






引言
前景提要
在上一次的分享中,我介绍了自己如何使用CNN-XGBoost模型来预测比亚迪股票的未来走势。XGBoost作为一种高效的树模型,以其出色的预测性能在业界广受好评。然而,随着技术的发展,深度学习领域涌现出了更多先进的模型,其中CNN-LSTM模型因其结合了卷积神经网络(CNN)和长短期记忆网络(LSTM)的优势,而成为当前预测领域的热门选择。
CNN-LSTM模型通过CNN捕捉时间序列数据中的局部特征,再利用LSTM处理序列数据的长期依赖问题,从而在时间序列预测任务中展现出卓越的性能。现在,我将分享我使用CNN-LSTM模型对比亚迪股票进行预测的最新尝试。这种方法不仅能够更准确地捕捉市场动态,还有助于我们深入理解股票价格波动的内在机制。
在这次的股票预测中,我将详细阐述CNN-LSTM模型的构建过程、训练策略以及预测结果的评估方法。希望通过这次分享,能够为投资者和对量化感兴趣的朋友提供一种新的视角,以更全面地理解和预测股票市场。同时,郑重申明,金融市场有风险,投资需谨慎。写这个博客,希望大家能够学习到相关的知识,提升自己的量化能力。
股票背景
比亚迪作为新能源汽车行业的领军企业,确实对整个产业链有着深远的影响。它不仅在汽车制造领域取得了显著成就,还涉足电池、电子、半导体等多个领域,形成了强大的产业链竞争力。此外,比亚迪在技术创新和市场拓展方面也展现出了强劲的增长潜力。
从股票市场的角度来看,比亚迪的股价受到公司业绩、行业趋势、政策支持以及投资者情绪等多种因素的影响。根据相关分析报告,比亚迪在2023年实现了营收和利润的稳健增长,这为其股票价值提供了坚实的基础。同时,国内许多金融机构对比亚迪未来几年的业绩也给出了较为乐观的预测,预计2024年每股收益和净利润将实现显著增长。因此,我们对它进行股票预测。
代码分析:
必要包的导入
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
import torch.optim as optim
import optuna
import torch.nn.functional as F
import matplotlib.pyplot as plt
CNN-LSTM网络搭建
class CNNLSTM(nn.Module):
def __init__(self, conv_out_channels, kernel_size, lstm_hidden_size, lstm_num_layers):
super(CNNLSTM, self).__init__()
self.conv1 = nn.Conv1d(in_channels=4, out_channels=conv_out_channels, kernel_size=kernel_size, padding=1)
self.res_block = ResidualBlock(conv_out_channels, conv_out_channels)
self.pool = nn.MaxPool1d(kernel_size=2, stride=2)
self.lstm = nn.LSTM(input_size=conv_out_channels, hidden_size=lstm_hidden_size, num_layers=lstm_num_layers, batch_first=True)
self.fc = nn.Linear(lstm_hidden_size, 1)
def forward(self, x):
x = x.permute(0, 2, 1) # 调整输入数据的形状以匹配Conv1d的要求
x = F.relu(self.conv1(x))
x = self.res_block(x)
x = self.pool(x)
if x.size(2) < 1:
raise RuntimeError(f'Output size too small after pooling: {x.size()}')
x = x.permute(0, 2, 1) # 调整输入数据的形状以匹配LSTM的要求
x, (hn, cn) = self.lstm(x)
x = self.fc(x[:, -1, :])
return x
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv1d(in_channels, out_channels, kernel_size=kernel_size, padding=1)
self.conv2 = nn.Conv1d(out_channels, out_channels, kernel_size=kernel_size, padding=1)
self.shortcut = nn.Conv1d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
residual = self.shortcut(x)
out = F.relu(self.conv1(x))
out = self.conv2(out)
out += residual
out = F.relu(out)
return out
-
CNNLSTM 类:这是一个继承自
nn.Module的类,表示一个结合了CNN和LSTM的模型。 -
初始化方法 (
__init__):conv_out_channels: 卷积层的输出通道数。kernel_size: 卷积核的大小。lstm_hidden_size: LSTM层的隐藏层大小。lstm_num_layers: LSTM的层数。conv1: 一个一维卷积层。res_block: 一个残差块,用于增加网络的深度而不损害训练。pool: 一个最大池化层,用于降低特征维度。lstm: LSTM层,用于处理序列数据。fc: 一个全连接层,用于最终的分类或回归任务。
-
