






目录
1.代码
提示:导入数据集时,需按照自己电脑的实际情况修改文件路径。
# 导入所需模块
import pandas as pd
import numpy as np
import requests
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder, PowerTransformer
import math
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 展开全部内容
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
# 导入数据集
train = pd.read_csv(r"E:\AwfulCollege\obesity\train.csv")
test = pd.read_csv(r"E:\AwfulCollege\obesity\test.csv")
# 查看训练集前五行样本
print(train.head())
# 查看数据集的基本信息
print(train.info())
print(test.info())
# 描述性统计分析
print(train.describe())
print(test.describe())
# 绘制环形图和条形图:查看某个属性的数据分布
def single_plot_distribution(column_name, dataframe):
# 获取指定属性列的值计数
value_counts = dataframe[column_name].value_counts()
# 创建一个包含两个子图的图表对象fig,其中子图的布局是一行两列,每个子图的大小是15x5,且宽度比为1:1
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5), gridspec_kw={'width_ratios': [1, 1]})
# color_palette函数使用两种颜色代码创建了一个调色板,以便在数据可视化中使用
palette = ["#00B1D2FF", "#FDDB27FF"]
color_palette = sns.color_palette(palette)
# 环形图
pie_colors = palette[0:3]
# 绘制饼图,设置了百分比显示格式、起始角度、百分比标签的距离和颜色
ax1.pie(value_counts, autopct='%0.001f%%', startangle=90, pctdistance=0.85, colors=pie_colors, labels=None)
# 创建了一个白色的圆形,将其添加到了饼图中心
centre_circle = plt.Circle((0, 0), 0.70, fc='white')
ax1.add_artist(centre_circle)
# 设置了饼图的标题
ax1.set_title(f'Distribution of {column_name}', fontsize=16)
# 条形图
# 绘制条形图,其中指定了x轴和y轴的数据,以及绘图的目标坐标轴ax2和颜色调色板palette
sns.barplot(x=value_counts.index, y=value_counts.values, ax=ax2, palette=palette[0:3])
ax2.set_title(f'Count of {column_name}', fontsize=16)
ax2.set_xlabel(column_name, fontsize=14)
ax2.set_ylabel('Count', fontsize=14)
# 设置了x轴标签的旋转角度为45度
ax2.tick_params(axis='x', rotation=45)
# 自动调整图表的布局,使得图表中的元素能够更好地适应图像的大小,从而避免它们重叠或超出图像范围
plt.tight_layout()
# 显示绘图
plt.show()
single_plot_distribution('NObeyesdad', train) # 肥胖等级
single_plot_distribution('CALC', train) # 饮酒频率 训练集
single_plot_distribution('CALC', test) # 饮酒频率 测试集
# 绘制散点图:在某个目标属性当中,显示其它两个属性之间的关系
def advanced_scatter_plot(x_column, y_column, target_column, dataframe):
palette = ["#00B1D2FF", "#FDDB27FF"]
color_palette = sns.color_palette(palette)
# 创建了一个15x6大小的画布
plt.figure(figsize=(15, 6))
