







后续大多数模型提升速度和精度:
提升速度:
-知识蒸馏,以distillBert和tinyBert为代表
-神经网络优化技巧。prune来剪裁多余的网络节点,混合精度(fp32和fp26混合来降低计算精度从从而实现速度的提升)
提升精度:
-增强算力。Roberta
-改进网络。xlnet,利用transformer-xl
-多任务学习(ensemble)
DistillBERT
DistilBERT, a distilled version of BERT: smaller, faster, cheaper andlighter HuggingFace
原因:
模型:应用到线上服务对服务的计算资源要求非常高
效果:对transformer进行了知识蒸馏,得到了一个只有原始模型40%大小的学生模型,并且在下游任务上的效果和教室模型相差不多,并且inference的时间是之前的60%
使用Bert-base作为teacher model
-在12层Transformer-encoder的基础上每2层中去掉一层,减少到6层,每一层用teacher model对应层的参数初始化。
-去掉了token type embedding和pooler。
-利用teacher model的soft target和teacher model的隐层参数来训练student model.
目的:在精度损失不大的情况下压缩模型大小提高其推理速度,更适应线上应用满足业务需求。
完整的大模型在线项目流程:
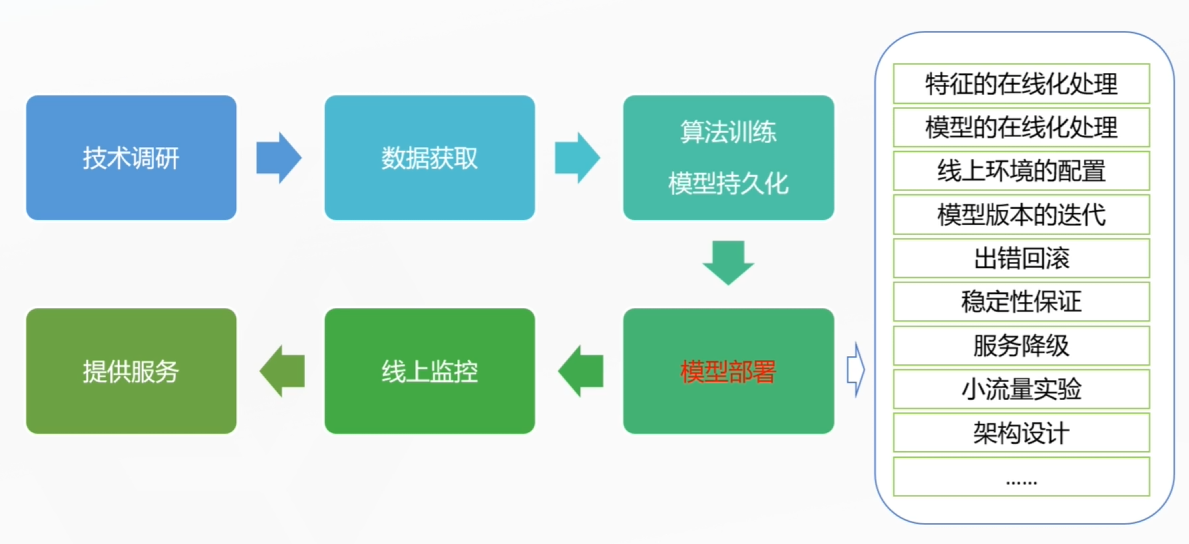
为什么要部署?
模型的服务方式
模型的服务方式主要分为离线预测和在线预测两大类,这两种服务方式各有特点,适用于不同的场景需求。下面详细解释这两种服务方式:
离线预测
定义: 离线预测是指在非实时的环境下,对历史数据或批量数据进行模型预测。这种预测方式通常在数据处理和分析阶段使用,不直接响应即时查询或请求。
特点:
- 数据处理量大: 适合处理大量历史数据或大数据集,可以在计算资源相对充裕的时间段(如夜间)运行。
- 不实时: 预测结果不是立即生成,不需要实时响应用户请求,因此对延迟要求不高。
- 资源调度灵活: 可以利用闲时计算资源进行批处理,成本效益较高。
- 适用场景: 适用于数据分析、市场趋势预测、报表生成、用户行为分析等不需要即时反馈的场景。
在线预测
定义: 在线预测是指模型部署在服务器上,能够实时接收输入数据并迅速返回预测结果的一种服务方式。它强调低延迟和高可用性,以支持即时决策。
特点:
- 实时性: 能够立即响应用户的查询或请求,提供即时预测结果,适用于需要快速反馈的场景。
- 低延迟: 对系统的响应时间有严格要求,需要高效的计算能力和优化的算法设计来保证用户体验。
- 资源要求高: 需要持续运行的计算资源和高效的数据传输能力,以应对不确定的并发访问压力。
- 适用场景: 适用于推荐系统、实时交易分析、欺诈检测、语音识别、自动驾驶等需要即时决策的场景。
总结
选择离线预测还是在线预测,主要取决于应用场景对时效性的要求、数据处理规模以及资源成本的考量。离线预测适用于大数据量的批处理分析,而在线预测则更侧重于实时交互和服务响应。在实际应用中,两者往往结合使用,比如先通过离线预测进行模型训练和参数优化,然后将模型部署为在线服务,以满足不同业务场景的需求。
部署方式:
1.server framework + deeplearning framework api
2.server framework+ deeplearning serving
Server Framework (服务器框架)
服务器框架是构建应用程序后端的核心,它提供了处理网络请求、数据处理、安全控制及与其他系统交互的能力。常见的服务器框架包括但不限于:
- Flask / Django (Python): Flask以其轻量级和灵活性著称,适合快速搭建小型服务;Django则是一个功能全面的高级Web框架,适合构建大型项目,自带ORM、模板引擎等。
- Express.js (Node.js): 适用于快速构建Web应用和服务的轻量级框架,特别适合开发RESTful APIs。
- Spring Boot (Java): 面向Java平台,简化了新Spring应用的初始搭建以及开发过程,提供了默认配置来快速运行应用程序。
