







目录
一、前言
在先前的博客学习中我们已经简单的学习了无监督学习,今天就进入监督学习这块部分。本文重点讲的是决策树这一算法,文中将会介绍决策树算法,以及提供泰坦尼克号数据集的实战代码及效果图。
对了,这期的决策树我们做了分类。作者看到好像决策树也可以解决回归问题(这个以后在去探索)创作不易,循循渐进。
同样的希望各位能支持一下!
一、介绍泰坦尼克号数据集
在做任何的机器学习之前,我们都先要熟悉数据集的组成情况。本次采用的是泰坦尼克号数据集。泰坦尼克号数据集kaggle比赛经常用的数据集。各位可以自行搜索下载,找不到数据集可以私信我。
那么具体看一下数据集吧。

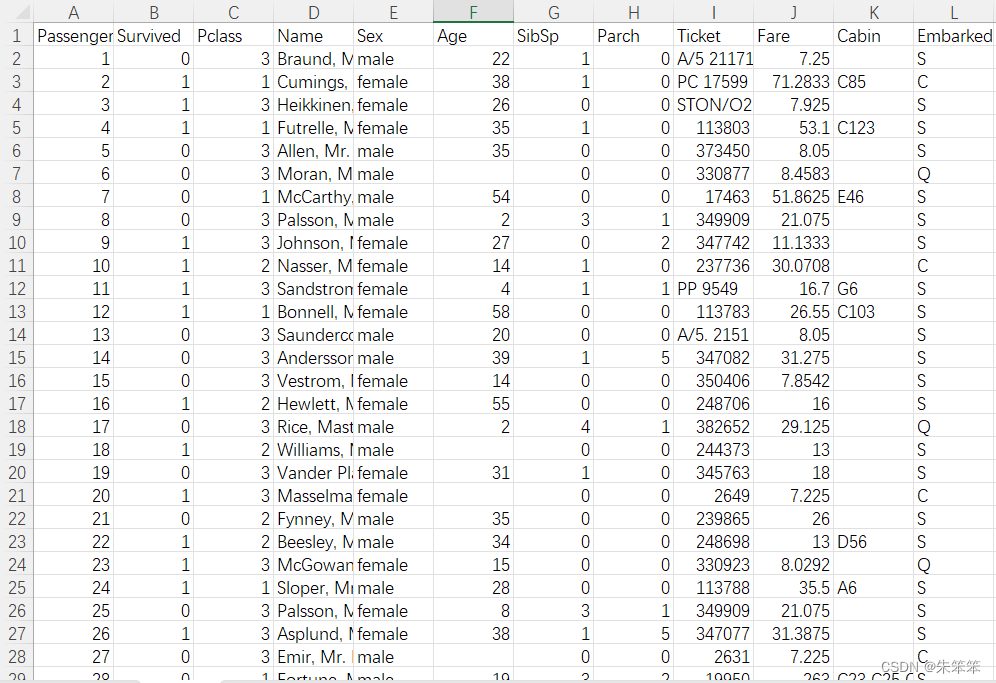
训练数据集的基本情况:有11列属性,分别是乘客的ID、获救情况,乘客等级、姓名、性别、年龄、堂兄弟妹个数、父母与小孩的个数、船票信息、票价、船舱、登船的港口;从其中我们获取到几点认知:
PassengerId(乘客ID),Name(姓名),Ticket(船票信息)存在唯一性,三类意义不大,可以考虑不加入后续的分析;
Survived(获救情况)变量为因变量,其值只有两类1或0,代表着获救或未获救;
Age(年龄),Cabin(船舱)和Embarked(登船港口)信息存在缺失数据。
二、数据的预处理
2.1 导入此次需要的工具库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.style.use('ggplot')
#导入决策树模型
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.tree import export_graphviz
from sklearn.model_selection import train_test_split经典的pandas numpy matplotlib三件套 加上sklean中所需的模型、划分训练集和测试集的模块。
2.2查看数据分布情况,做预处理
data = pd.read_csv('Titanic.csv', encoding='gbk', index_col=0)
data.head()
data.info()
data运行结果如下:
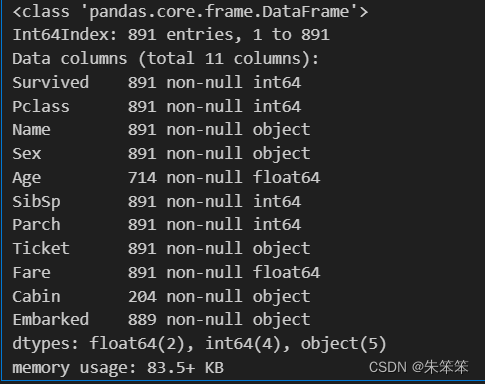
