



本文涉及所有项目源码及笔记分享如下:
链接: https://pan.baidu.com/s/1eoZk_CcpSae_5jhE5aEuAw?pwd=7kcb 提取码: 7kcb
1.快速入门及底层原理
简介
LangChain是一个开源的PythonAl应用开发框架,它提供了构建基于大模型的Al应用所需的模块和工具。通过LangChain,开发者可以轻松地与大型语言模型(LLM)集成,完成文本生成、问答、翻译、对话等任务。LangChain降低了AI应用开发的门槛,让任何人都可以基于LLM构建属于自己的创意应用。
LangChain特性:
- LLM和提示(Prompt):LangChain对所有LLM大模型进行了API抽象,统一了大模型访问API,同时提供了Prompt提示模板管
理机制。 - 链(Chain):Langchain对一些常见的场景封装了一些现成的模块,例如:基于上下文信息的问答系统,自然语言生成SQL查询等等,因为这些任务的过程就像工作流一样,一步一步的执行,所以叫链(chain)。
- LCEL:LangChainExpressionLanguage(LCEL),langchain新版本的核心特性,用于解决工作流编排问题,通过LCEL表达式,我们
可以灵活的自定义AI任务处理流程,也就是灵活自定义链(Chain)。 - 数据增强生成(RAG):因为大模型(LLM)不了解新的信息,无法回答新的问题,所以我们可以将新的信息导入到LLM,用于增强LLM生成内容的质量,这种模式叫做RAG模式(RetrievalAugmentedGeneration)。
- Agents:是一种基于大模型的应用设计模式,利用LLM的自然语言理解和推理能力,根据用户的需求自动调用外部系统、设备共同去完成任务,例如:用户输入“明天请假一天”,大模型(LLM)自动调用请假系统,发起一个请假申请。
- 模型记忆(memory):让大模型(llm)记住之前的对话内容,这种能力成为模型记忆(memory)。
LangChain框架组成

包括四个部分
LangChain框架由几个部分组成,包括:
- LangChain库:Python库和JavaScript库。包含接口和集成多种组件的运行时基础,以及线程的链和代理的实现。
- LangChain模板:Langchain官方提供的一些Al任务模板。
- LangServe:基于FastAPl可以将Langchain定义的链(Chain),发布成为RESTAPl。
- LangSmith:开发平台,是个云服务,支持Langchaindebug、任务监控。
LangChain库(Libraries)
LangChain库本身由几个不同的包组成。
- langchain-core:基础抽象和LangChain表达语言。
- langchain-community:第三方集成,主要包括langchain集成的第三方组件。
- langchain:主要包括链(chain)、代理(agent)和检索策略。
LangChain任务处理流程
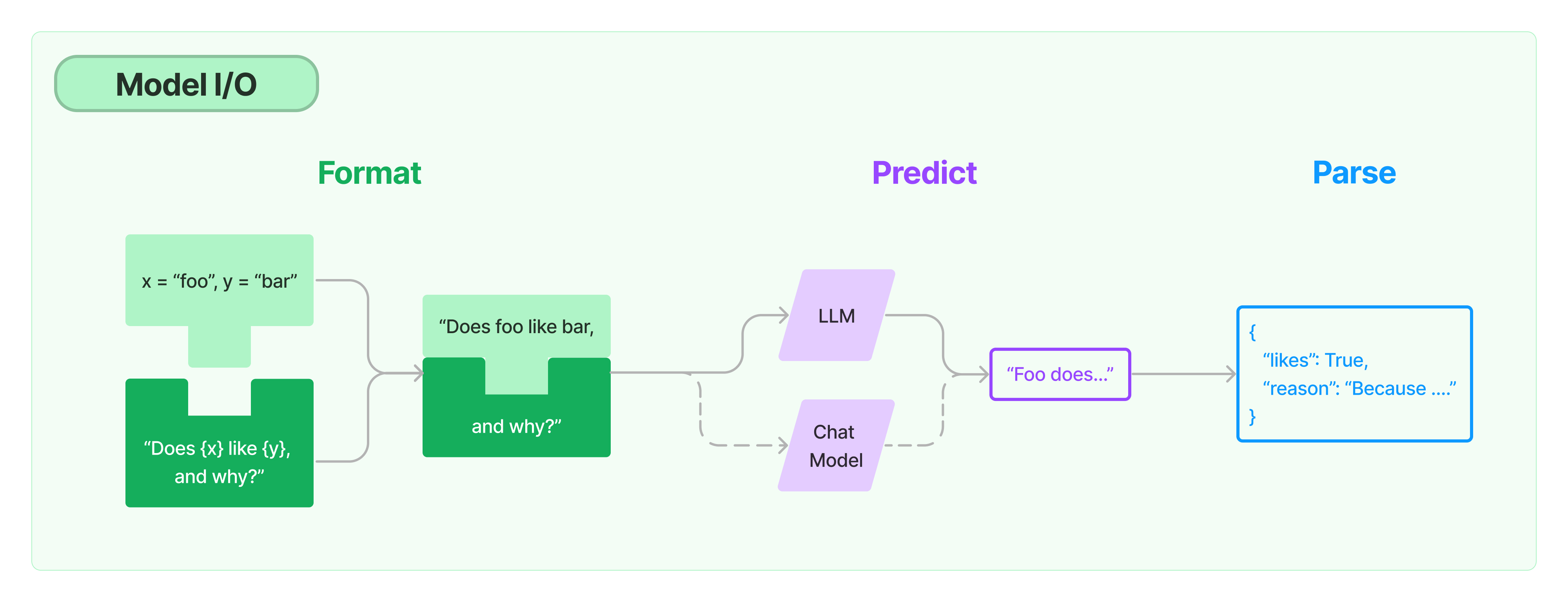
左侧为模板,把用户的问题放到模板中,然后放到模板里面组成提示词,交给后面的Chat Model进行对话处理,然后再经过Parse解析器将回答进行整理
如上图,langChain提供一套提示词模板(prompttemplate)管理工具,负责处理提示词,然后传递给大模型处理,最后处理大模型返回的结果,LangChain对大模型的封装主要包括LLM和Chat Model 两种类型。
- LLM-问答模型,模型接收一个文本输入,然后返回一个文本结果。
- Chat Model - 对话模型,接收一组对话消息,然后返回对话消息,类似聊天消息一样。
核心概念
-
LLMs:LangChain封装的基础模型,模型接收一个文本输入,然后返回一个文本结果。
-
ChatModels:聊天模型(或者成为对话模型),与LLMs不同,这些模型专为对话场景而设计。模型可以接收一组对话消息,然后返回对话消息,类似聊天消息一样。
-
消息(Message):指的是聊天模型(ChatModels)的消息内容,消息类型包括包括HumanMessage、AIMessage、SystemMessage、FunctionMessage和ToolMessage等多种类型的消息。
-
提示(prompts):LangChain封装了一组专门用于提示词(prompts)管理的工具类,方便我们格式化提示词(prompts)内容。
输出解析器(OutputParsers):将llm输出的内容转成python对象。
-
Retrievers:为方便我们将私有数据导入到大模型(LLM),提高模型回答问题的质量,LangChain封装了检索框架(Retrievers),切割文档数据、存储和检索文档数据。
-
向量存储(Vector stores):为支持私有数据的语义相似搜索,langchain支持多种向量数据库。
-
Agents:是一种以大模型(LLM)为核心的应用设计模式。
快速入门
安装LangChain
要安装LangChain,可以使用pip和Conda进行安装,以下是步骤(使用pip)
pip install langchain
在使用LangChain之前,需要导入LangChain×OpenAl集成包,并设置API密钥作为环境变量或直接传递给OpenAl LLM类。
首先,获取OpenAI的API密钥,可以通过创建账户并访问此链接来获取。然后,可以将API密钥设置为环境变量,方法如下:
export OPENAI_API_KEY = "YOUR_API_KEY"
接下来初始化模型
from langchain_openai import ChatOpenAI
11m = ChatOpenAI()
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
QWEN_API_KEY ="sk-*************************"
QWEN_API_URI ="https://dashscope.aliyuncs.com/compatible-mode/v1"
model = ChatOpenAI(api_key=QWEN_API_KEY,
base_url=QWEN_API_URI,
model="qwen-long",
)
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant."),
("human", "{input}")
])
chain = prompt | model
response = chain.invoke({"input": "帮我写一篇100字的ai技术文章"})
print(response)

from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
QWEN_API_KEY = "sk-**************"
QWEN_API_URI = "https://dashscope.aliyuncs.com/compatible-mode/v1"
model = ChatOpenAI(
api_key=QWEN_API_KEY,
base_url=QWEN_API_URI,
model="qwen-long",
)
prompt = ChatPromptTemplate.from_messages(
[("system", "You are a helpful assistant."), ("human", "{input}")]
)
# 加上一个输出解析器则输出只有content
output_parser = StrOutputParser()
chain = prompt | model | output_parser
response = chain.invoke({"input": "帮我写一篇100字的ai技术文章"})
print(response)

2.提示词工程应用实践
目的是指导大模型的输出,让他的输出内容更加的准确
语言模型以文本作为输入-这个文本通常被称为提示词(prompt)。在开发过程中,对于提示词通常不能直接硬编码,不利于提示词管理,而是通过提示词模板进行维护,类似开发过程中遇到的短信模板、邮件模板等等。
提示词模板就是一个字符串模板,模板可以包含一组模板参数,参数值可以进行替换
一个提示词模板可以包含以下内容:
- 发给LLM的指令
- 一组问答,来提醒模型以什么格式进行返回请求
- 发给语言的问题
创建一个提示词模板
字符串提示词模板,使用PromptTemplate
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template(
"给我将一个关于{content}的{objective}笑话"
)
message = prompt_template.format(content="猴子", objective="冷")
print(message)
# 给我将一个关于猴子的冷笑话
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
prompt_template = PromptTemplate.from_template(
"给我将一个关于{content}的{objective}笑话"
)
QWEN_API_KEY = "sk-*******************"
QWEN_API_URI = "https://dashscope.aliyuncs.com/compatible-mode/v1"
model = ChatOpenAI(
api_key=QWEN_API_KEY,
base_url=QWEN_API_URI,
model="qwen-long",
)
# 使用具体的输出解析器
# 如果没有初始化StrOutputParser,则需要写成StrOutputParser()
chain = prompt_template | model | StrOutputParser()
message = chain.invoke({"content": "猴子", "objective": "冷"})
print(message)
聊天提示词模板,使用ChatTemplate
from langchain_core.prompts import ChatPromptTemplate
# 使用template创建message
# 数组中的每个元素都是一个元组,元组的第一个元素是角色(system, human, assistant),第二个元素是对应的消息内容
chat_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant."),
("human", "{input}"),
("assistant", "{output}")
])
messages = chat_template.format_messages(name="ChatGPT", input="你好,AI!", output="你好!Bob!")
print(messages)
# 控制台打印信息报文:[SystemMessage(content='You are a helpful assistant.', additional_kwargs={}, response_metadata={}), HumanMessage(content='你好,AI!', additional_kwargs={}, response_metadata={}), AIMessage(content='你好!Bob!', additional_kwargs={}, response_metadata={})]
另外一种对象引用的消息格式的例子(常用,因为更清晰)
from langchain_core.messages import SystemMessage
from langchain_core.prompts import ChatPromptTemplate
from langchain.prompts import HumanMessagePromptTemplate
chat_template = ChatPromptTemplate.from_messages([
SystemMessage(
content=(
"You are a helpful assistant that can answer questions about the LangChain library."
)
),
HumanMessagePromptTemplate.from_template("{text}")
])
# 使用模板参数格式化模板
messages = chat_template.format_messages(text="What is LangChain?")
print(messages)
# [SystemMessage(content='You are a helpful assistant that can answer questions about the LangChain library.', additional_kwargs={}, response_metadata={}), HumanMessage(content='What is LangChain?', additional_kwargs={}, response_metadata={})]
MessagePlaceHolder
类似于消息占位符,比如说一些克服软件在用户刚刚点进来的时候就会给出提示
这个提示模板负责在特定位置添加消息列表。在上面的ChatPromptTemplate中,我们看到了如何格式化两条消息,每条消息都是一个字符串。但是,如果我们希望用户传入一个消息列表,我们将其插入到特定位置,该怎么办?这就是您使用MessagesPlaceholder的方式。
from langchain_core.messages import HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
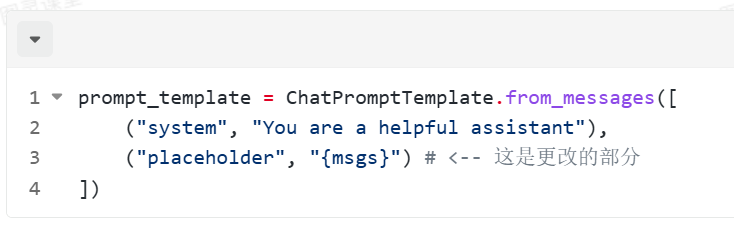
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant."),
MessagesPlaceholder("content")
])
result = prompt_template.invoke({"content": [HumanMessage(content="你好,AI!"), HumanMessage(content="你好!Bob!")]})
print(result)
这将生成两条消息,第一条是系统消息,第二条是我们传入的HumanMessage。如果我们传入了5条消息,那么总共会生成6条消息(系统消息加上传入的5条消息)。这对于将一系列消息插入到特定位置非常有用。另一种实现相同效果的替代方法是,不直接使用MessagesPlaceholder类,而是:
提示词追加示例(Few-Shot prompt templates)
提示词中包含交互样本的作用是为了帮助模型更好地理解用户的意图,从而更好地回答问题或执行任务。小样本提示模板是指使用一组少量的示例来指导模型处理新的输入。这些示例可以用来训练模型,以便模型可以更好地理解和回答类似的问题。
例子:
Q:什么是蝙蝠侠?
A:蝙蝠侠是一个虚拟的动漫人物
Q:什么是torsalplexicity
A:未知。
Q:什么是语言模型
A:
告诉模型,Q是问题,A是答案,按照这种格式进行问答交互
下面就是langchain针对在提示词中插入少量交互样本提供的工具类
使用示例集
创建示例集
from langchain.prompts.few_shot import FewShotPromptTemplate
from langchain.prompts.prompt import PromptTemplate
examples = [
{
"question": "谁的寿命更长,穆罕默德·阿里还是艾伦·图灵?",
"answer": """
这里需要跟进问题吗。是的。
跟进:穆罕默德·阿里去世时多大?
中间答案:穆罕默德·阿里去世时74岁。
跟进:文化·图灵去世时多大?
中间答案:文化·图灵去世时41岁。
所以最终答案是:穆罕默德·阿里
"""
},
{
"question": "craigslist的创始人是什么时候出生的?",
"answer": """
这里需要跟进问题吗。是的。
跟进:craigslist的创始人是谁?
中间答案:craigslist由Craig Newmark创立。
跟进:Craig Newmark是什么时候出生的?
中间答案:Craig Newmark于1952年12月6日出生。
所以最终答案是:1952年12月6日
"""
},
{
"question": "乔治·华盛顿的祖父母中的母亲是谁?",
"answer": """
这里需要跟进问题吗。是的。
跟进:乔治·华盛顿的母亲是谁?
中间答案:乔治·华盛顿的母亲是Mary Ball Washington。
跟进:Mary Ball Washington的父亲是谁?
中间答案:Mary Ball Washington的父亲是Joseph Ball。
所以最终答案是:Joseph Ball
"""
},
{
"question": "《大白鲨》和《皇家赌场》的导演都来自同一个国家吗?",
"answer": """
这里需要跟进问题吗。是的。
跟进:《大白鲨》的导演是谁?
中间答案:《大白鲨》的导演是Steven Spielberg。
跟进:Steven Spielberg来自哪里?
中间答案:美国。
跟进:《皇家赌场》的导演是谁?
中间答案:《皇家赌场》的导演是Martin Campbell。
跟进:Martin Campbell来自哪里?
中间答案:新西兰。
所以最终答案是:不是
"""
}
]
创建小样本示例的格式化程序
example_prompt = PromptTemplate(input_variables=["question", "answer"], template="问题: {question}\\n{answer}")
# “**”可以格式化字符串
print(example_prompt.format(**examples[0]))
#
问题: 谁的寿命更长,穆罕默德·阿里还是艾伦·图灵?\n
这里需要跟进问题吗。是的。
跟进:穆罕默德·阿里去世时多大?
中间答案:穆罕默德·阿里去世时74岁。
跟进:文化·图灵去世时多大?
中间答案:文化·图灵去世时41岁。
所以最终答案是:穆罕默德·阿里
将示例和格式化程序提供给FewShotPromptTemplate
# 接收examples示例数组参数,通过example_prompt提示词模板批量渲染示例内容
# suffix和input_variables参数用于在提示词模板最后追加内容,input_variables用于定义suffix中包含的模板参数
prompt = FewShotPromptTemplate(
examples = examples,
example_prompt=example_prompt,
suffix = "问题:{input}",
input_variables=["input"],
)
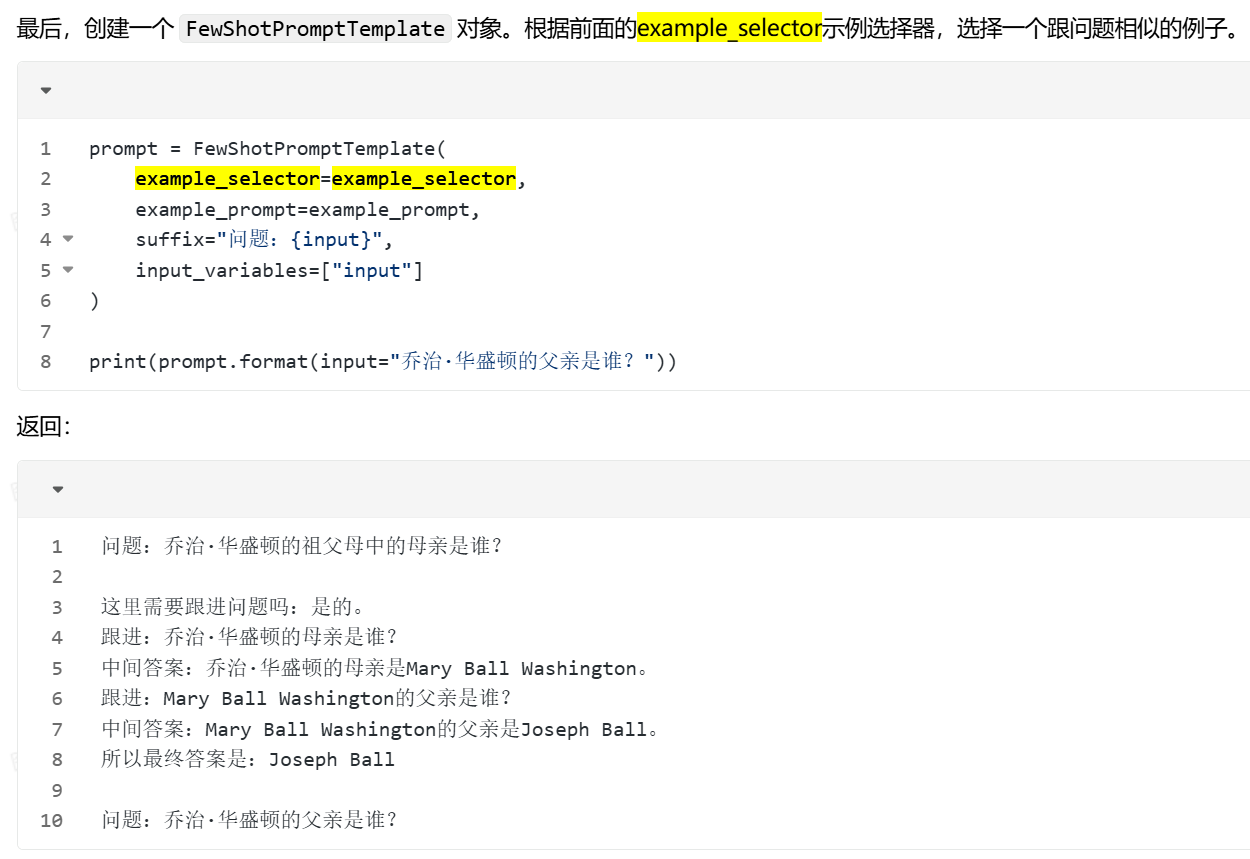
print(prompt.format(input="乔治·华盛顿的父亲是谁?"))
问题: 谁的寿命更长,穆罕默德·阿里还是艾伦·图灵?\n
这里需要跟进问题吗。是的。
跟进:穆罕默德·阿里去世时多大?
中间答案:穆罕默德·阿里去世时74岁。
跟进:文化·图灵去世时多大?
中间答案:文化·图灵去世时41岁。
所以最终答案是:穆罕默德·阿里
问题: 谁的寿命更长,穆罕默德·阿里还是艾伦·图灵?\n
这里需要跟进问题吗。是的。
跟进:穆罕默德·阿里去世时多大?
中间答案:穆罕默德·阿里去世时74岁。
跟进:文化·图灵去世时多大?
中间答案:文化·图灵去世时41岁。
所以最终答案是:穆罕默德·阿里
问题: craigslist的创始人是什么时候出生的?\n
这里需要跟进问题吗。是的。
跟进:craigslist的创始人是谁?
中间答案:craigslist由Craig Newmark创立。
跟进:Craig Newmark是什么时候出生的?
中间答案:Craig Newmark于1952年12月6日出生。
所以最终答案是:1952年12月6日
问题: 乔治·华盛顿的祖父母中的母亲是谁?\n
这里需要跟进问题吗。是的。
跟进:乔治·华盛顿的母亲是谁?
中间答案:乔治·华盛顿的母亲是Mary Ball Washington。
跟进:Mary Ball Washington的父亲是谁?
中间答案:Mary Ball Washington的父亲是Joseph Ball。
所以最终答案是:Joseph Ball
问题: 《大白鲨》和《皇家赌场》的导演都来自同一个国家吗?\n
这里需要跟进问题吗。是的。
跟进:《大白鲨》的导演是谁?
中间答案:《大白鲨》的导演是Steven Spielberg。
跟进:Steven Spielberg来自哪里?
中间答案:美国。
跟进:《皇家赌场》的导演是谁?
中间答案:《皇家赌场》的导演是Martin Campbell。
跟进:Martin Campbell来自哪里?
中间答案:新西兰。
所以最终答案是:不是
问题:乔治·华盛顿的父亲是谁?
使用示例选择器(向量相似度匹配,类似于RAG)
将示例提供给ExampleSelector
主要目的是节约成本,因为有的大模型是有token限制的,不能有过长的上下文,也不能有超出token的限制
将示例提供给ExampleSelector
这里重用前一部分中的示例集和提示词模板(prompttemplate)。但是,不会将示例直接提供给 FewShotPromptTemplate对象,把全部示例插入到提示词中,而是将它们提供给一个 ExampleSelector对象,插入部分示例
这里我们使用SemanticSimilarityExampleSelector类。该类根据与输入的相似性选择小样本示例。它使用嵌入模型计算输入和小样本示例之间的相似性,然后使用向量数据库执行相似搜索,获取跟输入相似的示例。下面的例子就是找到和问题“乔治·华盛顿的父亲是谁?“最相似的示例
- 提示:这里涉及向量计算、向量数据库,在A领域这两个主要用于数据相似度搜索,例如:查询相似文章内容、相似的图片、视频等等,这里先简单了解下就行。
examples = [
{
"question": "谁的寿命更长,穆罕默德·阿里还是艾伦·图灵?",
"answer": """
这里需要跟进问题吗。是的。
跟进:穆罕默德·阿里去世时多大?
中间答案:穆罕默德·阿里去世时74岁。
跟进:文化·图灵去世时多大?
中间答案:文化·图灵去世时41岁。
所以最终答案是:穆罕默德·阿里
"""
},
{
"question": "craigslist的创始人是什么时候出生的?",
"answer": """
这里需要跟进问题吗。是的。
跟进:craigslist的创始人是谁?
中间答案:craigslist由Craig Newmark创立。
跟进:Craig Newmark是什么时候出生的?
中间答案:Craig Newmark于1952年12月6日出生。
所以最终答案是:1952年12月6日
"""
},
{
"question": "乔治·华盛顿的祖父母中的母亲是谁?",
"answer": """
这里需要跟进问题吗。是的。
跟进:乔治·华盛顿的母亲是谁?
中间答案:乔治·华盛顿的母亲是Mary Ball Washington。
跟进:Mary Ball Washington的父亲是谁?
中间答案:Mary Ball Washington的父亲是Joseph Ball。
所以最终答案是:Joseph Ball
"""
},
{
"question": "《大白鲨》和《皇家赌场》的导演都来自同一个国家吗?",
"answer": """
这里需要跟进问题吗。是的。
跟进:《大白鲨》的导演是谁?
中间答案:《大白鲨》的导演是Steven Spielberg。
跟进:Steven Spielberg来自哪里?
中间答案:美国。
跟进:《皇家赌场》的导演是谁?
中间答案:《皇家赌场》的导演是Martin Campbell。
跟进:Martin Campbell来自哪里?
中间答案:新西兰。
所以最终答案是:不是
"""
}
]
import os
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# 设置 DeepSeek API 配置
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
# 使用 OpenAI 的嵌入模型
embeddings = OpenAIEmbeddings(
api_key="sk-*",
base_url="https://api.openai-*",
model="text-embedding-ada-002" # 或者 OpenAI 支持的其他嵌入模型
)
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples, # 这是可供选择的示例列表
# 这是用于生成嵌入的嵌入类,该嵌入用于衡量语义相似性。
OpenAIEmbeddings(),
# 这是用于存储嵌入和执行相似性搜索的VectorStore类。Chroma是开源的向量数据库
Chroma,
# 这是要生成的示例数。
k=1
)
# 选择与输入最相似的示例。
question = "乔治·华盛顿的父亲是谁?"
selected_examples = example_selector.select_examples({"question": question})
print(f"最相似的示例: {question}")
for example in selected_examples:
print("\n")
for k, v in example.items():
print(f"{k}: {v}")

