






目录
2、 证明target分支+Osrc的合理性 —— 编辑性能
【建议先跳到第六部分BASIC看完背景知识再看motivation!】
一、motivation
inversion过程的准确率影响source image的保留和特瑞个体prompt的编辑,以往的inversion更多的都在于找到source 和target分支的统一处理方式
DDIM在无条件扩散下效果是好i的,但是图像编辑应用带是具有prompt去指导生成,而DDIM引入input去指导会导致inversion结果不如意。
先前的方法是通过简介调整模型输入参数来最小化Z0和Z0‘’的distance(例如null-text是通过优化他的指令而非优化diffusion过程),但是不理解为什么将目标潜在优化限制在几次迭代?
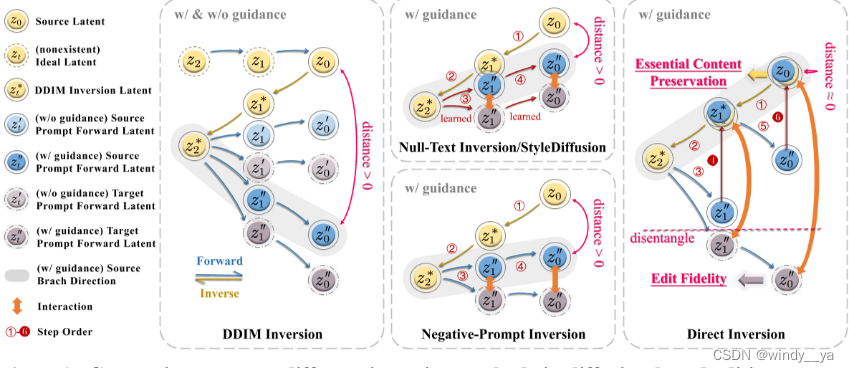
这里放上null-inversion:
上面是通过guaidance的参数去优化整个模型,但是这样代价很大;所以null-text提出了优化它的饿指令而非模型的去噪过程,通过MSE优化null-text让文本指导去更有利于真实图像,即生成的图像更接近于source image,distance 减小。
但是这里有一个问题就是,学习的那个null-text在原本与训练模型中并没有出现,所以在这里的 模型输入和一开始的与训练模型的输入存在偏离,可能会因相关i昂模型的生成能力。导致Z0''和Z0有明显的gap。
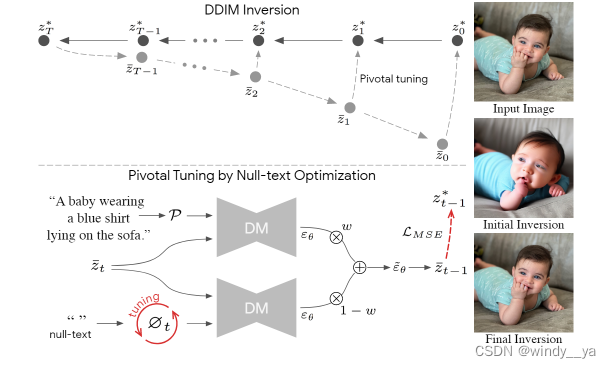
OK上面字太多了这里做个总结
1、null-text为了优化潜在变量会延迟他的推理速度,交互编辑任务步ok