数据集的shape为(891,11) 然后我们发现cabin严重缺失,Age字段则是缺少177个数据,这里我打算直接用均值来代替缺失值。紧接着我们删除没有必要的列。然后Embarked登船港口的信息差2条,因为数据量少,所以我们可以删除缺少的那两行数据。然后数据会变成(889,8)的dataframe对象
data.drop(['Name', 'Ticket', 'Cabin'], inplace=True,axis = 1)#删除无用数据 名字 船票号 船舱号都对幸存率没有影响
data = data[data["Embarked"].notnull()]#删除缺失值
print(data.shape)#转文本型数据为数字型,然后填补年龄缺失值
data["Sex"] = (data["Sex"] == "male").astype("int")#将性别转换为数字 1为男 0为女
labels = data["Embarked"].unique().tolist()#将港口转换为数字,unique 之后会变成["s","c",“q”]的形式,tolist()将其转换为列表
data["Embarked"] = data["Embarked"].apply(lambda x: labels.index(x))#将港口转换为数字apply函数是一个循环函数
data["Age"] = data["Age"].fillna(data["Age"].mean())#用平均值填充年龄的缺失值
data.info()做完这些后info的内容如下:
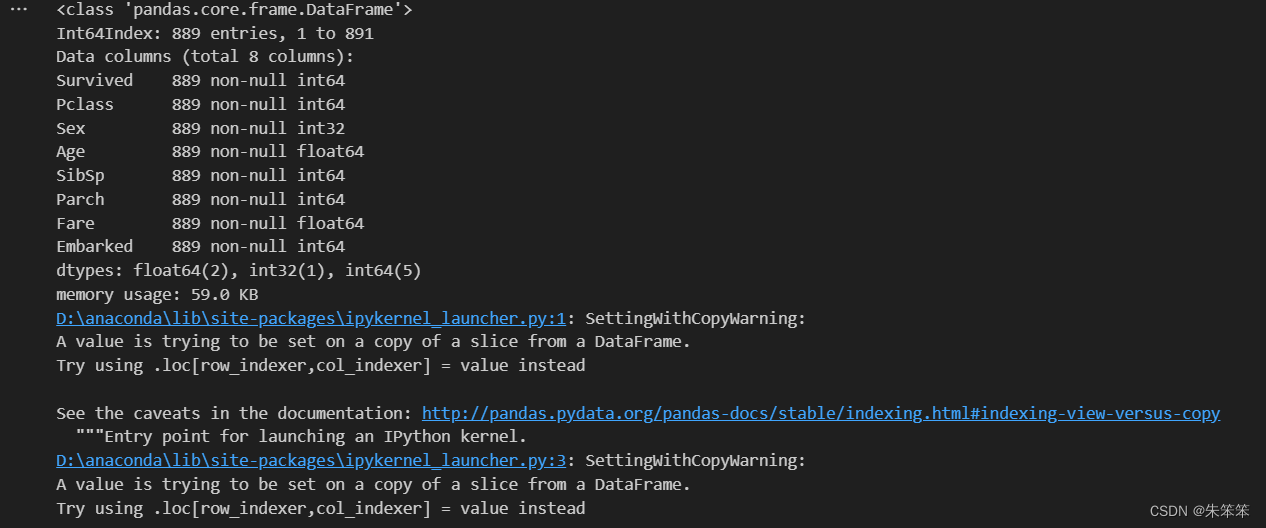
然后我们的数据已经是完整的了,那么直接进行切分。这次我们采用28原则。
#切分数据集
x = data.iloc[:,data.columns != "Survived"]
y = data.iloc[:,data.columns == "Survived"]
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.2,random_state = 22)#切分数据集,20%为测试集,80%为训练集
print(x_train.shape)
print(x_test.shape)
print(y_train.shape)
print(y_test.shape)
我们要做一个分类任务,所以把y设置成是否存活,x设置为特征。
(711, 7) (178, 7) (711, 1) (178, 1)这是打印出来的结果。就此划分数据集的步骤我们做完了