将示例选择器提供给 FewShotPromptTemplate
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
examples = [
{
"question": "谁的寿命更长,穆罕默德·阿里还是艾伦·图灵?",
"answer": """
这里需要跟进问题吗。是的。
跟进:穆罕默德·阿里去世时多大?
中间答案:穆罕默德·阿里去世时74岁。
跟进:文化·图灵去世时多大?
中间答案:文化·图灵去世时41岁。
所以最终答案是:穆罕默德·阿里
"""
},
{
"question": "craigslist的创始人是什么时候出生的?",
"answer": """
这里需要跟进问题吗。是的。
跟进:craigslist的创始人是谁?
中间答案:craigslist由Craig Newmark创立。
跟进:Craig Newmark是什么时候出生的?
中间答案:Craig Newmark于1952年12月6日出生。
所以最终答案是:1952年12月6日
"""
},
{
"question": "乔治·华盛顿的祖父母中的母亲是谁?",
"answer": """
这里需要跟进问题吗。是的。
跟进:乔治·华盛顿的母亲是谁?
中间答案:乔治·华盛顿的母亲是Mary Ball Washington。
跟进:Mary Ball Washington的父亲是谁?
中间答案:Mary Ball Washington的父亲是Joseph Ball。
所以最终答案是:Joseph Ball
"""
},
{
"question": "《大白鲨》和《皇家赌场》的导演都来自同一个国家吗?",
"answer": """
这里需要跟进问题吗。是的。
跟进:《大白鲨》的导演是谁?
中间答案:《大白鲨》的导演是Steven Spielberg。
跟进:Steven Spielberg来自哪里?
中间答案:美国。
跟进:《皇家赌场》的导演是谁?
中间答案:《皇家赌场》的导演是Martin Campbell。
跟进:Martin Campbell来自哪里?
中间答案:新西兰。
所以最终答案是:不是
"""
}
]
import os
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# 设置 DeepSeek API 配置
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
# 使用 OpenAI 的嵌入模型
embeddings = OpenAIEmbeddings(
api_key="sk-*",
base_url="https://api.openai-*",
model="text-embedding-ada-002" # 或者 OpenAI 支持的其他嵌入模型
)
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples, # 这是可供选择的示例列表
# 这是用于生成嵌入的嵌入类,该嵌入用于衡量语义相似性。
OpenAIEmbeddings(),
# 这是用于存储嵌入和执行相似性搜索的VectorStore类。Chroma是开源的向量数据库
Chroma,
# 这是要生成的示例数。
k=1
)
example_prompt = PromptTemplate(input_variables=["question", "answer"], template="问题: {question}\\n{answer}")
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
suffix="问题: {input}",
input_variables=["input"]
)
print(prompt.format(input="乔治·华盛顿的父亲是谁? "))
3.LangChain工作流编排
LCEL介绍
langchain表达式语言是LCEL
LCEL(LangChain Expression Language)是一种强大的工作流编排工具,可以从基本组件构建复杂任务链(chain),并支持诸如流式处理、并行处理和日志记录等开箱即用的功能。
LCEL从第一天起就被设计为支持将原型投入生产,无需更改代码,从最简单的“"提示+LLM”链到最复杂的链(我们已经看到有人成功地在生产中运行了包含数百步的LCL链)。以下是您可能想要使用LCL的一些原因的几个亮点:
一流的流式支持:当您使用LCL构建链时,您将获得可能的最佳时间到第一个标记(直到输出的第一块内容出现所经过的时间)。对于某些链,这意味着我们直接从LLM流式传输标记到流式输出解析器,您将以与LLM提供程序输出原始标记的速率相同的速度获得解析的增量输出
块。
异步支持:使用LCEL构建的任何链都可以使用同步API(例如,在您的upyter笔记本中进行原型设计)以及异步API(例如,在LangServe服务器中)进行调用。这使得可以在原型和生产中使用相同的代码,具有出色的性能,并且能够在同一服务器中处理许多并发请求。
优化的并行执行:每当您的LCL链具有可以并行执行的步骤时(例如,如果您从多个检索器中获取文档),我们会自动执行,无论是在同步接口还是异步接口中,以获得可能的最小延迟
重试和回退:为LCEL链的任何部分配置重试和回退。这是使您的链在规模上更可靠的好方法。我们目前正在努力为重试/回退添加流式支持这样您就可以获得额外的可靠性而无需任何延迟成本。
访问中间结果:对于更复杂的链,访问中间步骤的结果通常非常有用,即使在生成最终输出之前。这可以用于让最终用户知道正在发生的事情,甚至只是用于调试您的链。您可以流式传输中间结果,并且在每个LangServe服务器上都可以使用。
输入和输出模式:输入和输出模式为每个LCEL链提供了从链的结构推断出的Pydantic和JSONSchema模式。这可用于验证输入和输出,并且是LangServe的一个组成部分。
Runnable Interface
为了尽可能简化创建自定义链的过程,我们实现了一个"Runnable"协议。许多LangChain组件都实现了Runnable协议,包括聊天模型、LLMs、输出解析器、检索器、提示模板等等。此外,还有一些有用的基本组件可用于处理可运行对象,您可以在下面了解更多。这是一个标准接口,可以轻松定义自定义链,并以标准方式调用它们。以下是同步调用方法,标准接口包括:
- stream:返回响应的数据块,类似于看视频的推流缓冲,有一块出一块
- invoke:对输入调用链,同步调用,没有输出就会一直等待
- batch:对输入列表调用链,批量调用
这些还有相应的异步方法,应该与asyncio(pyhton中一个异步的库)一起使用await语法以实现并发(在上面的方法左侧加一个a):
- astream:异步返回响应的数据块
- ainvoke:异步对输入调用链
- abatch:异步对输入列表调用链
- astream_log:异步返回中间步骤,以及最终响应
- astream events:beta流式传输链中发生的事件(在langchain-core0.1.14中引入)
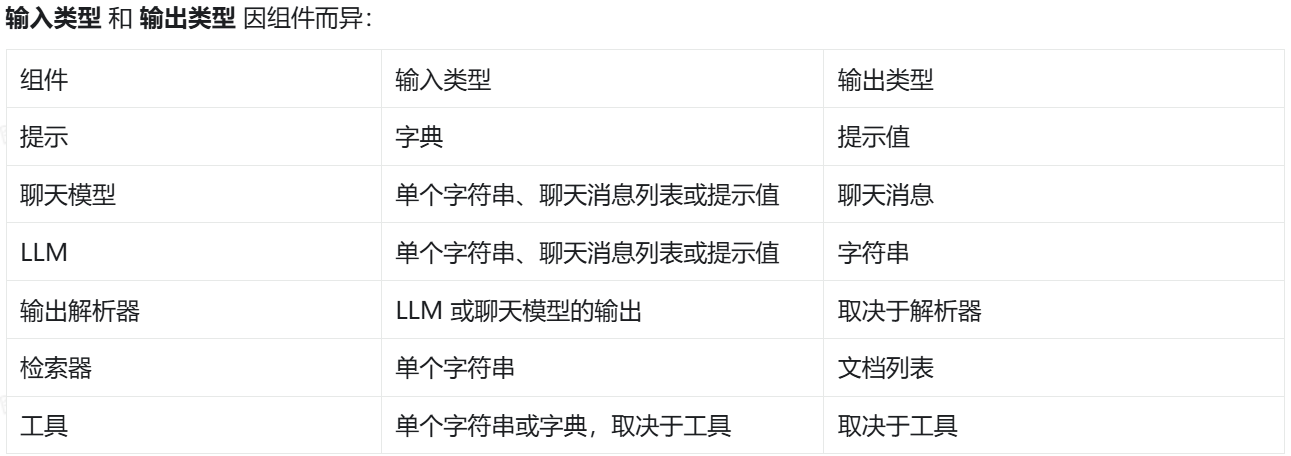
所有可运行对象都公开输入和输出模式以检查输入和输出:
- input_schema:从可运行对象结构自动生成的输入Pydantic模型
- output_schema:从可运行对象结构自动生成的输出Pydantic模型
流式运行对于使基于LLM的应用程序对最终用户具有响应性至关重要。重要的LangChain原语,如聊天模型、输出解析器、提示模板、检索器和代理都实现了LangChain Runnable接口。该接口提供了两种通用的流式内容方法:
1.同步stream和异步astream:流式传输链中的最终输出的默认实现
2.异步astream_events和异步astream_log:这些方法提供了一种从链中流式传输中间步骤和最终输出的方式。让我们看看这两种方法,并尝试理解如何使用它们。
Stream(流)
astream是异步的流式调用,分为同步和异步两种方式
所有Runnable对象都实现了一个名为stream的同步方法和一个名为astream的异步变体。这些方法旨在以块的形式流式传输最终输出,尽快返回每个块。只有在程序中的所有步骤都知道如何处理输入流时,才能进行流式传输;即,逐个处理输入块,并产生相应的输出块。这种处理的复杂性可以有所不同,从简单的任务,如发出LLM生成的令牌,到更具挑战性的任务,如在整个JSON完成之前流式传输JSON结果的部分。开始探索流式传输的最佳方法是从LLM应用程序中最重要的组件开始——LLM本身!
LLM和聊天模型
大型语言模型及其聊天变体是基于LLM的应用程序的主要瓶颈。大型语言模型可能需要几秒钟才能对查询生成完整的响应。这比应用程序对最终用户具有响应性的约200-300毫秒的阈值要慢得多。使应用程序具有更高的响应性的关键策略是显示中间进度;即,逐个令牌流式传输模型的输出。我们将展示使用聊天模型进行流式传输的示例。从以下选项中选择一个:
先从同步的Stream API开始
from langchain_openai import ChatOpenAI
import os
# 设置 DeepSeek API 配置
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
model = ChatOpenAI(model="gpt-4")
chunks = []
for chunk in model.stream("天空是什么颜色?"):
chunks.append(chunk)
print(chunk.content, end="|", flush=True)
使用model.stream相当于流式调用大模型的接口,会返回chunk数据块,比如说我们向大模型提出一个问题,大模型后端也就是服务器端有一个数据传输协议,langchain相当于是一个client,会跟大模型的server端建立一个连接,后端如果是流式传输的话就会通过SSE协议进行传输,那么后端就会把一个个的数据按照一块一块的传输出来,结果如下图所示,这里体现为一个一个的字,像打字机一样输出

为什么会有流式传输,当我们要得到的答案十分长,大模型没办法在短时间内就全部输出出来,所以需要先只能一部分一部分输出,这样就导致流式输出是十分有必要的,优化体验
其中的每一个chunk(代码可以调用chunks[1]来输出),其实是一个个的AIMessageChunk对象
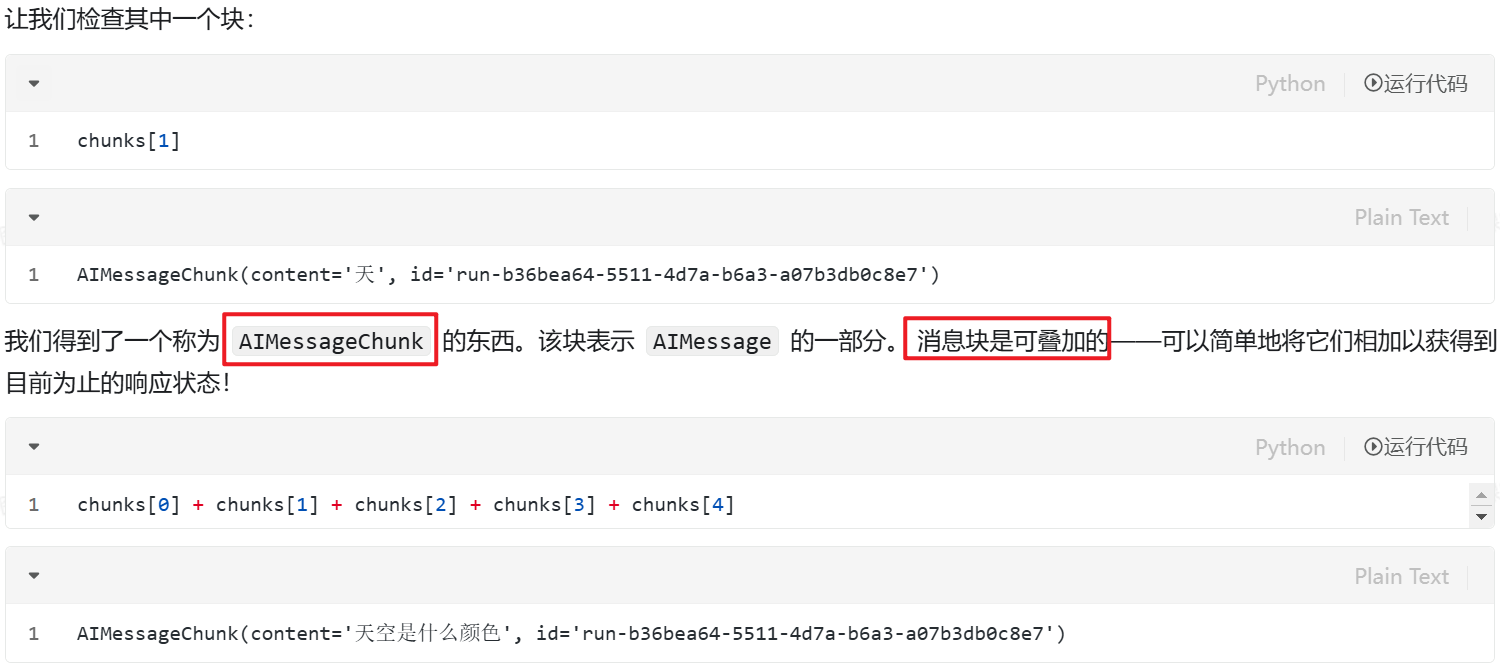
chain(链)
异步调用
几乎所有的LLM应用程序都涉及不止一步的操作,而不仅仅是调用语言模型。让我们使用LangChain表达式语言(LCEL)构建一个简单的链,该链结合了一个提示、模型和解析器,并验证流式传输是否正常工作。我们将使用StrOutputParser来解析模型的输出。这是一个简单的解析器,从AIMessageChunk中提取content字段,给出模型返回的token。
LCEL是一种声明式的方式,通过将不同的LangChain原语链接在一起来指定一个"程序”。使用LCEL创建的链可以自动实现stream和astream,从而实现对最终输出的流式传输。事实上,使用LCEL创建的链实现了整个标准Runnable接口。
要想使用异步的链方式进行调用,就不能直接在main函数里面使用main.stream,这样会报错,报错为不是一个iterable对象
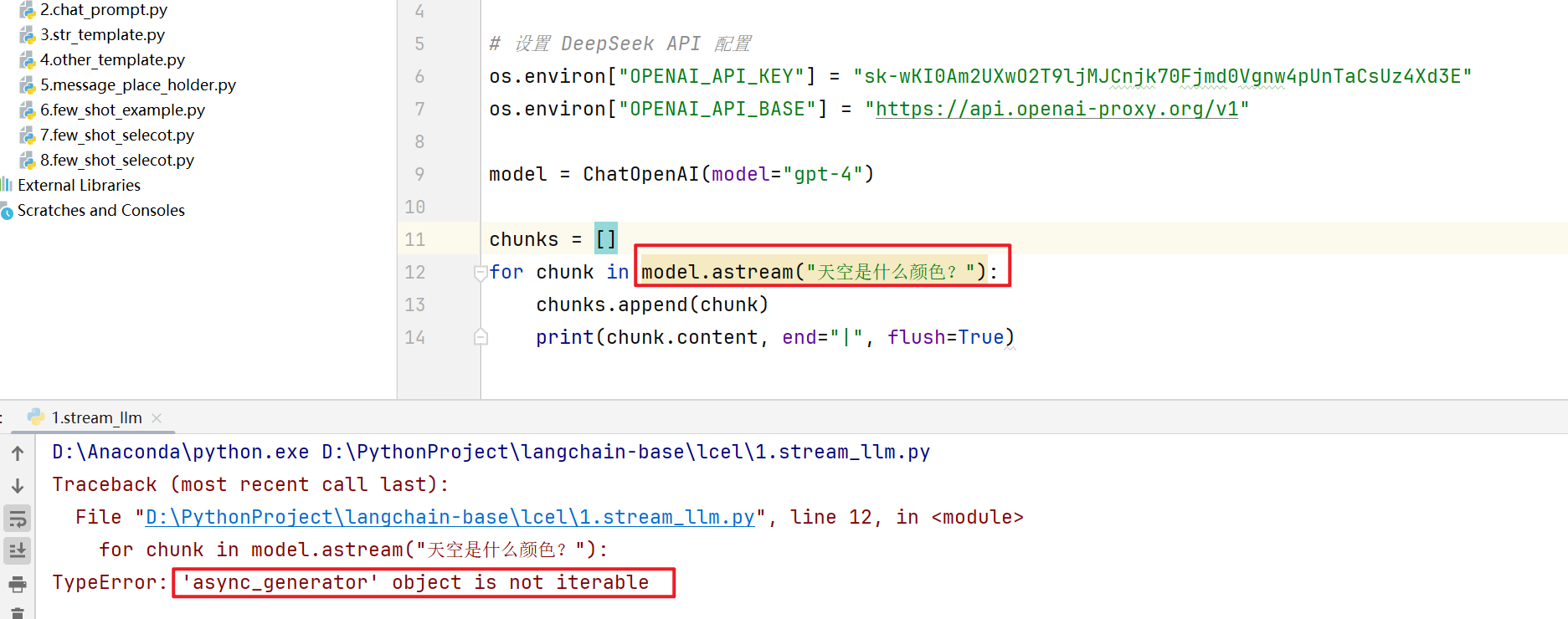
我们需要用到asyncio库,是一个异步的线程库,使用async关键字来声明一个函数,然后在函数里面去执行代码逻辑
from langchain_openai import ChatOpenAI
import os
import asyncio
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 设置 OPENAI API 配置
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
prompt = ChatPromptTemplate.from_template("给我讲一个关于{content}的笑话")
model = ChatOpenAI()
parse = StrOutputParser()
chain = prompt | model | parse
# 在 Windows 上设置事件循环策略
if os.name == 'nt': # Windows
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
async def async_stream():
async for chunk in chain.astream({"content": "猫"}):
# 因为我们使用了StrOutputParser,所以不需要使用取content了,因为chunk直接拿到的就是一个字符串,StrOutputParser会把chunk对象转换成一个字符串
print(chunk, end="|", flush=True)
# 运行异步函数
asyncio.run(async_stream())

如果我们定义两个异步方法,然后去同时执行,就会看到内容会串在一起
from langchain_openai import ChatOpenAI
import os
import asyncio
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 设置 OPENAI API 配置
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
prompt = ChatPromptTemplate.from_template("给我讲一个关于{content}的笑话")
model = ChatOpenAI()
parse = StrOutputParser()
chain = prompt | model | parse
# 在 Windows 上设置事件循环策略
if os.name == 'nt': # Windows
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
async def async_stream1():
async for chunk in chain.astream({"content": "猫"}):
print(chunk, end="|", flush=True)
async def async_stream2():
async for chunk in chain.astream({"content": "狗"}):
print(chunk, end="|", flush=True)
# async def main():
# # 按顺序调用,下面的两个任务会按照顺序执行
# await async_stream1()
# await async_stream2()
# 运行异步函数
async def main():
# 并发执行,输出会混合在一起
await asyncio.gather(
async_stream1(),
async_stream2()
)
asyncio.run(main())

