






目录
一、引言
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素贝叶斯(Naive Bayes)朴素贝叶斯分类是贝叶斯分类中最简单的,它是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法。由于朴素贝叶斯计算联合概率,所以朴素贝叶斯模型属于生成式模型。经典应用案例包括:文本分类、垃圾邮件过滤等。
二、贝叶斯
2.1 贝叶斯公式
贝叶斯公式又被称为贝叶斯规则,是概率统计中的应用所观察到的现象对有关概率分布的主观判断(先验概率)进行修正的标准方法。如果你看到一个人总是做一些好事,则那个人多半会是一个好人。这就是说,当你不能准确知悉一个事物的本质时,你可以依靠与事物特定本质相关的事件出现的多少去判断其本质属性的概率。用数学语言表达就是:支持某项属性的事件发生得愈多,则该属性成立的可能性就愈大。贝叶斯公式中涉及到先验概率、后验概率、条件概率等,具体解释如下。
先验概率:即基于统计的概率,是基于以往历史经验和分析得到的结果,不需要依赖当前发生的条件。
后验概率:则是从条件概率而来,由因推果,是基于当下发生了事件之后计算的概率,依赖于当前发生的条件。
条件概率:记事件A发生的概率为P(A),事件B发生的概率为P(B),则在B事件发生的前提下,A事件发生的概率即为条件概率,记为P(A|B)。
联合概率:表示两个事件共同发生的概率。A与B的联合概率表示为P(AB),或者P(A,B),或者P(A∩B)。
贝叶斯公式:贝叶斯公式便是基于条件概率P(B|A)求得联合概率,再求得P(A|B)。既可以将贝叶斯公式看成如下结果:

2.2 朴素贝叶斯
在机器学习中如KNN、逻辑回归、决策树等模型都是判别方法,也就是直接学习出特征输出Y和特征X之间的关系(决策函数Y= f(X)或者条件分布P(Y|X))。但朴素贝叶斯是生成方法,它直接找出特征输出Y和特征X的联合分布P(X,Y),进而通过计算得出结果判定。
朴素贝叶斯分类器是一类简单的概率分类器,在强(朴素)独立性假设的条件下运用贝叶斯公式来计算每个类别的后验概率,假设每个特征之间没有联系。
2.2.1 特征条件假设
假设每个特征之间没有联系,给定训练数据集,其中每个样本都包括
维特征,即
,类标记集合含有
种类别,即
。
对于给定的新样本,判断其属于哪个标记的类别,根据贝叶斯定理,可以得到
属于
类别的概率
。
通俗的解释:已知结果(先验概率),结果与在此结果为条件下出现的现象(条件概率)相乘的到结果和现象同时发生的联合概率。除以现象单独发生的概率,就得出在某现象发生的条件下,发生结果的概率(后验概率)。
后验概率最大的类别记为预测类别,即:。
朴素贝叶斯算法对条件概率分布作出了独立性的假设,通俗地讲就是说假设各个维度的特征互相独立,在这个假设的前提上,条件概率可以转化为:
代入上面贝叶斯公式中,得到:
于是,朴素贝叶斯分类器可表示为:
因为对所有的,上式中的分母的值都是一样的,所以可以忽略分母部分,朴素贝叶斯分类器最终表示为:
适用范围:
- 朴素贝叶斯只适用于特征之间是条件独立的情况下,否则分类效果不好,这里的朴素指的就是条件独立。
- 朴素贝叶斯主要被广泛地使用在文档分类中。
朴素贝叶斯常用的三个模型有:
高斯模型:处理特征是连续型变量的情况。
多项式模型:最常见,要求特征是离散数据。
伯努利模型:要求特征是离散的,且为布尔类型,即true和false,或者1和0。
2.2.2 拉普拉斯平滑
拉普拉斯平滑是一种用于解决朴素贝叶斯算法中零概率问题的技术。在计算条件概率时,有些情况下会出现某个特征在某个类别下没有出现过的情况,导致概率为零,这就无法使用贝叶斯公式进行计算。为了避免这种情况,可以对概率进行平滑处理,使得每个特征在每个类别下至少出现一次,从而避免概率为零的情况。而拉普拉斯平滑就是一种常用的平滑方法,它在计算概率时将每个特征的计数都加上一个常数k,从而保证每个特征至少出现k次。
在进行拉普拉斯平滑时,条件概率的计算会涉及多个特征的连乘积,这容易导致数值过小而出现下溢(underflow)或者上溢(overflow)的问题。因此,为了避免这种问题,在实际应用中通常会使用对数操作,将连乘积转换成加和运算,从而方便计算。
2.2.3 朴素贝叶斯优缺点
优点:
- 对待预测样本进行预测,过程简单速度快
- 对于多分类问题也同样有效,复杂度也不会有大程度地上升。
- 在分布独立这个假设成立的情况下,贝叶斯的分类效果很好,会略胜于逻辑回归,我们需要的样本量也更少一点。
- 对于类别类的输入特征变量,效果非常好。对于数值型变量特征,我们默认它符合正态分布。
三、案例
3.1 导入数据集以及库
链接如下:
https://pan.baidu.com/s/16rkfb79BlgypxgDVaZCfgA?_at_=1715610625132#list/path=%2F
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn.preprocessing import StandardScaler, MinMaxScaler, PolynomialFeatures
from sklearn.naive_bayes import GaussianNB, MultinomialNB#高斯贝叶斯和多项式朴素贝叶斯
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
## 设置属性防止中文乱码
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
# 花萼长度、花萼宽度,花瓣长度,花瓣宽度
iris_feature_E = 'sepal length', 'sepal width', 'petal length', 'petal width'
iris_feature_C = u'花萼长度', u'花萼宽度', u'花瓣长度', u'花瓣宽度'
iris_class = 'Iris-setosa', 'Iris-versicolor', 'Iris-virginica'
features = [2,3]3.2 读取数据
path = 'D:\python\.venv\Iris.data' # 数据文件路径
data = pd.read_csv(path, header=None)
x = data[list(range(4))]
x = x[features]
y = pd.Categorical(data[4]).codes ## 直接将数据特征转换为0,1,2
print ("总样本数目:%d;特征属性数目:%d" % x.shape)结果:

3.3 形成模型训练数据和测试数据
x_train1, x_test1, y_train1, y_test1 = train_test_split(x, y, train_size=0.8, random_state=14)
x_train, x_test, y_train, y_test = x_train1, x_test1, y_train1, y_test1
print ("训练数据集样本数目:%d, 测试数据集样本数目:%d" % (x_train.shape[0], x_test.shape[0]))结果:
![]()
3.4 构建高斯贝叶斯
clf = Pipeline([
('sc', StandardScaler()),#标准化,把它转化成了高斯分布
('poly', PolynomialFeatures(degree=1)),
('clf', GaussianNB())])
## 训练模型
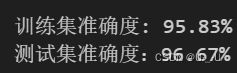
clf.fit(x_train, y_train)3.5 计算预测值并计算准确率
y_train_hat = clf.predict(x_train)
print ('训练集准确度: %.2f%%' % (100 * accuracy_score(y_train, y_train_hat)))
y_test_hat = clf.predict(x_test)
print ('测试集准确度:%.2f%%' % (100 * accuracy_score(y_test, y_test_hat)))结果:
3.5 可视化
## 产生区域图
N, M = 500, 500 # 横纵各采样多少个值
x1_min1, x2_min1 = x_train.min()
x1_max1, x2_max1 = x_train.max()
x1_min2, x2_min2 = x_test.min()
x1_max2, x2_max2 = x_test.max()
x1_min = np.min((x1_min1, x1_min2))
x1_max = np.max((x1_max1, x1_max2))
x2_min = np.min((x2_min1, x2_min2))
x2_max = np.max((x2_max1, x2_max2))
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x2_min, x2_max, N)
x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
x_show = np.dstack((x1.flat, x2.flat))[0] # 测试点
cm_light = mpl.colors.ListedColormap(['#77E0A0', '#FF8080', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
y_show_hat = clf.predict(x_show) # 预测值
y_show_hat = y_show_hat.reshape(x1.shape)
## 画图
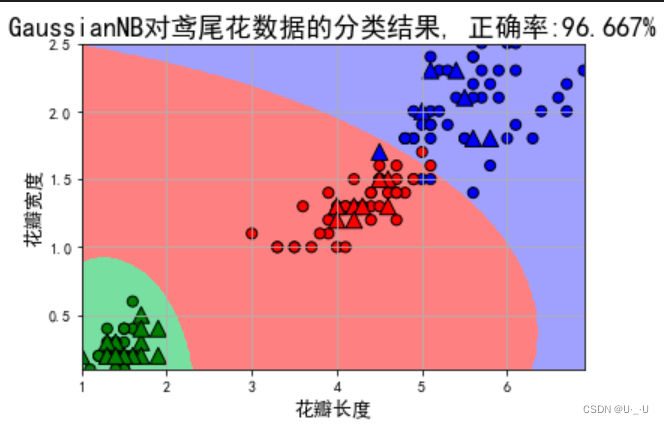
plt.figure(facecolor='w')
plt.pcolormesh(x1, x2, y_show_hat, cmap=cm_light) # 预测值的显示
plt.scatter(x_train[features[0]], x_train[features[1]], c=y_train, edgecolors='k', s=50, cmap=cm_dark)
plt.scatter(x_test[features[0]], x_test[features[1]], c=y_test, marker='^', edgecolors='k', s=120, cmap=cm_dark)
plt.xlabel(iris_feature_C[features[0]], fontsize=13)
plt.ylabel(iris_feature_C[features[1]], fontsize=13)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.title(u'GaussianNB对鸢尾花数据的分类结果, 正确率:%.3f%%' % (100 * accuracy_score(y_test, y_test_hat)), fontsize=18)
plt.grid(True)
plt.show()结果:
四、总结
4.1 朴素贝叶斯优缺点
优点:
- 对待预测样本进行预测,过程简单速度快
- 对于多分类问题也同样有效,复杂度也不会有大程度地上升。
- 在分布独立这个假设成立的情况下,贝叶斯的分类效果很好,会略胜于逻辑回归,我们需要的样本量也更少一点。
- 对于类别类的输入特征变量,效果非常好。对于数值型变量特征,我们默认它符合正态分布
缺点:
- 如果测试集中的一个类别变量特征在训练集里面没有出现过,那么概率就是0,预测功能就将失效,平滑技术可以解决这个问题
- 朴素贝叶斯中有分布独立的假设前提,但是在现实生活中,这个条件很难满足。
应用:
- 文本分类:朴素贝叶斯算法在文本分类领域具有广泛的应用,如垃圾邮件过滤、新闻分类、情感分析等。
- 情感分析:通过分析文本中的词汇和语法结构,朴素贝叶斯算法可以判断文本所表达的情感倾向,如积极、消极或中性。
- 垃圾邮件过滤:朴素贝叶斯算法可以有效地识别并过滤垃圾邮件,减少用户的干扰和损失。
4.2 小结
通过此次实验,深刻了解并掌握朴素贝叶斯的算法原理和基本流程,实验过程中也出现了各种错误,对该分类器有了深刻理解。总的来说,朴素贝叶斯算法是一个简单、易于实现、效果不错的分类算法,希望未来我还能学习更多关于机器学习算法的知识。















 6017
6017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