三、决策树简介
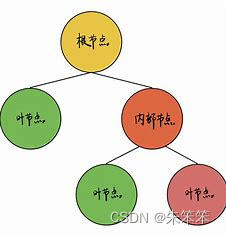
决策树算法是一种基于树形结构的分类算法,它通过对数据集进行划分并构建树形结构的方式来实现分类。决策树算法的基本思想是将数据集分为多个小的子集,每个子集对应一个节点,通过对节点进行判断和分类将数据集划分为不同的子集,直到达到叶子节点,即得到最终的分类结果。
在决策树算法中,通常采用信息熵、信息增益、基尼指数等指标来进行节点的划分,选择合适的指标可以提高决策树的分类精度。同时,为了防止决策树的过拟合问题,通常采用剪枝等技术来优化决策树模型。决策树算法的优点是易于理解和实现,能够处理多类别问题、缺失值以及非数值型数据等,缺点是容易受到噪声数据和过拟合的影响。
先做一个小总结:
算法 数据集特征 预测值类型 划分节点指标 适用场景
ID3 离散值 离散值 信息增益 分类
C4.5 离散值、连续值 离散值 信息增益率 分类
CART 离散值、连续值 离散值、连续值 Gini系数、方差 分类、回归
四、决策树模型的实战
老样子,先实例化然后传入数据接着fit一遍。对了到这里作者在可视化的时候出现了一些问题。就是graphviz这个插件的使用。这个建议大家就在csdn搜索“振华OPPO”这个作者,我在他的博客的帮助下解决了这件事情。
#决策树模型
clf = DTC(criterion="entropy")#实例化clf是分类器
clf.fit(x_train,y_train)#训练模型
score_ = clf.score(x_test,y_test)#评估模型
print("测试集上的精度"+str(score_))
score_ = clf.score(x_train,y_train)#评估模型
print("训练集上的精度"+str(score_))
#获得决策树的结构可视化
from IPython.display import Image
from io import StringIO
import pydotplus #这个库各位记得promt安装一下pip intsall pydotplus就行
dot_data = StringIO()#创建一个文件对象
#这两行去网上找就行了
export_graphviz(clf,out_file=dot_data,feature_names=x.columns)#将决策树结构写入文件对象
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())#将文件对象转换为图形对象
