







结论速递
这个迷你项目手搓了一个最小的RAG系统。之前基于Langchain实现过RAG(不用chain),对RAG结构还算熟悉,因此核心放在构思如何手搓和对照思路与TinyRAG的实现上。
TinyRAG项目中几个使用langchain得不到的小收获:
- 使用JSON做persistent
- cosine similarity的计算和加速
- chunk的切割方法
目录
1 绪论
1.1 RAG
RAG全称:Retrieval-Augmented Generation 检索增强生成。含义很直观,就是用检索到的内容增强LLM的回答能力。
RAG实际上诞生于LLM爆火之前,在最早的论文里,retrieval那一块是要梯度更新训练的(Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks)。23年初LLM应用开发爆火之后,RAG被用来给LLM进行knowledge injection,给LLM外挂知识库,让它能针对特定问题做开卷问答,以降低回答的知识幻觉。
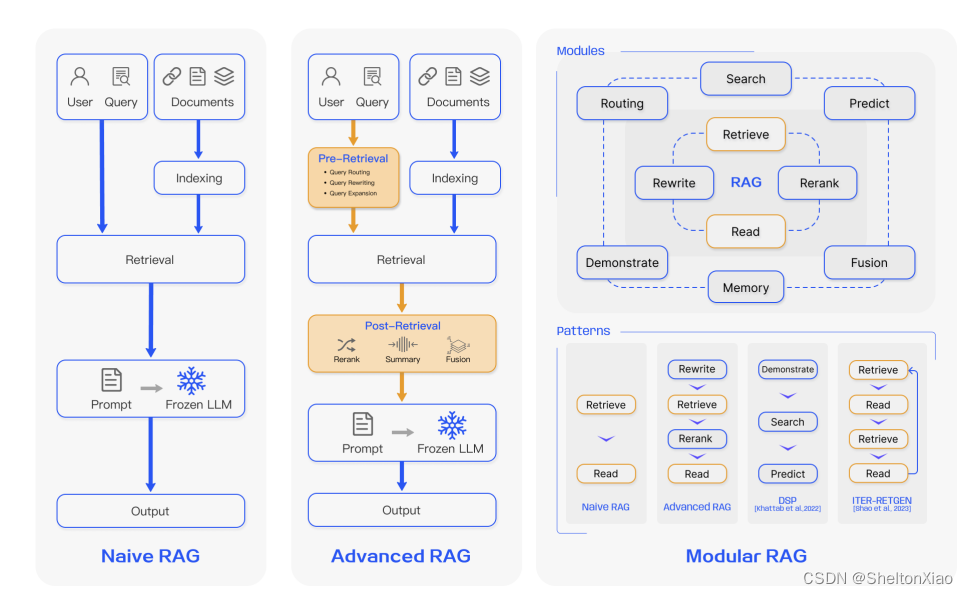
Naive RAG的实现非常非常简单,但是要做一个好的RAG系统并不容易,有很多小细节都可能影响RAG的效果。另外,目前的RAG的一些变体,比如在检索前初筛,或者检索后rerank等(如下图,出自Retrieval-Augmented Generation for Large Language Models: A Survey)其实也是在原流程上进行了一些改进得来的。因此,深入理解RAG的结构就变得非常重要。这也是参与手搓RAG的原因所在。
1.2 提前思考:如何手搓RAG
因为之前已经完成过RAG的项目,对RAG的流程比较有经验。这里尝试先根据已有经验梳理手搓RAG需要完成哪些工作。
数据流程图出自去年5月本人完成的一个使用Langchain实现的RAG项目:GitHub链接
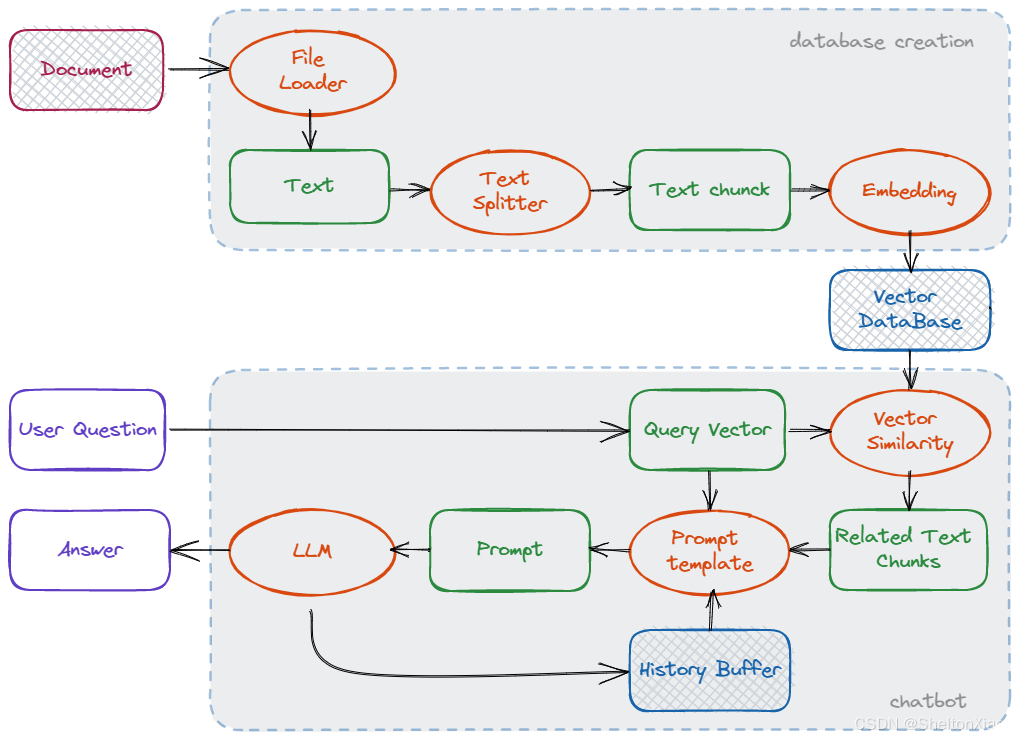
可以考虑一个RAG的项目代码需要实现的核心部分包括:
- Basis:
- Embedding:把文字变成向量,方便计算文本相似度实现检索;检索完把向量复原为文字