2、为了让他不延迟,我们就限制迭代次数,这样导致distance明显,我理解的就是只减小不消失
3、null-text通过学习到的潜在变量作为DM的输入,会导致跟一开始与训练DM 的输入不一致,影响去噪。
二、innovation
解耦source分支和target分支,每个分支各司其职表现出色:source修正偏差,target不变保持编辑效果。
三、methond
对于source分支:
把 加回
,即保持它不变。
-> ①无需优化 ②直接消除了distance ③没有去噪过程中输入不同的影响了

如上面算法,重点在于那三行代码——用加上O来直接消除distance而无需迭代优化;最重要的是实现了解耦: 的更新只是加上了前面
和sorce的
的distance,而不是target的;所以相当于它保留了原来的source信息,但是对于target prompt又留了部分的可编辑空间;
四、实验
1、评估指标
| 评估指标 | |||||
| 背景保留 | 编辑一致 | ||||
| structure distance↓ | PSNR↑ | LPIPS↓ | MSE↓ | SSIM↑ | CLIPSIM↑(分whole和edit) |
| 原图像和编辑后的图像之间的结构差异,越小代表信息保留的越好 | 重建图像和参考图像之间的差异。PSNR越高,表示重建图像与参考图像越接近,质量越好 | 感知相似性指标,越小就说明重建和编辑在人类感知下越相似 | 均方误差 | 结构相似性:亮度、对比度··· | 就是拿生成图跟prompt用clip看看相关性:whole就是拿整幅图,edit就是拿mask部分 |
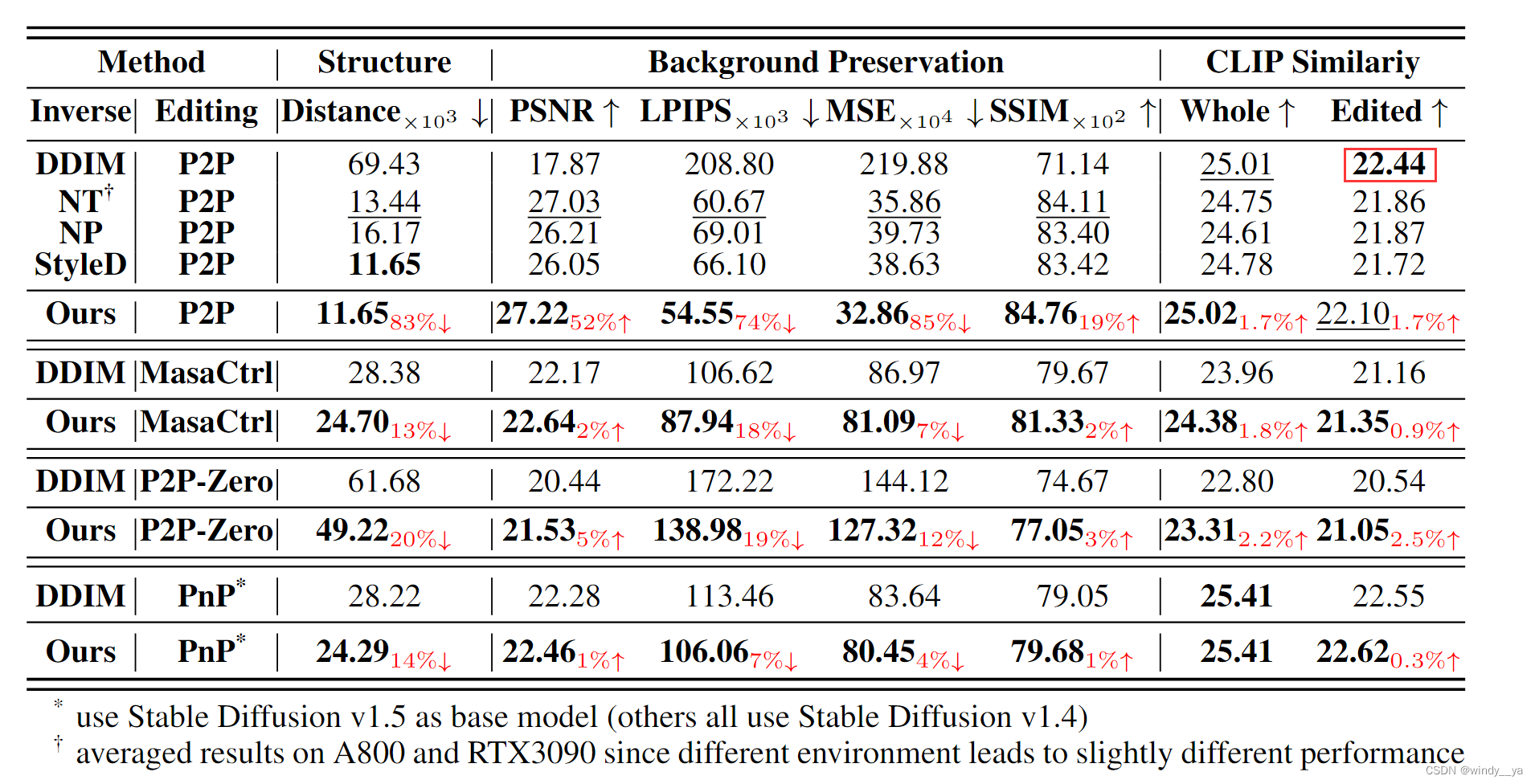