Image(graph.create_png())#将图形对象显示在notebook中 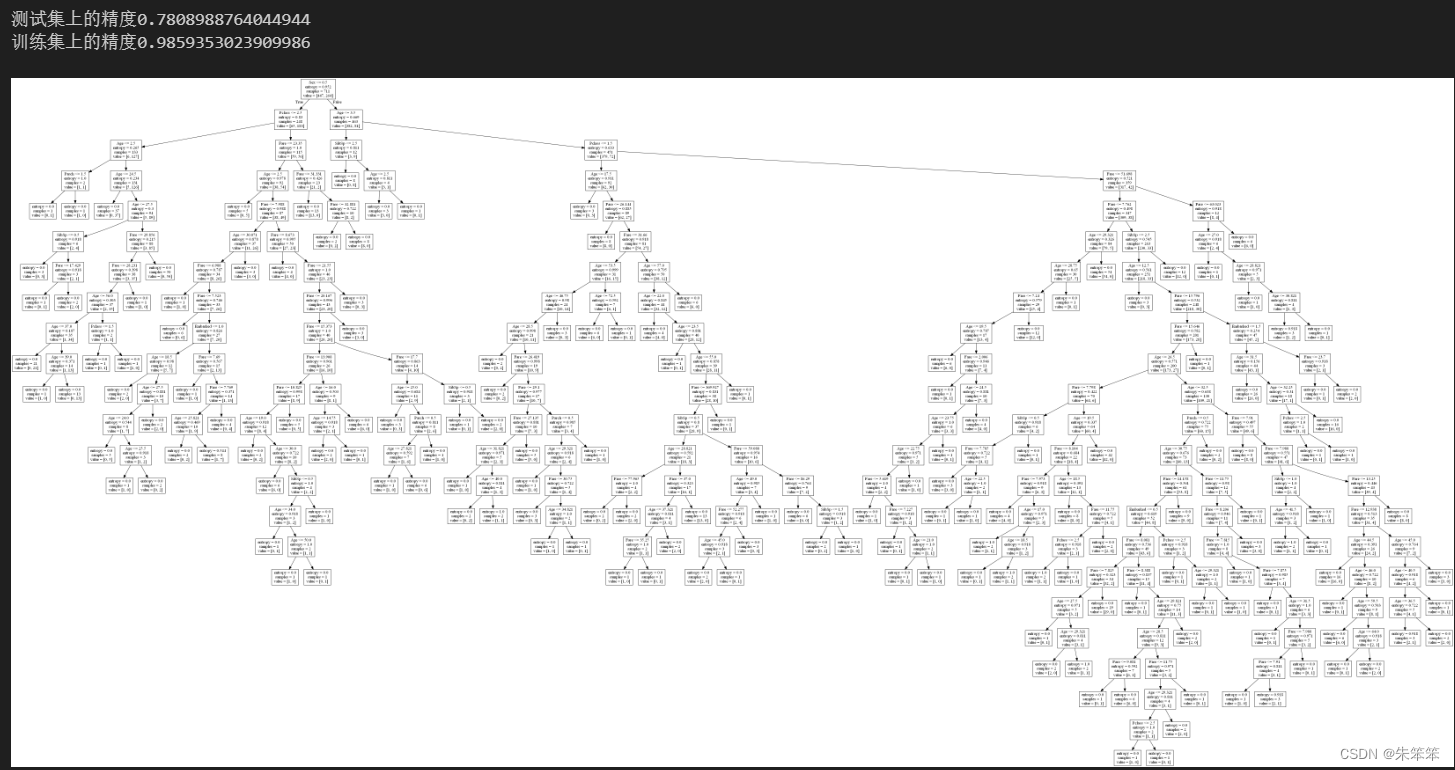
经过这些操作,我发现该模型在训练集上的精度只有0.78左右。这种精度对于机器学习来说其实算较低的精度了。于此同时训练集的精度缺有0.98,所以可以暂时确定一点。模型存在过拟合。所以我们只能看参数对模型的影响,并且做出一定的调整使得该决策树剪枝。
五、参数影响
在DTC中有
1、 max_depth: 树的最大深度,默认可以不输入,那么不会限制子树的深度,一般在样本少特征也少的情况下,可以不做限制。
2、 min_samples_split:节点再划分所需最少样本数,最小是2,默认是2,如果样本过多的情况下,可以设定一个阈值,具体可根据业务需求和数据量来定
3、 min_samples_leaf: 叶子节点所需最少样本数,如果达不到这个阈值,则同一父节点的所有叶子节点均被剪枝,这是一个防止过拟合的参数。
4、 max_features: 划分考虑最大特征数,不输入则默认全部特征。
等等还有几个不是,这里不一一举例了,接下来我们将绘制单参数变化情况下,测试集和训练集的精度变化情况,从而更直观的了解该模型,也为了能找到最好的参数(这里只是有可能哈,在六的时候会将网格搜索最优参数的方法的)
5.1max_depth的影响
#在不同的max_depth下观察模型的拟合情况
test = []
train = []
for i in range(10):
clf = DTC(criterion="entropy",random_state=25,max_depth=i+1)
clf.fit(x_train,y_train)
score_1 = clf.score(x_train,y_train)
score_2 = clf.score(x_test,y_test)
train.append(score_1)
test.append(score_2)
plt.plot(range(1,11),train,color="red",label="train")
plt.plot(range(1,11),test,color="blue",label="test")
plt.xticks(range(1,11))
plt.legend()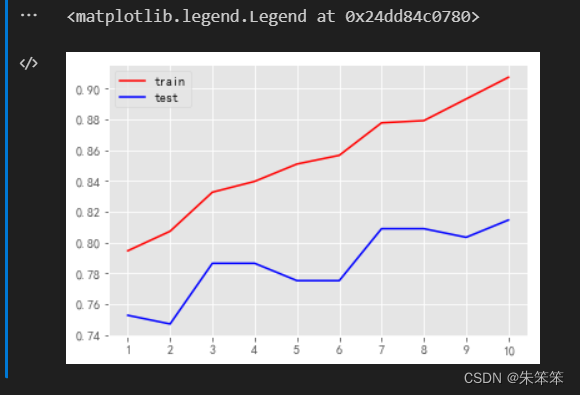
