







本人也是入局深度学习的小白一枚,欢迎大家指正修改。在深度学习目标识别中,对数据集中的目标物进行打标签是个繁琐枯燥的过程,尤其是在数据集很大的情况下。写本文章的目的在与介绍个提高打标签效率的小技巧。
首先,我们需要跑通YOLOV5,了解训练的流程,将自己预先标注好的少量数据集进行训练得到权重,具体训练流程在CSDN上有很多,就不介绍了。以我的冬枣数据集为例,我以500张标注好的照片进行训练得到自己数据集的权重。接着,我们打开detect.py,将自己的权重放入219行,在220行修改为想要进行标注的图片文件夹路径。图片最好预先按顺序重命名,重命名脚本网上有很多。221行改为自己的配置文件,将228行--save-txt中的默认store_true改为store_false。
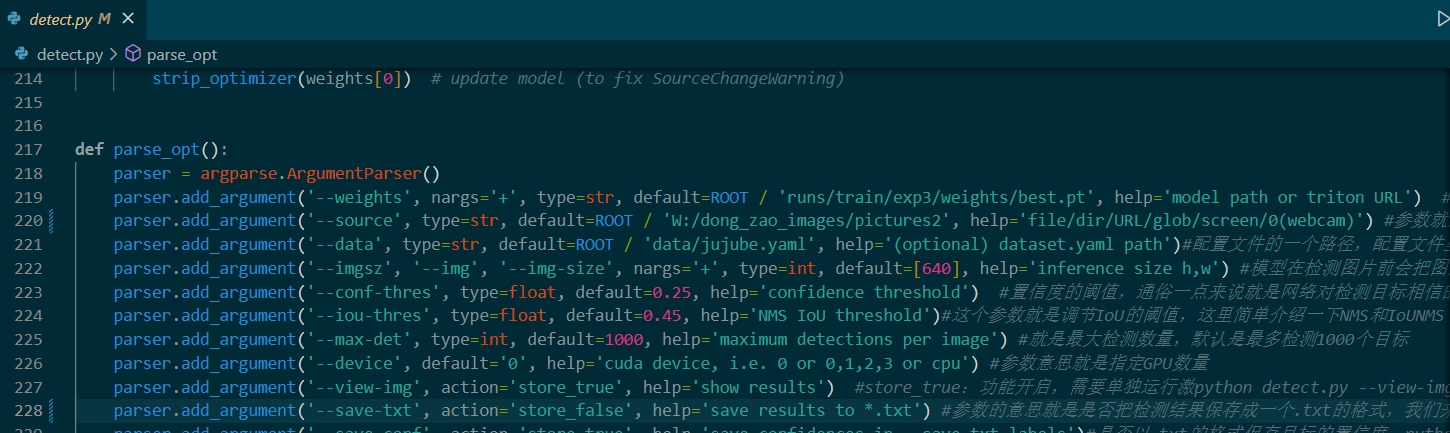
运行程序,会在runs/detect/exp中同步生成labels文件夹,有预测图片的txt文件。
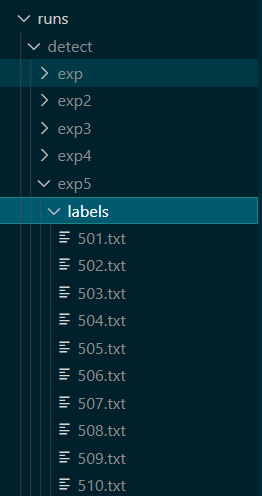
打开txt文件所在文件夹,全部复制到想要保存的文件夹内,同时新建classes.txt,按照检测时的顺序写上自己的类别
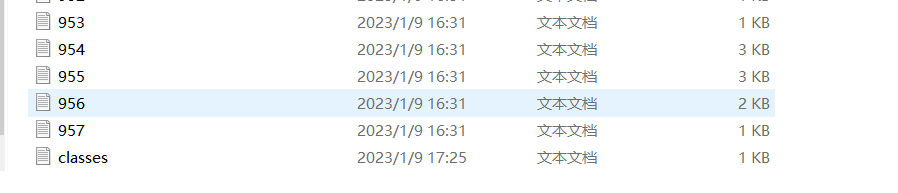
按照顺序就可以,以猫狗为例,记得保存

接着运行labeling,标签标注工具,open Dir打开数据集图片文件所在文件夹,chang save Dir 打开txt文件所在文件夹。
点击第一张图片,自动刷新,就可以得到标注的图片,可以选择保存为xml的格式,也可以使用脚本批量转为xml格式,这个网上也有很多将本。

需要注意的是,由于权重不是最优的会有部分标注错误的存在,需要自己修改后保存,单从打标签的角度来说,大大提高了效率。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









