






917的服务器一直连接超时 所以租了个autoDL的3090
一、数据准备
1.原始数据集
- 7581开源
- 工地数据集来自师兄

共14620张
210000 到217999 一共8000张是工地的(李师兄打的) 有hat和person、head
待解决:工地上的图片 hat和head基本都检测出来了,但是很多person没有检测出来 所以我需要再对这8000张 用李师兄的权重重新跑一边
还有6620张 来自开源
2.重构数据集(12.17版本、12.25版本)
- 第一次使用训练的数据集 备份在 E:\object detection\helmet_project\yolov5-6.1\VOCdevkit(back12.17 )
- 第二次训练 12.25版本 images1中的+ 两个开源 共4223 张 E:\object detection\helmet_project\yolov5-6.1\VOCdevkit(back12.25)
old:
0:person
1:hat
2:head
new:
0:person
1:personNoHat
参考:
1.增加数据集的分类
YOLOv5在建筑工地中安全帽佩戴检测的应用(已开源+数据集) - 知乎 (zhihu.com)
2.merge_data.py
Smart_Construction/data/gen_data/merge_data.py at master · PeterH0323/Smart_Construction · GitHub
3. 炮哥 vocToYolo
目标检测---数据集格式转化及训练集和验证集划分_bndbox-CSDN博客
4. yoloToVoc
方法一
Yolo标准数据集格式转Voc数据集_数据集转化为voc格式-CSDN博客
步骤:
本地代码 :E:\object detection\helmet_project\yolov5-6.1
数据:E:\object detection\dataset\helmet和E:\object detection\helmet_project\yolov5-6.1的VOCdevkit*
(注意 目前只做了images(useful)1中一部分 截止到12月19号)
1.检测person
yolov5 会推理出所有的分类,并在 inference/output 中生成对应图片的 .txt 标签文件;
(注意VOC2008已经改动 原本是跑了1608张图片 来自images(useful)1中前半部分开源的)
python detect.py --save-txt --source "E:\object detection\dataset\helmet\VOC2008\JPEGImages" --weights yolov5x.pt
结果在:E:\object detection\helmet_project\yolov5-6.1\runs\detect\exp8\labels
2. vocToYolo(为了merge)
E:\object detection\helmet_project\yolov5-6.1\voctoyolo.py
classes = ["person"]
# classes=["ball"]
TRAIN_RATIO = 100
将E:\object detection\helmet_project\yolov5-6.1\VOCdevkit(12.17)\VOC2007\Annotations下的xml转成了E:\object detection\helmet_project\yolov5-6.1\VOCdevkit(12.17)\VOC2007\YOLOLabels
3.merge
E:\object detection\helmet_project\yolov5-6.1\merge_data.py
将YOLOV5_LABEL_ROOT (步骤1得到的)的txt 和DATASET_LABEL_ROOT(步骤2得到的)的txt merge 是原地merge到 DATASET_LABEL_ROOT

4. yoloToXMl(为了打标签 以及和工地的一起划分)
E:\object detection\helmet_project\yolov5-6.1\yoloToVocNew.py
把3中得到的txt转为xml

5 jump到打标签
6.再次vocToYolo(划分训练集和测试集)

注意 换了文件夹
- xml都放到如下文件夹
- 对应的image放进去

补充开源行人数据集
行人检测数据集汇总(持续更新) - 知乎 (zhihu.com)
以下为voc格式的
【车辆行人检测和跟踪数据集及代码汇总】_车辆检测数据集-CSDN博客
YOLO行人目标检测数据集dataset_person.zip_行人目标检测数据集,目标检测行人数据集资源-CSDN文库
最后下的这两个