前向传播方法 (
forward):- 输入数据
x需要进行形状调整,以适应一维卷积层的要求。 - 通过ReLU激活函数和卷积层处理输入数据。
- 通过残差块进一步处理数据。
- 使用最大池化层降低数据维度。
- 如果池化后的输出尺寸小于1,会抛出运行时错误。
- 再次调整数据形状,以适应LSTM层。
- 将数据输入LSTM层,并获取最终的隐藏状态和输出。
- 通过全连接层处理LSTM的最后一个时间步的输出。
- 输入数据
-
ResidualBlock 类:这是一个残差块,用于提高网络的深度而不损害训练性能。
in_channels和out_channels分别是输入和输出通道数。kernel_size: 卷积核的大小,默认为3。conv1和conv2: 两个卷积层,用于处理数据。shortcut: 一个卷积层,用于创建残差连接。
-
ResidualBlock 的前向传播:
- 计算残差连接。
- 通过第一个卷积层和ReLU激活函数处理输入数据。
- 通过第二个卷积层处理数据。
- 将卷积层的输出与残差连接相加。
- 再次通过ReLU激活函数。
数据处理
def remove_outliers(df, column):
mean = df[column].mean()
std = df[column].std()
threshold = 3 # Z分数阈值
df = df[(df[column] - mean).abs() / std < threshold]
return df
def weighted_moving_average(values, weights):
return np.convolve(values, weights, mode='same')
def create_sequences(X, y, time_steps=5):
Xs, ys = [], []
for i in range(len(X) - time_steps):
Xs.append(X[i:(i + time_steps)])
ys.append(y[i + time_steps])
return np.array(Xs), np.array(ys)
# 加载并预处理数据
file_path = 'fin_sample.csv'
data = pd.read_csv(file_path)
byd_data = data[data['Name'] == '比亚迪'].fillna(method='ffill').fillna(method='bfill')
# byd_data = remove_outliers(byd_data, 'Close')
window_size = 5
weights = np.arange(1, window_size + 1)
weights = weights / weights.sum()
byd_data['Close'] = weighted_moving_average(byd_data['Close'], weights)
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(byd_data[['Open', 'High', 'Low', 'Close', 'Average']])
# 构建时间序列数据
time_steps = 5
X = scaled_data[:, :4]
y = scaled_data[:, 4]
X, y = create_sequences(X, y, time_steps)
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
remove_outliers函数:这个函数用于移除数据集中的异常值。它计算指定列的均值和标准差,然后使用Z分数(即数据点与均值的差除以标准差)来确定哪些数据点是异常值。如果Z分数的绝对值大于3(阈值),则认为该数据点是异常值并将其从数据集中移除。 -
weighted_moving_average函数:这个函数用于计算加权移动平均值。它使用numpy库的convolve函数来计算加权平均值,其中mode='same'表示输出数组的长度与输入数组相同。 -
create_sequences函数:这个函数用于将原始数据转换为适合时间序列预测模型的序列数据。它接受原始数据集和目标变量,以及时间步长(time_steps),然后为每个时间步生成序列数据。 -
数据加载和预处理:代码首先加载CSV文件中的数据,然后筛选出名称为“比亚迪”的数据行,并使用前向填充和后向填充方法填充缺失值。
-
异常值处理(被注释掉):原本的代码中有一个调用
remove_outliers函数的行,但由于被注释掉了,所以实际上没有执行。 -
加权移动平均:使用
weighted_moving_average函数计算“比亚迪”收盘价的加权移动平均,并更新原始数据集中的Close列。 -
数据标准化:使用
MinMaxScaler对数据进行标准化处理,使其值在0到1之间。 -
时间序列数据构建:使用
create_sequences函数将标准化后的数据转换为时间序列数据。 -
数据集拆分:使用
train_test_split函数将时间序列数据拆分为训练集和测试集。
超参数优化
# 定义目标函数
def objective(trial):
# 定义超参数搜索空间
conv_out_channels = trial.suggest_int('conv_out_channels', 16, 128)
