







 本文介绍了Python的Scrapy框架,它是一个用于web抓取和数据提取的高效工具。文章涵盖了Scrapy的整体架构,包括爬取流程和数据流,并简述了实战应用。
本文介绍了Python的Scrapy框架,它是一个用于web抓取和数据提取的高效工具。文章涵盖了Scrapy的整体架构,包括爬取流程和数据流,并简述了实战应用。
一、简介
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
所谓网络爬虫,就是一个在网上到处或定向抓取数据的程序,当然,这种说法不够专业,更专业的描述就是,抓取特定网站网页的HTML数据。抓取网页的一般方法是,定义一个入口页面,然后一般一个页面会有其他页面的URL,于是从当前页面获取到这些URL加入到爬虫的抓取队列中,然后进入到新页面后再递归的进行上述的操作,其实说来就跟深度遍历或广度遍历一样。
Scrapy 使用 Twisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy 使用 Twisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。
二、整体架构
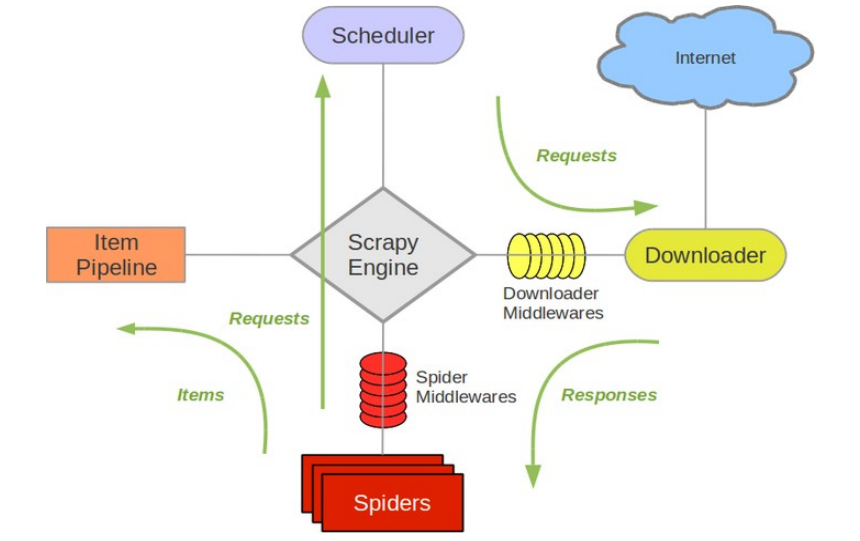
- 引擎(Scrapy Engine),用来处理整个系统的数据流处理,触发事务。
- 调度器(Scheduler),用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
- 下载器(Downloader),用于下载网页内容,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