YOLO行人目标检测数据集dataset_person.zip_行人目标检测数据集,目标检测行人数据集资源-CSDN文库
CUHKOcclusionDataset数据集yolo格式+VOC格式包括划分好的训练集和数据集_TT-100k数据集资源-CSDN文库
dataset-person

person2 3012张
person1 803张 用这个!
CUHK occlusion
set00 是车载摄像头 105张 不用了
把遮挡的部分也框了出来

set01 质量很好 70张 用!
set02 车载 不是很清楚 很多远处的人 没办法判断带没带 110张 勉强用
set03 是路人视角 128张 也可以
set04 路人视角 47张 稍微有点远了 不用!
set 05 路人视角 36张 可以用
set06 监控视角! 311张 perfect!
set07 商场监控 44张 用
set08 天桥监控 212张 用!
E:\object detection\dataset\helmet\VOCdevkit\VOCdevkit\VOC2007\useful 剩余 911张
person转为personNoHat
最终结果 就是把0转为1
使用vocToYolo (直接9:1划分好了)
结果分别保存在 E:\object detection\dataset\helmet\dataset_person\dataset_person\person-1\划分好的!!
E:\object detection\dataset\helmet\VOCdevkit\划分好的!!
到时候直接追加到总的就行
但是还没有挑 默认没有安全帽
3.打标签-labelimg
(12.17打标签到210684)
目标检测---利用labelimg制作自己的深度学习目标检测数据集_目标检测利用labeling制作-CSDN博客
E:\object detection\dataset\helmet\VOC2008

labelimg装在bytetrack环境中 ,然后去指定文件夹下 执行命令
注意这个按钮
一些标注rule
- 注意 无法判断的person(只有一只手 没有头部露出 肉眼分不清 ) 默认是戴了的 重点是将没带的挑出来
- 有时候只有一张脸(没戴帽子) 也可认为是没戴的 而不用全身
- 而且 原本无法判断帽子帽子是否戴在头上(拿在手里?)、是否规范佩戴 现在都可以解决了
- 安全帽没有黑色 但是对于戴了黑色帽子的建议标注为person
- 骑行头盔 不算!
- 对各种姿势的人标注 弯腰 蹲下 躺下
- 对只有一个人脸 yolov5x能认出来他是个人 所以我也标注
- 主要区分了 草帽、保安、军人/警察的帽子、自行车头盔、毛巾、遮阳帽
- 密集的图片删掉了 我的场景绝对不会很密集
- 解决了小目标的问题 远距离下 检测一个人的难度小于检测安全帽
- 之前的数据集 角度是水平的 但是实际应用应该是摄像头视角 补充的开源行人数据集也应该是摄像头视角


改动12.23 -12.25
12.17版本到210684
改动:E:\object detection\dataset\helmet\VOC2008\forReDet
images1 剩余2646张 工地838张
- 210111到210998 是工区右1 很多人没检测出来 而且没必要留这么多 所以重新跑 +留 210111到210311(200张)
-
210999 到211308 工区大门 留210999到211100 大门共200张
-
211309 到211784 03拌合站东 (小500张 画面很复杂 遮挡严重) 干掉
-
211785到212116 工区右2 留211785到212000 (168张)
-
212122到 212132 03拌合站东 干掉
-
212133到212441 工区大门 留212133到212200
-
212442 到 212779 03拌合站东 干掉
-
212780到 213136 工区右2 留213000到213136
-
213137到 213551 大门 (夜晚) 留 213290到213508
-
213552到213588 右1 干掉
images2和3 暂时不用 后续看看视频再少量补充500张吧
二、使用AutoDL训练
1.参考
1.yolov8官方文档
2. 主要步骤
我使用的base环境
在AutoDL中使用YOLOV8训练自己的数据集-CSDN博客
配置:
1.train.py (或者使用命令
2.data.yaml
3. yolov8.yaml 作者说“同时将yolov8n.yaml文件中的nc 改为nc=2,我的类别是两个” 但是现在版本
/root/autodl-tmp/ultralytics/ultralytics/cfg/models/v8/yolov8.yaml 没有之前yolov8n.yaml
包含了 n s m l x 后面改模型的时候再自己改吧

