






VanillaNet:一种极简设计的神经网络架构,性能与代表性CNN工作和视觉Transformer不相上下,突出了极简主义在深度学习中的潜力。

单位:华为诺亚, 悉尼大学
代码:https://github.com/huawei-noah/VanillaNet
论文:https://arxiv.org/abs/2305.12972
在本研究中,我们介绍了 VanillaNet,这是一种设计优雅的神经网络架构。 通过避免高深度、shortcuts和自注意力等复杂操作,VanillaNet 简洁明了但功能强大。
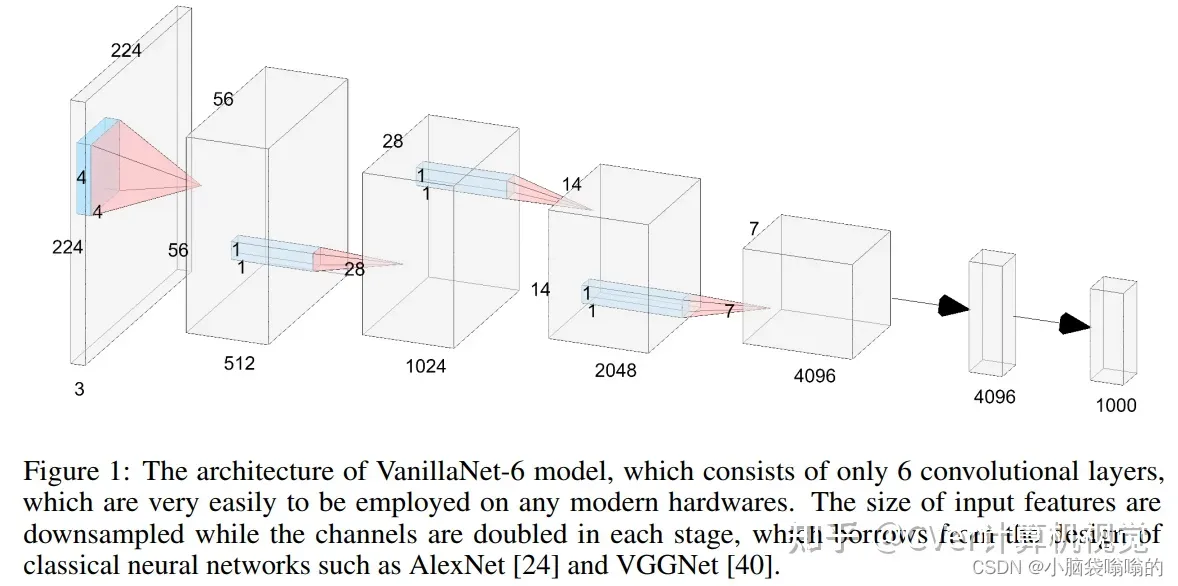
每一层都经过精心设计,简洁明了,非线性激活函数在训练后被剪枝以恢复原始架构。VanillaNet 克服了固有复杂性的挑战,使其成为资源受限环境的理想选择。 其易于理解和高度简化的架构为高效部署开辟了新的可能性。
