






 文章讲述了在Linux系统中使用HuggingFaceEmbeddings时遇到的连接超时错误,以及如何通过设置cache_folder、使用HF_ENDPOINT镜像和下载模型文件来解决不同网络环境下的模型加载问题。
文章讲述了在Linux系统中使用HuggingFaceEmbeddings时遇到的连接超时错误,以及如何通过设置cache_folder、使用HF_ENDPOINT镜像和下载模型文件来解决不同网络环境下的模型加载问题。
部分报错:
TimeoutError: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。
urllib3.exceptions.ConnectTimeoutError: (<urllib3.connection.HTTPSConnection object at
0x0000020872CE6DA0>, 'Connection to huggingface.co timed out. (connect timeout=None)')
urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /api/models/BAAI/bge-large-zh-v1.5/revision/main (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x0000020872CE6DA0>, 'Connection to huggingface.co timed out. (connect timeout=None)'))
huggingface_hub.utils._errors.LocalEntryNotFoundError: Cannot find an appropriate cached snapshot folder for the specified revision on the local disk and outgoing traffic has been disabled. To enable repo look-ups and downloads online, pass 'local_files_only=False' as input.
问题的可能原因:
Linux系统中在使用HuggingFaceEmbeddings或相近函数时会从huggingface下载embedding模型的部分文件(非模型文件),默认会保存在cache目录下,文件结构如图所示(以BAAI/bge-large-zh-v1.5为例)。