通过图片可以看出随着depth的增加训练集的精度成上升趋势,而测试集呈现先下降后上升然后起伏较大。在depth = 2时过拟合现象较为的严重
5.2 min_samples_split的影响
#在不同的min_samples_split下观察模型的拟合情况
test = []
train = []
for i in range(25):
clf = DTC(criterion="entropy",random_state=25,min_samples_split=i+2)
clf.fit(x_train,y_train)
score_1 = clf.score(x_train,y_train)
score_2 = clf.score(x_test,y_test)
train.append(score_1)
test.append(score_2)
plt.plot(range(2,27),train,color="red",label="train")#min_samples_split的最小值为2
plt.plot(range(2,27),test,color="blue",label="test")
plt.xticks(range(2,27))
plt.legend() 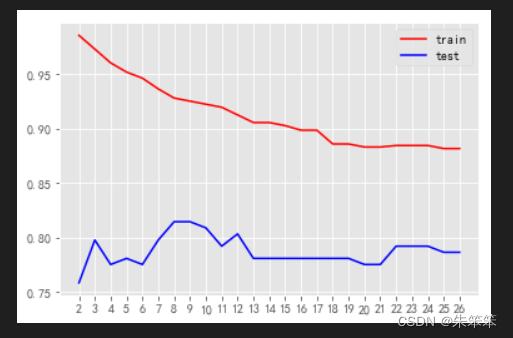
可以看出这个参数随着增大测试集和训练集的效果都不好。
5.3min_samples_leaf的影响
#在不同的min_samples_leaf下观察模型的拟合情况
test = []
train = []
for i in range(10):
clf = DTC(criterion="entropy",random_state=25,min_samples_leaf=i+1)
clf.fit(x_train,y_train)
score_1 = clf.score(x_train,y_train)
score_2 = clf.score(x_test,y_test)
train.append(score_1)
test.append(score_2)
plt.plot(range(1,11),train,color="red",label="train")
plt.plot(range(1,11),test,color="blue",label="test")
plt.xticks(range(1,11))