# 绘制散点图,根据dataframe中的数据,在x_column和y_column上绘制散点,并根据target_column的取值对散点进行着色
sns.scatterplot(x=x_column, y=y_column, hue=target_column, data=dataframe, palette=palette[0:3])
plt.title(f'Scatter Plot of {x_column} vs {y_column} Hue by {target_column}', fontsize=16)
plt.xlabel(x_column, fontsize=14)
plt.ylabel(y_column, fontsize=14)
# 为散点图添加图例,并为图例设置标题
plt.legend(title=target_column)
# 在图表上添加网格线,参数True表示显示网格线
plt.grid(True)
plt.show()
# 在男女当中,显示年龄与体重的关系
advanced_scatter_plot('Age', 'Weight', 'Gender', train)
# 在男女当中,显示年龄与身高的关系
advanced_scatter_plot('Age', 'Height', 'Gender', train)
# 特征编码
# 对肥胖等级属性进行标签编码
le = LabelEncoder()
train['NObeyesdad'] = le.fit_transform(train['NObeyesdad'])
# 对其余属性进行独热编码
train = pd.get_dummies(train)
test = pd.get_dummies(test)
# 获取标签与编码的映射
res = {}
for cl in le.classes_:
res.update({cl: le.transform([cl])[0]})
for i in res:
print(i, ':', res[i])
# 划分训练集和验证集
X = train.drop(['id', 'NObeyesdad'], axis=1)
y = train['NObeyesdad']
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# 建立随机森林模型
