







昨天通过pycharm已经能够连接到集群了
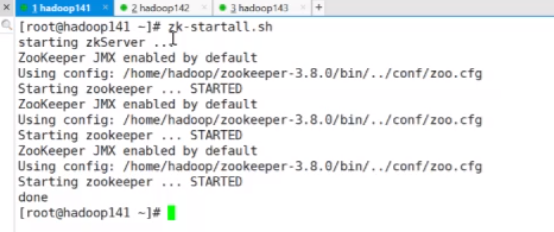
先启动spark集群
zk-startall.sh

start-all.sh

cd /home/hadoop/spark-3.5.0
./sbin/start-all.sh
启动以后看看集群里面的文件夹
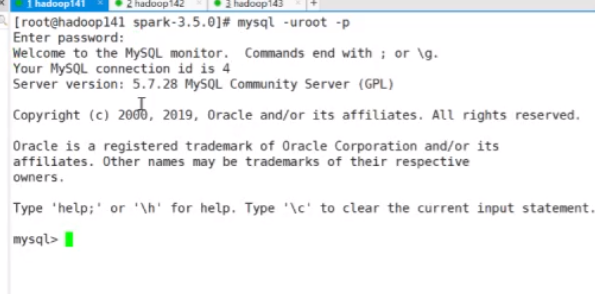
mysql -uroot -p
然后可以连接到虚拟机的数据库的 密码是123456
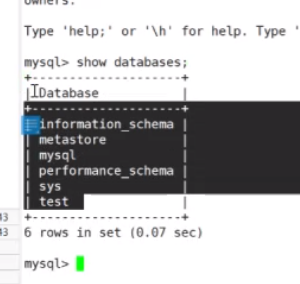
show databases
查看现有数据库
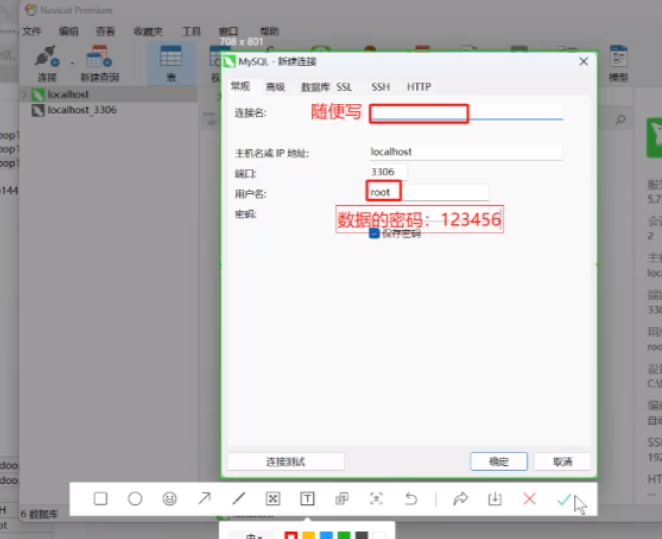