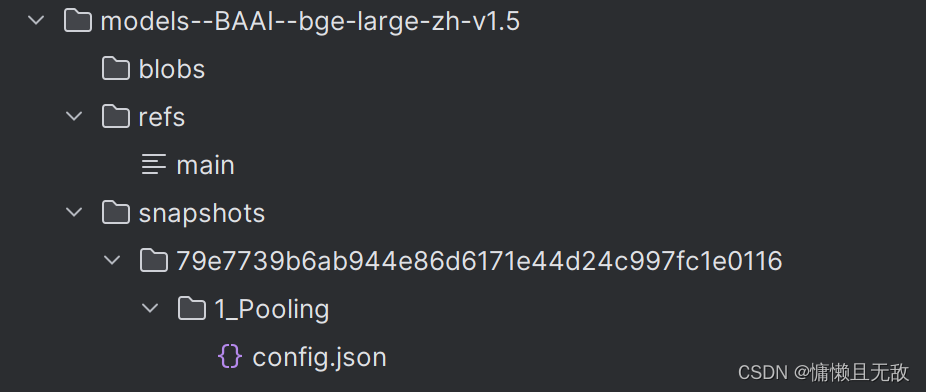
未成功下载以上文件时,无法调用本地embdding模型。我们可用通过在HuggingFaceEmbeddings函数中增加cache_folder='./',使上面名为models--BAAI-bge-large-zh-v1.5文件下载到运行的代码所在目录。
embedding = HuggingFaceEmbeddings(
model_name=model_name,
cache_folder='./',
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
)若未成功下载,可在命令行输入以下内容或者挂梯子后,再次运行上面调用embedding模型的代码。
export HF_ENDPOINT="https://hf-mirror.com"
内容演示:
1.在有本地embedding模型BAAI/bge-large-zh-v1.5与models--BAAI-bge-large-zh-v1.5文件,且断网情况下成功使用embedding模型构建向量数据库: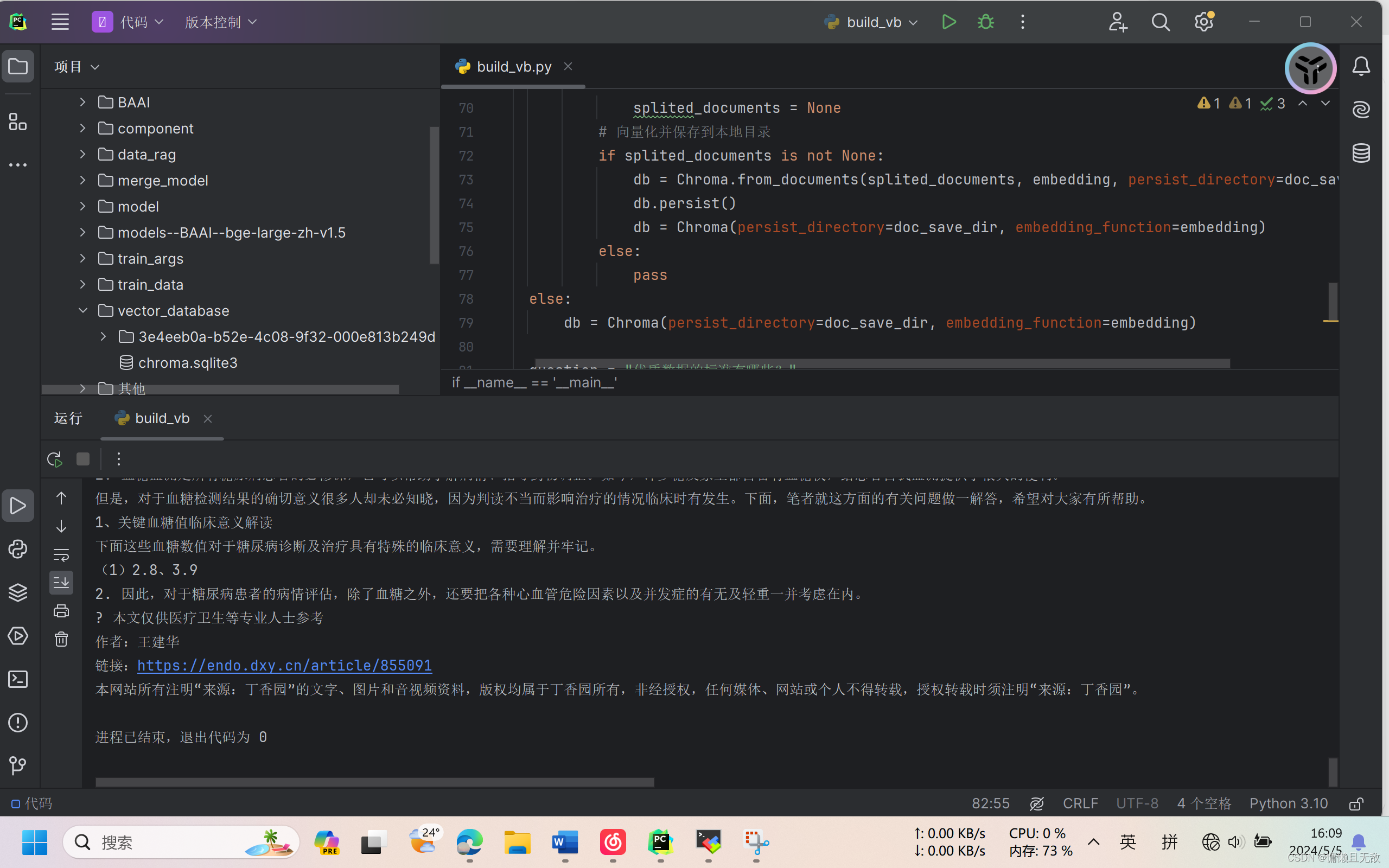