# 随机森林由100棵决策树组成。random_state用于设置随机数生成器的种子。模型的构建过程都是可复现的
model_RF = RandomForestClassifier(n_estimators=100, random_state=42)
# 使用训练集数据X_train和对应的标签y_train来训练这个随机森林模型。通过训练,模型会学习数据中的模式及特征与标签之间的关系。
model_RF.fit(X_train, y_train)
# 调用训练过的随机森林模型对验证集X_val进行预测
val_preds_RF = model_RF.predict(X_val)
# crosstab函数创建了一个混淆矩阵,用于随机森林模型的验证集预测结果。rownames和colnames参数分别设置了混淆矩阵中行和列的标题
conf_matrix_RF = pd.crosstab(y_val, val_preds_RF, rownames=['Actual'], colnames=['Predicted'])
# 输出混淆矩阵
print(conf_matrix_RF)
# 用accuracy_score函数比较y_val(真实标签)和val_preds_RF(预测标签),算得的准确率存储在accuracy_RF变量中
accuracy_RF = accuracy_score(y_val, val_preds_RF)
# 输出准确率
print(f"Validation Accuracy: {accuracy_RF}")
# 检验模型
# 检查测试集中是否包含名为CALC_Always(独热编码)的列,并在存在的情况下删除该列
if 'CALC_Always' in test.columns:
test.drop('CALC_Always', axis=1, inplace=True)
# 删除测试集的'id'列。使用之前训练的随机森林模型对处理过的测试集进行预测,预测结果存储在变量test_preds_RF中
test_preds_RF = model_RF.predict(test.drop('id', axis=1))2.运行结果说明
训练集前五行样本。

 训练集包含20758个样本,18个属性,没有缺失值。
训练集包含20758个样本,18个属性,没有缺失值。
 测试集包含13840个样本,17个属性(少1个类别属性:肥胖等级),没有缺失值。
测试集包含13840个样本,17个属性(少1个类别属性:肥胖等级),没有缺失值。
