







Gorilla是一个基于LLaMA(Large Language Model with API)的大型语言模型,它可以生成适当的API调用。它是在三个大型的机器学习库数据集上训练的:Torch Hub, TensorFlow Hub和HuggingFace。它还可以快速地添加新的领域,包括Kubernetes, GCP, AWS, OpenAPI等等。在零样本的情况下,Gorilla超越了GPT-4, Chat-GPT和Claude的性能。
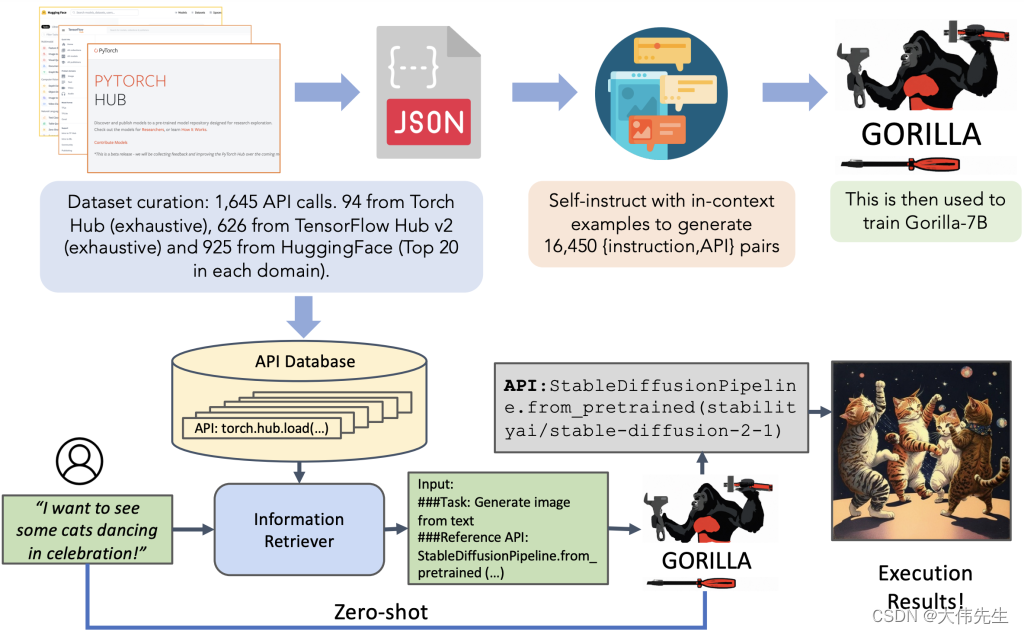
Gorilla的一个特点是它可以结合一个文档检索系统,从而能够适应测试时文档的变化,实现灵活的API更新和版本更换。它还显著地减少了直接使用LLM时常见的幻觉问题,提高了输出的可靠性和适用性。
为了评估Gorilla的能力,论文作者提出了一个全面的数据集APIBench,包括HuggingFace, TorchHub和TensorHub的API。Gorilla在这个数据集上表现出了强大的写API调用的能力,超过了GPT-4等其他模型。
Gorilla的代码、模型、数据和演示都可以在这个网址找到:https://github.com/ShishirPatil/gorilla 。
我觉得Gorilla是一个很有创意和前瞻性的项目,它展示了大型语言模型在使用API方面的潜力。我认为它可以为编程者提供很多便利和帮助,也可以为其他领域的应用提供灵感。
当然,它也有一些局限性和挑战,比如如何保证API调用的正确性和安全性,以及如何处理不同API之间的兼容性和冲突问题。我希望Gorilla能够不断地改进和完善,成为一个更加可靠和实用的工具。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1202
1202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









