






一、基本介绍
RAG:检索增强生成技术(retrieval-Augmented Generation),能在不需要重新训练的情况下利用额外的数据资源(私有或特有数据源)来辅助文本生成。其内容包括:
1、文本加载与切分模块:将输入的文本加载与切分成小段chunk(减少embedding内容的噪音,便于处理和分析)。
2、向量化模块:将文本片段向量化。通常涉及到Embedding技术(编码器),将非结构化的文本数据转换为连续的向量表示,使得文本数据能够在计算机中被更好地处理和理解。
3、数据库模块(可更新的向量索引):存放文本片段和对应的向量表示。
4、检索模块:根据Query(问题)和Chunk(文本片段)相似度进行检索。
5、大模型模块:对问题生成回答。
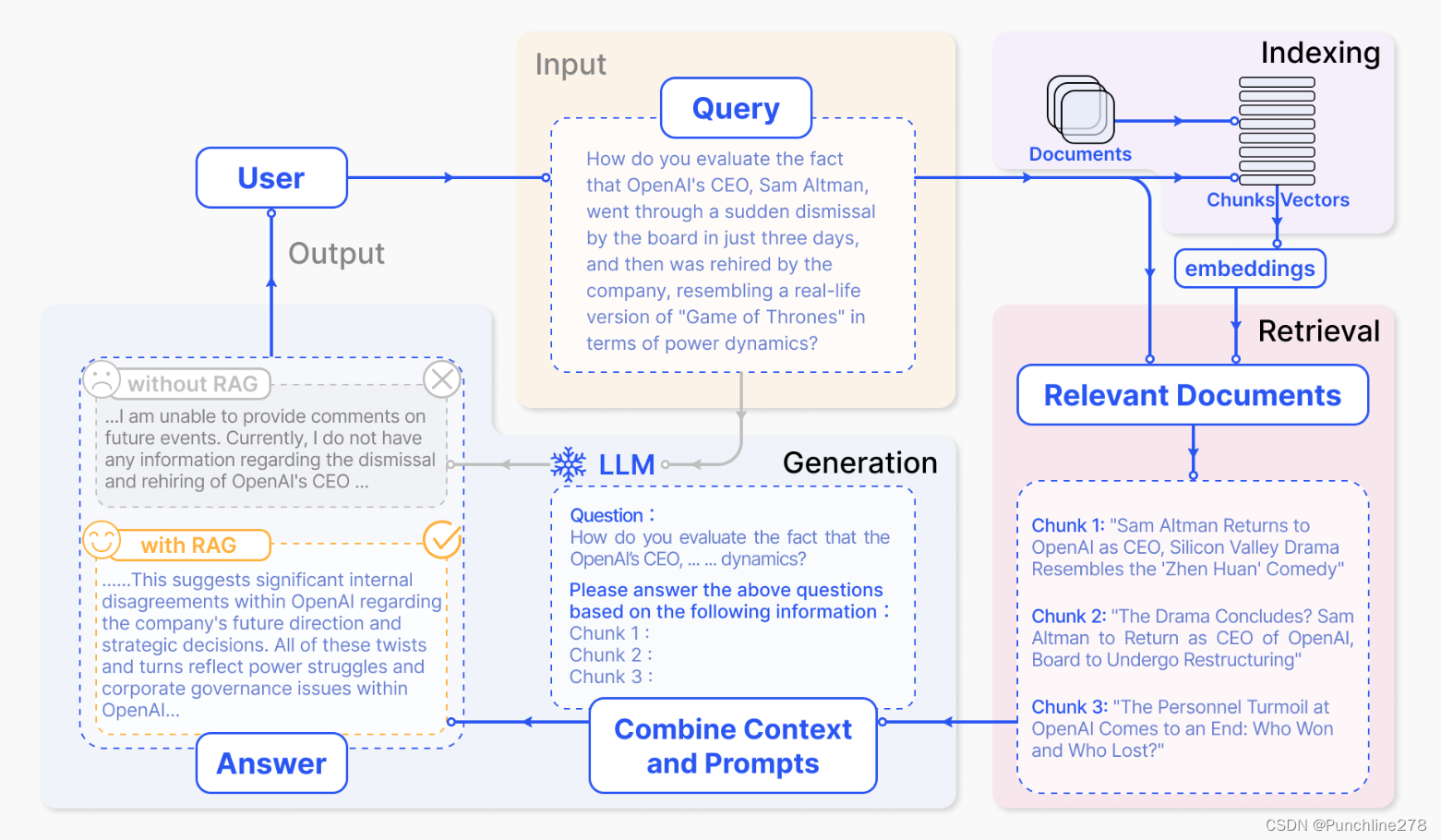 RAG
RAG
图片出处:tiny-universe/content/TinyRAG/images/RAG.png at main · datawhalechina/tiny-universe (github.com)
二、文本加载与切分
选择读取和处理的文档类型有三种:pdf,md和txt,在运行demo中用到的是《Chronos: Learning the Language of Time Series》这篇论文的PDF,注意将其放在对应的路径当中。
def get_chunk(cls, text: str, max_token_len: int = 600, cover_content: int = 150):
chunk_text = []
curr_len = 0
curr_chunk = ''
lines = text.split('\n') # 假设以换行符分割文本为行
for line in lines:
line = line.replace(' ', '') # 去除行内的所有空格
line_len = len(enc.encode(line))
if line_len > max_token_len:
print('warning line_len = ', line_len)
if curr_len + line_len <= max_token_len:
curr_chunk += line
curr_chunk += '\n'
curr_len += line_len
curr_len += 1
else:
chunk_text.append(curr_chunk)
curr_chunk = curr_chunk[-cover_content:]+line
