







·Basic:
这里可以谈到一下DETR,基于transofrmer,集合预测&二分图匹配,端到端,有跟fasteRCNN相当的性能。--> 简单来说就是bakebond为CNN提取特征,送入transformer进行关系建模,将输出通过二分图匹配去和GT做匹配算loss。
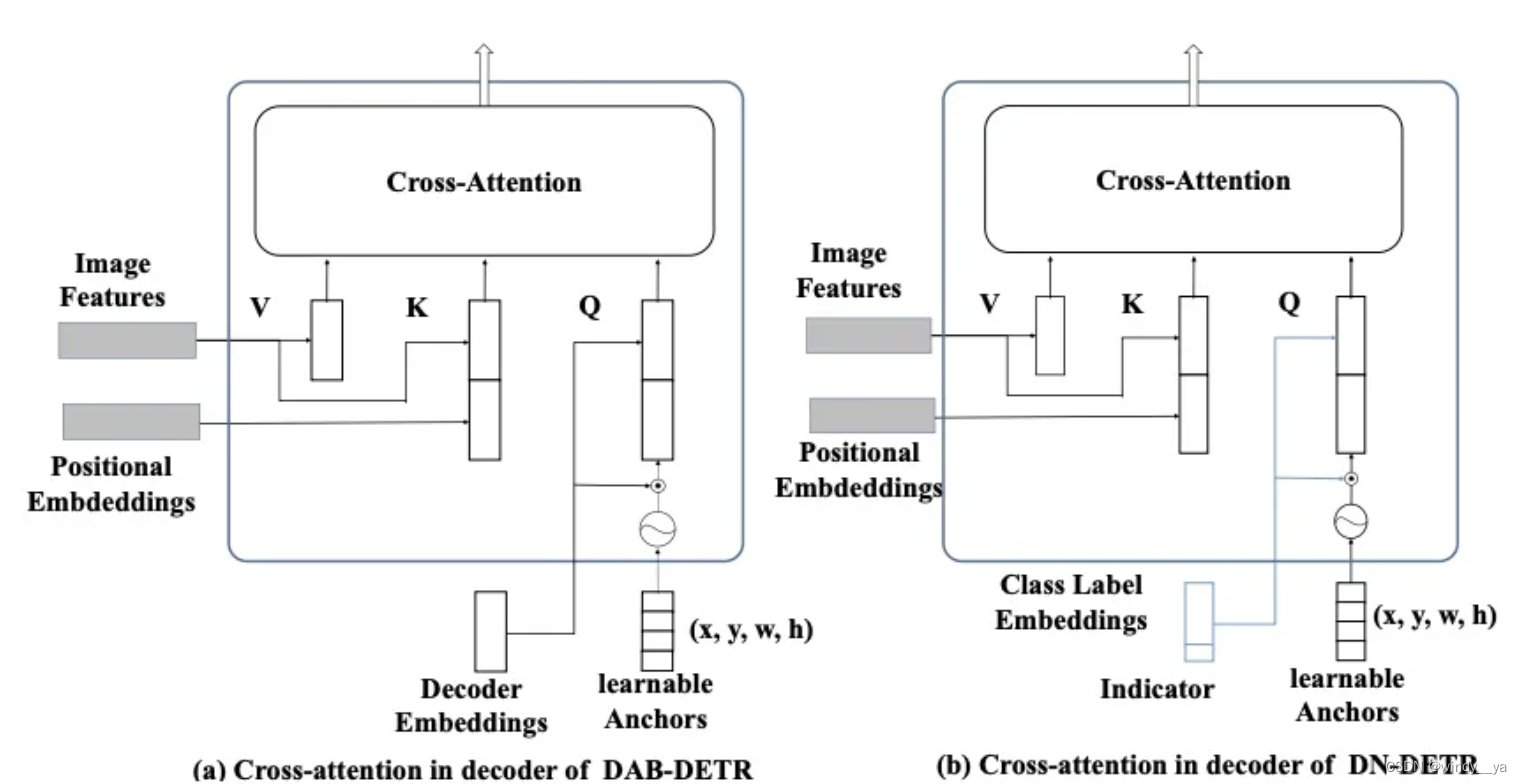
1.DAB:用类似于anchor来解决query,有预测框。
2.DN:noised labes, noised boxes & attention mask
针对二分图匹配【一开始匹配是随机的,且会一直发生变化,存在它匹配是不一致的】因此作者直接对模型加入真实框,将真实框输入解码器训练模型重建该框,从而跳过二分图匹配。但是直接输入真实框对transformer来说太过简单,会导致性能不好,所以引入了噪声,即带噪声的GT标签和框,输入解码器进行重建原始label&框。--> 加速训练,因为这样相当于shortcut在学习偏移量,直接跳过了匹配
噪音为
,
(x,y,w,h)为中心点,
为超参数;
因为DN是有点followDAB的感觉(就是把query也看做anchor),所以在DN中可以把这个噪音GT看作是GT附近的anchor。

【关于为什么要加入噪声,在这里可以理解成有噪声的GT是有自监督task的感觉,做box-domain的预训练模型】,这是来自于知乎上的一个理解,我觉得很好!如下图

3.Deformerable:
(1)可形变,参考点,offset,即self-attention关注到的是参考点周围的一小组点来作为采样点而非全局,这样就可以注意到稀疏点降低计算量。
(2)look forward once??
