






这里我们主要介绍机器学习的常用模型之一:线性模型的学习。众所周知,机器学习主要分为三个步骤:模型、策略、算法。我们根据具体问题确定假设空间,然后根据评价标准,选取最优模型的策略(此时通常会产生一个损失函数),然后我们通过算法模型求解损失函数,确定最优化模型。本次我们主要从线性模型展开学习。

为了能进行数学运算,样本中的非数值类属性都需要进行数值化。对于存在“序”关系的属性,可通过 连续化将其转化为带有相对大小关系的连续值;对于不存在“序”关系的属性,可根据属性取值将其拆解为 多个属性,例如“西瓜书”中所说的“瓜类”属性,可将其拆解为“是否是西瓜”、“是否是南瓜”、“是否是黄 瓜”3 个属性,其中每个属性的取值为 1 或 0,1 表示“是”,0 表示“否”。具体地,假如现有 3 个瓜类样本: x1 = (甜度 = 高; 瓜类 = 西瓜), x2 = (甜度 = 中; 瓜类 = 南瓜), x3 = (甜度 = 低; 瓜类 = 黄瓜),其中“甜 度”属性存在序关系,因此可将“高”、“中”、“低”转化为 {1.0, 0.5, 0.0}。“瓜类”属性不存在序关系,则按照上 述方法进行拆解,3 个瓜类样本数值化后的结果为:x1 = (1.0; 1; 0; 0), x1 = (0.5; 0; 1; 0), x1 = (0.0; 0; 0; 1)。
3.2线性回归
下面着重介绍几个概念:最小二乘法和正交回归的区别:

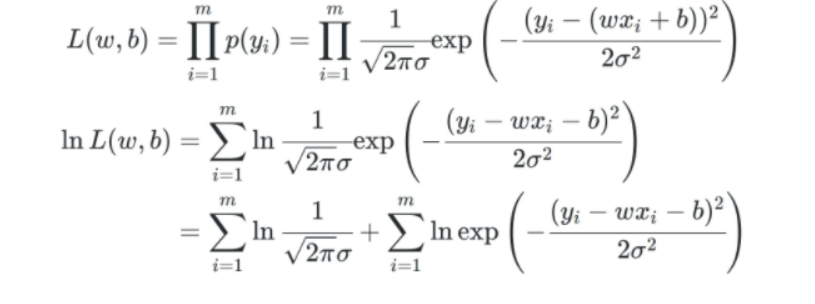

下面介绍几个概念:凸集,西瓜书中用的是最优化的概念,这和我们传统的凹凸性正好相反,这是从函数二次导的变化来解释的,常见的凸函数就是y=x²。

多元函数的导函数:梯度和海塞公式。



所以我们接下来对w和b的求解是基于海塞矩阵求出f(x)是凸函数的前提下,详细证明过程在南瓜书讲解有,感兴趣的同学可以自行学习。

上图所示,我们求 是最小二乘法运用在一元线性回归上的情形,那么对于多元线性回归来说,我们可以类似得到:
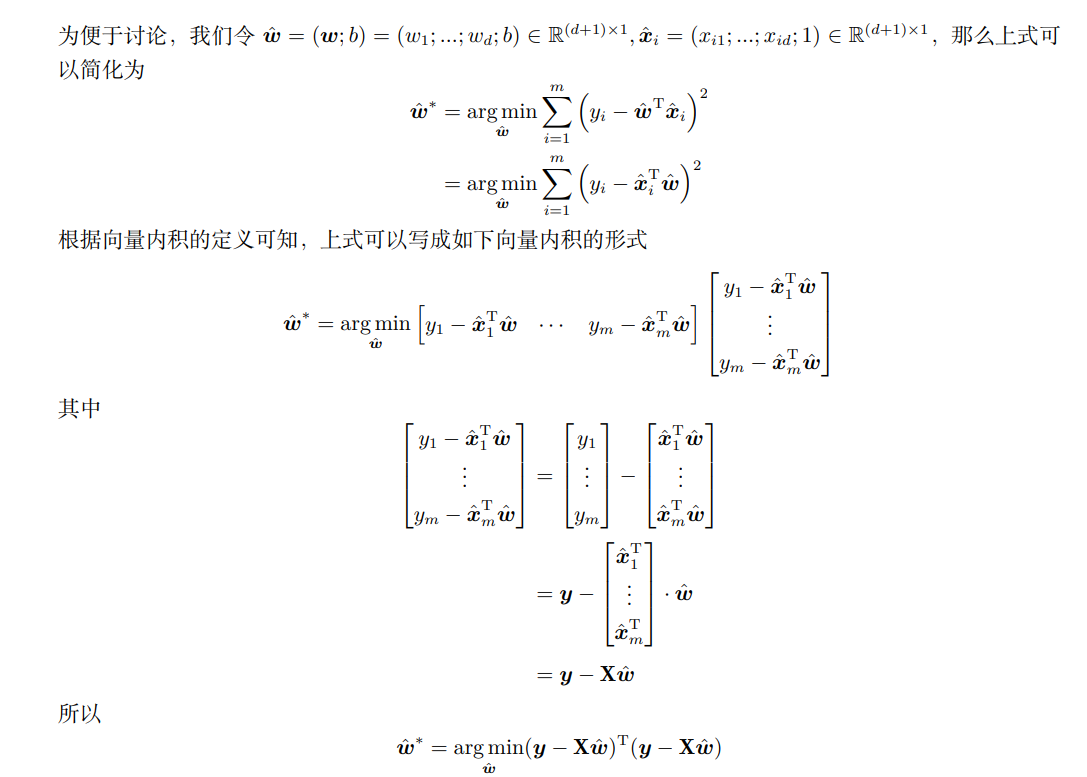

由于这一部分涉及到矩阵微分的知识,我们仅仅展示出来,具体推导过程有公式的。
3.3 对数几率回归
对数几率回归虽然被称为”回归“,但是本质是在线性模型的基础上套用一个映射函数来实现分类功能。
对数几率回归的一般使用流程如下:

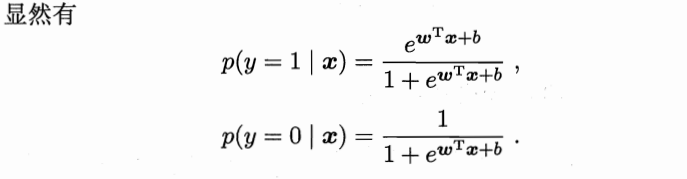
然后,接下来采用极大似然估计来求损失函数
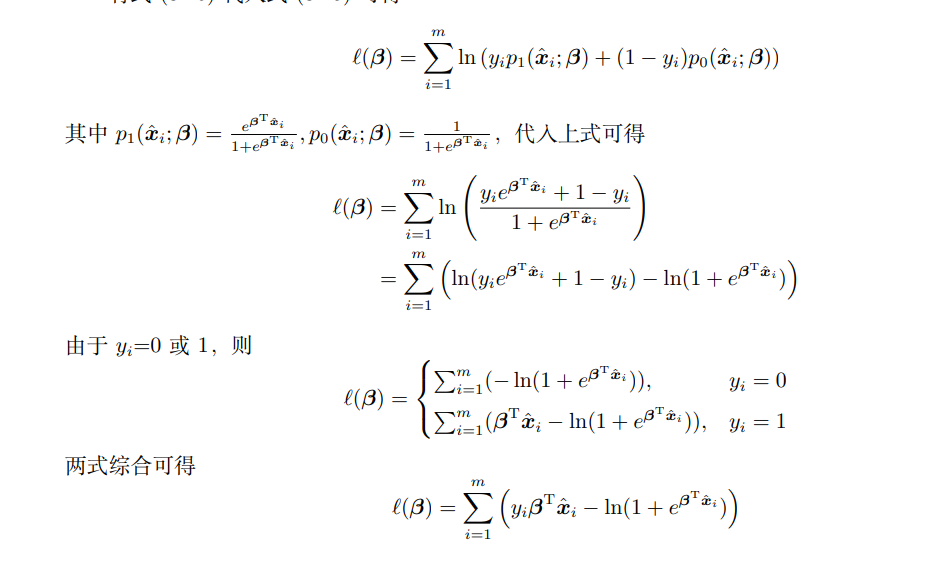
由于此式仍为极大似然估计的似然函数,所以最大化似然函数等价于最小化似然函数的相反数,即在似然函数前添加负号即可得在西瓜书式。
不同于3.1中线性回归可求得闭式解,式中的 β 没有闭式解,因此需要借助其他工具进行求解。求解使得式 取到最小值的 β 属于最优化中的“无约束优化问题”,在无约束优化问题中最常用的求解算法有“梯度下降法”和“牛顿法”,下面经行简单介绍。


