






目录
一.k-近邻算法简介
1.1KNN算法介绍
k-近邻算法采用测量不同特征值之间的距离方法进行分类
存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
1.2算法原理
K近邻算法的核心思想是基于特征空间中相邻数据点具有相似性的假设。在分类任务中,KNN算法通过测量不同数据点之间的距离来确定新数据点的分类。具体步骤如下:
- 计算新数据点与训练集中所有数据点的距离。
- 根据距离找到与新数据点最近的K个邻居。
- 根据这K个邻居的类别,通过多数表决的方式确定新数据点的类别。
1.3距离的计算
对于给定的新样本,计算它与训练数据集中所有样本的距离,常用的距离度量包括
- 欧氏距离

2.曼哈顿距离
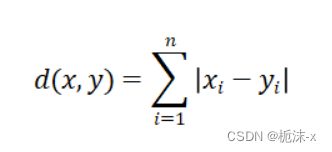
二.算法实例——性别判断
2.1算法流程
KNN算法的流程主要分为以下几个步骤:
1.4 k-近邻算法的一般步骤
1.收集数据:可以使用任何方法
2.准备数据:距离计算所需要的数值,最好是结构化的数据格式
3.分析数据:可以使用任何方法
4.训练算法:此步骤不适用k-近邻算法
5.测试算法:计算错误率
6.使用算法:首先需要输入样本数据和结构化的输出结果,然后运行k-近邻算法判定输入数据分别属于哪个分类,最后应用对计算出的分类执行后续的处理
2.2代码实现
导入需要的库
import numpy as np
import matplotlib.pyplot as plt1: 收集数据 - 数据格式:身高(cm),体重(kg),性别
将数据写入文本文件 D:/python code/data.txt 中
2: 准备数据 - 解析文本文件
def load_data(file_path):
data = []
labels = []
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
line = line.strip().split(',')
data.append([float(line[0]), float(line[1])])
labels.append(line[2])
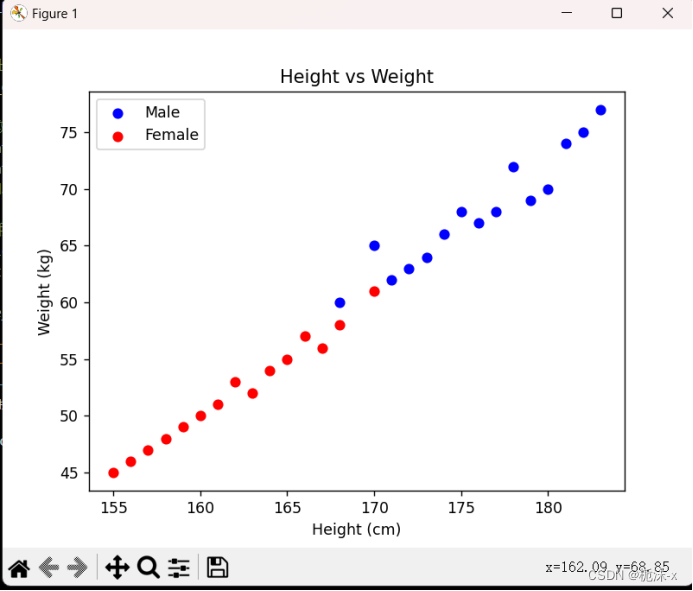
return np.array(data), labels3: 分析数据,画出二维散点图
def plot_data(X, y):
male = X[np.array(y) == '男']
female = X[np.array(y) == '女']
plt.scatter(male[:, 0], male[:, 1], color='blue', label='Male')
plt.scatter(female[:, 0], female[:, 1], color='red', label='Female')
plt.xlabel('Height (cm)')
plt.ylabel('Weight (kg)')
plt.title('Height vs Weight')
plt.legend()
plt.show()4.训练算法:此步骤不适用k-近邻算法
5: 测试算法 - 不需要额外步骤
6: 使用算法 - KNN分类
def knn_classify(new_data, X, y, k=3):
distances = np.linalg.norm(X - new_data, axis=1)
nearest_indices = np.argsort(distances)[:k]
nearest_labels = [y[i] for i in nearest_indices]
# 返回k个最近邻样本中出现次数最多的类别作为预测结果
return max(set(nearest_labels), key=nearest_labels.count)
def main():
# 加载数据
file_path = 'D:/python code/data.txt'
X, y = load_data(file_path)
# 画出二维散点图
plot_data(X, y)
# 获取用户输入的特征数据
height = float(input("请输入身高(cm):"))
weight = float(input("请输入体重(kg):"))
new_data = np.array([height, weight])
# 使用KNN算法进行预测
predicted_gender = knn_classify(new_data, X, y, k=3)
print("预测的性别为:", predicted_gender)
if __name__ == "__main__":
main()2.3运行结果
- 二维度散点图
2.测试判断

三.总结
3.1K值选择
- K值过小:
(1)容易受到异常点的影响;
(2)容易过拟合(即在训练集上表现好,但是在测试集上不好)。
- k值过大:
(1)受到样本均衡的问题;
(2)容易欠拟合。
3.2优缺点
- 优点:
·简单,易于理解,无需估计参数,无需训练。
- 缺点:
·懒惰算法,对测试样本分类时的计算量大,内存开销大;
·必须指定K值,K值选择不当,则分类精度不能保障。
3.3应用场景
K最近邻(KNN)算法是一种常用的监督学习算法,适用于各种应用场景。
- 分类问题:KNN可以用于分类问题,例如垃圾邮件过滤、文本分类、图像识别等。它通过将待分类样本的特征与已知类别的样本进行比较,根据最近邻的类别进行分类。
- 回归问题:除了分类,KNN还可以用于回归问题,例如预测房价、股票价格等。在这种情况下,KNN通过找到最近邻居的平均值或加权平均值来预测数值型输出。
- 推荐系统:KNN可用于构建基于用户或物品的协同过滤推荐系统。通过比较用户或物品之间的相似性,可以推荐给用户可能感兴趣的物品或者其他用户可能喜欢的用户。
- 异常检测:KNN可以用于检测异常值,例如信用卡欺诈检测、网络入侵检测等。异常值通常与其周围的数据点不同,因此可以通过KNN识别与其他数据点相异的样本。
- 模式识别:KNN也可用于模式识别领域,例如手写数字识别、人脸识别等。通过比较待识别样本与已知类别的样本,可以识别出相似的模式。
总的来说,KNN算法在各种领域都有广泛的应用,特别是在小型数据集、数据分布均匀的情况下表现良好。















 3724
3724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









