







文章目录
数据特征
包括:一个因变量Y,p个自变量X1,……,Xp,未知参数,误差项
通过一组自变量(独立变量)X1,……,Xp来预测或解释一个因变量(依赖变量)Y的值。
一、简单线性回归模型
1.定义
对于因变量Y和自变量 X,简单线性回归模型表示为:Y=β0+β1*X+ε
其中,ε是误差项。
对于样本数据(X1,Y1),(X2,Y2),……,(Xn,Yn)
我们假设每个样本点满足:
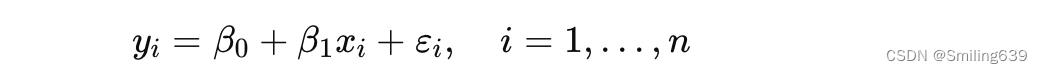 其中,误差项εi(i=1,……,n)服从独立同分布的正态分布 N(0,σ^2)
其中,误差项εi(i=1,……,n)服从独立同分布的正态分布 N(0,σ^2)
通过对模型参数β0和β1进行估计,我们得到估计值 :

2.最小二乘法
残差:残差表示实际观测值与模型预测值之间的差异。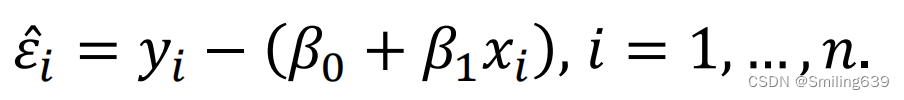
最小二乘法:目的是通过最小化残差的平方和来找到最佳拟合的回归直线。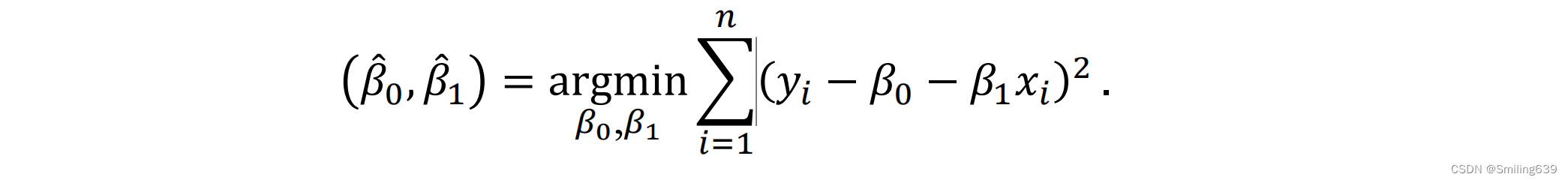
最小二乘估计:β0和β1分别是截距和斜率的估计值,通过它们可以建立回归方程,用来预测因变量的值。
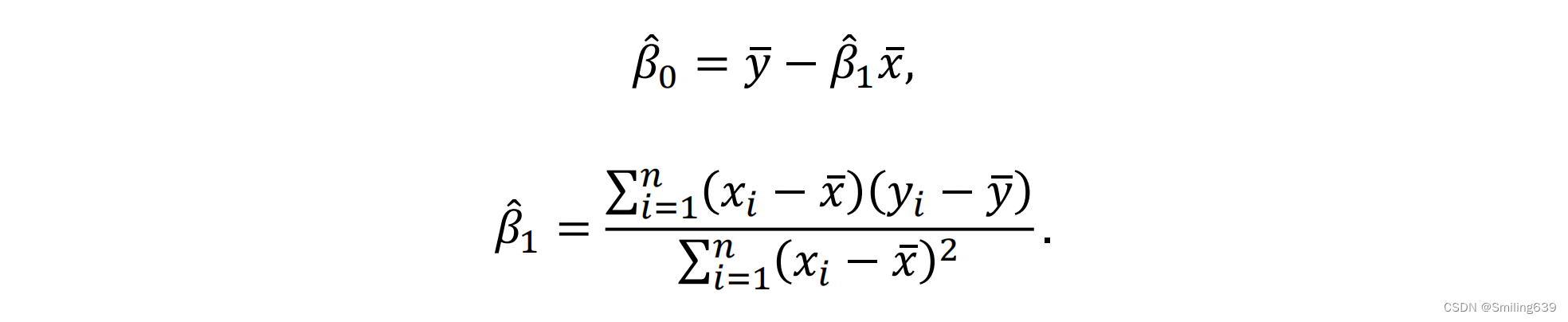
3. lm函数实现
在R语言中,用于拟合线性模型的基本函数是 lm()。其格式如下:
myfit <- lm(formula, data)
- formula 描述了要拟合的模型,通常写作 Y ~ X1 + X2 + … + Xk,其中 ~ 将左边的因变量与右边的自变量分隔开,并且自变量之间用 + 号分隔。
- data 是包含用于拟合模型的数据的数据框。
> mtcars2 <- mtcars[c("mpg", "wt")]
> fit<- lm(mpg~wt,data = mtcars2)
> class(fit)
[1] "lm"
fit的类型是lm(线性模型)对象。
> names(fit)
[1] "coefficients" "residuals" "effects" "rank" "fitted.values" "assign"
[7] "qr" "df.residual" "xlevels" "call" "terms" "model"
输出fit对象的所有组件
> summary(fit)
