







前言
这篇关于ViT的paper有不少术语:AN IMAGE IS WORTH 16X16 WORDS:
尤其是对于第一次阅读paper的人来说,确实困难。为此我整理了一下paper里出现的主要术语以及的对应的概念解释。
基础术语
saturating performance
性能在达到某一点后,不再显著提升。
tokens
处理和分析字词的基本单位。
downstream tasks
模型经过预训练之后的任务,如微调或者迁移学习。
fine-tune
模型在经过大规模的数据预训练后,再进一步在特定的小数据集上进行进一步训练。
self-supervision
自监督训练————模型通过数据本身生成标签,而不是依赖人工标注的标签。
validation accuracy
用测量训练过程中,评估各个阶段的性能,从而有助于调整超参数。
few shot learning
使用少量数据进行训练。
weight decay
一种正则化技术,用于防止模型过拟合。具体地,这使得模型会更容易去学习小的权重参数,而去学习较大的权重参数时会受到"惩罚"。
dropout
一种正则化技术,用于防止模型过拟合。具体指在训练过程中随机丢掉一些神经元。
label smoothing
一种正则化技术,也是用于防止过拟合。
把1换成小一点的值,把0换成大一点的值,目的是不要让模型太"自信"。
early stopping
一种正则化技术,防止过拟合。实时跟踪模型在验证集的性能,当发现性能开始恶化时提前停止训练。
ViT相关
embeddings
嵌入是一个向量,它可以看作是图像的数字表现形式。重要的是,这个向量是可学习的,可优化的。
patch embeddings
patch embeddings 是一个过程: 将图像拆分为多个块,然后把这些块排列成一个向量,对于每一个块,都通过线性映射到高维空间。
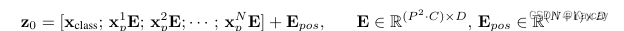
class embedding
类别嵌入用于学习整个图像的特征,从而实现图像分类。
postition embeddings
由于图片被分割成了patch 序列,position embedding可以学习各个patch在原始图像的位置信息。
embedding dimension
图片被分成patch,每个patch可以用一个向量表示,这个向量的长度就是embedding dimension。
Residual connections
也叫做skip connection,如果神经网络很深,反向传播过程中会出现梯度爆炸或梯度消失的情况。使用了残差连接,可以让保留输入的原始信息,同时由于单位矩阵的加入,使得梯度在传播中不会无限放大或者消失。
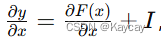
Encoder
多个(Norm+MSA+残差连接+Norm+MLP+残差连接)叠在一起。

inductive bias
归纳偏差:指的是模型学习时依赖的priors,如translation equivariance 、局部性。
neighborhood structure
领域结构:指的是图像像素之间的局部关系。卷积操作就利用了这种关系。
translation equivariance
图像发生平移,输出的特征图与原来一致。
Multi-head Attention
使用多次self-attention。
Layer Normalization
层规范化是一种正则化技术,它可以让每一层的输出值更加稳定。统一标准后更利于学习。例如学习学习爬楼梯,若每一阶楼梯的长宽高都不统一,那么你会学得很慢,因为阶梯的规格在变化。相反的,如果统一标准后,你每尝试爬一阶楼梯都会为爬下一阶楼梯积累非常有用的经验。
Hybrid architecture
结合不同模型的优势,用于提升性能的架构。CNN+transformer
具体地,关于分割图片,并排列成序列这一步骤,我们可以使用CNN来实现:让卷积核的kernel_size=patch_size,stride=patch_size即可。另外其实卷积核的数量就相于patch embedding的维度D。
结语
以上内容来自个人学习经验,若有疏漏,请不吝指正。















 534
534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