于是,在以上的基础上,出现了DINO;好了,那就开始DINO的解读吧。
一、motivation
二、innovation:
(1)把query变成动态的anchor box【DAB】
(2)添加噪音的GT的label和框输入解码去中,使模型你能够重建原始标签&框 --> 稳定二分图匹配【DN】
(3)可变形detr&look forward once的层参数更新,减少计算量提高运算效率提高性能【deformable detr】
a.加入了GT的正负样本从而去噪训练-->一对一,避免相同目标重复出现???
b.混合query:position auery来自encoder的输出;content query是可学习tensor;位置查询作为动态anchor,并且采用DN loss。
c.两次forward-->通过后面层来更新前面层的参数。
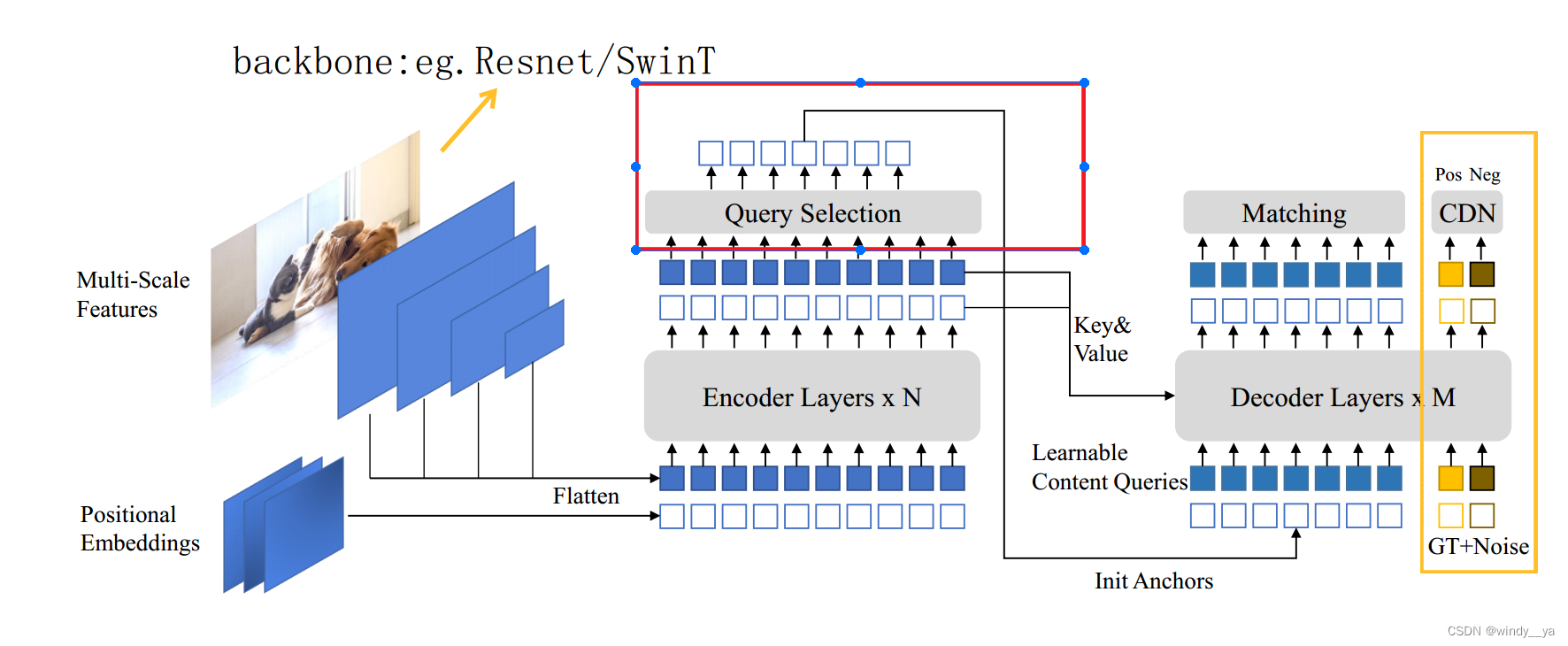
三、网络框架:
(1)用backbone去提取多尺度图形特征。’
(2)将图形特征和位置编码(transformer无序列区别)加起来放到Encoder;encoder的特征图输出将作为decoder中的V,K
(3)将encoder输出的特征图进入QS模块选取topK个作为anchor,其实就是position query
(4)Content query是可学习的tensor,和position一起放入decoder中和特征图的K,V进行attention。
(5)decoder输出后进行matching,anchor和分类
(6)另外,添加了CDN加速并且还加了lookforward twice来提高性能。