Deep Learning Framework API / Serving
这部分专注于如何高效、可靠地部署和管理深度学习模型,确保模型能够在生产环境中实时响应预测请求。关键技术和框架包括:
- TensorFlow Serving: 专为TensorFlow模型设计的高性能服务系统,支持模型版本管理、高效加载和低延迟预测服务。
- PyTorch Serving: 类似于TensorFlow Serving,针对PyTorch模型,旨在简化从研究到生产的路径,提供动态加载模型、版本控制等功能。
- ONNX Runtime: 开放神经网络交换(ONNX)格式的支持工具,允许模型在不同框架间转换,并高效执行,支持TensorFlow、PyTorch等多种模型格式。
综合部署方式
结合这两部分,一个典型的部署流程可能如下:
- 模型训练: 使用TensorFlow、PyTorch等框架训练模型。
- 模型转换与优化: 如有必要,将模型转换为通用格式如ONNX,进行优化以提高推理速度。
- 部署准备: 利用Server Framework(如Flask)搭建后端服务,配置API端点。
- 集成Deep Learning Serving: 将训练好的模型通过TensorFlow Serving或类似服务部署,确保模型加载至服务器内存,准备接受预测请求。
- 接口对接: 通过Server Framework的API调用Deep Learning Serving中的模型接口,处理客户端请求,将预测结果返回给前端应用或客户端。
这样的架构设计既充分利用了深度学习框架的强大功能,又通过服务器框架的灵活性和可扩展性保证了服务的稳定性和效率,是实现复杂AI应用部署的优选方案。
算法人员思考问题维度:
-长耗时操作
-一次性操作
-接口控制
-处理时长
-模型大小
-服务降级策略
-回滚兼容策略
-实验方式
-多模型并行或者串行
部署架构参考
python Server Framework & model API
Flask(灵活,轻量级,插件多)
Tornado(异步,速度快,插件少)
Django(全能,重,大型项目)
Python API实验、训练
Python/C++ API部署、预测
Bert-as-service & Tf-serving
https://github.com/hanxiao/bert-as-service
https://github.com/tensorflow/serving
https://www.tensorflow.org/tfx/guide/serving
可以基于docker来部署
tensorflow-模型容器化
是的,TensorFlow 主要是为了构建和运行机器学习模型而设计的。它是Google开发的一个开源软件库,特别强大于深度学习领域。TensorFlow 提供了一系列工具和库,帮助开发者完成以下任务:
-
构建模型:你可以使用 TensorFlow 来定义各种机器学习模型,无论是简单的线性模型还是复杂的深度神经网络。通过组合不同的层、激活函数和损失函数,你可以创建出定制化的模型来解决特定问题。
-
训练模型:TensorFlow 支持数据的导入、预处理,并提供了多种优化算法来训练模型。它利用反向传播和自动微分来高效地更新模型参数,以最小化损失函数。
-
评估与调整:模型训练完成后,你可以使用 TensorFlow 测试模型性能,进行验证,并根据需要调整模型参数或结构以优化结果。
-
部署模型:TensorFlow 支持将训练好的模型部署到服务器、移动设备或网页应用中,进行实时或批量预测。
-
分布式计算:TensorFlow 支持分布式训练,能够在多个GPU或TPU上并行运行,大大加快训练速度。
-
高级特性:除了基础功能,TensorFlow 还包括诸如模型优化、模型服务、可视化工具(如TensorBoard)等高级特性,便于模型的调试、监控和优化。
因此,简单来说,TensorFlow 是一个用于创建、训练、评估和部署机器学习模型的综合平台。
具体代码分析:
阅读理解与多模型集成技术
















 1186
1186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