2.在有本地embedding模型BAAI/bge-large-zh-v1.5,但没有models--BAAI-bge-large-zh-v1.5文件,且断网的情况下构建失败:
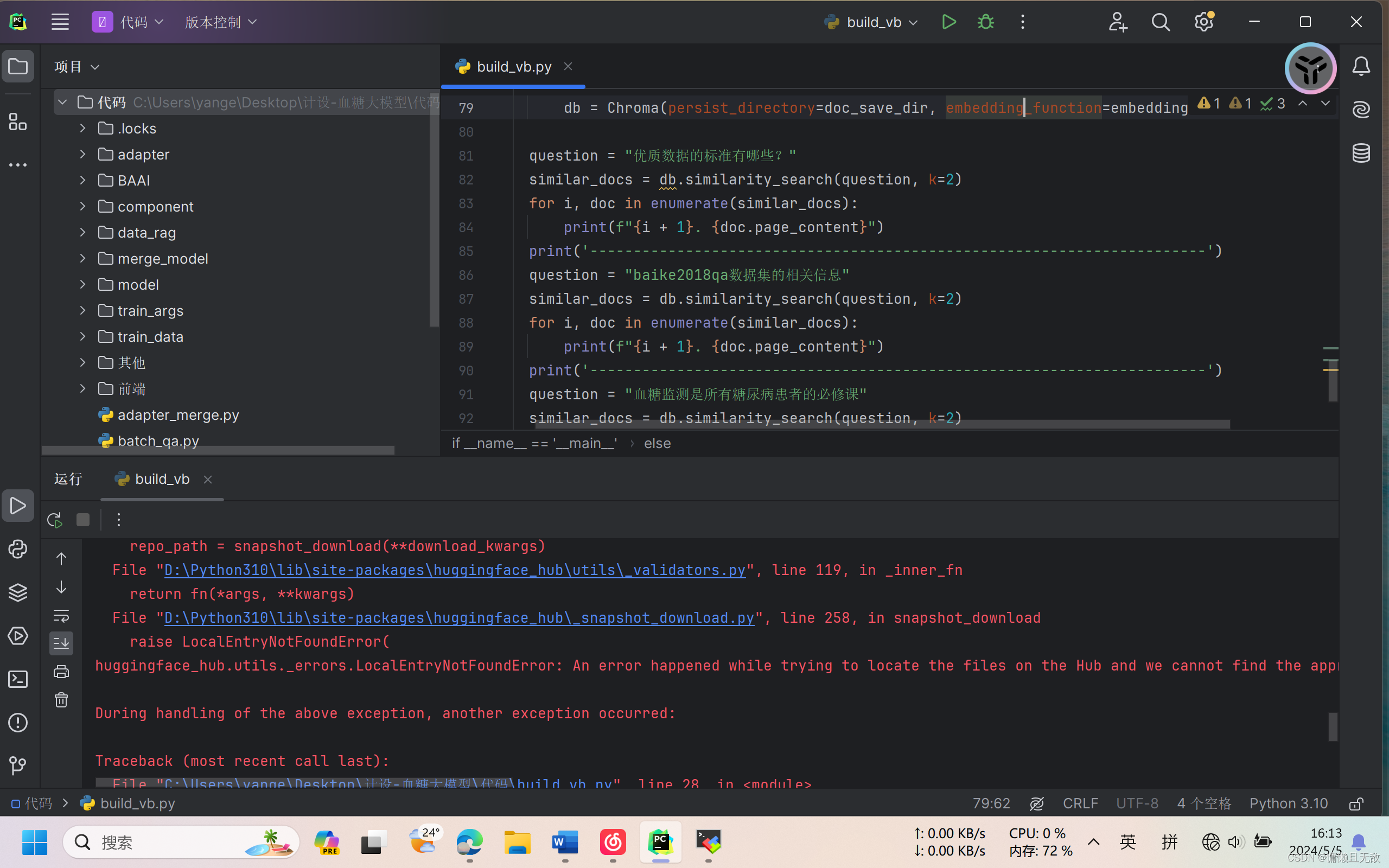
3.在有本地embedding模型BAAI/bge-large-zh-v1.5,没有models--BAAI-bge-large-zh-v1.5文件,但联网(未挂梯子)的情况下构建失败:
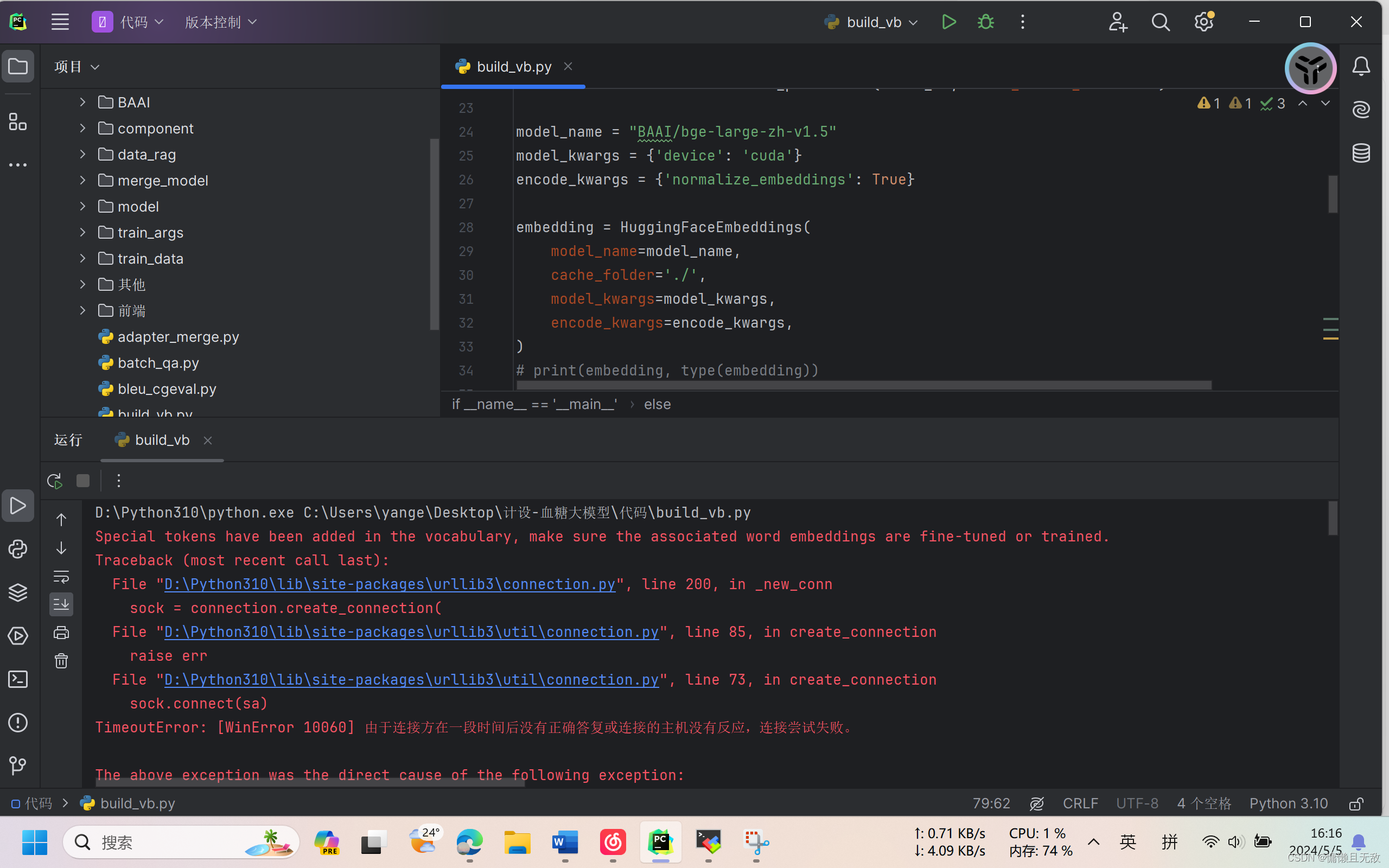
4.在有本地embedding模型BAAI/bge-large-zh-v1.5,没有models--BAAI-bge-large-zh-v1.5文件,但联网(已挂梯子)的情况下构建成功,并把models--BAAI-bge-large-zh-v1.5文件下载到cache_folder指定目录:















 3155
3155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