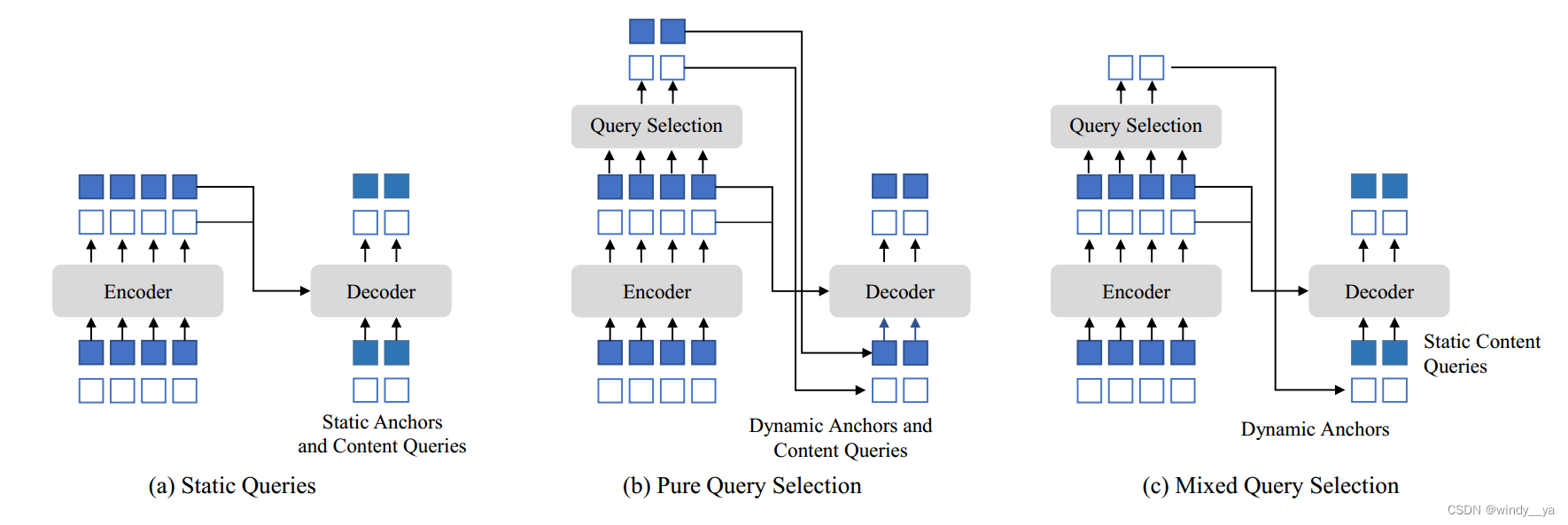
(1)Query Selection
motivation:DN\DAB\DETR中都是静态查询,没有加上encoder的图像特征,anchor(DN\DAB)或者position query都是在训练数据中得出,并且content query直接初始化为0;deformable的position&content(b)也是静态查询,anchor和content都是通过top K的特征图得出的,但是这样所选content没有经过进一步细化,较为模糊会导致误导;
innovation:混合query,position是通过topK个特征图得到,而content是可学习的。用较好的位置信息获取编码器的全面的content。