plt.legend()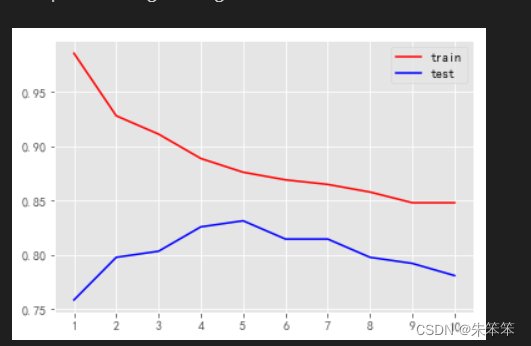
随着该参数的增加train的曲线一直下降,test的曲线先上升后下降,如果要选择的话该参数应该选择5会比较合适。此时两条曲线之间的距离最近,模型较为合理。
5.4max_features的影响
#在不同的max_features下观察模型的拟合情况
test = []
train = []
for i in range(6):
clf = DTC(criterion="entropy",random_state=25,max_features=i+1)
clf.fit(x_train,y_train)
score_1 = clf.score(x_train,y_train)
score_2 = clf.score(x_test,y_test)
train.append(score_1)
test.append(score_2)
plt.plot(range(1,7),train,color="red",label="train")
plt.plot(range(1,7),test,color="blue",label="test")
plt.xticks(range(1,7))
plt.legend()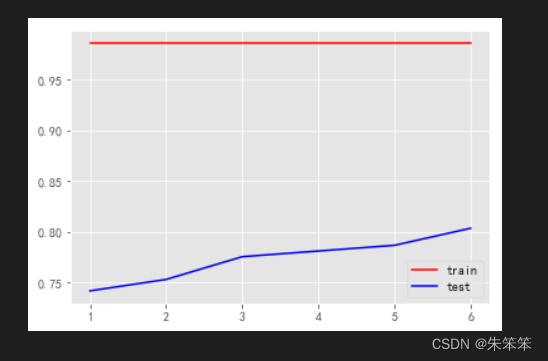
这个图就显得比较抽象了,无论如何最大特征为几,训练集都保持不懂,只有测试集在升高。
所以看了四张图初步认为depth和min_samples_leaf做出调整会比较好。所以接下来我要做的是调整参数,找到最优决策树。而做这件事情则需要遍历所有的参数。
六、网格搜索优化参数,剪枝后的决策树
#选择最优参数
from sklearn.model_selection import GridSearchCV
import numpy as np
gini_thresholds = np.linspace(0,0.5,20)#0到0.5之间产生20个数
parameters = {'splitter':('best','random')#splitter是切分策略,best是最优切分,random是随机切分
,'criterion':("gini","entropy")#criterion是评价标准,gini是基尼系数,entropy是信息增益
,"max_depth":[*range(1,10)]#max_depth是最大深度,*range(1,10)是将1到10之间的数全部作为参数,*的作用是将range(1,10)拆分成一个个数字
