









23年5月伯克利分校和微软的论文“Gorilla: Large Language Model Connected with Massive APIs”。
大语言模型(LLM)最近取得了令人印象深刻的进步,模型现在在各种任务中表现出色,例如数学推理和程序合成。 然而,其通过 API 调用有效使用工具的潜力仍未得到发挥。 即使对于当今最先进的LLM(例如 GPT-4)来说,这也是一项具有挑战性的任务,很大程度上是因为他们无法生成准确的输入参数,并且倾向于错误地使用 API 调用。 这里发布 Gorilla,一个基于 LLaMA 的微调模型,在编写 API 调用方面超越了 GPT-4 的性能。 与文档检索器结合使用,Gorilla 表现出强大的适应测试文档更改的能力,从而实现灵活的用户更新或版本更改。 它还大大减轻了直接提示LLM时经常遇到的幻觉问题。 为了评估模型的能力,引入 APIBench,一个由 HuggingFace、TorchHub 和 TensorHub API 组成的综合数据集。 检索系统与 Gorilla 的成功集成,表明LLM有潜力更准确地使用工具,跟上频繁更新的文档,从而提高其输出的可靠性和适用性。 Gorilla 的代码、模型、数据和演示可如下获取
https://gorilla.cs.berkeley.edu
LLM内部关于工具使用的讨论激增,其中 Toolformer 等模型处于领先地位 [33,19,21,26]。 通常合并的工具包括网络浏览器 [34]、计算器 [12, 39]、翻译系统 [39] 和 Python 解释器 [14]。 虽然这些努力可以被视为将LLMs与工具使用结合起来的初步探索,但它们通常侧重于特定的工具。 相比之下,本文旨在以开放式方式探索大量工具(即 API 调用),可能涵盖广泛的应用程序。
随着最近 Toolformer [33] 和 GPT-4 [29] 的推出,API 调用的重要性得到了强调,鼓励了许多使用 API 调用作为工具的工作 [35, 24]。 此外,API调用在机器人技术中的应用已经得到了一定程度的探索[41, 1]。 然而,这些工作主要旨在展示“促进”LLM的潜力,而不是建立系统的评估和训练方法(包括微调)。 另一方面,该工作集中于系统评估和建立供未来使用的流水线。
如图是API调用的例子:

APIBench,是一个由 TorchHub、TensorHub 和 HuggingFace API 模型卡构建的综合基准测试。 为了收集数据集,记录HuggingFace 的“模型中心”、PyTorch Hub 和 TensorFlow Hub 模型的所有在线模型卡。 为了简洁起见,分别将它们称为 HuggingFace、Torch Hub 和 TensorFlow Hub。
HuggingFace 平台托管和服务器大约 203,681 个模型。 然而,其中许多模型的文档质量较差、缺乏依赖性、模型卡中没有信息等。为了过滤掉这些模型,从每个域中挑选了前 20 个模型。 考虑多模态数据中的 7 个域、CV 中的 8 个域、NLP 中的 12 个域、音频中的 5 个域、表格数据中的 2 个域和强化学习中的 2 个域。 经过筛选,从 HuggingFace 中总共得到了 925 个模型。 TensorFlow Hub 版本为 v1 和 v2。 最新版本(v2)共有801个模型全部处理。 过滤掉其模型卡中几乎没有信息的模型后,还剩下 626 个模型。 与 TensorFlow Hub 类似,从 Torch Hub 获得 95 个模型。 然后,将这 1,645 个 API 调用中每个调用模型卡转换为具有以下字段的 json 目标(object):{domain,framework,functions,api_name,api_call,api_arguments,environment_requirements,example_code,performance 和 description}。 选择这些字段是为了将 ML 域内的 API 调用推广到其他域,包括 RESTful API 调用。
在自我指令范式 [42] 的指导下,采用 GPT-4 来生成合成指令数据。 提供三个上下文示例以及参考 API 文档,并要求模型生成调用 API 的真实用例。 特别指示模型在创建指令时不要使用任何 API 名称或提示。 为三个模型中心中的每一个构建六个示例(指令 API 对)。 这总共 18 个点是唯一手工生成或修改的数据。 对于 1,645 个 API 数据点中的每一个,对 6 个相应指令示例中的 3 个进行采样,生成总共 10 个指令 API 对,如图所示。
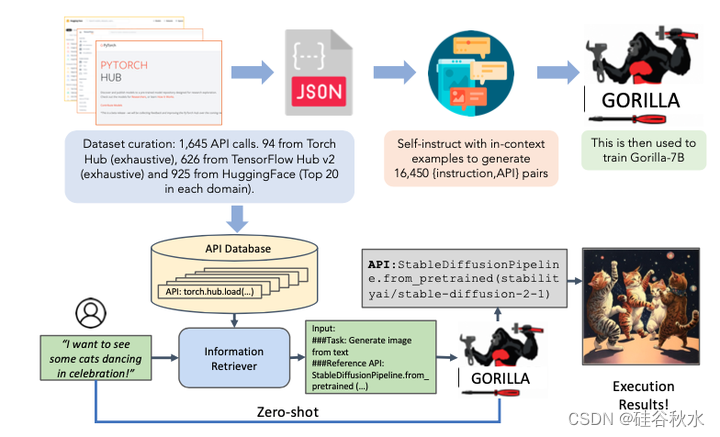
模型 Gorilla 是具有检索-觉察能力的微调 LLaMA-7B 模型,专门用于 API 调用。 用自我指令来生成{指令,API}对。 为了微调 LLaMA,将其转换为用户-智体的聊天-式对话,其中每个数据点都是用户和智体各一轮的对话。 然后,在基本 LLaMA-7B 模型上执行标准指令微调。 在实验中,训练了有或没有检索器的Gorilla。
上图所示Gorilla是一个使LLM能够与 API 交互的系统。 上半部分是训练过程,这是一个详尽的 ML API 数据集。 在推理过程中(下半部分),Gorilla 支持两种模式 - 检索和零样本。 在此示例中,它能够建议正确的 API 调用,以便根据用户的自然语言查询生成图像。要强调的是,只需要使用 GPT-4 来生成指令,这可以与 LLaMA、Alpaca 等开源替代模型进行交换。
在推理过程中,用户以自然语言提供提示。 这可以是一个简单的任务(例如,“我想识别图像中的目标”),或者他们可以指定一个模糊的目标(例如,“我要去动物园,并且想要跟踪动物 ”)。 Gorilla 与训练类似,可以通过两种模式进行推理:零样本和检索。 在零样本中,此提示(无需进一步的提示调整)将被馈送到 Gorilla LLM 模型,然后返回有助于完成任务和/或目标的 API 调用。 在检索模式下,检索器(BM25 或 GPT-Index)首先检索 API 数据库中存储的最新 API 文档。 然后将其连接到用户提示以及消息“使用此 API 文档作为参考:在将其提供给 Gorilla 之前”。 Gorilla 的输出是要调用的 API。 除了所描述的串联之外,没有在系统中进行进一步的提示调整。 虽然确实有一个执行这些 API 的系统,但这不是本文的重点。
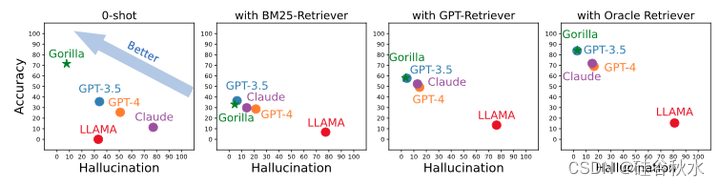
如图是四种设置下的准确性(与幻觉),即零样本(即没有任何检索器)和三种检索器的情况下。
归纳程序合成(即合成程序以满足测试用例)已在多种途径中取得成功 [4, 25]。 然而,测试用例在评估 API 调用时存在不足,因为通常很难验证代码的语义正确性。 例如,考虑对图像进行分类的任务。 有 40 多种不同的模型可用于该任务。 即使将范围缩小到单个 Densenet 系列,也有四种不同的配置可能。 因此,存在多个正确答案,并且很难通过单元测试判断所用API 在功能上是否等同于参考 API。 因此,为了评估模型的性能,用收集的数据集比较它们的功能等价性。 为了追踪数据集中哪个 API 是 LLM 调用,采用 抽象语法树(AST ,abstract syntax tree)匹配策略。 由于本文只考虑一个 API 调用,因此检查候选 API 调用的 AST 是否是参考 API 调用的子树可以揭示数据集中正在使用哪个 API。
识别甚至定义幻觉可能具有挑战性。 用 AST 匹配过程来直接识别幻觉。 将幻觉定义为 一种API 调用,它不是数据库中任何 API 的子树,即调用了一个完全想象的工具。 这种形式的幻觉与错误地调用 API 不同,将其定义为错误。
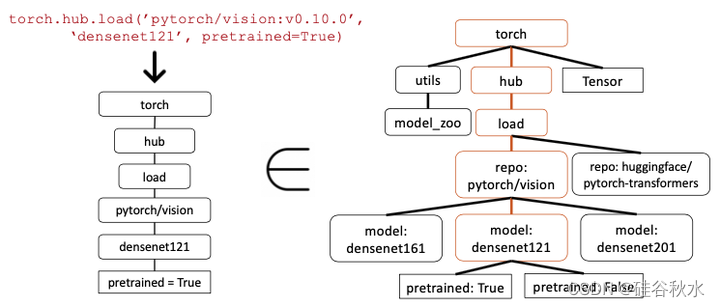
执行 AST 子树匹配来识别数据集中的哪个 API 是 LLM 调用。 由于每个 API 调用可以有许多参数,因此需要匹配每个参数。 此外,由于 Python 允许默认参数,因此对于每个 API,定义要在数据库中匹配的参数。 例如,在函数调用中检查 repo_or_dir 和模型参数。 这样,就可以轻松检查参数是否与参考 API 匹配。 在此示例中,Gorilla 返回 torch API 调用。 首先构建树,并验证它是否与数据集中沿节点 torch.hub.load-pytorch/vision 和 dendestnet121 的子树匹配。 但是,不会检查叶节点 pretrained = True 的匹配,因为这是一个可选的 python 参数。
详细信息请参见下图:左边是 Gorilla 返回的 API 调用,右边是AST;匹配的子树以棕色突出显示,表示 API 调用确实是正确的。
对收集的数据集进行了一系列实验,将模型 Gorilla 与其他模型进行基准测试,并探索不同的检索方法如何影响模型在进行 API 调用时的性能。 然后证明 Gorilla 可以轻松适应 API 文档中测试时的变化。 此外,还评估了 Gorilla 在约束下推理 API 调用的能力。 最后研究了在训练期间集成不同的检索方法如何影响模型的最终性能。
如图所示:Gorilla 的检索器-觉察训练使其能够对 API 中的变化做出反应。 第二列展示了将 FCN 的 ResNet-50 主干网络升级到 ResNet-101 的模型变化。 第三列展示了模型注册表从 pytorch/vision 到 NVIDIA/DeepLearningExamples:torchhub 的变化。


















 516
516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