(2)CDN模块:对于正负样本的去噪:这里是follow了之前的DAB-detr,但是在此基础上加上了负样本。
motivation:下图是DAB的去噪,主要是对cross-attention进行修改。如图(b),引入lable(class embed ing)&anchor(position)的噪声去训练从而重建。DAB中的噪声GT都是基于有物体的正样本,但是缺少no object,所以没有预测no object的能力
innovation:加入负样本
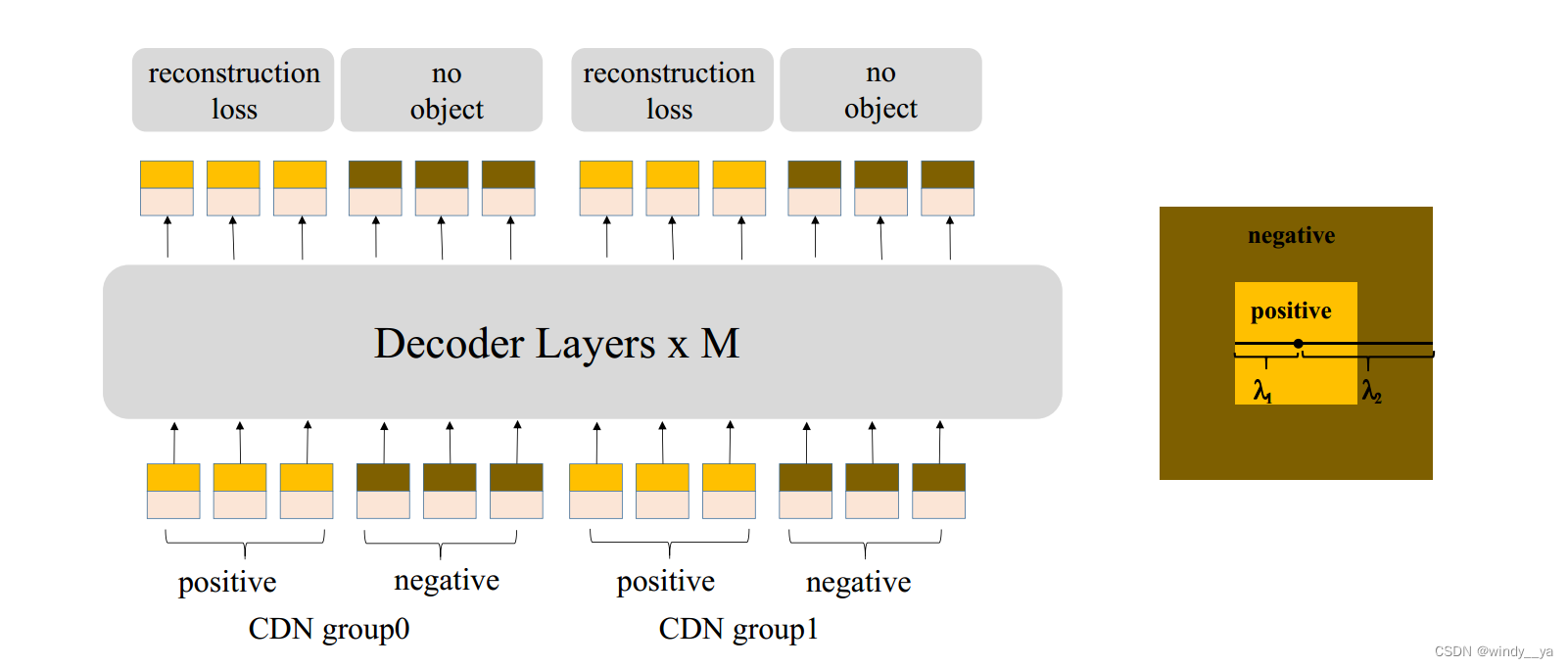
如上图,正负样本为右边的那个二维同心正方形,每一个group都有正负样本-->从而实现可以抑制混淆的anchor,选择高质量的anchor:这样可以避免两个问题1.避免重复预测(原论文有DN和DINO对比)2.避免选到远的anchor,因为CDN会抑制远的。