3. 其它
使用自定义数据集训练YOLOv8模型(基于AutoDL算力云平台,内附免费的源码、数据集和PYQT-GUI界面)-CSDN博客
手把手教你使用AutoDL云服务器训练yolov5模型-CSDN博客
云服务器训练YOLOv8-新手教程 - 哔哩哔哩 (bilibili.com) 迪菲赫尔曼 (没看)
4.YOLOv8
YOLOv8训练参数详解(全面详细、重点突出、大白话阐述小白也能看懂)-CSDN博客
三种训练模式
手把手实现 | 使用Yolov8训练自己的数据集【环境配置-准备数据集(采集&标注&划分)-模型训练(多种方式)-模型预测-模型导出】-CSDN博客
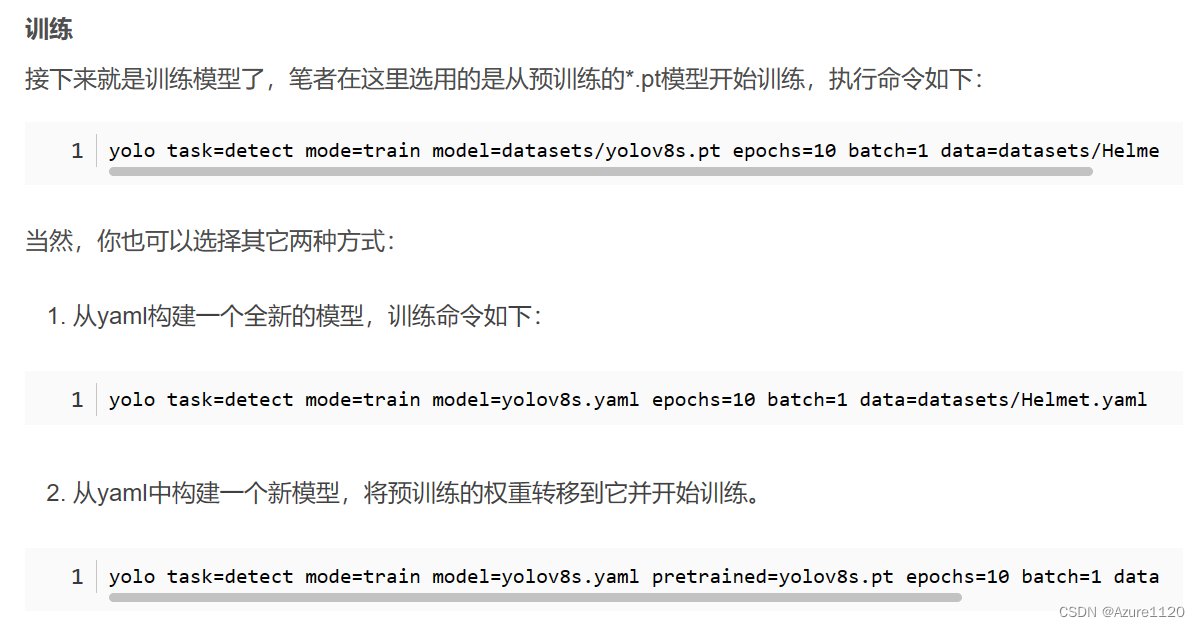
yolov8的train.py
第一个model没有用到预训练
第二个 就是pt
第三个 改了backbone以后用它!
from ultralytics import YOLO
# 加载一个模型
model = YOLO('yolov8n.yaml') # 从YAML建立一个新模型
model = YOLO('yolov8n.pt') # 加载预训练模型(推荐用于训练)
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # 从YAML建立并转移权重
# (另一种解读) 从YAML加载 然后再加载权重
# 训练模型
results = model.train(data='coco128.yaml', epochs=100, imgsz=640)model: 模型文件的路径。这个参数指定了所使用的模型文件的位置,例如 yolov8n.pt 或 yolov8n.yaml。
选择.pt和.yaml的区别
.pt类型的文件是从预训练模型的基础上进行训练。若我们选择 yolov8n.pt这种.pt类型的文件,其实里面是包含了模型的结构和训练好的参数的,也就是说拿来就可以用,就已经具备了检测目标的能力了,yolov8n.pt能检测coco中的80个类别。假设你要检测不同种类的狗,那么yolov8n.pt原本可以检测狗的能力对你训练应该是有帮助的,你只需要在此基础上提升其对不同狗的鉴别能力即可。但如果你需要检测的类别不在其中,例如口罩检测,那么就帮助不大。
.yaml文件是从零开始训练。采用yolov8n.yaml这种.yaml文件的形式,在文件中指定类别,以及一些别的参数。
2.上传文件
最开始使用jupyterLab踩了大坑 、还可以使用网盘
最终使用Xshell
3.解决RuntimeError
yolov8训练自己数据集遇到找不到yaml中路径问题-CSDN博客