Call:
lm(formula = mpg ~ wt, data = mtcars2)
Residuals:
Min 1Q Median 3Q Max
-4.5432 -2.3647 -0.1252 1.4096 6.8727
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 37.2851 1.8776 19.858 < 2e-16 ***
wt -5.3445 0.5591 -9.559 1.29e-10 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.046 on 30 degrees of freedom
Multiple R-squared: 0.7528, Adjusted R-squared: 0.7446
F-statistic: 91.38 on 1 and 30 DF, p-value: 1.294e-10
输出fit摘要信息,包括:
- Call: 显示拟合模型的公式。
- Residuals: 提供残差的五数摘要(最小值、第一四分位数、中位数、第三四分位数、最大值)。
- Coefficients: 显示回归系数(截距和斜率)、标准误差、t值及其对应的p值。
- (Intercept): 截距(37.2851),表示当 wt 为零时,mpg 的估计值。
- wt: 斜率(-5.3445),表示 wt 每增加一个单位,mpg 预计减少5.3445个单位。
- Pr(>|t|): p值,表示系数显著性的统计测试结果。这里两者都非常显著(p值远小于0.05)。
- Residual standard error: 残差标准误差,表示回归模型未解释的变异量。
- Multiple R-squared: 多重R平方,表示自变量解释的因变量变异的百分比(75.28%)。
- Adjusted R-squared: 调整后的R平方,调整了自变量数量的影响(74.46%)。
- F-statistic: F统计量及其p值,测试整体模型的显著性。这里F统计量为91.38,p值为1.294e-10,表明模型显著。
> coef(fit)
(Intercept) wt
37.285126 -5.344472
提取回归系数,截距为37.285126,斜率为-5.344472。
plot(mpg ~ wt, data=mtcars2, pch=20, col=4)