在这里作者引入TopK distance来验证有效性:因为越远的anchor混淆的概率越大。-->最后实验证明CDN用于小目标检测AP更高。
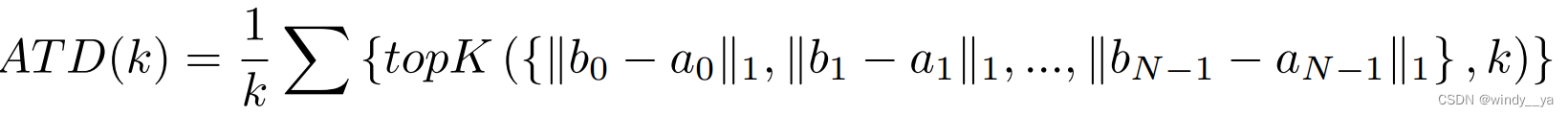
(3)二次forward
作者认为后一层框的信息可能也有助于改善前一层的预测框,
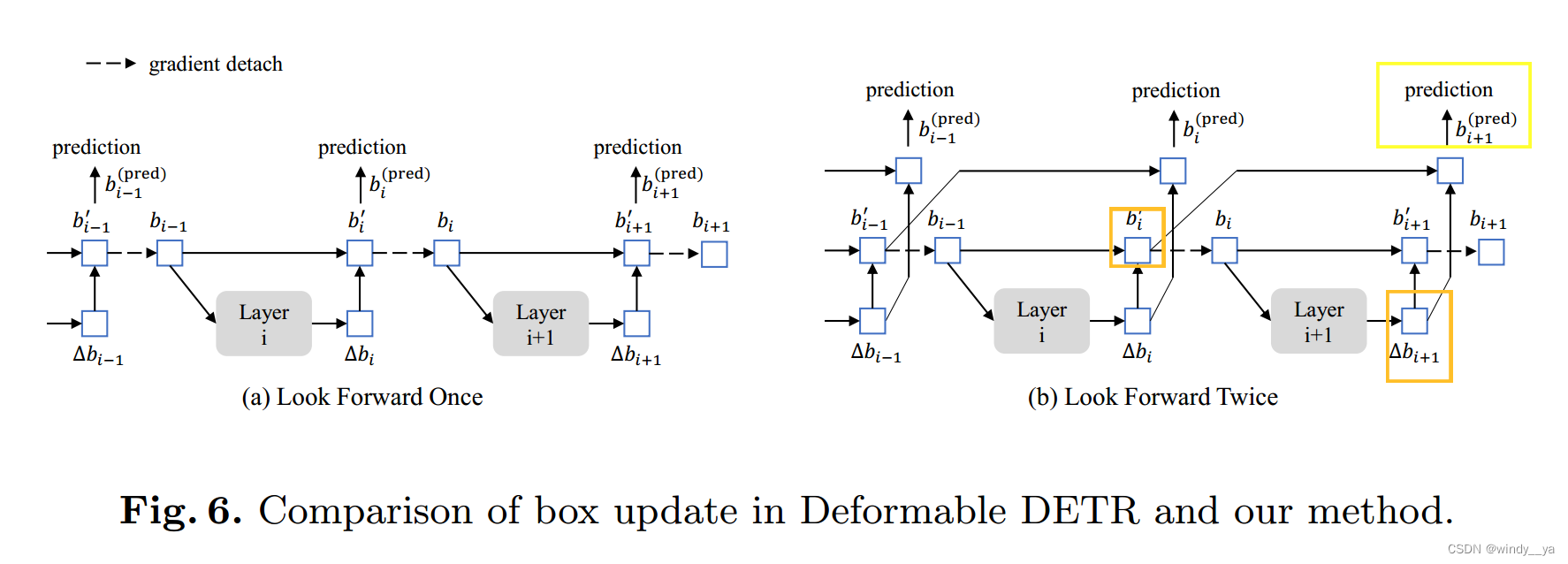
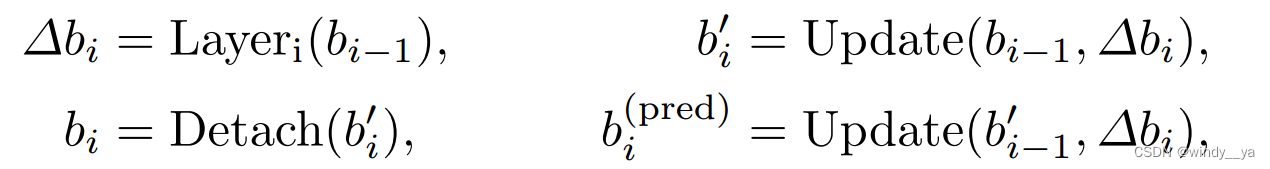
为了让第i层受到第i和i+1层的loss进行更新优化;可以看到在这里每一个偏移量都被用来更新框两次:一次是bi‘,一次是bpre(i+1);

