






问题
做练手的爬虫程序时,遇到了以下问题:
Exception has occurred: IndexError list index out of range File “D:\Desktop\vscode\python\biquge_book.py”, line 111, in bookTitle=main_html.xpath(‘/html/body/div[5]/div[2]/h1/text()’)[0] IndexError: list index out of range
获取xpath路径
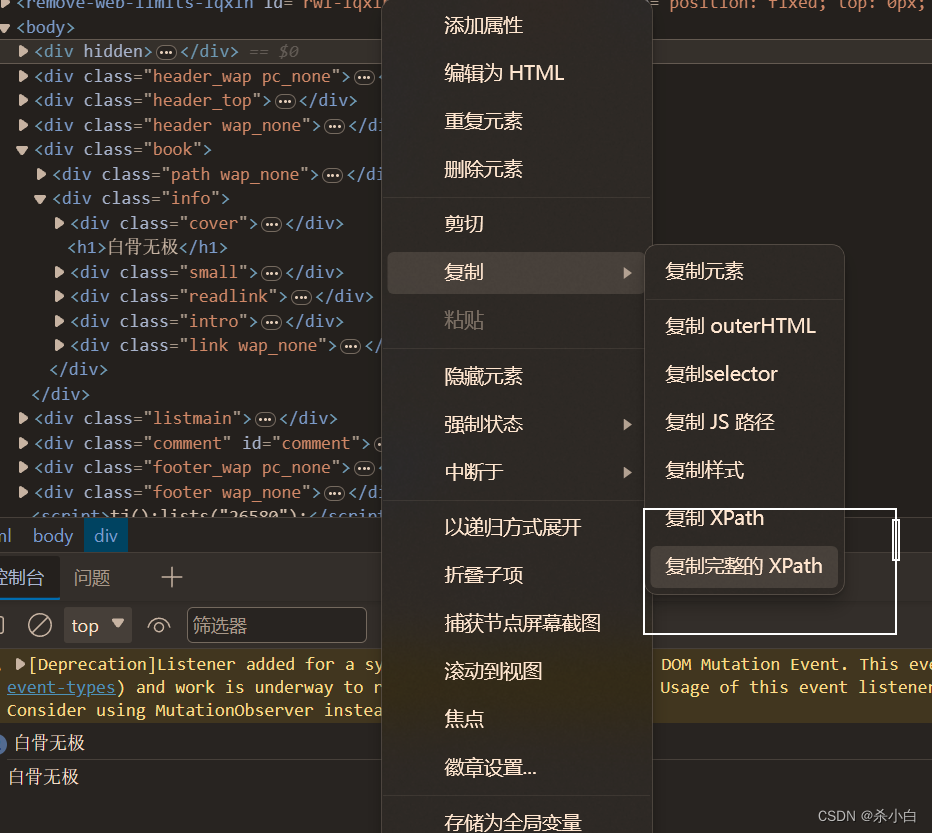
路径 报错
如果正确按照以上操作获取xpath路径,却报错:
Exception has occurred: IndexError list index out of range File “D:\Desktop\vscode\python\biquge_book.py”, line 111, in bookTitle=main_html.xpath(‘/html/body/div[5]/div[2]/h1/text()’)[0] IndexError: list index out of range
就要去仔细看一下网页源代码,看有没有啥陷阱了
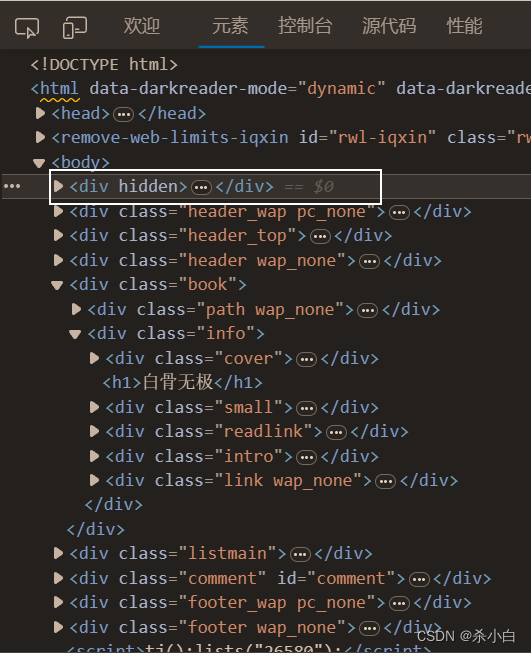
比如图上的框住的这个东西就会导致程序报错:
解决方法
某篇文章里的评论(路人真给力):
服务器在返回response浏览器渲染时有时候会加上一些特殊的标签,查看源代码看不出来,导致xpath取值 为空,需print()打印出来才可以看出来!
小说主页
main_url = "https://www.bige3.cc/book/26580/"
使用get方法请求网页
main_resp = requests.get(main_url, headers=headers)
将网页内容按utf-8规范解码为文本形式
main_text = main_resp.content.decode('utf-8')
调试用
print(main_text)
打印出来后就可以对照着网页源代码,找出错误原因了
我就是在仔细看了一遍后才发现

这东西貌似没有传给程序,导致出错
知道了原因,就很容易的解决问题了
先正常获取xpath路径
再根据打印内容更改
修改前
bookTitle=main_html.xpath(‘/html/body/div[5]/div[2]/h1/text()’)[0]
修改后
bookTitle=main_html.xpath(‘/html/body/div[4]/div[2]/h1/text()’)[0]
很明显,改个数字就行了
















 2214
2214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