abline(lm(mpg ~ wt, data=mtcars2), lty=1, col=2)
legend("topright", c("Real Points","Fitting"), cex=0.75,
pch=c(20,NA), lty=c(NA,1), col=c(4,2))
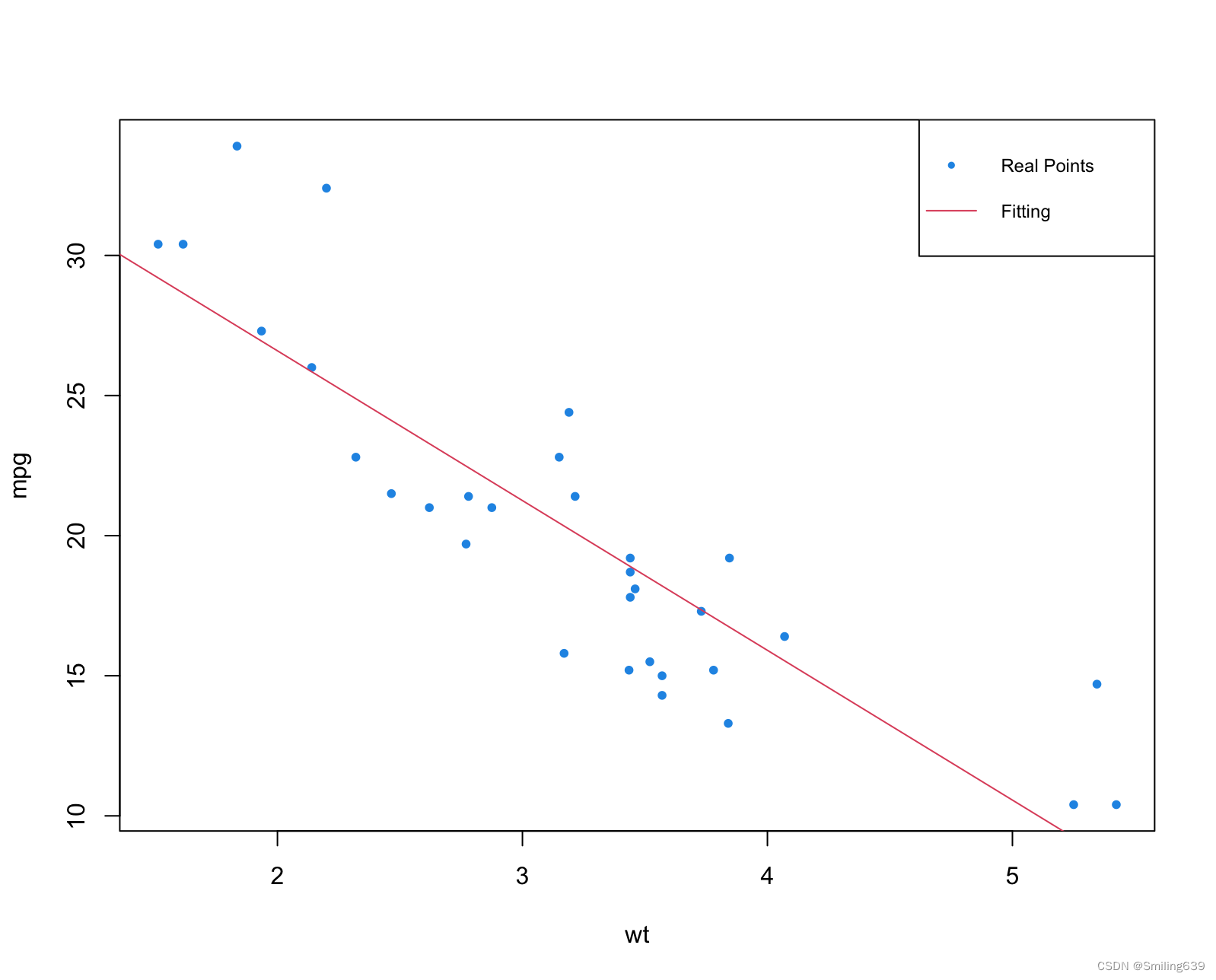
模型表明 wt(重量)对 mpg(每加仑行驶英里数)有显著的负向影响,模型整体拟合良好。
二. 多项式回归
1.定义
与简单线性回归不同,多项式回归使用一个或多个自变量的多项式来拟合数据。基本思想是在原始数据点之间拟合一条多项式曲线,以便更好地捕捉数据中的趋势和模式。
对于一个自变量x和因变量 y,多项式回归模型可以表示为: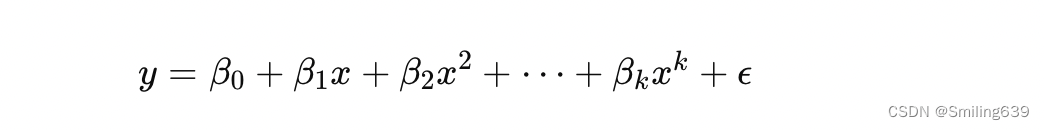
2.lm函数实现
fit2 <- lm(mpg ~ wt + I(wt^2), data=mtcars2)
mpg ~ wt + I(wt^2) 表示我们要拟合的模型,其中 mpg 是因变量,wt 和 wt^2 是自变量。I(wt^2) 表示 wt 的平方项。(I() 函数用于告诉 R 解释器将括号内的表达式作为普通的数学表达式来处理,而不是将其视为公式中的符号操作。)
# 载入数据
mtcars2 <- mtcars[c("mpg", "wt")]
# 拟合多项式回归模型
fit2 <- lm(mpg ~ wt + I(wt^2), data = mtcars2)
# 查看模型摘要
summary(fit2)
运行 summary(fit2) 后,我们可以看到模型的详细信息,包括回归系数、标准误差、R平方等。
Call:
lm(formula = mpg ~ wt + I(wt^2), data = mtcars2)
Residuals:
Min 1Q Median 3Q Max
-3.9410 -1.6001 -0.6335 1.4560 5.3371
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 49.9308 4.8512 10.292 1.78e-10 ***
wt -13.3803 2.9399 -4.552 9.12e-05 ***