然后Navicat新建连接数据库
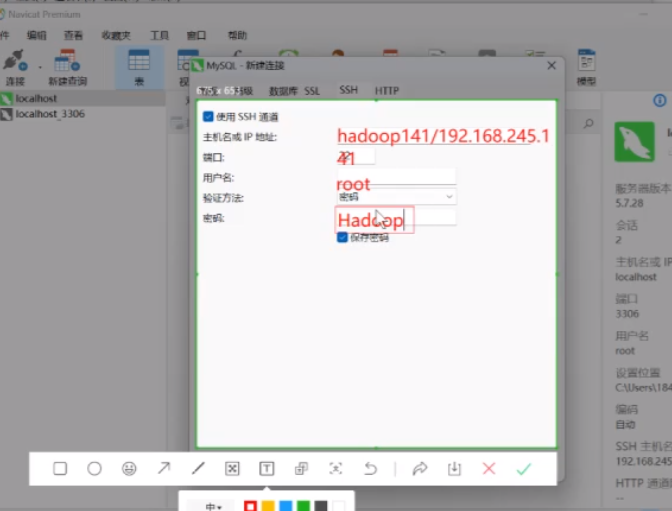
还需要SSH转接虚拟机
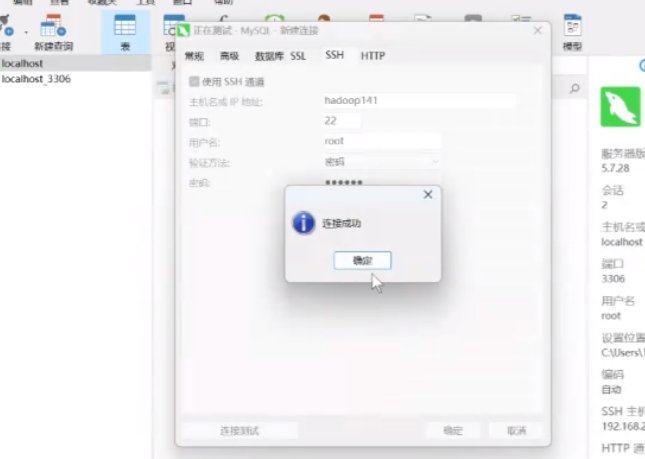
测试连接成功继续
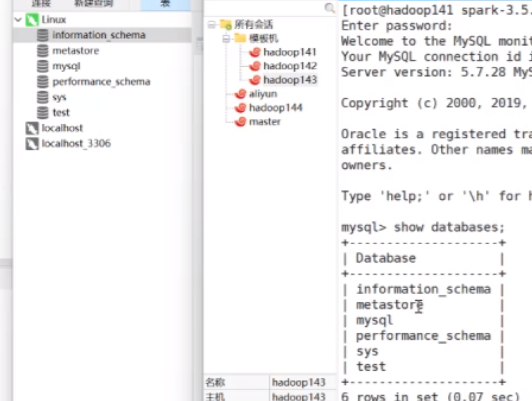
双击连接,里面数据库显示是一样的
就可以通过spark提交获取数据库里面的信息
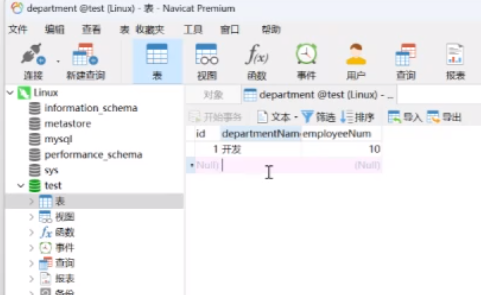
现在要做的是spark在Mysql里面去读取,然后存入到一个csv文件里面
实现编码,首先要导包
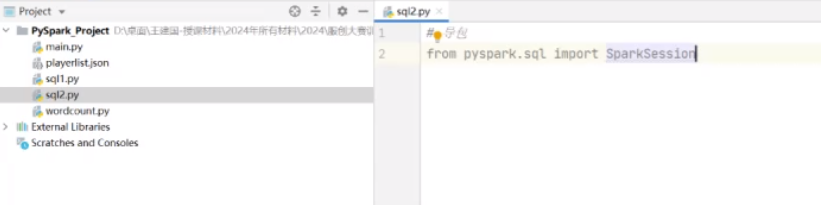
from pyspark.sql import SparkSession

