







文章目录
什么是数据分析
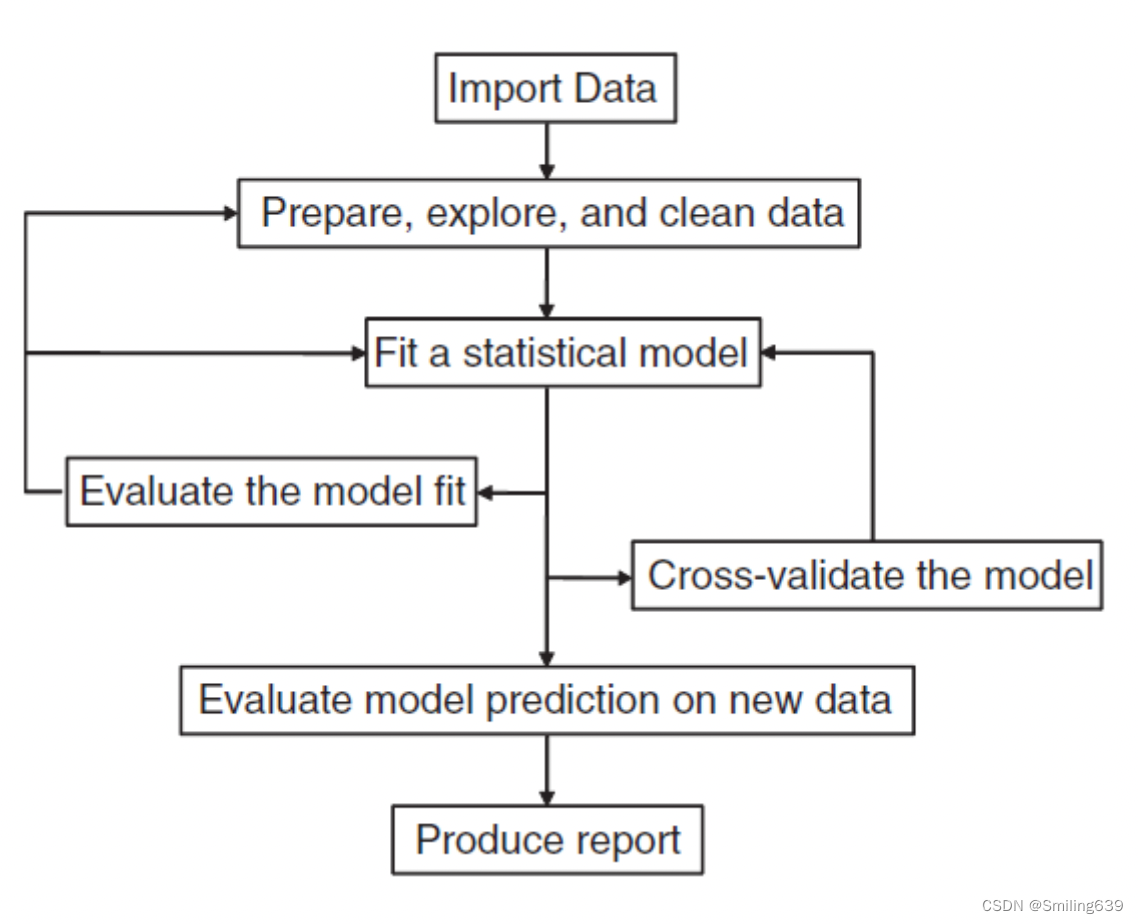
• 访问数据(从多个来源将数据导入应用程序)
• 清理数据(编码缺失数据,修复或删除错误编码的数据,将变量转换为更有用的格式)
• 注释数据(为了记住每个部分代表的含义)
• 总结数据(获取描述性统计信息来帮助表征数据)
• 可视化数据(因为一张图片确实胜过千言万语)
• 建模数据(发现关系和测试假设)
• 准备结果(创建出版质量的表格和图形)
一、质量分析
1.有问题的数据类型
缺失值、异常值、重复数据、不一致数据、偏倚值等
2.缺失值处理
- is.na():指明哪里有缺失值,在缺失值的位置标为TRUE
> mydata <- data.frame(col1 = c(1,2,NA,4,5),
+ col2 = c("a",NA,NA,"d","e"),
+ col3 = c(TRUE,FALSE,FALSE,TRUE,TRUE))
> is.na(mydata)
col1 col2 col3
[1,] FALSE FALSE FALSE
[2,] FALSE TRUE FALSE
[3,] TRUE TRUE FALSE
[4,] FALSE FALSE FALSE
[5,] FALSE FALSE FALSE
- complete.cases():判断每一行有没有缺失值,如果没有就是TRUE
> complete.cases(mydata)
[1] TRUE FALSE FALSE TRUE TRUE
- mydata[complete.cases(mydata),]:取出没有缺失值的行
> mydata[complete.cases(mydata),]
col1 col2 col3
1 1 a TRUE
4 4 d TRUE
5 5 e TRUE
> mydata[!complete.cases(mydata),]
