






文章目录
前言
简单记录一下爬取笔趣阁网站的小说图片的过程
目标已锁定,开炮:https://www.bige3.cc/xuanhuan/
注意事项
如何输出网页源代码
A = requests.get(url, headers=headers)
# 网页源代码中
# <head>
# <meta charset="utf-8">
# </head>
#decode -----把当前字符解码成Unicode编码
#encode-----把Unicode编码格式的字符编码成其他格式的编码
A.encoding = 'utf-8'
#判断请求是否得到正常回应(输出200则OK)
print(A.status_code)
content = A.text
#print(content)
精简点也行
A=requests.get(url,headers=headers)
print(A.status_code)
print(A.text.encode('utf-8','ignore'))
想了解详细一点的编码解码知识,可以看一下
Python爬虫中文乱码的几种解决办法
自动翻页
这个网站玄幻分类没有 1 2 3 … 翻页按钮
它会在你翻到底部时自动为你翻页(类似自动翻页的脚本)
但顶部的url却不变
这是我们可以通过查看网页源代码,看一下有啥线索
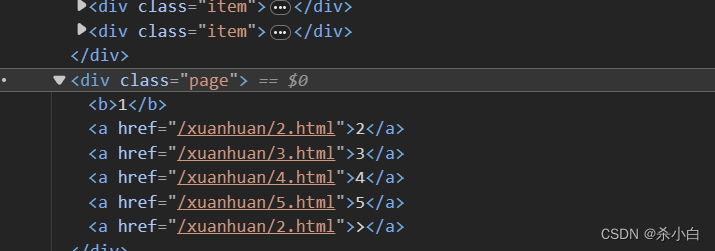
很明显,不同页面之间的规律很简单
通过以下方法便可成功得到不同网页的url
for i in range(1,page_num+1):
url=https://www.bige3.cc/xuanhuan/+str(i)+'.html'
源码
setting
# -*- coding: utf-8 -*-
import random
import re
import time
import requests
from urllib import error
from bs4 import BeautifulSoup
import os
#几乎没有反爬机制
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"
}
从玄幻分类的第一页开始爬取,自动翻页
def down(page_num,folder):
preurl="https://www.bige3.cc/xuanhuan/"
if page_num == 1:
try:
url=preurl+'index.html'
os.makedirs(filename)
except:
print('文件已创建,将保存进其中')
get_content(url,filename)
else:
for i in range(1,page_num+1):
url=preurl+str(i)+'.html'
filename=folder+'image/'
try:
os.makedirs(filename)
except:
print('文件已创建,将保存进其中')
get_content(url,filename)
接收url,并发起请求
def get_content(url,filename):
A = requests.get(url, headers=headers)
A.encoding = 'utf-8'
print(A.status_code)
content = A.text
#print(content)
refine(content,filename)
从得到的网页源代码中提取出图片的url和对应书名

def refine(content,filename):
soup=BeautifulSoup(content,'html.parser')
img_list=soup.find_all('img')
print('共找到'+str(len(img_list))+'张图片')
for img in img_list:
img_url=img.get('src')
img_name=img.get('alt')
print(img_name)
down_image(img_url,img_name,filename)
接收图片url,下载图片,并以相应书名命名
ef down_image(img_url,img_name,filename):
#print(time.time())
file_name=filename+img_name+'.jpg'
r=requests.get(img_url,headers=headers)
f=open(file_name,'wb')
f.write(r.content)
f.close()
# 自定义函数
sleep()
每爬取一次图片暂停一会,防止封ip
def sleep():
sleepTime=random.randint(1,3)
time.sleep(sleepTime)
主函数
if __name__ =="__main__":
folder_name=input('请输入存储图片的文件夹名称:')
folder=folder_name+'/'
try:
os.makedirs(folder)
except:
# 提示后继续进行
print('文件夹已创建,将保存进其中')
down_num=int(input('请输入要下载的页数:'))
down(down_num,folder)
print('爬取成功')


















 2610
2610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