使用输入流
比如输入的时候转换的是一个字符串,现在想让他在转换的时候动态输出一个json
import asyncio
import os
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.output_parsers import StrOutputParser
# 设置 OPENAI API 配置
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
# 在 Windows 上设置事件循环策略
if os.name == 'nt': # Windows
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
model = ChatOpenAI()
parser = StrOutputParser()
# 使用的是JsonOutputParser输出JSON格式
chain = (model | JsonOutputParser())
async def async_stream():
async for text in chain.astream(
"以JSON格式输出法国、西班牙和日本的国家及其人口列表。"
'使用一个带有“countries”外部键的字典,其中包含国家列表。'
"每个国家都应该有键`name`和`population`"
):
print(text, flush=True)
asyncio.run(async_stream())
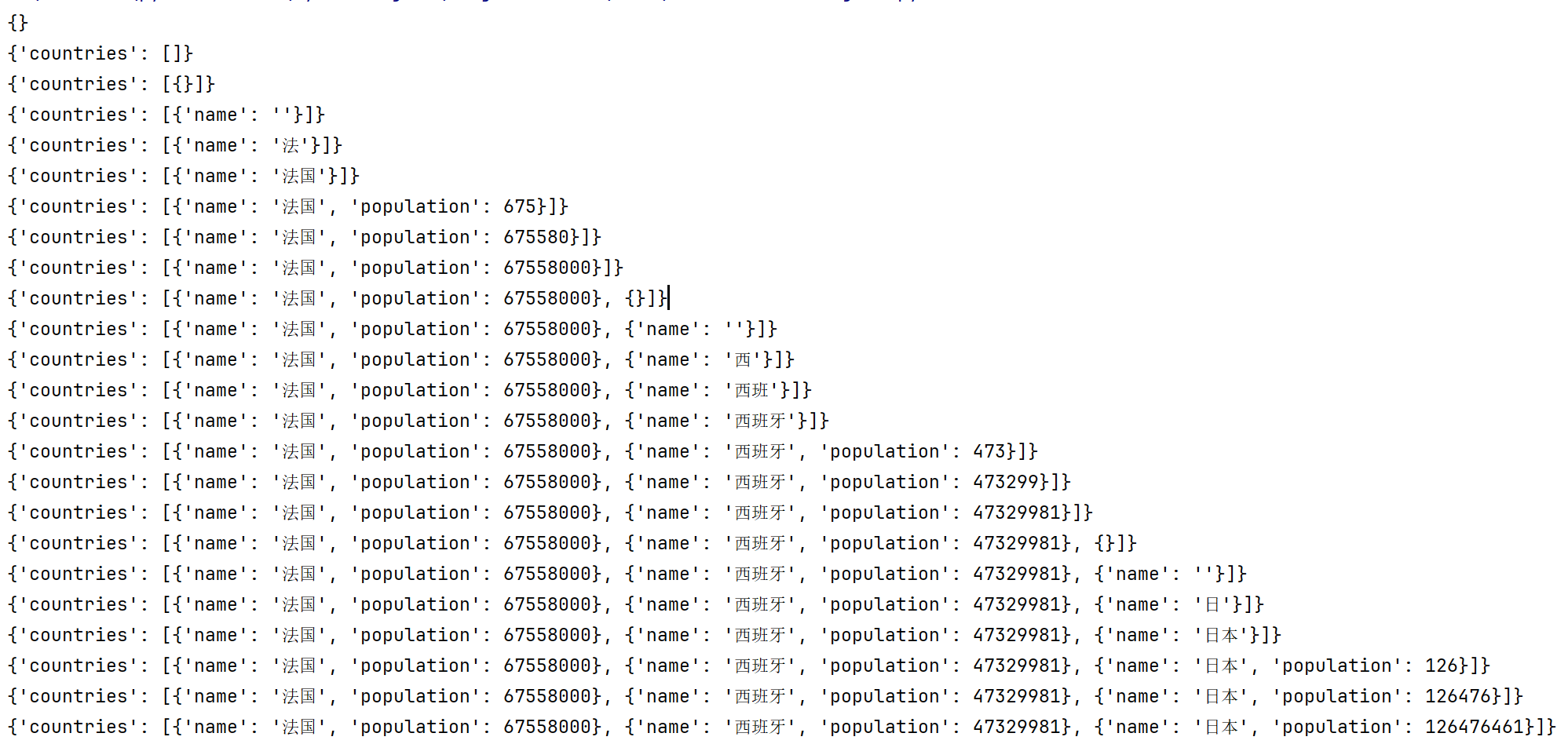
Stream Event(事件流)
做事件监控,知晓调用流程
在与大模型进行对话的时候,会发生一系列的事件,通过astream_events方法可以查看到一次调用背后发生了什么事件;所以在开发过程中排查问题的时候,想要知道是哪个环节出问题的话,可以在各种事件上加一些日志的打印,从而知道问题所在
from langchain_openai import ChatOpenAI
import asyncio
import os
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
model = ChatOpenAI()
async def async_stream():
events = []
async for event in model.astream_events("hello", version="v2"):
events.append(event)
print(events)
asyncio.run(async_stream())

4.Langchain服务部署与链路监控
LangChain服务部署
类似于django,有自己的创建app的方式
LangChain链路监控
与构建任何类型的软件一样,使用LLM构建时,总会有调试的需求。模型调用可能会失败,模型输出可能格式错误,或者可能存在一些嵌套的模型调用,不清楚在哪一步出现了错误的输出。有三种主要的调试方法:
- 详细模式(Verbose):为你的链中的“重要”事件添加打印语句。
- 调试模式(Debug):为你的链中的所有事件添加日志记录语句。
- LangSmithi跟踪:将事件记录到LangSmith,以便在那里进行可视化。

LangSmith Tracing(跟踪)
使用LangChain构建的许多应用程序将包含多个步骤,其中包含多次LLM调用。随着这些应用程序变得越来越复杂,能够检查链或代理内部发生了什么变得至关重要。这样做的最佳方式是使用LangSmith。在上面的链接上注册后,请确保设置你的环境变量以开始记录跟踪:
LangSmith官网:https:/smith.langchain.com/
tavily官网:https:/tavily.com/
#windows导入环境变量
#配置LangSmith监控开关,true开启,fa1se关闭
setx LANGCHAIN_TRACING_V2 "true"
#配置LangSmith api key
setx LANGCHAIN_API KEY ".."
#配置taily api key
setx TAVILY_API KEY "..."
#mac导入环境变量
export LANGCHAIN_TRACING V2="true"
export LANGCHAIN_API_KEY="..."
export TAVILY_API_KEY="..."
假设我们有一个代理,并且希望可视化它所采取的操作和接收到的工具输出。在没有任何调试的情况下,这是我们看到的:
import os
from langchain_openai import ChatopenAI
from langchain.agents import AgentExecutor,create_tool_calling_agent
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.prompts import ChatPromptTemplate
from langchain.globals import set_verbose
llm = ChatopenAI(model="gpt-4o")
tools = [TavilySearchResults(max_results=1)]
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是一位得力的助手。"
),
("placeholder","{chat_history}"),
("human","{input}"),
("placeholder","{agent_scratchpad}"),
]
#构建工具代理
agent = create_tool_calling_agent(11m,tools,prompt)
set_verbose(True)
#通过传入代理和工具来创建代理执行器
agent_executor = AgentExecutor(agent=agent,tools=tools)
agent_executor.invoke(
{"input":"谁执导了2a23年的电影《奥本海默》,他多少岁了?"}
)
{'input':'谁执导了2823年的电影《奥本海默》,他多少岁了?','output':'克里斯托弗·诺兰(Christopher Nolan)出生于1978年7月38日。
截至2023年,他53岁。}
我们没有得到太多输出,但由于我们设置了LangSmith,我们可以轻松地看到发生了什么:https:/smith.langchain.com/public/a89ff88f-9ddc-4757-a395-3a1b365655bf/r
Verbose(详细日志打印)
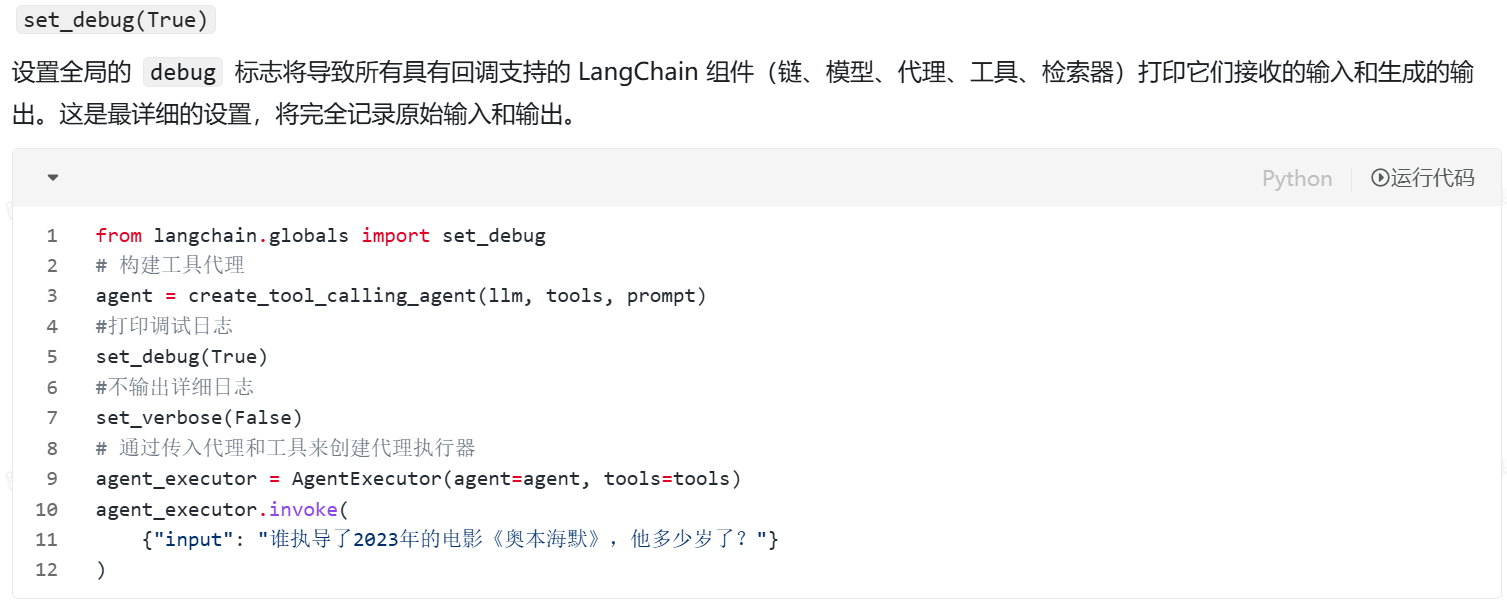
如果你在Jupyter笔记本中进行原型设计或运行Python脚本,打印出链运行的中间步骤可能会有所帮助。有许多方法可以以不同程度的详细程度启用打印。注意:即使启用了LangSmith,这些仍然有效,因此你可以同时打开并运行它们。**set verbose(True)**设置verbose标志将以稍微更易读的格式打印出输入和输出,并将跳过记录某些原始输出(例如LLM调用的令牌使用统计信息),以便您可以专注于应用程序逻辑。
from langchain.globals import set_verbose
set_verbose(True)
agent_executor = AgentExecutor(agent=agent,tools=tools)
agent_executor.invoke(
{"input":"Who directed the 2023 film Oppenheimer and what is their age in days?"}
)
>Entering new AgentExecutor chain...
Invoking:tavily_search_results_json'with{'query':'2023 movie Oppenheimer director'}
[{'url''https://www.imdb.com/title/tt15398776/fullcredits/',content''Oppenheimer (2023)cast and crew credits,including actors,actresses,directors,writers and more.Menu...director of photography:behind-the-scenes Jason Gary
... best boy grip ... film loader Luc Poullain ..aerial coordinator'}]
Invoking:tavily_search_results_json with{'query':'Christopher Nolan age'}
[['url':'https://www.nme.com/news/film/christopher-nolan-fans-are-celebrating-his-54th-birthday-youve-changed-things-forever-3779396','content':"Christopher Nolan is 54 Still my fave bit of Nolan trivia:Joey Pantoliano on creating Ralph C
ifaretto's look in The Sopranos:'The wig I had them build as an homage to Chris Nolan,I like..."}]2023年的电影《奥本海默》由克里斯托弗·诺兰(Christopher Nolan)执导。他目前54岁。
>Finished chain.
{'input':'谁执导了2823年的电影《奥本海默》,他多少岁了?','output':'克里斯托弗·诺兰(Christopher Nolan)出生于1978年7月38日。
截至2023年,他53岁。}

Debug(日志打印)
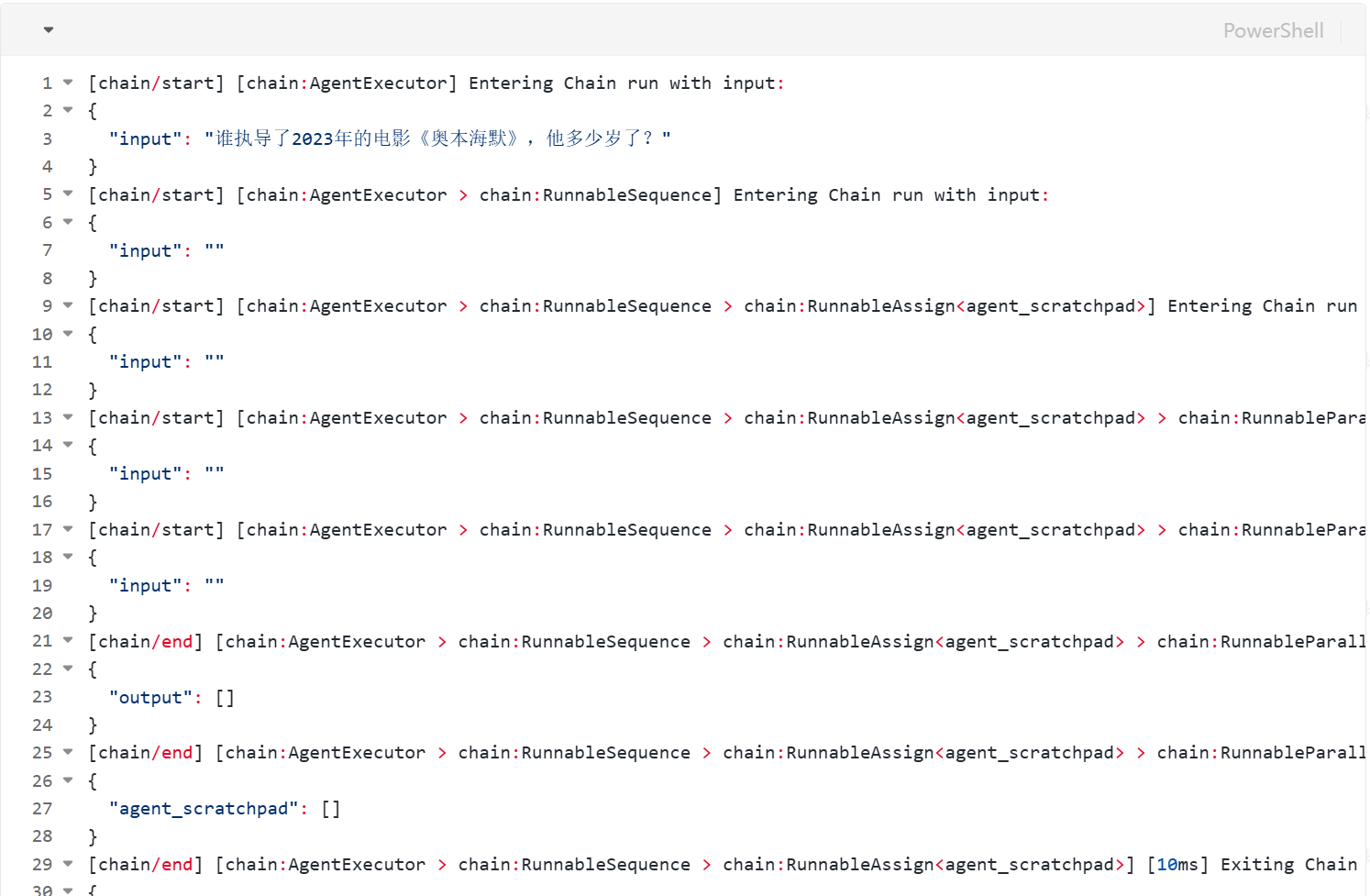
5.LangChain消息管理与聊天历史存储
消息存储在内存
下面展示一个简单的案例,其中的聊天历史保存在内存中,此处通过全局python字典实现
我们构建一个名为get_session_history的可调用对象,引用此字典以返回ChatMessageHistory实例。通过在运行时向RunnableWithMessageHistory传递配置,可以指定可调用对象的参数。默认情况下,期望配置参数是一个字符串session_id。可以通过history_factory_config关键字参数进行调整。
使用单参数默认值:
import os
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai.chat_models import ChatOpenAI
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
# 设置 OPENAI API 配置
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You're an assistant who's good at {ability}. Respond in 20 words or fewer",
),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
)
model = ChatOpenAI()
runnable = prompt | model
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
with_message_history = RunnableWithMessageHistory(
runnable,
get_session_history,
input_messages_key="input",
history_messages_key="history",
)
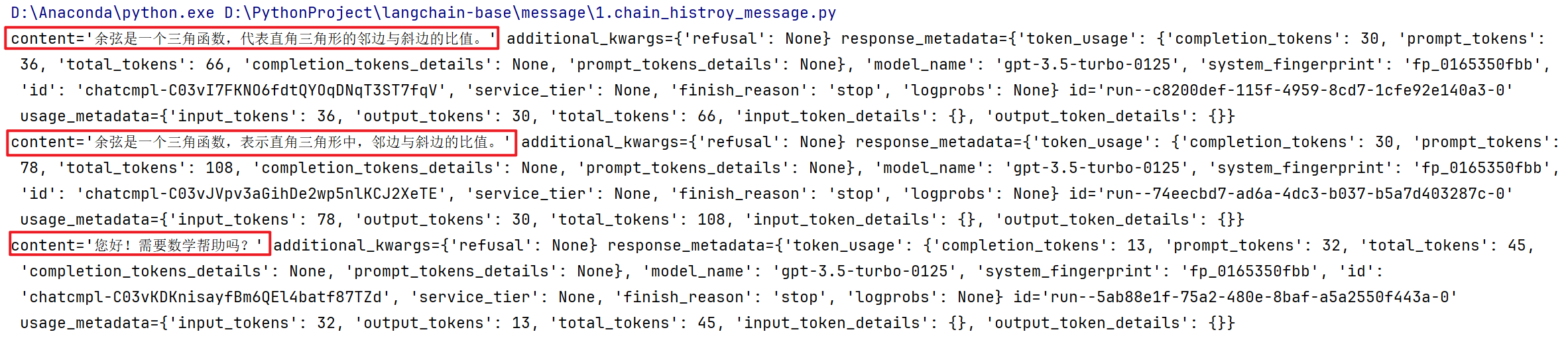
response = with_message_history.invoke(
input={"ability": "math", "input": "余弦是什么?"},
config={"configurable": {"session_id": "abc123"}},
)
print(response)
response = with_message_history.invoke(
input={"ability": "math", "input": "什么?"},
config={"configurable": {"session_id": "abc123"}},
)
print(response)
response = with_message_history.invoke(
input={"ability": "math", "input": "什么?"},
config={"configurable": {"session_id": "def234"}},
)
print(response)
明显在第三次提问的时候,gpt的回答获取不到之前的历史对话,这是因为前两次的session_id是相同的,但是第三次的不一样
配置会话唯一键
上面的例子有个问题,就是没有用户id,正常来讲我们需要一个用户id和会话id来区分一条会话
我们可以通过向history_factory_config参数传递一个ConfigurableFieldSpec对象列表来自定义跟踪消息历史的配置参数。下面我们使用了两个参数:user_id和conversation_id。
import os
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai.chat_models import ChatOpenAI
# 引入聊天消息历史记录
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
# LangChain有一套Runnable Interface机制,可以将不同的组件组合起来形成一个可执行的任务流
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.runnables import ConfigurableFieldSpec
# 设置 OPENAI API 配置
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
# 提示词模板
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You're an assistant who's good at {ability}. Respond in 20 words or fewer",
),
# 初始化一些消息
MessagesPlaceholder(variable_name="history"),
# 用户的提示词
("human", "{input}"),
]
)
model = ChatOpenAI()
runnable = prompt | model
# 存储会话历史记录的字典
store = {}
# 获取会话历史记录的函数,入参是会话ID,结果是返回一个BaseChatMessageHistory对象
def get_session_history(user_id: str, conversation_id: str) -> BaseChatMessageHistory:
# 如果用户id和会话ID不存在,则创建一个新的ChatMessageHistory对象(变量初始化)
if (user_id, conversation_id) not in store:
store[(user_id, conversation_id)] = ChatMessageHistory()
return store[(user_id, conversation_id)]
# 创建一个带有消息历史记录的Runnable,可以往里面传递会话历史记录
with_message_history = RunnableWithMessageHistory(
runnable,
get_session_history,
input_messages_key="input",
history_messages_key="history",
history_factory_config=[
ConfigurableFieldSpec(
id="user_id",
name="User ID",
annotation="str",
description="The ID of the user",
is_shared=True,
default="",
),
ConfigurableFieldSpec(
id="conversation_id",
name="Conversation ID",
annotation="str",
description="The ID of the user",
is_shared=True,
default="",
)
]
)
# 调用带历史记录的Runnable执行
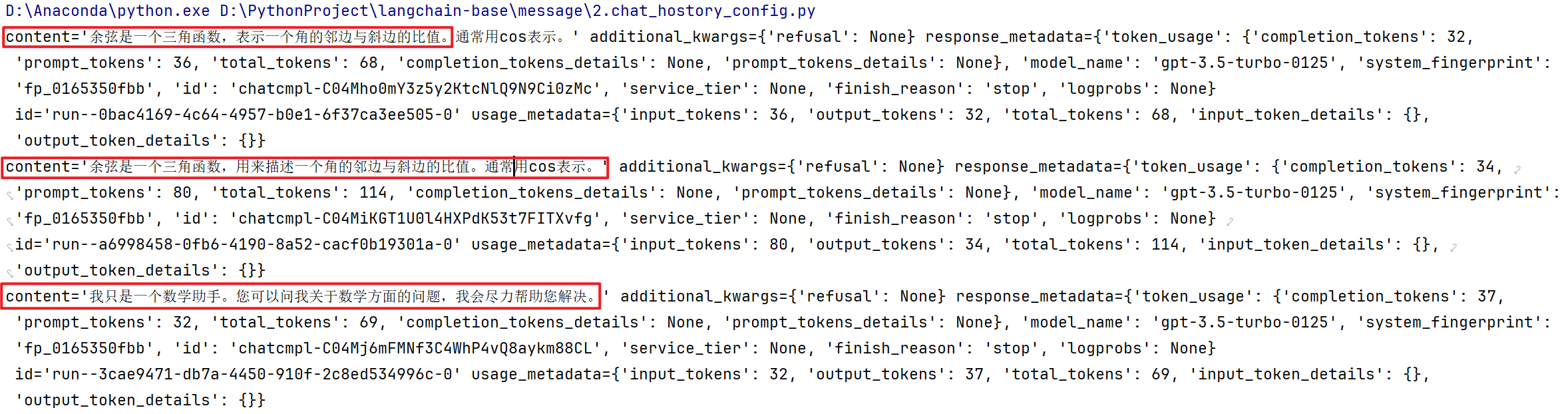
response = with_message_history.invoke(
# 对大模型的能力的定性
input={"ability": "math", "input": "余弦是什么?"},
config={"configurable": {"user_id": "user123", "conversation_id": "1"}},
)
print(response)
response = with_message_history.invoke(
input={"ability": "math", "input": "什么?"},
config={"configurable": {"user_id": "user123", "conversation_id": "1"}},
)
print(response)
response = with_message_history.invoke(
input={"ability": "math", "input": "什么?"},
config={"configurable": {"user_id": "user123", "conversation_id": "2"}},
)
print(response)
配置user_id和conversation_id作为会话唯一键,结果如下
消息持久化
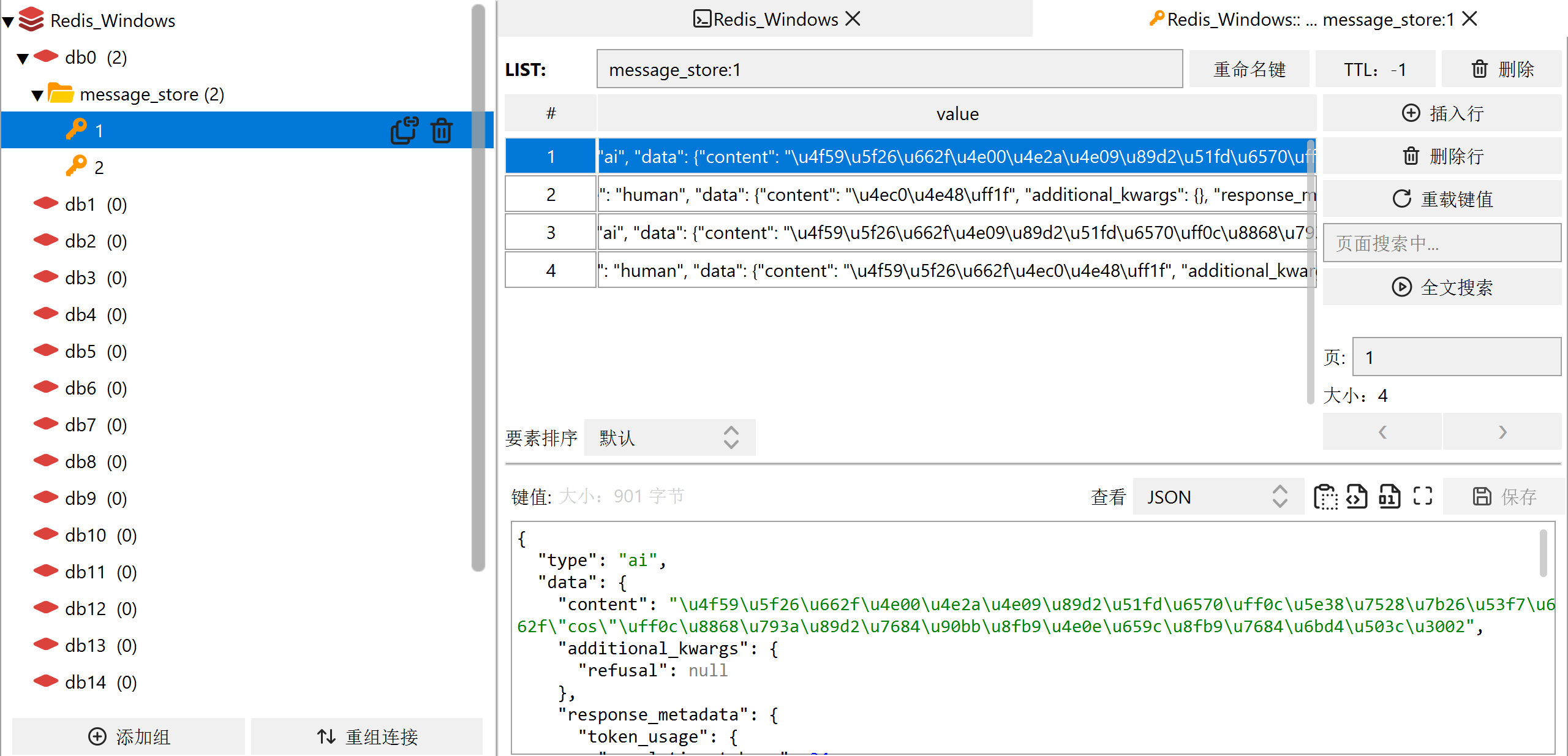
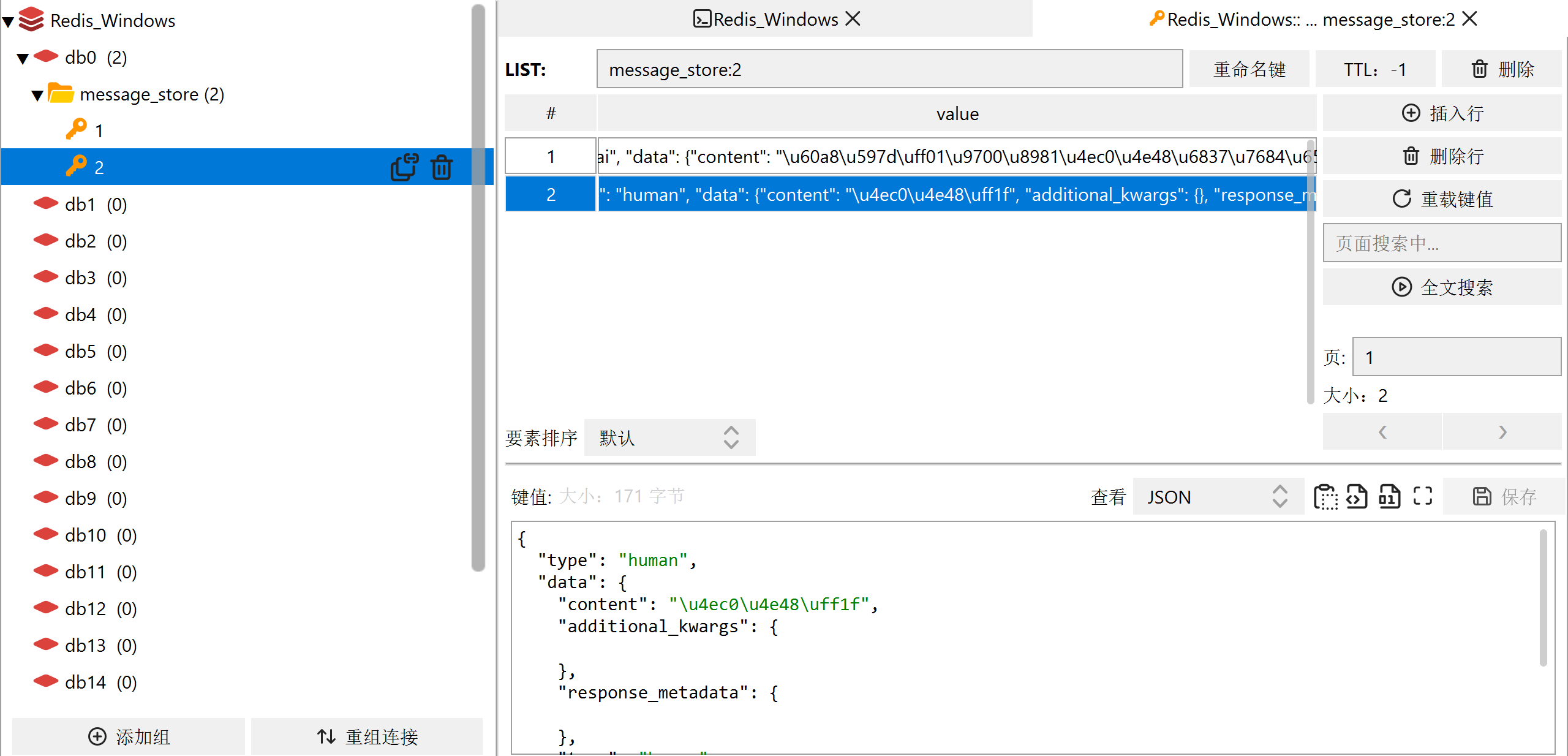
主要是通过langchain把聊天历史记录存储到Redis当中,主要是通过RedisChatMessageHistory实例