- Similarity calculation:相似文本检索。因为文字已经变成向量,所以这里通过计算向量相似度实现。
- Vector database creation:
- File loader:加载文件
- Text splitter:针对给定的分隔符,将文件切割成一个一个的段落
- Vector database:存储embedded后的段落,实现输入query后检索段落
- Retrieval:根据query在vector database当中检索内容
- Chatbot:
- Prompt template:能往里填内容的prompt模板,需要填的内容包括:检索出来的文本信息,用户的query,历史问答(如果有)
- ChatLLM(Chatbase):调用LLM,给出回复。
- Chatbot:起到一个interface的作用,根据用户query给结果
参考Langchain,ChatLLM的过程和Chatbot是两个分开的封装,前者是输入结构化prompt,输出结果;后者是输入用户query,内部调用检索,构建prompt,调用LLM,最后输出结果
2 TinyRAG
2.1 项目结构
TinyRAG项目结构由5大部分构成:
- Embedding:向量化模块,用来将文档片段向量化。包含了Similarity calculation的实现,实现为abstract类的方法,被所有子类继承。
- Load and split:文档加载和切分的模块,用来加载文档并切分成文档片段。结合了File loader和Text splitter两部分的实现。
- Vector database:数据库,用来存放文档片段和对应的向量表示。
- Retrieval:检索模块,用来根据 Query 在检索相关的文档片段。
- LLM:大模型模块,用来根据检索出来的文档回答用户的问题。对应ChatLLM&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 138
138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