2、和其他inversion在四种编辑的对比
可见在原图信息保留和编辑的保真性都有较好的性能(除了clipsmi的editted低于DDIM,但是只能说明DDIM在生成的时候性能好,但是对于原图信息的结构保留就很差,上面我们也有提到原因)
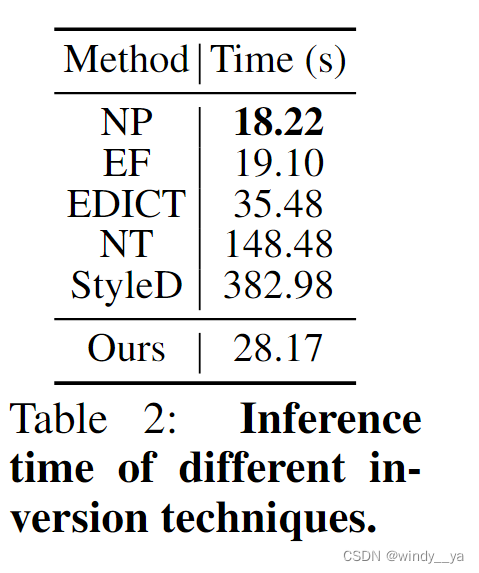
3、推理时间
Null-Text Inversion 和 StyleDiffusion 相比,direct inversion在推理时间要少得多的情况下获得了更好的编辑结果。尽管 Negative-Prompt Inversion 和 Edit Friendly DDPM 的推理速度比 Direct Inversion 快一点,但与 Direct Inversion 相比,它们的编辑结果是不ok的
4、和背景保留较好的inversion对比——证明编辑性好
以null-text为baseline,其余方法都是对背景信息保留较好的method,但是可以看到,CLPsmi都降了,而Direct inversion在保留source的同时编辑的也很好

5、消融实验
1、拿null-text去做消融:
1)NT和NT-S[学习到的null-text只加到source分支,target不变]:可以看到CLIP都上升了。——target不变的好处
2)NL代表null-text+Osrc; 数字代表Osrc的缩放,1就是Osrc
可以发现原null-text的潜在空间其实就是缩短了distance 0.4~0.8
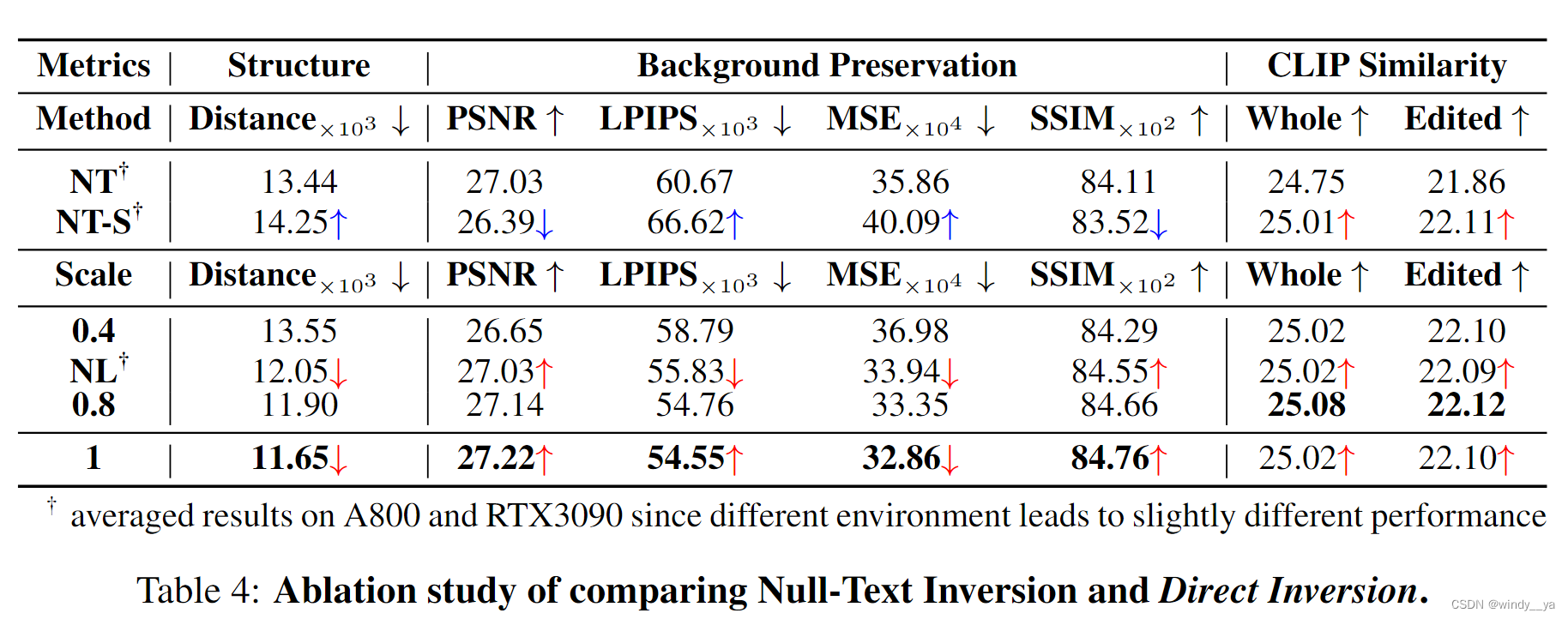