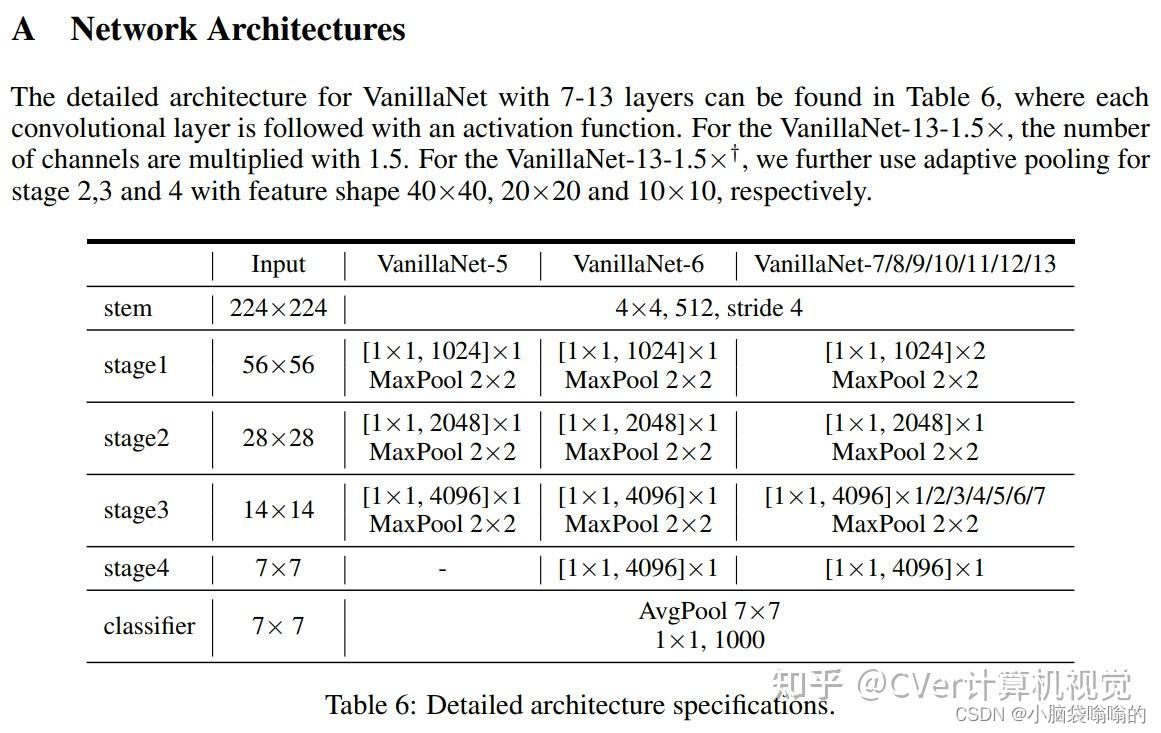
在这里,我们以6层为例详细展示了VanillaNet的体系结构。对于主干,我们使用4×4×3×C卷积层,步长为4,遵循[18,31,32]中的流行设置,将具有3个通道的图像映射到具有C个通道的特征。在阶段1、2和3,使用步长为2的最大池化层来减小大小和特征图,并且通道的数量增加2。在第4阶段,我们不增加信道的数量,因为它遵循平均池化层。最后一层是完全连接的层,用于输出分类结果。每个卷积层的核大小是1×1,因为我们的目标是在保留特征图信息的同时,对每个层使用最小的计算成本。在每个1×1卷积层之后应用激活函数。为了简化网络的训练过程,还在每一层之后添加了批量规范化。