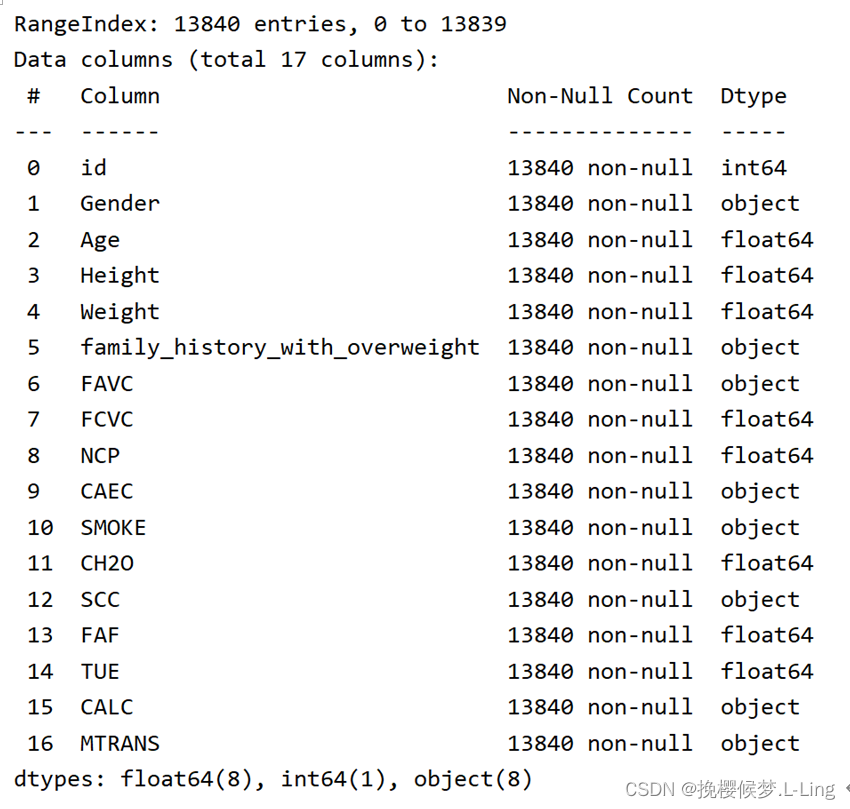 对年龄、身高、体重等数据类型为整形或浮点型的属性进行分析,指标有平均值、标准差、最值、中位数等。
对年龄、身高、体重等数据类型为整形或浮点型的属性进行分析,指标有平均值、标准差、最值、中位数等。
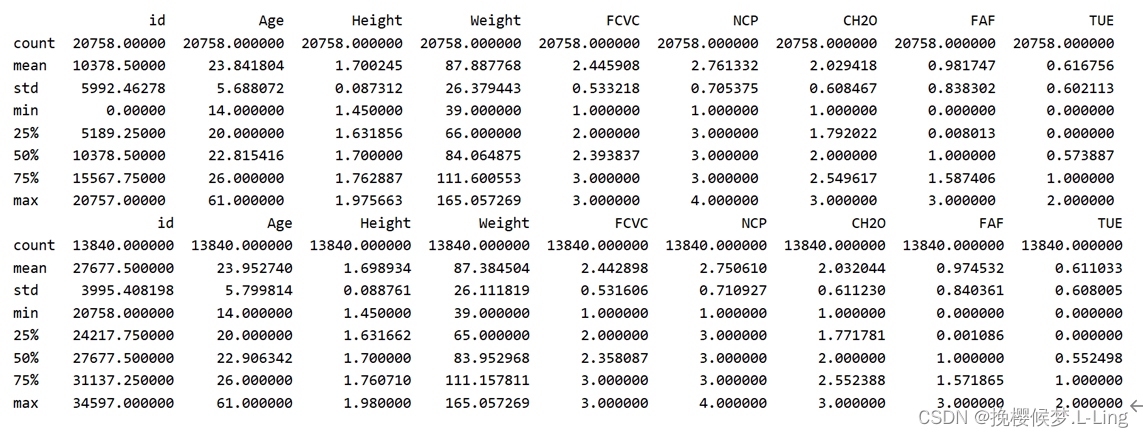 训练集的肥胖等级属性的数据分布情况如下,属性值有七个,数量由高到低依次为三级肥胖、二级肥胖、正常体重、一级肥胖、体重不足、二级超重和一级超重。
训练集的肥胖等级属性的数据分布情况如下,属性值有七个,数量由高到低依次为三级肥胖、二级肥胖、正常体重、一级肥胖、体重不足、二级超重和一级超重。
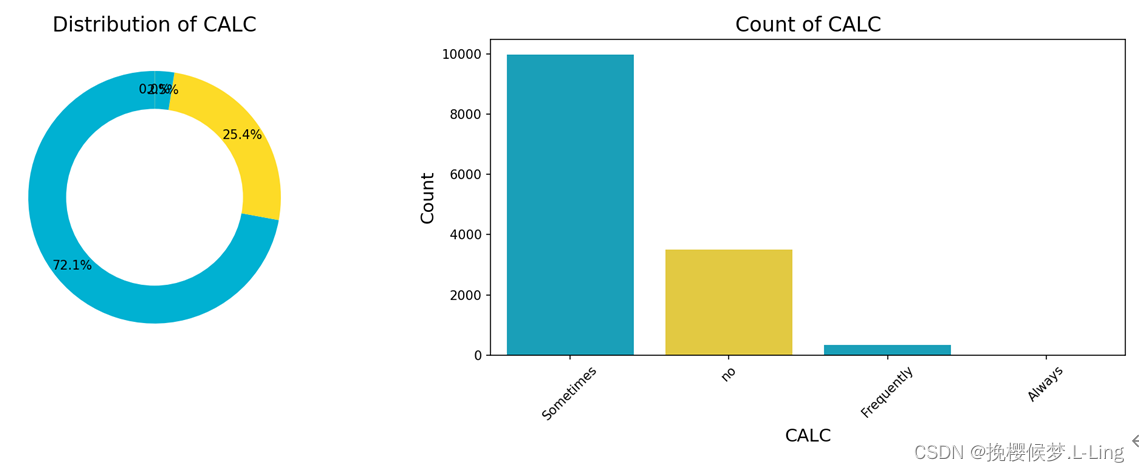
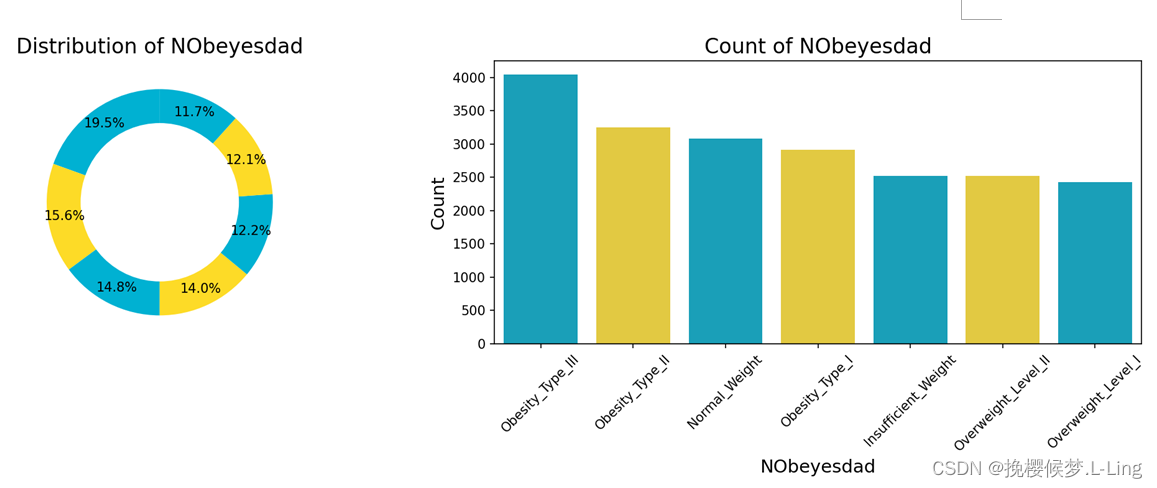 饮酒频率属性比较特殊,在训练集中该属性有三个值,测试集中有四个。
饮酒频率属性比较特殊,在训练集中该属性有三个值,测试集中有四个。
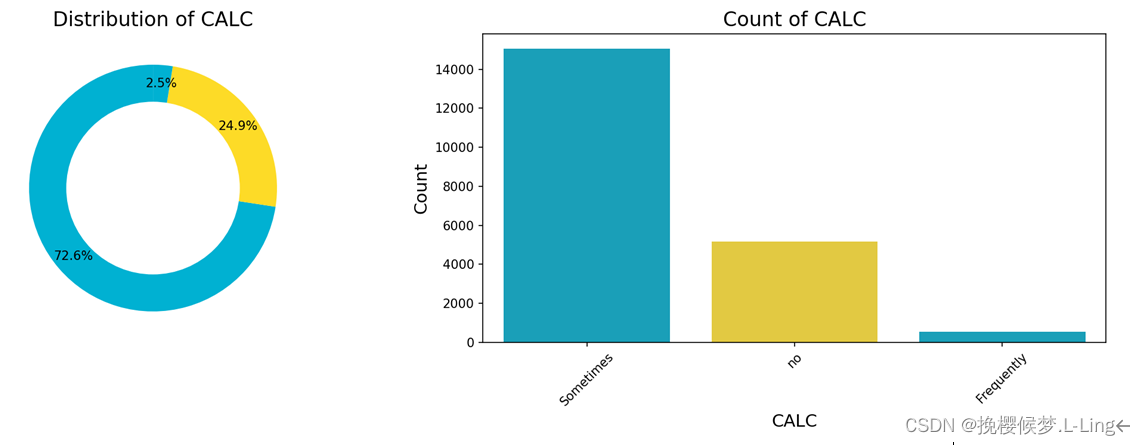 多出来的值为Always,它的占比不到0.01%,几乎可以忽略不记。因此检验模型时,可先将测试集中饮酒频率属性值为Always的样本删除。
多出来的值为Always,它的占比不到0.01%,几乎可以忽略不记。因此检验模型时,可先将测试集中饮酒频率属性值为Always的样本删除。
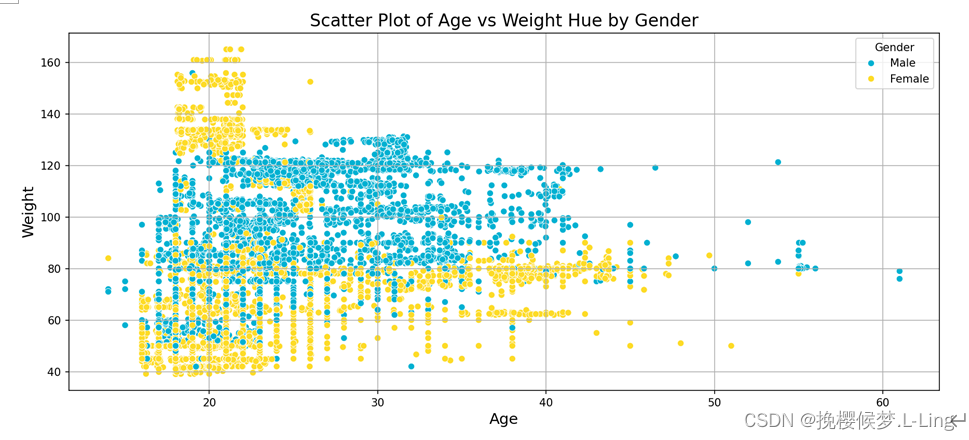
 以年龄为横轴,体重为纵轴,描绘散点,根据性别的取值对散点进行着色。总体上看,男性的体重分布比女性相对集中。
以年龄为横轴,体重为纵轴,描绘散点,根据性别的取值对散点进行着色。总体上看,男性的体重分布比女性相对集中。
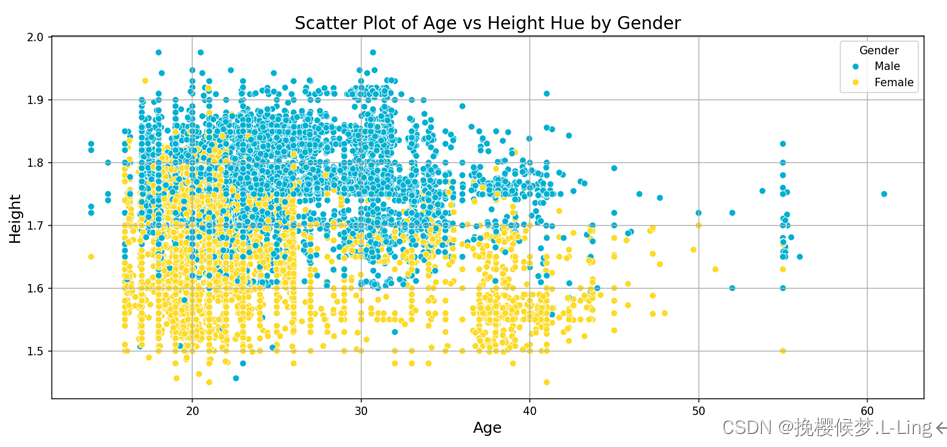
以年龄为横轴,身高为纵轴,描绘散点,根据性别的取值对散点进行着色。总体上看,大部分男性身高超过女性。
对肥胖等级属性进行标签编码后,输出其对应关系。 
划分出训练集和验证集,建立随机森林模型后,让模型拟合训练集的数据,再让训练过的模型对验证集进行预测。
输出混淆矩阵,查看预测结果。
比较验证集的真实标签和预测标签,算出模型准确率。
















 3774
3774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









