






分布式文件系统是分布式存储的一种实现,它与分布式块存储、分布式对象存储是同一层级、提供不同访问抽象和适用场景的存储解决方案。它们都属于分布式系统这个更大的范畴。互联网的兴起、大数据时代的到来、云计算的发展、科学计算(如基因测序、天体物理模拟)等场景产生了海量数据存储、高并发访问和高可靠性的需求,这些都极大地推动了分布式文件系统的发展和应用。像 Google 的 GFS 和开源的 HDFS 就是为了支撑大规模网络爬虫数据处理和 MapReduce 计算而诞生的典型例子。
1. 什么是分布式文件系统?
分布式文件系统是一种允许文件存储在网络上的多台物理服务器(称为节点或服务器)上,但对用户或应用程序来说,它看起来就像一个单一的、本地的文件系统。它将文件的存储和管理分布到多个机器上,以克服单机文件系统在容量、性能和可靠性上的限制。
简单来说,它解决了如何跨多台机器存储和访问大量数据的问题,同时提供统一的访问接口。
2. 为什么需要分布式文件系统?(主要优势)
-
可扩展性 (Scalability):
-
存储容量扩展: 当存储需求增长时,可以通过向集群中添加更多的存储节点来轻松扩展总容量,理论上可以达到 PB 甚至 EB 级别。
-
吞吐量扩展: 更多的节点意味着可以并行处理更多的读写请求,提高了整体的数据访问吞吐量。
-
-
高可用性与容错性 (High Availability & Fault Tolerance):
-
通过在不同的节点上存储文件的多个副本(数据冗余/Replication),即使部分服务器发生故障(如硬盘损坏、机器宕机),数据仍然可以从其他副本访问,系统可以继续提供服务,大大提高了数据的可靠性和服务的可用性。
-
-
高性能 (High Performance):
-
并行处理: 大文件被分成多个数据块(Block/Chunk)存储在不同的节点上。读取大文件时,可以从多个节点并行读取数据块,提高了读取速度。
-
负载均衡: 访问请求可以分发到不同的节点上,避免单点性能瓶颈。
-
-
数据共享与协作 (Data Sharing & Collaboration):
-
网络中的多个用户或应用程序可以方便地访问和共享存储在分布式文件系统中的同一份数据。
-
-
透明性 (Transparency):
-
位置透明性: 用户不需要知道文件具体存储在哪台物理服务器上。
-
访问透明性: 用户使用与访问本地文件系统类似的方式(如标准的 POSIX 接口或特定的 API)来访问分布式文件系统中的文件。
-
3. 分布式文件系统是如何工作的?(核心概念)
虽然具体实现各异,但大多数分布式文件系统包含以下关键组件和概念:
-
节点 (Nodes): 组成分布式文件系统的各个物理或虚拟服务器。通常分为管理元数据的节点和存储实际数据块的节点。
-
元数据节点 (Metadata Node / NameNode / Master): 负责管理文件系统的命名空间(目录树、文件名)、文件属性(权限、大小、时间戳)以及文件到数据块的映射关系(即一个文件由哪些数据块组成,每个数据块存储在哪些数据节点上)。元数据的管理是 DFS 的核心和难点,可能是集中的(如 HDFS NameNode)或分布式的(如 Ceph MDS)。
-
数据节点 (Data Node / Slave): 负责存储实际的文件数据块,并处理来自客户端的读写请求。它们会定期向元数据节点汇报自身状态和所存储的数据块信息。
-
-
客户端 (Client): 用户或应用程序通过客户端与分布式文件系统交互。客户端首先向元数据节点查询文件的位置信息,然后直接与相关的数据节点进行数据传输。
-
文件分块 (File Chunking/Blocking): 大文件被分割成固定大小(如 64MB, 128MB, 256MB)的数据块。这是实现并行读写和数据分布的基础。
-
数据复制/冗余 (Data Replication): 为了容错,每个数据块会被复制多份(通常是 3 份),并存储在不同的数据节点上(通常还会考虑机架感知 Rack Awareness,确保存储在不同物理机架上)。当某个节点失效时,可以从其他副本读取数据。
-
网络通信: 所有节点和客户端之间通过网络进行通信,传输控制信息(元数据操作)和数据。
-
一致性模型 (Consistency Model): 定义了当数据被写入或修改后,后续的读取操作能读到什么版本的数据。分布式系统中的一致性比单机系统复杂,有强一致性、最终一致性等不同模型。
4. 常见的分布式文件系统示例:
-
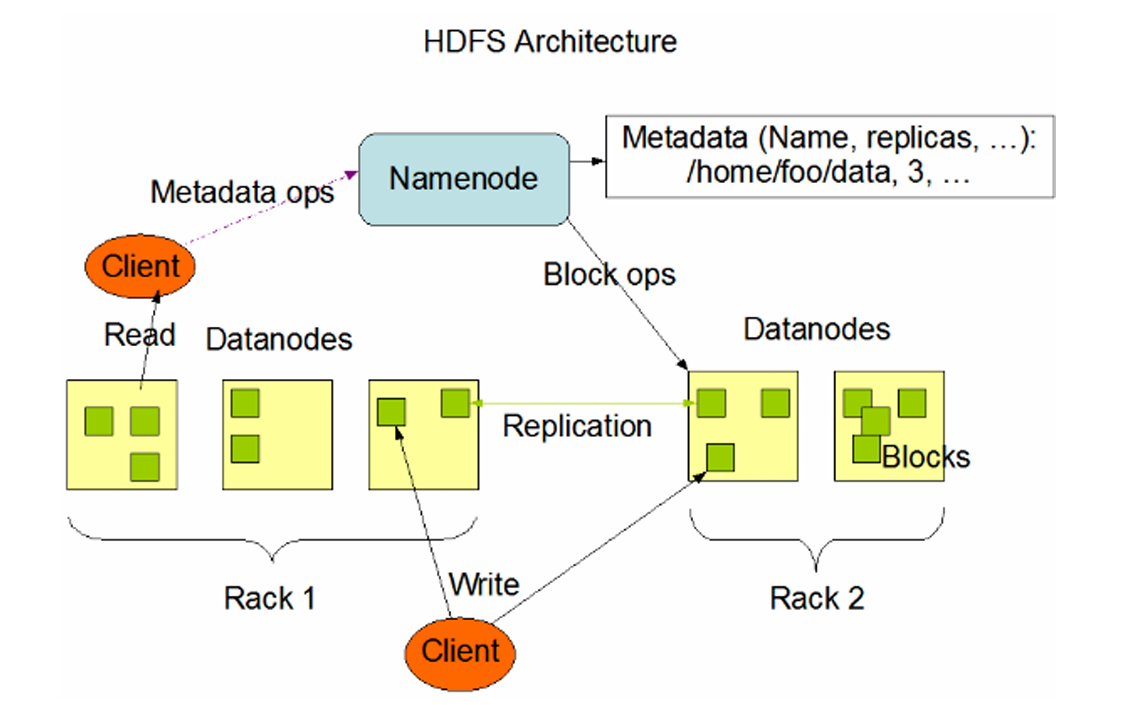
Hadoop Distributed File System (HDFS):
-
为运行 MapReduce 等大数据处理框架而设计。
-
优化点:高吞吐量、对超大文件(GB 到 TB 级)友好、高容错性。
-
架构:经典的 Master/Slave 结构(NameNode + DataNodes)。
-
特点:写入一次,读取多次(WORM)模型优化,对随机写入支持较弱。
-