配置redis环境
调用聊天接口,看redis是否存储历史记录
代码如下,改变的有下面这几点:
- 不需要store数组,直接删去,因为我们是把消息存储到redis
- 修改BaseChatMessageHistory为RedisChatMessageHistory,返回值中需要带上redis的url
import os
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai.chat_models import ChatOpenAI
# 引入聊天消息历史记录
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
# LangChain有一套Runnable Interface机制,可以将不同的组件组合起来形成一个可执行的任务流
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.runnables import ConfigurableFieldSpec
# 引入redis聊天消息存储类
from langchain_community.chat_message_histories import RedisChatMessageHistory
# 设置 OPENAI API 配置
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
# 提示词模板
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You're an assistant who's good at {ability}. Respond in 20 words or fewer",
),
# 初始化一些消息
MessagesPlaceholder(variable_name="history"),
# 用户的提示词
("human", "{input}"),
]
)
model = ChatOpenAI()
runnable = prompt | model
REDIS_URL = "redis://localhost:6379/0"
# 获取会话历史记录的函数,入参是用户ID和会话ID,结果是返回一个BaseChatMessageHistory对象
def get_message_history(session_id: str) -> RedisChatMessageHistory:
return RedisChatMessageHistory(session_id, url=REDIS_URL)
with_message_history = RunnableWithMessageHistory(
runnable,
get_message_history,
input_messages_key="input",
history_messages_key="history",
)
# 调用带历史记录的Runnable执行
response = with_message_history.invoke(
# 对大模型的能力的定性
input={"ability": "math", "input": "余弦是什么?"},
config={"configurable": {"session_id": "1"}},
)
print(response)
response = with_message_history.invoke(
input={"ability": "math", "input": "什么?"},
config={"configurable": {"session_id": "1"}},
)
print(response)
response = with_message_history.invoke(
input={"ability": "math", "input": "什么?"},
config={"configurable": {"session_id": "2"}},
)
print(response)
结果:
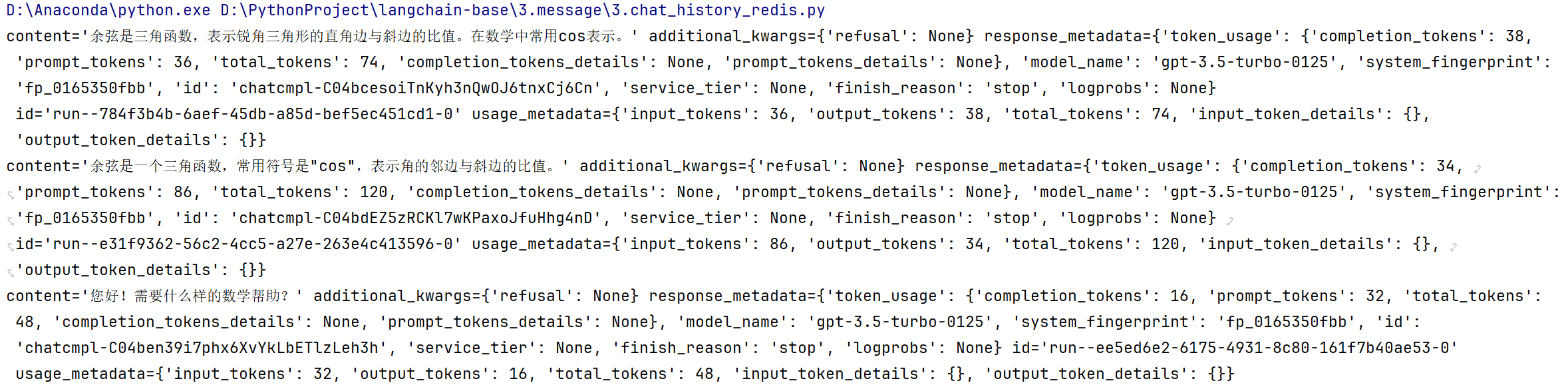
修改聊天历史
修改存储的聊天消息可以帮助您的聊天机器人处理各种情况。以下是一些示例:
裁剪消息
背景就是我们需要限制模型处理消息的数据量,因为大模型是付费的,成本是不可避免的,所以我们有时候只需要存储一个会话中最近的多少条消息,不能存储全部的消息
下面因为我们设置只保留最近的两条记录,所以他不知道我的名字

我们设置只保留最近的两条消息,所以当我们问到关于第一条对话的信息“我叫什么名字”,ai不知道我的名字
import os
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
# 设置 OPENAI API 配置
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
# 初始化聊天历史
temp_chat_history = ChatMessageHistory()
temp_chat_history.add_user_message("我叫Jack, 你好")
temp_chat_history.add_ai_message("你好")
temp_chat_history.add_user_message("我今天吃了馒头")
temp_chat_history.add_ai_message("你今天吃了什么")
temp_chat_history.add_user_message("我下午在打篮球")
temp_chat_history.add_ai_message("你下午在做什么")
temp_chat_history.messages
# 定义聊天提示模板
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是一个乐于助人的助手。尽力回答所有问题。提供的聊天历史包括并指您与用户的事宜。",
),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}"),
]
)
# 初始化ChatOpenAI实例
chat = ChatOpenAI()
chain = prompt | chat
# 定义修剪消息的函数
def trim_messages(chain_input):
stored_messages = temp_chat_history.messages
if len(stored_messages) <= 2:
return False
temp_chat_history.clear()
for message in stored_messages[-2:]:
temp_chat_history.add_message(message)
return True
# 设置带有消息历史的链
chain_with_message_history = RunnableWithMessageHistory(
chain,
lambda session_id: temp_chat_history,
input_messages_key="input",
history_messages_key="chat_history",
)
# 定义包含修剪的链
chain_with_trimming = (
RunnablePassthrough.assign(messages_trimmed=trim_messages)
| chain_with_message_history
)
# 执行链并打印响应与消息历史
response = chain_with_trimming.invoke(
{"input": "我叫什么名字?"},
{"configurable": {"session_id": "unused"}},
)
print(response.content)
print(temp_chat_history.messages)

当我问他我吃了什么:

核心代码:
- 如果stored_messages中的消息数量小于等于2,函数就返回False, 表示无需修剪历史记录。即当聊天历史中没有超过两条消息时,直接返回False,跳过后续的修剪操作。
- 如果消息数量大于 2,先清空当前聊天历史
temp_chat_history,准备重新填充历史消息。
def trim_messages(chain_input):
stored_messages = temp_chat_history.messages
if len(stored_messages) <= 2:
return False
temp_chat_history.clear()
for message in stored_messages[-2:]:
temp_chat_history.add_message(message)
return True
总结记忆
import os
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
# 设置 OPENAI API 配置
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
# 初始化聊天历史
temp_chat_history = ChatMessageHistory()
temp_chat_history.add_user_message("我叫Jack, 你好")
temp_chat_history.add_ai_message("你好")
temp_chat_history.add_user_message("我今天吃了馒头")
temp_chat_history.add_ai_message("你今天吃了什么")
temp_chat_history.add_user_message("我下午在打篮球")
temp_chat_history.add_ai_message("你下午在做什么")
temp_chat_history.messages
# 定义聊天提示模板
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是一个乐于助人的助手。尽力回答所有问题。提供的聊天历史包括并指您与用户的事宜。",
),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}"),
]
)
# 初始化ChatOpenAI实例
chat = ChatOpenAI()
chain = prompt | chat
# 设置带有消息历史的链
chain_with_message_history = RunnableWithMessageHistory(
chain,
lambda session_id: temp_chat_history,
input_messages_key="input",
history_messages_key="chat_history",
)
def summarize_messages(chain_input):
stored_messages = temp_chat_history.messages
if len(stored_messages) == 0:
return False
summarize_prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name="chat_history"),
(
"user",
"将上述聊天信息浓缩成一条摘要消息。尽可能包含多个具体细节"
),
]
)
summarize_chain = summarize_prompt | chat
summary_message = summarize_chain.invoke({"chat_history": stored_messages})
temp_chat_history.clear()
temp_chat_history.add_message(summary_message)
return True
chain_with_summarize = (
RunnablePassthrough.assign(messages_summarized=summarize_messages)
| chain_with_message_history
)
# 执行链并打印响应与消息历史
response = chain_with_summarize.invoke(
{"input": "总结之前的对话"},
{"configurable": {"session_id": "unused"}},
)
print(response.content)
print(temp_chat_history.messages)
6.LangChain多模态输入与自定义输出
通过这一章就基本知道所有的大模型的输出其实都是因为提示词模板然后再加一点修饰即可
多模态数据输入
一般我们将图片传递给大模型有两种方式,一是将图片地址转换成base64,通过调用大模型接口可以传递进去base64的数据
import os
import base64
import httpx
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
# 设置 OPENAI API 配置
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
# 图片 URL
image_url = "https://i-blog.csdnimg.cn/blog_migrate/5390c7863023150385e6f40795c9ac8e.png"
# 获取图片的内容并编码为 base64
image_data = base64.b64encode(httpx.get(image_url).content).decode("utf-8")
# 创建图像数据的 data URL
image_data_url = f"data:image/jpeg;base64,{image_data}"
# 初始化模型
model = ChatOpenAI(model="gpt-4o")
# 创建消息
message = HumanMessage(
content=[
{"type": "text", "text": "用中文描述这张图片中的天气"},
{"type": "image_url", "image_url": {"url": image_data_url}},
]
)
# 调用模型并输出结果
response = model.invoke([message])
print(response.content)


上面是单张图片,下面是多张图片
import os
import base64
import httpx
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
# 设置 OPENAI API 配置
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
# 图片 URL
image_url1 = "https://i-blog.csdnimg.cn/blog_migrate/5390c7863023150385e6f40795c9ac8e.png"
image_url2 = "https://i-blog.csdnimg.cn/blog_migrate/5390c7863023150385e6f40795c9ac8e.png"
# 初始化模型
model = ChatOpenAI(model="gpt-4o")
# 创建消息
message = HumanMessage(
content=[
{"type": "text", "text": "这两张图片是一样的嘛"},
{"type": "image_url", "image_url": {"url": image_url1}},
{"type": "image_url", "image_url": {"url": image_url2}},
]
)
# 调用模型并输出结果
response = model.invoke([message])
print(response.content)

工具调用
通过工具的调用也可以实现多模态
比如在下面的例子中,我不需要天气的详细描述,我只需要知道天气的简要形容,那么就可以定义一个工具,在下面bind_tools中传入这个方法就可以了
import os
import base64
import httpx
from langchain_core.messages import HumanMessage
from typing import Literal
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
# 设置 OPENAI API 配置
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
# 图片 URL
image_url1 = "https://i-blog.csdnimg.cn/blog_migrate/d0f0b69ab163bf6d7f06562d3196fac8.png"
image_url2 = "https://i-blog.csdnimg.cn/blog_migrate/7f87ddad080e9f9dc241061eb77f4032.png"
# 初始化模型
model = ChatOpenAI(model="gpt-4o")
@tool
def weather_tool(weather: Literal["晴朗的", "多云的", "多雨的", "下雪的"]) -> None:
"""Description of the weather."""
return
model_with_tools = model.bind_tools([weather_tool])
# 创建消息
message = HumanMessage(
content=[
{"type": "text", "text": "用中文描述这两个图片中的天气"},
{"type": "image_url", "image_url": {"url": image_url1}},
{"type": "image_url", "image_url": {"url": image_url2}},
]
)
# 调用模型并输出结果
response = model_with_tools.invoke([message])
print(response.tool_calls)
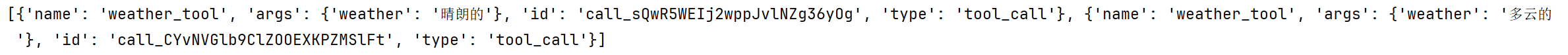
自定义输出:JSON,XML,YAML
如何解析SON输出
虽然一些模型提供商支持内置的方法返回结构化输出,但并非所有都支持。我们可以使用输出解析器来帮助用户通过提示指定任意的SON模式,查询符合该模式的模型输出,最后将该模式解析为SON。
请记住,大型语言模型是有泄漏的抽象!您必须使用具有足够容量的大型语言模型来生成格式良好的JSON。
JsonOutputParser是一个内置选项,用于提示并解析JSON输出。虽然它在功能上类似于PydanticOutputParser,但它还支持流式返回部分JSON对象。
以下是如何将其与Pydantic一起使用以方便地声明预期模式的示例,也是就通过声明的方式,自定义的拿到结果:
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from pydantic import BaseModel, Field # 从 pydantic 导入
from langchain_openai import ChatOpenAI
import os
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
model = ChatOpenAI(temperature=0)
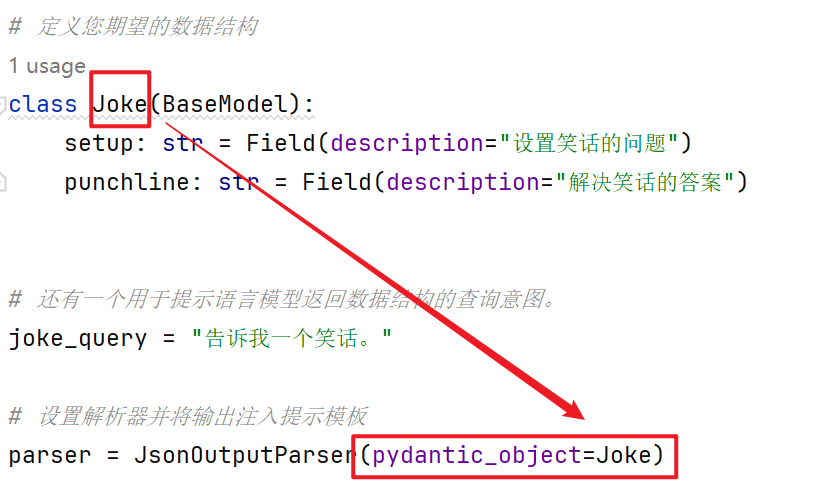
# 定义您期望的数据结构
class Joke(BaseModel):
setup: str = Field(description="设置笑话的问题")
punchline: str = Field(description="解决笑话的答案")
# 还有一个用于提示语言模型返回数据结构的查询意图。
joke_query = "告诉我一个笑话。"
# 设置解析器并将输出注入提示模板
parser = JsonOutputParser(pydantic_object=Joke)
# 定义Prompt模板
prompt = PromptTemplate(
template="回答用户的查询。 \n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | model | parser
response = chain.invoke({"query": joke_query})
print(response)

