












现在的
AI
模型中包含大量的矩阵运算,
AI
专用芯片都是对矩阵乘法做了优化,通过引
入各种处理单元来高效进行矩阵运算。

训练芯片需要考虑的因素更多,设计上也更加复杂,精度通常为
FP32
、
FP16
推理芯片考虑的因素较少,对精度要求也不高,
INT8
即可

云端芯片部署在专业机房,对环境要求不高;边缘计算通常部署的户外,需要适应高温
和低温环境;终端设备主要考虑功耗和成本
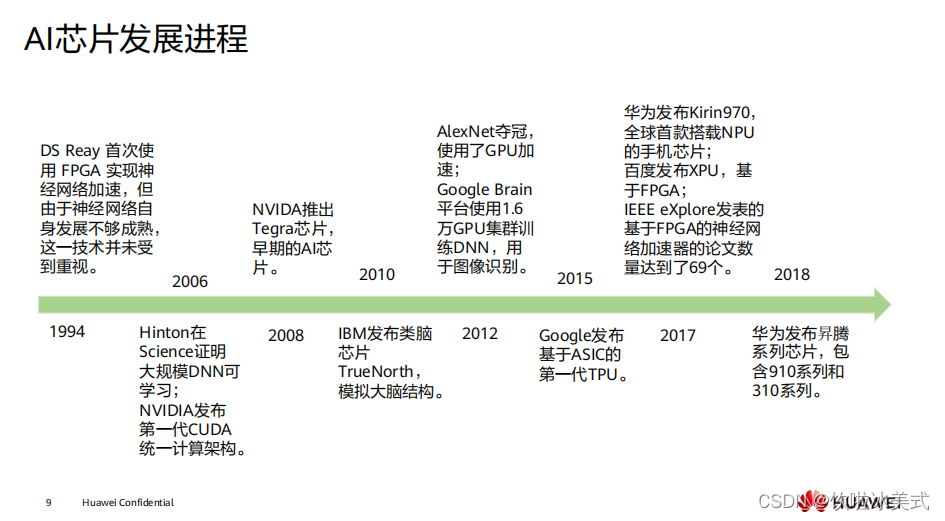
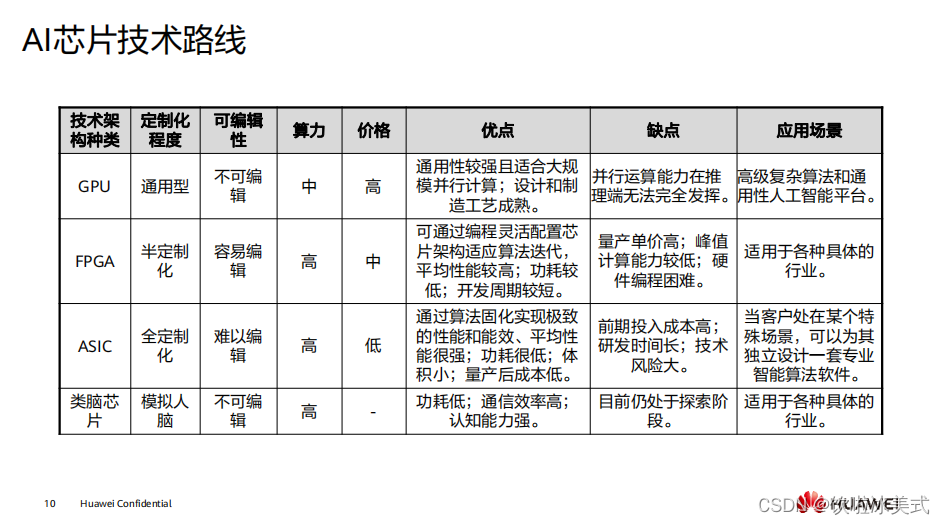
现在芯片领域主流的为
GPU
、
FPGA
、
ASIC
,后两者衍生出了
XPU
、
TPU
等一系列芯片
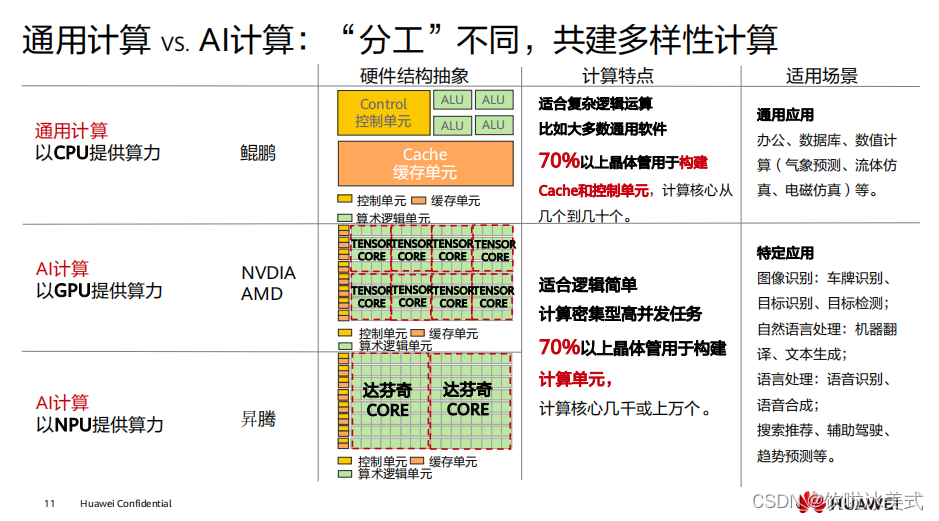
CPU
考虑通用计算,
GPU
考虑数学计算,
NPU
考虑
AI
需要的矩阵计算