I(wt^2) 1.1711 0.3944 2.971 0.00668 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.508 on 29 degrees of freedom
Multiple R-squared: 0.8194, Adjusted R-squared: 0.805
F-statistic: 56.67 on 2 and 29 DF, p-value: 3.026e-11
通过拟合一个包含平方项的多项式回归模型,我们能够捕捉到 mpg 和 wt 之间的非线性关系。wt 和 wt^2 的回归系数显著,说明它们对 mpg 有重要影响。模型的R平方值较高,表明拟合效果较好。
三、多元线性回归
1.定义
多元线性回归(Multiple Linear Regression)是通过多个自变量(独立变量)来预测一个因变量(响应变量)的值。其模型形式是多个自变量的线性组合。与简单线性回归相比,多元线性回归能够处理更复杂的关系,因为它考虑了多个因素对因变量的共同影响。
多元线性回归模型的数学表达式如下: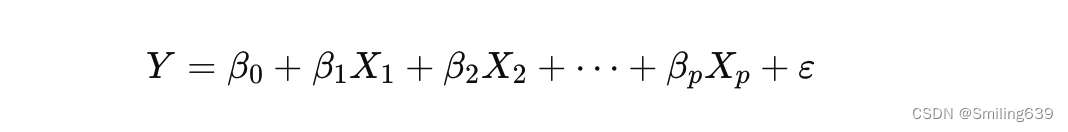
多元线性回归的假设
- 线性关系:因变量与自变量之间存在线性关系。
- 独立性:观测值之间相互独立。
- 同方差性:误差项具有恒定的方差(不随自变量的变化而变化)。
- 正态性:误差项服从正态分布。
- 无多重共线性:自变量之间不存在完全的线性关系。
2.lm函数实现
函数的基本格式如下:
fit <- lm(Y ~ X1 + X2 + ... + Xp, data = dataset)
示例:
# 加载数据集
data(mtcars)
# 拟合多元线性回归模型
fit <- lm(mpg ~ wt + hp + qsec, data = mtcars)
# 查看模型摘要
summary(fit)
运行summary(fit)后得到结果:
Call:
lm(formula = mpg ~ wt + hp + qsec, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-3.5084 -1.6797 -0.5779 1.4149 5.2807
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 19.3440 9.6121 2.012 0.053387 .