2、 证明target分支+Osrc的合理性 —— 编辑性能
可以发现,加Otgt会有较好的保留source的能力没错,但是edit就急剧下降了。所以再次证明,只加Osrc是在保留sorce 结构和target edit上有较好的权衡。
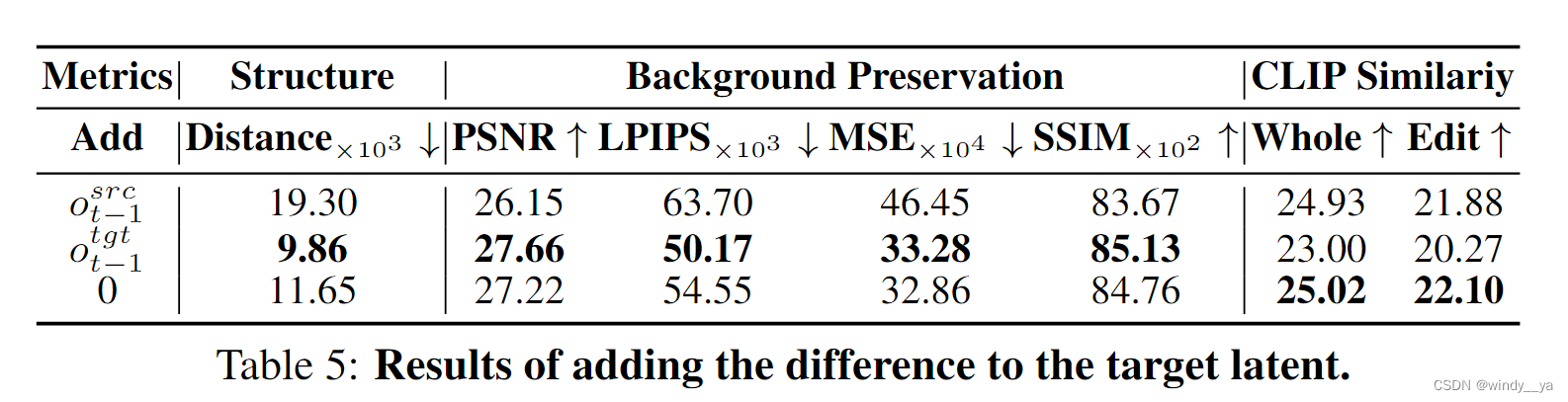
6、可视化

五、基准数据集 —— PIE-Bench
700张图,10种编辑方法
5个标注:①source prompt ②target prompt ③edit instruction ④main editing body ⑤editing mask
六、BASIC
关于背景知识:包括Diffusion model、DDIM inversion
1、diffusion model
1)Zt = f(z0) ddpm里的加噪,一步做到
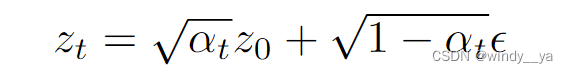
2)为了后续去噪过程中,训练noise predicter(Unet)
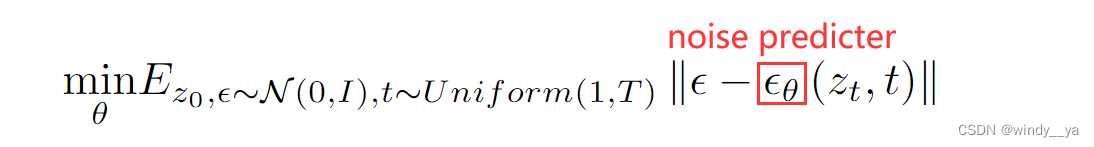
3)生成图片时去噪,用Zt - unet预测的噪声 实现逐步去噪
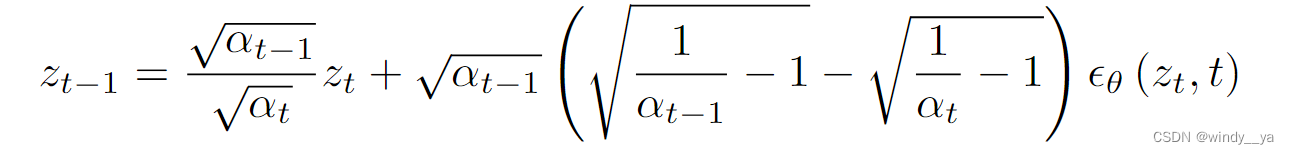
2、DDIM inversion
因为在DDIM中主要是对于ZT的去噪生成图片,但是 在图像编辑输入的是它的原始真实图像source image,而非生成的图像,DM没见过很难去实现编辑。所以,我们需要有一个将真实图像Z0-> ZT的过程,然后在将ZT这个latent送入DM中去噪得到编辑后的图像。而这个Z0-> ZT的过程就是inversion。
