






目录
一、引言
PCA是一种数据数据降维算法(非监督)通过析取主成分显出的最大的个体差异,发现更便于人们能够理解的特征,也可以用来削减回归分析和聚类分析中变量的数目。
二、PCA原理
2.1 主成分分析(PCA)算法步骤
PCA(Principal Components Analysis)即主成分分析,是一种常用的数据分析手段,是图像处理中经常用到的降维方法。对于一组不同维度之间可能存在线性相关关系的数据,PCA能够把这组数据通过正交变换变成各个维度之间线性无关的数据,经过PCA处理的数据中的各个样本之间的关系往往更直观,所以它是一种非常常用的数据分析和预处理工具。PCA处理之后的数据各个维度之间是线性无关的,通过剔除方差较小的那些维度上的数据,我们可以达到数据降维的目的。
PCA从原始变量出发,通过旋转变化(即原始变量的线性组合)构建出一组新的,互不相关的新变量,这些变量尽可能多的解释原始数据之间的差异性(即数据内在的结构),他们就成为原始数据的主成分。由于这些变量不相关,因此他们无重叠的各自解释一部分差异性。依照每个变量解释时差异性大小排序,他们成为第一主成分,第二主成分,以此类推。
主成分分析(PCA)是一种基于变量协方差矩阵对数据进行压缩降维,去噪的有效方法,PCA的思想是将n维特征映射到k维上(k<n),这k维特征称为主元(主成分),是旧特征的线性组合,这些线性组合最大化样本方差,尽量使用新的k个特征互不相关。这k维是全新的正交特征,是重新构造出来的k维特征,而不是简单地从n维特征中取出其余n-k维特征。
说了这么多,下面说一下PCA降维的算法步骤。
1) 将原始数据按列组成n行m列矩阵X
2)将X的每一行(代表一个属性字段)进行零均值化(去平均值),即减去这一行的均值
3)求出协方差矩阵 C= 1/m*X*XT
4)求出协方差矩阵的特征值及对应的特征向量
5)将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P(保留最大的k各特征向量)
6)Y=PX 即为降维到K维后的数据
2.2 核主成分分析KPCA介绍
在上面的PCA算法中,我们假设存在一个线性的超平面,可以让我们对数据进行投影。但是有些时候,数据不是线性的,不能直接进行PCA降维。这里就需要用到和支持向量机一样的核函数的思想,先把数据集从 n 维映射到线性可分的高维 N>n,然后再从N维降维到一个低维度 n’,这里的维度之间满足 n’ < n< N。
使用了核函数的主成分分析一般称之为核主成分分析(Kernelized PCA,以下简称 KPCA。假设高维空间的数据是由 n 维空间的数据通过映射 Φ 产生)。
则对于 n 维空间的特征分解:
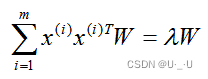
映射为:
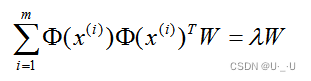
通过在高维空间进行协方差矩阵的特征值分解,然后用和PCA一样的方法进行降维。一般来说,映射 Φ 不用显式的计算,而是在需要计算的时候通过核函数完成。由于KPCA需要核函数的运算,因此它的计算量要比PCA大很多。
2.2 PCA算法总结
这里对PCA算法做一个总结,作为一个非监督学习的降维方法,它只需要特征值分解,就可以对数据进行压缩,去噪。因此在实际场景应用很广泛。为了克服PCA一些缺点,出现了很多PCA的变种,比如上面为解决非线性降维的KPCA,还有解决内存限制的增量PCA方法 Incremental PCA,以及解决稀疏数据降维的PCA方法Sparse PCA等。
PCA算法的主要优点:
- 仅仅需要以方差衡量信息量,不受数据集以外的因素影响
- 各主成分之间正交,可消除原始数据成分间的互相影响的因素
- 计算方法简单,主要运算是特征值分解,易于实现
PCA算法的主要缺点:
- 主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强
- 方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响
三、PCA实现
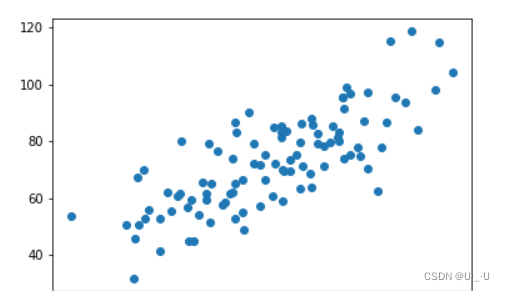
3.1 首先载入数据查看我们数据的分布情况
import numpy as np
import matplotlib.pyplot as plt
data = np.genfromtxt("data.csv", delimiter=",")
x_data = data[:,0]
y_data = data[:,1]
plt.scatter(x_data,y_data)
plt.show()
print(x_data.shape)
结果:
3.2 将数据中心化
def zeroMean(dataMat):
# 按列求平均,即各个特征的平均
meanVal = np.mean(dataMat, axis=0)
newData = dataMat - meanVal
return newData, meanVal
3.3 求协方差矩阵
newData,meanVal=zeroMean(data)
# np.cov用于求协方差矩阵,参数rowvar=0说明数据一行代表一个样本
covMat = np.cov(newData, rowvar=0)
