






由于我的电脑的性能并不能支持在GPU环境下运行
尽量支持GPU的话还是使用GPU,二者相差的速度可能相差3-5倍
官方默认的是使用CPU环境下的,直接下载官方的包即可
环境配置
首先电脑要下载Anaconda和PyTorch
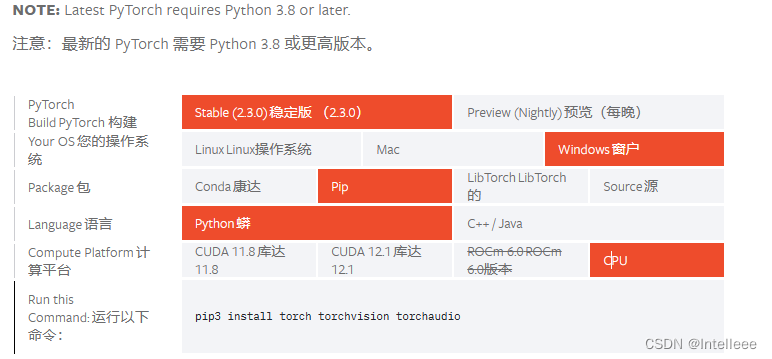
PyTorch安装(也可以使用一些其他的镜像源下载):
地址:在本地启动 |PyTorch的 --- Start Locally | PyTorch
模型训练
labelimg工具进行数据标注
pip install labelimg
启动:命令行输入 labelimg
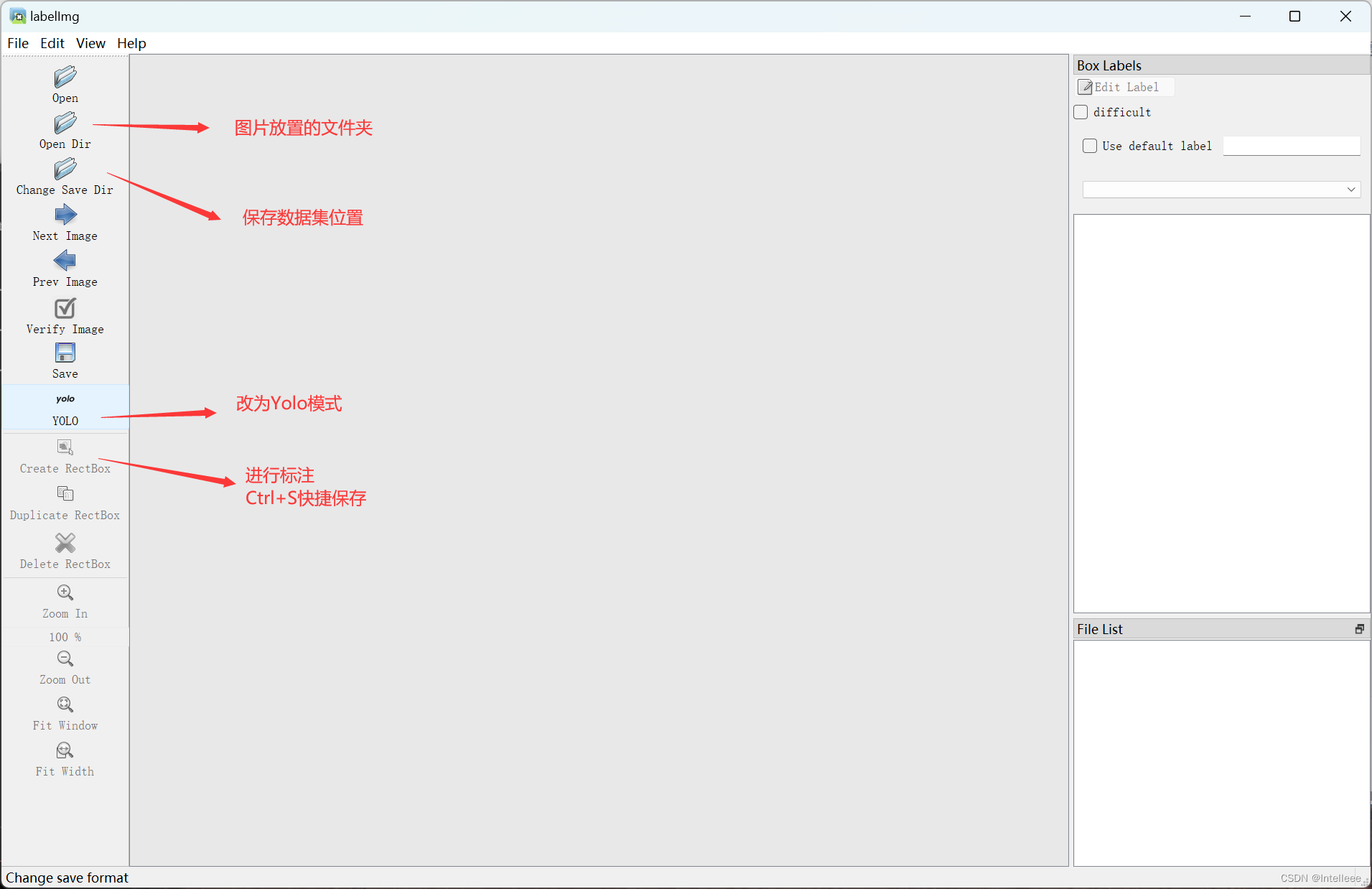
新建一个文件夹(比如我要实现垃圾分类检测)
新建Trash01文件夹
子目录:
train (内含子目录images、labels)
valid (内含子目录images、labels)
data.yaml
train为训练组,valid为对照组,一般为9:1
images放图片,labels放用labelimg标注好的数据
data.yaml:
names:
- RecyclableWaste
- HazardousWaste
- KitchenWaste
- OtherWaste
nc: 4
train: D:\A_Yolov5\Main01\yolov5-mask-42\Garbage06\train
val: D:\A_Yolov5\Main01\yolov5-mask-42\Garbage06\valid