对于
CPU
和
GPU
,比较有效能够提高
AI
算力的方法都是加入
AI
专用计算模块

两者目前发力的领域不同,并无明显的竞争关系

https://zhuanlan.zhihu.com/p/152167194?from_voters_page=true

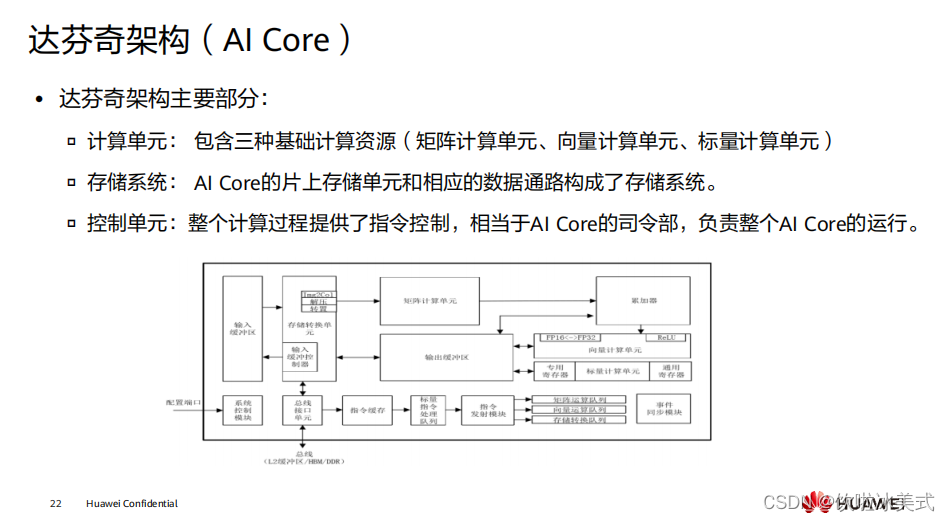
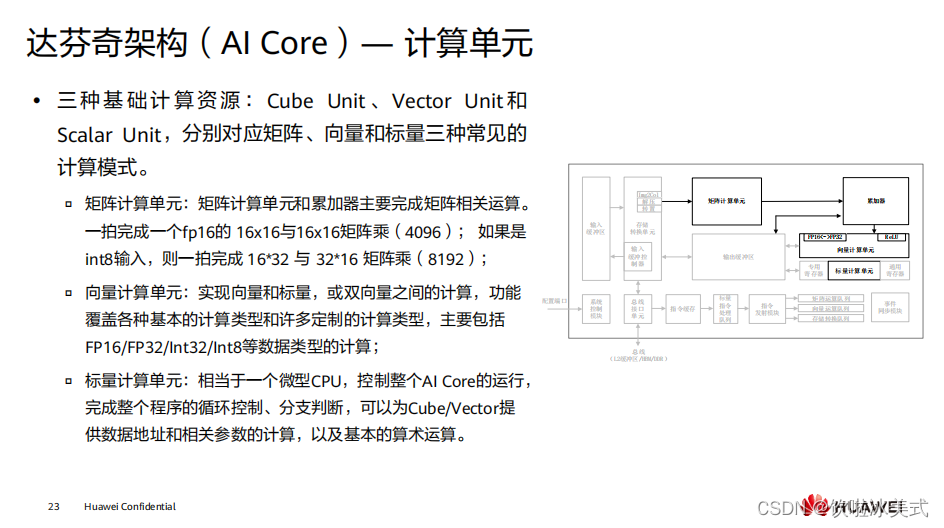