综合以上,本节实际上是用线性回归模型的预测结果去逼近真实标记的对数几率,所以称为对数几率回归。用机器学习三要素进行总结如下:

3.4二分类线性判别分析
线性判别分析的一般使用流程如下:首先在训练集上学得模型
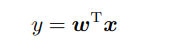
由向量内积的几何意义可知,y 可以看作是 x 在 w 上的投影,因此在训练集上学得的模型能够保证训练 集中的同类样本在 w 上的投影 y 很相近,而异类样本在 w 上的投影 y 很疏远。然后对于新的测试样本 xi,将其代入模型得到它在 w 上的投影 yi,然后判别这个投影 yi 与哪一类投影更近,则将其判为该类。
用西瓜书的图详细表示如下:
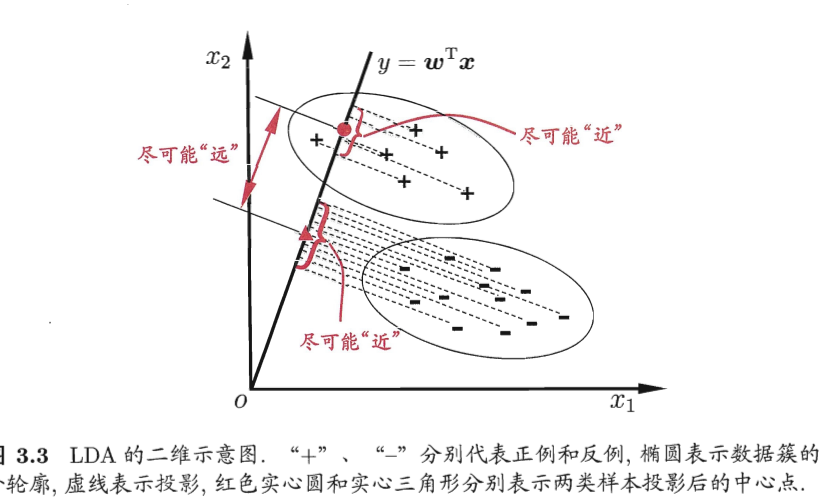
也就是说满足两个关键条件:
同类样本方差尽可能小,异类样本方差尽可能大
由此推导出损失函数:
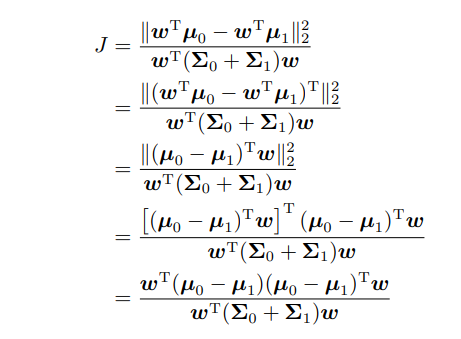
为了尽可能表示出来w,我们引入了拉格朗日乘子法来进行计算:

由于最终要求解的 w 不关心其大小,只关心其方向,所以其大小可以任意取值。
这里借用课件补充说明一下啥是拉格朗日乘子法:
















 3422
3422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