对于不同层数的VanillaNet,我们在每个阶段添加块,这将在补充材料中详细说明。需要注意的是,VanillaNet没有捷径,因为我们从经验上发现,添加捷径几乎不会提高性能。这也带来了另一个好处,即所提出的架构非常容易实现,因为没有分支和额外的块,如挤压和激励块[22]。
实验结果
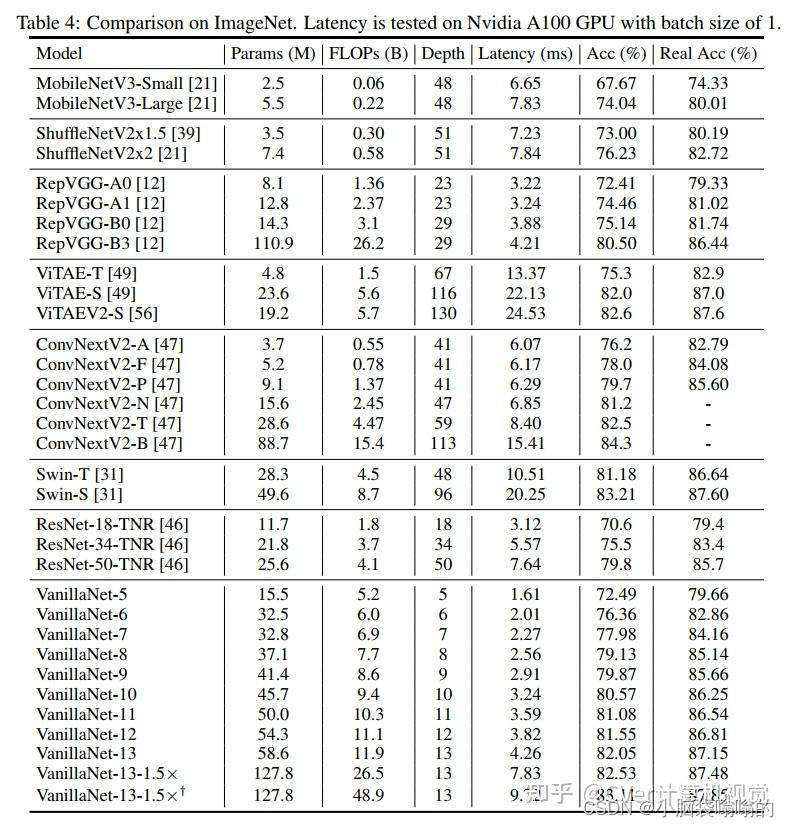
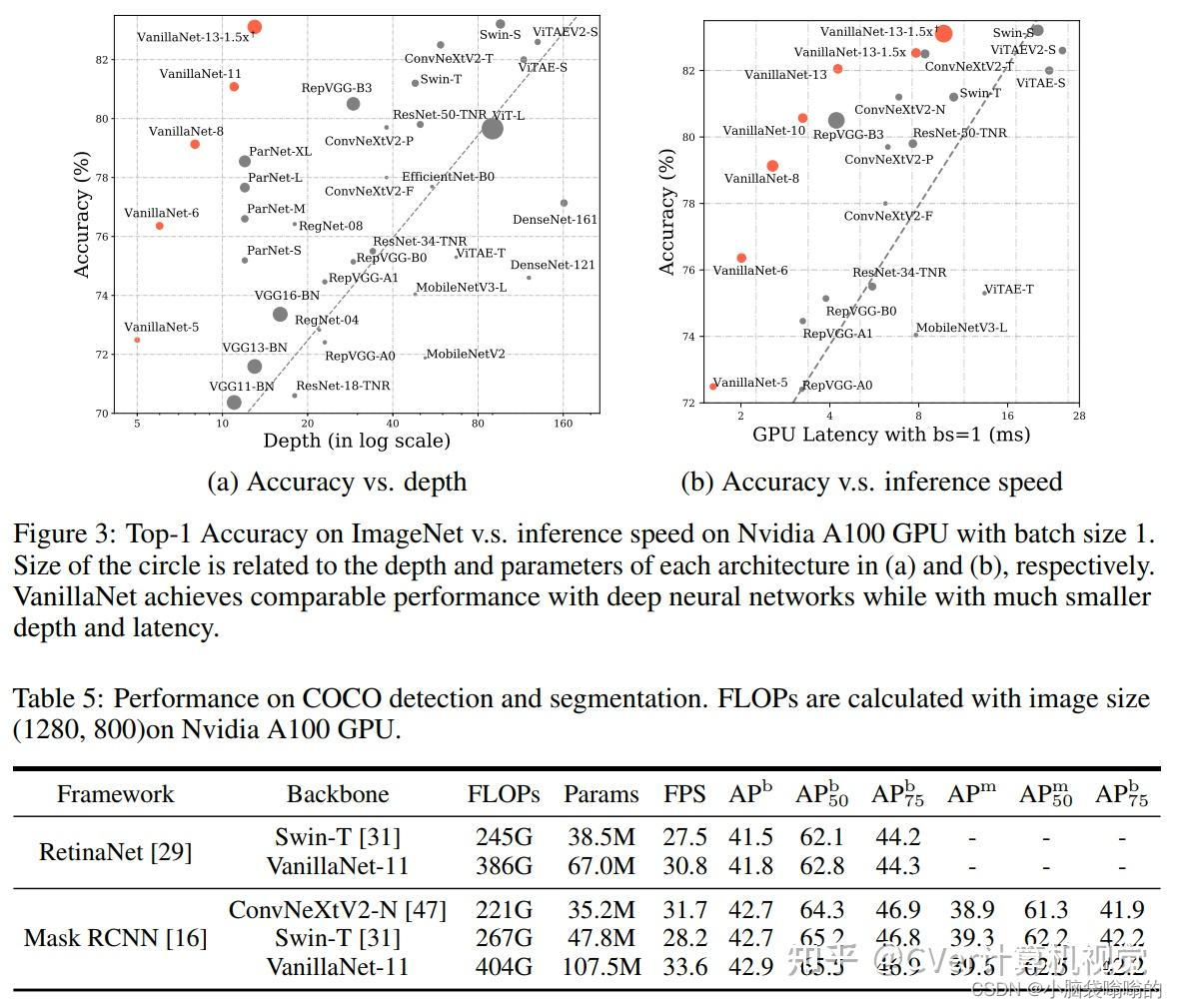
广泛的实验表明,VanillaNet 提供的性能与著名的深度神经网络和视觉Transformer器相当,展示了深度学习中极简主义的力量
github 官网下载vanillanet.py
#Copyright (C) 2023. Huawei Technologies Co., Ltd. All rights reserved.