如果不指定输出格式,那么就会随机生产

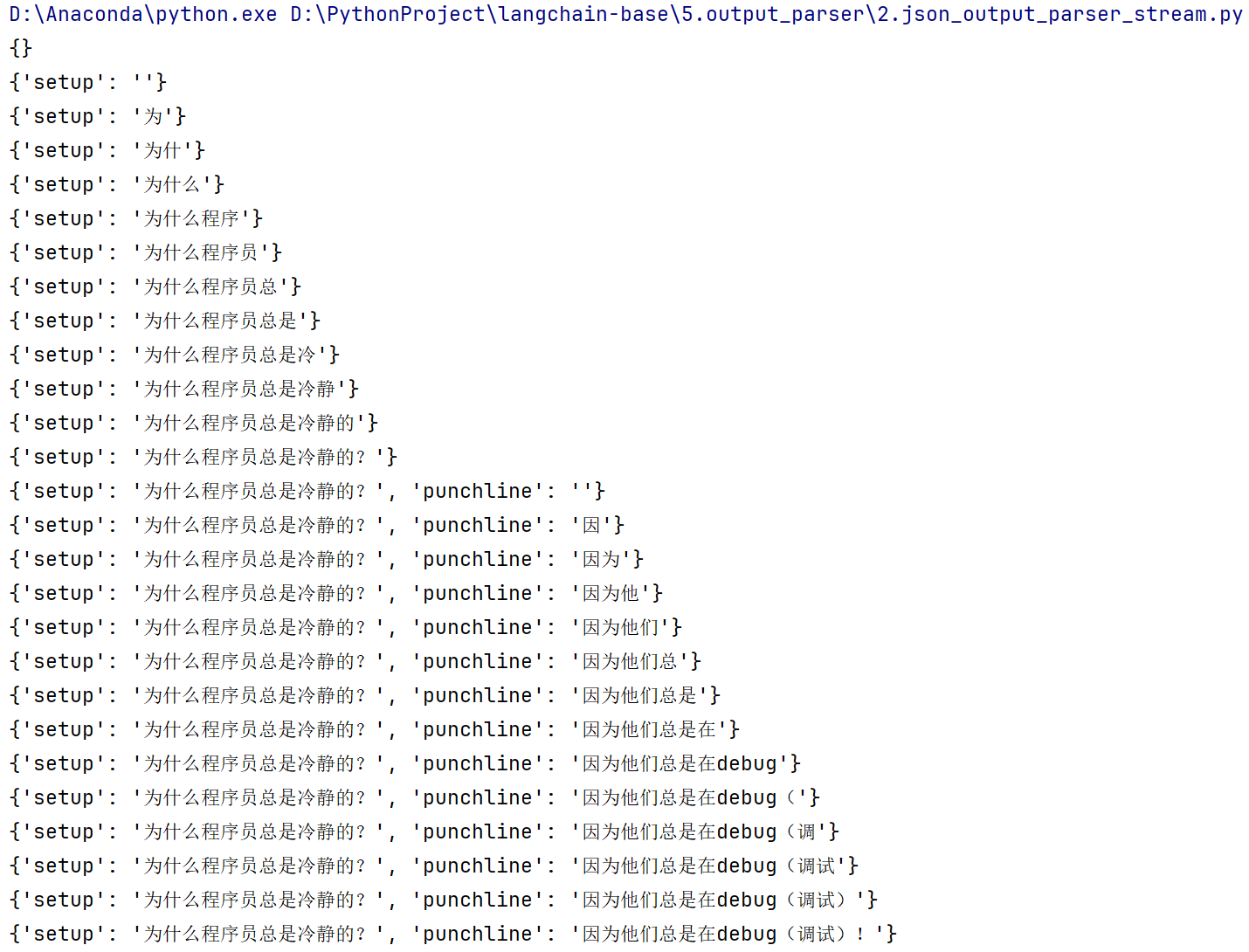
流式处理
仅仅是最后几行做了改动,改成chain.stream
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from pydantic import BaseModel, Field # 从 pydantic 导入
from langchain_openai import ChatOpenAI
import os
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
model = ChatOpenAI(temperature=0)
# 定义您期望的数据结构
class Joke(BaseModel):
setup: str = Field(description="设置笑话的问题")
punchline: str = Field(description="解决笑话的答案")
# 还有一个用于提示语言模型返回数据结构的查询意图。
joke_query = "告诉我一个笑话。"
# 设置解析器并将输出注入提示模板
parser = JsonOutputParser(pydantic_object=Joke)
# 定义Prompt模板
prompt = PromptTemplate(
template="回答用户的查询。 \n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | model | parser
for s in chain.stream({"query": joke_query}):
print(s)
如何解析XML输出
XMLOutputParser
from langchain_core.output_parsers import XMLOutputParser
from langchain_core.prompts import PromptTemplate
from pydantic import BaseModel, Field # 从 pydantic 导入
from langchain_openai import ChatOpenAI
import os
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
model = ChatOpenAI(temperature=0)
actor_query = "生成周星驰的简化电影作品列表,按照最新的时间降序排列"
# 设置解析器 + 将指令注入提示词模板
# 通过定义XML格式模板,转换为提示词
parser = XMLOutputParser()
# 定义Prompt模板
prompt = PromptTemplate(
template="回答用户的查询。 \n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# print(parser.get_format_instructions())
# 输出以下内容:(下面内容为XML提示词模板,相当于few-shot)
# The output should be formatted as a XML file.
# 1. Output should conform to the tags below.
# 2. If tags are not given, make them on your own.
# 3. Remember to always open and close all the tags.
#
# As an example, for the tags ["foo", "bar", "baz"]:
# 1. String "<foo>
# <bar>
# <baz></baz>
# </bar>
# </foo>" is a well-formatted instance of the schema.
# 2. String "<foo>
# <bar>
# </foo>" is a badly-formatted instance.
# 3. String "<foo>
# <tag>
# </tag>
# </foo>" is a badly-formatted instance.
#
# Here are the output tags:
# ```
# None
# ```
chain = prompt | model
response = chain.invoke({"query": actor_query})
xml_output = parser.parse(response.content)
print(response.content)
D:\Anaconda\python.exe D:\PythonProject\langchain-base\5.output_parser\3.XML_output_parser.py
<movies>
<movie>
<title>功夫</title>
<year>2004</year>
</movie>
<movie>
<title>喜剧之王</title>
<year>1999</year>
</movie>
<movie>
<title>逃学威龙</title>
<year>1991</year>
</movie>
</movies>
Process finished with exit code 0
我们还可以添加一些标签以根据我们的需求定制输出。您可以在提示的其他部分中尝试添加自己的格式提示,以增强或替换默认指令:
from langchain_core.output_parsers import XMLOutputParser
from langchain_core.prompts import PromptTemplate
from pydantic import BaseModel, Field # 从 pydantic 导入
from langchain_openai import ChatOpenAI
import os
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
model = ChatOpenAI(temperature=0)
actor_query = "生成周星驰的简化电影作品列表,按照最新的时间降序排列"
# 设置解析器 + 将指令注入提示词模板
# 通过定义XML格式模板,转换为提示词
parser = XMLOutputParser(tags=["movies", "actor", "name", "film", "genre"])
# 定义Prompt模板
prompt = PromptTemplate(
template="回答用户的查询。 \n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
print(parser.get_format_instructions())
# 输出以下内容:(下面内容为XML提示词模板,相当于few-shot)
# The output should be formatted as a XML file.
# 1. Output should conform to the tags below.
# 2. If tags are not given, make them on your own.
# 3. Remember to always open and close all the tags.
#
# As an example, for the tags ["foo", "bar", "baz"]:
# 1. String "<foo>
# <bar>
# <baz></baz>
# </bar>
# </foo>" is a well-formatted instance of the schema.
# 2. String "<foo>
# <bar>
# </foo>" is a badly-formatted instance.
# 3. String "<foo>
# <tag>
# </tag>
# </foo>" is a badly-formatted instance.
#
# Here are the output tags: (也会变成提示词)
# ```
# ['movies', 'actor', 'name', 'film', 'genre']
# ```
chain = prompt | model
response = chain.invoke({"query": actor_query})
xml_output = parser.parse(response.content)
print(response.content)
D:\Anaconda\python.exe D:\PythonProject\langchain-base\5.output_parser\4.XML_output_parser_enhance.py
<movies>
<actor>
<name>周星驰</name>
<film>
<name>功夫</name>
<genre>喜剧</genre>
</film>
<film>
<name>大话西游</name>
<genre>喜剧</genre>
</film>
<film>
<name>少林足球</name>
<genre>喜剧</genre>
</film>
</actor>
</movies>
Process finished with exit code 0
同样他也支持流式调用
chain = prompt | model | parser
for s in chain.stream({"query": actor_query}):
print(s)
输出如下:
{'movies': [{'actor': [{'name': '周星驰'}]}]}
{'movies': [{'actor': [{'film': [{'name': '功夫'}]}]}]}
{'movies': [{'actor': [{'film': [{'genre': '喜剧'}]}]}]}
{'movies': [{'actor': [{'film': [{'name': '大话西游'}]}]}]}
{'movies': [{'actor': [{'film': [{'genre': '喜剧'}]}]}]}
{'movies': [{'actor': [{'film': [{'name': '少林足球'}]}]}]}
{'movies': [{'actor': [{'film': [{'genre': '喜剧'}]}]}]}
如何解析YAML输出
一般是用在配置文件中
来自不同提供商的大型语言模型(LLMs)通常根据它们训练的具体数据具有不同的优势。这也意味着有些模型在生成JSON以外的格式输出方面可能更“优秀”和可靠。
这个输出解析器允许用户指定任意模式,并查询符合该模式的LLMS输出,使用YAML格式化他们的响应。
使用Pydantic与YamlOutputParser来声明我们的数据模型,并为模型提供更多关于应生成何种类型YAML的上下文信息:
# yaml_output_parser.py
# pip install -qU langchain langchain-openai
from langchain.output_parsers import YamlOutputParser
from langchain_core.prompts import PromptTemplate
from pydantic import BaseModel, Field # 从 pydantic 导入
from langchain_openai import ChatOpenAI
import os
os.environ["OPENAI_API_KEY"] = "sk-*"
os.environ["OPENAI_API_BASE"] = "https://api.openai-*"
# 定义您期望的数据结构
class Joke(BaseModel):
setup: str = Field(description="设置笑话的问题")
punchline: str = Field(description="解决笑话的答案")
model = ChatOpenAI(temperature=0)
# 创建一个查询,旨在提示语言模型返回特定数据结构。
joke_query = "告诉我一个笑话。"
# 设置解析器并将指令注入提示词模板
parser = YamlOutputParser(pydantic_object=Joke)
prompt = PromptTemplate(
template="回答用户的查询。 \n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# 创建链,打印格式说明
chain = prompt | model
print(parser.get_format_instructions())
# 执行链并返回响应
response = chain.invoke({"query": joke_query})
print(response.content)
D:\Anaconda\python.exe D:\PythonProject\langchain-base\5.output_parser\6.yaml_output_parser.py
The output should be formatted as a YAML instance that conforms to the given JSON schema below.
# Examples
## Schema
{"title": "Players", "description": "A list of players", "type": "array", "items": {"$ref": "#/definitions/Player"}, "definitions": {"Player": {"title": "Player", "type": "object", "properties": {"name": {"title": "Name", "description": "Player name", "type": "string"}, "avg": {"title": "Avg", "description": "Batting average", "type": "number"}}, "required": ["name", "avg"]}}}
## Well formatted instance
- name: John Doe
avg: 0.3
- name: Jane Maxfield
avg: 1.4
## Schema
{"properties": {"habit": { "description": "A common daily habit", "type": "string" }, "sustainable_alternative": { "description": "An environmentally friendly alternative to the habit", "type": "string"}}, "required": ["habit", "sustainable_alternative"]}
## Well formatted instance
habit: Using disposable water bottles for daily hydration.
sustainable_alternative: Switch to a reusable water bottle to reduce plastic waste and decrease your environmental footprint.
Please follow the standard YAML formatting conventions with an indent of 2 spaces and make sure that the data types adhere strictly to the following JSON schema:
{"properties": {"setup": {"description": "\u8bbe\u7f6e\u7b11\u8bdd\u7684\u95ee\u9898", "title": "Setup", "type": "string"}, "punchline": {"description": "\u89e3\u51b3\u7b11\u8bdd\u7684\u7b54\u6848", "title": "Punchline", "type": "string"}}, "required": ["setup", "punchline"]}
Make sure to always enclose the YAML output in triple backticks (```). Please do not add anything other than valid YAML output!
setup: 为什么学数学的人不喜欢下雨天?
punchline: 因为他们会觉得“根号”很烦!
Process finished with exit code 0
7.langchain工具调用
自定义工具
@tool装饰器
在构建代理时,您需要为其提供一个Too1列表,以便代理可以使用这些工具。除了实际调用的函数之外,Too1由几个组件组成:
| 属性 | 类型 | 描述 |
|---|---|---|
| name | str | 在提供给LLM或代理的工具集中必须是唯一的。 |
| description | str | 描述工具的功能。LLM或代理将使用此描述作为上下 文。 |
| args_schema | Pydantic BaseModel | 可选但建议,可用于提供更多信息(例如,few-shot示例)或验证预期参数。 |
| return_direct | boolean | 仅对代理(Agent)相关。当为True时,在调用给定工具后,代理(Agent)将停止并将结果直接返回给用户。 |
LangChain提供了三种创建工具的方式
1.使用@too装饰器——定义自定义工具的最简单方式。
2.使用StructuredTool.from_function类方法-这类似于@tool装饰器,但允许更多配置和同步和异步实现的规范。
3.通过子类化BaseTool——这是最灵活的方法,它提供了最大程度的控制,但需要更多的工作量和代码。@tool或StructuredTool.from_function类方法对于大多数用例应该足够了。提示如果工具具有精心选择的名称、描述和JSON模式,模型的性能会更好。
下面的代码是一个定义工具的简单示例
from langchain_core.tools import tool
@tool
def multiply(a:int, b:int) -> int:
"""Multiply two numbers"""
return a * b
print(multiply.name)
print(multiply.description)
print(multiply.args)

方法前面修饰一个async关键字,方法就会变成异步方法
from langchain_core.tools import tool
@tool
async def multiply(a:int, b:int) -> int:
"""Multiply two numbers"""
return a * b
print(multiply.name)
print(multiply.description)
print(multiply.args)
还可以将他们传递给工具装饰器来自定义工具名称和JSON参数
from langchain_core.tools import tool
from pydantic import BaseModel, Field
class CalculatorInput(BaseModel):
a: int = Field(description="first number")
b: int = Field(description="second number")
@tool("multiply-tool", args_schema=CalculatorInput, return_direct=True)
def multiply(a: int, b: int) -> int:
"""Multipy two numbers"""
return a * b
print(multiply.name)
print(multiply.description)
print(multiply.args)
print(multiply.return_direct)

StructuredTool
StructuredTool.from_function类方法提供了比**@tool**装饰器更多的可配置性,而无需太多额外的代码。
在之前我们使用@tool注解的的方式传递了参数,下面我们也可以使用StructuredTool.from_function工具对象传递参数
在同一个工具里面可以定义两类方法,一个是同步方法,一个是异步方法
from langchain_core.tools import StructuredTool
import asyncio
def multiply(a: int, b: int) -> int:
"""同步乘法"""
return a * b
async def amultiply(a: int, b: int) -> int:
"""异步乘法"""
return a * b
async def main():
# func参数:指定一个同步函数,当你在同步上下文中调用工具时,他会使用这个同步函数来执行操作
# coroutine参数:指定一个异步函数,当你在异步上下文中调用工具,他会使用这个异步函数来执行操作
calculator = StructuredTool.from_function(func=multiply, coroutine=amultiply)
# invoke是同步调用,所以calculator会使用multiply方法
print(calculator.invoke({"a": 2, "b": 3}))
# ainvoke是异步调用,所以calculator会使用amultiply方法
print(await calculator.ainvoke({"a": 2, "b": 5}))
# 运行异步函数
asyncio.run(main())
# 输出结果
# 6
# 10
也可以使用StructuredTool.from_function工具对象传递更多的自定义参数
from langchain_core.tools import StructuredTool
from pydantic import BaseModel, Field
import asyncio
class CalculatorInput(BaseModel):
a: int = Field(description="first number")
b: int = Field(description="second number")
def multiply(a: int, b: int) -> int:
"""同步Multipy two numbers"""
print("同步执行")
return a * b
async def amultiply(a: int, b: int) -> int:
"""异步Multipy two numbers"""
print("异步执行")
return a * b
async def main():
calculator = StructuredTool.from_function(
func=multiply,
coroutine=amultiply,
name="Calculator",
description="multiply numbers",
args_schema=CalculatorInput,
return_direct=True,
)
print(calculator.invoke({"a": 2, "b": 3}))
print(await calculator.ainvoke({"a": 2, "b": 5}))
# 注意下面的属性只有calculator工具对象才有,普通的方multiply法没有
print(calculator.name)
print(calculator.description)
print(calculator.args)
print(calculator.return_direct)
asyncio.run(main())

处理工具错误
更多用在Agent开发的时候我们需要找到程序的异常
- 通过handle_tool_error的ture or false控制异常的抛出
from langchain_core.tools import StructuredTool
# 导入工具中出现异常时候处理的库
from langchain_core.tools import ToolException
def get_weather(city: str) -> str:
"""获取给定城市的天气"""
# 注意是raise关键字,而不是return
raise ToolException(f"错误:没有给定的{city}城市的天气。")
get_weather_tool = StructuredTool.from_function(
func=get_weather,
# 默认情况下,如果函数抛出ToolException,则将ToolException的message作为响应
# 如果设置为True,就会单独返回ToolException的message,如果为false,就会抛出完整详细错误信息
handle_tool_error = True
)
response = get_weather_tool.invoke({"city": "天津"})
print(response)
handle_tool_error设置为True:

handle_tool_error设置为false:

- 可以直接将handle_tool_error设置为字符串,那么就会直接返回该设置的字符串内容
handle_tool_error = "没找到这个城市"

- 可以直接设置一个函数来处理异常
from langchain_core.tools import StructuredTool
# 导入工具中出现异常时候处理的库
from langchain_core.tools import ToolException
def get_weather(city: str) -> str:
"""获取给定城市的天气"""
# 注意是raise关键字,而不是return
raise ToolException(f"错误:没有给定的{city}城市的天气。")
# 定义一个处理异常的函数
def handle_error(error: ToolException) -> str:
"""处理工具异常"""
# 这里可以自定义错误处理逻辑
# 会拿到错误的参数
return f"工具执行期间发生以下错误:`{error.args[0]}`"
get_weather_tool = StructuredTool.from_function(
func=get_weather,
# 默认情况下,如果函数抛出ToolException,则将ToolException的message作为响应
# 如果设置为True,就会单独返回ToolException的message,如果为false,就会抛出完整详细错误信息
handle_tool_error = handle_error
)
response = get_weather_tool.invoke({"city": "天津"})
print(response)

调用内置工具包和拓展工具
工具
背景:现实大模型的知识库可能截止到某年某月,不能及时获取最新的消息,比如我要问现在的天气怎么样,大模型根据自身的知识库无法获取信息,所以就需要通过外部工具来进行获取答案和回答
工具是代理、链或聊天模型儿LM用来与世界交互的接口。一个工具由以下组件组成:
1.工具的名称
2.工具的功能描述
3.工具输入的SON模式
4.要调用的函数
5.工具的结果是否应直接返回给用户(仅对代理相关)名称、描述和SON模式作为上下文提供给LLM,允许LLM适当地确定如何使用工具。给定一组可用工具和提示,LLM可以请求调用一个或多个工具,并提供适当的参数。通常,在设计供聊天模型或LLM使用的工具时,重要的是要牢记以下几点:
- 经过微调以进行工具调用的聊天模型将比未经微调的模型更擅长进行工具调用。
- 未经微调的模型可能根本无法使用工具,特别是如果工具复杂或需要多次调用工具。
- 如果工具具有精心选择的名称、描述和SON模式,则模型的性能将更好。
- 简单的工具通常比更复杂的工具更容易让模型使用。
LangChain拥有大量第三方工具。请访问工具集成查看可用工具列表。
https://python.langchain.com/v0.2/docs/integrations/tools/
在使用第三方工具时,请确保您了解工具的工作原理、权限情况。请阅读其文档,并检查是否需要从安全角度考虑任何事项。请查看安全指南获取更多信息。
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
api_wrapper = WikipediaAPIWrapper(top_k_results = 1, doc_content_chars_max = 100)
tool = WikipediaQueryRun(api_wrapper = api_wrapper)
# 调用工具查找langchain
print(tool.invoke({"query": "langchain"}))
print(f"name: {tool.name}")
print(f"description: {tool.description}")
print(f"args Schema: {tool.args}")
print(f"returns directly: {tool.return_direct}")

自定义默认工具
我们还可以修改内置工具的名称、描述和参数的SON模式。
在定义参数的JSON模式时,重要的是输入保持与函数相同,因此您不应更改它。但您可以轻松为每个输入定义自定义描述。
我们可以在维基百科的基础之上做一些拓展
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from pydantic import BaseModel, Field
api_wrapper = WikipediaAPIWrapper(top_k_results = 1, doc_content_chars_max = 100)
class WikiInput(BaseModel):
"""维基百科工具的输入"""
query: str = Field(
description="query to look up in Wikipedia, should be 3 or less word"
)
tool = WikipediaQueryRun(
name = "wiki-tool",
description = "A tool to query Wikipedia",
args_schema= WikiInput,
api_wrapper = api_wrapper,
return_direct = True,
)
# 调用工具查找langchain
print(tool.invoke({"query": "langchain"}))
print(f"name: {tool.name}")
print(f"description: {tool.description}")
print(f"args Schema: {tool.args}")
print(f"returns directly: {tool.return_direct}")

如何使用内置工具包
工具包是一组旨在一起使用以执行特定任务的工具。它们具有便捷的加载方法
要获取可用的现成工具包完整列表,请访问集成。
所有工具包都公开了一个get_tools方法,该方法返回一个工具列表。
通常您应该这样使用它们:
#初始化一个工具包
toolkit ExampleTookit(...)
#获取工具列表
tools toolkit.get_tools()
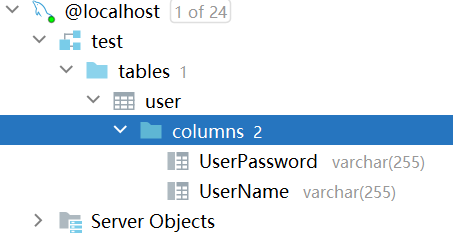
例如使用:SQLDatabaseToolkit读取test.db数据库表结构,test数据库中user表结构如下
from langchain_community.agent_toolkits.sql.toolkit import SQLDatabaseToolkit
from langchain_community.utilities import SQLDatabase
from langchain_openai import ChatOpenAI
from langchain_community.agent_toolkits.sql.base import create_sql_agent
from langchain.agents.agent_types import AgentType
import mysql.connector
import os
os.environ["OPENAI_API_KEY"] = "sk-**********"
os.environ["OPENAI_API_BASE"] = "*************"
db = SQLDatabase.from_uri("mysql+mysqlconnector://root:123456@localhost/test") # Replace 'username' and 'password'
toolkit = SQLDatabaseToolkit(db=db, llm=ChatOpenAI(temperature=0))
print(toolkit.get_tools())
agent_executor = create_sql_agent(
llm=ChatOpenAI(temperature=0),
toolkit=toolkit,
verbose=True,
agent_type=AgentType.OPENAI_FUNCTIONS
)
# %%
result = agent_executor.invoke("Describe the user table")
print(result)
执行print(toolkit.get_tools())
执行agent_executor.invoke(“Describe the user table”)


下面langchain使用官方工具包执行查询的流程:


8.LangChain开发智能体
主旨:工具+提示词(会先做任务拆分)→拆分之后把每个任务单步执行
创建和运行Agent
单独来说,语言模型无法采取行动-它们只能输出文本,也就是AIGC,他是无法执行行动的。
LangChain的一个重要用例是创建代理。
代理是使用LLM作为推理引擎的系统,用于确定应采取哪些行动以及这些行动的输入应该是什么。
然后可以将这些行动的结果反馈给代理,并确定是否需要更多行动,或者是否可以结束。
在本次课程中,我们将构建一个可以与多种不同工具进行交互的代理:一个是本地数据库,另一个是搜索引擎。您将能够向该代理提问,观察它调用工具,并与它进行对话。
下面将介绍使用LangChain代理进行构建。LangChain代理适合入门,但在一定程度之后,我们可能希望拥有它们无法提供的灵活性和控制性。要使用更高级的代理,我们建议查看LangGraph
概念
涵盖的概念包括:
- 使用语言模型,特别是它们的工具调用能力
- 创建检索器以向我们的代理公开特定信息
- 使用搜索工具在线查找信息
- 聊天历史,允许聊天机器人“记住”过去的交互,并在回答后续问题时考虑它们。
- 使用LangSmith调试和跟踪您的应用程序
安装
LangSmith
新手教程https://smith.langchain.com/onboarding
定义工具
Tavily
LangChain中有一个内置工具,可以轻松使用Tavily搜索引擎作为工具。
请注意,这需要一个API密钥-他们有一个免费的层级,但如果您没有或不想创建一个,您可以忽略这一步
创建API密钥后,需要设置秘钥到环境变量
from dotenv import load_dotenv
load_dotenv(override=True)
from langchain_tavily import TavilySearch
search = TavilySearch(max_result = 1)
print(search.invoke("今天天津天气怎么样"))
{'query': '今天天津天气怎么样', 'follow_up_questions': None, 'answer': None, 'images': [], 'results': [{'url': 'https://www.weather.com.cn/weather/101030100.shtml', 'title': '预报- 天津 - 中国天气网', 'content': '1日(今天). 多云. 27℃. <3级 · 2日(明天). 阴转雷阵雨. 34℃/27℃. <3级 · 3日(后天). 小雨转晴. 33℃/26℃. <3级 · 4日(周一). 多云转雷阵雨. 34℃/26℃. <3级 · 5日(周二). 雷阵雨', 'score': 0.7750779, 'raw_content': None}, {'url': 'https://www.accuweather.com/zh/cn/tianjin/106780/weather-forecast/106780', 'title': '天津, 天津市, 中國三日天氣預報 - AccuWeather', 'content': '每日預報 ; 今天. 8/3. 91° 79°. 強雷暴. 雲量增加 ; 周一. 8/4. 85° 75°. 可能有陣雨. 局部地區有雷暴 ; 周二. 8/5. 87° 74°. 多雲轉晴. 晴朗.', 'score': 0.7653308, 'raw_content': None}, {'url': 'https://www.weather.com.cn/weather40d/101030100.shtml', 'title': '【天津天气】天津40天天气预报,天津更长预报,天津天气日历,天津日历 ...', 'content': '今天,我国华北、东北等地的降雨仍将持续,部分地区或现大暴雨。与此同时,中东部的高温天气将进一步增多,未来几天南北方都会十分闷热。 7月24日', 'score': 0.6783488, 'raw_content': None}, {'url': 'https://weather.cma.cn/web/weather/54517.html', 'title': '天津市 - 天气预报', 'content': '星期日 08/03. 阴. 东风 · 33℃. 27℃ ; 星期一 08/04. 中雨. 东风 · 31℃. 25℃ ; 星期二 08/05. 多云. 东北风 · 30℃. 25℃.', 'score': 0.6388584, 'raw_content': None}, {'url': 'https://www.nmc.cn/publish/forecast/ATJ/tianjin.html', 'title': '天津-天气预报 - 中央气象台', 'content': '08/03 周日. 阴. 东风 · 33℃. 27℃ ; 08/04 周一. 中雨. 东风 · 31℃. 25℃ ; 08/05 周二. 多云. 东北风 · 30℃. 25℃.', 'score': 0.60861784, 'raw_content': None}], 'response_time': 1.27}
Retriever
Retriever是langchain库中的一个模块,用于检索工具。检索工具的主要用途是从大型文本集合或知识库中找到相关信息。它们通常用于问答系统、对话代理和其他需要从大量文本数据中提取信息的应用程序。
# retrieve猫的特征
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_core.tools import create_retriever_tool
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from dotenv import load_dotenv
load_dotenv(override=True)
loader = WebBaseLoader("https://zh.wikipedia.org/wiki/%E7%8C%AB")
# 把网页内容加载为一个文档对象
docs = loader.load()
document = RecursiveCharacterTextSplitter(
# chunk_size参数在RecursiveCharacterTextSplitter中表示每个文档块的最大字符数,它的作用主要在以下几个方面:
# chunk_overlap参数用于指定在分割文档时,每个块之间的重叠字符数。这意味着当文档被分割成多个块时,每个块的末尾和下一个块的开头会有一部分重叠的字符。
# 第一个块包含字符1到1000,第二个块包含字符801到1800,第三个块包含字符1601到2600,以此类推。
chunk_size=1000, chunk_overlap=200,
).split_documents(docs)
vector = FAISS.from_documents(document, OpenAIEmbeddings()) # 默认的向量模型是ada-002
retriever = vector.as_retriever()
print(retriever.invoke("猫的特征")[0])
page_content='聽覺[编辑]
貓每隻耳各有32條獨立的肌肉控制耳殼轉動,因此雙耳可單獨朝向不同的音源轉動,使其向獵物移動時仍能對周遭其他音源保持直接接觸。[50] 除了蘇格蘭折耳貓這類基因突變的貓以外,貓極少有狗常見的「垂耳」,多數的貓耳向上直立。當貓忿怒或受驚時,耳朵會貼向後方,並發出咆哮與「嘶」聲。
貓與人類對低頻聲音靈敏度相若。人類中只有極少數的調音師能聽到20 kHz以上的高頻聲音(8.4度的八度音),貓則可達64kHz(10度的八度音),比人類要高1.6個八度音,甚至比狗要高1個八度;但是貓辨別音差須開最少5度,比起人類辨別音差須開最少0.5度來得粗疏。[51][47]
嗅覺[编辑]
家貓的嗅覺較人類靈敏14倍。[52]貓的鼻腔內有2億個嗅覺受器,數量甚至超過某些品種的狗(狗嗅覺細胞約1.25億~2.2億)。
味覺[编辑]
貓早期演化時由於基因突變,失去了甜的味覺,[53]但貓不光能感知酸、苦、鹹味,选择适合自己口味的食物,还能尝出水的味道,这一点是其他动物所不及的。不过总括来说猫的味觉不算完善,相比一般人類平均有9000個味蕾,貓一般平均僅有473個味蕾且不喜好低於室溫之食物。故此,貓辨認食物乃憑嗅覺多於味覺。[47]
觸覺[编辑]
貓在磨蹭時身上會散發出特別的費洛蒙,當這些獨有的費洛蒙留下時,目的就是在宣誓主權,提醒其它貓這是我的,其實這種行為算是一種標記地盤的象徵,會讓牠們有感到安心及安全感。
被毛[编辑]
主条目:貓的毛色遺傳和顏色
長度[编辑]
貓主要可以依據被毛長度分為長毛貓,短毛貓和無毛貓。' metadata={'source': 'https://zh.wikipedia.org/wiki/%E7%8C%AB', 'title': '猫 - 维基百科,自由的百科全书', 'language': 'zh'}
现在,我们已经填充了我们将要进行Retriever的索引,我们可以轻松地将其转换为一个工具(代理程序正确使用所需的格式)
# 封装为一个工具调用
retriever_tool = create_retriever_tool(
retriever,
name="wiki-cat",
description="A tool to retrieve information about cats from Wikipedia",
)
工具
以上我们只是创建了工具的一部分,还没有到我们agent的部分,工具有了之后还需要一个大语言模型
下面是一个工具列表
tools = [search, retriever_tool]
使用语言模型
接下来,让我们学习如何使用语言模型来调用工具。LangChain支持许多可以互换使用的不同语言模型-选择您想要使用的语言模型!
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4")
通过传入消息列表来调用语言模型,默认情况下,响应是一个content字符串
from langchain_core.messages import HumanMessage
response = model.invoke([HumanMessage(content="hi!")])
response.content
Hello! 😊 How can I assist you today?
现在,我们可以看看如何使这个模型能够调用工具。为了使其具备这种能力,我们使用**.bind_tools**来让语言模型了解这些工具。
model_with_tools = model.bind_tools(tools)
现在开始调用模型,让我们首先用一个普通的消息来调用它,看看它的响应。我们可以查看content字段和tool_calls字段。
response = model_with_tools.invoke([HumanMessage(content="你好")])
print(f"ContentString: {response.content}")
print(f"ToolCalls: {response.tool_calls}")
Hello! How can I assist you today?
ContentString:
ToolCalls: [{'name': 'tavily_search', 'args': {'query': '天津今天天气', 'search_depth': 'basic'}, 'id': 'call_qsCCkfNtJ0qIznMIyZlX5spM', 'type': 'tool_call'}]
我们可以看到现在没有内容,但有一个工具调用!它要求我们调用Tavily Search工具。注意当提问一些简单的问题的时候,不会准备调用工具,比如问候语这种
完整代码:
# 环境变量需要在WebBaseLoader之前加载,因为会找USERAGENT环境变量
from dotenv import load_dotenv
load_dotenv(override=True)
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_core.tools import create_retriever_tool
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = WebBaseLoader("https://zh.wikipedia.org/wiki/%E7%8C%AB")
# 把网页内容加载为一个文档对象
docs = loader.load()
document = RecursiveCharacterTextSplitter(
# chunk_size参数在RecursiveCharacterTextSplitter中表示每个文档块的最大字符数,它的作用主要在以下几个方面:
# chunk_overlap参数用于指定在分割文档时,每个块之间的重叠字符数。这意味着当文档被分割成多个块时,每个块的末尾和下一个块的开头会有一部分重叠的字符。
# 第一个块包含字符1到1000,第二个块包含字符801到1800,第三个块包含字符1601到2600,以此类推。
chunk_size=1000, chunk_overlap=200,
).split_documents(docs)
vector = FAISS.from_documents(document, OpenAIEmbeddings()) # 默认的向量模型是ada-002
retriever = vector.as_retriever()
# 封装为一个工具准备调用
retriever_tool = create_retriever_tool(
retriever,
name="wiki-cat",
description="A tool to retrieve information about cats from Wikipedia",
)
from langchain_tavily import TavilySearch
search = TavilySearch(max_result = 1)
print(search.invoke("今天天津天气怎么样"))
# 组装成一个工具列表
tools = [search, retriever_tool]
from langchain_openai import ChatOpenAI
model = ChatOpenAI()
from langchain_core.messages import HumanMessage
response = model.invoke([HumanMessage(content="hi!")])
print(response.content)
model_with_tools = model.bind_tools(tools)
response = model_with_tools.invoke([HumanMessage(content="今天天津天气怎么样")])
print(f"ContentString: {response.content}")
print(f"ToolCalls: {response.tool_calls}")
这并不是在调用该工具——它只是告诉我们要调用,还没有实际调用。为了实际调用它,我们将创建我们的代理程序。
创建代理程序
既然我们已经定义了工具和LLM,我们可以创建代理程序。我们将使用一个工具调用代理程序——有关此类代理程序以及其他选项的更多信息
请参阅此指南。
我们可以首先选择要用来指导代理程序的提示。
如果您想查看此提示的内容并访问LangSmith,您可以转到:
https://smith.langchain.com/hub/hwchase17/openai-functions-agent
from langchain import hub
# 获取要使用的提示 - 您可以修改这个!
# hwchase17/openai-functions-agent是一个提示词仓库,里面有写好的提示词可以直接调用
prompt = hub.pull("hwchase17/openai-functions-agent")
print(prompt.messages)

现在,我们可以使用LLM、提示和工具初始化代理。代理负责接收输入并决定采取什么行动。关键的是,代理不执行这些操作-这是由AgentExecutor(下一步)完成的。
请注意,我们传递的是model,而不是model_with_tools。这是因为create_tool_calling_agent会在幕后调用.bind_tools。
from langchain.agents import create_tool_calling_agent
agent = create_tool_calling_agent(model, tools, prompt)
最后,我们将代理(大脑)与AgentExecutorr中的工具结合起来(AgentExecutor将重复调用代理并执行工具)
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools)
{'input': '你好', 'output': '你好!有什么可以帮助你的吗?'}
运行代理
上面的问候式的agent的响应是无状态查询(他不会记住先前的交互),并且也没有调用工具
为了确切了解底层发生了什么(并确保它没有调用工具),我们可以查看LangSmith跟踪
现在让我们尝试一个应该调用检索器的示例:
print(agent_executor.invoke({"input": "猫的特征"}))
# 环境变量需要在WebBaseLoader之前加载
from dotenv import load_dotenv
load_dotenv(override=True)
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_core.tools import create_retriever_tool
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = WebBaseLoader("https://baike.baidu.com/item/%E7%8C%AB/22261")
# 把网页内容加载为一个文档对象
docs = loader.load()
document = RecursiveCharacterTextSplitter(
# chunk_size参数在RecursiveCharacterTextSplitter中表示每个文档块的最大字符数,它的作用主要在以下几个方面:
# chunk_overlap参数用于指定在分割文档时,每个块之间的重叠字符数。这意味着当文档被分割成多个块时,每个块的末尾和下一个块的开头会有一部分重叠的字符。
# 第一个块包含字符1到1000,第二个块包含字符801到1800,第三个块包含字符1601到2600,以此类推。
chunk_size=1000, chunk_overlap=200,
).split_documents(docs)
vector = FAISS.from_documents(document, OpenAIEmbeddings()) # 默认的向量模型是ada-002
retriever = vector.as_retriever()
# 封装为一个工具准备调用
retriever_tool = create_retriever_tool(
retriever,
name="wiki-cat",
description="A tool to retrieve information about cats from Wikipedia",
)
from langchain_tavily import TavilySearch
search = TavilySearch(max_result = 1)
# 组装成一个工具列表
tools = [search, retriever_tool]
from langchain_openai import ChatOpenAI
model = ChatOpenAI()
#示例:agent_tools_create.py
from langchain import hub
# 获取要使用的提示 - 您可以修改这个!
prompt = hub.pull("hwchase17/openai-functions-agent")
# print(prompt.messages)
# 使用LLM,工具和提示词初始化一个代理agent
from langchain.agents import create_tool_calling_agent
agent = create_tool_calling_agent(model, tools, prompt)
# 创建一个AgentExecutor,它将代理和工具结合起来,以便在调用时使用
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 运行代理
print(agent_executor.invoke({"input":"猫的特征?今天上海天气怎么样?"}))

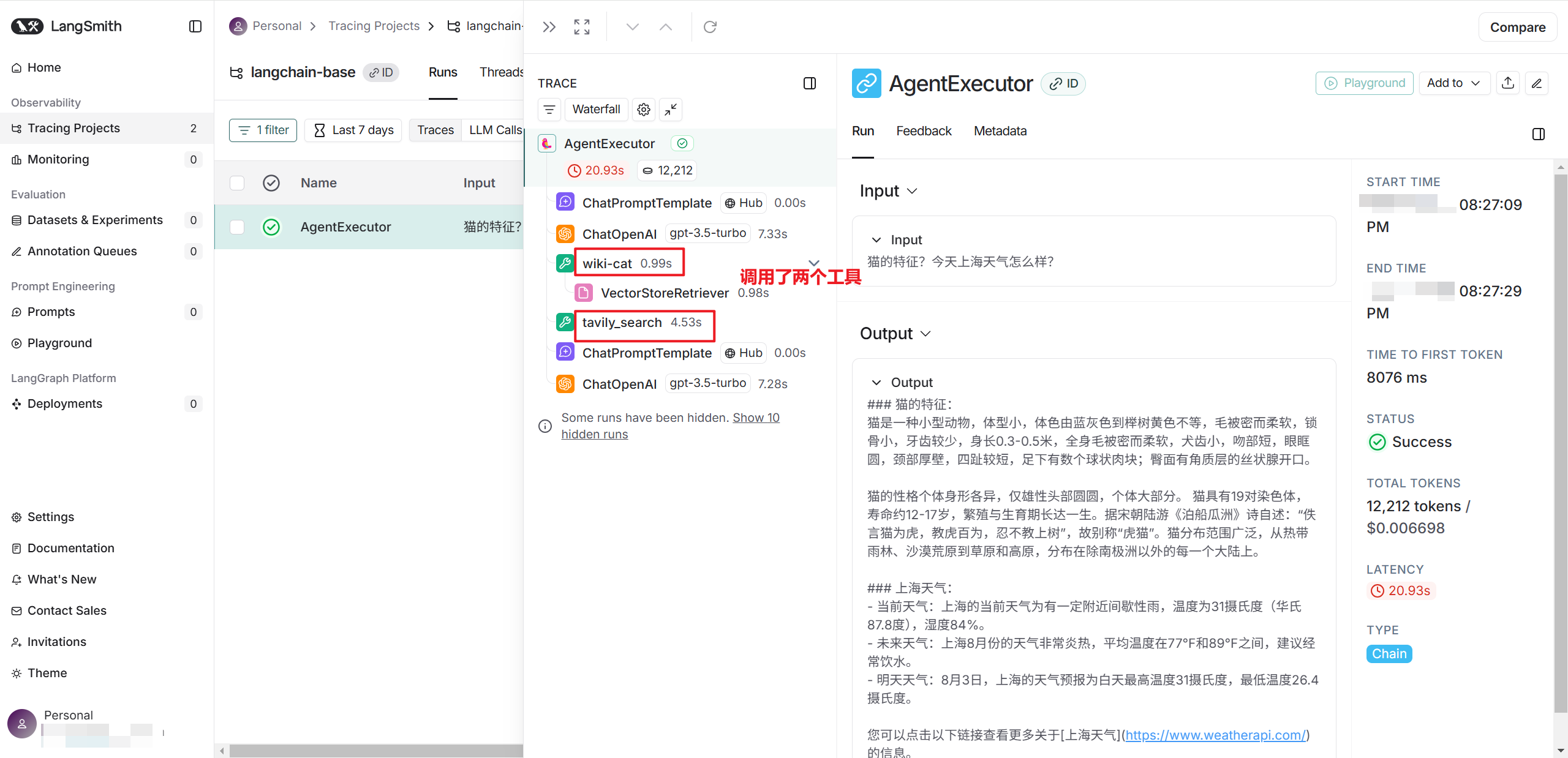
可以看到agent对任务进行了拆分,并且对于每个任务都有对应的工具调用。
通过langSmith可以观察到整个调用过程
添加记忆
如前所述,此代理是无状态的。这意味着它不会记住先前的交互。要给它记忆,我们需要传递先前的chat_history。注意:由于我们使用相同的提示,它需要被称为chat_history。如果我们使用不同的提示,我们可以更改变量名
from langchain_core.messages import AIMessage, HumanMessage
agent_executor.invoke(
{
"chat_history": [
HumanMessage(content="hi! my name is bob"),
AIMessage(content="你好Bob!我今天能帮你什么?"),
],
"input": "我的名字是什么?",
}
)