1.使用绝对路径
这个方法其实没问题 而且会把settings.yaml中的ignore掉
但是lnb把datasets拼成了datesets 所以一直报错
2.相对路径
Yolov8训练自己数据集时出现的RuntimeError:DataSet ......error-CSDN博客
vim /root/.config/Ultralytics/settings.yaml 查看如下这样一个配置文件
其中datasets_dir 我修改了 它会去这个地方去找数据集 然后拼上data.yaml中的train和val

4.训练记录
1. 12.17第一次训练 使用12.17数据集 结果在 autodl-tmp/ultralytics/runs/detect/train30/weights
2. 12.25第二次训练 使用12.25数据集 train31
效果还不如第一次 容易把戴了的判断为没带 所以数据不是越多越好 感觉是因为增加的 dataset_person数据集的问题
5. 解决数据集waring问题
三种错误 2、3 还未解决 有空需要好好看
1.直接将png jped bmp等格式的图像数据强制转化为了jpg
WARNING ⚠️ /root/autodl-tmp/ultralytics/datasets/dataset/images/val/set00_set01-occ_16.jpg: corrupt JPEG restored and saved
YOLO系列模型训练日志【WARNING】 corrupt JPEG restored and saved/ignoring corrupt image/label:-CSDN博客

2. 负值
WARNING ⚠️ /root/autodl-tmp/ultralytics/datasets/dataset/images/val/set00_set06-occ_104.jpg: ignoring corrupt image/label: negative label values [ -0.0023041 -0.0025773 -0.0023041 -0.0025773 -0.0023041 -0.0025773 -0.0023041 -0.0025773 -0.0023041 -0.0025773 -0.0023041 -0.0025773 -0.0023041 -0.0025773 -0.0023041 -0.0025773 -0.0023041 -0.0025773]
3.标签重复
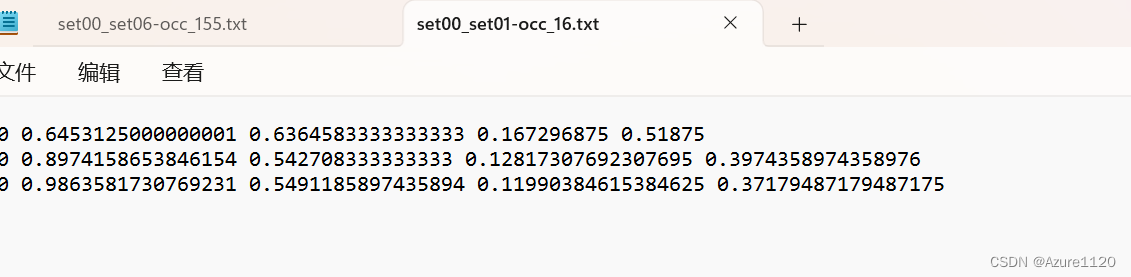
WARNING ⚠️ /root/autodl-tmp/ultralytics/datasets/dataset/images/val/set00_set06-occ_155.jpg: 6 duplicate labels removed

问题出在港大数据集 标签内部有负值
验证集共114个 有30多个出问题














 1555
1555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