col1 col2 col3
2 2 <NA> FALSE
3 NA <NA> FALSE
3.异常值处理
- 最小值、最大值
min、max函数 - 箱线图
> x<-c(0:100,-100,200)
> boxplot(x)
> outliers<-boxplot(x)$out
> outliers
[1] -100 200
二、特征分析
1.描述型统计量
描述性统计量是用来描述数据分布、集中趋势和离散程度等特征的统计量。常见的描述性统计量包括:
集中趋势:
均值(Mean):所有观测值的平均数,用来表示数据的集中程度。
中位数(Median):将数据按大小排列后,位于中间位置的数值,对于存在异常值或偏态分布的数据更为稳健。
众数(Mode):数据集中出现最频繁的数值。
离散程度:
方差(Variance):每个数据与均值之差的平方的平均数,用来衡量数据的离散程度。
标准差(Standard Deviation):方差的平方根,与原始数据同单位,是方差的常用衡量方式。
极差(Range):最大值与最小值之差,衡量数据的全局离散程度。
四分位数范围(Interquartile Range,IQR):第三四分位数与第一四分位数之差,用于度量数据的分散程度。
形状特征:
偏度(Skewness):数据分布的不对称程度,正偏表示右侧尾部较长,负偏表示左侧尾部较长。
峰度(Kurtosis):数据分布的峰态,衡量数据分布的尖峭程度,高峰度表示尖峭,低峰度表示平缓。
获取描述型统计量的方法
- summary函数
根据输入对象的类型生成相应的摘要统计信息,包括最小值、最大值、中位数、四分位数、因子变量的水平等等。
对于数值型数据,summary 函数会给出以下统计信息:
·最小值(Minimum)
·第一四分位数(1st Quartile)
·中位数(Median)
·平均值(Mean)
·第三四分位数(3rd Quartile)
·最大值(Maximum)