如果我们想要自动跟踪这些消息,我们可以将其包装在一个RunnableWithMessageHistory中
也就是我们想要做会话隔离,当有不同的会话,我们需要用session_id来区分不同的会话
#示例:agent_tools_memory_store.py
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
因为我们有多个输入,我们需要指定两个事项:
- input_messages._key:用于将输入添加到对话历史记录中的键。
- history_messages_key:用于将加载的消息添加到其中的键。
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
)
response = agent_with_chat_history.invoke(
{"input": "Hi,我的名字是Cyber"},
config={"configurable": {"session_id": "123"}},
)
response = agent_with_chat_history.invoke(
{"input": "我叫什么名字?"},
config={"configurable": {"session_id": "123"}},
)
# 环境变量需要在WebBaseLoader之前加载
from dotenv import load_dotenv
load_dotenv(override=True)
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_core.tools import create_retriever_tool
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = WebBaseLoader("https://baike.baidu.com/item/%E7%8C%AB/22261")
# 把网页内容加载为一个文档对象
docs = loader.load()
document = RecursiveCharacterTextSplitter(
# chunk_size参数在RecursiveCharacterTextSplitter中表示每个文档块的最大字符数,它的作用主要在以下几个方面:
# chunk_overlap参数用于指定在分割文档时,每个块之间的重叠字符数。这意味着当文档被分割成多个块时,每个块的末尾和下一个块的开头会有一部分重叠的字符。
# 第一个块包含字符1到1000,第二个块包含字符801到1800,第三个块包含字符1601到2600,以此类推。
chunk_size=1000, chunk_overlap=200,
).split_documents(docs)
vector = FAISS.from_documents(document, OpenAIEmbeddings()) # 默认的向量模型是ada-002
retriever = vector.as_retriever()
# 封装为一个工具准备调用
retriever_tool = create_retriever_tool(
retriever,
name="wiki-cat",
description="A tool to retrieve information about cats from Wikipedia",
)
from langchain_tavily import TavilySearch
search = TavilySearch(max_result = 1)
# 组装成一个工具列表
tools = [search, retriever_tool]
from langchain_openai import ChatOpenAI
model = ChatOpenAI()
#示例:agent_tools_create.py
from langchain import hub
# 获取要使用的提示 - 您可以修改这个!
prompt = hub.pull("hwchase17/openai-functions-agent")
# print(prompt.messages)
# 使用LLM,工具和提示词初始化一个代理agent
from langchain.agents import create_tool_calling_agent
agent = create_tool_calling_agent(model, tools, prompt)
# 创建一个AgentExecutor,它将代理和工具结合起来,以便在调用时使用
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
#示例:agent_tools_memory_store.py
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
)
response = agent_with_chat_history.invoke(
{"input": "Hi,我的名字是Cyber"},
config={"configurable": {"session_id": "123"}},
)
print(response)
response = agent_with_chat_history.invoke(
{"input": "我叫什么名字?"},
config={"configurable": {"session_id": "123"}},
)
print(response)
response = agent_with_chat_history.invoke(
{"input": "我叫什么名字?"},
config={"configurable": {"session_id": "456"}},
)
print(response)
可以看到第一次id为123的对话的信息被存储到chat_history中
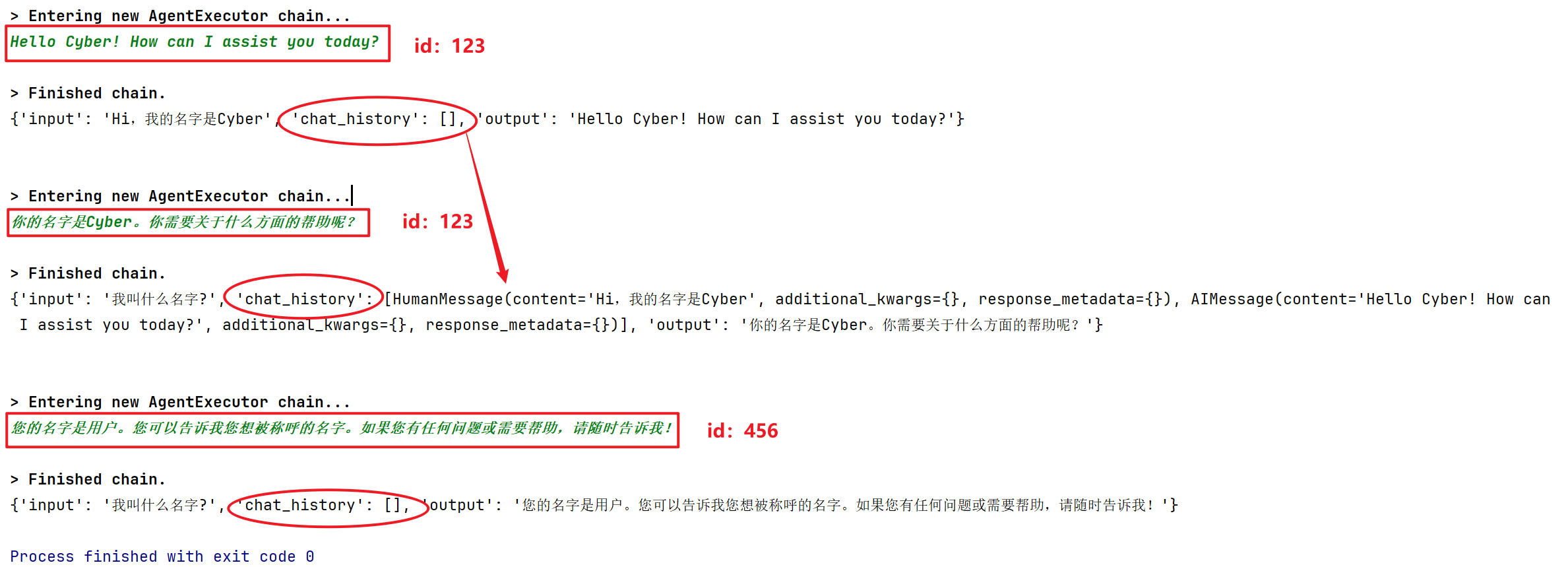
9.Langchain基于RAG实现文档问答
RAG是什么?
大语言模型所实现的最强大应用之一是复杂的问答(Q&A)聊天机器人。这些应用能够回答关于特定源信息的问题。这些应用使用一种称为检索增强生成(RAG)的技术。
RAG是一种用额外数据增强大语言模型知识的技术。
大语言模型可以对广泛的主题进行推理,但它们的知识仅限于训练时截止日期前的公开数据。如果你想构建能够对私有数据或模型截止日期后引入的数据进行推理的人工智能应用,你需要用特定信息来增强模型的知识。检索适当信息并将其插入模型提示的过程被称为检索增强生成(RAG)。
LangChain有许多组件旨在帮助构建问答应用,以及更广泛的RAG应用。
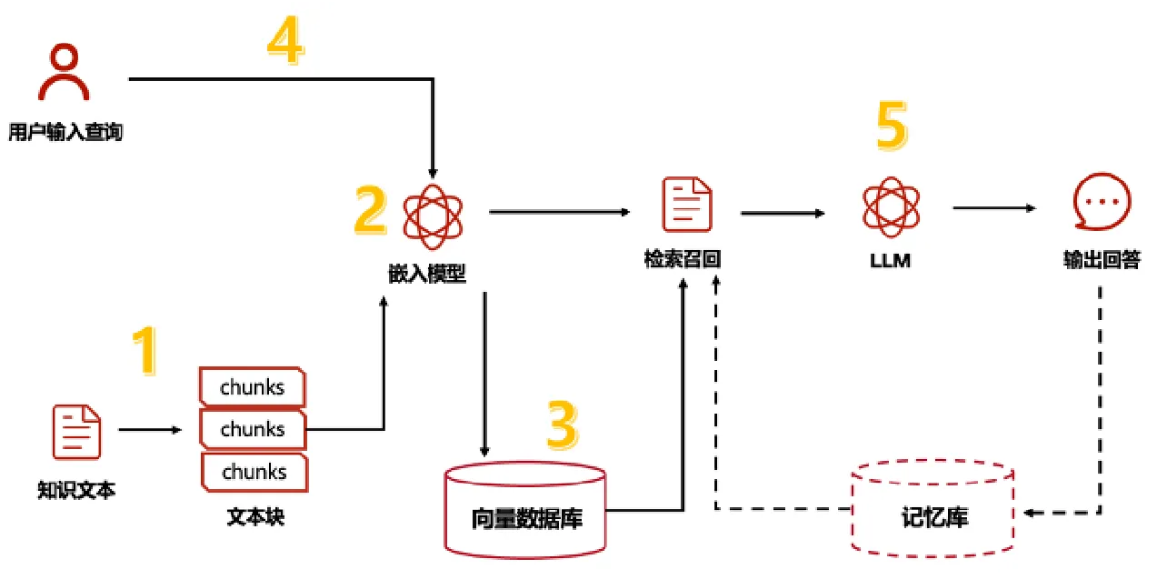
RAG工作流
一个典型的RAG应用有两个主要组成部分:
索引(Indexing):从数据源获取数据并建立索的管道(pipeline)。这通常在离线状态下进行。
检索和生成(Retrieval and generation):实际的RAG链,在运行时接收用户查询,从索引中检索相关数据,然后将其传递给模型。
从原始数据到答案的最常见完整顺序如下:
索引(Indexing)
1.加载(Load):首先我们需要加载数据。这是通过文档加载器Document_Loaders完成的。
2.分割(Split):文本分割器Text splitters将大型文档(Documents)分成更小的块(chunks)。这对于索引数据和将其传递给模型都很有用,因为大块数据更难搜索,而且不适合模型有限的上下文窗口。
3.存储(Store):我们需要一个地方来存储和索引我们的分割(splits),以便后续可以对其进行搜索。这通常使用向量存储VectorStore和嵌入模型Embeddings model来完成。
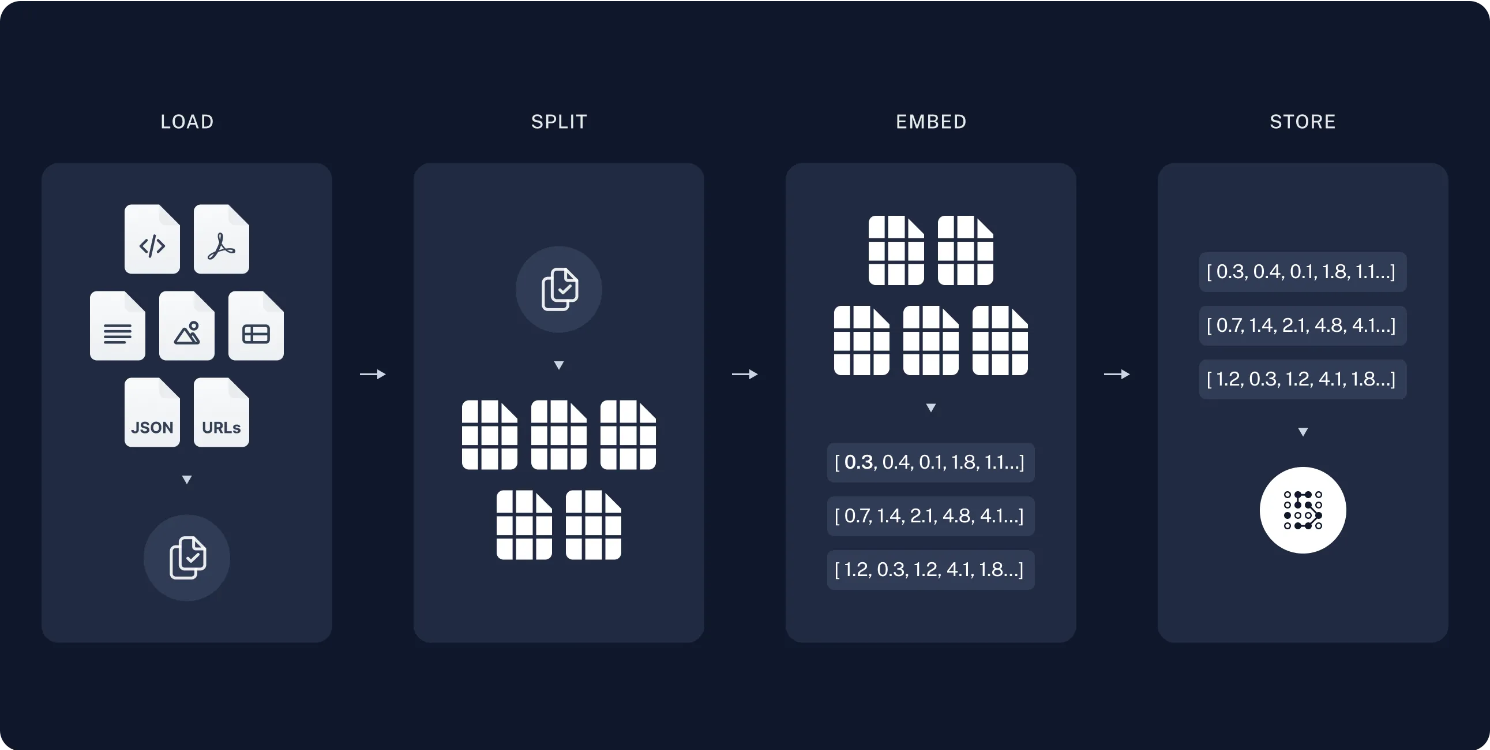
检索和生成(Retrieval and generation)
检索(Retrieve):给定用户输入,使用检索器Retriever)从存储中检索相关的文本片段。
生成(Generate):ChatModel使用包含问题和检索到的数据的提示来生成答案。
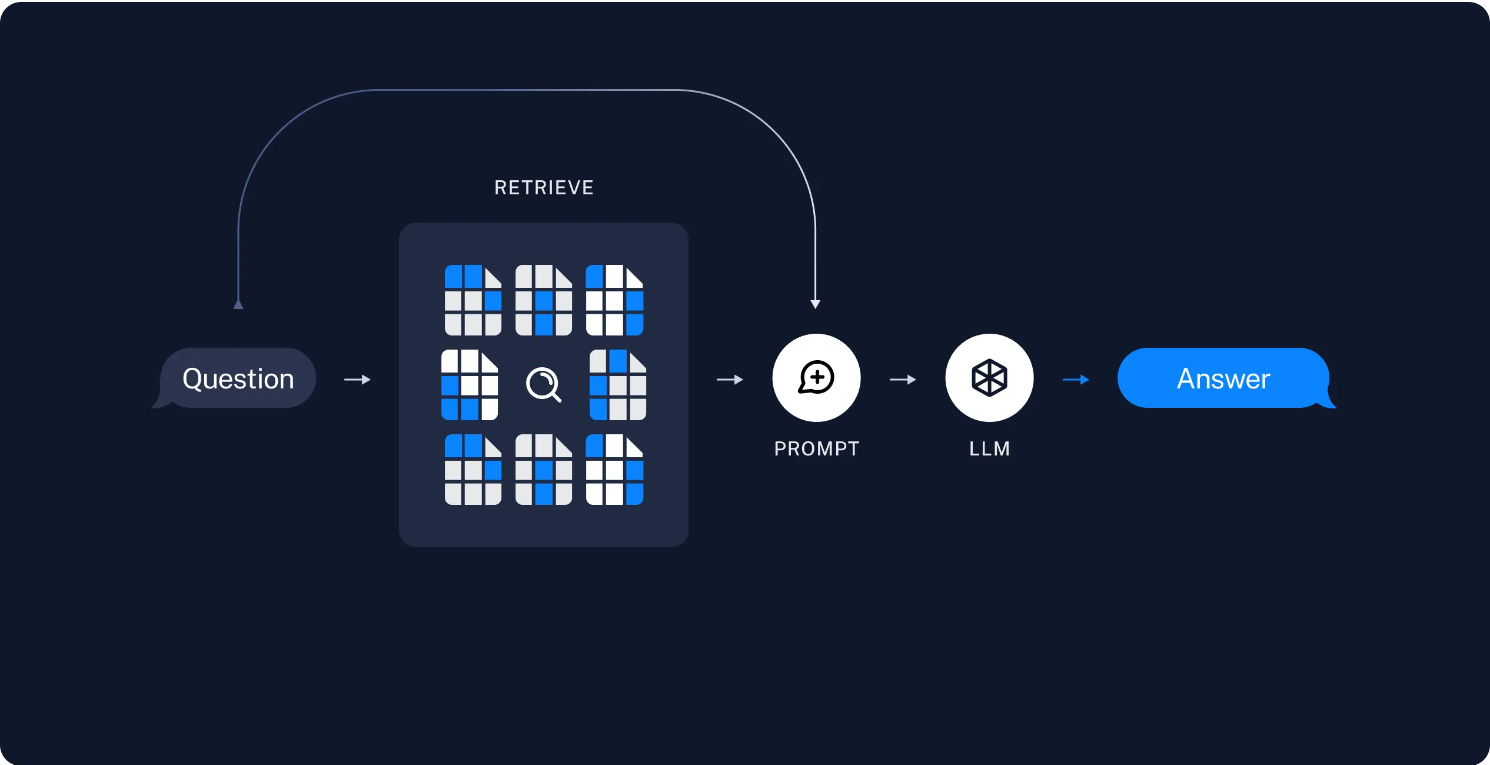
文档问答
下面是一个实际案例的实现
实现流程
一个RAG程序的APP主要有以下流程:
1.用户在RAG客户端上传一个txt文件
2.服务器端接收客户端文件,存储在服务端
3.服务器端程序对文件进行读取
4.对文件内容进行拆分,防止一次性塞给Embedding模型超token限制
5.把Embedding后的内容存储在向量数据库,生成检索器
6.程序准备就绪,允许用户进行提问
7.用户提出问题,大模型调用检索器检索文档,把相关片段找出来后,组织后,回复用户。
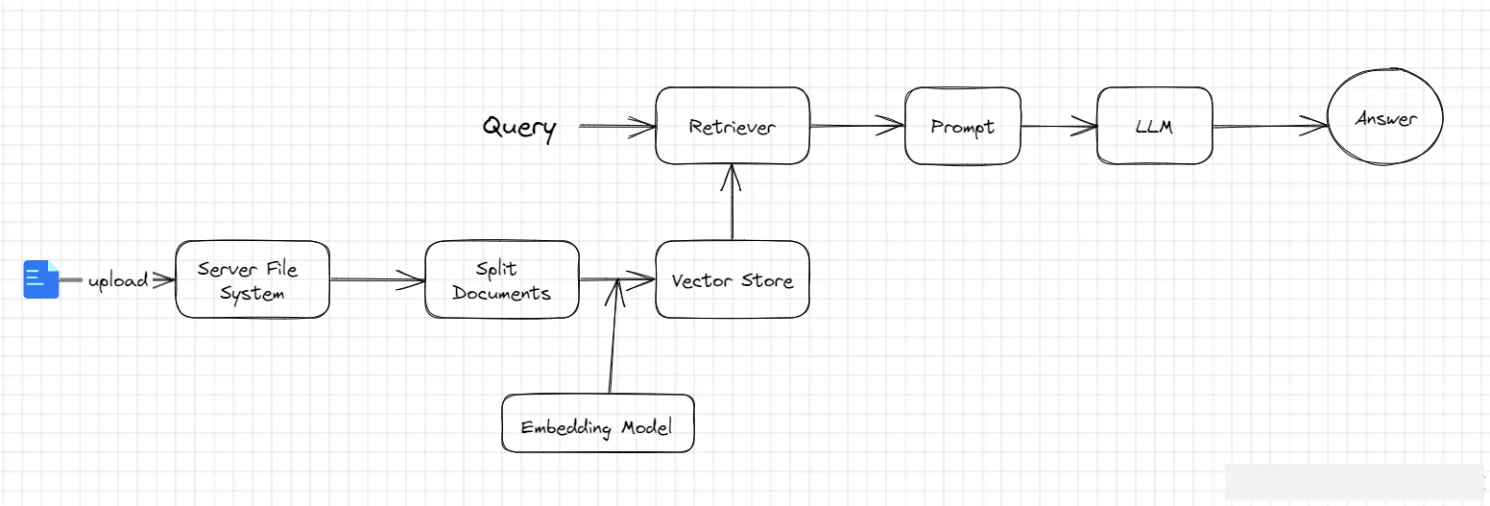
代码实现
使用Streamlit实现文件上传,我这里只实现了txt文件上传,其实这里可以在type参数里面设置多个文件类型,在后面的检索器方法里面
针对每个类型进行处理即可。
实现文件上传
import streamlit as st
# 上传txt文件,允许上传多个文件
uploaded_files = st.sidebar.file_uploader(
label="上传txt文件", type=["txt"], accept_multiple_files=True
)
if not uploaded_files:
st.info("请先上传按TXT文档。")
st.stop()
实现检索器
注意chunk_size最大设置数值取决于Embedding模型允许单词的最大字符数限制。
import tempfile
import os
from langchain.document_loaders import TextLoader
from langchain_community.embeddings import QianfanEmbeddingsEndpoint
from langchain_chroma import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 实现检索器
@st.cache_resource(ttl="1h")
def configure_retriever(uploaded_files):
# 读取上传的文档,并写入一个临时目录
docs = []
temp_dir = tempfile.TemporaryDirectory(dir=r"D:\\")
for file in uploaded_files:
temp_filepath = os.path.join(temp_dir.name, file.name)
with open(temp_filepath, "wb") as f:
f.write(file.getvalue())
loader = TextLoader(temp_filepath, encoding="utf-8")
docs.extend(loader.load())
# 进行文档分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=30)
splits = text_splitter.split_documents(docs)
# 这里使用了OpenAI向量模型
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(splits, embeddings)
retriever = vectordb.as_retriever()
return retriever
retriever = configure_retriever(uploaded_files)
创建检索工具
langchain提供了create_retriever_tool工具,可以直接用。
# 创建检索工具
from langchain.tools.retriever import create_retriever_tool
tool = create_retriever_tool(
retriever,
"文档检索",
"用于检索用户提出的问题,并基于检索到的文档内容进行回复.",
)
tools = [tool]
创建React Agent
instructions = """您是一个设计用于查询文档来回答问题的代理。
您可以使用文档检索工具,并基于检索内容来回答问题
您可能不查询文档就知道答案,但是您仍然应该查询文档来获得答案。
如果您从文档中找不到任何信息用于回答问题,则只需返回“抱歉,这个问题我还不知道。”作为答案。
"""
base_prompt_template = """
{instructions}
TOOLS:
------
You have access to the following tools:
{tools}
To use a tool, please use the following format:
•```
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
•```
When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format:
•```
Thought: Do I need to use a tool? No
Final Answer: [your response here]
•```
Begin!
Previous conversation history:
{chat_history}
New input: {input}
{agent_scratchpad}"""
base_prompt = PromptTemplate.from_template(base_prompt_template)
prompt = base_prompt.partial(instructions=instructions)
# 创建llm
llm = ChatOpenAI()
# 创建react Agent
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, memory=memory, verbose=False)
实现Agent回复
# 创建聊天输入框
user_query = st.chat_input(placeholder="请开始提问吧!")
if user_query:
st.session_state.messages.append({"role": "user", "content": user_query})
st.chat_message("user").write(user_query)
with st.chat_message("assistant"):
st_cb = StreamlitCallbackHandler(st.container())
config = {"callbacks": [st_cb]}
response = agent_executor.invoke({"input": user_query}, config=config)
st.session_state.messages.append({"role": "assistant", "content": response["output"]})
st.write(response["output"])
实现效果
完整代码:
from dotenv import load_dotenv
load_dotenv(override=True)
# pip install streamlit==1.39.0
import streamlit as st
import tempfile
import os
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_message_histories import StreamlitChatMessageHistory
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
from langchain_core.prompts import PromptTemplate
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.agents import create_react_agent, AgentExecutor
from langchain_community.callbacks.streamlit import StreamlitCallbackHandler
from langchain_openai import ChatOpenAI
# 设置Streamlit应用的页面标题和布局
st.set_page_config(page_title="文档问答", layout="wide")
# 设置标题
st.title("文档问答")
# 上传txt文件,允许上传多个文件
uploaded_files = st.sidebar.file_uploader(
label="上传txt文件", type=["txt"], accept_multiple_files=True
)
if not uploaded_files:
st.info("请先上传TXT文档。")
st.stop()
# Cache resource
@st.cache_resource(ttl="1h")
def configure_retriever(uploaded_files):
docs = []
temp_dir = tempfile.TemporaryDirectory(dir=r"D:\\")
for file in uploaded_files:
temp_filepath = os.path.join(temp_dir.name, file.name)
with open(temp_filepath, "wb") as f:
f.write(file.getvalue())
# 使用TextLoader加载文本文件
loader = TextLoader(temp_filepath, encoding="utf-8")
docs.extend(loader.load())
# 进行文本分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# 使用OpenAIEmbeddings创建向量数据库
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(splits, embeddings)
# 创建文档检索器
retriever = vectordb.as_retriever()
return retriever
# 配置检索器
retriever = configure_retriever(uploaded_files)
# 如果会话状态中没有消息,或者用户点击了“清空聊天记录”按钮,则初始化消息列表
if "messages" not in st.session_state or st.sidebar.button("清空聊天记录"):
st.session_state.messages = [{"role": "assistant", "content": "您好,我是文档问答助手"}]
# 加载历史消息并显示在聊天界面
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
# 创建检索工具
from langchain.tools.retriever import create_retriever_tool
tool = create_retriever_tool(
retriever,
name="文档检索",
description="用于检索用户提出的问题,并基于检索到的文档内容进行回答。",
)
tools = [tool]
# 创建聊天消息历史记录
msg_history = StreamlitChatMessageHistory()
# 创建对话缓冲区内存
memory = ConversationBufferMemory(
chat_memory=msg_history, return_messages=True, memory_key="chat_history", output_key="output"
)
instructions = """
您是一个设计用于查询文档来回答问题的代理。
您可以使用文档检索工具,并基于检索内容回答问题。
您可能不能查询文档外的信息,但是您仍然可以查询文档来获得答案。
如果您从文档中找不到任何用于回答问题的信息,则只需返回“抱歉,这个问题我还不知道。”作为答复。
"""
base_prompt_template = """
{instructions}
TOOLS:
------
You have access to the following tools:
{tools}
To use a tool, please use the following format:
{tools}
To use a tool, please use the following format:
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [{tool_names}]
Action Input: {input}
Observation: the result of the action
When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format:
Thought: Do I need to use a tool? No
Final Answer: [your response here]
Begin!
Previous conversation history:
{chat_history}
Begin!
New input: {input}
{agent_scratchpad}
"""
# 创建基础提示词模板
base_prompt = PromptTemplate.from_template(base_prompt_template)
# 创建部分填充的提示词模板
prompt = base_prompt.partial(instructions=instructions)
# 创建LLM
llm = ChatOpenAI()
# 创建react agent
agent = create_react_agent(llm, tools, prompt)
# 创建Agent执行器
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
verbose=True,
handle_parsing_errors=True, # 添加这个参数
)
# 创建聊天输入框
user_query = st.chat_input(placeholder="请开始提问!")
# 如果用户输入了查询,则将其添加到会话状态的消息列表中,并显示在聊天界面上
if user_query:
# 添加用户消息到session_state
st.session_state.messages.append({"role": "user", "content": user_query})
# 现实用户消息
st.chat_message("user").write(user_query)
with st.chat_message("assistant"):
# 创建Streamlit回调处理器
st_cb = StreamlitCallbackHandler(st.container())
# agent执行过程日志回调喜爱你是在Streamlit Container(如思考、选择工具、观察结果等)
config = {"callbacks": [st_cb]}
# 执行agent并且获取响应
response = agent_executor.invoke(input={"input": user_query}, config=config)
# 添加助手消息到session_state
st.session_state.messages.append({"role": "assistant", "content": response["output"]})
# 显示助手消息
st.write(response["output"])
命令行启动运行:
streamlit run doc-chat.py
显示效果:
10.LangGraph快速入门与底层原理
LangGraph
LangGraph是一个用于构建具有LLMs的有状态、多角色应用程序的库,用于创建代理和多代理工作流。与其他LLM框架相比,它提供了以下核心优势:循环、可控性和持久性。
LangGraph允许您定义涉及循环的流程,这对于大多数代理架构至关重要。作为一种非常底层的框架,它提供了对应用程序的流程和状态的精细控制,这对创建可靠的代理至关重要。此外,LangGraph包含内置的持久性,可以实现高级的“人机交互”和内存功能。
LangGraph是LangChain的高级库,为大型语言模型(LLM)带来循环计算能力。它超越了LangChain的线性工作流,通过循环支持复杂的任务处理。
- 状态:维护计算过程中的上下文,实现基于累积数据的动态决策
- 节点:代表计算步骤,执行特定任务,可以定制以适应不同的工作流
- 边:连接节点,定义计算流程,支持条件逻辑,实现复杂工作流
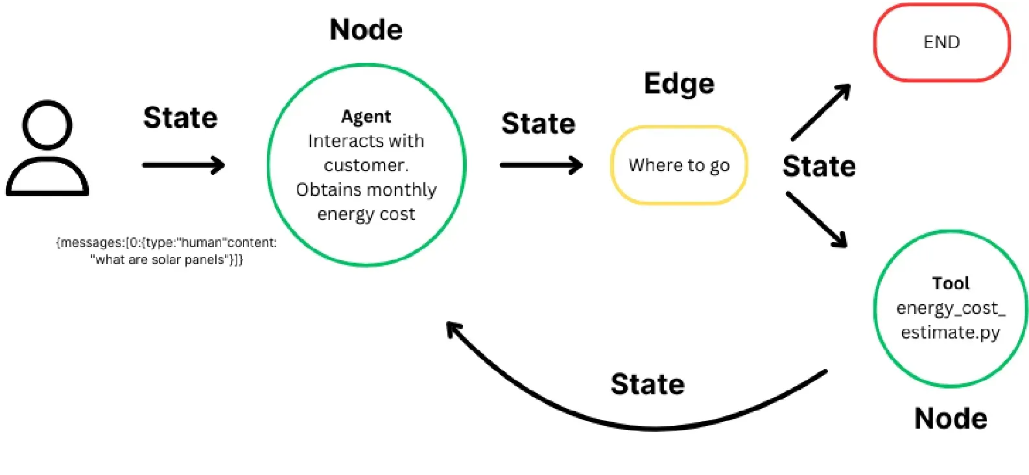
主要功能
- 循环和分支:在您的应用程序中实现循环和条件语句。
- 持久性:在图中的每个步骤之后自动保存状态。在任何时候暂停和恢复图执行以支持错误恢复、“人机交互”工作流、时间旅行等等。
- “人机交互”:中断图执行以批准或编辑代理计划的下一个动作。
- 流支持:在每个节点产生输出时流式传输输出(包括令牌流式传输)。
- 与LangChain集成:LangGraph与LangChain和LangSmith无缝集成(但不需要它们)。
安装
pip install -U langgraph
示例
from dotenv import load_dotenv
# 加载环境变量
load_dotenv(override=True)
#示例:langgraph_hello.py
from typing import Literal
from langchain_core.messages import HumanMessage
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
# pip install langgraph
# 导入LangGraph检查点,用于持久化状态
from langgraph.checkpoint.memory import MemorySaver
# 导入状态图和状态
from langgraph.graph import END, StateGraph, MessagesState
# 导入工具节点,用来调用工具
from langgraph.prebuilt import ToolNode
# 定义工具函数,用于代理调用外部工具
@tool
def search(query: str):
"""模拟一个搜索工具"""
if "上海" in query.lower() or "Shanghai" in query.lower():
return "现在30度,有雾."
return "现在是35度,阳光明媚。"
# 将工具函数放入工具列表
tools = [search]
# 创建工具节点
tool_node = ToolNode(tools)
# 1.初始化模型和工具,定义并绑定工具到模型,因为我们将使用模型来调用工具,大模型来决定何时调用工具
model = ChatOpenAI(temperature=0).bind_tools(tools)
# 定义函数,决定是否继续执行
# 路由函数,我当前的结点是需要调用工具还是需要结束,这个函数做了一个判断
# 拿到state里面的message,这个message是大模型返回的消息,如果大模型需要调用工具,那么就会在消息里面带一个tool_calls对象
# 所以LangGraph需要一个函数来解析大模型返回的消息,然后看有没有tool_calls对象,有的话就返回tools,也就是返回这个边的名字
# Literal["tools", END]字面量,就是两类边
def should_continue(state: MessagesState) -> Literal["tools", END]:
messages = state['messages']
last_message = messages[-1]
# 如果LLM调用了工具,则转到“tools”节点
if last_message.tool_calls:
return "tools"
# 否则,停止(回复用户)
return END
# 定义调用模型的函数
# MessagesState传递提示词
def call_model(state: MessagesState):
messages = state['messages']
response = model.invoke(messages)
# 返回列表,因为这将被添加到现有列表中
return {"messages": [response]}
# 2.用状态初始化图,定义一个新的状态图
workflow = StateGraph(MessagesState)
# 3.定义图节点,定义我们将循环的两个节点
workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node)
# 4.定义入口点和图边
# 设置入口点为“agent”
# 这意味着这是第一个被调用的节点
workflow.set_entry_point("agent")
# 添加条件边
workflow.add_conditional_edges(
# 首先,定义起始节点。我们使用`agent`。
# 这意味着这些边是在调用`agent`节点后采取的。
"agent",
# 接下来,传递决定下一个调用节点的函数。
# 边的走向通过路由函数决定
should_continue,
)
# 添加从`tools`到`agent`的普通边。
# 这意味着在调用`tools`后,接下来调用`agent`节点。
workflow.add_edge("tools", 'agent')
# 初始化内存以在图运行之间持久化状态,相当于存档
checkpointer = MemorySaver() # 可以存redis,可以是mongodb
# 5.编译图
# 这将其编译成一个LangChain可运行对象,
# 这意味着你可以像使用其他可运行对象一样使用它。
# 注意,我们(可选地)在编译图时传递内存
app = workflow.compile(checkpointer=checkpointer)
# 6.执行图,使用可运行对象
final_state = app.invoke(
{"messages": [HumanMessage(content="上海的天气怎么样?")]},
config={"configurable": {"thread_id": 42}}
)
# 从 final_state 中获取最后一条消息的内容
result = final_state["messages"][-1].content
print(result)
上海现在的天气是30度,有雾。
现在,当我们传递相同的"thread id"时,对话上下文将通过保存的状态(即存储的消息列表)保留下来。
final_state = app.invoke(
{"messages": [HumanMessage(content="我刚才问的是哪个城市?")]}, # 其实是在检查存储点是否有效
config={"configurable": {"thread_id": 42}}
)
result = final_state["messages"][-1].content
print(result)
您刚才问的是上海的天气。
逐步分解
1.初始化模型和工具
- 我们使用ChatopenAI作为我们的LLM。注意:我们需要确保模型知道可以使用哪些工具。我们可以通过将LangChain工具转换为OpenAl工具调用格式来完成此操作,方法是使用.bind tools()方法。
- 我们定义要使用的工具一在本例中是搜索工具。创建自己的工具非常容易一请参阅此处的文档了解如何操作此处。
2.用状态初始化图
- 我们通过传递状态模式(在本例中为Messagesstate)来初始化图(StateGraph)。
- Messagesstate是一个预构建的状态模式,它具有一个属性,一个LangChain Message对象列表,以及将每个节点的更新合并到状态中的逻辑。
3.定义图节点
我们需要两个主要节点:
- agent节点:负责决定采取什么(如果有)行动
- 调用工具的tools节点:如果代理决定采取行动,此节点将执行该行动
4.定义入口点和图边
首先,我们需要设置图执行的入口点一一agent节点。然后,我们定义一个普通边和一个条件边。条件边意味着目的地取决于图状态(Messagestate)的内容。在本例中,目的地在代理(LLM)决定之前是未知的。
。条件边:调用代理后,我们应该要么
- a.如果代理说要采取行动,则运行工具
- b.如果代理没有要求运行工具,则完成(回复用户)。
。普通边:调用工具后,图应该始终返回到代理以决定下一步操作。
5.编译图
当我们编译图时,我们将其转换为LangChain Runnable,这会自动启用使用您的输入调用.invoke()、.stream()
和.batch()。
我们还可以选择传递检查点对象以在图运行之间持久化状态,并启用内存、“人机交互”工作流、时间旅行等等。在本例中,我们使用MemorySaver——一个简单的内存中检查点。
6.执行图
a.LangGraph将输入消息添加到内部状态,然后将状态传递给入口点节点"agent"。
b."agent"节点执行,调用聊天模型。
c.聊天模型返回AIMessage。LangGraph将其添加到状态中。
d.图循环以下步骤,直到AIMessage上不再有tool_calls
- 如果AIMessage具有too1ca1ls,则"tools’"节点执行。
- "agent"节点再次执行并返AIMessage
e.执行进度到特殊的END值,并输出最终状态。因此,我们得到所有聊天消息的列表作为输出。
11.LangGraph快速构建Agent工作流应用
Agent工作流
下面展示了如何创建一个“计划并执行”风格的代理,这在很大程度上借鉴了计划和解决论文以及Baby-AGI项目。核心思想是先制定一个多步骤计划,然后逐项执行。完成一项特定任务之后,您可以重新审视计划并且根据需要进行修改。
一般的计算图如下所示:
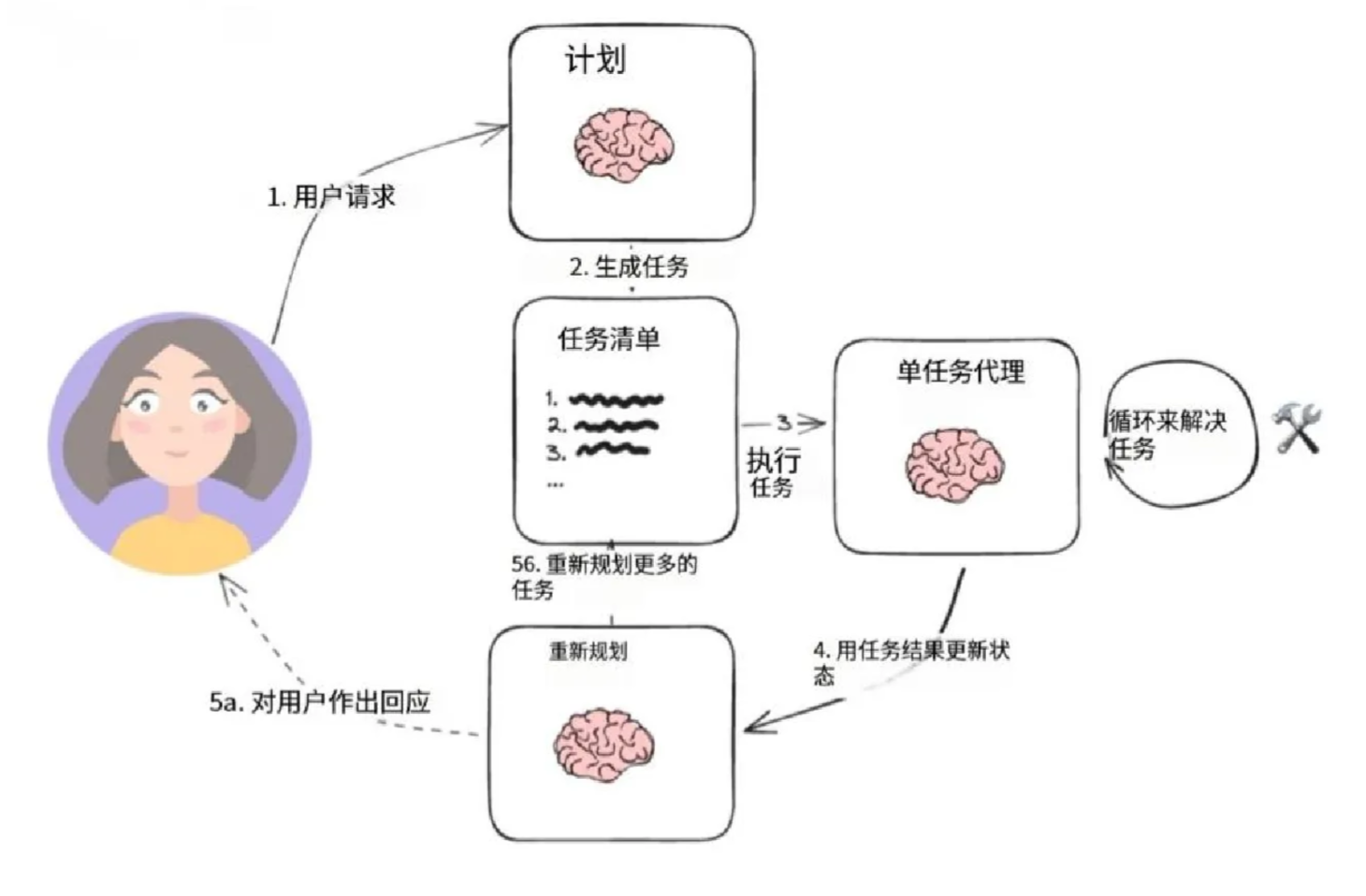
这与典型的React风格的代理进行了比较,在该代理中,您一次只思考一步,这种计划并且执行风格代理的优势在于:
1.明确的长期规划(即使是真正强大的LLM也难以做到)
2.能够使用更小更弱的模型来执行步骤,尽在规划步骤中使用更大更好的模型
设置
首先,我们需要安装所需的软件包
%pip install --quiet -U langgraph langchain-community langchain-openai tavily-python
接下来,我们需要为OpenAl 我们将使用的LLM)和Tavily (我们将使用的搜索工具)设置API密钥
可以选择设置LangSmith跟踪的API密钥,这将为我们提供一流的可观察性
setx TAVILY_API_KEY ""
# Optional, add tracing in LangSmith
setx LANGCHAIN_TRACING_V2 "true"
setx LANGCHAIN_API_KEY ""
定义工具
我们将首先定义要使用的工具。 对于这个简单的示例,我们将使用Tavily内置的搜索工具。
#示例:plan_execute.py
from langchain_community.tools.tavily_search import TavilySearchResults
# 创建TavilySearchResults工具,设置最大结果数为1
tools = [TavilySearchResults(max_results=1)]
定义我们的执行代理
现在我们将创建要用于执行任务的执行代理。请注意,对于此示例,我们将对每个任务使用相同的执行代理,
但这并非必须如此。
from langchain import hub
from langchain_openai import ChatOpenAI
import asyncio
from langgraph.prebuilt import create_react_agent
# 从LangChain的Hub中获取prompt模板,可以进行修改
prompt = hub.pull("wfh/react-agent-executor")
prompt.pretty_print()
# 选择驱动代理的LLM,使用OpenAI的ChatGPT-4o模型
llm = ChatOpenAI(model="gpt-4o")
# 创建一个REACT代理执行器,使用指定的LLM和工具,并应用从Hub中获取的prompt
agent_executor = create_react_agent(llm, tools, messages_modifier=prompt)
================================ System Message ================================
You are a helpful assistant.
============================= Messages Placeholder =============================
{{messages}}
# 调用代理执行器,询问“谁是美国公开赛的冠军”
agent_executor.invoke({"messages": [("user", "谁是美国公开赛的获胜者")]})