3.4 求矩阵的特征值和特征向量
eigVals, eigVects = np.linalg.eig(np.mat(covMat))
3.5 对特征值排序,取最大
eigValIndice = np.argsort(eigVals)
n_eigValIndice = eigValIndice[-1:-(top+1):-1]
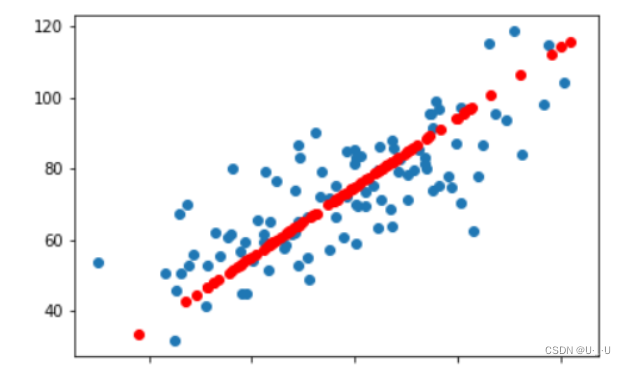
3.6 特征空间的数据
data = np.genfromtxt("data.csv", delimiter=",")
x_data = data[:,0]
y_data = data[:,1]
plt.scatter(x_data,y_data)
# 重构的数据
x_data = np.array(reconMat)[:,0]
y_data = np.array(reconMat)[:,1]
plt.scatter(x_data,y_data,c='r')
plt.show()
结果:
四、手写体识别数字降维
4.1 引入sklearn中的手写数字识别
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report,confusion_matrix
import numpy as np
import matplotlib.pyplot as plt
digits = load_digits()#载入数据
x_data = digits.data #数据
y_data = digits.target #标签
x_train,x_test,y_train,y_test = train_test_split(x_data,y_data) #分割数据1/4为测试数据,3/4为训练数据
mlp = MLPClassifier(hidden_layer_sizes=(100,50) ,max_iter=500)
mlp.fit(x_train,y_train)
# 数据中心化
def zeroMean(dataMat):
# 按列求平均,即各个特征的平均
meanVal = np.mean(dataMat, axis=0)
newData = dataMat - meanVal
return newData, meanVal
def pca(dataMat,top):
# 数据中心化
newData,meanVal=zeroMean(dataMat)
# np.cov用于求协方差矩阵,参数rowvar=0说明数据一行代表一个样本
covMat = np.cov(newData, rowvar=0)
# np.linalg.eig求矩阵的特征值和特征向量
eigVals, eigVects = np.linalg.eig(np.mat(covMat))
# 对特征值从小到大排序
eigValIndice = np.argsort(eigVals)
# 最大的n个特征值的下标
n_eigValIndice = eigValIndice[-1:-(top+1):-1]
# 最大的n个特征值对应的特征向量
n_eigVect = eigVects[:,n_eigValIndice]
# 低维特征空间的数据
lowDDataMat = newData*n_eigVect
# 利用低纬度数据来重构数据
reconMat = (lowDDataMat*n_eigVect.T) + meanVal
# 返回低维特征空间的数据和重构的矩阵
return lowDDataMat,reconMat
lowDDataMat,reconMat = pca(x_data,2)
# 重构的数据
x = np.array(lowDDataMat)[:,0]
y = np.array(lowDDataMat)[:,1]
plt.scatter(x,y,c='r')
plt.show()
predictions = mlp.predict(x_data)
# 重构的数据
x = np.array(lowDDataMat)[:,0]
y = np.array(lowDDataMat)[:,1]
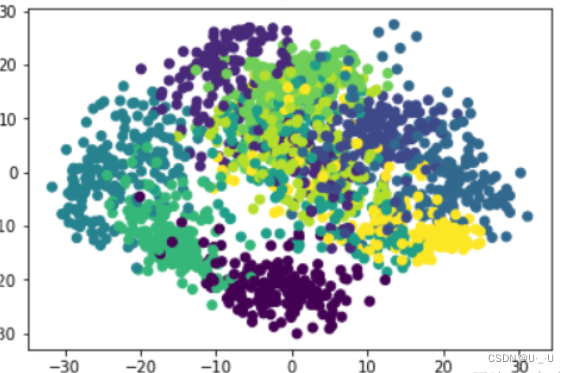
plt.scatter(x,y,c=y_data)
plt.show()
lowDDataMat,reconMat = pca(x_data,3)
from mpl_toolkits.mplot3d import Axes3D
x = np.array(lowDDataMat)[:,0]
y = np.array(lowDDataMat)[:,1]
z = np.array(lowDDataMat)[:,2]
ax = plt.figure().add_subplot(111, projection = '3d')
ax.scatter(x, y, z, c = y_data, s = 10) #点为红色三角形
plt.show()
结果:

















 188
188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