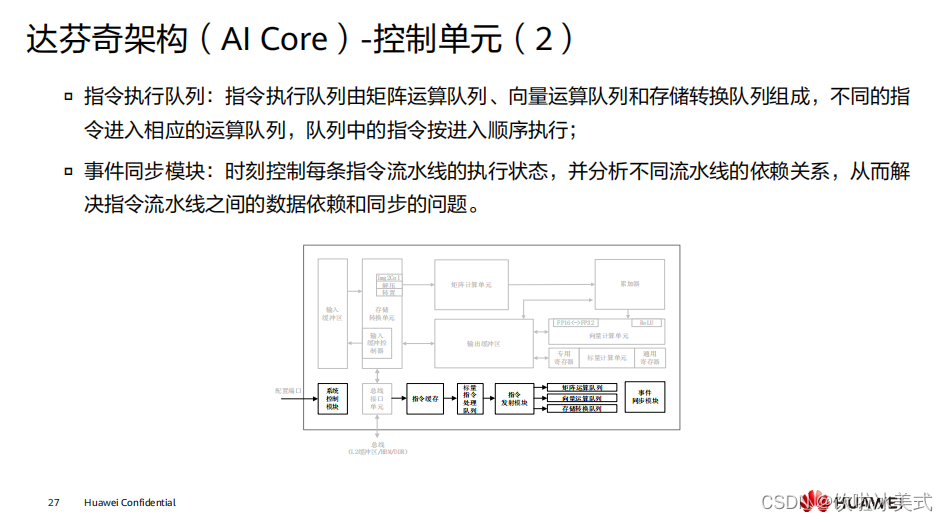
达芬奇架构的核心就是
CUBE
计算单元
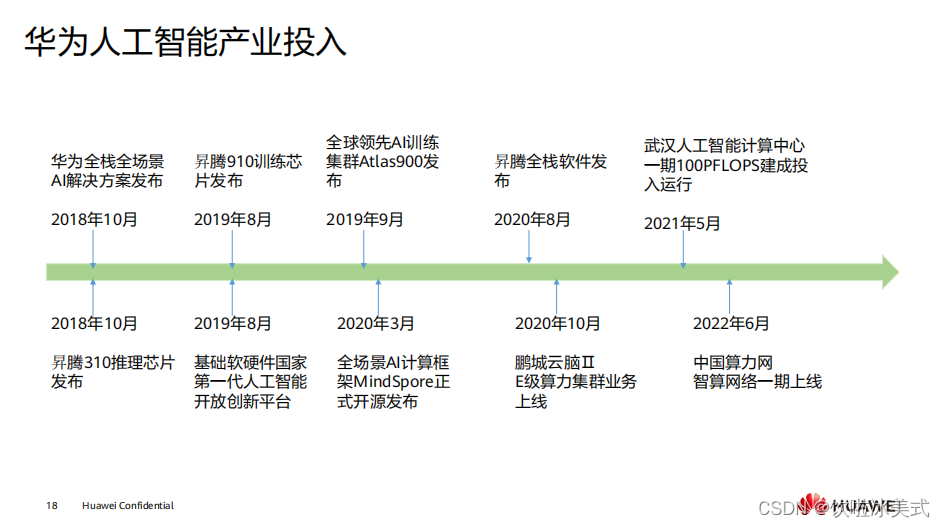
科技部在
2019
世界人工智能大会宣布,将依托华为建设基础软硬件国家新一代人工智
能开放创新平台,面向各行业、初创公司、高校和科研机构等的
AI
应用与研究,以云
服务和产品软硬件组合的方式,提供全流程、普惠的基础平台类服务。