对于因子(factor)型数据,summary 函数会给出因子水平(factor levels)及各水平对应的频数。
> myvars <- c("mpg", "hp", "wt")
> summary(mtcars[myvars])#对上述三个属性分别进行summary分析
mpg hp wt
Min. :10.40 Min. : 52.0 Min. :1.513
1st Qu.:15.43 1st Qu.: 96.5 1st Qu.:2.581
Median :19.20 Median :123.0 Median :3.325
Mean :20.09 Mean :146.7 Mean :3.217
3rd Qu.:22.80 3rd Qu.:180.0 3rd Qu.:3.610
Max. :33.90 Max. :335.0 Max. :5.424
- describe函数
n: 变量的样本数量,即非缺失值的观测数量。
missing: 变量的缺失值数量。
distinct: 变量中不同取值的数量,即唯一值的数量。
Info: 变量的信息量,通常指非缺失值的比例,取值范围在0到1之间,越接近1表示信息量越大。
Mean: 变量的均值,即所有观测值的平均数。
Gmd: 广义中位数差,是中位数的一种变体,用于衡量数据的离散程度。
.05, .10, .25, .50, .75, .90, .95: 分位数,表示在排序后的数据中,对应百分比位置处的值。比如,.05表示排在前5%位置的值,.95表示排在前95%位置的值。
- 其他函数
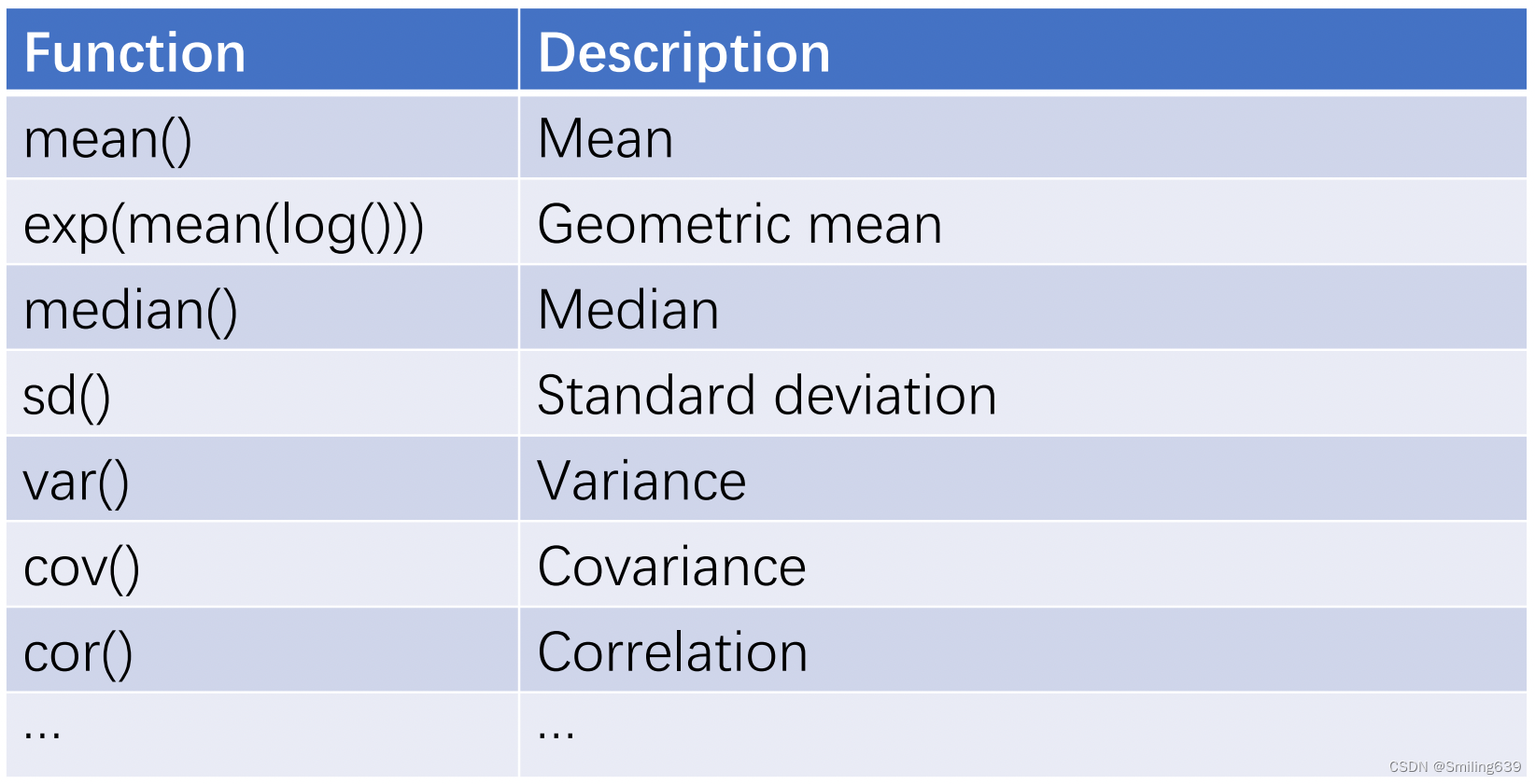
2.可视化结果
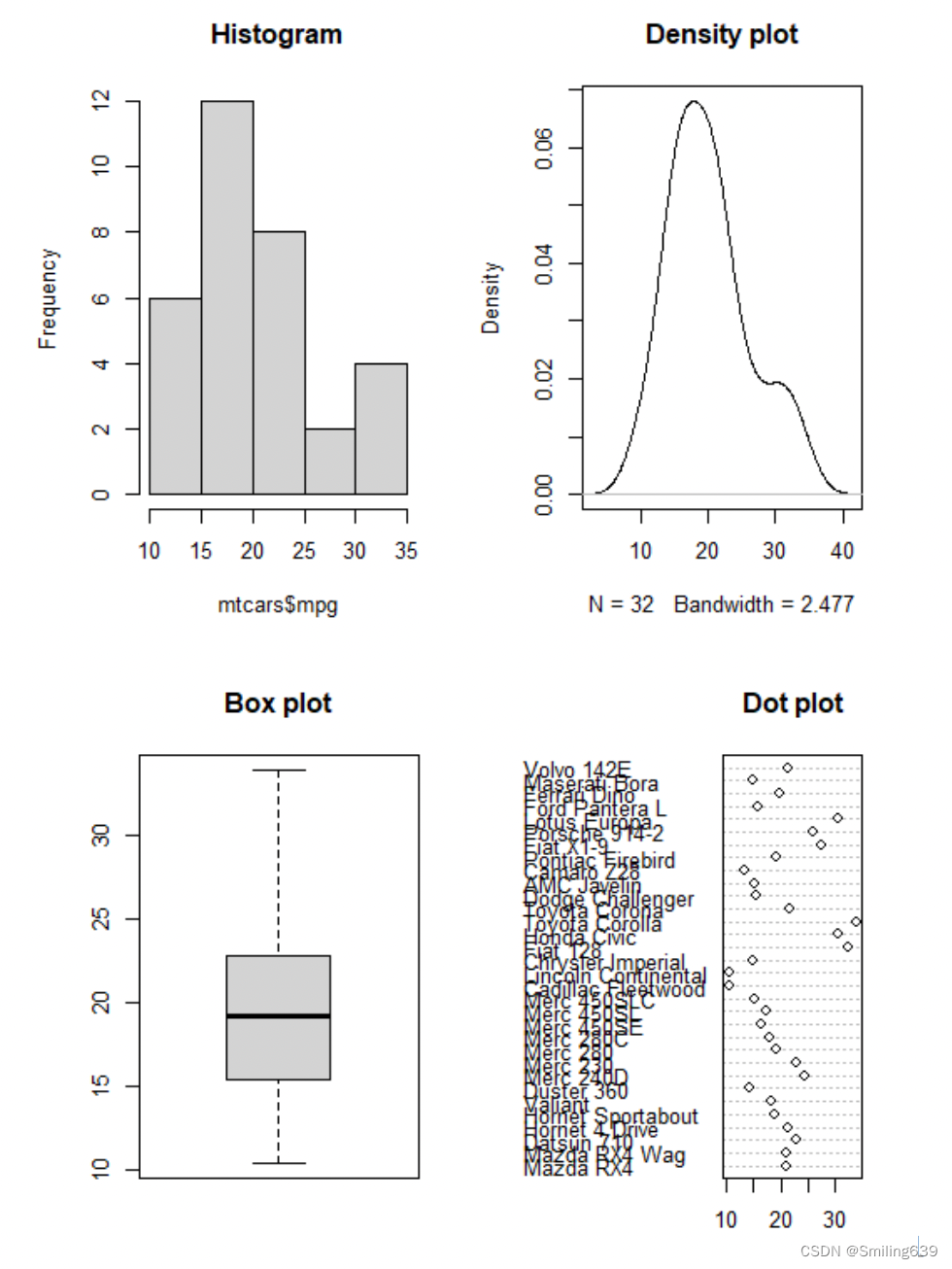
- 直方图(Histogram):主要用于显示连续变量的分布情况,可以观察数据的分布形状、中心位置、离散程度等特征,以及是否存在异常值或峰态。