wt -5.3445 0.9268 -5.766 3.25e-06 ***
hp -0.0184 0.0147 -1.252 0.222147
qsec 0.9315 0.2657 3.507 0.001971 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.538 on 28 degrees of freedom
Multiple R-squared: 0.8497, Adjusted R-squared: 0.8336
F-statistic: 52.98 on 3 and 28 DF, p-value: 5.419e-12
系数估计值:Estimate 列给出了截距和每个自变量的系数估计值。
四、比较不同回归模型效果
# 加载数据集
data(mtcars)
mtcars2 <- mtcars[c("mpg", "wt")]
# 简单线性回归
fit_lm <- lm(mpg ~ wt, data = mtcars2)
# 多项式回归 (k = 2)
fit_poly2 <- lm(mpg ~ poly(wt, 2, raw=TRUE), data = mtcars2)
# 多项式回归 (k = 3)
fit_poly3 <- lm(mpg ~ poly(wt, 3, raw=TRUE), data = mtcars2)
#分析拟合效果
summary(fit_lm)
summary(fit_poly2)
summary(fit_poly3)
# 创建数据框,用于绘图
new_data <- data.frame(wt = seq(min(mtcars2$wt), max(mtcars2$wt), length.out = 100))
# 预测值
new_data$mpg_lm <- predict(fit_lm, newdata = new_data)
new_data$mpg_poly2 <- predict(fit_poly2, newdata = new_data)
new_data$mpg_poly3 <- predict(fit_poly3, newdata = new_data)
# 绘图
plot(mtcars2$wt, mtcars2$mpg, main = "Regression Models Comparison",
xlab = "Weight (wt)", ylab = "Miles per Gallon (mpg)",
pch = 19, col = "blue")
# 绘制拟合曲线
lines(new_data$wt, new_data$mpg_lm, col = "red", lwd = 2, lty = 1) # 简单线性回归
lines(new_data$wt, new_data$mpg_poly2, col = "green", lwd = 2, lty = 2) # 多项式回归 (k=2)
lines(new_data$wt, new_data$mpg_poly3, col = "purple", lwd = 2, lty = 3) # 多项式回归 (k=3)
# 添加图例
legend("topright", legend = c("Linear Regression", "Polynomial Regression (k=2)", "Polynomial Regression (k=3)"),
col = c("red", "green", "purple"), lwd = 2, lty = 1:3)
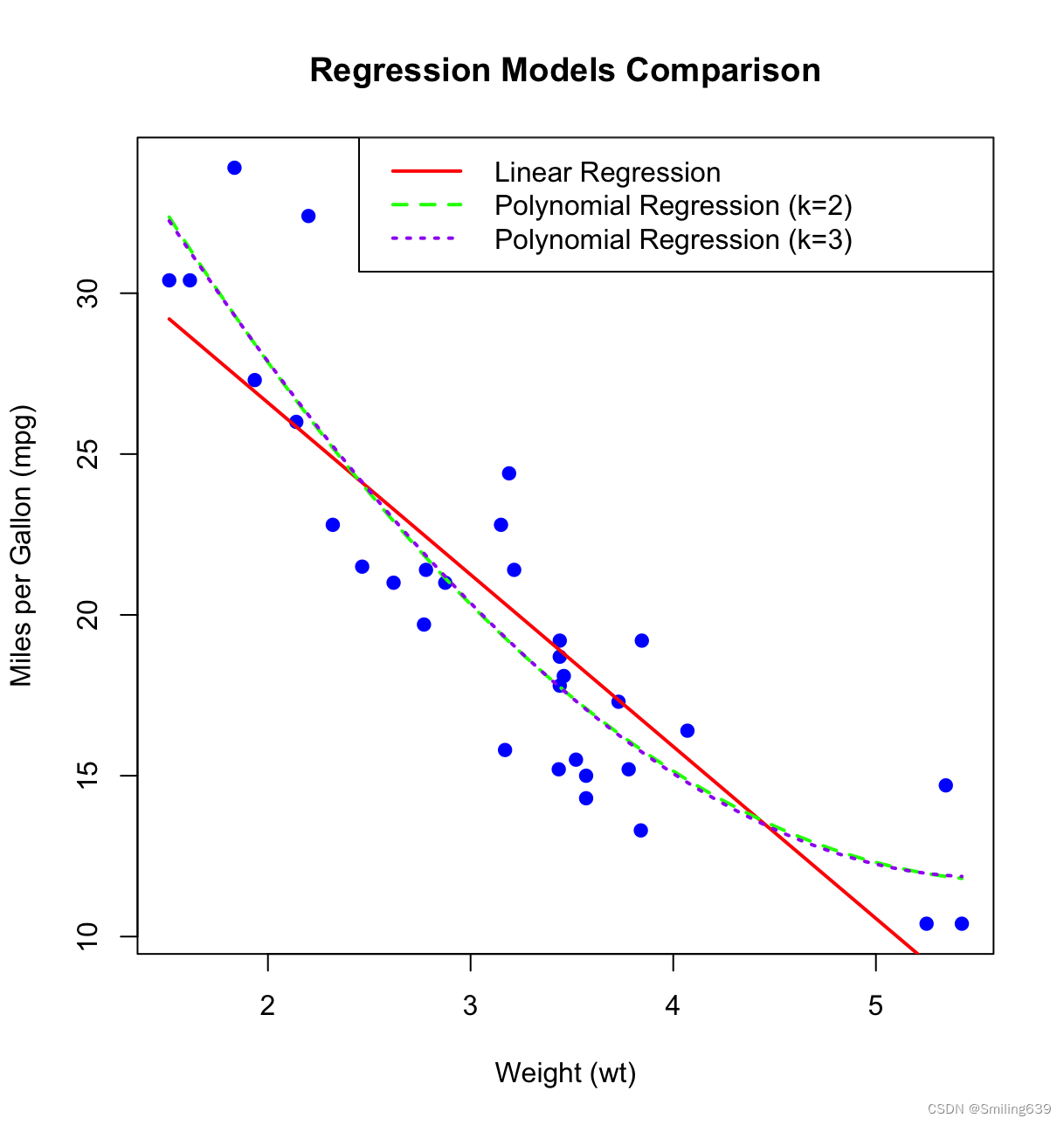
通过绘制的图形,可以直观地看到不同模型的拟合效果。简单线性回归(红色)提供了最基本的线性关系,可能无法捕捉到数据的非线性趋势。多项式回归(绿色和紫色)随着多项式阶数的增加,可以更好地拟合数据的非线性关系,但也有过拟合的风险。选择最适合的数据模型需要在拟合效果和模型复杂性之间取得平衡。
summary的结果:
> summary(fit_lm)
Call:
lm(formula = mpg ~ wt, data = mtcars2)
Residuals:
Min 1Q Median 3Q Max
-4.5432 -2.3647 -0.1252 1.4096 6.8727
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 37.2851 1.8776 19.858 < 2e-16 ***
wt -5.3445 0.5591 -9.559 1.29e-10 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.046 on 30 degrees of freedom
Multiple R-squared: 0.7528, Adjusted R-squared: 0.7446
F-statistic: 91.38 on 1 and 30 DF, p-value: 1.294e-10
> summary(fit_poly2)
Call:
lm(formula = mpg ~ poly(wt, 2, raw = TRUE), data = mtcars2)
Residuals:
Min 1Q Median 3Q Max
-3.483 -1.998 -0.773 1.462 6.238
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 49.9308 4.2113 11.856 1.21e-12 ***
poly(wt, 2, raw = TRUE)1 -13.3803 2.5140 -5.322 1.04e-05 ***
poly(wt, 2, raw = TRUE)2 1.1711 0.3594 3.258 0.00286 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.651 on 29 degrees of freedom
Multiple R-squared: 0.8191, Adjusted R-squared: 0.8066
F-statistic: 65.64 on 2 and 29 DF, p-value: 1.715e-11
> summary(fit_poly3)
Call:
lm(formula = mpg ~ poly(wt, 3, raw = TRUE), data = mtcars2)
Residuals:
Min 1Q Median 3Q Max
-3.506 -1.999 -0.768 1.490 6.188
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 48.40370 15.58379 3.106 0.00431 **
poly(wt, 3, raw = TRUE)1 -11.82598 15.46346 -0.765 0.45081
poly(wt, 3, raw = TRUE)2 0.68938 4.74034 0.145 0.88541
poly(wt, 3, raw = TRUE)3 0.04594 0.45070 0.102 0.91954
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.697 on 28 degrees of freedom
Multiple R-squared: 0.8191, Adjusted R-squared: 0.7997
F-statistic: 42.27 on 3 and 28 DF, p-value: 1.585e-10
1.测试误差
假设我们拥有一组训练数据,包括因变量Y和自变量X1……Xn,那么我们可以计算出回归系数的估计值𝛽0,𝛽1, … ,𝛽n 。
对于给定的新观测值𝑋1*, … , 𝑋p*,我们可以利用这些估计的回归系数来预测对应的响应变量 𝑌*,预测公式为:𝑌*= ̂𝛽0 +𝛽1𝑋1*+……+𝛽𝑝𝑋𝑝*
测试误差被定义为Y-Y*的平方的期望值,即: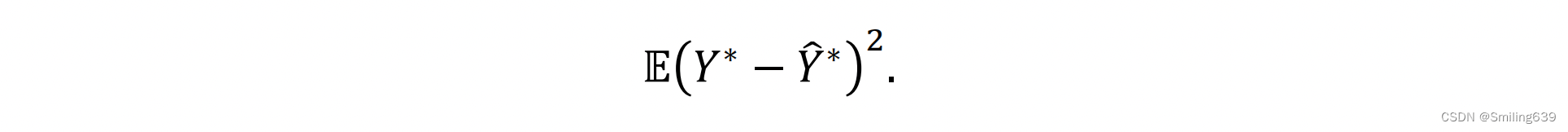
2.交叉验证