spark = SparkSession.builder.master('spark://hadoop141:7077').appName('ReadMysql').getOrCreate()
注意读取的所有东西,要按照虚拟机的位置来写
spark想要读取数据库有个read函数,jdbc连接,想要连接数据库要记住四个url、driver(驱动)、user、password


这里用的test数据库
读的时候还需要告诉它读哪个表所以要加
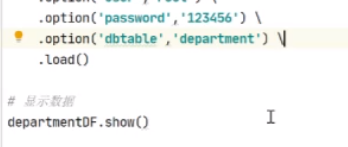
.option('dbtable','department').load()
departmentDF.show()
然后你需要先回到hadoop141里,因为数据库的驱动程序你要找到一个具体的位置
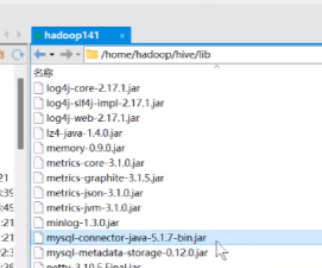
看见有这个jar包

要先切换位置
cd /home/hadoop/hive/

cd lib/
ls -l
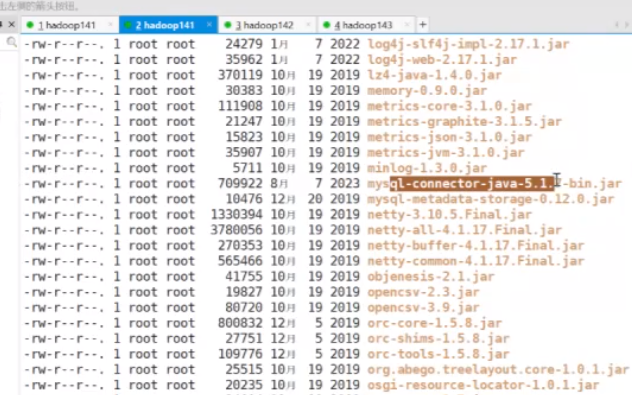
这里面能够找到

指定驱动,然后在告诉他的驱动 然后把jar包显示出来 后面还要有执行的文件路径
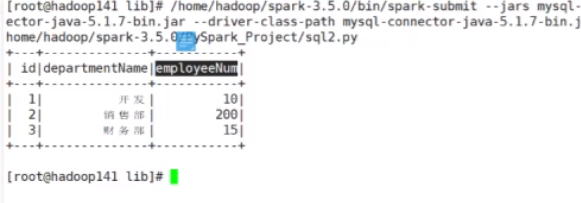
接下来保存数据