- 密度图(Density Plot):也适用于连续变量,但更加平滑地展示了数据的分布情况,可以更清晰地观察数据的概率密度分布,并进行比较。
- 箱线图(Box Plot):主要用于显示数值型变量的分布和离散程度,可以观察数据的中位数、四分位数、异常值等,帮助发现数据的集中趋势和离散程度。
- 点图(Dot Plot):适用于显示分类变量的分布情况,可以观察不同类别之间的差异,特别是在数据点较少的情况下,点图可以更直观地展示数据的分布情况。
三、数据预处理
1.数据清洗
处理缺失值、异常值和重复值等数据质量问题,确保数据的完整性和准确性。
步骤1:处理缺失值
方法1:删除
样本量很大或缺失值较少时,可以采用删除缺失值的方法。
> mydata <- data.frame(col1 = c(1,2,NA,4,5),
+ col2 = c("a",NA,NA,"d","e"),
+ col3 = c(TRUE,FALSE,FALSE,TRUE,TRUE))
> newdata <- na.omit(mydata)
> newdata
col1 col2 col3
1 1 a TRUE
4 4 d TRUE
5 5 e TRUE
> newdata <- mydata[complete.cases(mydata), ]
> newdata
col1 col2 col3
1 1 a TRUE
4 4 d TRUE
5 5 e TRUE
方法2:填补
数值型数据:用当前样本的均值来填补。
> mydata1 <- mydata[complete.cases(mydata$col1), ]#取出第1列所有的非缺失值
> mydata2 <- mydata[!complete.cases(mydata$col1), ]#取出第1列所有的缺失值
> aver_col1 <- mean(mydata1$col1)#计算第1列非缺失值的均值