四、实验
1,
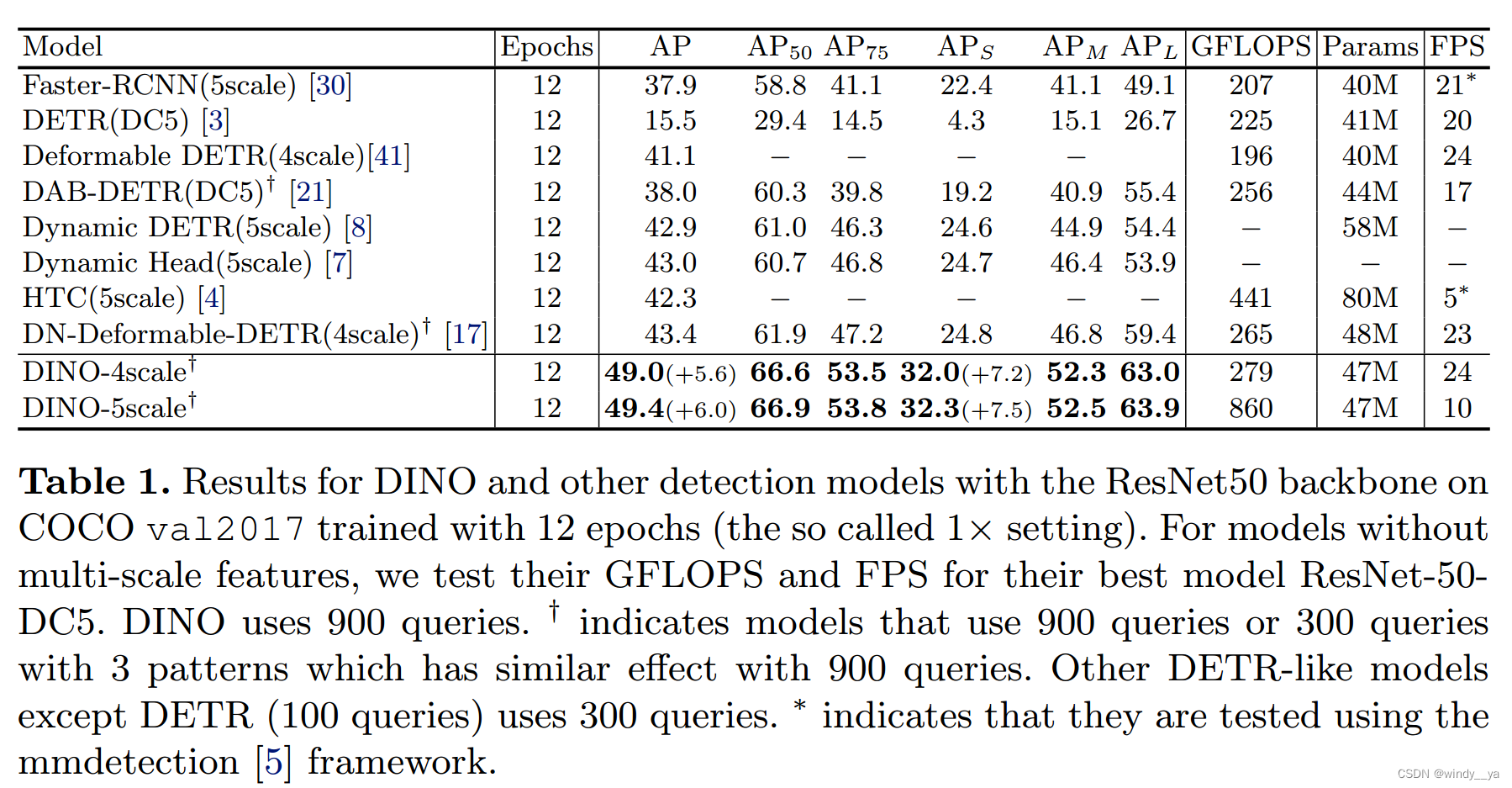
(1)用DINO-4/5后AP涨点+5.6/+6.0
(2)APs,即小目标检测上+7.2/7.5
(3)DINO-4没有引入额外的计算量和参数量却获得了可观的性能。
2.sota
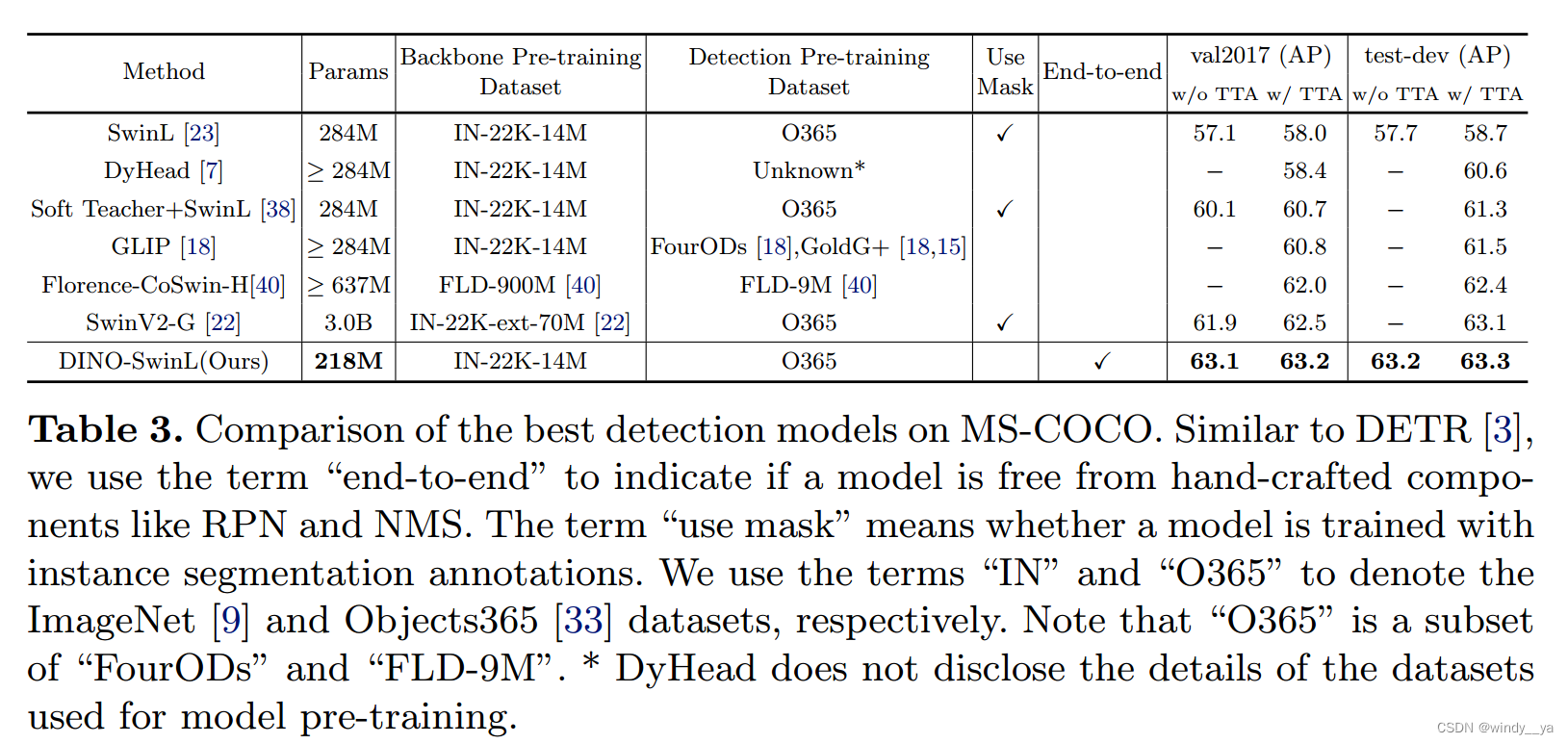
3.
1.detr的query分为两个部分:一个是position query(4D坐标),一个是contentquery;【这个得再理解一下】、
2.MMDetection















 4849
4849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