先把前面这个换成local本地的

保存后重新执行
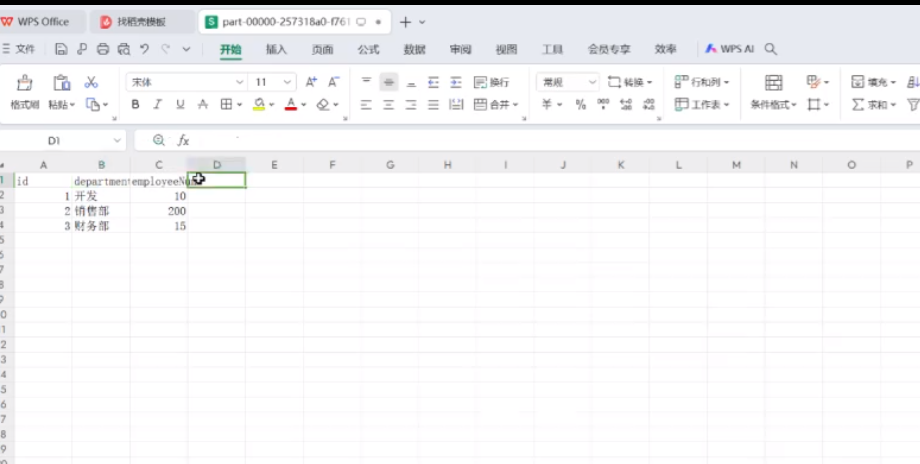
这就是最终执行出的数据,这是一个简单读取数据、写入文本的案例

用这个也行
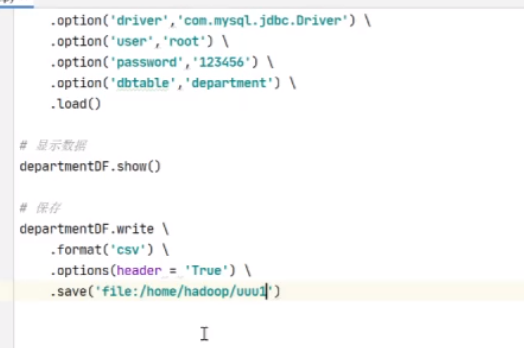
之后必须要在虚拟机里执行,里面的路径也是虚拟机的路径
之后把这两个文件ctrl+c,
新建一个date包,放在包里面
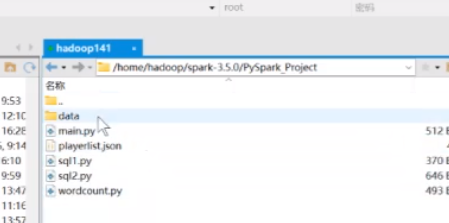
然后在这里面就能看的到了
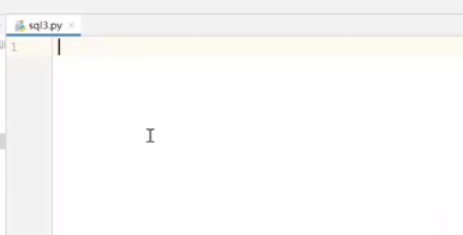
新建sql3python文件
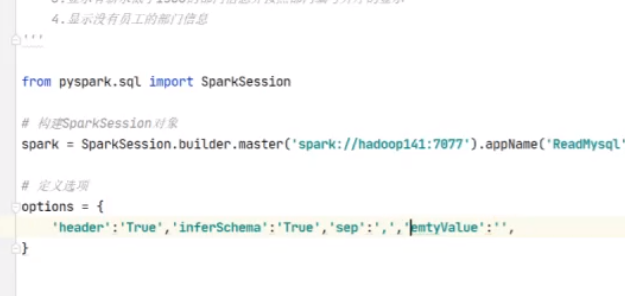
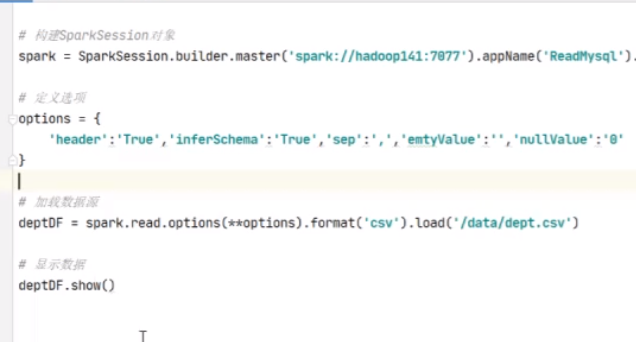
如果有空值用’ '代替


加载数据源读取csv文件
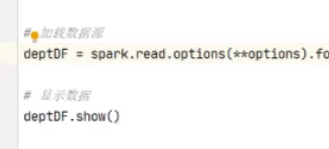
然后显示数据
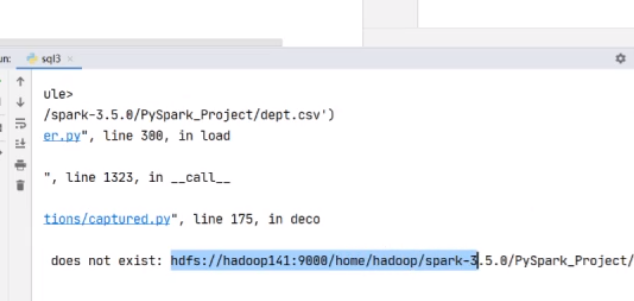
没找到因为它默认的是hdfs,如果想读取本地要加入file:

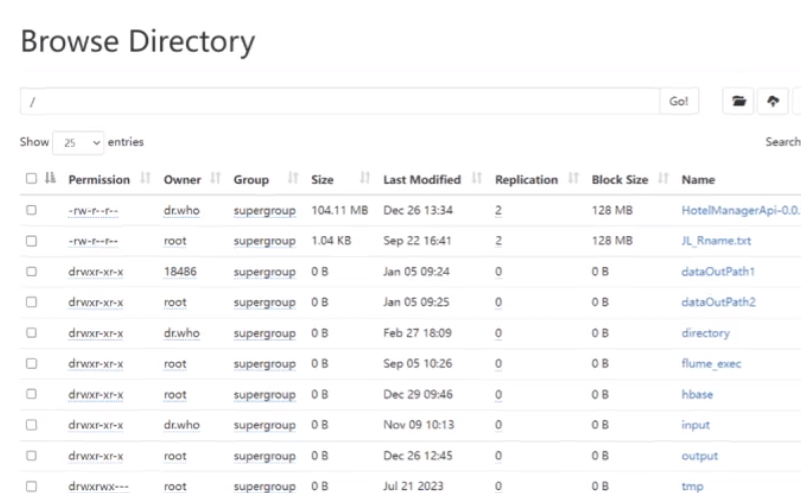
或者可以把csv传入到hdfs里面,记录相对应的路径后可以读取
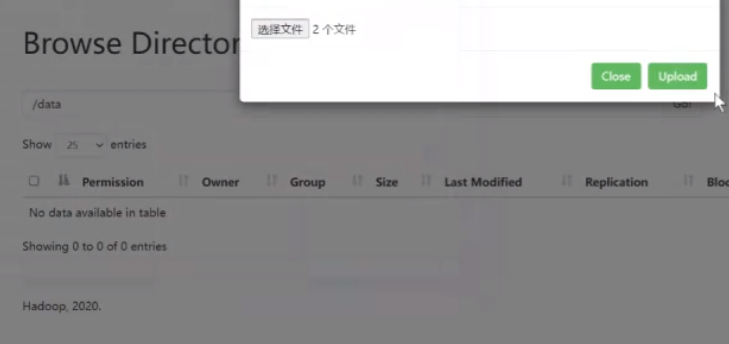
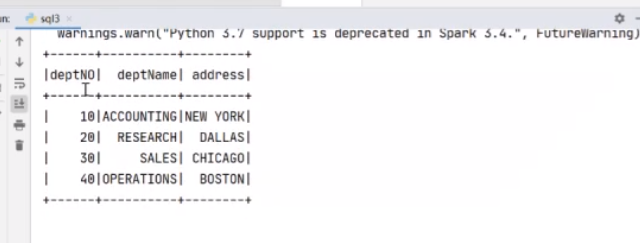
这个比较慢,和电脑配置有关

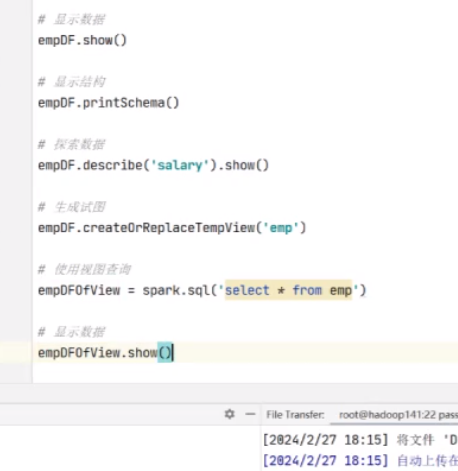
还可以显示结构
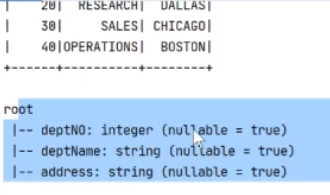
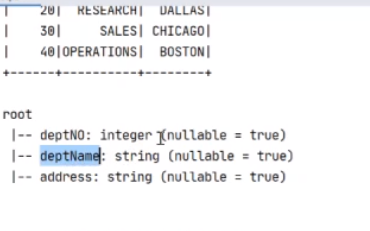
还可以探索数据

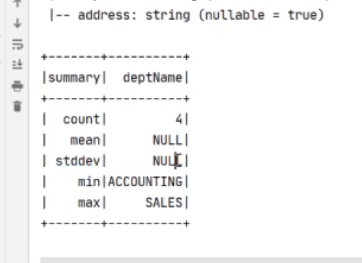

用sql来读取csv文件里的数据,spark主要做的就是数据分析
等于csv文件给它形成了一个数据库
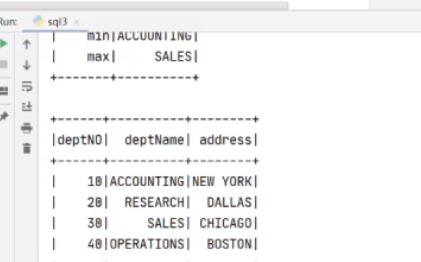
接下来弄另一个