> mydata2$col1 <- rep(aver_col1, nrow(mydata2))#把均值填到缺失值的位置上,重复次数就是缺失值的个数
> mydata_filled <- rbind(mydata1, mydata2)#把填充好的两部分重新合在一起(位置改变)
> mydata_filled
col1 col2 col3
1 1 a TRUE
2 2 <NA> FALSE
4 4 d TRUE
5 5 e TRUE
3 3 <NA> FALSE
非数值型数据:用当前样本的众数填补。(自己定义一个众数函数)
> mode_function <- function(x) {
+ unique_x <- unique(x)#获取唯一值(重复的只留一个)
+ unique_x[which.max(tabulate(match(x, unique_x)))]
+ #match函数用于在一个向量中查找另一个向量的元素,并返回第一个向量中每个元素在第二个向量中的位置,这里表示返回原始数组对应的每个唯一值的位置
+ #tabulate函数用于统计整数向量中各个整数出现的次数,并返回一个与整数向量长度相同的向量,其中每个元素表示对应整数在原始向量中出现的次数。
+ #which.max函数用于找出向量或数组中的最大值所在的位置(索引)
+ }
> mode_column3 <- mode_function(mydata$col3)
> mode_column3
[1] TRUE
方法3:回归插补
lm 函数用于拟合线性模型。其基本用法是将待拟合的模型表示为一个公式,然后将该公式作为参数传递给 lm 函数,同时指定数据集。
x <- c(1, 2, 3, 4, 5)
y <- c(2, 3, 4, 5, 6)
my_data <- data.frame(x, y)
# 拟合简单线性回归模型
model <- lm(y ~ x, data = my_data)