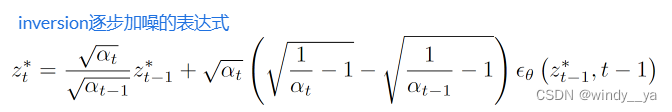
但是,前面在理想状态下,我们假设的是在无穷小的时间步下,可以实现rverse;但是现实情况下我们是没有办法无穷小的,所以inversion出来的Zt*跟原预训练时图像的Zt是有差别的,进一步导致将Zt*送入DM中去噪出来的Z0’跟原来的Z0是不一样的,就是说生出来的图跟原图是有区别的。【如下图存在distance】

3、Classifier-free Guidance
就是在解决输入中添加文本的情况下的噪声处理

在文本的guidance下会出现上米艾尼DDIM inversion的Z‘’和Z‘的差距,进一步导致Z0''和Z0的distance。
所以基于上述对inversion的介绍,先前的 inversion技术的改进都是针对解决①DDIM的distance; ②加入文本guidance后的影响。
其实我感觉就是相当于没有办法很好地保留原图信息,生成出来的图会有些许差异。所以现在的invversion都努力让inversion得到的ZT* 去噪完得到的Z0’ 更多的去往原图的Z0靠。
4、NUll-text inversion
把3的公式改了一下,加了一个null-text,就是优化它的文本输入吧我感觉。通过z‘’-z*这个MSE来学习出一个减少distance的好的潜在变量;在后续的source和target分支都加进去这个潜在变量。
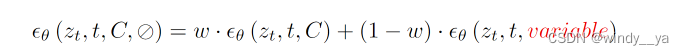















 98
98

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