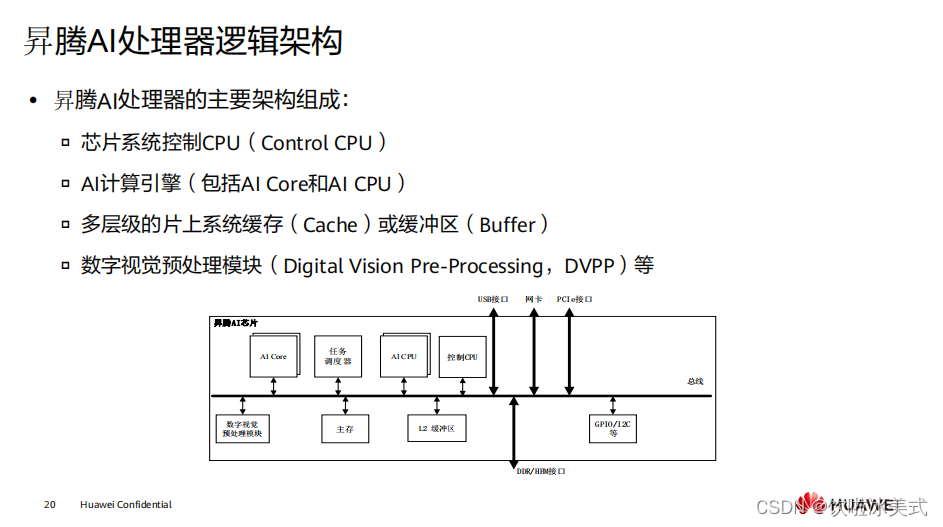

AI Core
负责高效矩阵运算,
AI CPU
负责通用运算




https://www.hiascend.com/zh/software/cann

推理类应用指基于
AscendCL
开发的应用,框架类为
MindSpore
等底层使用
昇
腾芯片
训练的框架,

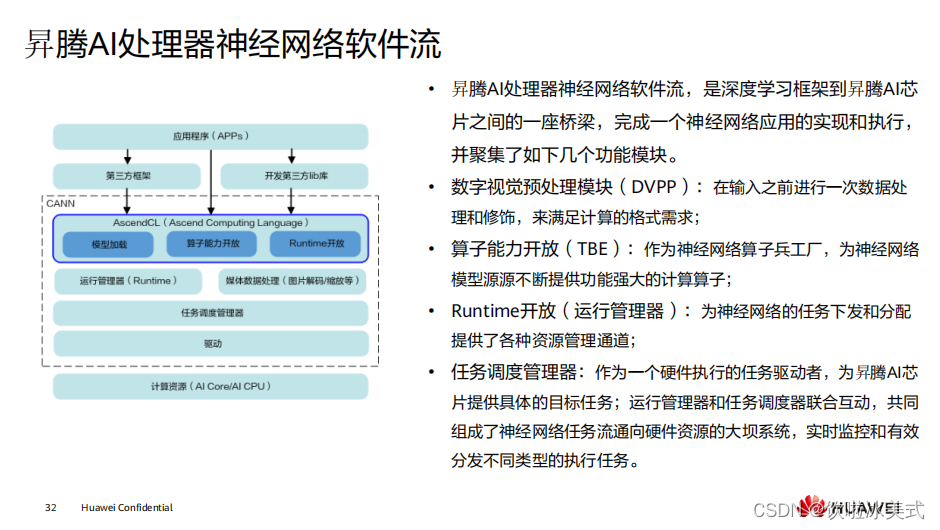
此处展示的是推理应用的神经网络软件流,非训练的


200
加速模块支持调整功耗,不同功耗对应的算力也不同



 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1739
1739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