# 查看模型摘要
summary(model)
方法4:多重插补
用mice包实现,步骤:
library(mice)
imp <- mice(data, m)#data是包含缺失值的矩阵或数据框,m表示被插补的数据集个数,即用m种方式进行插补
fit <- with(imp, analysis)#对每个数据集应用模型analysis
pooled <- pool(fit)#把m个统计结果合在一起
summary(pooled)
步骤2:处理异常值
• 删除异常值
• 将异常值视为缺失值
• 使用均值修正异常值
• 保留异常值
2.数据集成
将来自不同数据源的数据整合到一个统一的数据集中,以便进行分析和建模。
方法1:rbind或cbind函数(要求数据有某一致性)
rbind(dataframeA, dataframeB): join two datasets vertically
cbind(dataframeA, dataframeB): join two datasets horizontally
方法2:merge函数
merge(dataframeA, dataframeB, by=“keywords")
3.数据转换
对数据进行变换,如对数变换、标准化、归一化等,以改善数据的分布特性和降低数据之间的相关性,使建模更容易。
对数据的变换取决于计划使用的建模方法。
使用数学函数进行简单变换
当模型不满足正态性、线性或同方差性这些假设时,对一个或多个变量进行转换往往能够改善或纠正这种情况。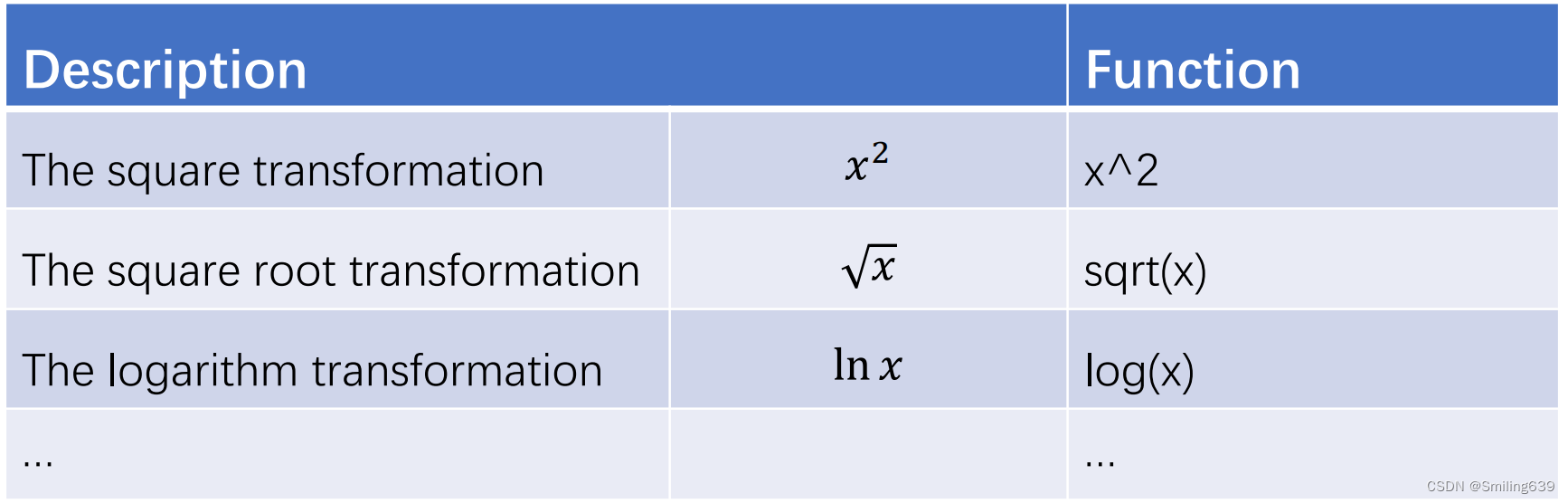
归一化和标准化
归一化常用于量纲不一致的情况(每个变量的范围相差很大,通过归一化使它们都在[0,1]中),称为最小最大归一化:
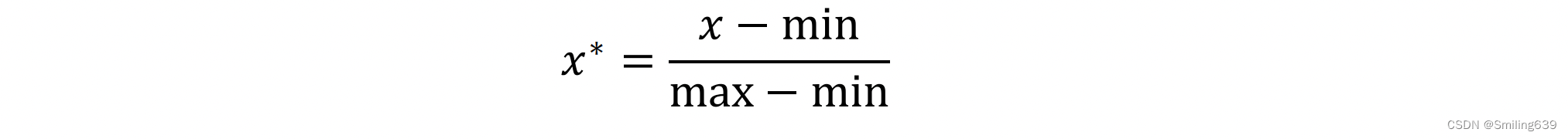
标准化:
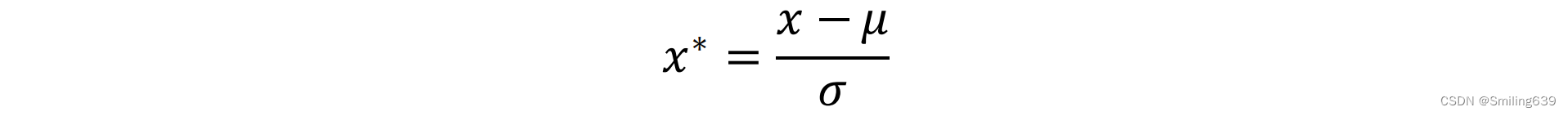