kernel_size = trial.suggest_int('kernel_size', 2, 5)
lstm_hidden_size = trial.suggest_int('lstm_hidden_size', 16, 128)
lstm_num_layers = trial.suggest_int('lstm_num_layers', 1, 3)
learning_rate = trial.suggest_float('learning_rate', 1e-4, 1e-1, log=True)
model = CNNLSTM(conv_out_channels, kernel_size, lstm_hidden_size, lstm_num_layers)
criterion = nn.MSELoss()
optimizer = optim.AdamW(model.parameters(), lr=learning_rate)
# 训练模型
num_epochs = 50
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
output = model(torch.from_numpy(X_train).float())
train_loss = criterion(output, torch.from_numpy(y_train).float().view(-1, 1))
train_loss.backward()
optimizer.step()
# 验证模型
model.eval()
with torch.no_grad():
test_output = model(torch.from_numpy(X_test).float())
test_loss = criterion(test_output, torch.from_numpy(y_test).float().view(-1, 1))
return test_loss.item()
# 创建Optuna研究对象并优化目标函数
study = optuna.create_study(direction='minimize')
study.optimize(objective, n_trials=50)
# 输出最佳超参数
best_params = study.best_params
print('Best hyperparameters:', best_params)
-
目标函数 (
objective):这是一个定义超参数搜索空间并训练模型的函数。Optuna将调用这个函数多次,每次尝试不同的超参数组合。 -
超参数搜索空间:
conv_out_channels:卷积层的输出通道数,使用suggest_int方法从16到128之间搜索整数。kernel_size:卷积核大小,同样使用suggest_int方法从2到5之间搜索整数。lstm_hidden_size:LSTM层的隐藏层大小,使用suggest_int方法从16到128之间搜索整数。lstm_num_layers:LSTM的层数,使用suggest_int方法从1到3之间搜索整数。learning_rate:学习率,使用suggest_float方法从1e-4到1e-1之间搜索浮点数,并使用对数尺度(log=True)。
-
模型定义:创建一个
CNNLSTM模型实例,该模型是之前提到的结合了CNN和LSTM的模型。 -
损失函数和优化器:定义均方误差损失函数(
MSELoss)和AdamW优化器,学习率由超参数learning_rate确定。 -
模型训练:进行50个epoch的训练,每个epoch中执行以下步骤:
- 将模型设置为训练模式。
- 清空梯度。
- 通过模型传递训练数据
X_train,计算输出。 - 计算损失并进行反向传播。
- 更新模型参数。
-
模型验证:在测试集上评估模型性能,不计算梯度,计算测试损失。
-
返回值:函数返回测试损失,Optuna将使用这个值来评估超参数组合的性能。
-
Optuna研究对象:创建一个Optuna研究对象,设置优化方向为最小化目标函数。
-
优化过程:调用
optimize方法开始优化过程,指定进行50次试验(n_trials=50)。 -
输出最佳超参数:优化完成后,打印出表现最佳的超参数组合。
模型训练
model = CNNLSTM(
conv_out_channels=best_params['conv_out_channels'],
kernel_size=best_params['kernel_size'],
lstm_hidden_size=best_params['lstm_hidden_size'],
lstm_num_layers=best_params['lstm_num_layers']
)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=best_params['learning_rate'])
# 训练模型
num_epochs = 50
train_losses = []
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
output = model(torch.from_numpy(X_train).float())
train_loss = criterion(output, torch.from_numpy(y_train).float().view(-1, 1))
train_loss.backward()
optimizer.step()
train_losses.append(train_loss.item())