定义状态
核心操作
现在让我们从定义要跟踪此代理的状态开始。
首先,我们需要跟踪当前计划。让我们将其表示为字符串列表。
接下来,我们应该跟踪先前执行的步骤。让我们将其表示为元组列表(这些元组将包含步骤及其结果)
最后,我们需要一些状态来表示最终响应以及原始输入。
import operator
from typing import Annotated, List, Tuple, TypedDict
# 定义一个TypedDict类PlanExecute,用于存储输入、计划、过去的步骤和响应
class PlanExecute(TypedDict):
input: str
plan: List[str] # 一个大的问题拆分成多个计划
past_steps: Annotated[List[Tuple], operator.add] # 计划执行的步骤,完成的状态
response: str
规划步骤
现在让我们考虑创建规划步骤。这将使用函数调用来创建计划。
from langchain_core.pydantic_v1 import BaseModel, Field
# 定义一个Plan模型类,用于描述未来要执行的计划
class Plan(BaseModel):
"""未来要执行的计划"""
steps: List[str] = Field(
description="需要执行的不同步骤,应该按顺序排列"
)
from langchain_core.prompts import ChatPromptTemplate
# 创建一个计划生成的提示模板
planner_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""对于给定的目标,提出一个简单的逐步计划。这个计划应该包含独立的任务,如果正确执行将得出正确的答案。不要添加任何多余的步骤。最后一步的结果应该是最终答案。确保每一步都有所有必要的信息 - 不要跳过步骤。""",
),
("placeholder", "{messages}"),
]
)
planner = planner_prompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(Plan)
# 调用计划生成器,询问“当前澳大利亚公开赛冠军的家乡是哪里?”
planner.invoke(
{
"messages": [
("user", "现任澳网冠军的家乡是哪里?")
]
}
)

重新规划步骤
现在我们创建一个根据上一步执行结果重新制定计划的步骤
from typing import Union
# 定义一个响应模型类,用于描述用户的响应
class Response(BaseModel):
"""用户响应"""
response: str
# 定义一个行为模型类,用于描述要执行的行为
class Act(BaseModel):
"""要执行的行为"""
action: Union[Response, Plan] = Field(
description="要执行的行为。如果要回应用户,使用Response。如果需要进一步使用工具获取答案,使用Plan。"
)
# 创建一个重新计划的提示模板
replanner_prompt = ChatPromptTemplate.from_template(
"""对于给定的目标,提出一个简单的逐步计划。这个计划应该包含独立的任务,如果正确执行将得出正确的答案。不要添加任何多余的步骤。最后一步的结果应该是最终答案。确保每一步都有所有必要的信息 - 不要跳过步骤。
你的目标是:
{input}
你的原计划是:
{plan}
你目前已完成的步骤是:
{past_steps}
相应地更新你的计划。如果不需要更多步骤并且可以返回给用户,那么就这样回应。如果需要,填写计划。只添加仍然需要完成的步骤。不要返回已完成的步骤作为计划的一部分。"""
)
# 使用指定的提示模板创建一个重新计划生成器,使用OpenAI的ChatGPT-4o模型
replanner = replanner_prompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(Act)
创建图
现在我们可以创建图了
from typing import Literal
# 定义一个异步主函数
async def main():
# 定义一个异步函数,用于执行步骤
async def execute_step(state: PlanExecute):
plan = state["plan"]
plan_str = "\n".join(f"{i + 1}. {step}" for i, step in enumerate(plan))
task = plan[0]
task_formatted = f"""对于以下计划:
{plan_str}\n\n你的任务是执行第{1}步,{task}。"""
agent_response = await agent_executor.ainvoke(
{"messages": [("user", task_formatted)]}
)
return {
"past_steps": state["past_steps"] + [(task, agent_response["messages"][-1].content)],
}
# 定义一个异步函数,用于生成计划步骤
async def plan_step(state: PlanExecute):
plan = await planner.ainvoke({"messages": [("user", state["input"])]})
return {"plan": plan.steps}
# 定义一个异步函数,用于重新计划步骤
async def replan_step(state: PlanExecute):
output = await replanner.ainvoke(state)
if isinstance(output.action, Response):
return {"response": output.action.response}
else:
return {"plan": output.action.steps}
# 定义一个函数,用于判断是否结束
def should_end(state: PlanExecute) -> Literal["agent", "__end__"]:
if "response" in state and state["response"]:
return "__end__"
else:
return "agent"
from langgraph.graph import StateGraph, START
# 创建一个状态图,初始化PlanExecute
workflow = StateGraph(PlanExecute)
# 添加计划节点
workflow.add_node("planner", plan_step)
# 添加执行步骤节点
workflow.add_node("agent", execute_step)
# 添加重新计划节点
workflow.add_node("replan", replan_step)
# 设置从开始到计划节点的边
workflow.add_edge(START, "planner")
# 设置从计划到代理节点的边
workflow.add_edge("planner", "agent")
# 设置从代理到重新计划节点的边
workflow.add_edge("agent", "replan")
# 添加条件边,用于判断下一步操作
workflow.add_conditional_edges(
"replan",
# 传入判断函数,确定下一个节点
should_end,
)
# 编译状态图,生成LangChain可运行对象
app = workflow.compile()
#将生成的图片保存到文件
graph_png = app.get_graph().draw_mermaid_png()
with open("plan_execute.png","wb")as f:
f.write(graph_png)
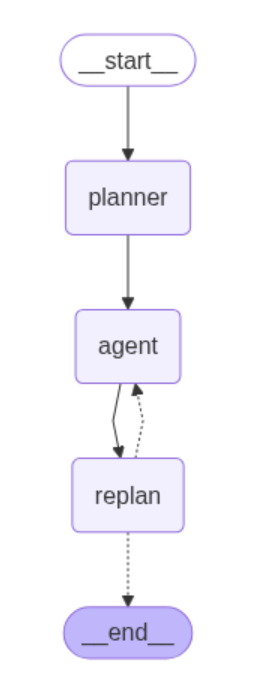
# 设置配置,递归限制为50
config = {"recursion_limit": 50}
# 输入数据
inputs = {"input": "2024年巴黎奥运会100米自由泳决赛冠军的家乡是哪里?请用中文答复"}
# 异步执行状态图,输出结果
async for event in app.astream(inputs, config=config):
for k, v in event.items():
if k != "__end__":
print(v)
asyncio.run(main())
{'plan': ['查找2024年巴黎奥运会100米自由泳决赛的冠军信息。', '确认冠军的家乡。', '提供冠军家乡的中文名称作为答案。']}
{'past_steps': [('查找2024年巴黎奥运会100米自由泳决赛的冠军信息。', '在2024年巴黎奥运会男子100米自由泳决赛中,中国选手潘展乐以46.40的成绩夺得冠军,并刷新了世界纪录。')]}
{'plan': ['确认冠军潘展乐的家乡。', '提供冠军家乡的中文名称作为答案。']}
{'past_steps': [('查找2024年巴黎奥运会100米自由泳决赛的冠军信息。', '在2024年巴黎奥运会男子100米自由泳决赛中,中国选手潘展乐以46.40的成绩夺得冠军,并刷新了世界纪录。'), ('确认冠军潘展乐的家乡。', '冠军潘展乐的家乡是浙江温州。')]}
{'response': '冠军潘展乐的家乡是浙江温州。'}
12.LangGraph基于RAG构建智能客服应用
大致过程与《9.Langchain基于RAG实现文档问答》相似,只不过本项目提供了requirements.txt,创建python=3.10并且名字为agentrag的环境之后,直接pip install -r requirement.txt即可
运行效果



















 2162
2162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