在基本的交叉验证过程中,数据集被分为两部分:一部分作为训练集(training sample),用于构建模型;另一部分作为验证集或保留集(hold-out sample),用于评估模型的性能。通过这种方式,可以测试模型在未参与训练的数据上的泛化能力。
2.1 K折交叉验证
K折交叉验证(k-fold Cross-validation) 是交叉验证的一种变体,它将数据集均匀地分成k个子集(或“折”)。每一轮验证中,其中一个子集被作为验证集(即hold-out group),其余k-1个子集合并起来作为训练集。这个过程重复k次,每次选择不同的子集作为验证集,确保所有数据点都被用作一次验证。模型会在k次迭代中分别训练和验证,得到k组性能指标(如预测误差),最后这些性能指标会被平均,以此作为模型整体性能的估计。
在R语言中,使用bootstrap包里的crossval()函数可以进行交叉验证。
crossval(x, y, theta.fit, theta.predict, ..., ngroup=n)
x: 一个矩阵,包含预测变量(自变量)的值。每一行对应一个观测样本。
y: 一个向量,包含响应变量(因变量)的值。
theta.fit: 需要进行交叉验证的函数。该函数接受x和y作为参数。
theta.predict: 根据theta.fit产生的预测值函数。其参数为一个预测变量矩阵x,以及theta.fit产生的拟合对象。
…: 需要传递给theta.fit的额外参数。
ngroup: 可选参数,用于指定形成的组数。默认值为样本大小,即对应于留一交叉验证(leave-one-out cross-validation)。
例:
library(bootstrap)
x <- rnorm(80)
y <- 2*x +.5*rnorm(80)
theta.fit <- function(x,y){lsfit(x,y)}
theta.predict <- function(fit,x){cbind(1,x)%*%fit$coef}
results <- crossval(x, y, theta.fit, theta.predict, ngroup=5)
这段R代码演示了如何使用bootstrap包中的crossval()函数对一个简单线性回归模型进行5折交叉验证。下面是代码的详细解释:
-
生成模拟数据:
x <- rnorm(80) y <- 2*x + .5*rnorm(80)这里生成了模拟数据。
x是一个包含80个正态分布随机数的向量,代表自变量或预测变量。y则是基于线性关系y = 2x + 0.5*N(0,1)生成的响应变量,其中.5*rnorm(80)引入了随机噪声,模拟真实世界数据中的误差。 -
定义拟合函数 (
theta.fit):theta.fit <- function(x,y){lsfit(x,y)}theta.fit函数使用R的lsfit()函数来拟合一个线性模型到给定的x和y数据上。lsfit()执行最小二乘法回归,返回模型的参数估计。 -
定义预测函数 (
theta.predict):theta.predict <- function(fit,x){cbind(1,x)%*%fit$coef}这个函数根据之前拟合的模型(
fit)和新的预测数据x来产生预测值。它首先构造一个设计矩阵(通过cbind(1,x)添加截距项),然后用该设计矩阵乘以模型的系数(fit$coef)来计算预测值。 -
执行交叉验证:
results <- crossval(x, y, theta.fit, theta.predict, ngroup=5)最后,使用
crossval()函数执行5折交叉验证。它将数据集分割成5个子集,轮流将每个子集作为验证集,其余子集合并作为训练集,进行模型拟合和预测。x和y分别是自变量和因变量,theta.fit和theta.predict是之前定义的拟合和预测函数,ngroup=5指定了交叉验证的折数。
results变量将包含每次交叉验证循环中的预测结果:
$cv.fit
[1] 0.262072038 0.889517362 4.108081779 -5.955577522 -2.077708891 2.156974057 -1.095580762