#This program is free software; you can redistribute it and/or modify it under the terms of the MIT License.
#This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the MIT License for more details.
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import weight_init, DropPath
from timm.models.registry import register_model
class activation(nn.ReLU):
# 初始化激活函数
def __init__(self, dim, act_num=3, deploy=False):
super(activation, self).__init__()
# 判断是否是部署模式
self.deploy = deploy
# 初始化权重
self.weight = torch.nn.Parameter(torch.randn(dim, 1, act_num*2 + 1, act_num*2 + 1))
# 初始化偏置
self.bias = None
# 初始化BatchNorm2d
self.bn = nn.BatchNorm2d(dim, eps=1e-6)
# 设置维度
self.dim = dim
# 设置激活函数个数
self.act_num = act_num
# 初始化权重
weight_init.trunc_normal_(self.weight, std=.02)
def forward(self, x):
if self.deploy:
return torch.nn.functional.conv2d(
super(activation, self).forward(x),
self.weight, self.bias, padding=(self.act_num*2 + 1)//2, groups=self.dim)
else:
return self.bn(torch.nn.functional.conv2d(
super(activation, self).forward(x),
self.weight, padding=(self.act_num*2 + 1)//2, groups=self.dim))
def _fuse_bn_tensor(self, weight, bn):
kernel = weight
running_mean = bn.running_mean
running_var = bn.running_var
gamma = bn.weight
beta = bn.bias
eps = bn.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta + (0 - running_mean) * gamma / std
def switch_to_deploy(self):
kernel, bias = self._fuse_bn_tensor(self.weight, self.bn)
self.weight.data = kernel
self.bias = torch.nn.Parameter(torch.zeros(self.dim))
self.bias.data = bias
self.__delattr__('bn')
self.deploy = True
class vanillanetBlock(nn.Module):
# 初始化vanillanetBlock类
def __init__(self, dim, dim_out, act_num=3, stride=2, deploy=False, ada_pool=None):
super().__init__()
# 定义激活函数
self.act_learn = 1
self.deploy = deploy
# 如果deploy为True,则将conv设置为Conv2d,否则设置为Conv2d + BatchNorm2d
if self.deploy:
self.conv = nn.Conv2d(dim, dim_out, kernel_size=1)
else:
self.conv1 = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=1),
nn.BatchNorm2d(dim, eps=1e-6),
)
self.conv2 = nn.Sequential(
nn.Conv2d(dim, dim_out, kernel_size=1),
nn.BatchNorm2d(dim_out, eps=1e-6)
)
# 如果不是ada_pool,则将pool设置为Identity,否则设置为AdaptiveMaxPool2d
if not ada_pool:
self.pool = nn.Identity() if stride == 1 else nn.MaxPool2d(stride)
else:
self.pool = nn.Identity() if stride == 1 else nn.AdaptiveMaxPool2d((ada_pool, ada_pool))
# 定义激活函数
self.act = activation(dim_out, act_num)
def forward(self, x):
if self.deploy:
x = self.conv(x)
else:
x = self.conv1(x)
x = torch.nn.functional.leaky_relu(x,self.act_learn)
x = self.conv2(x)
x = self.pool(x)
x = self.act(x)
return x
def _fuse_bn_tensor(self, conv, bn):
kernel = conv.weight
bias = conv.bias
running_mean = bn.running_mean
