






3.1 一元线性回归
基本形式:
通过均方误差去衡量模型,保证均方误差最小来求得w和b(最小二乘法),其中需要证明函数为凸函数(海塞矩阵半正定),这样才能保证极值点就是最小值点。

3.2 多元线性回归
基本形式:
类似一元,也可采用最小二乘法对w,b估计,但其中求导过程需要涉及矩阵微分
3.3 对数几率回归
基本形式:
一种分类学习方法,通过sigmoid函数将实值转换为(0,1)上的值,可以通过极大似然法估计w,b的值(也可以通过信息论的方法,即求使交叉熵最小的w,b值),求解算法为梯度下降、牛顿法。
3.4线性判别分析
将样本投影到直线上,使同类距离尽可能近,异类距离尽可能远

同类距离尽可能近,可以用方差刻画:

再将两式相除得到最大化目标
因为此式的解和w的长度无关,只与它的方向相关,所以可以令分母为1,求分子最大。即:
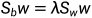
因为 ,后面乘积是个数,所以方向为
,后面乘积是个数,所以方向为 ,不妨令:
,不妨令:

即可求出
3.5多分类学习
是基于二分类学习的拓展,先拆解成若干个二分类任务,然后再进行集成
常见策略:
OvO(一对一),将任意两个类配对,形成n(n-1)/2个分类器,结果可通过最多的那个分类表示;
OvR(一对其余),将任意一个类作为正类,其余类作为负类,形成n个分类器,结果为显示正类的那个分类。若有多个正类,则考虑每个分类器的预测置信度;
MvM(多对多),将一部分类别作为正类,另一部分作为负类,一种常见的技术:“纠错输出码”(进行M次划分,结果为测试编码和类别编码距离最小的那个分类)
3.6类别不平衡问题
实际情况中不同类别的样本数很大可能不同,甚至差别较大,而之前是基于假设正类负类数目相同展开的,所以此时可以用“再缩放”策略解决类别不平衡问题。















 582
582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