curr_len = line_len + cover_content
if curr_chunk:
chunk_text.append(curr_chunk)
return chunk_text添加token,若超过最大长度限制600,则进行块分割。
分割块时的重叠处理很有意思,使用 curr_chunk[-cover_content:] 获取当前块最后cover_content个字符,并将其与新行line 连接,创建新的块curr_chunk,这确保了每个文本块的前 cover_content个字符与前一个文本块的最后cover_content个字符重叠,以保证上下文的连续性。
三、向量化
class BaseEmbeddings:
"""
Base class for embeddings
"""
def __init__(self, path: str, is_api: bool) -> None:
self.path = path
self.is_api = is_api
def get_embedding(self, text: str, model: str) -> List[float]:
raise NotImplementedError
@classmethod
def cosine_similarity(cls, vector1: List[float], vector2: List[float]) -> float:
"""
calculate cosine similarity between two vectors
"""
dot_product = np.dot(vector1, vector2)
magnitude = np.linalg.norm(vector1) * np.linalg.norm(vector2)
if not magnitude:
return 0
return dot_product / magnitude这里定义一个Embedding基类,方便之后使用其它开源大模型或API时能够直接继承(使用其它API时,self.is_api设为true),具有可扩展性。
值得注意的是,这里使用了一个cosine_similarity的类方法以计算两个向量之间的余弦相似度,接受两个浮点数列表(vector),计算两个向量的点积,然后计算它们的范数乘积——如果范数乘积为0,则返回0;否则,返回点积除以范数乘积(返回的是浮点数)。
当然,除了使用numpy计算余弦相似度,还能用sklearn提供的内置函数cosine_similarity直接计算余弦相似度:
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
"""
""" 后面各种大模型的继承类包含定义初始函数与编写get_embedding方法等,具体参数可参考开源文档。(API模型如OpenAI不要load_model方法,但开源模型如Jina则需要load_model)
四、数据库&&检索
VectorBase.py主要实现这一模块的功能。
# 获得文档的向量表示
def get_vector(self, EmbeddingModel: BaseEmbeddings) -> List[List[float]]:
# 数据库持久化,本地保存
def persist(self, path: str = 'storage'):
# 从本地加载数据库
def load_vector(self, path: str = 'storage'):
# 根据问题检索相关的文档片段
def query(self, query: str, EmbeddingModel: BaseEmbeddings, k: int = 1) -> List[str]:
persist函数相当于创建一个storage文件夹,在该文件夹里会生成两个json文件,一个是doecment.json,存放文档片段:
另一个是vector.json,存放文档片段对应的向量:

对于query函数:
def query(self, query: str, EmbeddingModel: BaseEmbeddings, k: int = 1) -> List[str]:
# 将输入的查询字符串 query 转换为一个向量 query_vector
query_vector = EmbeddingModel.get_embedding(query)
# 计算查询向量与每个文档向量之间的相似度
result = np.array([self.get_similarity(query_vector, vector)
for vector in self.vectors])
# 按相似度结果从小到大进行排序并选择相似度最高的 k 个文档
return np.array(self.document)[result.argsort()[-k:][::-1]].tolist()其中,
result.argsort()[-k:]获取相似度最高的k个索引。[::-1]将这些索引倒序,使得相似度最高的文档索引排在前面。
