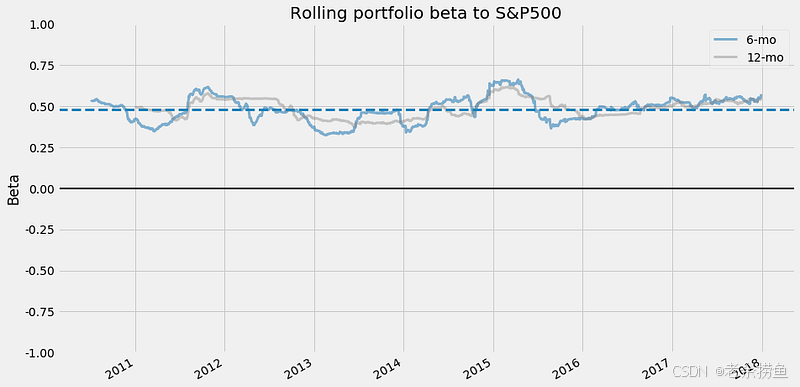
函数 plot_rolling_beta 显示投资组合与标准普尔 500 指数基准相比的滚动贝塔系数。参数 returns 和 factor_returns 分别代表投资组合和基准收益。滚动贝塔值衡量的是投资组合收益随基准收益变化而变化的程度。
输出结果为时间序列图,X 轴为 2011 年至 2018 年的年份,Y 轴为贝塔值。图中显示了两条线:蓝色实线表示 6 个月的滚动贝塔值,浅灰色线表示 12 个月的滚动贝塔值。水平虚线 0.5 表示贝塔值,表明投资组合的波动性低于基准。
贝塔值在整个绘制期间波动,反映了投资组合相对于标准普尔 500 指数的风险状况的变化。6 个月的贝塔值更能反映近期的市场状况,而 12 个月的贝塔值则提供了更平滑的长期视角。这种可视化方法有助于投资者了解其投资组合的风险敞口随时间的变化,尤其是在不同的市场阶段,并支持根据历史表现做出明智的投资决策。
fig, ax = plt.subplots(nrows=2, ncols=2, figsize=(16, 10))
axes = ax.flatten()plot_drawdown_periods(returns=returns, ax=axes[0])
plot_rolling_beta(returns=returns, factor_returns=benchmark_rets, ax=axes[1])
plot_drawdown_underwater(returns=returns, ax=axes[2])
plot_rolling_sharpe(returns=returns)
plt.tight_layout();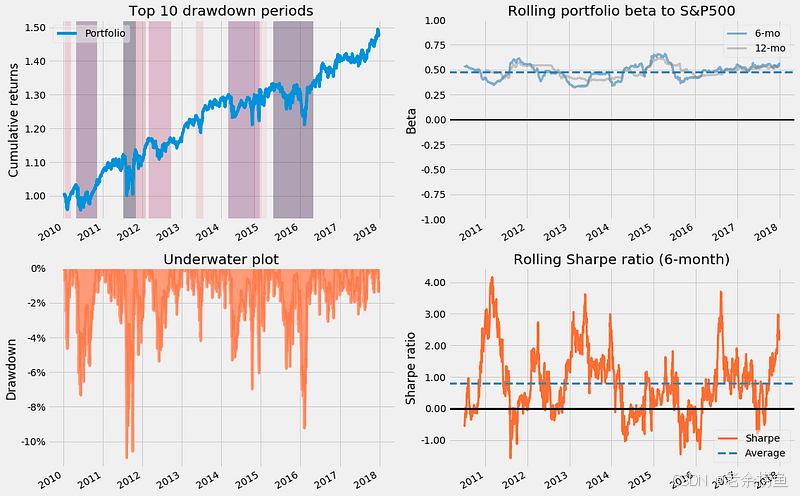
代码片段使用 Matplotlib 创建了一个 2x2 网格的子图,以可视化金融投资组合随时间变化的绩效指标。第一个子图显示了前 10 个缩水期,蓝线代表 2010 年至 2018 年的累计回报,阴影区域表示大幅缩水。这有助于识别大幅下跌期和评估风险敞口。
第二个子图显示投资组合与标准普尔 500 指数在 6 个月和 12 个月期间的滚动贝塔值。贝塔值显示了投资组合对市场波动的敏感度,贝塔值超过 1 表示波动率高于市场。该图说明了投资组合的风险状况是如何随时间变化的。
第三个子图是水下图,突出显示了指定时间段内从高峰到低谷的最大损失。橙色线表示缩水深度,让人了解投资组合表现最差的时期。
第四个子图显示的是按 6 个月间隔计算的滚动夏普比率,该比率衡量投资组合的风险调整后回报。夏普比率越高,表明业绩与风险相比越好,该图反映了夏普比率随时间的波动。
这些可视化内容共同提供了投资组合的业绩、风险和回报特征的全面概览,有助于做出更明智的投资决策。
interesting_times = extract_interesting_date_ranges(returns=returns)
(interesting_times['Fall2015']