-
Network File System (NFS):
-
历史悠久,广泛使用的标准。
-
目标:让用户像访问本地文件一样访问网络上的文件。
-
架构:相对简单,Client/Server 模式。
-
特点:易于部署和使用,通常用于企业内部的文件共享,扩展性和容错性相对 HDFS 等较弱。
-
-
CephFS:
-
开源、高可扩展、高性能的分布式文件系统。
-
架构:去中心化设计,元数据服务 (MDS) 也可以集群化,数据存储基于 RADOS 对象存储层。
-
特点:提供 POSIX 文件系统接口,动态扩展性好,高可靠性。
-
-
GlusterFS:
-
开源、可扩展的网络附加存储 (NAS) 文件系统。
-
架构:无中心元数据服务器设计,通过哈希算法确定文件位置。
-
特点:部署灵活,易于扩展,适合多种工作负载。
-
-
Google File System (GFS): (内部系统,非开源,但其设计思想影响深远,HDFS 受其启发)
-
为 Google 内部大规模数据处理需求设计。
-
特点:针对 Google 应用特点优化,如大文件、顺序读写、组件故障是常态等。
-
5. 面临的挑战:
-
一致性维护: 在数据有多个副本的情况下,保证数据的一致性是一个复杂的问题(CAP 理论)。
-
网络延迟与带宽: 系统性能严重依赖于网络状况。
-
元数据管理瓶颈: 在中心化元数据设计的系统中,元数据节点可能成为性能瓶颈或单点故障(需要高可用方案)。
-
复杂性: 设计、部署和维护分布式文件系统比单机系统复杂得多。
-
安全性: 在网络环境中保证数据的安全访问和传输更为困难。
总而言之,分布式文件系统是现代计算基础设施(尤其是在大数据、云计算领域)的基石,它通过将数据分散存储在多台机器上,提供了传统单机文件系统无法比拟的可扩展性、可靠性和性能。

















 982
982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