通过 [result.argsort()[-k:][::-1]]实现对文档索引的排序与选择,并将结果转换为列表。
五、大模型
简单的讲,就是根据检索query函数返回的结果生成回答。其内容与“向量化”有相似之处,先定义一个基类BaseModel,再根据各种大模型写继承类,继承类中的方法主要是chat函数,主要格式为:
def chat(self, prompt: str, history: List[dict], content: str) -> str:
# 在这里编写函数实现
pass对于开源大模型如 InternLM2-chat-7B 模型,还需要添加一个load_model方法。
def load_model(self):
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
self.tokenizer = AutoTokenizer.from_pretrained(self.path, trust_remote_code=True)
self.model = AutoModelForCausalLM.from_pretrained(self.path, torch_dtype=torch.float16, trust_remote_code=True).cuda()
主要作用是加载一个预训练的模型并将其存储起来。其中torch_dtype=torch.float16参数指定了模型的数据类型为半精度浮点数(float16),目的是为了在运行过程中节省内存,提高计算效率(相比float32)。
六、代码运行(Run Demo)
通过tiny-universe提供的代码,尝试跑了一下。

对于论文中主题Chronos的提问,模型能较为准确地给出回答。
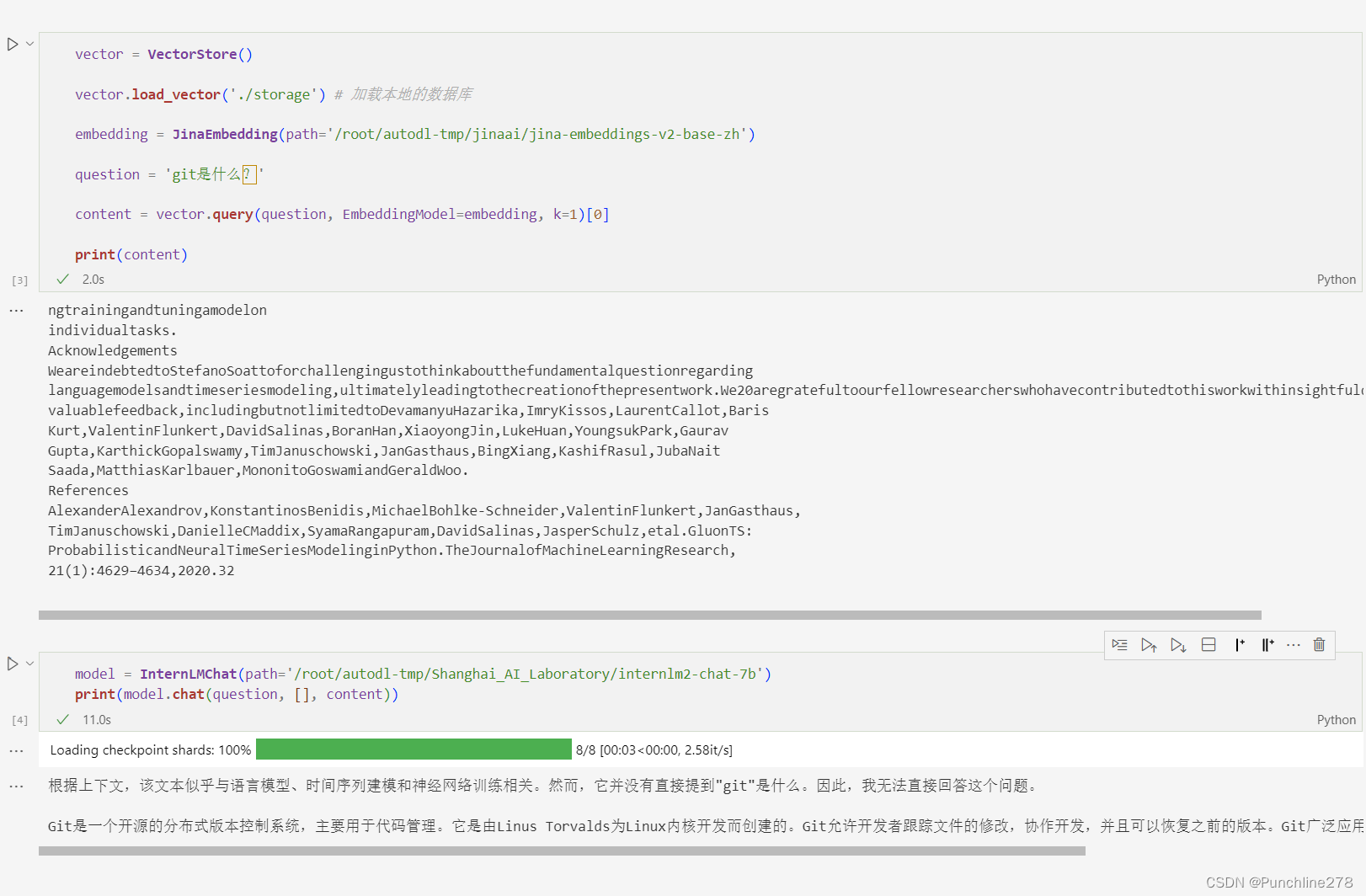
对于新建知识库(论文)中不存在,但原有数据库中含有的信息,模型也能给出答案(输出的content也很有意思啊)。
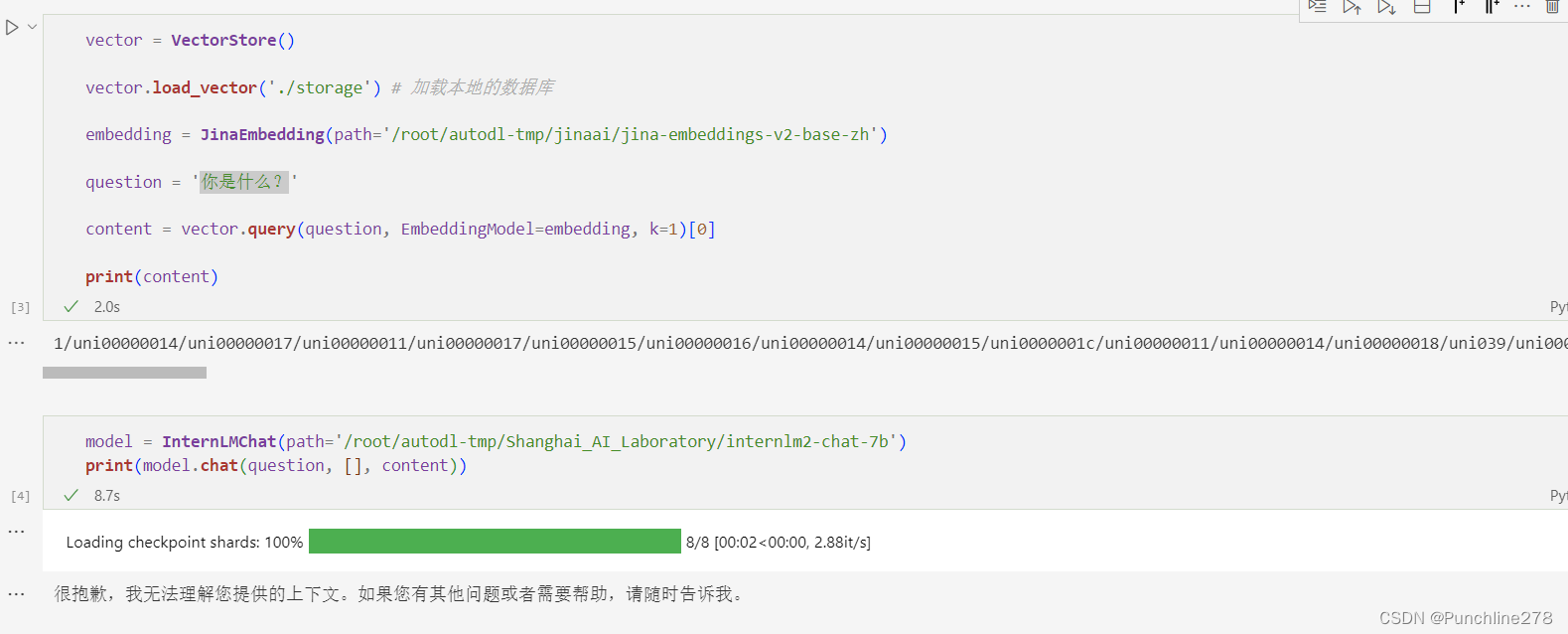
而对于新建知识库和原有数据库都不相关的信息,模型会表示无法解答。
(注:对于已经建立好知识库的模型来说,Query相关的Chunk不在库中,但有可能会回答,乃至效果很差,前言不搭后语。为了优化,可以设置prompt控制,或设置阈值——若所有的余弦相似度都小于该阈值,不回答或回答不知道。)
参考资料:















 1481
1481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}