[8] -3.400503478 2.099222561 -0.811836401 0.202694635 -1.426527616 -3.450822395 -1.486316855
[15] -1.925302391 0.120290624 -1.467026949 -3.653666502 1.271503400 -2.058324463 4.997845050
[22] -1.126920199 -1.960043791 0.638953523 1.766701854 0.619079984 0.543926177 -0.692497328
[29] 2.953659432 1.511629113 -2.013152405 0.621806481 0.556036367 3.135968121 2.041546965
[36] -1.611361556 3.828866532 -0.210724185 -0.398807788 0.847442991 -1.580852219 1.980815285
[43] -1.364560906 -0.622611107 1.551170193 -1.234075254 -0.481716081 -0.964445161 4.246274778
[50] -4.117030194 -2.358979926 2.944778069 -1.602770943 0.763311637 0.971807317 -0.584378693
[57] -1.074348253 0.970909699 -2.714220111 0.355973462 0.075013281 0.372225634 0.258389196
[64] -2.892958946 0.843656597 -2.544784756 1.197965104 -1.323694804 -0.851259252 0.001497762
[71] -1.726032056 0.750911706 0.307093437 0.074809179 -0.355324819 0.181239613 -1.549124486
[78] -4.001835230 2.518808506 -2.630376649
$ngroup
[1] 5
$leave.out
[1] 16
$groups
$groups[[1]]
[1] 49 55 40 21 79 56 7 19 33 27 11 57 9 34 36 41
$groups[[2]]
[1] 77 66 72 39 23 15 3 70 20 18 17 44 42 78 68 51
$groups[[3]]
[1] 67 75 24 28 22 54 37 5 16 48 50 45 8 43 46 61
$groups[[4]]
[1] 14 38 60 53 64 59 58 29 35 71 62 52 2 63 4 74
$groups[[5]]
[1] 30 6 26 13 32 80 73 65 1 10 69 47 31 25 76 12
$call
crossval(x = x, y = y, theta.fit = theta.fit, theta.predict = theta.predict,
ngroup = 5)
当k等于数据集中的样本总数n时,这种特殊的交叉验证称为留一交叉验证(Leave-One-Out Cross-validation, LOOCV)。在这种情况下,每次迭代只留下一个样本作为验证集,其余所有样本作为训练集。虽然LOOCV提供了最大程度的数据利用(每个样本都作为验证集被单独评估一次),但由于每次训练集几乎都包含了全部数据,这可能导致计算成本较高,特别是在大数据集上。同时,LOOCV有时可能对噪声敏感,因为模型在每次迭代中都是基于几乎相同的数据训练的,只是缺少一个样本。
五、矫正措施
若回归效果不佳,则需要采取矫正措施,包括以下几种方法:
- 删除观测值(针对异常值或有影响力的观测)
- 变量转换
- 增加或删除变量
- 采用另一种回归方法

















 368
368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