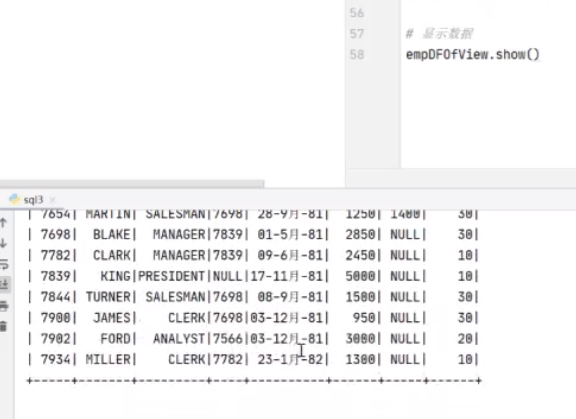
出来了

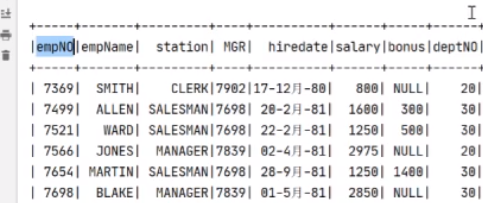
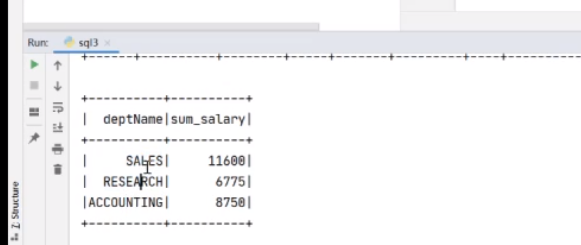
然后准备查询这个和这个
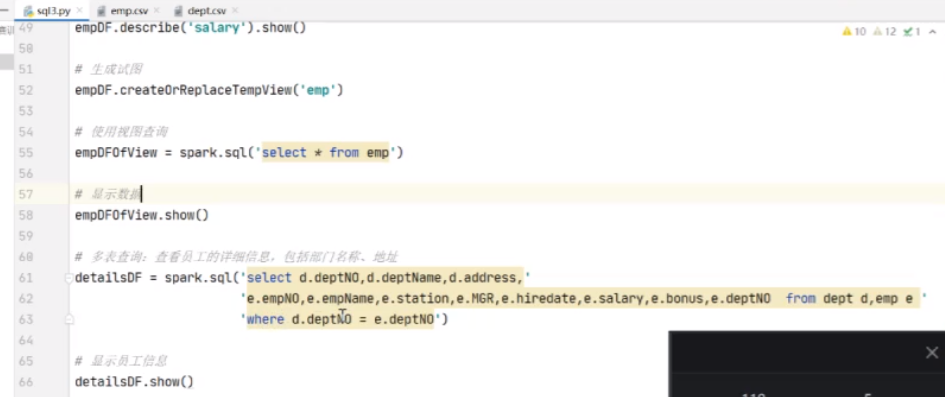
e后面不要忘了加空格,不然不能自动识别到
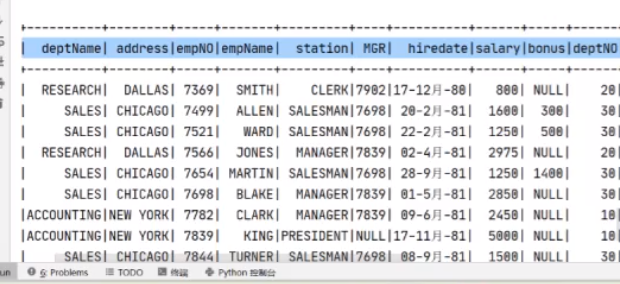
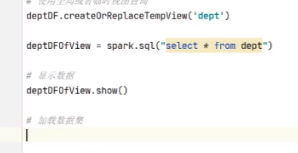
既然出来了,就给他创建一个视图,后面所有信息都可以从这里去获取
有了这个details就可以实现业务分析了


















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