进行训练(每次训练2张,一共100次) 该精度我的cpu还能带的动,再高一点就不好训练了
python train.py --batch-size 2 --epochs 100 --data D:\A_Yolov5\Main01\yolov5-mask-42\Garbage06\data.yaml --weights D:\A_Yolov5\Main01\yolov5-mask-42\yolov5s.pt
用视频进行实时识别:
在detect.py同目录下创建一个文件夹stream.txt,在里面写入一个0以此代表使用本机摄像头,如果有USB摄像头则为1,2,3等。
放置训练集位置:
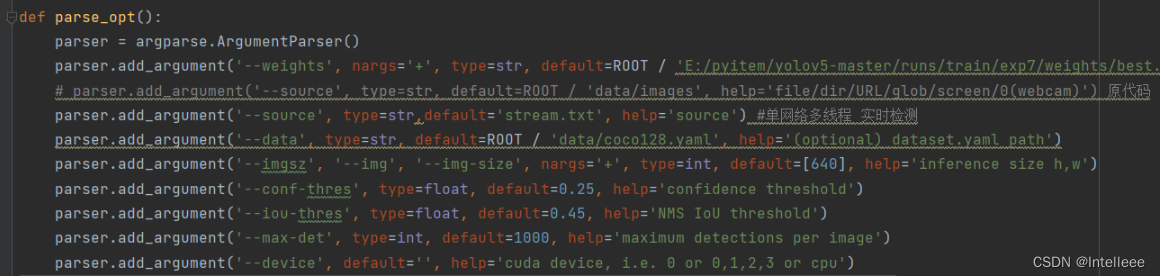
将source注释掉,然后改为下面的这行
parser.add_argument('--source', type=str,default='stream.txt', help='source') #单网络多线程 实时检测
然后直接运行:delect.py即可
总结:
训练经验:单个物体模型的话物体照片在 CPU-2张-100次:batch-size 2 --epochs 100情况下需要不同背景不同角度下150张图片左右
多个物体识别为一个种类的话最好300张以上
垃圾分类与识别效果图:



2023.11.13















 6168
6168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