四、抽样
抽样是在分析和建模过程中,选择总体的一个子集来代表整个总体的过程。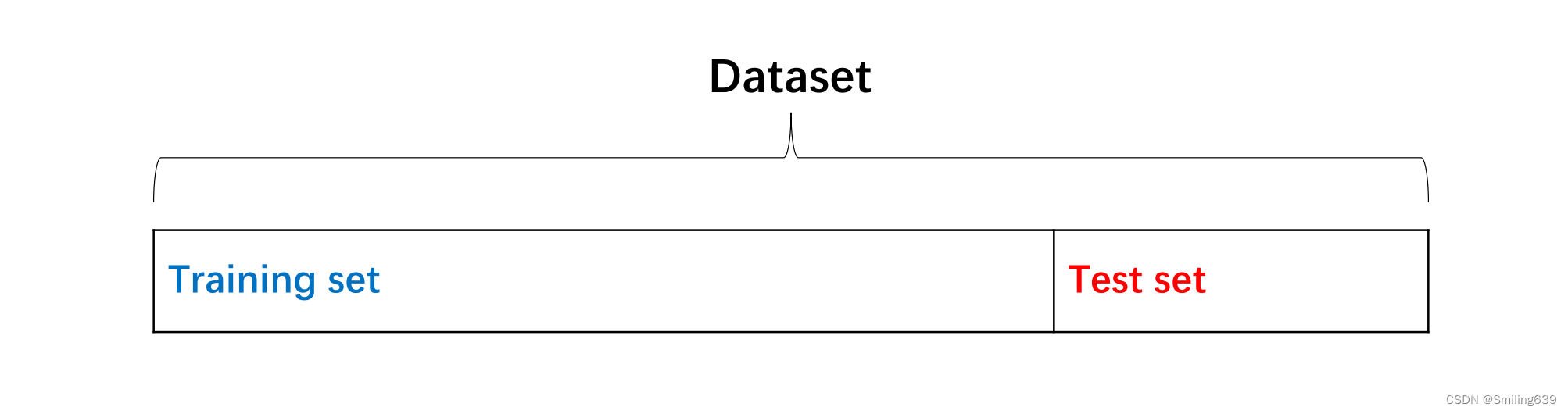
• 训练集是提供给模型构建算法的数据,以便算法能够设置正确的参数,最好地预测结果变量。
• 测试集是输入到最终模型中的数据,用于验证模型的预测是否准确。
注意:不能只划分一次训练集和测试集,而是多次划分,求平均值(增加稳定性)!
抽样方法1
id <- sample(1:nrow(data), round(0.2*nrow(data)), replace=FALSE)
testSet <- data[id,]
trainingSet <- data[-id,]
从1到总行数的范围内,随机且不重复地抽取数据集大约20%的行数的行编号;
根据抽取行号,从原始数据集data中选取对应行,构成测试集;
通过从原始数据集data中排除已经被选入测试集的行(即-id),创建剩余的数据作为训练集。
抽样方法2(这种更便于debug)
data$gp <- runif(nrow(data))
testSet <- subset(data, data$gp <= 0.2)
trainingSet <- subset(data, data$gp > 0.2)
为数据框data中的每一行添加了一个新的列gp,该列的每个值都是从均匀分布[0,1)中随机抽取的,从而每一行都有一个0~1上的随机数;
之后使用subset函数,从data中选择那些gp值小于等于0.2的行作为测试集。因为gp值是随机生成的,这样可以随机选择大约20%的数据作为测试集;
最后同样使用subset函数,但这次选择的是gp列值大于0.2的行,作为训练集。这会包含剩下的大约80%的数据行。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