running_var = bn.running_var
gamma = bn.weight
beta = bn.bias
eps = bn.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta + (bias - running_mean) * gamma / std
def switch_to_deploy(self):
kernel, bias = self._fuse_bn_tensor(self.conv1[0], self.conv1[1])
self.conv1[0].weight.data = kernel
self.conv1[0].bias.data = bias
# kernel, bias = self.conv2[0].weight.data, self.conv2[0].bias.data
kernel, bias = self._fuse_bn_tensor(self.conv2[0], self.conv2[1])
self.conv = self.conv2[0]
self.conv.weight.data = torch.matmul(kernel.transpose(1,3), self.conv1[0].weight.data.squeeze(3).squeeze(2)).transpose(1,3)
self.conv.bias.data = bias + (self.conv1[0].bias.data.view(1,-1,1,1)*kernel).sum(3).sum(2).sum(1)
self.__delattr__('conv1')
self.__delattr__('conv2')
self.act.switch_to_deploy()
self.deploy = True
class VanillaNet(nn.Module):
def __init__(self, in_chans=3, num_classes=1000, dims=[96, 192, 384, 768],
drop_rate=0, act_num=3, strides=[2,2,2,1], deploy=False, ada_pool=None, **kwargs):
super().__init__()
self.deploy = deploy
if self.deploy:
self.stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
activation(dims[0], act_num)
)
else:
self.stem1 = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
nn.BatchNorm2d(dims[0], eps=1e-6),
)
self.stem2 = nn.Sequential(
nn.Conv2d(dims[0], dims[0], kernel_size=1, stride=1),
nn.BatchNorm2d(dims[0], eps=1e-6),
activation(dims[0], act_num)
)
self.act_learn = 1
self.stages = nn.ModuleList()
for i in range(len(strides)):
if not ada_pool:
stage = vanillanetBlock(dim=dims[i], dim_out=dims[i+1], act_num=act_num, stride=strides[i], deploy=deploy)
else:
stage = vanillanetBlock(dim=dims[i], dim_out=dims[i+1], act_num=act_num, stride=strides[i], deploy=deploy, ada_pool=ada_pool[i])
self.stages.append(stage)
self.depth = len(strides)
if self.deploy:
self.cls = nn.Sequential(
nn.AdaptiveAvgPool2d((1,1)),
nn.Dropout(drop_rate),
nn.Conv2d(dims[-1], num_classes, 1),
)
else:
self.cls1 = nn.Sequential(
nn.AdaptiveAvgPool2d((1,1)),
nn.Dropout(drop_rate),
nn.Conv2d(dims[-1], num_classes, 1),
nn.BatchNorm2d(num_classes, eps=1e-6),
)
self.cls2 = nn.Sequential(
nn.Conv2d(num_classes, num_classes, 1)
)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
weight_init.trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def change_act(self, m):
for i in range(self.depth):
self.stages[i].act_learn = m
self.act_learn = m
def forward(self, x):
if self.deploy:
x = self.stem(x)
else:
x = self.stem1(x)
x = torch.nn.functional.leaky_relu(x,self.act_learn)
x = self.stem2(x)
for i in range(self.depth):
x = self.stages[i](x)
if self.deploy:
x = self.cls(x)
else:
x = self.cls1(x)
x = torch.nn.functional.leaky_relu(x,self.act_learn)