.to_frame('pf').join(benchmark_rets)
.add(1).cumprod().sub(1)
.plot(lw=2, figsize=(14, 6), title='Post-Brexit Turmoil'))
plt.tight_layout()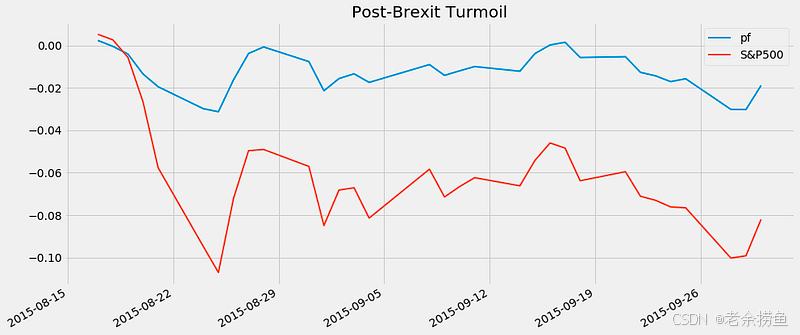
代码片段从收益数据集中提取特定日期范围,主要集中在 2016 年英国脱欧投票后的时期。函数 extract_interesting_date_ranges 调用的是回报数据(可能包含历史财务业绩数据),结果存储在 interesting_times 变量中,主要集中在 2015 年秋季。
然后对提取的数据进行转换,以提高可用性。to_frame 方法将所选数据转换为标有 "pf "的 DataFrame,并将其与另一个 DataFrame(benchmark_rets,包含标准普尔 500 指数收益等基准收益数据)连接起来。合并后的数据会进行计算,将每个值加 1,计算累计乘积,再减去 1,从而有效计算出指定期间的累计回报,用于业绩比较。
最后一步是绘制结果图,以 2 的线宽和指定的数字大小直观显示投资组合在一段时间内相对于基准的累计回报。标题为 "英国脱欧后的动荡",反映了这一重大政治事件中的市场行为。输出图像显示了两条线:一条是蓝色的投资组合表现线,另一条是红色的标准普尔 500 指数线,说明了英国脱欧后期间回报的波动性和趋势,并突出了投资组合相对于大盘的表现。
观点回顾
- 算法交易策略的开发和测试应该基于历史数据和现实的交易条件,以确保策略在实际市场中的有效性。
- 均值回归是算法交易中的一种重要策略,它假设资产价格会回归到其平均水平,因此可以通过识别偏离平均水平的资产来获利。
- 绩效分析和可视化对于评估交易策略至关重要,Pyfolio 提供了一套完整的工具来分析和展示策略的绩效指标。
- 数据的准确处理和存储对于算法交易至关重要,使用 HDF5 文件可以有效地管理和访问大型数据集。
- 风险管理是算法交易中的一个关键环节,通过分析波动率、夏普比率、最大回撤和贝塔值等指标,可以更好地理解和控制交易风险。
- 使用滚动窗口来分析和监控策略的短期和长期风险敞口,如滚动贝塔和滚动夏普比率,有助于时刻掌握策略的风险状况。
- 算法交易策略的绩效不仅要在样本内数据上进行测试,还应该在样本外数据上进行验证,以确保策略的稳健性和适用性。
- 通过可视化工具,如 Matplotlib 和 Seaborn,可以更直观地展示策略的表现和市场动态,帮助交易者做出更明智的决策。
感谢您阅读到最后。如果对文中的内容有任何疑问,请给我留言,必复。
本文内容仅仅是技术探讨和学习,并不构成任何投资建议。
转发请注明原作者和出处。



















 375
375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