print(f'Epoch {epoch + 1}/{num_epochs}, Train Loss: {train_loss.item()}')
# 验证模型
model.eval()
with torch.no_grad():
test_output = model(torch.from_numpy(X_test).float())
test_loss = criterion(test_output, torch.from_numpy(y_test).float().view(-1, 1))
print(f'Test Loss: {test_loss.item()}')
-
模型初始化:使用Optuna优化得到的超参数创建
CNNLSTM模型实例。这些超参数包括:conv_out_channels:卷积层的输出通道数。kernel_size:卷积核大小。lstm_hidden_size:LSTM层的隐藏层大小。lstm_num_layers:LSTM的层数。
-
损失函数和优化器:定义均方误差损失函数(
MSELoss)和Adam优化器。学习率由超参数learning_rate确定。 -
模型训练:
- 设置训练轮数为50个epoch。
- 初始化一个列表
train_losses来记录每个epoch的训练损失。 - 对于每个epoch,执行以下步骤:
- 将模型设置为训练模式。
- 清空梯度。
- 将训练数据
X_train转换为PyTorch张量并传递给模型,计算输出。 - 计算损失并进行反向传播。
- 更新模型参数。
- 记录当前epoch的训练损失。
- 打印当前epoch的编号和训练损失。
-
模型验证:
- 将模型设置为评估模式。
- 使用
torch.no_grad()上下文管理器来禁用梯度计算。 - 将测试数据
X_test转换为PyTorch张量并传递给模型,计算输出。 - 计算测试损失。
- 打印测试损失。
可视化和计算MSE
# 反标准化
y_test_actual = scaler.inverse_transform(np.hstack((np.zeros((y_test.shape[0], 4)), y_test.reshape(-1, 1))))[:, -1]
test_output_actual = scaler.inverse_transform(np.hstack((np.zeros((test_output.numpy().shape[0], 4)), test_output.numpy().reshape(-1, 1))))[:, -1]
# 计算均方误差 (MSE)
mse = np.mean((test_output_actual - y_test_actual) ** 2)
print(f'Mean Squared Error: {mse}')
# 绘制预测值与真实值的对比图
plt.figure(figsize=(10, 6))
plt.plot(y_test_actual, label='True Value')
plt.plot(test_output_actual, label='Predicted Value')
plt.title('True vs Predicted Values')
plt.xlabel('Time Step')
plt.ylabel('Close Price')
plt.legend(loc='upper right')
plt.show()
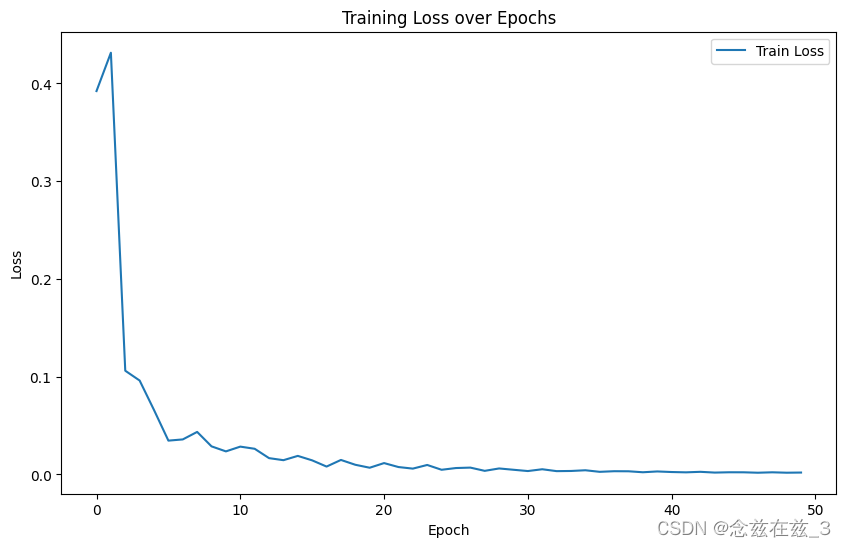
# 绘制训练损失
plt.figure(figsize=(10, 6))
plt.plot(train_losses, label='Train Loss')
plt.title('Training Loss over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(loc='upper right')
plt.show()
-
反标准化:
- 使用
MinMaxScaler的inverse_transform方法将测试数据y_test和模型预测输出test_output反标准化回原始数据的范围。这是因为在训练之前,数据被标准化到0到1之间。 np.hstack用于水平堆叠两个数组,这里首先创建一个全0的数组,其形状与y_test的前4列相同,然后将y_test或test_output的数组作为最后一列添加到这个全0数组中。[:, -1]用于从堆叠的数组中选择最后一列,即实际值或预测值所在的列。
- 使用
-
计算均方误差 (MSE):
- 计算反标准化后的测试输出与实际值之间的均方误差,这是衡量模型预测准确性的一种常用方法。
-
绘制预测值与真实值的对比图:
- 使用
matplotlib.pyplot绘制测试集中的真实值和模型预测值。 - 设置图表大小、标题、轴标签和图例。
- 使用
-
绘制训练损失:
- 使用
matplotlib.pyplot绘制模型在训练过程中每个epoch的训练损失。 - 设置图表大小、标题、轴标签和图例。
- 使用
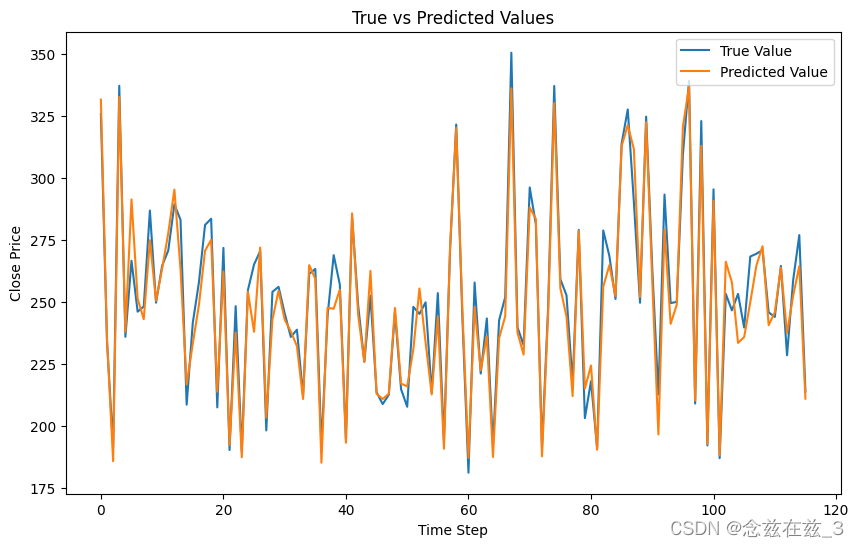
MSE: 74.88241952138789
结论
最后,我想说这是一个自己学习机器学习的一个项目,这一次尝试超参数优化,对误差进行可视化,自己认为这是一次很好的尝试,希望每个入门的友友,可以勇敢地学习,哪怕一开始很难,探索本身就是很好的事情。喜欢文章的友友,可以多多点赞关注。

















 1635
1635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