x = self.cls2(x)
return x.view(x.size(0),-1)
def _fuse_bn_tensor(self, conv, bn):
kernel = conv.weight
bias = conv.bias
running_mean = bn.running_mean
running_var = bn.running_var
gamma = bn.weight
beta = bn.bias
eps = bn.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta + (bias - running_mean) * gamma / std
def switch_to_deploy(self):
self.stem2[2].switch_to_deploy()
kernel, bias = self._fuse_bn_tensor(self.stem1[0], self.stem1[1])
self.stem1[0].weight.data = kernel
self.stem1[0].bias.data = bias
kernel, bias = self._fuse_bn_tensor(self.stem2[0], self.stem2[1])
self.stem1[0].weight.data = torch.einsum('oi,icjk->ocjk', kernel.squeeze(3).squeeze(2), self.stem1[0].weight.data)
self.stem1[0].bias.data = bias + (self.stem1[0].bias.data.view(1,-1,1,1)*kernel).sum(3).sum(2).sum(1)
self.stem = torch.nn.Sequential(*[self.stem1[0], self.stem2[2]])
self.__delattr__('stem1')
self.__delattr__('stem2')
for i in range(self.depth):
self.stages[i].switch_to_deploy()
kernel, bias = self._fuse_bn_tensor(self.cls1[2], self.cls1[3])
self.cls1[2].weight.data = kernel
self.cls1[2].bias.data = bias
kernel, bias = self.cls2[0].weight.data, self.cls2[0].bias.data
self.cls1[2].weight.data = torch.matmul(kernel.transpose(1,3), self.cls1[2].weight.data.squeeze(3).squeeze(2)).transpose(1,3)
self.cls1[2].bias.data = bias + (self.cls1[2].bias.data.view(1,-1,1,1)*kernel).sum(3).sum(2).sum(1)
self.cls = torch.nn.Sequential(*self.cls1[0:3])
self.__delattr__('cls1')
self.__delattr__('cls2')
self.deploy = True
@register_model
def vanillanet_5(pretrained=False,in_22k=False, **kwargs):
model = VanillaNet(dims=[128*4, 256*4, 512*4, 1024*4], strides=[2,2,2], **kwargs)
return model
@register_model
def vanillanet_6(pretrained=False,in_22k=False, **kwargs):
model = VanillaNet(dims=[128*4, 256*4, 512*4, 1024*4, 1024*4], strides=[2,2,2,1], **kwargs)
return model
@register_model
def vanillanet_7(pretrained=False,in_22k=False, **kwargs):
model = VanillaNet(dims=[128*4, 128*4, 256*4, 512*4, 1024*4, 1024*4], strides=[1,2,2,2,1], **kwargs)
return model
@register_model
def vanillanet_8(pretrained=False, in_22k=False, **kwargs):
model = VanillaNet(dims=[128*4, 128*4, 256*4, 512*4, 512*4, 1024*4, 1024*4], strides=[1,2,2,1,2,1], **kwargs)
return model
@register_model
def vanillanet_9(pretrained=False, in_22k=False, **kwargs):
model = VanillaNet(dims=[128*4, 128*4, 256*4, 512*4, 512*4, 512*4, 1024*4, 1024*4], strides=[1,2,2,1,1,2,1], **kwargs)
return model
@register_model
def vanillanet_10(pretrained=False, in_22k=False, **kwargs):
model = VanillaNet(
dims=[128*4, 128*4, 256*4, 512*4, 512*4, 512*4, 512*4, 1024*4, 1024*4],
strides=[1,2,2,1,1,1,2,1],
**kwargs)
return model
@register_model