,"min_samples_leaf":[*range(1,50,5)]#min_samples_leaf是叶子节点最少样本数,*range(1,50,5)是将1到50之间的数每隔5个取一个,作为参数
,"min_impurity_decrease":[*np.linspace(0,0.5,20)]#min_impurity_decrease是停止增长的阈值,*np.linspace(0,0.5,20)是0到0.5之间产生20个数
}
clf = DTC(random_state=25)
GS = GridSearchCV(clf,parameters,cv=10)
GS.fit(x_train,y_train)
GS.best_params_#返回最优参数
GS.best_score_#返回最优分数
GS.best_estimator_#返回最优模型
GS.best_index_#返回最优模型的索引号
GS.cv_results_#返回所有模型的评估结果
#使用最优参数的模型
clf = GS.best_estimator_
clf.fit(x_train,y_train)
clf.score(x_test,y_test)
#可视化最优决策树
dot_data = StringIO()
export_graphviz(clf,out_file=dot_data,feature_names=x.columns)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())
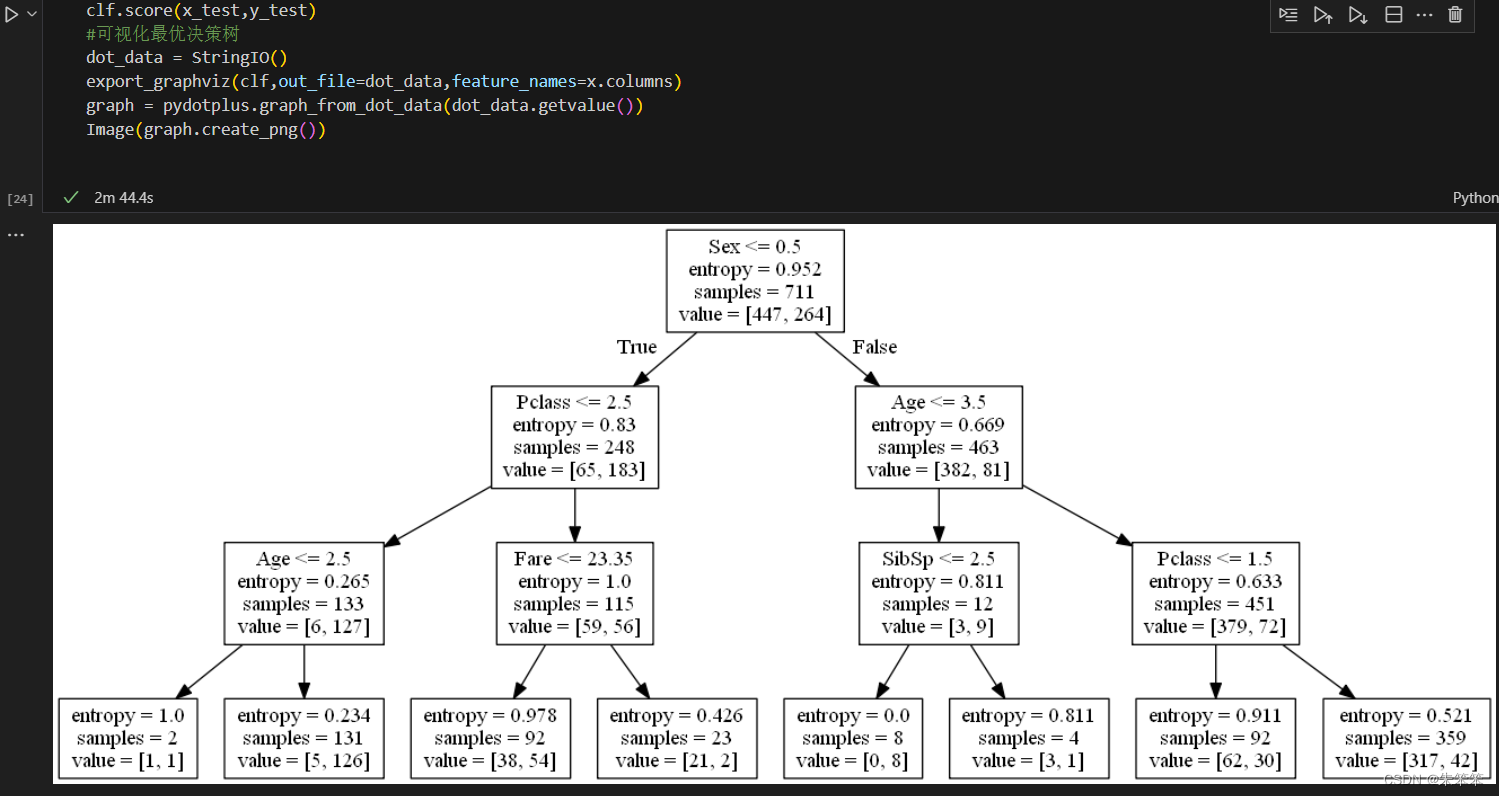
说实话挺不容易的,这里用了sklearn重点GridsearchCV,然后在我设置的范围中跑了接近三分钟,找到了一个目前来说最优的决策树了。
七、总结
总的来说决策树可以理解为那么多的特征中选择一些比较有代表性的特征将我们的样本进行细分,期间的评判标准就是信息增益、Gini系数、方差,当然不同算法适合不通的任务。各位要依据数据集进行合理分析。
看完的小伙伴应该很少吧。如果可以的话能不能帮作者点个赞,评论一下读完的想法呢?你们的问题作者会及时做出回答的!
谢谢各位读者的支持。
















 8067
8067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











