






目录
4. 使用`LogisticRegression`类进行比较
一、简介
在机器学习中,分类问题是一种常见的任务,目标是根据输入特征将数据点分配到不同的类别中。为了实现分类,我们需要训练一个分类器,该分类器能够根据输入数据的特征进行预测。
逻辑回归(Logistic Regression)是一种常用的分类算法,尤其适用于二分类问题。逻辑回归的核心思想是通过对数几率函数(logistic function)将线性回归的输出映射到概率空间,从而实现分类。
注意:逻辑回归虽然名字中有回归二字,但是它不是回归算法,而是分类算法。
二、逻辑回归的原理
逻辑回归(Logistic Regression)是一种广泛使用的分类算法,它的主要思想是将输入变量的线性组合映射到0到1之间的概率,用于预测二元输出变量的概率。
2.1逻辑回归模型的执行流程
若以贷款为例,逻辑回归的执行流程
1. 输入:对于贷款申请的输入数据,例如申请人的收入、年龄和其他相关信息,可以构建一个输入向量 x(3) = [1, 4000, 20]T。这个向量包括了两个特征变量,分别是收入和年龄。
2. 处理:通过逻辑回归模型构建一个预测函数 gθ(x(i)),其中 θ 表示模型的参数。该预测函数可以将输入向量映射到一个介于0和1之间的概率值,表示是否批准贷款的可能性。
3. 输出:经过预测函数的处理后,可以得到一个输出结果 gθ(x(3)),表示对输入数据的反馈。比如,如果 gθ(x(3)) = 1,表示该分类器认为对于向量 x(3) 提出的贷款申请可批准;如果 gθ(x(3)) = 0,表示不可批准。这个输出结果可以被银行用来决定是否批准该贷款申请。
2.2逻辑回归模型的算法原理:
- 假设我们有一个二元分类问题,需要预测一个样本属于两个类别中的哪一个。
- 逻辑回归模型使用一个参数化函数来计算给定输入变量的输出概率。该函数称为 sigmoid 函数,它将输入变量的线性组合映射到0到1之间的值,表示预测样本属于正例的概率。
- 训练模型的过程就是通过最大化似然函数来估计模型的权重。似然函数是一个关于模型参数的函数,表示给定模型下,样本的概率。
- 为了最大化似然函数,我们可以使用梯度下降算法来更新模型的权重。梯度下降算法通过反复迭代来最小化损失函数,直到找到最优解。
- 损失函数通常使用对数损失函数(log loss)来衡量模型的性能。
- 训练模型后,我们可以使用模型来预测新的样本的类别标签。预测类别标签的方法是,将新样本的特征向量代入 sigmoid 函数,计算输出概率,如果概率大于0.5,则预测为正例,否则预测为负例。
逻辑回归模型简单而直观,易于理解和实现,常用于二元分类问题的建模
2.2.1sigmoid 函数
sigmoid 函数的数学形式为:其中,z 是输入变量的线性组合,可以表示为: 其中, 是模型的权重(即系数), 是输入变量的值。
sigmoid 函数的数学形式为:
它是一个定义域为 (−∞, +∞) ,值域为 (0,1) 的严格单调递增函数,其图像如下图所示:

其中,z 是输入变量的线性组合,可以表示为:Z=b+W1X1+W2X2+...+WnXn其中,Wi是模型的权重(即系数),Xi是输入变量的值。
在逻辑回归中,我们将输入变量通过线性组合得到 z 值,然后将 z 值代入 sigmoid 函数中,得到一个介于 0 和 1 之间的概率值,表示预测为正类的概率。sigmoid 函数的特性使其能够将任意实数映射到 (0, 1) 区间,因此适用于二分类问题的概率预测。
2.2.2似然函数
似然函数是一个关于模型参数的函数,表示给定模型下,样本的概率。在逻辑回归中,似然函数可以表示为:
其中,Zi是第i个样本的线性组合,Yi是对应的类别标签(0或1)。
2.2.3损失函数
对数损失函数可以表示为:
其中, 是第Zi个样本的线性组合,Yi是对应的类别标签(0或1)。
三、梯度下降法
3.1介绍
梯度下降法(Gradient Descent)是一种常用的优化算法,用于最小化代价函数(Cost Function)或损失函数。在逻辑回归等机器学习模型中,梯度下降法常用于更新模型参数,以找到使代价函数最小化的权重和偏置。
梯度下降法的基本思想是通过迭代更新参数,沿着代价函数的负梯度方向移动,以逐步接近代价函数的最小值。
具体而言,梯度下降法包括以下步骤:
- 初始化参数:将权重向量w和偏置b初始化为任意值。
- 计算梯度:对于每个参数,计算代价函数关于该参数的偏导数(梯度)。这可以使用链式法则来计算,根据代价函数的形式不同而有所不同。
- 更新参数:根据梯度的方向和学习率(learning rate),更新参数的值。学习率决定了每次参数更新的步长,较大的学习率可能导致无法收敛,而较小的学习率可能导致收敛速度过慢。
- 重复步骤2和3:重复计算梯度和更新参数的过程,直到达到停止条件。停止条件可以是达到一定的迭代次数,或者代价函数的变化小于某个阈值等。
3.2更新规则
假设我们有一个目标函数f(x),我们所处的初始点为x0。我们需要找到这个函数的局部最小值(可能是全局最小值)。梯度下降算法的更新规则:

其中α 是学习率,决定了我们沿着梯度方向迈出的步长;∇f(x) 是函数 f(x) 在点 x 的梯度。我们首先选择一个初始值x0,并计算函数在该点的梯度∇f(x0)。
下图是函数f(x)=2x^2+2x+1的梯度下降找到局部最小值的过程:

四、python实现
1. 数据预处理和准备
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
# 加载数据集,并数据归一化
iris = load_iris()
X = iris.data[:, :2]
y = (iris.target != 0) * 1
scaler = StandardScaler()
X = scaler.fit_transform(X)加载了鸢尾花数据集,并提取了其中的两个特征作为输入特征X,将目标变量转换为二元分类问题(0或1)。然后对输入特征进行了归一化处理,使其具有相似的尺度。
2. 逻辑回归模型的手动实现
# Sigmoid函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 损失函数
def cross_entropy(y, y_pred):
return -np.mean(y * np.log(y_pred) + (1 - y) * np.log(1 - y_pred))
# 梯度下降
def gradient_descent(X, y, theta, alpha, num_iters):
m = len(y)
for i in range(num_iters):
z = np.dot(X, theta)
h = sigmoid(z)
loss = cross_entropy(y, h) # 计算损失
grad = np.dot(X.T, (h - y)) / m
theta -= alpha * grad
if i % 1 == 0:
print("Iteration %d, Loss: %f" % (i, loss))
return theta
# 初始化参数
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
theta = np.zeros(X_train.shape[1])
alpha = 0.1
num_iters = 1000定义了Sigmoid函数、交叉熵损失函数和梯度下降算法,然后利用这些函数手动实现了逻辑回归模型的训练过程。在训练过程中,根据训练集数据更新模型参数,以最小化损失函数。
结果(选取其中一段):
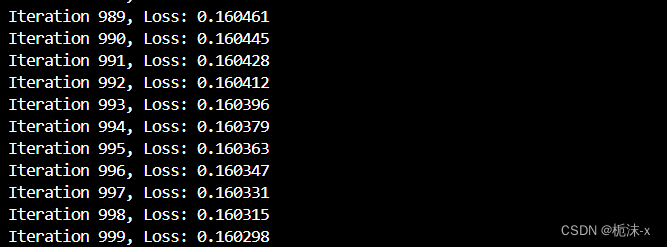
3. 模型训练和评估
# 训练模型
theta = gradient_descent(X_train, y_train, theta, alpha, num_iters)
# 预测测试集
y_pred = sigmoid(np.dot(X_test, theta))
y_pred = (y_pred > 0.5).astype(int)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)使用训练集对逻辑回归模型进行训练,然后利用测试集数据进行模型的预测,并计算了模型在测试集上的准确率。
结果:
![]()
4. 使用`LogisticRegression`类进行比较
# 计算最佳拟合直线的斜率和截距
clf = LogisticRegression()
clf.fit(X_train, y_train)
slope = -clf.coef_[0][0] / clf.coef_[0][1]
intercept = -clf.intercept_ / clf.coef_[0][1]
利用scikit-learn库中的`LogisticRegression`类训练了一个逻辑回归模型,以便与手动实现的梯度下降方法进行比较。
5. 绘制结果
# 使用matplotlib绘制散点图
plt.scatter(X_test[y_test == 0][:, 0], X_test[y_test == 0][:, 1], color='red', label='0')
plt.scatter(X_test[y_test == 1][:, 0], X_test[y_test == 1][:, 1], color='blue', label='1')
# 绘制最佳拟合直线
x_min, x_max = X_test[:, 0].min() - 1, X_test[:, 0].max() + 1
y_min, y_max = X_test[:, 1].min() - 1, X_test[:, 1].max() + 1
plt.plot([x_min, x_max], [slope*x_min + intercept, slope*x_max + intercept], color='black', linestyle='-', linewidth=2)
# 显示图像
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()使用matplotlib库绘制了测试集的散点图,并在图上绘制了最佳拟合直线,以直观地展示模型的预测效果。
结果:
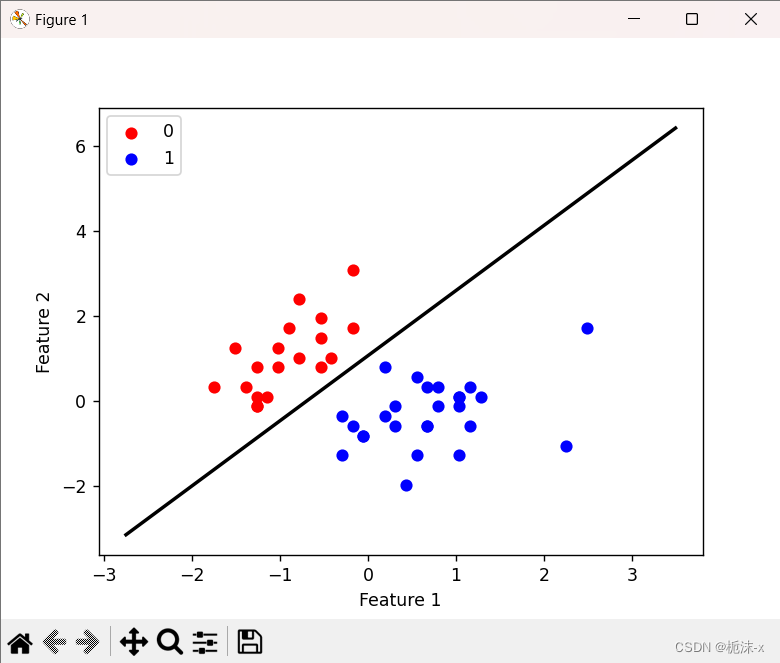
此段代码展示了从头开始实现逻辑回归模型的全过程,包括数据预处理、模型实现、训练和评估,以及结果可视化。同时也使用了scikit-learn库中的`LogisticRegression`类进行了模型训练,以便比较手动实现的方法和现成的库函数的效果。
五、总结
5.1逻辑回归的优缺点
优点:
1. 简单易懂:逻辑回归是一种直观且易于理解的算法,很容易通过概率和回归分析来解释结果。
2. 计算效率高:逻辑回归的计算成本相对较低,训练速度快,并且在处理大型数据集时表现良好。
3. 输出结果具有概率解释:逻辑回归可以输出样本属于某个类别的概率,这对于风险管理和决策制定非常有帮助。
4. 对特征工程友好:逻辑回归对特征之间的关系不敏感,能够很好地处理高维度数据。
缺点:
1. 只能处理线性可分问题:逻辑回归是一种线性分类器,对于非线性问题表现不佳。
2. 容易受到异常值影响:逻辑回归对异常值敏感,可能会影响模型的性能。
3. 需要依赖大量特征工程:在处理复杂数据集时,逻辑回归需要进行大量的特征工程处理,以保证模型的性能。
4. 无法处理复杂关系:逻辑回归无法捕捉特征之间的复杂交互作用,对于非线性关系的建模能力有限。
总的来说,逻辑回归是一种简单而有效的分类算法,特别适用于线性可分的问题和需要概率解释的场景。然而,在处理非线性问题和复杂关系时,就需要考虑其他更为复杂的模型。















 911
911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