def vanillanet_11(pretrained=False, in_22k=False, **kwargs):
model = VanillaNet(
dims=[128*4, 128*4, 256*4, 512*4, 512*4, 512*4, 512*4, 512*4, 1024*4, 1024*4],
strides=[1,2,2,1,1,1,1,2,1],
**kwargs)
return model
@register_model
def vanillanet_12(pretrained=False, in_22k=False, **kwargs):
model = VanillaNet(
dims=[128*4, 128*4, 256*4, 512*4, 512*4, 512*4, 512*4, 512*4, 512*4, 1024*4, 1024*4],
strides=[1,2,2,1,1,1,1,1,2,1],
**kwargs)
return model
@register_model
def vanillanet_13(pretrained=False, in_22k=False, **kwargs):
'''
VanillaNet-13
:param pretrained: 是否使用预训练模型
:param in_22k: 是否使用22k帧的图像
:param kwargs: 其他参数
:return: VanillaNet
'''
model = VanillaNet(
dims=[128*4, 128*4, 256*4, 512*4, 512*4, 512*4, 512*4, 512*4, 512*4, 512*4, 1024*4, 1024*4],
strides=[1,2,2,1,1,1,1,1,1,2,1],
**kwargs)
return model
@register_model
def vanillanet_13_x1_5(pretrained=False, in_22k=False, **kwargs):
model = VanillaNet(
dims=[128*6, 128*6, 256*6, 512*6, 512*6, 512*6, 512*6, 512*6, 512*6, 512*6, 1024*6, 1024*6],
strides=[1,2,2,1,1,1,1,1,1,2,1],
**kwargs)
return model
@register_model
def vanillanet_13_x1_5_ada_pool(pretrained=False, in_22k=False, **kwargs):
model = VanillaNet(
dims=[128*6, 128*6, 256*6, 512*6, 512*6, 512*6, 512*6, 512*6, 512*6, 512*6, 1024*6, 1024*6],
strides=[1,2,2,1,1,1,1,1,1,2,1],
ada_pool=[0,40,20,0,0,0,0,0,0,10,0],
**kwargs)
return model
在tasks.py中
from ultralytics.nn.vanillanet import (vanillanetBlock)elif m is vanillanetBlock:
c1, c2 = ch[f], args[0]
if c2 != torch.NoneType:
c2 = make_divisible(c2 * width, 8)
args = [c1, c2, *args[1:]]修改yaml文件
# Ultralytics YOLO 🚀, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1 # scales module repeats
width_multiple: 0.5 # scales convolution channels
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 4, 4 ]] # 0-P2/4
- [-1, 1, vanillanetBlock, [128, 1, 2]] # 1-P2/8
- [-1, 1, vanillanetBlock, [256, 1, 2]] # 2-P2/16
- [-1, 1, vanillanetBlock, [512, 1, 2]] # 3-P2/32
- [-1, 1, vanillanetBlock, [512, 1, 1]] # 4-P3/32
# YOLOv8.0s head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] #1/16
- [[-1, 2], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 7
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] #1/8
- [[-1, 1], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 10 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]] #1/16
- [[-1, 7], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 13 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 4], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 16 (P5/32-large)
- [[10, 13, 16], 1, Detect, [nc]] # Detect(P3, P4, P5)
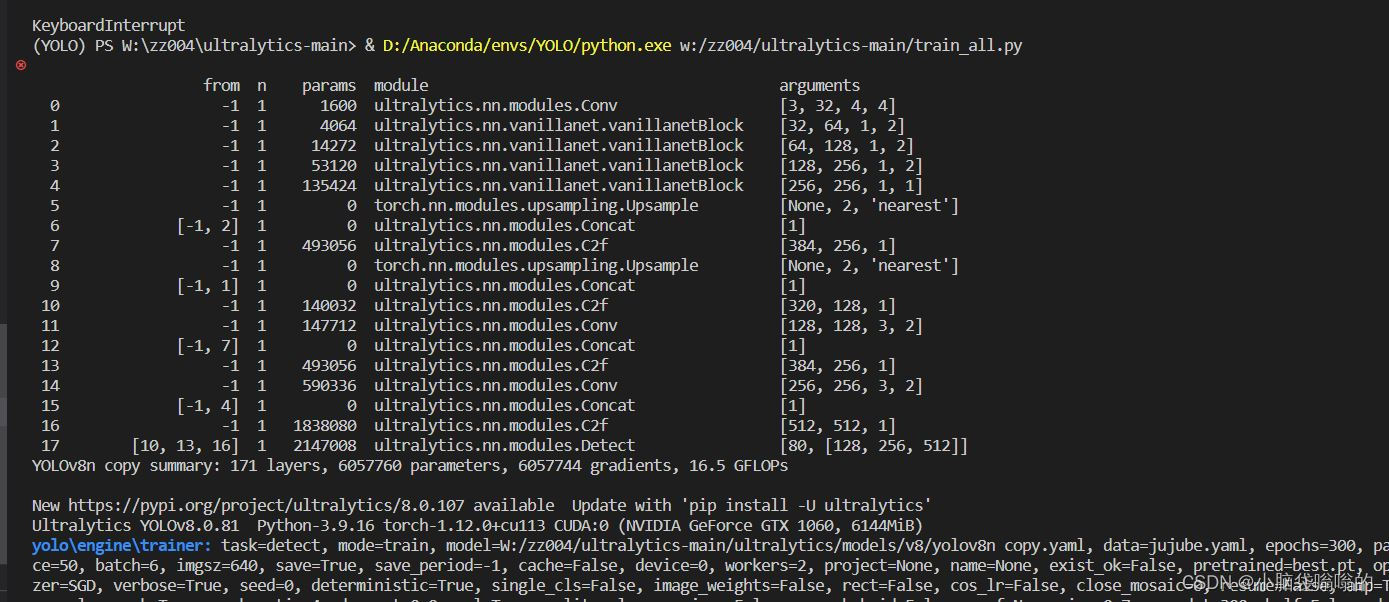
运行训练即可















 2448
2448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









